
Persistent storage verwijst naar het bewaren van gegevens op een niet-vluchtige manier, zodat ze beschikbaar blijven, zelfs nadat een apparaat of applicatie is uitgeschakeld of opnieuw opgestart. Door het opslaan en ophalen van gegevens kunnen webapplicaties gebruikersinformatie en states opslaan en op een betrouwbare manier hun werk doen.
In monolithische toepassingen is toegang tot de opslag eenvoudig, omdat de server en de opslag bij elkaar staan. Geografisch gedistribueerde systemen maken de toegang echter complexer, omdat het opslagsysteem beschikbaar moet blijven voor alle componenten wereldwijd.
Containerisatie maakt de zaak nog ingewikkelder, omdat containers licht, stateloos en efemeer zijn – ongeschikte eigenschappen voor het opslaan van gegevens. Daarom moet elke persistente opslagoplossing naadloos kunnen samenwerken met containers, wat nog een extra laag complexiteit toevoegt.
Kinsta’s gecontaineriseerde Applicatie Hosting maakt gebruik van Kubernetes persistente volumes om persistente opslag te koppelen aan een of meer processen van een applicatie. Kinsta gebruikers kunnen hun vereisten voor persistente opslag definiëren tijdens het creëren van applicaties in het MyKinsta dashboard.
Dit artikel werpt een platformonafhankelijke blik op persistente opslag door de soorten, architectuur en gebruikssituaties ervan te verkennen. Het geeft ook een praktische demonstratie die het verschil illustreert tussen volumeopslag en persistente volumeopslag in Docker.
Soorten persistente opslag
Er zijn verschillende soorten niet-vluchtige opslag, waaronder traditionele draaiende schijven (harde schijven of HDD’s), solid-state drives (SSD’s), network-attached storage (NAS) en storage area networks (SAN’s).
- Harde schijven zijn elektromechanische gegevensopslagapparaten die digitale gegevens opslaan en ophalen met behulp van draaiende schijven van magnetische media. De schijven gebruiken magnetische koppen op een beweegbare actuatorarm die gegevens lezen en schrijven.
- SSD’s, ook wel halfgeleider-opslagapparaten, solid-state apparaten of solid-state schijven genoemd, gebruiken geïntegreerde schakelingen om gegevens permanent op te slaan, meestal met behulp van onderling verbonden flash-apparaten zonder bewegende delen. Door hun stationaire aard zijn ze sneller en betrouwbaarder dan HDD’s.
- Netwerkgebonden opslag is een groep HDD’s, SSD’s, of beide, verbonden via een lokaal netwerk met een bestandssysteem zoals het New Technology File System (NTFS) of het vierde uitgebreide bestandssysteem (EXT4).
- SAN’s zijn genetwerkte snelle opslagapparaten op blokniveau, zoals tape libraries of disk arrays. Hun verbinding verschijnt voor het besturingssysteem als lokale opslag en is niet toegankelijk via het lokale netwerk (LAN).
Persistente opslagarchitectuur
Er zijn drie benaderingen van persistente opslag, elk met unieke gebruikssituaties en beperkingen.
Object persistente architectuur
De object persistente architectuur benadering gebruikt object-relationele mapping (ORM) om gegevens op te slaan als objecten in een relationele of key-value database. Deze aanpak is nuttig wanneer de gegevens geen gedefinieerd schema hebben, omdat de ORM de opslag en het opvragen ervan afhandelt.
Blok persistente architectuur
De blok-persistente architectuur gebruikt opslagapparatuur op blokniveau, die nuttig is bij het opslaan van grote bestanden. Deze aanpak is gunstig bij het opslaan van grote hoeveelheden gegevens, omdat je meerdere blokken kunt gebruiken om de opslagcapaciteit te vergroten.
Filestore persistente architectuur
Zoals de naam al zegt, maakt de filestore persistente architectuur gebruik van een bestandssysteem om gegevens op te slaan. Eén methode maakt gebruik van databaseservers, die een gecentraliseerde manier bieden om gegevens op te slaan. Cloud hosting oplossingen zoals die van Kinsta gebruiken databaseservers die gemakkelijk aan applicaties kunnen worden gekoppeld en persistentie bieden.
De persistente architectuur van Filestore is nuttig in toepassingen waarbij bestanden vaak opgehaald moeten worden en wanneer je een interface nodig hebt om ze te beheren.
Persistente Opslag Gebruiksgevallen
Deze sectie bespreekt enkele use cases van elk opslagtype.
Object persistente opslag
- Cloudopslag: Object persistente opslag wordt vaak gebruikt in cloud storage oplossingen voor het opslaan en ophalen van grote hoeveelheden ongestructureerde gegevens, zoals afbeeldingen, video’s en documenten. Cloud providers gebruiken objectopslag om klanten schaalbare, hoog beschikbare en duurzame opslagdiensten te bieden.
- Big data analyse: Object persistente opslag wordt gebruikt bij big data analytics om grote datasets op te slaan en te beheren die vaak worden gebruikt voor data-analyse, machine learning en AI. Objectopslag maakt snelle en efficiënte toegang tot gegevens mogelijk, waardoor het een belangrijk onderdeel is van big data-architecturen.
- Content delivery netwerken: Object persistente opslag wordt gebruikt in content delivery netwerken (CDN’s) om inhoud, zoals afbeeldingen, video’s en statische bestanden, op te slaan en te verspreiden over een wereldwijd netwerk van servers. Met objectopslag kunnen CDN’s snelle inhoud leveren aan gebruikers over de hele wereld, ongeacht hun locatie.
Blok persistente opslag
- High-performance computing (HPC): HPC-omgevingen verwerken snel en efficiënt grote hoeveelheden gegevens. Met blokopslag kunnen HPC-clusters grote datasets opslaan en opvragen, zoals wetenschappelijke simulaties, weermodellen en financiële analyses. Blokopslag geniet vaak de voorkeur voor HPC omdat het snelle toegang tot gegevens met een lage latentie biedt, en parallelle invoer/uitvoer (I/O) operaties mogelijk maakt, wat de verwerkingstijd aanzienlijk kan verbeteren.
- Videobewerking: Toepassingen voor videobewerking vereisen krachtige toegang met lage latentie tot grote videobestanden. Ze moeten ook aanzienlijke aantallen I/O-bewerkingen per seconde kunnen uitvoeren en een lage latentie hebben om videobestanden in real-time te renderen en te bewerken. Blokopslag biedt deze mogelijkheden, waardoor het een ideale oplossing is voor videobewerking.
- Gaming: Gaming toepassingen vereisen ook hoge prestaties en een lage latentie om toegang te krijgen tot spelmateriaal en spelersgegevens. Blokopslag slaat grote hoeveelheden gegevens snel op en haalt ze op, zodat spelomgevingen snel worden geladen en tijdens het spelen responsief blijven.
Filestore Persistente Opslag
- Media en entertainment: Toepassingen voor videobewerking, animatie en rendering maken vaak gebruik van persistente opslag. Deze toepassingen vereisen hoge prestaties en toegang met lage latentie tot grote mediabestanden, zoals video, audio en afbeeldingen. Filestore biedt een gedeeld bestandssysteem dat door meerdere clients benaderd kan worden, waardoor het een ideale opslagoplossing is voor deze toepassingen.
- Beheer van webinhoud: Web content management systemen (CMS’en) gebruiken filestore persistente opslag in gedeelde bestandssystemen voor het opslaan en beheren van website inhoud, zoals tekst, afbeeldingen en multimedia bestanden. Filestore biedt een centrale locatie voor website-inhoud, wat het beheren en bijwerken ervan gemakkelijker maakt. Ook kunnen meerdere gebruikers tegelijkertijd aan dezelfde inhoud werken, wat de samenwerking en productiviteit ten goede komt.
Persistente opslag in containers
Containers zijn lichtgewicht, draagbaar, veilig en eenvoudig, en bieden een fusie tussen verschillende toepassingen. Ze moeten een mechanisme hebben om gegevens te persisteren tussen container herstarts en verwijdering. Containers hebben bestandsopslag of een bestandssysteem zoals traditionele toepassingen, maar wanneer je ze opnieuw bouwt met nieuwe wijzigingen, verlies je alle niet-permanente gegevens.
Daarom bieden containers de optie om volumeopslag op te nemen of een opslagvolume te mounten. Containers behandelen opslagvolumes als een map. Alle gegevens die naar het volume worden geschreven gaan naar het host bestandssysteem.
Persistente opslag voor containers moet op deze manier werken omdat het herstarten van een container een nieuwe instantie aanmaakt en de oude instantie weggooit. Als een container geen consistente weergave van de gegevens heeft, zullen de gegevens verdwijnen als de container opnieuw opstart. Een opslagvolume bewaart de gegevens over sessies en containerherstartingen heen, zodat de container zijn toestand behoudt, zelfs als hij wordt verplaatst of opnieuw wordt opgestart.
Volume versus persistent volume
Containers bieden 2 manieren om persistente gegevens op te slaan: met behulp van volumes en persistente volumes. Er is een belangrijk verschil tussen beide. Een container beheert de gegevens in volumeopslag. Als je een container stopt, blijven de gegevens staan en zijn ze beschikbaar als je de container opnieuw start. Wanneer je echter een container verwijdert of verwijdert, gaan de gegevens verloren omdat je ook de onderliggende volumeopslag verwijdert.
Persistente volumeopslag of bind mounts is een manier om de gegevens buiten het bestandssysteem van de container op te slaan. Op deze manier gaan de gegevens niet verloren, zelfs niet als je de container verwijdert. Ze zijn persistent totdat ze handmatig worden verwijderd.
De volgende sectie demonstreert beide volumesoorten met voorbeelden.
Container Persistente Opslag Demo
We hebben een kleine webapplicatie gemaakt om persistente opslag met Docker containers te demonstreren. Je kunt meelopen door Docker te installeren en de code te pakken van deze GitHub repository.
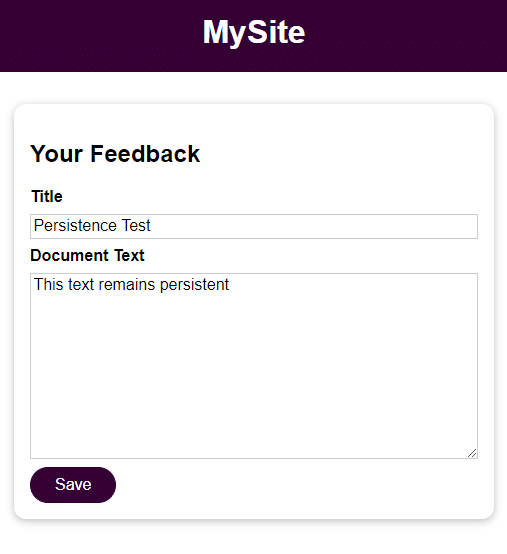
De applicatie is een elementair formulier met 2 velden voor gebruikersinvoer:
- Titel
- Document Tekst
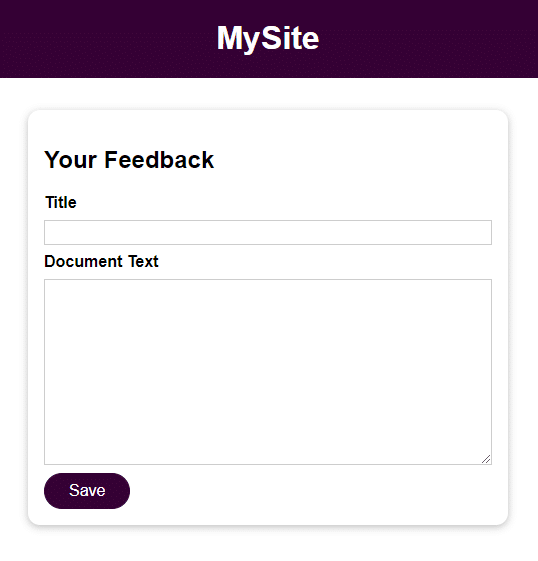
Zodra je de gebruikersinvoer hebt opgeslagen, kun je die openen door het bestand te openen in de feedback directory met de naam die in het Titel veld is opgegeven. De invoer van het veld Documenttekst is de inhoud van het bestand.
Hoe Volume Opslag te gebruiken
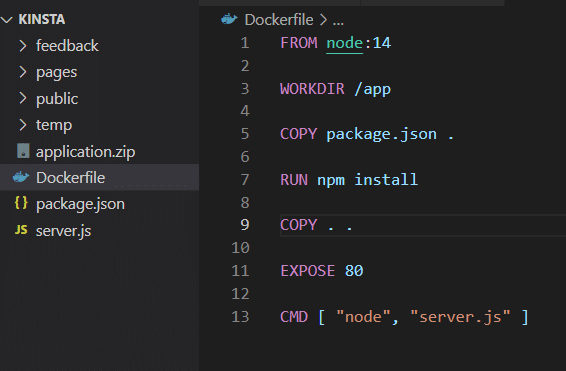
Als je de applicatie eenmaal op je eigen machine hebt geïnstalleerd, kan deze gebruik maken van volumeopslag zoals getoond in het Dockerbestand.
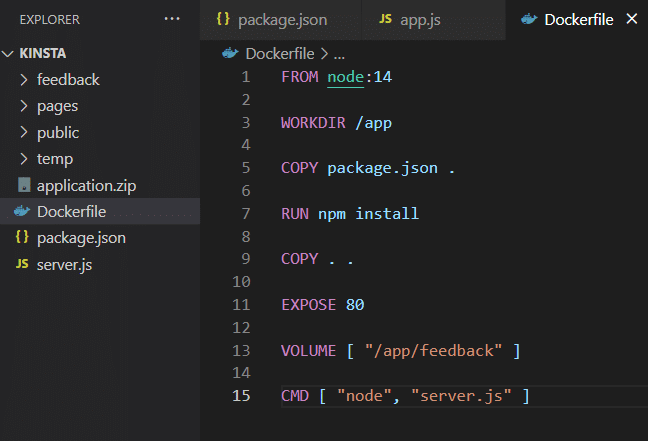
Nu bouw je het image en voer je de container uit. Voer daarvoor de volgende commando’s uit.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
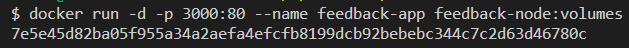
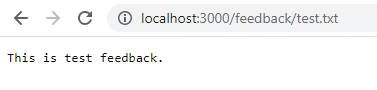
Zodra de applicatie draait, navigeer je naar localhost:3000 om feedback te geven.
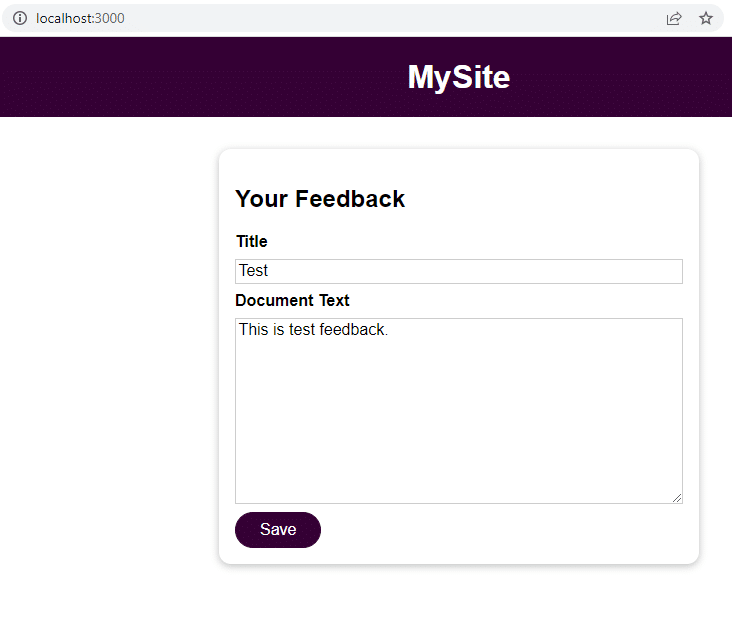
Klik op Opslaan en navigeer naar localhost:3000/feedback/test.txt om te zien of de invoer succesvol is opgeslagen of niet.
Verwijder en herstart de container om te zien of de invoer aanhoudt.
docker stop feedback-app
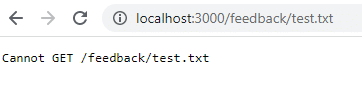
docker start feedback-appAls je nu dezelfde URL bezoekt, zie je dat de feedback er nog steeds is. Maar wat gebeurt er als je de container verwijdert en opnieuw opstart?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesAls je na het herstarten terugkeert naar die URL, bestaat die niet meer, omdat de gegevens verloren zijn gegaan toen je de container verwijderde. Volumegegevens blijven alleen bestaan bij het stoppen van de container, niet bij het verwijderen ervan.
Om dit probleem te beperken en de gegevens te laten persisteren, zelfs als je de container verwijdert, moet je persistente volumeopslag of named storage gebruiken. Eerst moet je de containers en images opruimen.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesHoe persistente volumeopslag te gebruiken
Voordat je dit gaat testen, moet je het VOLUME attribuut uit het Dockerbestand verwijderen en de image opnieuw opbouwen.
docker build -t feedback-node:volumes .
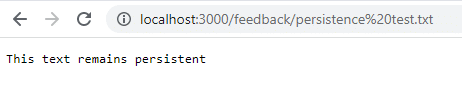
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesZoals je ziet, gebruik je in het tweede commando de -v vlag om het persistente volume buiten de container te definiëren, dat ook blijft bestaan als je de container verwijdert.
Probeer net als de vorige stap feedback toe te voegen en toegang te krijgen zodra je de container stopt, verwijdert en opnieuw opstart.
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesZoals je ziet zijn de gegevens ook na het stoppen en verwijderen van de container toegankelijk en blijven ze bestaan.
Samenvatting
Persistente opslag is van vitaal belang voor gecontaineriseerde toepassingen, omdat het het persisteren van gegevens buiten de levenscyclus van een container mogelijk maakt. De 2 belangrijkste typen persistente opslag voor gecontaineriseerde toepassingen zijn volumes en bind mounts, elk met hun voordelen en gebruikssituaties.
Volumes worden opgeslagen in het bestandssysteem van de container, terwijl bindmounts direct toegankelijk zijn op de hostmachine.
Persistente opslag maakt het mogelijk gegevens te delen tussen containers, waardoor het mogelijk wordt complexe, meerlagige toepassingen te bouwen. Persistente opslag is essentieel voor de stabiliteit en continuïteit van gecontaineriseerde toepassingen, en biedt een betrouwbare en flexibele manier om cruciale gegevens op te slaan.
Ontwikkel je een applicatie die persistente opslag vereist? Blader door onze bibliotheek met Quickstart voorbeelden om te zien hoe je je applicatie kunt deployen naar Kinsta vanuit Git hosts zoals GitHub, GitLab en Bitbucket. Onze officiële Persistent Storage documentatie helpt je om je applicatie en de gegevens snel online te krijgen.

Steve Bonisteel is Technical Editor bij Kinsta. Hij begon zijn schrijverscarrière als verslaggever en achtervolgde ambulances en brandweerwagens. Sinds eind jaren negentig schrijft hij over internetgerelateerde technologie.

