
It can be discouraging to see your website’s decline in search rankings. When your pages are no longer crawled by Google, these lower rankings can contribute to fewer visitors and conversions.
The “Indexed, though blocked by robots.txt” error can signify a problem with search engine crawling on your site. When this happens, Google has indexed a page that it cannot crawl. Fortunately, you can edit your robots.txt file to specify which pages should or should not be indexed.
In this post, we’ll explain the “Indexed, though blocked by robots.txt” error and how to test your website for this problem. Then, we’ll show you two different methods of fixing it. Let’s get started!
Check Out Our Video Guide to Fixing the Indexed Though Blocked by robots.txt Error
What Is the “Indexed, Though Blocked by robots.txt” Error?
As a website owner, Google Search Console can help you analyze your site’s performance in many vital areas. This tool can monitor page speed, security, and “crawlability” so that you can optimize your online presence:
For example, Search Console’s Index Coverage report can help you improve your site’s Search Engine Optimization (SEO). It will analyze how Google indexes your online content, returning information about common errors, such as an “Indexed, though blocked by robots.txt” warning:
To understand this error, let’s first discuss the robots.txt file. Essentially, it informs search engine crawlers which of your website files should or should not be indexed. With a well-structured robots.txt file, you can ensure that only important web pages are crawled.
If you’ve received an “Indexed, though blocked by robots.txt” warning, Google crawlers have found the page but notice that it is blocked in your robots.txt file. When this happens, Google isn’t sure whether you want that page indexed.
As a result, this page can appear in search results, but it won’t display a description. It will also exclude images, videos, PDFs, and non-HTML files. Therefore, you’ll need to update your robots.txt file if you want to display this information.
Potential Problems in Page Indexing
You can intentionally add directives to your robots.txt file that block pages from crawlers. However, these directives may not completely remove the pages from Google. If an external website links to the page, it can cause an “Indexed, though blocked by robots.txt” error.
Google (and other search engines) need to index your pages before they can accurately rank them. To ensure that only relevant content appears in the search results, it’s crucial to understand how this process works.
Although certain pages should be indexed, they may not be. This could be due to a few different reasons:
- A directive in the robots.txt file that prevents indexing
- Broken links or redirect chains
- Canonical tags in the HTML header
On the other hand, some web pages should not be indexed. They may end up accidentally indexed because of these factors:
- Incorrect noindex directives
- External links from other sites
- Old URLs in the Google index
- No robots.txt file
If too many of your pages are indexed, your server may become overwhelmed by Google’s crawler. Plus, Google could waste time indexing irrelevant pages on your website. Therefore, you’ll need to create and edit your robots.txt file correctly.
Finding the Source of the “Indexed, Though Blocked by robots.txt” Error
One effective way to identify problems in page indexing is to sign in to Google Search Console. After you verify site ownership, you’ll be able to access reports about your website’s performance.
In the Index section, click on the Valid with warnings tab. This will pull up a list of your indexing errors, including any “Indexed, though blocked by robots.txt” warnings. If you don’t see any, your website likely isn’t experiencing this problem.
Alternatively, you can use Google’s robots.txt tester. With this tool, you can scan your robots.txt file to look for syntax warnings and other errors:
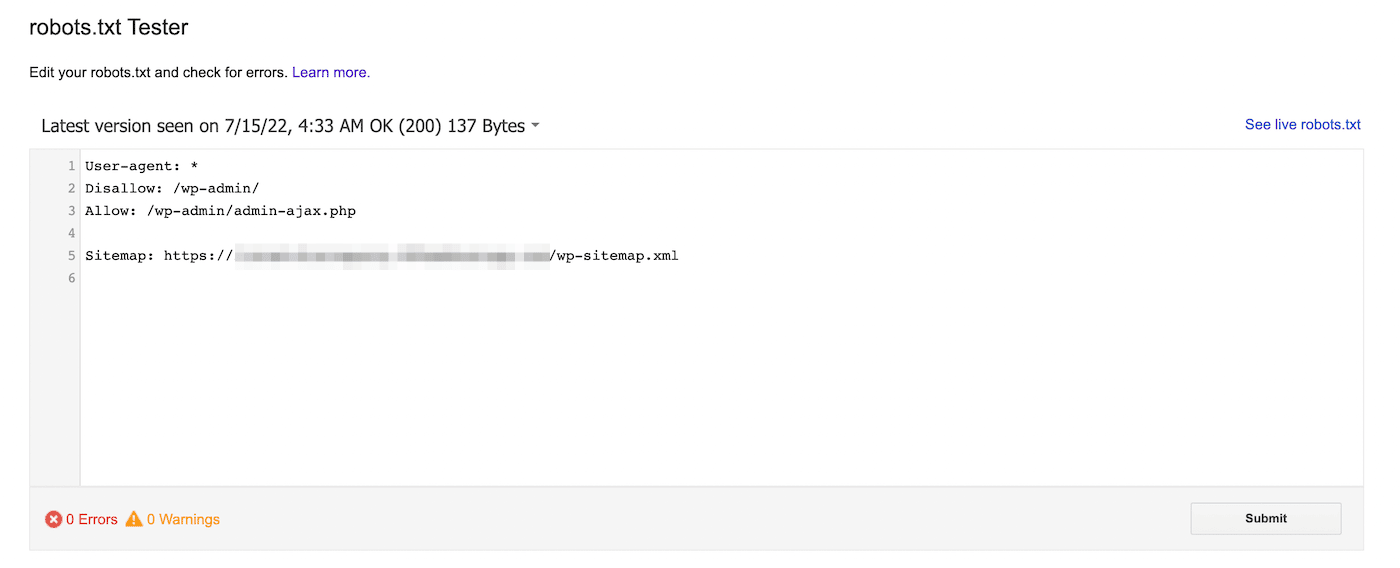
At the bottom of the page, enter a specific URL to see if it’s blocked. You’ll need to choose a user-agent from the dropdown menu and select Test:

You can also navigate to domain.com/robots.txt. If you already have a robots.txt file, this will allow you to view it:
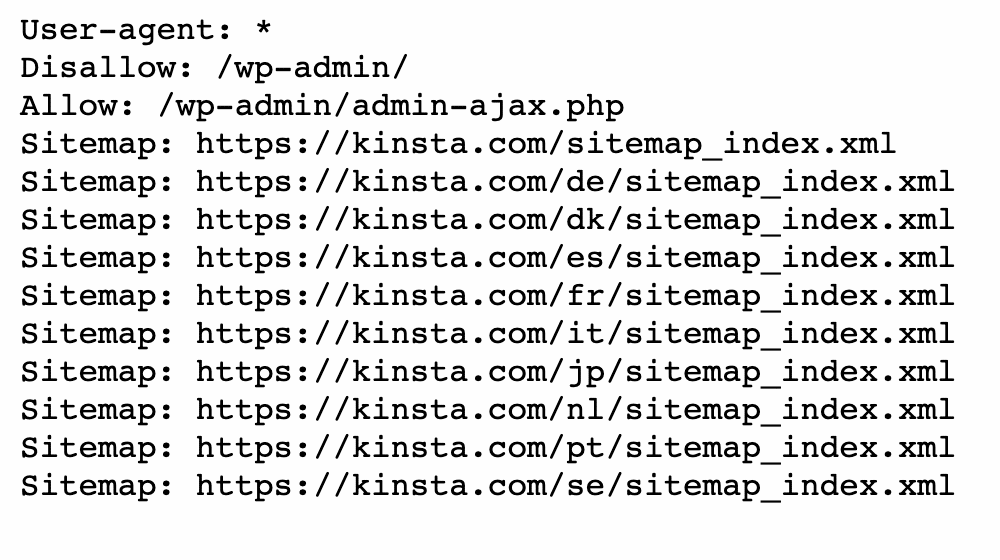
Next, look for disallow statements. Site administrators can add these statements to instruct search crawlers on how to access specific files or pages.
If the disallow statement blocks all search engines, it might look like this:
Disallow: /It may also block a specific user-agent:
User-agent: *
Disallow: /With any of these tools, you’ll be able to identify any issues with your page indexing. Then, you’ll need to take action to update your robots.txt file.
How to Fix the “Indexed, Though Blocked by robots.txt” Error
Now that you know more about the robots.txt file and how it can prevent page indexing, it’s time to fix the “Indexed, though blocked by robots.txt” error. However, make sure to evaluate first whether the blocked page needs to be indexed before using these solutions.
Method 1: Edit robots.txt Directly
If you have a WordPress website, you’ll probably have a virtual robots.txt file. You can visit it by searching for domain.com/robots.txt in a web browser (replacing domain.com with your domain name). However, this virtual file won’t enable you to make edits.
To start editing robots.txt, you’ll need to create a file on your server. Firstly, choose a text editor and create a new file. Be sure to name it “robots.txt”:
Then, you’ll need to connect to an SFTP client. If you’re using a Kinsta hosting account, sign in to MyKinsta and navigate to Sites > Info:
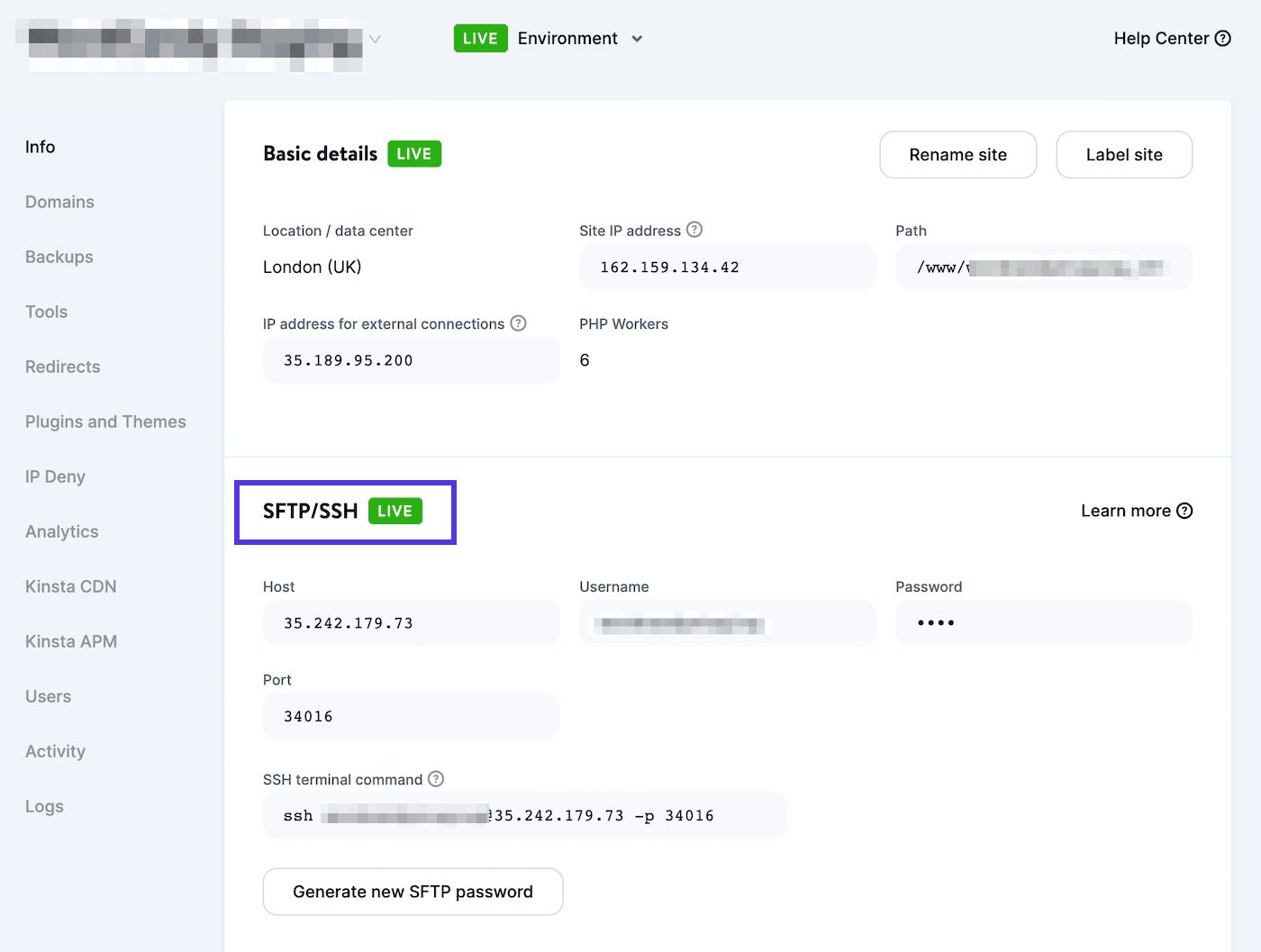
You’ll find your username, password, host, and port number here. You can then download an SFTP client such as FileZilla. Enter your SFTP login credentials and click on Quickconnect:

Lastly, upload the robots.txt file to your root directory (for WordPress sites, it should be called public_html). Then, you can open the file and make the necessary changes.
You can use allow and disallow statements to customize the indexing of your WordPress site. For example, you may want a certain file to be crawled without indexing the entire folder. In this case, you can add this code:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpRemember to target the page causing the “Indexed, though blocked by robots.txt” error during this process. Depending on your goal, you can specify whether Google should or should not crawl the page.
When you’re finished, save your changes. Then, go back to Google Search Console to see if this method resolved the error.
Method 2: Use an SEO Plugin
If you have an SEO plugin activated, you won’t have to create an entirely new robots.txt file. In many cases, the SEO tool will build one for you. Plus, it may also provide ways to edit the file without leaving the WordPress dashboard.
Yoast SEO
One of the most popular SEO plugins is Yoast SEO. It can provide a detailed on-page SEO analysis, along with additional tools to customize your search engine indexing.
To start editing your robots.txt file, go to Yoast SEO > Tools in your WordPress dashboard. From the list of built-in tools, select the File editor:

Yoast SEO will not automatically create a robots.txt file. If you don’t already have one, click on Create robots.txt file:
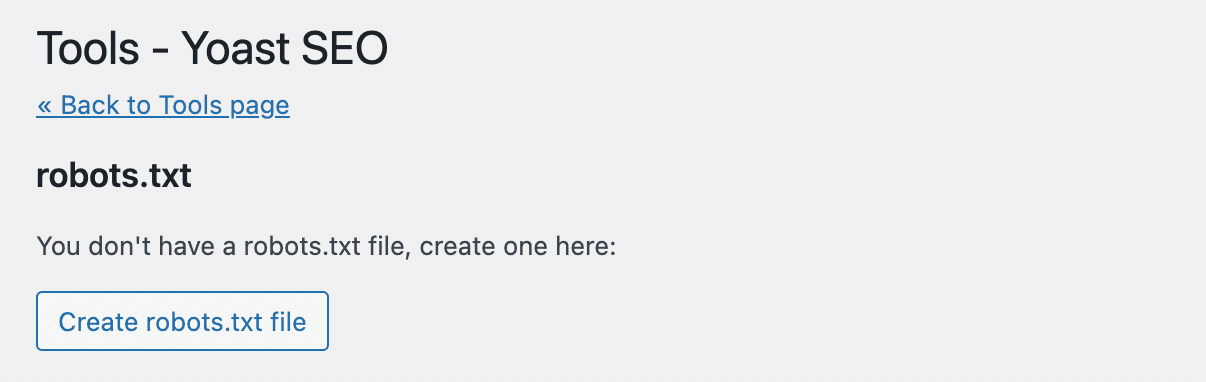
This will open a text editor with the content of your new robots.txt file. Similar to the first method, you can add allow statements to pages you want to be indexed. Alternatively, use disallow statements for URLs to avoid indexing:
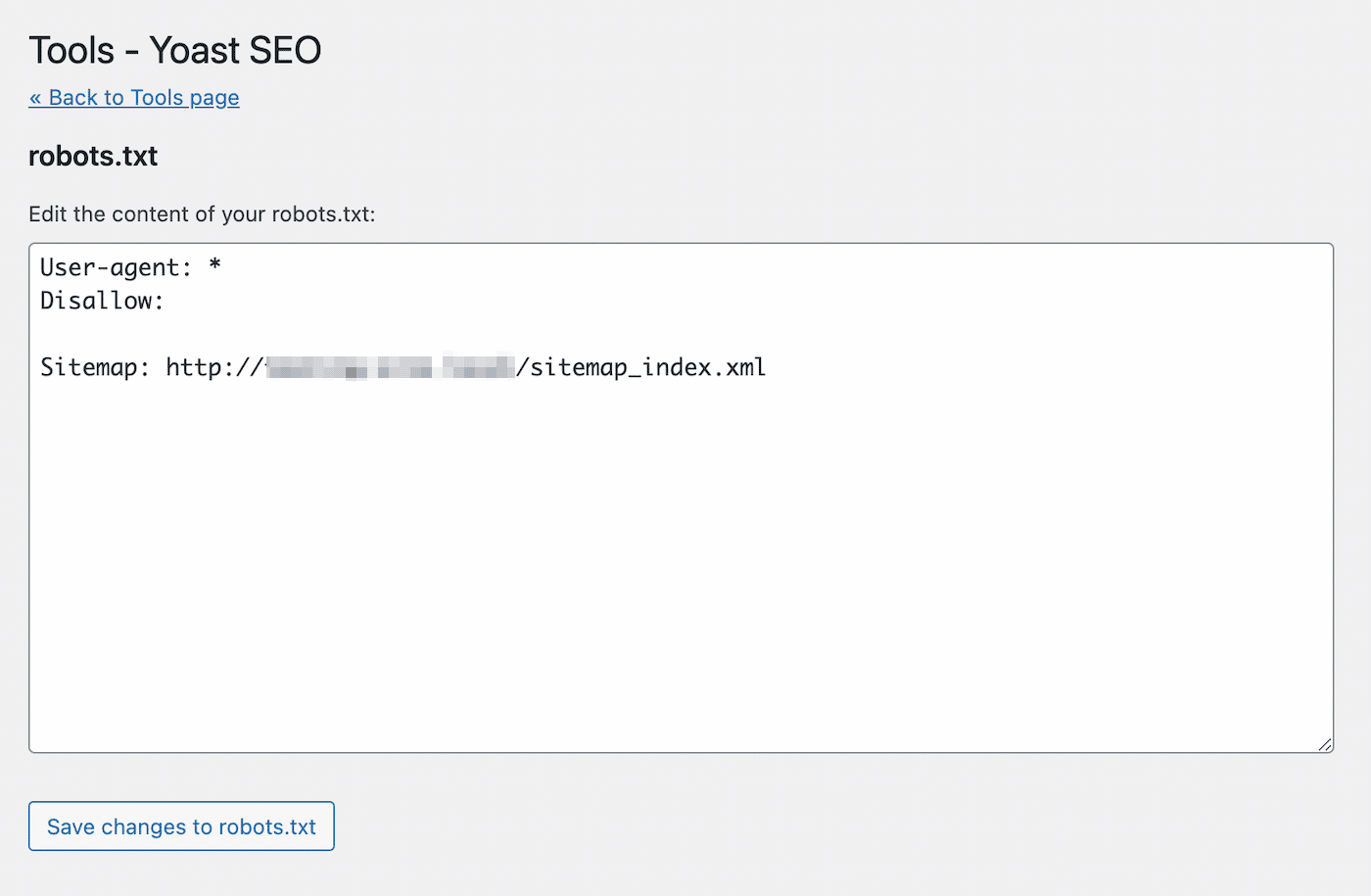
After making your changes, save the file. Yoast SEO will alert you when you’ve updated the robots.txt file.
Rank Math
Rank Math is another freemium plugin that includes a robots.txt editor. After activating the tool on your WordPress site, go to Rank Math > General Settings > Edit robots.txt:
In the code editor, you’ll see some default rules, including your sitemap. To update its settings, you can paste or delete code as necessary.
During this editing process, there are a few rules you should follow:
- Use one or more groups, with each group containing multiple rules.
- Start each group with a user-agent and follow with specific directories or files.
- Assume that any web page allows indexing unless it has a disallow rule.
Keep in mind that this method is only possible when you don’t already have a robots.txt file in your root directory. If you do, you’ll have to edit the robot.txt file directly using an SFTP client. Alternatively, you can delete this pre-existing file and use the Rank Math editor instead.
Once you disallow a page in robots.txt, you should also add a noindex directive. It will keep the page private from Google searches. To do this, navigate to Rank Math > Titles & Meta > Posts:
Scroll down to Post Robots Meta and enable it. Then, select No Index:
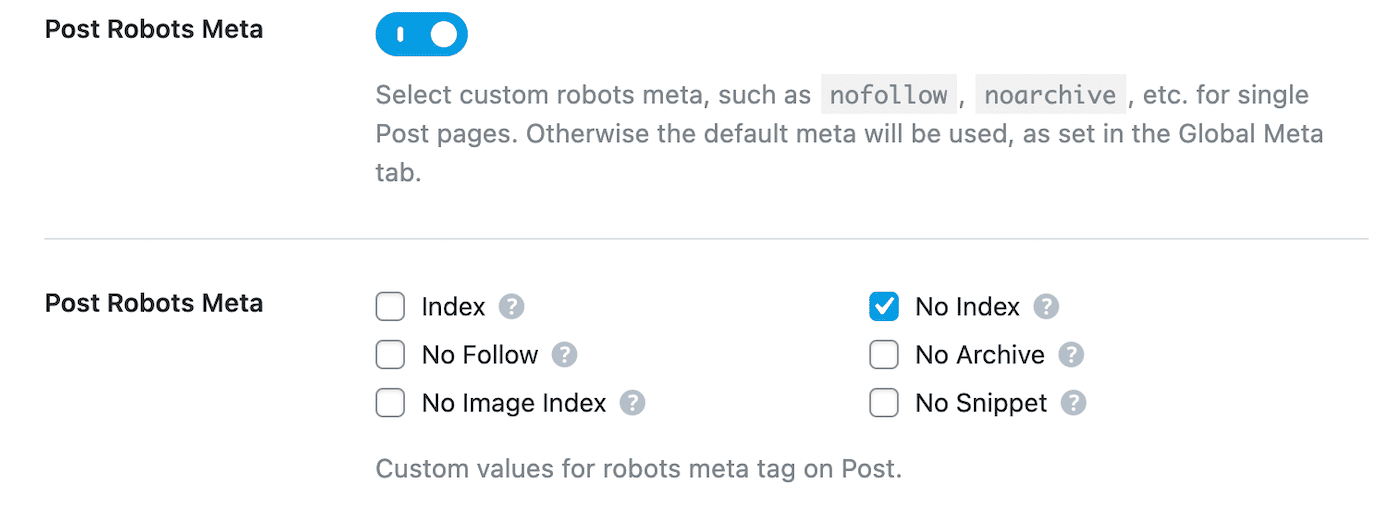
Finally, save your changes. In Google Search Console, find the “Indexed, though blocked by robots.txt” warning and click on Validate Fix. This will enable Google to recrawl the given URLs and resolve the error.
Squirrly SEO
Using the Squirrly SEO plugin, you can similarly edit robots.txt. To get started, click on Squirrly SEO > SEO Configuration. This will open the Tweaks and Sitemap settings:
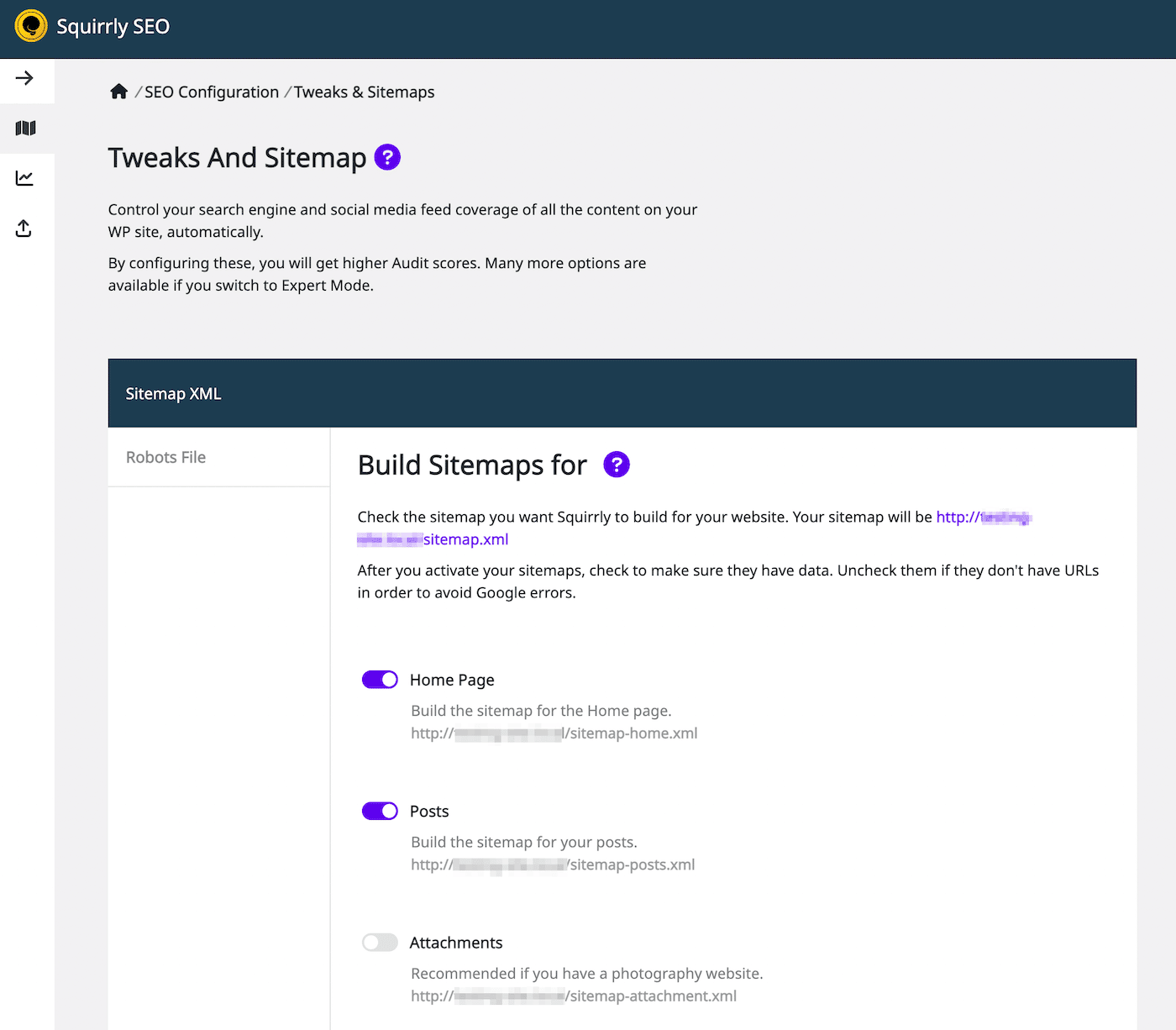
On the left-hand side, select the Robots File tab. Then, you’ll see a robots.txt file editor that looks similar to other SEO plugins:
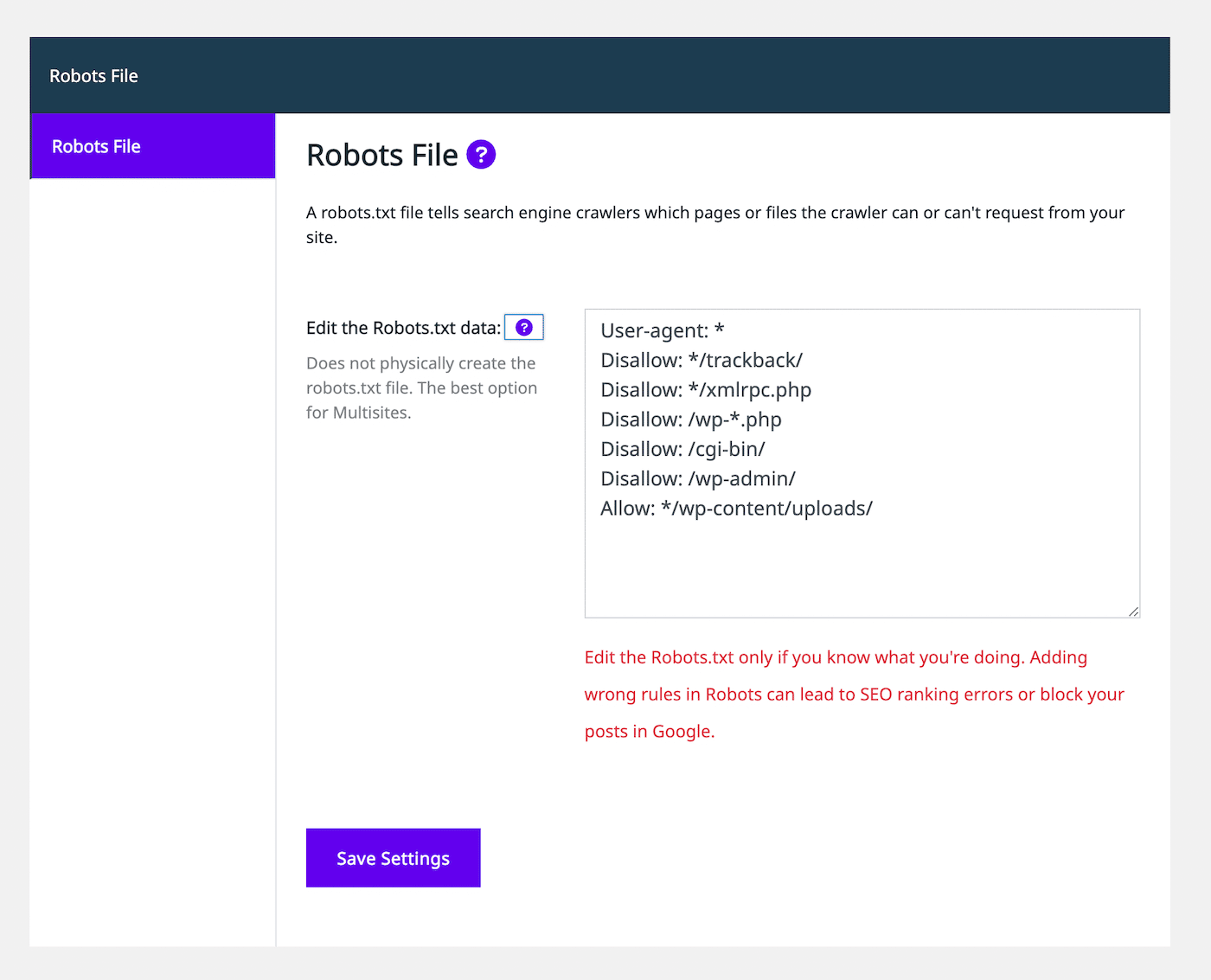
Using the text editor, you can add allow or disallow statements to customize the robots.txt file. Continue to add as many rules as you need. When you’re happy with how this file looks, select Save Settings.
Additionally, you can add noindex rules to certain post types. To do this, you’ll simply need to disable the Let Google Index It setting in the Automation tab. By default, SEO Squirrly will leave this enabled.
Summary
Typically, Google will find your web pages and index them in its search results. However, a poorly configured robots.txt file can confuse search engines about whether to ignore this page during crawling. In this case, you’ll need to clarify crawling instructions to continue maximizing SEO on your website.
You can edit robots.txt directly with an SFTP client such as FileZilla. Alternatively, many SEO plugins, including Yoast, Rank Math, and Squirrly SEO, include robots.txt editors within their interfaces. Using any of these tools, you’ll be able to add allow and disallow statements to help search engines index your content correctly.
To help your website rise to the top of search results, we recommend choosing an SEO-optimized web host. At Kinsta, our managed WordPress hosting plans include SEO tools such as uptime monitoring, SSL certificates, and redirect management. Check out our plans today!

Head of Content at Kinsta and Content Marketing Consultant for WordPress plugin developers. Connect with Matteo on Twitter.

