
Ooit de term robots.txt gehoord en je afgevraagd wat die te maken heeft met je website? De meeste websites hebben een robots.txt bestand, maar dat betekent niet dat de meeste site eigenaren het begrijpen. In dit artikel hopen we dat te veranderen door in meer detail te kijken naar in het WordPress robots.txt bestand, en hoe het de toegang tot je site kan controleren en beperken.
Er is veel te vertellen, dus laten we beginnen!
Wat is een WordPress robots.txt bestand?
Voordat we het kunnen hebben over het WordPress robots.txt bestand, is het belangrijk om te definiëren wat een “robot” in dit geval is. Robots zijn elk soort “bot” die websites op het internet bezoekt. Het meest voorkomende voorbeeld zijn zoekmachinecrawlers. Deze bots “crawlen” over het web om zoekmachines als Google te helpen de miljarden pagina’s op het internet te indexeren en te rangschikken.
Dus, bots zijn in het algemeen een goede zaak voor het Internet… of tenminste een noodzakelijke zaak. Maar dat betekent niet noodzakelijkerwijs dat jij, of andere site eigenaren, willen dat bots ongehinderd rondrennen. De wens om te controleren hoe webrobots omgaan met websites leidde in het midden van de jaren negentig tot het ontstaan van de standaard voor het uitsluiten van robots. Robots.txt is de praktische uitvoering van die standaard – het stelt je in staat te bepalen hoe deelnemende bots met je site omgaan. Je kunt bots volledig blokkeren, hun toegang tot bepaalde delen van je site beperken, en meer.
Dat “deelnemende” deel is wel belangrijk. Robots.txt kan een bot niet dwingen zijn richtlijnen te volgen. En kwaadwillende bots kunnen en zullen het robots.txt bestand negeren. Bovendien negeren zelfs gerenommeerde organisaties sommige opdrachten die je in robots.txt kunt zetten. Google zal bijvoorbeeld alle regels negeren die je aan je robots.txt toevoegt over hoe vaak zijn crawlers langskomen. Je kunt de snelheid waarmee Google je website crawlt aanpassen op de pagina Crawl Rate Settings voor je property in Google Search Console.
Als je veel problemen hebt met bots, kan een beveiligingsoplossing zoals Cloudflare of Sucuri van pas komen.
Hoe vind je robots.txt?
Het robots.txt bestand leeft in de root van je website, dus het toevoegen van /robots.txt achter je domein zou het bestand moeten laden (als je er een hebt). Bijvoorbeeld https://kinsta.com/robots.txt.
Wanneer moet je een robots.txt bestand gebruiken?
Voor de meeste site-eigenaren komen de voordelen van een goed gestructureerd robots.txt bestand neer op twee categorieën:
- Optimaliseren van de crawlresources van zoekmachines door ze te vertellen geen tijd te verspillen aan pagina’s die je niet geïndexeerd wilt hebben. Dit zorgt ervoor dat zoekmachines zich concentreren op het crawlen van de pagina’s die jij het belangrijkst vindt.
- Je servergebruik optimaliseren door bots te blokkeren die resources verspillen.
Robots.txt gaat niet specifiek over het controleren welke pagina’s geïndexeerd worden in zoekmachines
Robots.txt is geen waterdichte manier om te controleren welke pagina’s zoekmachines indexeren. Als je primair wilt voorkomen dat bepaalde pagina’s worden opgenomen in de resultaten van zoekmachines, dan is de juiste aanpak het gebruik van een noindex metatag of wachtwoordbeveiliging.
Dit komt omdat je robots.txt zoekmachines niet direct vertelt om content niet te indexeren – het vertelt ze alleen om het niet te crawlen. Hoewel Google de gemarkeerde delen van je site niet zal crawlen, stelt Google zelf dat als een externe site linkt naar een pagina die je uitsluit met je robots.txt bestand, Google die pagina toch kan indexeren.
John Mueller, een Google Webmaster Analyst, heeft ook bevestigd dat als een pagina links heeft die ernaar verwijzen, zelfs als die door robots.txt geblokkeerd zijn, toch geïndexeerd kunnen worden. Hieronder staat wat hij te zeggen had in een Webmaster Central hangout:
Een ding dat je misschien in gedachten moet houden is dat als deze pagina’s door robots.txt worden geblokkeerd, het theoretisch zou kunnen gebeuren dat iemand willekeurig naar een van deze pagina’s linkt. En als ze dat doen, kan het gebeuren dat we deze URL indexeren zonder enige content, omdat hij door robots.txt wordt geblokkeerd. We zouden dus niet weten dat je deze pagina’s niet geïndexeerd wilt hebben.
Maar als ze niet door robots.txt worden geblokkeerd kun je een noindex metatag op die pagina’s zetten. En als iemand er toevallig naar linkt, en we crawlen die link en denken dat er misschien iets nuttigs op staat, dan weten we dat die pagina’s niet geïndexeerd hoeven te worden en kunnen we ze gewoon helemaal overslaan.
Dus, wat dat betreft, als je iets op deze pagina’s hebt dat je niet geïndexeerd wilt hebben, disallow ze dan niet, maar gebruik noindex.
Heb ik een robots.txt bestand nodig?
Het is belangrijk om te onthouden dat je geen robots.txt bestand op je site hoeft te hebben. Als je er geen probleem mee hebt dat alle bots vrij spel hebben om al je pagina’s te crawlen, dan kun je ervoor kiezen er geen toe te voegen, omdat je geen echte instructies aan de crawlers hoeft te geven.
In sommige gevallen kun je zelfs geen robots.txt bestand toevoegen vanwege beperkingen van het CMS dat je gebruikt. Dit is prima, en er zijn andere methoden om bots te instrueren hoe ze je pagina’s moeten crawlen zonder een robots.txt bestand te gebruiken.
Welke HTTP statuscode moet worden teruggegeven voor het robots.txt bestand?
Het robots.txt bestand moet een 200 OK HTTP statuscode teruggeven, zodat crawlers het bestand kunnen openen.
Als je problemen hebt om je pagina’s geïndexeerd te krijgen door zoekmachines, is het de moeite waard om de statuscode van je robots.txt bestand te controleren. Alles anders dan een 200 statuscode kan voorkomen dat crawlers je site bezoeken.
Sommige site eigenaren hebben gemeld dat pagina’s werden gedeïndexeerd omdat hun robots.txt bestand een niet-200 status teruggaf. Een website eigenaar vroeg naar een indexeringsprobleem in een Google SEO office hangout in maart 2022 en John Mueller legde uit dat het robots.txt bestand ofwel een 200 status moet retourneren als ze aanwezig zijn, of een 4XX status als het bestand niet bestaat. In dit geval werd een 500 interne serverfout geretourneerd, wat er volgens Mueller toe kan hebben geleid dat Googlebot de site uitsluit van indexering.
Hetzelfde is te zien in deze Tweet, waar een site eigenaar meldde dat zijn hele site werd gedeïndexeerd omdat een robots.txt bestand een 500 fout teruggaf.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
Kan de robots metatag gebruikt worden in plaats van een robots.txt bestand?
Nee. Met de robots metatag kun je bepalen welke pagina’s geïndexeerd worden, terwijl je met het robots.txt bestand kunt bepalen welke pagina’s gecrawld worden. Bots moeten pagina’s eerst crawlen om de metatags te kunnen zien, dus je moet niet proberen om zowel een disallow als een noindex metatag te gebruiken, omdat de noindex dan niet wordt opgepikt.
Als het je doel is om een pagina uit te sluiten van de zoekmachines, dan is de noindex metatag meestal de beste optie.
Zo maak en bewerk je je WordPress robots.txt bestand
Standaard maakt WordPress automatisch een virtueel robots.txt bestand aan voor je site. Dus zelfs als je niks doet, zou je site al het standaard robots.txt bestand moeten hebben. Je kunt testen of dit het geval is door “/robots.txt” toe te voegen aan het eind van je domeinnaam. Bijvoorbeeld, “https://kinsta.com/robots.txt” toont het robots.txt bestand dat we hier bij Kinsta gebruiken.
Voorbeeld van een robots.txt bestand
Hier is een voorbeeld van Kinsta’s robots.txt bestand:
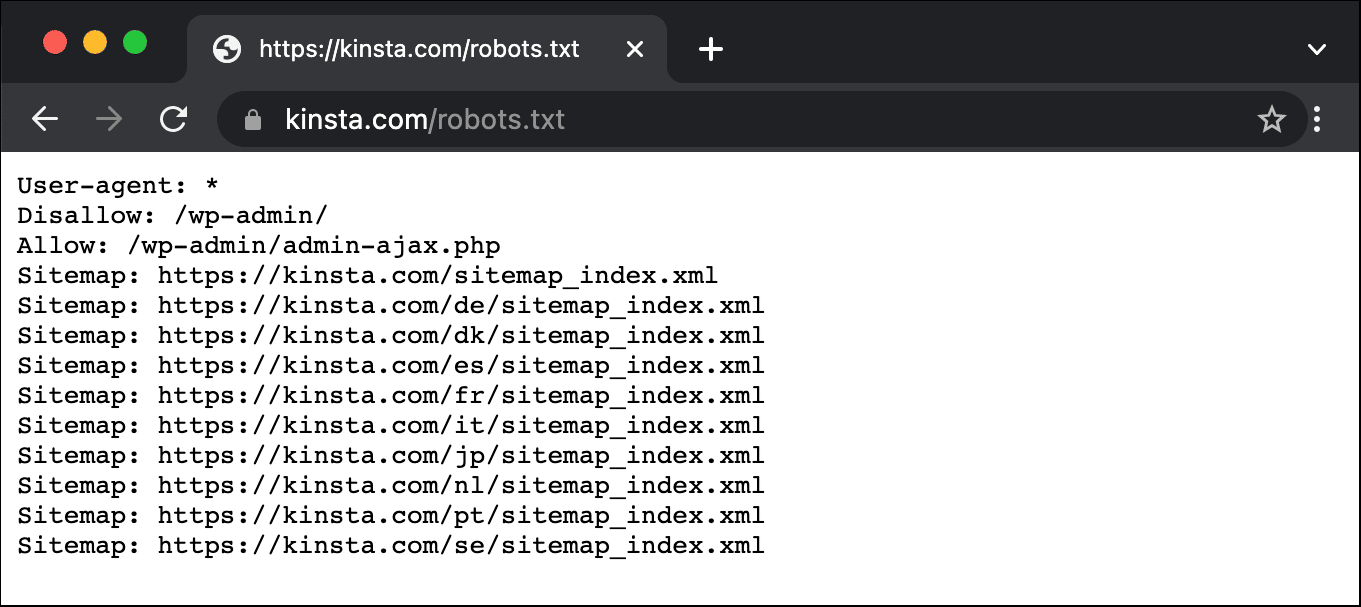
Dit geeft alle robots instructies over welke paden ze moeten negeren (bijv. het wp-admin pad), met eventuele uitzonderingen (bijv. het admin-ajax.php bestand), samen met Kinsta’s XML sitemap locaties.
Omdat dit bestand echter virtueel is, kun je het niet bewerken. Als je je robots.txt bestand wilt bewerken, moet je een fysiek bestand op je server maken dat je naar behoefte kunt manipuleren. Hier zijn drie eenvoudige manieren om dat te doen:
Zo maak en bewerk je een robots.txt bestand in WordPress met Yoast SEO
Als je de populaire Yoast SEO plugin gebruikt, kun je je robots.txt bestand direct vanuit de interface van Yoast aanmaken (en later bewerken). Maar voordat je het kunt openen, moet je naar SEO → Tools gaan en klikken op File editor
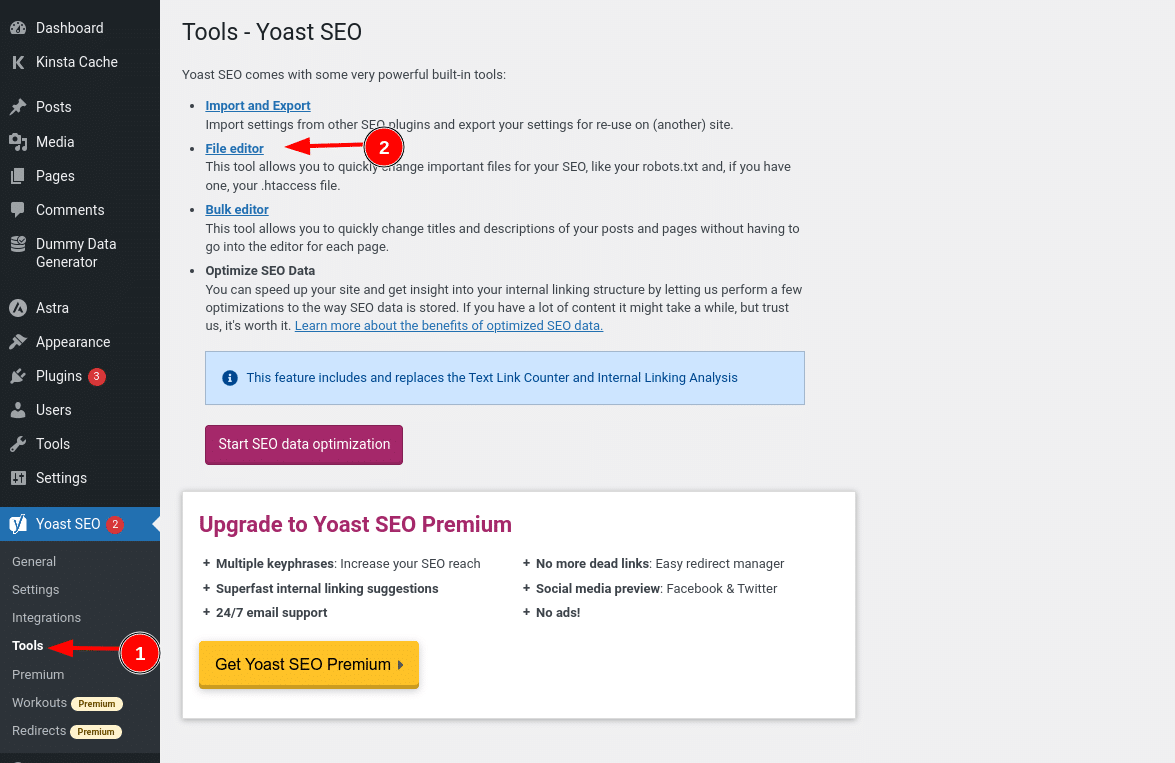
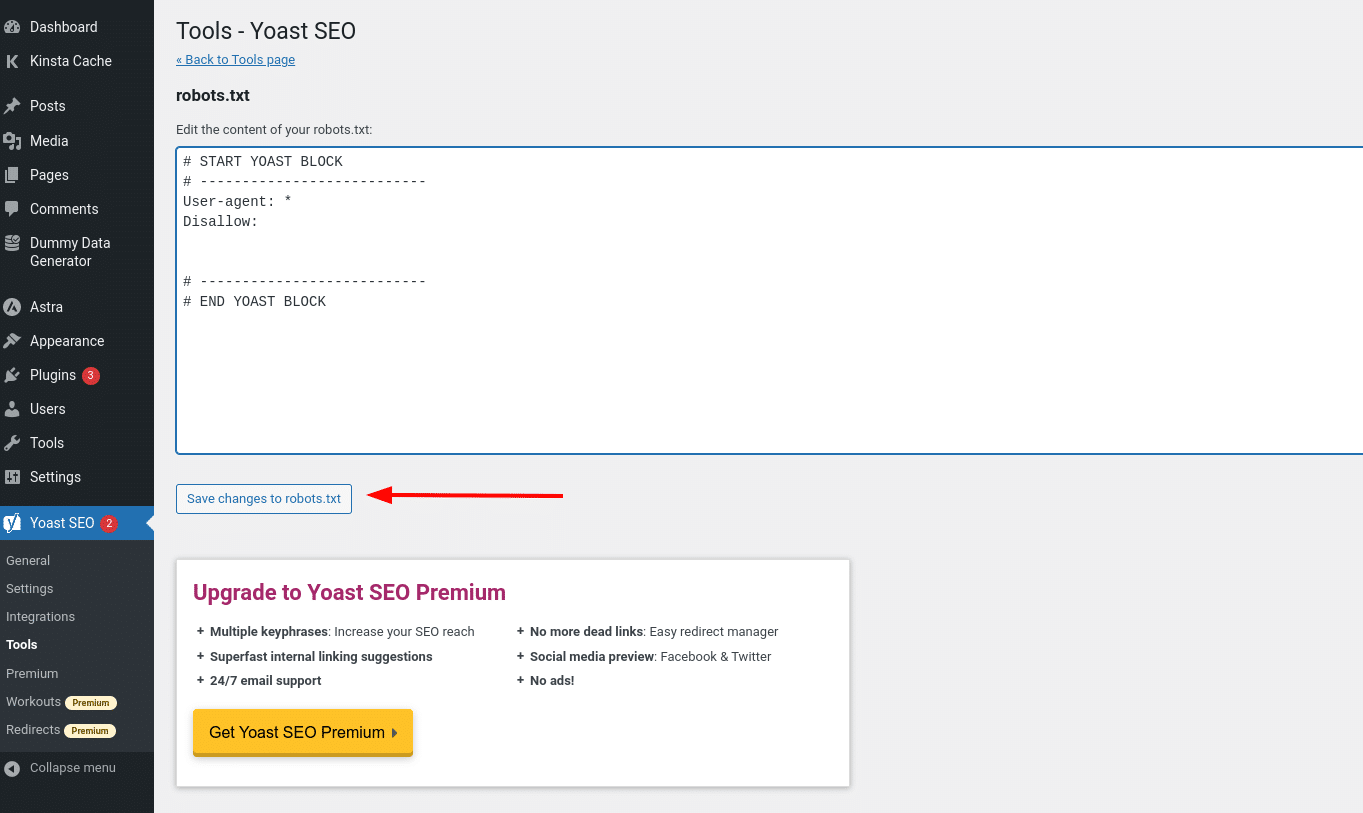
En zodra je op die knop klikt, kun je de inhoud van je robots.txt bestand direct vanuit dezelfde interface bewerken en vervolgens alle aangebrachte wijzigingen opslaan.
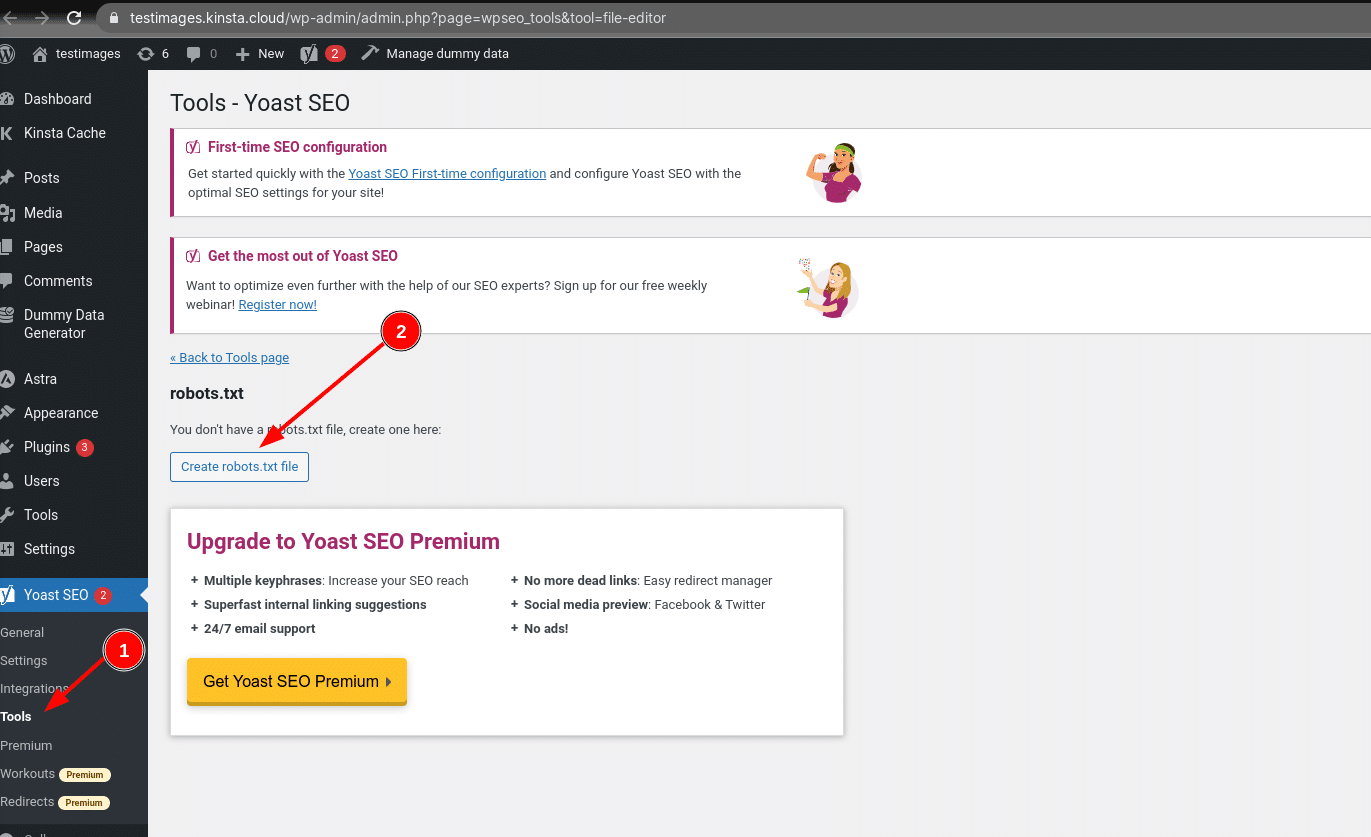
Ervan uitgaande dat je nog geen fysiek robots.txt bestand hebt, geeft Yoast je de optie Create robots.txt file:
Als je verder leest, zullen we meer ingaan op welke soorten richtlijnen je in je WordPress robots.txt bestand moet zetten.
Zo maak en bewerk je een robots.txt bestand met All in One SEO
Als je de bijna net zo populaire All in One SEO Pack plugin gebruikt, kun je je WordPress robots.txt bestand ook direct vanuit de interface van de plugin maken en bewerken. Het enige wat je hoeft te doen is naar All in One SEO → Tools te gaan:
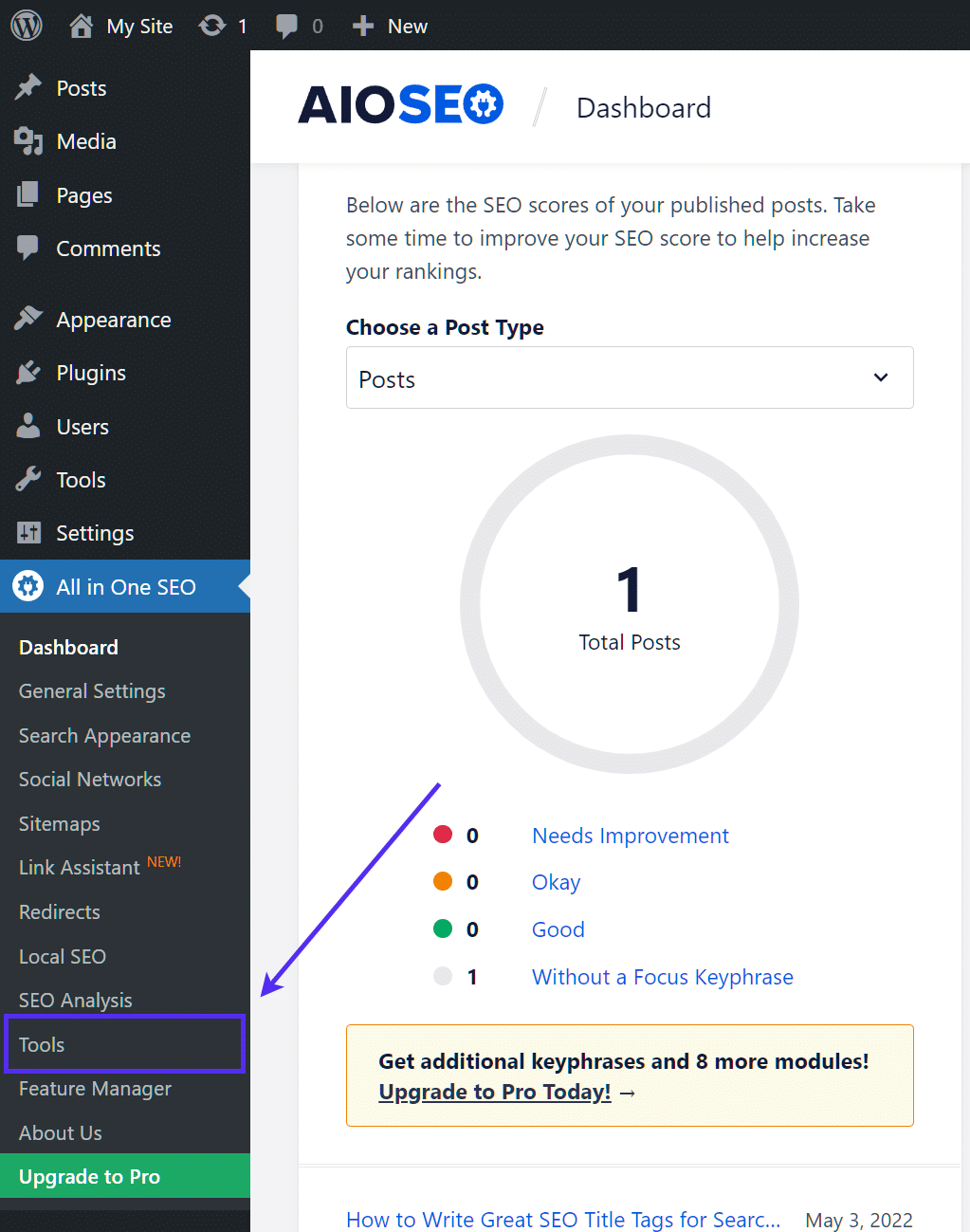
Zet dan het keuzerondje Enable Custom robots.txt aan. Hiermee kun je aangepaste regels maken en toevoegen aan je robots.txt bestand:
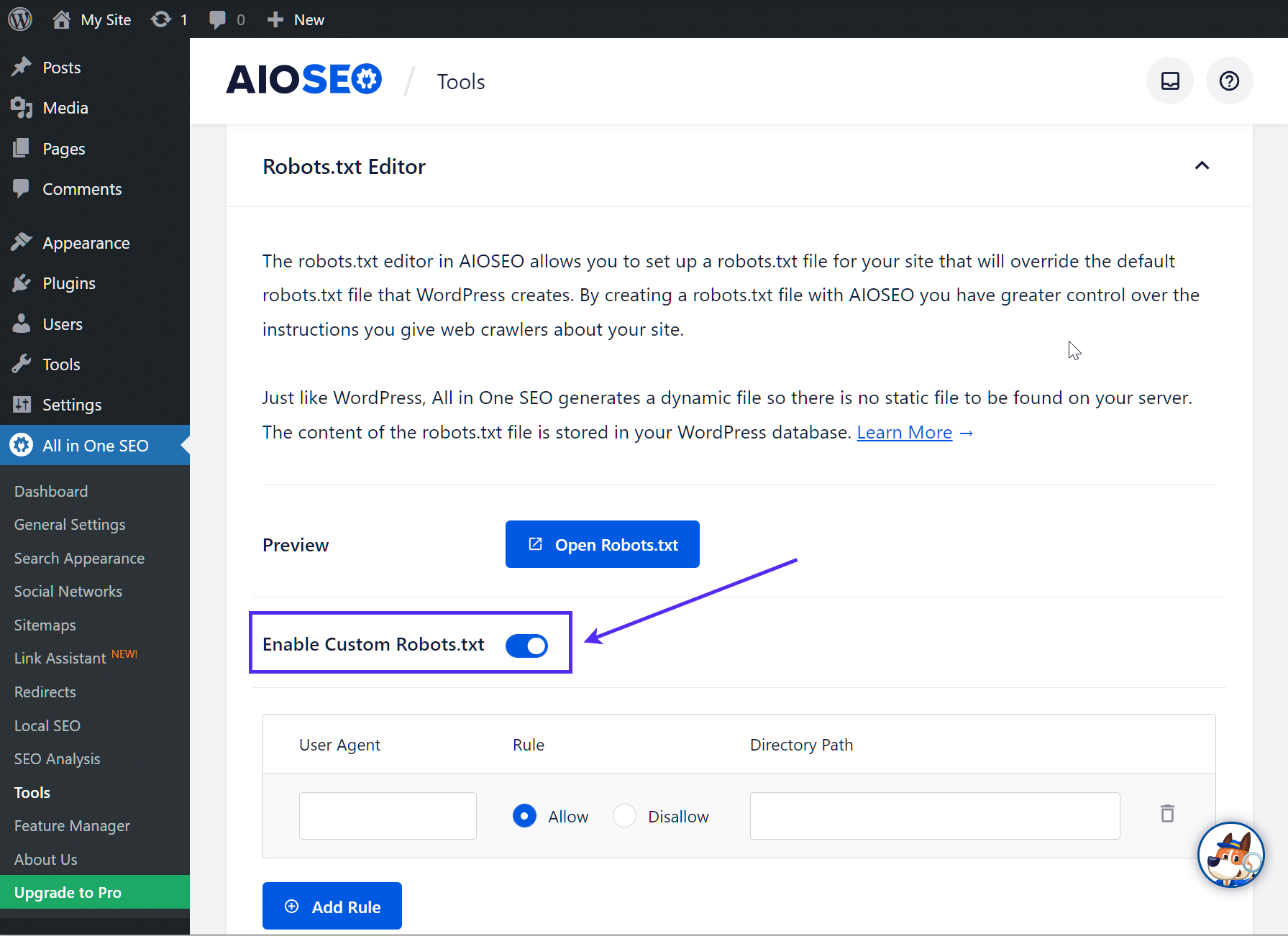
Zo maak en bewerk je een robots.txt bestand via FTP
Als je geen SEO plugin gebruikt die robots.txt functionaliteit biedt, kun je nog steeds je robots.txt bestand maken en beheren via SFTP. Maak eerst met een willekeurige tekst editor een leeg bestand aan met de naam “robots.txt”:
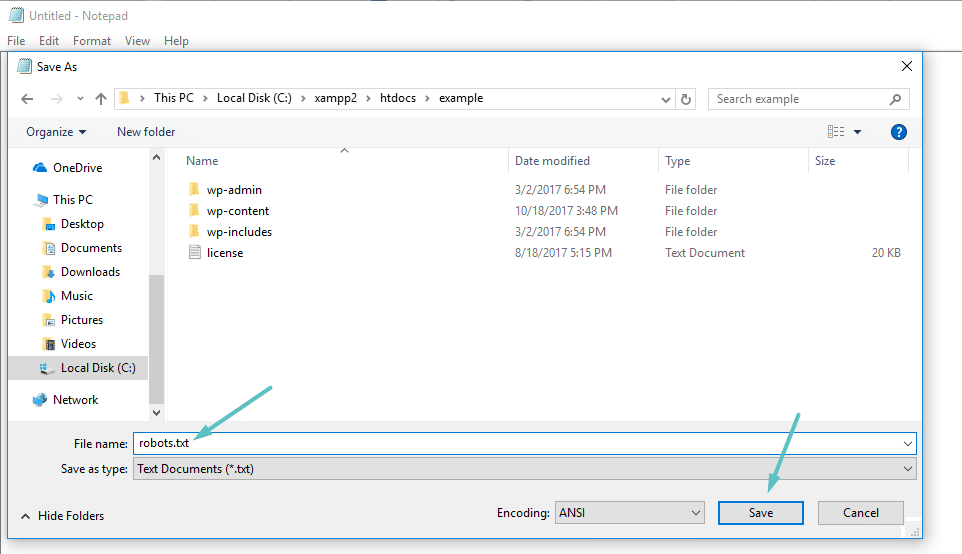
Maak vervolgens via SFTP verbinding met je site en upload dat bestand naar de root map van je site. Je kunt je robots.txt bestand verder aanpassen door het via SFTP te bewerken of nieuwe versies van het bestand te uploaden.
Dit zet je in je robots.txt bestand
Ok, nu heb je een fysiek robots.txt bestand op je server dat je naar behoefte kunt bewerken. Maar wat doe je eigenlijk met dat bestand? Nou, zoals je in het eerste deel hebt geleerd, kun je met robots.txt regelen hoe robots met je site omgaan. Dat doe je met twee kerncommando’s:
- User-agent – hiermee kun je specifieke bots targeten. User-agents zijn wat bots gebruiken om zich te identificeren. Hiermee kun je bijvoorbeeld een regel maken die geldt voor Bing, maar niet voor Google.
- Disallow – hiermee kun je robots vertellen dat ze bepaalde delen van je site niet mogen bezoeken.
Er is ook een Allow commando dat je zult gebruiken in nichesituaties. Standaard is alles op je site gemarkeerd met Allow, dus het is in 99% van de situaties niet nodig om het commando Allow te gebruiken. Maar het is wel handig als je de toegang tot een map en zijn submappen wilt Disallowen, maar de toegang tot een specifieke map wilt Allowen.
Je voegt regels toe door eerst aan te geven op welke User-agent de regel van toepassing moet zijn en dan op te sommen welke regels je wilt toepassen met Disallow en Allow. Er zijn ook enkele andere commando’s zoals Crawl-delay en Sitemap, maar die zijn of:
- Genegeerd door de meeste grote crawlers, of op enorm verschillende manieren geïnterpreteerd (in het geval van crawl delay)
- Overbodig gemaakt door tools als Google Search Console (voor sitemaps)
Laten we enkele specifieke use cases doornemen om je te laten zien hoe dit alles in elkaar steekt.
Zo kun je robots.txt disallow all gebruiken om de toegang tot je hele site te blokkeren
Stel dat je alle crawlertoegang tot je site wilt blokkeren. Het is onwaarschijnlijk dat dit gebeurt op een live site, maar het is wel handig voor een ontwikkelingssite. Daarvoor voeg je de code robots.txt disallow all toe aan je WordPress robots.txt bestand:
User-agent: *
Disallow: /Wat gebeurt er in die code?
Het *asterisk naast User-agent betekent “alle user agents”. Het sterretje is een wildcard, wat betekent dat het voor elke user-agent geldt. De /slash naast Disallow zegt dat je de toegang wilt weigeren tot alle pagina’s die “yourdomain.com/” bevatten (dat is elke pagina op je site).
Zo gebruik je robots.txt om een enkele bot de toegang tot je site te ontzeggen
Laten we de dingen eens veranderen. In dit voorbeeld doen we alsof je het niet leuk vindt dat Bing je pagina’s crawlt. Je bent helemaal Team Google en wilt niet eens dat Bing naar je site kijkt. Om alleen Bing te verhinderen je site te crawlen, vervang je de wildcard *asterisk door Bingbot:
User-agent: Bingbot
Disallow: /In wezen zegt de bovenstaande code om de Disallow regel alleen toe te passen op bots met de User-agent “Bingbot”. Nu is het onwaarschijnlijk dat je de toegang tot Bing wilt blokkeren – maar dit scenario is wel handig als er een specifieke bot is die je niet op je site wilt hebben. Deze site heeft een goede lijst van de meeste bekende User-agent namen van diensten.
Zo gebruik je robots.txt om de toegang tot een specifieke map of bestand te blokkeren
Laten we in dit voorbeeld zeggen dat je alleen de toegang tot een specifieke map of bestand (en alle submappen van die map) wilt blokkeren. Om dit toe te passen op WordPress, laten we zeggen dat je wilt blokkeren:
- De hele map wp-admin
- wp-login.php
Je zou de volgende commando’s kunnen gebruiken:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpZo gebruik je robots.txt allow all om robots volledige toegang tot je site te geven
Als je momenteel geen reden hebt om crawlers de toegang tot je pagina’s te ontzeggen, kun je het volgende commando toevoegen.
User-agent: *
Allow: /
Of als alternatief:
User-agent: *
Disallow:
Zo gebruik je robots.txt om toegang te verlenen tot een specifiek bestand in een disallowed map
Ok, laten we nu zeggen dat je een hele map wilt blokkeren, maar toch de toegang wilt toestaan tot een specifiek bestand in die map. Dit is waar het commando Allow van pas komt. En het is eigenlijk heel goed toepasbaar op WordPress. In feite illustreert het virtuele robots.txt bestand van WordPress dit voorbeeld perfect:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpDeze snippet blokkeert de toegang tot de hele map /wp-admin/ , behalve tot het bestand /wp-admin/admin-ajax.php.
Zo gebruik je bobots.txt om bots te verhinderen de WordPress zoekresultaten te crawlen
Een WordPress-specifieke aanpassing die je misschien wilt maken is om te voorkomen dat zoekmachines je zoekresultaten pagina’s crawlen. Standaard gebruikt WordPress de query parameter “?s=”. Dus om de toegang te blokkeren hoef je alleen maar de volgende regel toe te voegen:
User-agent: *
Disallow: /?s=
Disallow: /search/Dit kan een effectieve manier zijn om ook zachte 404 fouten te stoppen als je die krijgt. Lees zeker onze diepgaande handleiding over hoe je het zoeken in WordPress kunt versnellen.
Zo maak je verschillende regels voor verschillende bots in robots.txt
Tot nu toe gingen alle voorbeelden over één regel tegelijk. Maar wat als je verschillende regels wilt toepassen op verschillende bots? Je hoeft alleen maar elke set regels toe te voegen onder de User-agent declaration voor elke bot. Als je bijvoorbeeld één regel wilt maken die voor alle bots geldt en een andere regel die alleen voor Bingbot geldt, zou je het zo kunnen doen:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /In dit voorbeeld worden alle bots geblokkeerd voor toegang tot /wp-admin/, maar Bingbot wordt geblokkeerd voor toegang tot je hele site.
Je Robots.txt bestand testen
Om er zeker van te zijn dat je robots.txt bestand correct is ingesteld en werkt zoals verwacht, moet je het grondig testen. Eén verkeerd geplaatst teken kan rampzalig zijn voor de prestaties van een site in de zoekmachines, dus testen kan helpen om potentiële problemen te voorkomen.
Google’s robots.txt Tester
Google’s robots.txt Tester tool (voorheen onderdeel van Google Search Console) is eenvoudig te gebruiken en laat mogelijke problemen in je robots.txt bestand zien.
Navigeer gewoon naar de tool en selecteer de property voor de site die je wilt testen, scroll dan naar de onderkant van de pagina en voer een willekeurige URL in het veld in, klik dan op de rode TEST knop:
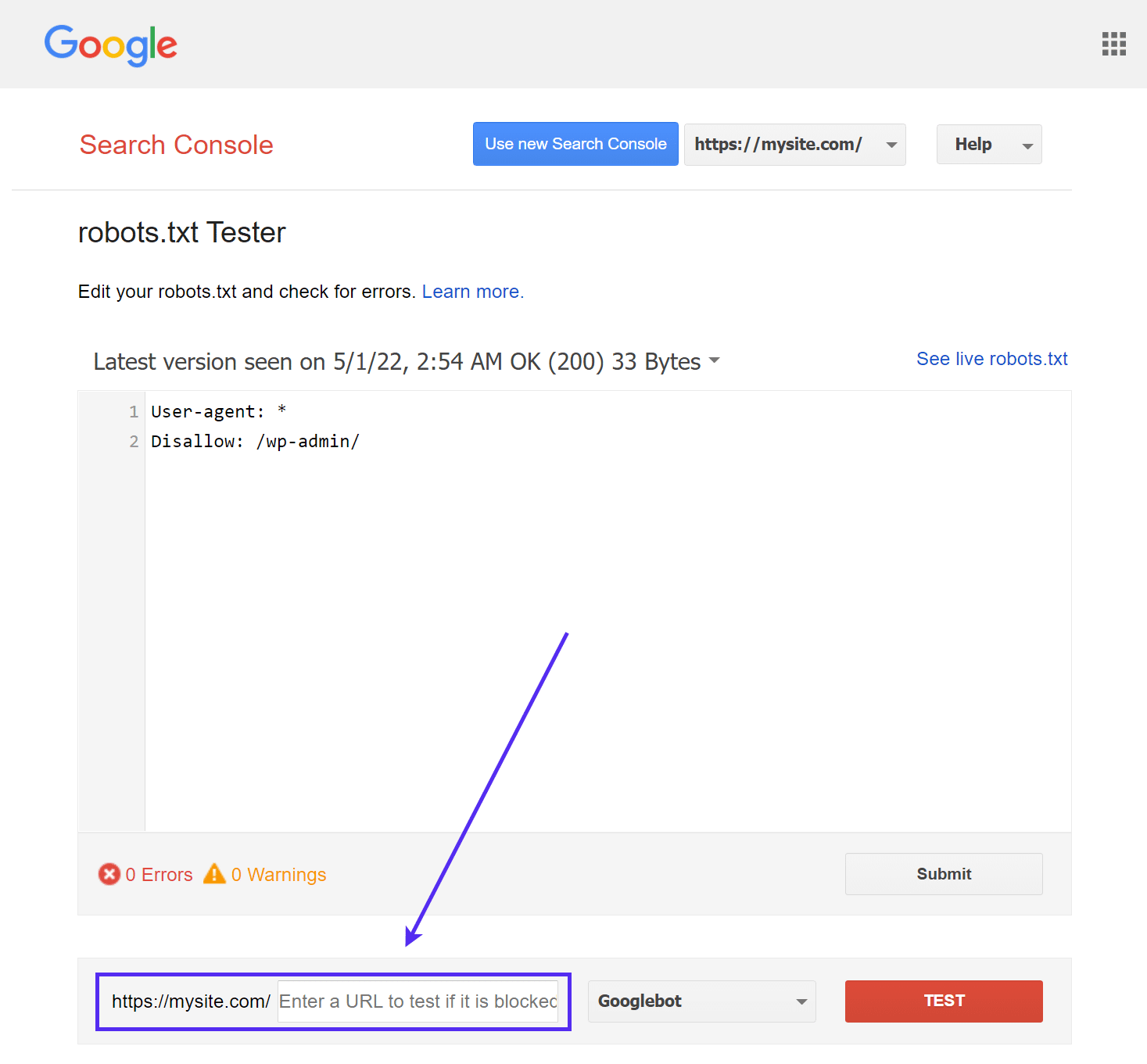
Je ziet een groen Allowed antwoord als alles crawlbaar is.
Je kunt ook kiezen met welke versie van Googlebot je de test wilt uitvoeren, door te kiezen uit Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google of Adbot-Google.
Je kunt ook elke afzonderlijke URL die je hebt geblokkeerd testen om er zeker van te zijn dat ze inderdaad geblokkeerd en/of Disallowed zijn.
Pas op voor de UTF-8 BOM
BOM staat voor byte order mark en is eigenlijk een onzichtbaar karakter dat soms aan bestanden wordt toegevoegd door oude tekst editors en dergelijke. Als dit gebeurt met je robots.txt bestand, kan het zijn dat Google het niet goed leest. Daarom is het belangrijk om je bestand te controleren op fouten. Bijvoorbeeld, zoals hieronder te zien, had ons bestand een onzichtbaar karakter en Google klaagt erover dat de syntaxis niet wordt begrepen. Dit maakt in wezen de eerste regel van ons robots.txt bestand helemaal ongeldig, en dat is niet goed! Glenn Gabe heeft een uitstekend artikel over hoe een UTF-8 Bom je SEO om zeep kan helpen.

Googlebot is meestal afkomstig uit de VS
Het is ook belangrijk om de Googlebot uit de Verenigde Staten niet te blokkeren, zelfs als je je richt op een lokale regio buiten de Verenigde Staten. Ze doen soms lokale crawling, maar de Googlebot is meestal gebaseerd op de VS.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
Wat populaire WordPress sites in hun Robots.txt bestand zetten
Om eigenlijk wat context te bieden voor de bovenstaande punten, is hier hoe enkele van de populairste WordPress sites hun robots.txt bestanden gebruiken.
TechCrunch
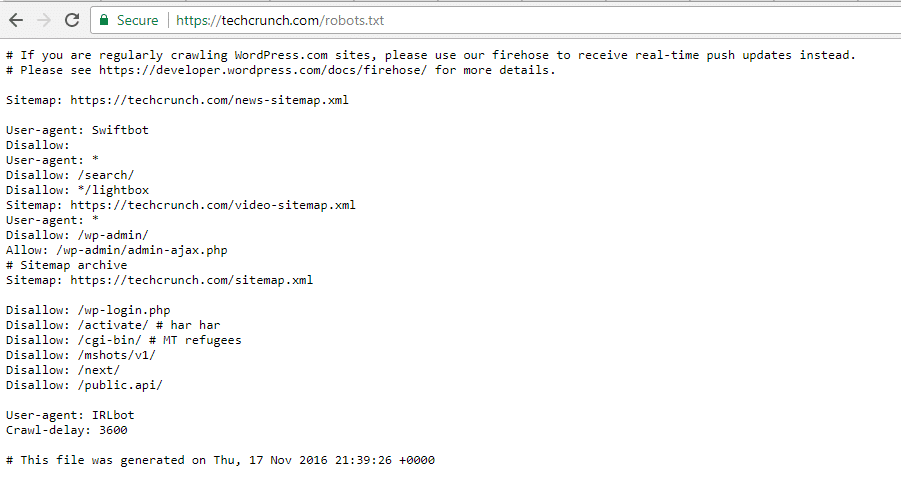
Naast het beperken van de toegang tot een aantal unieke pagina’s, verbiedt TechCrunch met name crawlers voor:
- /wp-admin/
- /wp-login.php
Ze hebben ook speciale beperkingen ingesteld voor twee bots:
- Swiftbot
- IRLbot
Mocht je geïnteresseerd zijn, IRLbot is een crawler van een onderzoeksproject van de Texas A&M University. Dat is vreemd!
De Obama Foundation
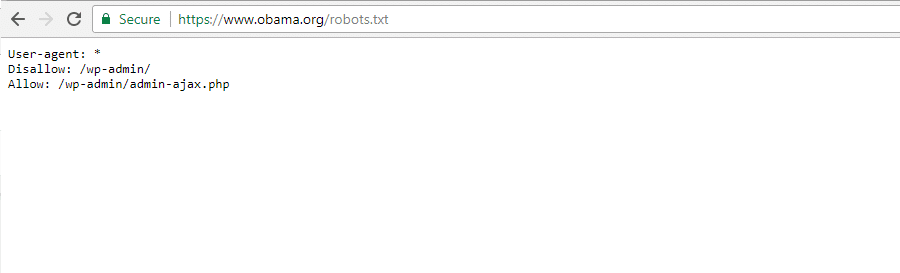
De Obama Foundation heeft geen speciale toevoegingen gedaan en kiest uitsluitend voor beperking van de toegang tot /wp-admin/.
Angry Birds
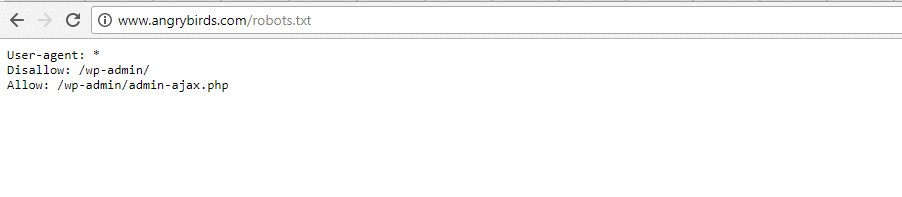
Angry Birds heeft dezelfde standaardinstelling als The Obama Foundation. Er is niets speciaals toegevoegd.
Drift

Tenslotte kiest Drift ervoor om zijn sitemaps in het Robots.txt bestand te definiëren, maar laat verder dezelfde standaard beperkingen als The Obama Foundation en Angry Birds.
Gebruik Robots.txt op de juiste manier
Nu we onze robots.txt handleiding afsluiten, willen we je er nog één keer aan herinneren dat het gebruik van een Disallow commando in je robots.txt bestand niet hetzelfde is als het gebruik van een noindex tag. Robots.txt blokkeert het crawlen, maar niet noodzakelijkerwijs het indexeren. Je kunt het gebruiken om specifieke regels toe te voegen om te bepalen hoe zoekmachines en andere bots met je site omgaan, maar het zal niet expliciet bepalen of je content geïndexeerd wordt of niet.
Voor de meeste gewone WordPress gebruikers is er geen dringende noodzaak om het standaard virtuele robots.txt bestand aan te passen. Maar als je problemen hebt met een specifieke bot, of wilt veranderen hoe zoekmachines omgaan met een bepaalde plugin of thema dat je gebruikt, dan wil je misschien je eigen regels toevoegen.
We hopen dat je genoten hebt van deze handleiding en laat zeker een reactie achter als je nog vragen hebt over het gebruik van je WordPress robots.txt bestand.

Brian heeft een enorme passie voor WordPress, gebruikt het al meer dan tien jaar en heeft zelfs al aantal premium plugins ontwikkeld. Brian houdt van bloggen, films en hikes. Kom in contact met Brian op Twitter.

