
Hast du schon mal den Begriff robots.txt gehört und dich gefragt, was er mit deiner Website zu tun hat? Die meisten Websites haben eine robots.txt-Datei, aber das bedeutet nicht, dass die meisten Website-Betreiber sie verstehen. In diesem Beitrag wollen wir das ändern, indem wir die WordPress robots.txt-Datei genauer unter die Lupe nehmen und erklären, wie sie den Zugriff auf deine Website kontrollieren und einschränken kann.
Es gibt viel zu berichten, also fangen wir an!
Was ist eine WordPress robots.txt-Datei?
Bevor wir über die robots.txt-Datei von WordPress sprechen, ist es wichtig zu definieren, was ein „Roboter“ in diesem Fall ist. Robots sind alle Arten von „Bots“, die Websites im Internet besuchen. Das häufigste Beispiel sind die Crawler von Suchmaschinen. Diese Bots „krabbeln“ durch das Internet, um Suchmaschinen wie Google dabei zu helfen, die Milliarden von Seiten im Internet zu indexieren und zu bewerten.
Bots sind also im Allgemeinen eine gute Sache für das Internet … oder zumindest eine notwendige Sache. Das bedeutet aber nicht unbedingt, dass du oder andere Website-Betreiber/innen wollen, dass Bots ungehindert herumlaufen. Der Wunsch zu kontrollieren, wie Webroboter mit Websites interagieren, führte Mitte der 1990er Jahre zur Schaffung des Robots-Exclusion-Standards. Robots.txt ist die praktische Umsetzung dieses Standards – sie ermöglicht es dir zu kontrollieren, wie die teilnehmenden Bots mit deiner Website interagieren. Du kannst Bots komplett blockieren, ihren Zugang zu bestimmten Bereichen deiner Website einschränken und vieles mehr.
Der Teil „teilnehmenden“ ist allerdings wichtig. Robots.txt kann einen Bot nicht dazu zwingen, seinen Anweisungen zu folgen. Und bösartige Bots können und werden die robots.txt-Datei ignorieren. Außerdem ignorieren selbst seriöse Unternehmen einige Befehle, die du in robots.txt eingeben kannst. Google ignoriert zum Beispiel alle Regeln, die du in deine robots.txt einträgst, um festzulegen, wie oft die Crawler deine Seite besuchen. Du kannst die Häufigkeit, mit der Google deine Website crawlt, auf der Seite Crawl-Rate-Einstellungen für deine Website in der Google Search Console einstellen.
Wenn du viele Probleme mit Bots hast, kann eine Sicherheitslösung wie Cloudflare oder Sucuri sehr hilfreich sein.
Wie findet man die robots.txt?
Die robots.txt-Datei befindet sich im Stammverzeichnis deiner Website. Wenn du also /robots.txt nach deiner Domain hinzufügst, sollte die Datei geladen werden (falls du eine hast). Zum Beispiel: https://kinsta.com/robots.txt.
Wann solltest du eine robots.txt-Datei verwenden?
Für die meisten Website-Betreiber/innen lassen sich die Vorteile einer gut strukturierten robots.txt-Datei auf zwei Kategorien beschränken:
- Sie optimiert die Crawl-Ressourcen der Suchmaschinen, indem sie ihnen sagt, dass sie keine Zeit auf Seiten verschwenden sollen, die nicht indiziert werden sollen. So wird sichergestellt, dass sich die Suchmaschinen auf das Crawlen der Seiten konzentrieren, die dir am wichtigsten sind.
- Optimierung der Serverauslastung durch Blockieren von Bots, die Ressourcen verschwenden.
Robots.txt ist nicht speziell dafür gedacht, zu kontrollieren, welche Seiten von Suchmaschinen indiziert werden
Robots.txt ist keine narrensichere Methode, um zu kontrollieren, welche Seiten von Suchmaschinen indiziert werden. Wenn du in erster Linie verhindern willst, dass bestimmte Seiten in die Suchmaschinenergebnisse aufgenommen werden, solltest du ein Noindex-Tag oder einen Passwortschutz verwenden.
Das liegt daran, dass deine robots.txt den Suchmaschinen nicht direkt sagt, dass sie die Inhalte nicht indizieren sollen – sie sagt ihnen nur, dass sie sie nicht crawlen sollen. Auch wenn Google die markierten Bereiche innerhalb deiner Website nicht crawlen wird, gibt Google selbst an, dass Google diese Seite trotzdem indexieren kann, wenn eine externe Website auf eine Seite verlinkt, die du mit deiner robots.txt-Datei ausgeschlossen hast.
John Mueller, ein Google Webmaster Analyst, hat ebenfalls bestätigt, dass eine Seite, auf die Links verweisen, auch dann indexiert werden kann, wenn sie durch die robots.txt-Datei blockiert ist. Im Folgenden findest du, was er in einem Webmaster Central Hangout zu sagen hatte:
Wenn diese Seiten durch robots.txt blockiert sind, könnte es theoretisch passieren, dass jemand zufällig auf eine dieser Seiten verlinkt. Und dann könnte es passieren, dass wir diese URL ohne Inhalt indexieren, weil sie durch robots.txt blockiert ist. Wir wüssten also nicht, dass du nicht willst, dass diese Seiten indexiert werden.
Wenn sie aber nicht durch robots.txt blockiert sind, kannst du ein noindex-Meta-Tag auf diese Seiten setzen. Und wenn jemand zufällig auf diese Seiten verlinkt und wir diesen Link crawlen und denken, dass es hier vielleicht etwas Nützliches gibt, dann wissen wir, dass diese Seiten nicht indiziert werden müssen und können sie einfach komplett aus der Indizierung herausnehmen.
Wenn du also etwas auf diesen Seiten hast, das nicht indiziert werden soll, dann verbiete es nicht, sondern benutze stattdessen noindex.
Brauche ich eine robots.txt-Datei?
Es ist wichtig, daran zu denken, dass du keine robots.txt-Datei auf deiner Website haben musst. Wenn du kein Problem damit hast, dass alle Bots alle deine Seiten crawlen können, brauchst du keine robots.txt-Datei hinzuzufügen, da du den Crawlern keine wirklichen Anweisungen geben musst.
In manchen Fällen kannst du aufgrund von Beschränkungen des von dir verwendeten CMS nicht einmal eine robots.txt-Datei hinzufügen. Das ist in Ordnung und es gibt andere Methoden, um den Bots mitzuteilen, wie sie deine Seiten crawlen sollen, ohne eine robots.txt-Datei zu verwenden.
Welcher HTTP-Statuscode sollte für die robots.txt-Datei zurückgegeben werden?
Die robots.txt-Datei muss einen 200 OK HTTP-Statuscode zurückgeben, damit Crawler auf sie zugreifen können.
Wenn du Probleme mit der Indizierung deiner Seiten durch Suchmaschinen hast, solltest du den Statuscode deiner robots.txt-Datei überprüfen. Alles andere als ein 200-Statuscode könnte Crawler daran hindern, auf deine Seite zuzugreifen.
Einige Website-Betreiber haben berichtet, dass Seiten deindexiert wurden, weil ihre robots.txt-Datei einen Statuscode ungleich 200 zurückgegeben hat. Ein Website-Begtreiber fragte im März 2022 in einer Google SEO-Sprechstunde nach einem Indexierungsproblem und John Mueller erklärte, dass die robots.txt-Datei entweder einen 200-Status zurückgeben sollte, wenn sie vorhanden ist, oder einen 4XX-Status, wenn die Datei nicht existiert. In diesem Fall wurde ein interner Serverfehler 500 zurückgegeben, was laut Mueller dazu geführt haben könnte, dass Googlebot die Seite von der Indexierung ausgeschlossen hat.
Dasselbe kann man in diesem Tweet sehen, in dem ein Website-Betreiber berichtet, dass seine gesamte Website deindexiert wurde, weil eine robots.txt-Datei einen 500-Fehler zurückgab.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
Kann der Robots-Meta-Tag anstelle einer robots.txt-Datei verwendet werden?
Nein. Mit dem Robots-Meta-Tag kannst du steuern, welche Seiten indiziert werden, während du mit der robots.txt-Datei steuern kannst, welche Seiten gecrawlt werden. Bots müssen die Seiten erst crawlen, um die Meta-Tags zu sehen. Deshalb solltest du es vermeiden, sowohl ein disallow- als auch ein noindex-Meta-Tag zu verwenden, da das noindex-Tag nicht erfasst wird.
Wenn du eine Seite von den Suchmaschinen ausschließen willst, ist das noindex-Meta-Tag in der Regel die beste Option.
So erstellst und bearbeitest du deine WordPress robots.txt-Datei
Standardmäßig erstellt WordPress automatisch eine virtuelle robots.txt-Datei für deine Website. Auch wenn du keinen Finger rührst, sollte deine Website bereits über die Standard robots.txt-Datei verfügen. Du kannst testen, ob dies der Fall ist, indem du „/robots.txt“ an das Ende deines Domainnamens anhängst. Zum Beispiel: „https://kinsta.com/robots.txt“ ruft die robots.txt-Datei auf, die wir hier bei Kinsta verwenden.
Beispiel für eine robots.txt-Datei
Hier ist ein Beispiel für die robots.txt-Datei von Kinsta:
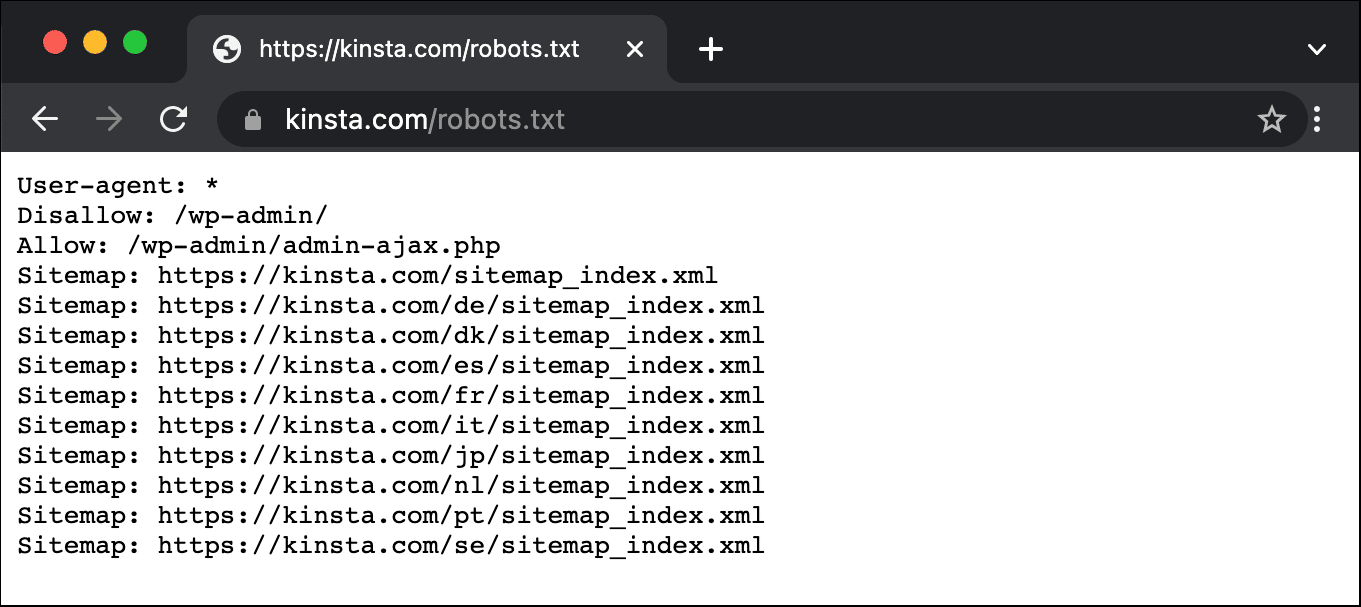
Sie gibt allen Bots Anweisungen, welche Pfade sie ignorieren sollen (z.B. den wp-admin-Pfad) und welche Ausnahmen es gibt (z.B. die Datei admin-ajax.php), sowie die Standorte der XML-Sitemap von Kinsta.
Da diese Datei jedoch virtuell ist, kannst du sie nicht bearbeiten. Wenn du deine robots.txt-Datei bearbeiten willst, musst du eine physische Datei auf deinem Server erstellen, die du nach Bedarf bearbeiten kannst. Hier sind drei einfache Methoden, um das zu tun:
So erstellst und bearbeitest du eine robots.txt-Datei in WordPress mit Yoast SEO
Wenn du das beliebte Yoast SEO-Plugin verwendest, kannst du deine robots.txt-Datei direkt in der Yoast-Oberfläche erstellen (und später bearbeiten). Bevor du jedoch darauf zugreifen kannst, musst du auf SEO → Tools gehen und auf File editor klicken.
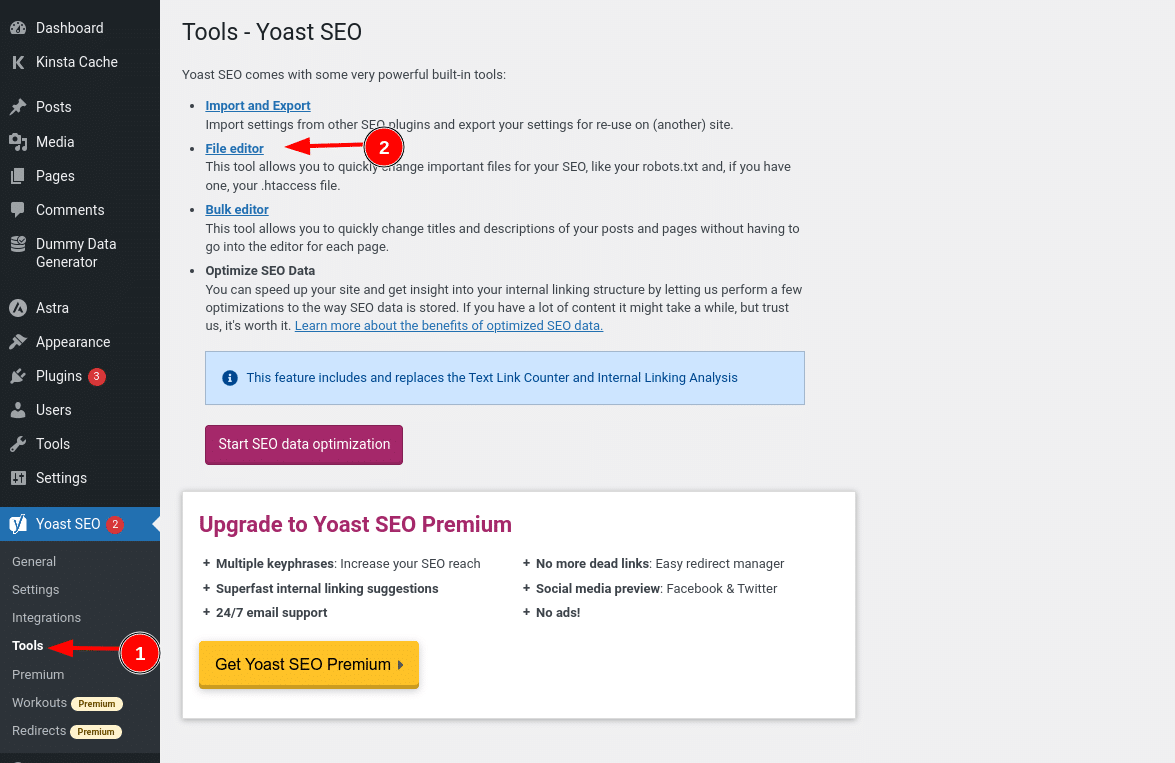
Sobald du auf diese Schaltfläche klickst, kannst du den Inhalt deiner robots.txt-Datei direkt in der Benutzeroberfläche bearbeiten und alle Änderungen speichern.
Wenn du noch keine physische robots.txt-Datei hast, bietet dir Yoast die Möglichkeit, eine robots.txt-Datei zu erstellen:
Wenn du weiterliest, erfahren wir mehr darüber, welche Arten von Direktiven du in deine WordPress robots.txt-Datei aufnehmen solltest.
So erstellst und bearbeitest du eine robots.txt-Datei mit All in One SEO
Wenn du das fast genau so beliebte Plugin All in One SEO Pack verwendest, kannst du deine WordPress robots.txt-Datei auch direkt über die Oberfläche des Plugins erstellen und bearbeiten. Dazu musst du nur zu All in One SEO → Tools gehen:
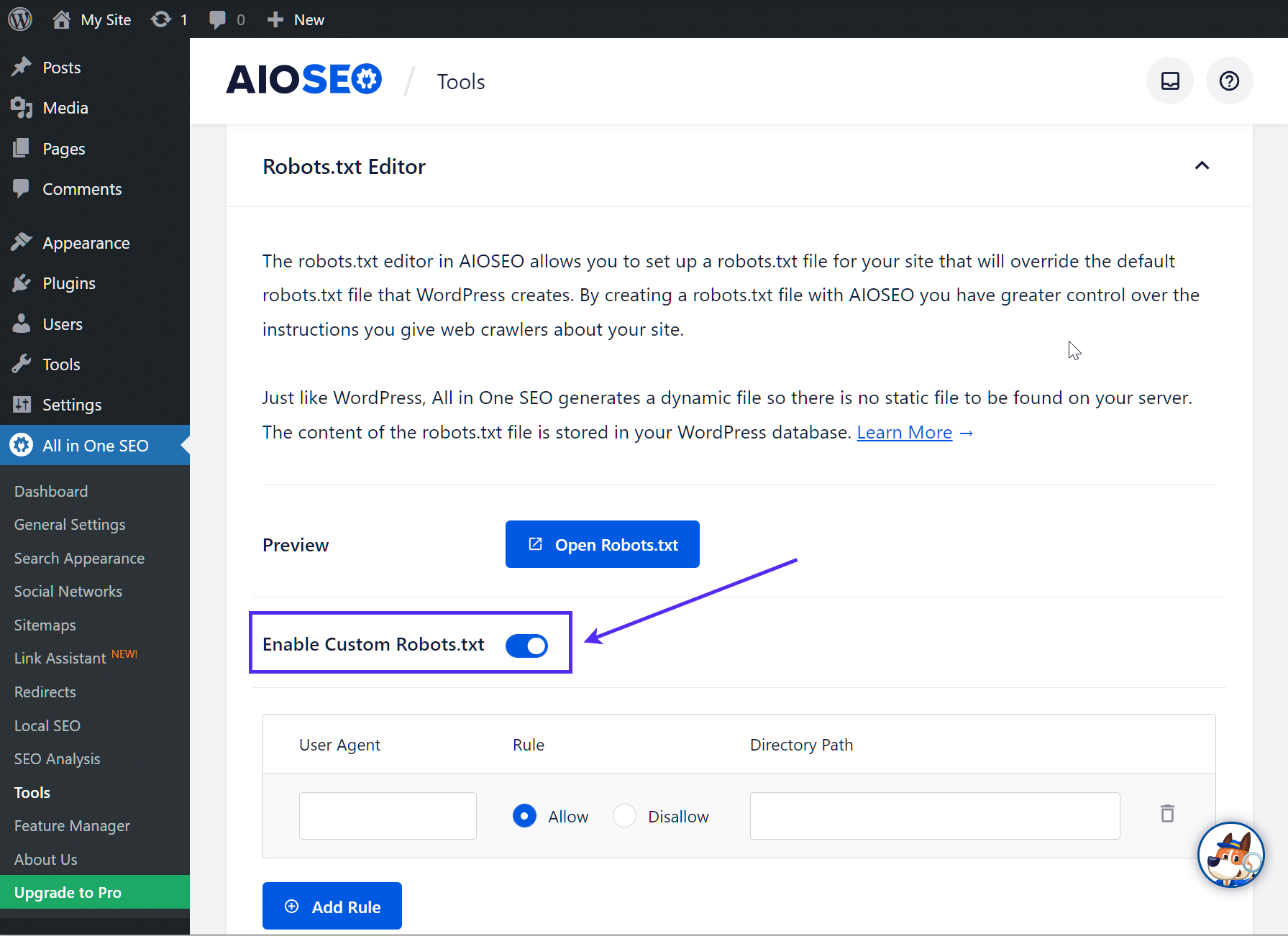
Aktiviere dann das Optionsfeld Benutzerdefinierte robots.txt aktivieren, damit es eingeschaltet ist. So kannst du benutzerdefinierte Regeln erstellen und sie zu deiner robots.txt-Datei hinzufügen:
So erstellst und bearbeitest du eine robots.txt-Datei per FTP
Wenn du kein SEO-Plugin verwendest, das die robots.txt-Funktionalität bietet, kannst du deine robots.txt-Datei auch per SFTP erstellen und verwalten. Verwende zunächst einen beliebigen Texteditor, um eine leere Datei namens „robots.txt“ zu erstellen:
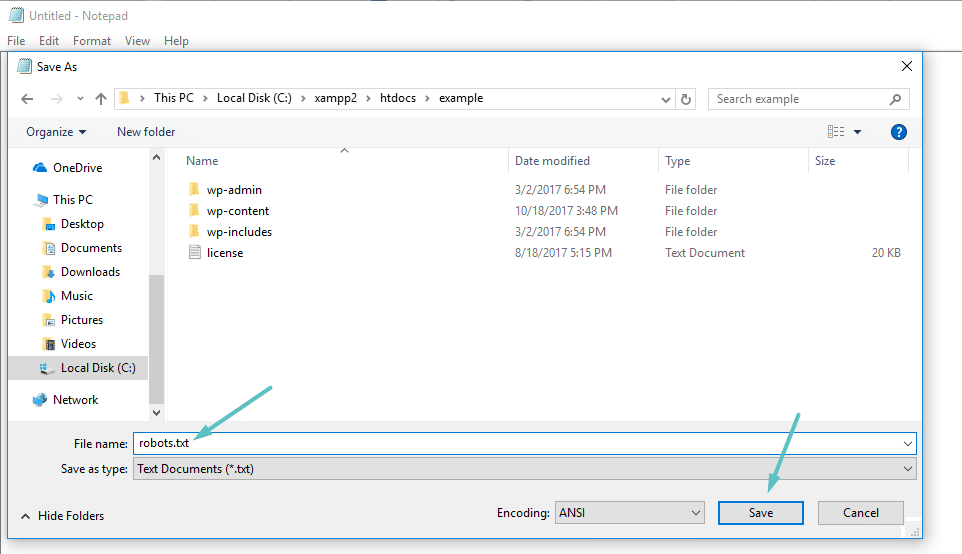
Verbinde dich dann über SFTP mit deiner Website und lade diese Datei in den Stammordner deiner Website hoch. Du kannst weitere Änderungen an deiner robots.txt-Datei vornehmen, indem du sie per SFTP bearbeitest oder neue Versionen der Datei hochlädst.
Was du in deine robots.txt-Datei schreiben solltest
Ok, jetzt hast du eine physische robots.txt-Datei auf deinem Server, die du nach Bedarf bearbeiten kannst. Aber was tust du eigentlich mit dieser Datei? Wie du im ersten Abschnitt gelernt hast, kannst du mit der robots.txt-Datei steuern, wie Robots mit deiner Website interagieren. Das machst du mit zwei zentralen Befehlen:
- User-Agent – damit kannst du bestimmte Bots ansprechen. über User-Agents identifizieren sich Bots. Mit ihnen kannst du zum Beispiel eine Regel erstellen, die für Bing gilt, aber nicht für Google.
- Disallow – Damit kannst du Bots den Zugriff auf bestimmte Bereiche deiner Website verbieten.
Es gibt auch einen Allow-Befehl , den du in Nischensituationen verwenden wirst. Standardmäßig ist alles auf deiner Website mit Allow markiert, daher ist es in 99 % der Fälle nicht notwendig, den Allow-Befehl zu verwenden. Er ist jedoch nützlich, wenn du den Zugriff auf einen Ordner und seine Unterordner verbieten, aber den Zugriff auf einen bestimmten Unterordner zulassen willst.
Du fügst Regeln hinzu, indem du zuerst angibst, für welchen User-Agent die Regel gelten soll, und dann auflistest, welche Regeln mit Disallow und Allow angewendet werden sollen. Es gibt auch einige andere Befehle wie Crawl-delay und Sitemap, aber diese sind entweder:
- Von den meisten großen Crawlern ignoriert oder auf sehr unterschiedliche Weise interpretiert (im Fall von Crawl delay)
- Sie werden von Tools wie Google Search Console überflüssig gemacht (für Sitemaps)
Gehen wir einige konkrete Anwendungsfälle durch, um dir zu zeigen, wie das alles zusammenhängt.
Wie du Robots.txt Disallow All verwendest, um den Zugriff auf deine gesamte Website zu sperren
Nehmen wir an, du möchtest den Zugriff von Crawlern auf deine Website komplett unterbinden. Auf einer Live-Site ist das eher unwahrscheinlich, aber für eine Entwicklungsseite ist es sehr nützlich. Dazu fügst du den Code robots.txt disallow all zu deiner WordPress robots.txt-Datei hinzu:
User-agent: *
Disallow: /Was passiert in diesem Code?
Das *Sternchen neben User-agent bedeutet „alle User-Agents“. Das Sternchen ist ein Platzhalter, das heißt, es gilt für jeden einzelnen User-Agent. Der /slash neben Disallow bedeutet, dass du den Zugriff auf alle Seiten, die „yourdomain.com/“ enthalten (d.h. alle Seiten deiner Website), verbieten willst.
Wie man Robots.txt verwendet, um einem einzelnen Bot den Zugriff auf deine Website zu verweigern
Ändern wir die Situation. In diesem Beispiel nehmen wir an, es gefällt dir nicht, dass Bing deine Seiten crawlt. Du bist ganz auf Google eingestellt und willst nicht einmal, dass Bing sich deine Seite ansieht. Um zu verhindern, dass nur Bing deine Seite crawlt, würdest du den Platzhalter *asterisk durch Bingbot ersetzen :
User-agent: Bingbot
Disallow: /Im Wesentlichen besagt der obige Code, dass die Disallow-Regel nur auf Bots mit dem User-Agent „Bingbot“ angewendet werden soll. Es ist zwar unwahrscheinlich, dass du den Zugriff auf Bing blockieren willst, aber dieses Szenario ist sehr nützlich, wenn es einen bestimmten Bot gibt, der nicht auf deine Website zugreifen soll. Auf dieser Seite findest du eine hilfreiche Liste mit den Namen der meisten bekannten User-Agents.
Wie man Robots.txt verwendet, um den Zugriff auf einen bestimmten Ordner oder eine Datei zu blockieren
Nehmen wir an, du möchtest nur den Zugriff auf eine bestimmte Datei oder einen bestimmten Ordner (und alle Unterordner dieses Ordners) sperren. Um dies auf WordPress anzuwenden, nimm an, du möchtest den Zugriff sperren auf:
- Den gesamten wp-admin Ordner.
- wp-login.php.
Du könntest die folgenden Befehle verwenden:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpSo verwendest du Robots.txt Allow All, um Bots vollen Zugriff auf deine Website zu geben
Wenn du derzeit keinen Grund hast, Crawlern den Zugriff auf deine Seiten zu verweigern, kannst du den folgenden Befehl hinzufügen.
User-agent: *
Allow: /
Oder alternativ:
User-agent: *
Disallow:
Wie man Robots.txt verwendet, um den Zugriff auf eine bestimmte Datei in einem gesperrten Ordner zu erlauben
Angenommen, du willst einen ganzen Ordner sperren, aber trotzdem den Zugriff auf eine bestimmte Datei in diesem Ordner erlauben. Hier kommt der Befehl Zulassen ins Spiel. Und er ist sogar sehr gut auf WordPress anwendbar. Die virtuelle robots.txt-Datei von WordPress veranschaulicht dieses Beispiel sogar perfekt:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpDieses Snippet blockiert den Zugriff auf den gesamten Ordner /wp-admin/ mit Ausnahme der Datei /wp-admin/admin-ajax.php.
Wie du Robots.txt verwendest, um zu verhindern, dass Bots die WordPress-Suchergebnisse crawlen
Eine WordPress-spezifische Anpassung, die du vornehmen solltest, ist es zu verhindern, dass Suchcrawler deine Suchergebnisseiten crawlen. WordPress verwendet standardmäßig den Abfrageparameter „?s=“. Um den Zugriff zu blockieren, musst du nur die folgende Regel hinzufügen:
User-agent: *
Disallow: /?s=
Disallow: /search/Dies kann ein effektiver Weg sein, um auch softe 404-Fehler zu verhindern, falls du sie bekommst. Lies unbedingt unsere ausführliche Anleitung, wie du die WordPress-Suche beschleunigen kannst.
Wie man verschiedene Regeln für verschiedene Bots in der Robots.txt erstellt
Bis jetzt haben sich alle Beispiele mit jeweils einer Regel befasst. Aber was ist, wenn du verschiedene Regeln auf verschiedene Bots anwenden willst? Dann musst du einfach die Regeln unter der User-Agent-Deklaration für jeden Bot hinzufügen. Wenn du zum Beispiel eine Regel für alle Bots und eine andere für Bingbot erstellen willst, kannst du das so machen:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /In diesem Beispiel wird allen Bots der Zugriff auf /wp-admin/ verwehrt, aber Bingbot wird der Zugriff auf deine gesamte Website verwehrt.
Testen deiner Robots.txt-Datei
Um sicherzustellen, dass deine robots.txt-Datei korrekt eingerichtet wurde und wie erwartet funktioniert, solltest du sie gründlich testen. Ein einziges falsches Zeichen kann sich katastrophal auf die Leistung einer Website in den Suchmaschinen auswirken, daher kann ein Test helfen, mögliche Probleme zu vermeiden.
Der robots.txt-Tester von Google
Das Tool robots.txt Tester von Google (früher Teil der Google Search Console) ist einfach zu bedienen und zeigt dir mögliche Probleme in deiner robots.txt-Datei auf.
Navigiere einfach zum Tool und wähle die Eigenschaft der Website aus, die du testen möchtest. Scrolle dann zum Ende der Seite und gib eine beliebige URL in das Feld ein und klicke auf die rote Schaltfläche TEST:
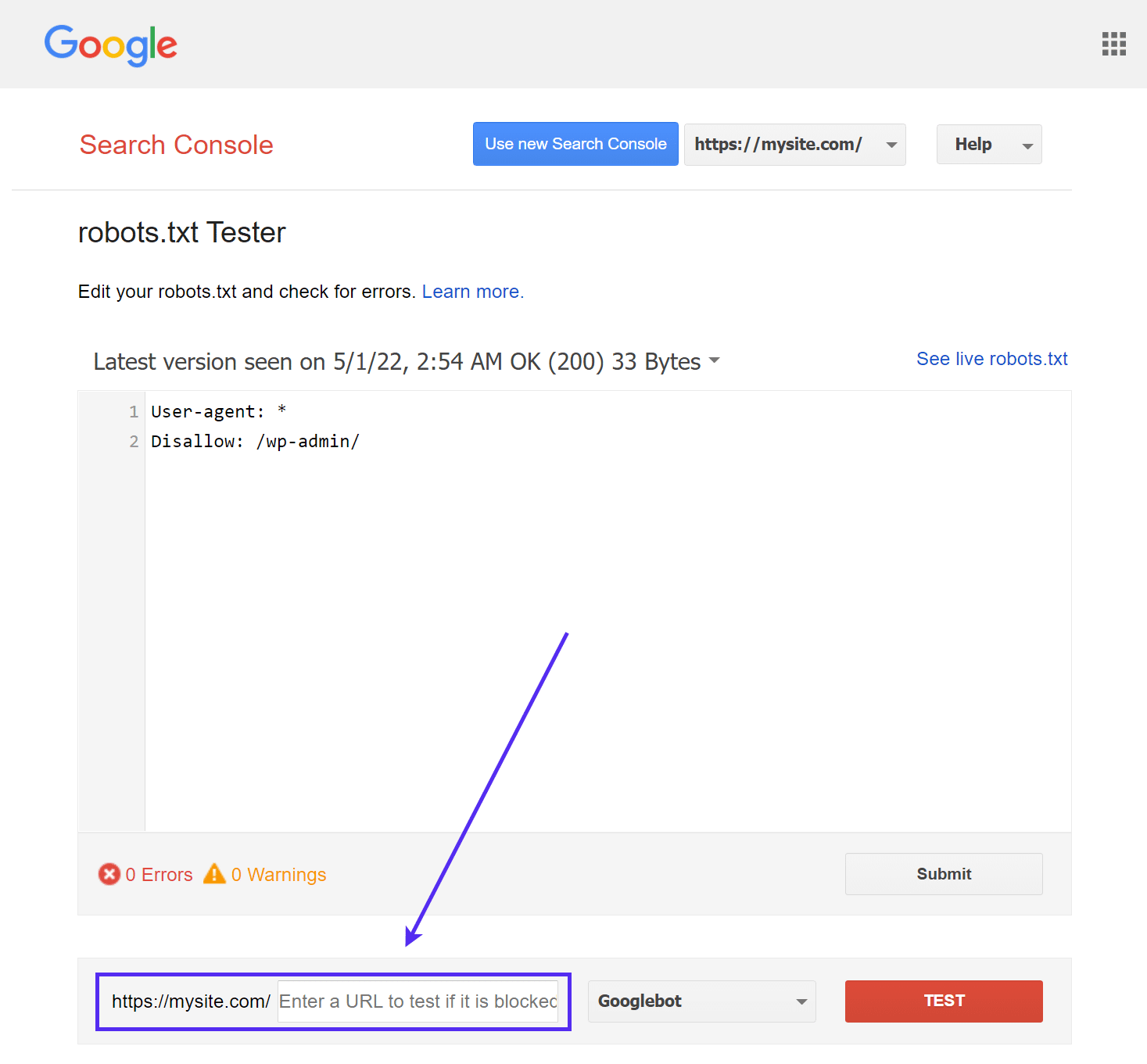
Wenn alles gecrawlt werden kann, siehst du eine grüne Antwort „Allowed„.
Du kannst auch auswählen, mit welcher Version von Googlebot du den Test durchführen möchtest. Zur Auswahl stehen Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartner-Google oder Adsbot-Google.
Du kannst auch jede einzelne URL, die du blockiert hast, testen, um sicherzustellen, dass sie tatsächlich blockiert und/oder nicht zugelassen ist.
Hüte dich vor dem UTF-8 BOM
BOM steht für Byte Order Mark und ist im Grunde ein unsichtbares Zeichen, das manchmal von alten Texteditoren und Ähnlichem in Dateien eingefügt wird. Wenn dies mit deiner robots.txt-Datei passiert, kann Google sie möglicherweise nicht richtig lesen. Deshalb ist es wichtig, dass du deine Datei auf Fehler überprüfst. Wie unten zu sehen, hatte unsere Datei zum Beispiel ein unsichtbares Zeichen und Google beschwert sich, dass die Syntax nicht verstanden wurde. Dadurch wird die erste Zeile unserer robots.txt-Datei komplett ungültig, was nicht gut ist! Glenn Gabe hat einen ausgezeichneten Artikel darüber geschrieben, wie eine UTF-8 Bombe dein SEO ruinieren kann.

Googlebot ist meist in den USA ansässig
Es ist auch wichtig, den Googlebot aus den Vereinigten Staaten nicht zu blockieren, selbst wenn du auf eine lokale Region außerhalb der Vereinigten Staaten abzielst. Manchmal wird zwar auch lokal gecrawlt, aber der Googlebot ist hauptsächlich in den USA ansässig.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
Was beliebte WordPress-Seiten in ihre Robots.txt-Datei schreiben
Um die oben genannten Punkte zu verdeutlichen, zeigen wir dir hier, wie einige der beliebtesten WordPress-Websites ihre robots.txt-Dateien verwenden.
TechCrunch
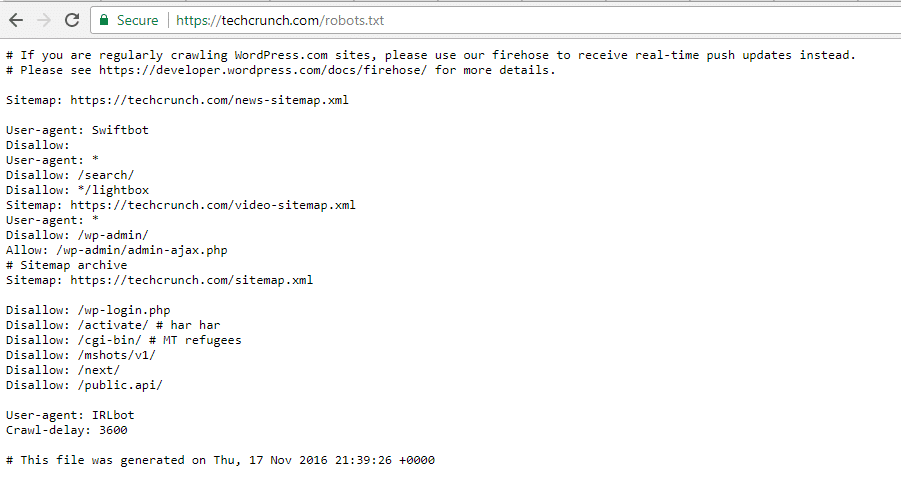
TechCrunch schränkt nicht nur den Zugriff auf eine Reihe von Seiten ein, sondern verbietet den Crawlern vor allem Folgendes
- /wp-admin/
- /wp-login.php
Auch für zwei Bots wurden besondere Beschränkungen festgelegt:
- Swiftbot
- IRLbot
Falls es dich interessiert: IRLbot ist ein Crawler aus einem Forschungsprojekt der Texas A&M University. Das ist seltsam!
Die Obama-Stiftung
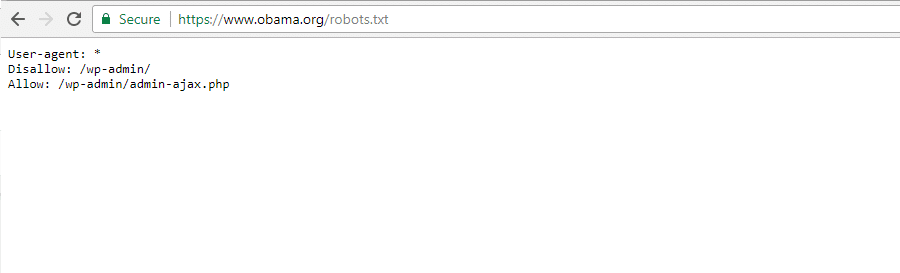
Die Obama-Stiftung hat keine besonderen Ergänzungen vorgenommen und sich dafür entschieden, nur den Zugriff auf /wp-admin/ zu beschränken.
Angry Birds
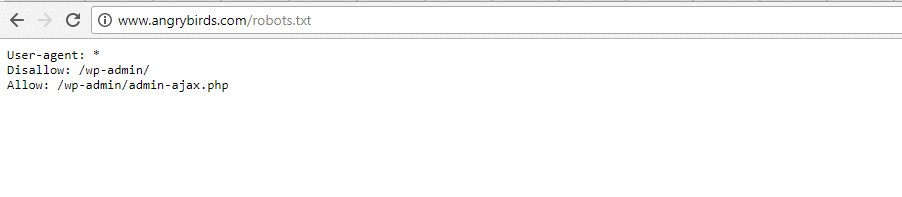
Angry Birds hat die gleichen Standardeinstellungen wie die Obama-Stiftung. Es wurde nichts Besonderes hinzugefügt.
Drift

Drift schließlich entscheidet sich dafür, seine Sitemaps in der Datei Robots.txt zu definieren, belässt aber ansonsten die gleichen Standardeinstellungen wie The Obama Foundation und Angry Birds.
Die Robots.txt richtig nutzen
Zum Abschluss unseres robots.txt-Leitfadens möchten wir dich noch einmal daran erinnern, dass die Verwendung eines Disallow-Befehls in deiner robots.txt-Datei nicht dasselbe ist wie die Verwendung eines noindex-Tags . Robots.txt blockiert das Crawlen, aber nicht unbedingt das Indexieren. Du kannst damit bestimmte Regeln hinzufügen, um zu bestimmen, wie Suchmaschinen und andere Bots mit deiner Website interagieren, aber es wird nicht explizit kontrolliert, ob deine Inhalte indexiert werden oder nicht.
Für die meisten WordPress-Nutzer ist es nicht dringend notwendig, die standardmäßige virtuelle robots.txt-Datei zu ändern. Wenn du aber Probleme mit einem bestimmten Bot hast oder ändern willst, wie Suchmaschinen mit einem bestimmten Plugin oder Theme interagieren, solltest du deine eigenen Regeln hinzufügen.
Wir hoffen, dass dir dieser Leitfaden gefallen hat. Hinterlasse einen Kommentar, wenn du weitere Fragen zur Verwendung der robots.txt-Datei in WordPress hast.

Brian hat eine große Leidenschaft für WordPress, verwendet es seit über einem Jahrzehnt und entwickelt sogar einige Premium-Plugins. Brian liebt Blogging, Filme und Wandern. Verbinde dich mit Brian auf Twitter.

