
Node.js ist eine serverseitige JavaScript-Laufzeitumgebung, die ein ereignisgesteuertes, nicht blockierendes Input-Output (I/O)-Modell verwendet. Node.js ist weithin bekannt für die Entwicklung schneller und skalierbarer Webanwendungen. Außerdem gibt es eine große Community und eine umfangreiche Bibliothek mit Modulen, die verschiedene Aufgaben und Prozesse vereinfachen.
Clustering steigert die Leistung von Node.js-Anwendungen, indem es ihnen ermöglicht, auf mehreren Prozessen zu laufen. Diese Technik ermöglicht es ihnen, das volle Potenzial eines Multi-Core-Systems zu nutzen.
Dieser Artikel wirft einen umfassenden Blick auf das Clustering in Node.js und wie es die Leistung einer Anwendung beeinflusst.
Was ist Clustering?
Standardmäßig laufen Node.js-Anwendungen auf einem einzigen Thread. Dieser Single-Thread-Charakter bedeutet, dass Node.js nicht alle Kerne in einem Multi-Core-System nutzen kann – was bei den meisten Systemen der Fall ist.
Node.js kann trotzdem mehrere Anfragen gleichzeitig bearbeiten, indem es nicht-blockierende E/A-Operationen und asynchrone Programmiertechniken nutzt.
Allerdings können schwere Rechenaufgaben die Ereignisschleife blockieren und dazu führen, dass die Anwendung nicht mehr ansprechbar ist. Deshalb verfügt Node.js über ein natives Clustermodul – unabhängig von seinem Single-Thread-Charakter – um die gesamte Rechenleistung eines Multi-Core-Systems zu nutzen.
Die Ausführung mehrerer Prozesse nutzt die Rechenleistung mehrerer CPU-Kerne (Central Processing Unit), um eine parallele Verarbeitung zu ermöglichen, die Antwortzeiten zu verkürzen und den Durchsatz zu erhöhen. Das wiederum verbessert die Leistung und Skalierbarkeit von Node.js-Anwendungen.
Wie funktioniert Clustering?
Das Node.js-Cluster-Modul ermöglicht es einer Node.js-Anwendung, einen Cluster aus gleichzeitig laufenden Kindprozessen zu erstellen, von denen jeder einen Teil der Arbeitslast der Anwendung übernimmt.
Bei der Initialisierung des Clustermoduls erstellt die Anwendung einen primären Prozess, der die untergeordneten Prozesse zu Worker-Prozessen forkt. Der Hauptprozess fungiert als Load Balancer und verteilt die Arbeitslast auf die Worker-Prozesse, während jeder Worker-Prozess auf eingehende Anfragen wartet.
Das Node.js-Cluster-Modul verfügt über zwei Methoden zur Verteilung eingehender Verbindungen.
- Das round-Robin-Verfahren – Der primäre Prozess lauscht an einem Port, nimmt neue Verbindungen an und verteilt die Arbeitslast gleichmäßig, um sicherzustellen, dass kein Prozess überlastet wird. Dies ist die Standardmethode auf allen Betriebssystemen außer Windows.
- Der zweite Ansatz – Der Hauptprozess erstellt den Listen-Socket und sendet ihn an „interessierte“ Worker, die eingehende Verbindungen direkt annehmen.
Theoretisch sollte der zweite Ansatz – der komplizierter ist – eine bessere Leistung bringen. Aber in der Praxis ist die Verteilung der Verbindungen sehr unausgewogen. In der Node.js-Dokumentation wird erwähnt, dass 70 % aller Verbindungen in nur zwei von acht Prozessen landen.
Wie du deine Node.js-Anwendungen clustern kannst
Schauen wir uns nun an, welche Auswirkungen das Clustering in einer Node.js-Anwendung hat. In diesem Tutorial wird eine Express-Anwendung verwendet, die absichtlich eine rechenintensive Aufgabe ausführt, um die Ereignisschleife zu blockieren.
Führe diese Anwendung zunächst ohne Clustering aus. Dann zeichnest du die Leistung mit einem Benchmarking-Tool auf. Als Nächstes wird das Clustering in die Anwendung implementiert und das Benchmarking wird wiederholt. Vergleiche schließlich die Ergebnisse, um zu sehen, wie das Clustering die Leistung deiner Anwendung verbessert.
Erste Schritte
Um diesen Lehrgang zu verstehen, musst du mit Node.js und Express vertraut sein. So richtest du deinen Express-Server ein:
- Beginne mit der Erstellung des Projekts.
mkdir cluster-tutorial - Navigiere zum Anwendungsverzeichnis und erstelle zwei Dateien, no-cluster.js und cluster.js, indem du den folgenden Befehl ausführst:
cd cluster-tutorial && touch no-cluster.js && touch cluster.js - Initialisiere NPM in deinem Projekt:
npm init -y - Zum Schluss installierst du Express, indem du den folgenden Befehl ausführst:
npm install express
Erstellen einer nicht geclusterten Anwendung
Füge in deiner no-cluster.js-Datei den folgenden Codeblock ein:
const express = require("express");
const PORT = 3000;
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
//Start timer
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});Der obige Codeblock erstellt einen Express-Server, der auf Port 3000 läuft. Der Server hat zwei Routen, eine Root-Route (/) und eine /slow Route. Die Root-Route sendet eine Antwort an den Client mit der Nachricht: „Antwort vom Server“
Die Route /slow führt jedoch absichtlich einige schwere Berechnungen durch, um die Ereignisschleife zu blockieren. Diese Route startet einen Timer und füllt dann mit Hilfe einer for Schleife ein Array mit 100.000 Zufallszahlen.
Dann wird in einer weiteren for Schleife jede Zahl in dem erzeugten Array quadriert und addiert. Der Timer endet, wenn der Vorgang abgeschlossen ist, und der Server antwortet mit den Ergebnissen.
Starte deinen Server, indem du den unten stehenden Befehl ausführst:
node no-cluster.jsStelle dann eine GET-Anfrage an localhost:3000/slow.
Wenn du während dieser Zeit versuchst, andere Anfragen an deinen Server zu stellen – zum Beispiel an die Root-Route (/) – sind die Antworten langsam, da die /slow Route die Ereignisschleife blockiert.
Eine Clusteranwendung erstellen
Erzeuge mit dem Clustermodul Child-Prozesse, um sicherzustellen, dass deine Anwendung nicht nicht mehr reagiert und nachfolgende Anfragen bei schweren Rechenaufgaben abwürgt.
Jeder Child-Prozess führt seine eigene Ereignisschleife aus und teilt sich den Serverport mit dem Elternprozess, sodass die verfügbaren Ressourcen besser genutzt werden können.
Importiere zunächst die Module Node.js cluster und os in deine cluster.js-Datei. Das cluster-Modul ermöglicht die Erstellung von Child-Prozessen, um die Arbeitslast auf mehrere CPU-Kerne zu verteilen.
Das Modul os liefert Informationen über das Betriebssystem deines Computers. Du brauchst dieses Modul, um die Anzahl der auf deinem System verfügbaren Kerne abzufragen und sicherzustellen, dass du nicht mehr Child-Prozesse erstellst als Kerne auf deinem System vorhanden sind.
Füge den folgenden Codeblock hinzu, um diese Module zu importieren und die Anzahl der Kerne in deinem System zu ermitteln:
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;Als Nächstes fügst du den folgenden Codeblock in deine cluster.js-Datei ein:
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
}Der obige Codeblock überprüft, ob der aktuelle Prozess der primäre oder der Worker-Prozess ist. Wenn ja, erzeugt der Codeblock abhängig von der Anzahl der Kerne in deinem System Child-Prozesse. Als Nächstes wartet er auf das Exit-Ereignis der Prozesse und ersetzt sie durch das Erzeugen neuer Prozesse.
Zum Schluss verpackst du die gesamte zugehörige Express-Logik in einen else-Block. Deine fertige cluster.js-Datei sollte dem unten stehenden Codeblock ähneln.
//cluster.js
const express = require("express");
const PORT = 3000;
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
} else {
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});
}Nachdem du das Clustering implementiert hast, werden mehrere Prozesse die Anfragen bearbeiten. Das bedeutet, dass deine Anwendung auch bei schweren Rechenaufgaben reaktionsschnell bleibt.
Benchmarking der Leistung mit loadtest
Um die Auswirkungen des Clustering in einer Node.js-Anwendung genau zu demonstrieren und darzustellen, verwende das npm-Paket loadtest, um die Leistung deiner Anwendung vor und nach dem Clustering zu vergleichen.
Führe den folgenden Befehl aus, um loadtest global zu installieren:
npm install -g loadtestDas Paket loadtest führt einen Lasttest für eine bestimmte HTTP/WebSockets-URL durch.
Starte als Nächstes deine Datei no-cluster.js in einer Terminalinstanz. Öffne dann eine weitere Terminalinstanz und führe den folgenden Lasttest aus:
loadtest http://localhost:3000/slow -n 100 -c 10Der obige Befehl sendet 100 Anfragen mit einer Gleichzeitigkeit von 10 an deine nicht geclusterte App. Die Ausführung dieses Befehls führt zu den folgenden Ergebnissen:
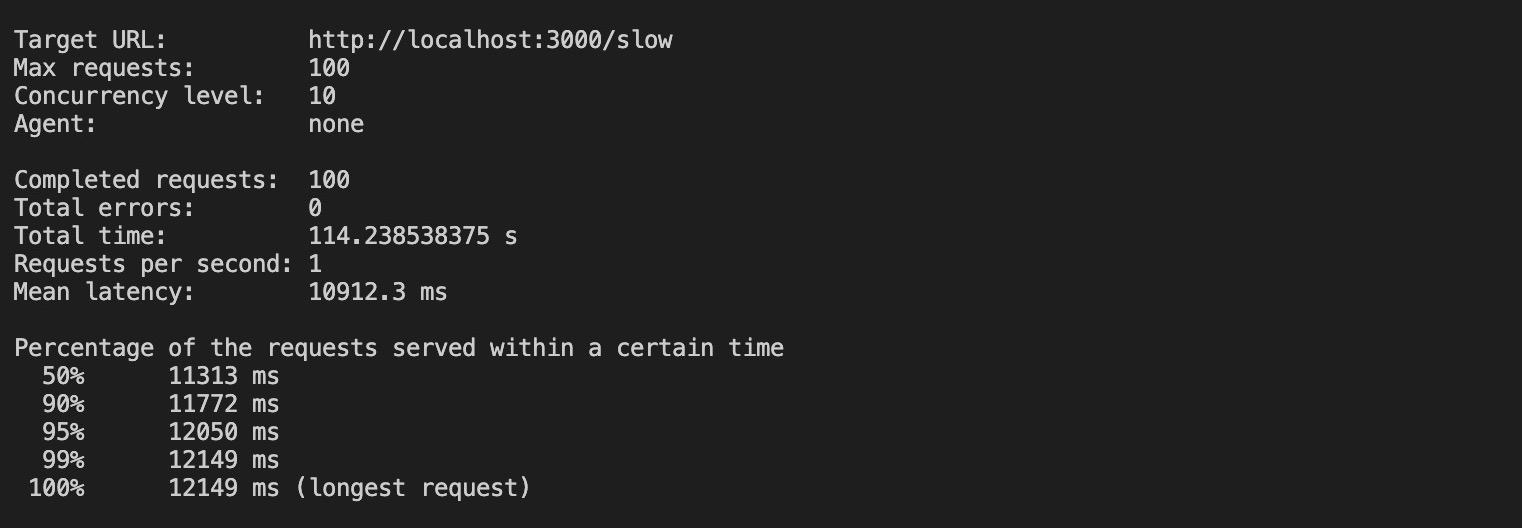
Die Ergebnisse zeigen, dass es etwa 100 Sekunden dauerte, bis alle Anfragen ohne Clustering abgeschlossen waren, wobei die längste Anfrage bis zu 12 Sekunden benötigte.
Die Ergebnisse hängen von deinem System ab.
Als Nächstes beendest du die Ausführung der Datei no-cluster.js und startest die Datei cluster.js in einer Terminalinstanz. Öffne dann eine weitere Terminalinstanz und führe diesen Lasttest durch:
loadtest http://localhost:3000/slow -n 100 -c 10Der obige Befehl sendet 100 Anfragen mit einer Gleichzeitigkeit 10 an deine geclusterte Anwendung.
Die Ausführung dieses Befehls führt zu den folgenden Ergebnissen:
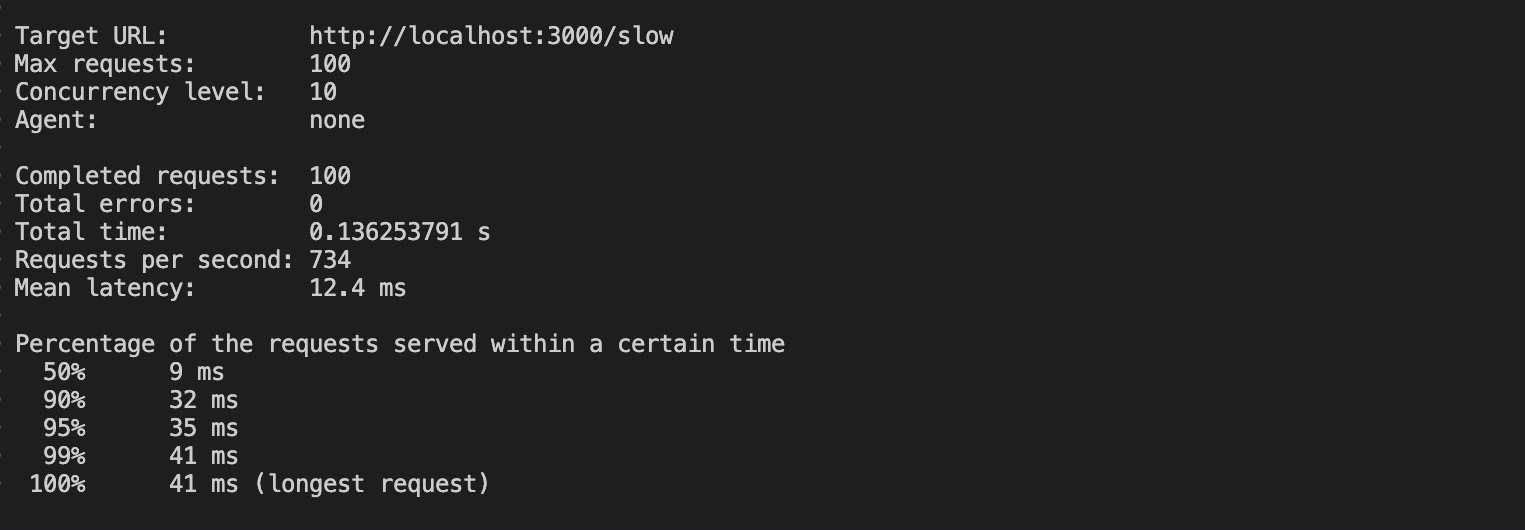
Mit dem Cluster brauchte die Anwendung 0,13 Sekunden (136 ms), um ihre Anfragen zu bearbeiten. Das ist ein enormer Rückgang gegenüber den 100 Sekunden, die die Anwendung ohne Cluster benötigte. Außerdem dauerte die längste Anfrage bei der geclusterten Anwendung 41 ms bis zum Abschluss.
Diese Ergebnisse zeigen, dass die Implementierung von Clustern die Leistung deiner Anwendung erheblich verbessert. Beachte, dass du eine Prozessmanagement-Software wie PM2 verwenden solltest, um dein Clustering in Produktionsumgebungen zu verwalten.
Verwendung von Node.js mit dem Anwendungs-Hosting von Kinsta
Kinsta ist ein Hosting-Unternehmen, das es dir leicht macht, deine Node.js-Anwendungen bereitzustellen. Die Hosting-Plattform von Kinsta basiert auf der Google Cloud Platform, die eine zuverlässige Infrastruktur für hohen Datenverkehr und komplexe Anwendungen bietet. Das verbessert letztlich die Leistung von Node.js-Anwendungen.
Kinsta bietet verschiedene Funktionen für die Node.js-Bereitstellung, z. B. interne Datenbankverbindungen, Cloudflare-Integration, GitHub-Bereitstellung und Google C2 Machines.
Diese Funktionen erleichtern die Bereitstellung und Verwaltung von Node.js-Anwendungen und rationalisieren den Entwicklungsprozess.
Um deine Node.js-Anwendung auf dem Kinsta Anwendungs-Hosting bereitzustellen, musst du den Code und die Dateien deiner Anwendung auf den von dir gewählten Git-Anbieter (Bitbucket, GitHub oder GitLab) übertragen.
Sobald dein Repository eingerichtet ist, folgst du diesen Schritten, um deine Express-Anwendung bei Kinsta bereitzustellen:
- Logge dich ein oder erstelle ein Konto, um dein MyKinsta-Dashboard zu sehen.
- Autorisiere Kinsta mit deinem Git-Anbieter.
- Klicke in der linken Seitenleiste auf Anwendungen und dann auf Anwendung hinzufügen.
- Wähle das Repository und den Branch aus, von dem aus du die Anwendung bereitstellen möchtest.
- Gib deiner Anwendung einen eindeutigen Namen und wähle einen Standort für das Rechenzentrum.
- Als Nächstes konfigurierst du deine Build-Umgebung. Wähle die Standard-Build-Maschinen-Konfiguration mit der für diese Demo empfohlenen Nixpacks-Option.
- Verwende alle Standardkonfigurationen und klicke dann auf Anwendung erstellen.
Zusammenfassung
Clustering in Node.js ermöglicht die Erstellung mehrerer Worker-Prozesse, um die Arbeitslast zu verteilen und so die Leistung und Skalierbarkeit von Node.js-Anwendungen zu verbessern. Die richtige Implementierung von Clustering ist entscheidend, um das volle Potenzial dieser Technik auszuschöpfen.
Die Gestaltung der Architektur, die Verwaltung der Ressourcenzuweisung und die Minimierung der Netzwerklatenz sind wichtige Faktoren bei der Implementierung von Clustering in Node.js. Die Wichtigkeit und Komplexität dieser Implementierung sind der Grund, warum Prozessmanager wie PM2 in Produktionsumgebungen eingesetzt werden sollten.
Was denkst du über Node.js Clustering? Hast du es schon einmal benutzt? Teile sie im Kommentarbereich mit!


