
Die meisten WordPress-Ausfälle beginnen nicht mit Traffic-Spitzen oder Infrastrukturausfällen. Sie beginnen mit gewöhnlichen Änderungen, wie z.B. einem Plugin-Update, einer Anpassung der Konfigurationsdatei oder einer kleinen Korrektur, die live geschaltet wird.
WordPress ist leistungsstark und flexibel, aber es hängt auch von den Menschen ab, die es reibungslos am Laufen halten, und das bedeutet, dass Fehler immer Teil der Gleichung sind.
Zuverlässigkeit bedeutet also nicht, dass nichts schief gehen kann. Es bedeutet, dass du dir darüber im Klaren bist, dass irgendwann etwas passieren wird.
Die eigentliche Frage ist nicht, wie du diese Fehler ganz ausschließen kannst. Es geht darum, wie gut du vorbereitet bist, wenn sie passieren. Wie schnell identifizierst du Fehlerquellen, wie sicher kannst du sie beheben und welche Auswirkungen hat das auf den laufenden Betrieb? Das ist es, was letztlich die Zuverlässigkeit in der Praxis ausmacht.
Warum menschliches Versagen die wahre Ursache für die meisten Ausfallzeiten ist
Es ist leicht anzunehmen, dass Ausfallzeiten durch hohe Besucherzahlen oder Infrastrukturprobleme verursacht werden. In der Praxis sind die meisten Probleme jedoch auf Änderungen an der Website selbst zurückzuführen.
WordPress entwickelt sich ständig weiter. Plugins werden aktualisiert, Themes werden angepasst, Konfigurationen werden verfeinert und Inhalte werden bearbeitet. Jede dieser Änderungen wird mit der klaren Absicht vorgenommen, etwas zu verbessern, aber jede führt auch eine neue Variable in das System ein.
Hier können kleine Fehler große Auswirkungen haben. Ein kleiner Syntaxfehler in einer Konfigurationsdatei, ein Plugin-Update oder eine Änderung in einem Teil des Systems kann eine Website zum Absturz bringen.
Deshalb sind diese Vorfälle weder ungewöhnlich noch auf lange Sicht vermeidbar. Sie sind ein natürliches Ergebnis der Arbeit mit einem flexiblen, vielschichtigen System.
Es geht nicht darum, menschliches Versagen völlig auszuschalten, sondern zu erkennen, dass es zum Betrieb moderner WordPress-Websites dazugehört. Sobald das klar ist, kann sich der Fokus von dem Versuch, jedes Problem zu verhindern, auf die Bewältigung dieser Probleme verlagern.
Wo es typischerweise zu Problemen kommt
Wenn etwas schief geht, ist das normalerweise kein Zufall. Die meisten Pannen fallen in ein paar bekannte Kategorien:
-
- Konfigurationsfehler in Kerndateien
- Plugin- und Theme-Konflikte nach Updates
- Editor- und JavaScript-Probleme, die den Content-Workflow unterbrechen
- Moderne Konfigurationsprobleme in Dateien wie
theme.json
Jedes dieser Probleme zeigt sich auf etwas andere Weise, aber sie beginnen oft mit kleinen, routinemäßigen Änderungen.
Auf der Konfigurationsebene können selbst kleine Fehler eine Website sofort offline nehmen. Ein kleiner Syntaxfehler in einer .htaccess-Datei zum Beispiel reicht aus, um einen Ausfall auf Serverebene auszulösen.
RewriteEngine On
RewriteRule ^index.php$ - [LDie fehlende schließende Klammer ist leicht zu übersehen, kann aber zu einem kompletten Ausfall der Website führen, der in der Regel mit folgender Fehlermeldung angezeigt wird:
500 Internal Server Error
The server encountered an internal error or misconfiguration.Andere Konfigurationsprobleme verhalten sich ähnlich. Falsche Datenbankzugangsdaten in der wp-config.php können verhindern, dass WordPress überhaupt eine Verbindung herstellt, während ein Tippfehler in der functions.php zu einem weißen Bildschirm führen kann, der sowohl Besucher als auch Administratoren aussperrt.
Konflikte zwischen Plugins und Themes sind eine weitere häufige Ursache für Probleme. Da alles im selben Ausführungsbereich läuft, können sich Aktualisierungen in einer Komponente auf unerwartete Weise auf andere auswirken. Ein routinemäßiges Plugin-Update kann einen Checkout-Flow unterbrechen, eine Funktion deaktivieren oder Fehler verursachen, die vorher nicht vorhanden waren.
Auch im Editor treten Probleme auf, vor allem bei Websites, die stark auf Blöcke und JavaScript angewiesen sind. Ein Skriptfehler kann dazu führen, dass der Editor ohne Steuerelemente geladen wird oder dass Inhalte nicht gespeichert werden können. In manchen Fällen funktioniert das Frontend weiter, während das Backend für die Content-Teams unbrauchbar wird.
In jüngerer Zeit hat die Konfiguration über Dateien wie theme.json eine weitere Risikoebene eingeführt. Eine falsch gesetzte Einstellung oder eine ungültige Struktur kann zwar nicht die gesamte Website zum Absturz bringen, aber sie kann zu subtilen Problemen führen, die schwieriger zu verfolgen sind.
Zum Beispiel ein kleiner struktureller Fehler wie dieser:
{
"settings": {
"color": {
"palette": [
{
"name": "Primary",
"slug": "primary",
"color": "#0073aa"
}
]
}
},
"styles": {
"color": {
"text": "#333333"
}
}
}Auf den ersten Blick mag das korrekt aussehen, aber wenn die Schlüssel falsch platziert oder dupliziert sind oder nicht dem erwarteten Schema entsprechen, ignoriert WordPress möglicherweise Teile der Konfiguration.
Das Ergebnis ist keine sichtbare Fehlermeldung. Stattdessen wirst du feststellen, dass die erwarteten Stile nicht angewendet werden, dass die Steuerelemente des Editors verschwinden oder dass sich Blöcke auf verschiedenen Seiten uneinheitlich verhalten.
Dies spiegelt das Verhalten von WordPress im täglichen Gebrauch wider, wo sich kleine Änderungen auf eine Art und Weise auswirken können, die auf den ersten Blick nicht immer offensichtlich ist.
Warum Vorbeugung allein das Problem nicht löst
Es liegt nahe, auf diese Risiken mit einer Verschärfung der Prozesse zu reagieren. Die Teams gehen vorsichtiger mit Aktualisierungen um, Änderungen werden genauer überprüft und wo immer möglich, werden Tests durchgeführt, bevor etwas in die Produktion gelangt.
Diese Maßnahmen verringern die Wahrscheinlichkeit von Problemen und sind für die Verwaltung jeder WordPress-Website unerlässlich. Aber sie beseitigen das Problem nicht.
Plugins entwickeln sich unabhängig voneinander, Abhängigkeiten ändern sich im Laufe der Zeit, und die Wechselwirkungen zwischen den Komponenten sind nicht immer vorhersehbar. Eine Änderung, die beim Testen sicher aussieht, kann sich in der Produktion anders verhalten, vor allem, wenn sie auf echte Daten, echten Traffic oder eine Kombination von Plugins trifft, die nicht berücksichtigt wurden. In vielen Fällen werden Probleme nicht durch einen einzelnen Fehler verursacht, sondern dadurch, wie mehrere Teile des Systems unter realen Bedingungen zusammenwirken.
Aus diesem Grund ist Vorsicht keine Garantie für Stabilität. Es senkt die Wahrscheinlichkeit, dass etwas schief läuft, aber es kann die Möglichkeit nicht völlig ausschließen.
Backups werden oft als Ausweichlösung betrachtet, und sie sind wichtig. Aber Backups sind nur ein Teil der Gleichung. Genauso wichtig ist, wie schnell und sicher diese Backups genutzt werden können, wenn etwas schief geht. In manchen Umgebungen ist die Wiederherstellung einer Website sofort und kontrolliert möglich. In anderen ist die Wiederherstellung von manuellen Schritten oder Support-Wartezeiten abhängig, was die Problembehebung verzögert und den Ausfall verlängert.
Und auch wenn diese Vorfälle nicht jeden Tag vorkommen, sind ihre Auswirkungen selten gering. Ein defekter Checkout, ein unzugänglicher Admin-Bereich oder ein standortweiter Fehler können den Betrieb innerhalb von Minuten unterbrechen.
Was Zuverlässigkeit in der Praxis bedeutet
An diesem Punkt wird klar, dass es bei der Zuverlässigkeit nicht nur darum geht, Fehler zu vermeiden, sondern auch darum, wie das System reagiert, wenn diese Fehler unvermeidlich auftreten. Eine Website, die nie ausfällt, ist unrealistisch. Eine Website, die sich schnell und vorhersehbar erholt, ist in der Praxis viel wertvoller.
Damit verschiebt sich der Schwerpunkt von der Prävention zur Kontrolle. Anstatt zu fragen, ob eine Veränderung ein Risiko mit sich bringt, ist die sinnvollere Frage, wie begrenzt dieses Risiko ist.
Wenn etwas vorfällt, kann es isoliert werden, ohne dass die gesamte Website betroffen ist? Kann das Problem sofort erkannt werden, oder dauert es eine Weile, bis es jemandem auffällt? Und wenn es einmal erkannt wurde, kann es rückgängig gemacht werden, ohne die ohnehin schon stressige Situation noch komplizierter zu machen?
In der Praxis sind verlässliche Systeme so konzipiert, dass Ausfälle beherrschbar sind. Änderungen werden in Umgebungen getestet, die die Produktionsumgebung widerspiegeln, und nicht direkt an den Live-Websites. Wenn etwas kaputt geht, gibt es einen klaren und schnellen Weg, um zu einem bekannten, funktionierenden Zustand zurückzukehren. Frühzeitige Überwachung von Problemen, oft bevor die Nutzer sie melden. Das Ziel ist nicht, Fehler auszuschließen, sondern sicherzustellen, dass Fehler nicht zu längeren Ausfallzeiten oder größeren Störungen führen.
An dieser Stelle werden die Unterschiede zwischen den verschiedenen Systemen deutlich. Zwei Websites können das gleiche Problem haben, z. B. ein problematisches Plugin-Update oder einen Konfigurationsfehler, aber das Ergebnis kann völlig unterschiedlich sein. Die eine erholt sich innerhalb von Minuten mit minimalen Auswirkungen. Die andere bleibt instabil, während das Team manuelle Korrekturen, Wiederherstellungen oder Supportprozesse durchführt. Der ursprüngliche Fehler ist derselbe, aber das System, das ihn umgibt, bestimmt die Auswirkungen.
Wie deine Hosting-Umgebung zum Sicherheitssystem wird
Wenn du anfängst, über Zuverlässigkeit im Sinne von Prävention und Wiederherstellung nachzudenken, ändert sich die Rolle deiner Hosting-Umgebung.
Sie wird zu dem System, das bestimmt, wie sicher du Änderungen vornehmen kannst und wie schnell etwas wiederhergestellt werden kannst, wenn mal Probleme auftauchen.
Bei der Vorbeugung geht es darum, keine unnötigen Risiken in eine laufende Website einzubauen. Das bedeutet in der Regel, dass es eine Möglichkeit gibt, Änderungen zu testen, bevor sie die Produktion erreichen. Ob Plugin-Update, Konfigurationsänderung oder neue Funktion: Wenn du Änderungen in einer Staging-Umgebung testest, sinkt das Risiko, dass Fehler live für deine Nutzer sichtbar werden.
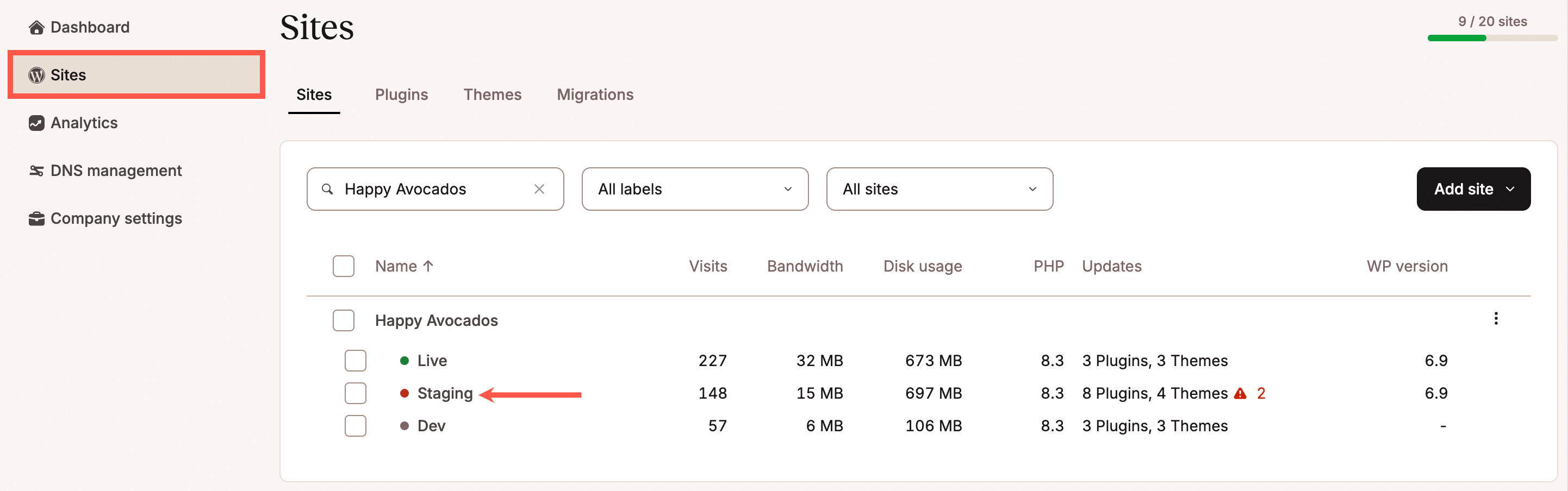
Das Risiko wird dadurch zwar nicht vollständig beseitigt, aber es wird in einen kontrollierten Bereich verlagert, in dem Probleme frühzeitig erkannt werden können.
Wenn Beeinträchtigungen auftreten, wird der Fokus sofort auf die Wiederherstellung gelegt. An dieser Stelle wird der Unterschied zwischen den Umgebungen deutlicher. In manchen Umgebungen ist die Wiederherstellung einer Website ein langwieriger, manueller Prozess mit ungewissem Ausgang. In anderen ist es ein einfacher Vorgang, der innerhalb von Minuten abgeschlossen werden kann, mit klaren Wiederherstellungspunkten und minimalen Unterbrechungen. Dieser Unterschied in der Wiederherstellungsgeschwindigkeit entscheidet oft darüber, ob sich ein Problem wie ein kleiner Rückschlag oder wie ein großer Vorfall anfühlt.
Auch die Erkennung spielt hier eine Rolle. Wenn ein Problem nicht sofort sichtbar ist, kann es die Nutzer/innen schon lange beeinträchtigen, bevor jemand im Team es bemerkt. Umgebungen, die eine klare Überwachung bieten und Probleme frühzeitig aufdecken, helfen dabei, dieses Zeitfenster zu verkürzen, so dass die Teams reagieren können, bevor sich die Auswirkungen ausbreiten.
Zusammengenommen verändern diese Funktionen die Arbeitsweise von Teams. Aktualisierungen müssen nicht mehr aus Vorsicht hinausgezögert werden, und Fehler bergen nicht mehr das gleiche Risiko, weil ein klarer Weg zur Behebung besteht. Das System unterstützt sowohl vorsichtige Veränderungen als auch schnelle Korrekturen, was die Weiterentwicklung nachhaltig macht.
Zuverlässigkeit im Ernstfall
Egal, wie erfahren das Team ist oder wie sorgfältig Änderungen vorgenommen werden, irgendwann geht etwas schief. Das ist kein Versagen des Prozesses oder der Disziplin. Es ist ein natürliches Ergebnis der Arbeit mit einem System, das sich ständig weiterentwickelt.
Der Unterschied zwischen stabilen und instabilen Websites liegt darin, wie mit diesen Fehlern umgegangen wird. Wenn Probleme schnell erkannt, sicher behoben und eingedämmt werden können, ohne dass die gesamte Website in Mitleidenschaft gezogen wird, sind sie keine großen Zwischenfälle mehr, sondern werden Teil des normalen Betriebs.
Genau für diese Art von Umgebung ist Kinsta konzipiert. Von integrierten Staging- und automatischen Backups bis hin zu schnellen, kontrollierten Wiederherstellungspunkten – so halten wir deine Website nicht nur online, sondern machen sie auch widerstandsfähig gegen die alltäglichen Änderungen, die oft Probleme verursachen.
Wenn dein derzeitiges System die Wiederherstellung langsam, unsicher oder stressig macht, lohnt es sich vielleicht, nicht nur die Art und Weise, wie du deine Website verwaltest, sondern auch das System, das sie unterstützt, zu überdenken.

Bud Kraus has been working with WordPress as an in-class and online instructor, site developer, and content creator since 2009. He has produced instructional videos and written many articles for WordPress businesses.

