
Si vous gérez de nombreux sites WordPress, vous êtes probablement toujours à la recherche de moyens pour simplifier et accélérer vos flux de travail.
Maintenant, imaginez ceci : avec une seule commande dans votre terminal, vous pouvez déclencher des sauvegardes manuelles pour tous tes sites, même si vous en gérez des dizaines. C’est la puissance de la combinaison des scripts shell avec l’API de Kinsta.
Ce guide vous apprend à utiliser les scripts shell pour mettre en place des commandes personnalisées qui rendent la gestion de vos sites plus efficace.
Pré-requis
Avant de commencer, voici ce dont vous avez besoin :
- Un terminal : Tous les systèmes d’exploitation modernes sont livrés avec un logiciel de terminal, vous pouvez donc commencer à écrire des scripts dès le début.
- Un IDE ou un éditeur de texte : Utilisez un outil avec lequel vous êtes à l’aise, qu’il s’agisse de VS Code, Sublime Text, ou même d’un éditeur léger comme Nano pour des modifications rapides sur le terminal.
- Une clé API Kinsta : Elle est essentielle pour interagir avec l’API de Kinsta. Pour générer la votre :
- Connectez-vous à votre tableau de bord MyKinsta.
- Allez dans Votre nom > Réglages de l’entreprise > Clés API.
- Cliquez sur Créer une clé API et enregistrez-la en toute sécurité.
curletjq: Indispensables pour effectuer des requêtes d’API et manipuler des données JSON. Vérifiez qu’ils sont installés, ou installez-les.- Connaissance de base de la programmation : Vous n’avez pas besoin d’être un expert, mais comprendre les bases de la programmation et la syntaxe des scripts shell sera utile.
Écrire votre premier script
Créer votre premier script shell pour interagir avec l’API de Kinsta est plus simple que vous ne le pensez. Commençons par un script simple qui répertorie tous les sites WordPress gérés sous votre compte Kinsta.
Étape 1 : Configurer votre environnement
Commencez par créer un dossier pour votre projet et un nouveau fichier de script. L’extension .sh est utilisée pour les scripts shell. Par exemple, vous pouvez créer un dossier, y naviguer, et créer et ouvrir un fichier de script dans VS Code à l’aide de ces commandes :
mkdir my-first-shell-scripts
cd my-first-shell-scripts
touch script.sh
code script.shÉtape 2 : Définir vos variables d’environnement
Pour sécuriser votre clé API, stockez-la dans un fichier .env au lieu de la coder en dur dans le script. Cela vous permet d’ajouter le fichier .env à .gitignore, ce qui l’empêche d’être transféré au contrôle de version.
Dans votre fichier .env, ajoutez :
API_KEY=your_kinsta_api_keyEnsuite, tirez la clé API du fichier .env vers votre script en ajoutant ce qui suit en haut de votre script :
#!/bin/bash
source .envLe shebang #!/bin/bash garantit que le script s’exécute à l’aide de Bash, tandis que source .env importe les variables d’environnement.
Étape 3 : Rédiger la requête API
Tout d’abord, enregistrez l’identifiant de ton entreprise (que vous trouverez dans MyKinsta sous Réglages de l’entreprise > Détails de la facturation) dans une variable :
COMPANY_ID="<your_company_id>"Ensuite, ajoutez la commande curl pour faire une requête GET au point de terminaison /sites, en passant l’ID de l’entreprise comme paramètre de requête. Utilisez jq pour formater la sortie afin qu’elle soit lisible :
curl -s -X GET
"https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json" | jqCette requête récupère les détails de tous les sites associés à votre entreprise, y compris leurs identifiants, leurs noms et leurs états.
Étape 4 : Rendre le script exécutable
Sauvegardez le script et rendez-le exécutable en l’exécutant :
chmod +x script.shÉtape 5 : Exécuter le script
Exécutez le script pour voir une liste formatée de vos sites :
./list_sites.shLorsque vous exécuterez le script, vous obtiendrez une réponse similaire à celle-ci :
{
"company": {
"sites": [
{
"id": "a8f39e7e-d9cf-4bb4-9006-ddeda7d8b3af",
"name": "bitbuckettest",
"display_name": "bitbucket-test",
"status": "live",
"site_labels": []
},
{
"id": "277b92f8-4014-45f7-a4d6-caba8f9f153f",
"name": "duketest",
"display_name": "zivas Signature",
"status": "live",
"site_labels": []
}
]
}
}Bien que cela fonctionne, améliorons-le en mettant en place une fonction pour récupérer et formater les détails du site pour une meilleure lisibilité.
Étape 6 : Refonte avec une fonction
Remplacez la requête curl par une fonction réutilisable qui se chargera de récupérer et de formater la liste des sites :
list_sites() {
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "https://api.kinsta.com/v2/sites?company=$COMPANY_ID"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "Company Sites:"
echo "--------------"
echo "$RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}
# Run the function
list_sitesLorsque vous exécuterez à nouveau le script, vous obtiendrez une sortie bien formatée :
Fetching all sites for company ID: b383b4c-****-****-a47f-83999c5d2...
Company Sites:
--------------
bitbucket-test (bitbuckettest) - Status: live
zivas Signature (duketest) - Status: liveAvec ce script, vous avez fait un premier pas vers l’utilisation de scripts shell et de l’API Kinsta pour automatiser la gestion de votre site WordPress. Dans les sections suivantes, nous explorerons la création de scripts plus avancés pour interagir avec l’API de manière puissante.
Cas d’utilisation avancé 1 : Création de sauvegardes
La création de sauvegardes est un aspect crucial de la gestion d’un site web. Elles vous permettent de restaurer votre site en cas de problèmes imprévus. Grâce à l’API Kinsta et aux scripts shell, ce processus peut être automatisé, ce qui permet d’économiser du temps et des efforts.
Dans cette section, nous créons des sauvegardes et abordons la limite de cinq sauvegardes manuelles par environnement imposée par Kinsta. Pour cela, nous mettrons en place un processus pour :
- Vérifier le nombre actuel de sauvegardes manuelles.
- Identifier et supprimer la sauvegarde la plus ancienne (avec la confirmation de l’utilisateur) si la limite est atteinte.
- Procéder à la création d’une nouvelle sauvegarde.
Entrons dans les détails.
Le flux de travail des sauvegardes
Pour créer des sauvegardes à l’aide de l’API Kinsta, vous utiliserez le point de terminaison suivant :
POST /sites/environments/{env_id}/manual-backupsCela nécessite :
- ID de l’environnement : Identifiez l’environnement (comme le stzaging ou la production) dans lequel la sauvegarde sera créée.
- Libellé de sauvegarde : Un libellé pour identifier la sauvegarde (facultatif).
Récupérer manuellement l’identifiant de l’environnement et exécuter une commande telle que backup <environment ID> peut s’avérer fastidieux. Au lieu de cela, nous allons créer un script convivial dans lequel vous n’aurez qu’à spécifier le nom du site, et le script :
- Récupèrera la liste des environnements pour le site.
- Vous invitera à choisir l’environnement à sauvegarder.
- Gérera le processus de création de la sauvegarde.
Des fonctions réutilisables pour un code propre
Pour que notre script reste modulaire et réutilisable, nous allons définir des fonctions pour des tâches spécifiques. Passons en revue la configuration étape par étape.
1. Configurer les variables de base
Vous pouvez vous débarrasser du premier script que vous avez créé ou créer un nouveau fichier de script pour cela. Commencez par déclarer l’URL de base de l’API Kinsta et l’identifiant de votre entreprise dans le script :
BASE_URL="https://api.kinsta.com/v2"
COMPANY_ID="<your_company_id>"Ces variables vous permettent de construire des points d’accès à l’API de façon dynamique tout au long du script.
2. Récupérer tous les sites
Définissez une fonction pour récupérer la liste de tous les sites de l’entreprise. Cela vous permet de récupérer ultérieurement les détails de chaque site.
get_sites_list() {
API_URL="$BASE_URL/sites?company=$COMPANY_ID"
echo "Fetching all sites for company ID: $COMPANY_ID..."
RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
# Check for errors
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API."
exit 1
fi
echo "$RESPONSE"
}Vous remarquerez que cette fonction renvoie une réponse non formatée de l’API. Pour obtenir une réponse formatée. Vous pouvez ajouter une autre fonction pour gérer cela (bien que ce ne soit pas notre préoccupation dans cette section) :
list_sites() {
RESPONSE=$(get_sites_list)
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while fetching sites."
exit 1
fi
echo "Company Sites:"
echo "--------------"
# Clean the RESPONSE before passing it to jq
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//') # Removes extra characters before the JSON starts
echo "$CLEAN_RESPONSE" | jq -r '.company.sites[] | "(.display_name) ((.name)) - Status: (.status)"'
}L’appel à la fonction list_sites affiche vos sites comme indiqué précédemment. L’objectif principal, cependant, est d’accéder à chaque site et à son identifiant, ce qui vous permet de récupérer des informations détaillées sur chaque site.
3. Récupérer les détails d’un site
Pour obtenir des détails sur un site spécifique, utilisez la fonction suivante, qui récupère l’ID du site en fonction du nom du site et obtient des détails supplémentaires, comme les environnements :
get_site_details_by_name() {
SITE_NAME=$1
if [ -z "$SITE_NAME" ]; then
echo "Error: No site name provided. Usage: $0 details-name "
return 1
fi
RESPONSE=$(get_sites_list)
echo "Searching for site with name: $SITE_NAME..."
# Clean the RESPONSE before parsing
CLEAN_RESPONSE=$(echo "$RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
# Extract the site ID for the given site name
SITE_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg SITE_NAME "$SITE_NAME" '.company.sites[] | select(.name == $SITE_NAME) | .id')
if [ -z "$SITE_ID" ]; then
echo "Error: Site with name "$SITE_NAME" not found."
return 1
fi
echo "Found site ID: $SITE_ID for site name: $SITE_NAME"
# Fetch site details using the site ID
API_URL="$BASE_URL/sites/$SITE_ID"
SITE_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "$SITE_RESPONSE"
}La fonction ci-dessus filtre le site à l’aide du nom du site, puis récupère des détails supplémentaires sur le site à l’aide du point de terminaison /sites/<site-id>. Ces détails incluent les environnements du site, ce dont nous avons besoin pour déclencher des sauvegardes.
Création de sauvegardes
Maintenant que vous avez mis en place des fonctions réutilisables pour récupérer les détails du site et lister les environnements, vous pouvez vous concentrer sur l’automatisation du processus de création des sauvegardes. L’objectif est d’exécuter une simple commande avec seulement le nom du site, puis de choisir de manière interactive l’environnement à sauvegarder.
Commencez par créer une fonction (nous l’appellerons trigger_manual_backup). À l’intérieur de la fonction, définissez deux variables : la première pour accepter le nom du site en entrée et la seconde pour définir une étiquette par défaut (default-backup) pour la sauvegarde. Cette étiquette par défaut sera appliquée à moins que vous ne choisissiez de spécifier une étiquette personnalisée plus tard.
trigger_manual_backup() {
SITE_NAME=$1
DEFAULT_TAG="default-backup"
# Ensure a site name is provided
if [ -z "$SITE_NAME" ]; then
echo "Error: Site name is required."
echo "Usage: $0 trigger-backup "
return 1
fi
# Add the code here
}Ce SITE_NAME est l’identifiant du site que vous voulez gérer. Vous définissez également une condition pour que le script se termine par un message d’erreur si l’identifiant n’est pas fourni. Cela permet de s’assurer que le script n’est pas exécuté sans les données nécessaires, ce qui permet d’éviter les erreurs potentielles de l’API.
Ensuite, vous utilisez la fonction réutilisable get_site_details_by_name pour obtenir des informations détaillées sur le site, y compris ses environnements. La réponse est ensuite nettoyée pour supprimer tout problème de formatage inattendu qui pourrait survenir pendant le traitement.
SITE_RESPONSE=$(get_site_details_by_name "$SITE_NAME")
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch site details for site "$SITE_NAME"."
return 1
fi
CLEAN_RESPONSE=$(echo "$SITE_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Une fois que nous avons les détails du site, le script ci-dessous extrait tous les environnements disponibles et les affiche dans un format lisible. Cela t’aide à visualiser quels environnements sont liés au site.
Le script vous invite ensuite à sélectionner un environnement par son nom. Cette étape interactive rend le processus plus convivial en éliminant la nécessité de se souvenir ou de saisir les identifiants des environnements.
ENVIRONMENTS=$(echo "$CLEAN_RESPONSE" | jq -r '.site.environments[] | "(.name): (.id)"')
echo "Available Environments for "$SITE_NAME":"
echo "$ENVIRONMENTS"
read -p "Enter the environment name to back up (e.g., staging, live): " ENV_NAMELe nom de l’environnement sélectionné est ensuite utilisé pour rechercher l’identifiant de l’environnement correspondant dans les détails du site. Cet identifiant est nécessaire pour les demandes d’API visant à créer une sauvegarde.
ENV_ID=$(echo "$CLEAN_RESPONSE" | jq -r --arg ENV_NAME "$ENV_NAME" '.site.environments[] | select(.name == $ENV_NAME) | .id')
if [ -z "$ENV_ID" ]; then
echo "Error: Environment "$ENV_NAME" not found for site "$SITE_NAME"."
return 1
fi
echo "Found environment ID: $ENV_ID for environment name: $ENV_NAME"Dans le code ci-dessus, une condition est créée pour que le script sorte avec un message d’erreur si le nom d’environnement fourni ne correspond pas.
Maintenant que vous avez l’ID de l’environnement, vous pouvez procéder à la vérification du nombre actuel de sauvegardes manuelles pour l’environnement sélectionné. La limite de Kinsta étant de cinq sauvegardes manuelles par environnement, cette étape est cruciale pour éviter les erreurs.
Commençons par récupérer la liste des sauvegardes à l’aide du point de terminaison de l’API /backups API.
API_URL="$BASE_URL/sites/environments/$ENV_ID/backups"
BACKUPS_RESPONSE=$(curl -s -X GET "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_RESPONSE=$(echo "$BACKUPS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')
MANUAL_BACKUPS=$(echo "$CLEAN_RESPONSE" | jq '[.environment.backups[] | select(.type == "manual")]')
BACKUP_COUNT=$(echo "$MANUAL_BACKUPS" | jq 'length')Le script ci-dessus filtre ensuite les sauvegardes manuelles et les compte. Si le décompte atteint la limite, nous devons gérer les sauvegardes existantes :
if [ "$BACKUP_COUNT" -ge 5 ]; then
echo "Manual backup limit reached (5 backups)."
# Find the oldest backup
OLDEST_BACKUP=$(echo "$MANUAL_BACKUPS" | jq -r 'sort_by(.created_at) | .[0]')
OLDEST_BACKUP_NAME=$(echo "$OLDEST_BACKUP" | jq -r '.note')
OLDEST_BACKUP_ID=$(echo "$OLDEST_BACKUP" | jq -r '.id')
echo "The oldest manual backup is "$OLDEST_BACKUP_NAME"."
read -p "Do you want to delete this backup to create a new one? (yes/no): " CONFIRM
if [ "$CONFIRM" != "yes" ]; then
echo "Aborting backup creation."
return 1
fi
# Delete the oldest backup
DELETE_URL="$BASE_URL/sites/environments/backups/$OLDEST_BACKUP_ID"
DELETE_RESPONSE=$(curl -s -X DELETE "$DELETE_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
echo "Delete Response:"
echo "$DELETE_RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'
fiLa condition ci-dessus identifie la sauvegarde la plus ancienne en triant la liste en fonction de l’horodatage created_at. Elle vous demande ensuite de confirmer si vous souhaitez la supprimer.
Si vous acceptez, le script supprime la sauvegarde la plus ancienne en utilisant son ID, libérant ainsi de l’espace pour la nouvelle sauvegarde. Cela permet de s’assurer que les sauvegardes peuvent toujours être créées sans avoir à gérer manuellement les limites.
Maintenant qu’il y a de l’espace, passons au code pour déclencher la sauvegarde de l’environnement. N’hésitez pas à ignorer ce code, mais pour une meilleure expérience, il t’invite à spécifier une étiquette personnalisée, avec par défaut « default-backup » si aucune n’est fournie.
read -p "Enter a backup tag (or press Enter to use "$DEFAULT_TAG"): " BACKUP_TAG
if [ -z "$BACKUP_TAG" ]; then
BACKUP_TAG="$DEFAULT_TAG"
fi
echo "Using backup tag: $BACKUP_TAG"Enfin, c’est dans le script ci-dessous que se produit l’action de sauvegarde. Il envoie une requête POST au point de terminaison /manual-backups avec l’identifiant d’environnement et la balise de sauvegarde sélectionnés. Si la demande aboutit, l’API renvoie une réponse confirmant la création de la sauvegarde.
API_URL="$BASE_URL/sites/environments/$ENV_ID/manual-backups"
RESPONSE=$(curl -s -X POST "$API_URL"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json"
-d "{"tag": "$BACKUP_TAG"}")
if [ -z "$RESPONSE" ]; then
echo "Error: No response from the API while triggering the manual backup."
return 1
fi
echo "Backup Trigger Response:"
echo "$RESPONSE" | jq -r '[
"Operation ID: (.operation_id)",
"Message: (.message)",
"Status: (.status)"
] | join("n")'Et voilà ! La réponse obtenue à partir de la requête ci-dessus est formatée pour afficher l’ID de l’opération, le message et l’état pour plus de clarté. Si vous appellez la fonction et exécutez le script, vous obtiendrez une sortie similaire à celle-ci :
Available Environments for "example-site":
staging: 12345
live: 67890
Enter the environment name to back up (e.g., staging, live): live
Found environment ID: 67890 for environment name: live
Manual backup limit reached (5 backups).
The oldest manual backup is "staging-backup-2023-12-31".
Do you want to delete this backup to create a new one? (yes/no): yes
Oldest backup deleted.
Enter a backup tag (or press Enter to use "default-backup"): weekly-live-backup
Using backup tag: weekly-live-backup
Triggering manual backup for environment ID: 67890 with tag: weekly-live-backup...
Backup Trigger Response:
Operation ID: backups:add-manual-abc123
Message: Adding a manual backup to environment in progress.
Status: 202Création de commandes pour votre script
Les commandes simplifient l’utilisation de votre script. Au lieu de modifier le script ou de commenter le code manuellement, les utilisateurs peuvent l’exécuter à l’aide d’une commande spécifique comme :
./script.sh list-sites
./script.sh backup À la fin de votre script (en dehors de toutes les fonctions), incluez un bloc conditionnel qui vérifie les arguments passés au script :
if [ "$1" == "list-sites" ]; then
list_sites
elif [ "$1" == "backup" ]; then
SITE_NAME="$2"
if [ -z "$SITE_NAME" ]; then
echo "Usage: $0 trigger-backup "
exit 1
fi
trigger_manual_backup "$SITE_NAME"
else
echo "Usage: $0 {list-sites|trigger-backup }"
exit 1
fiLa variable $1 représente le premier argument passé au script (par exemple, dans ./script.sh list-sites, $1 est list-sites). Le script utilise des contrôles conditionnels pour faire correspondre $1 à des commandes spécifiques telles que list-sites ou backup. Si la commande est backup, il attend également un deuxième argument ($2), qui est le nom du site. Si aucune commande valide n’est fournie, le script affiche par défaut les instructions d’utilisation.
Vous pouvez maintenant déclencher une sauvegarde manuelle pour un site spécifique en exécutant la commande :
./script.sh backupCas d’utilisation avancé 2 : Mise à jour des plugins sur plusieurs sites
La gestion des extensions WordPress sur plusieurs sites peut être fastidieuse, surtout lorsque des mises à jour sont disponibles. Kinsta fait un excellent travail pour gérer cela via le tableau de bord MyKinsta, grâce à la fonctionnalité d’actions groupées que nous avons introduite l’année dernière.
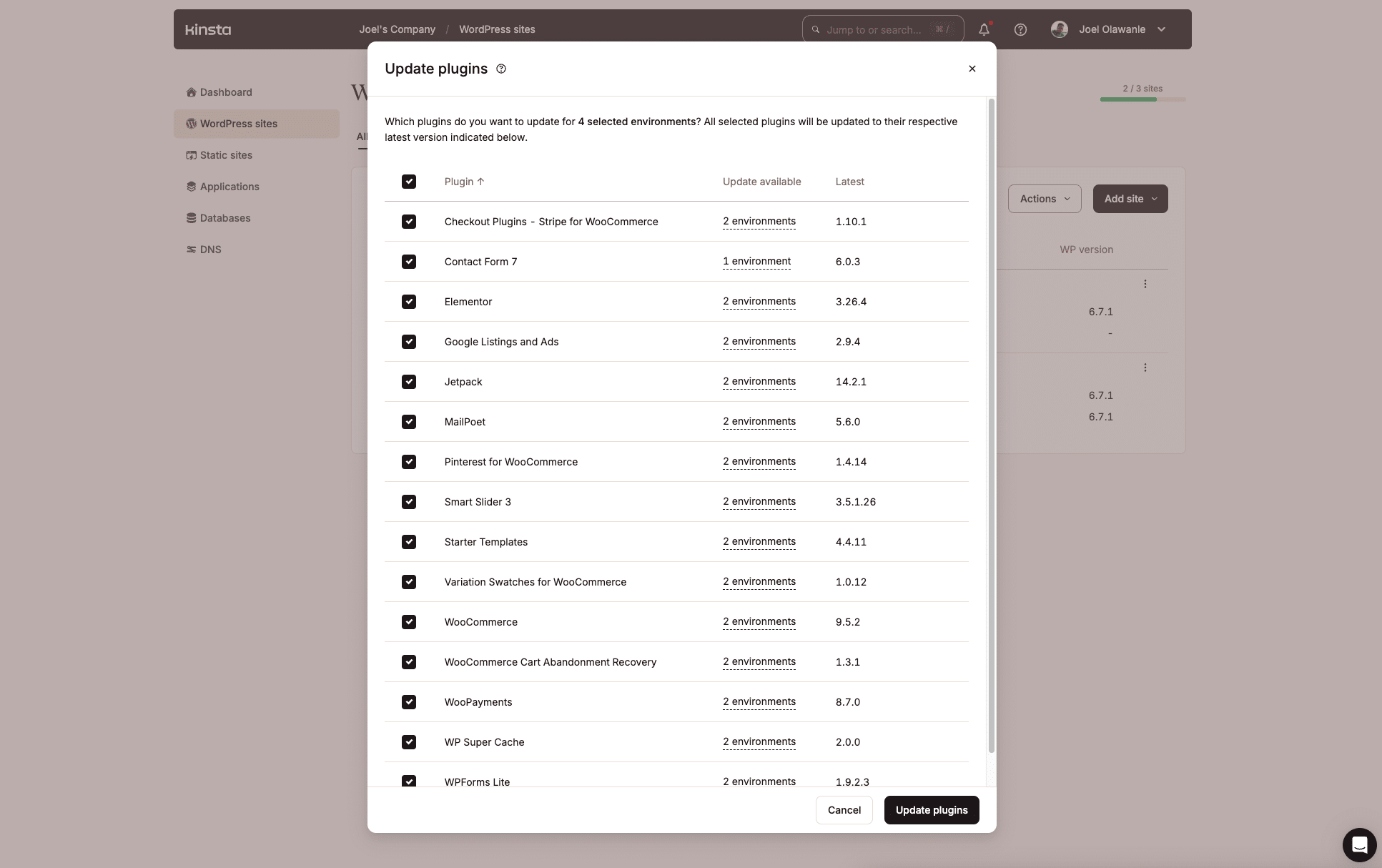
Mais si vous n’aimez pas travailler avec des interfaces utilisateur, l’API de Kinsta offre une autre possibilité de créer un script shell pour automatiser le processus d’identification des extensions obsolètes et leur mise à jour sur plusieurs sites ou dans des environnements spécifiques.
Décomposer le flux de travail
1. Identifier les sites dont les extensions sont obsolètes : Le script itère à travers tous les sites et environnements, à la recherche de l’extension spécifiée avec une mise à jour disponible. Le point de terminaison suivant est utilisé pour récupérer la liste des extensions pour un environnement de site spécifique :
GET /sites/environments/{env_id}/pluginsÀ partir de la réponse, nous filtrons les extensions pour lesquelles "update": "available".
2. Invitez l’utilisateur à choisir les options de mise à jour : Cela affiche les sites et les environnements avec l’extension obsolète, ce qui permet à l’utilisateur de sélectionner des instances spécifiques ou de les mettre toutes à jour.
3. Déclencher les mises à jour de l’extension : Pour mettre à jour l’extension dans un environnement spécifique, le script utilise ce point de terminaison:
PUT /sites/environments/{env_id}/pluginsLe nom de l’extension et sa version mise à jour sont transmis dans le corps de la requête.
Le script
Comme le script est long, la fonction complète est hébergée sur GitHub pour en faciliter l’accès. Ici, nous allons expliquer la logique de base utilisée pour identifier les extensions obsolètes sur plusieurs sites et environnements.
Le script commence par accepter le nom de l’extension à partir de la commande. Ce nom spécifie l’extension que vous voulez mettre à jour.
PLUGIN_NAME=$1
if [ -z "$PLUGIN_NAME" ]; then
echo "Error: Plugin name is required."
echo "Usage: $0 update-plugin "
return 1
fiLe script utilise ensuite la fonction réutilisable get_sites_list (expliquée plus haut) pour rechercher tous les sites de l’entreprise :
echo "Fetching all sites in the company..."
# Fetch all sites in the company
SITES_RESPONSE=$(get_sites_list)
if [ $? -ne 0 ]; then
echo "Error: Failed to fetch sites."
return 1
fi
# Clean the response
CLEAN_SITES_RESPONSE=$(echo "$SITES_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Vient ensuite le cœur du script : parcourir en boucle la liste des sites pour vérifier la présence d’extensions obsolètes. Le CLEAN_SITES_RESPONSE, qui est un objet JSON contenant tous les sites, est transmis à une boucle while pour effectuer les opérations pour chaque site un par un.
Elle commence par extraire certaines données importantes comme l’identifiant, le nom et le nom d’affichage du site dans des variables :
while IFS= read -r SITE; do
SITE_ID=$(echo "$SITE" | jq -r '.id')
SITE_NAME=$(echo "$SITE" | jq -r '.name')
SITE_DISPLAY_NAME=$(echo "$SITE" | jq -r '.display_name')
echo "Checking environments for site "$SITE_DISPLAY_NAME"..."Le nom du site est ensuite utilisé avec la fonction get_site_details_by_name définie précédemment pour obtenir des informations détaillées sur le site, y compris tous ses environnements.
SITE_DETAILS=$(get_site_details_by_name "$SITE_NAME")
CLEAN_SITE_DETAILS=$(echo "$SITE_DETAILS" | tr -d 'r' | sed 's/^[^{]*//')
ENVIRONMENTS=$(echo "$CLEAN_SITE_DETAILS" | jq -r '.site.environments[] | "(.id):(.name):(.display_name)"')Les environnements sont ensuite parcourus en boucle pour extraire les détails de chaque environnement, tels que l’ID, le nom et le nom d’affichage :
while IFS= read -r ENV; do
ENV_ID=$(echo "$ENV" | cut -d: -f1)
ENV_NAME=$(echo "$ENV" | cut -d: -f2)
ENV_DISPLAY_NAME=$(echo "$ENV" | cut -d: -f3)
echo "Checking plugins for environment "$ENV_DISPLAY_NAME"..."Pour chaque environnement, le script récupère maintenant sa liste d’extensions à l’aide de l’API de Kinsta.
PLUGINS_RESPONSE=$(curl -s -X GET "$BASE_URL/sites/environments/$ENV_ID/plugins"
-H "Authorization: Bearer $API_KEY"
-H "Content-Type: application/json")
CLEAN_PLUGINS_RESPONSE=$(echo "$PLUGINS_RESPONSE" | tr -d 'r' | sed 's/^[^{]*//')Ensuite, le script vérifie si l’extension spécifiée existe dans l’environnement et si une mise à jour est disponible :
OUTDATED_PLUGIN=$(echo "$CLEAN_PLUGINS_RESPONSE" | jq -r --arg PLUGIN_NAME "$PLUGIN_NAME" '.environment.container_info.wp_plugins.data[] | select(.name == $PLUGIN_NAME and .update == "available")')Si une extension obsolète est trouvée, le script enregistre ses détails et les ajoute au tableau SITES_WITH_OUTDATED_PLUGIN:
if [ ! -z "$OUTDATED_PLUGIN" ]; then
CURRENT_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.version')
UPDATE_VERSION=$(echo "$OUTDATED_PLUGIN" | jq -r '.update_version')
echo "Outdated plugin "$PLUGIN_NAME" found in "$SITE_DISPLAY_NAME" (Environment: $ENV_DISPLAY_NAME)"
echo " Current Version: $CURRENT_VERSION"
echo " Update Version: $UPDATE_VERSION"
SITES_WITH_OUTDATED_PLUGIN+=("$SITE_DISPLAY_NAME:$ENV_DISPLAY_NAME:$ENV_ID:$UPDATE_VERSION")
fiVoici à quoi ressembleraient les détails enregistrés des extensions obsolètes :
Outdated plugin "example-plugin" found in "Site ABC" (Environment: Production)
Current Version: 1.0.0
Update Version: 1.2.0
Outdated plugin "example-plugin" found in "Site XYZ" (Environment: Staging)
Current Version: 1.3.0
Update Version: 1.4.0À partir d’ici, nous effectuons les mises à jour de chaque extension en utilisant son point de terminaison. Le script complet se trouve dans ce dépôt GitHub.
Résumé
Cet article vous a guidé dans la création d’un script shell pour interagir avec l’API Kinsta.
Prends le temps d’explorer davantage l’API de Kinsta – vous découvrirez des fonctions supplémentaires que vous pouvez automatiser pour gérer des tâches adaptées à vos besoins spécifiques. Vous pourriez envisager d’intégrer l’API à d’autres API pour améliorer la prise de décision et l’efficacité.
Enfin, consultez régulièrement le tableau de bord MyKinsta pour découvrir les nouvelles fonctionnalités conçues pour rendre la gestion du site web encore plus conviviale grâce à son interface intuitive.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

