
De nombreux sites web et applications stockent généralement leurs données dans une base de données. La lecture et l’écriture des données d’une base de données peuvent affecter de manière significative la latence d’une application. Il est important de réduire la latence autant que possible, car les utilisateurs attendent des applications rapides et réactives, et les sites web plus rapides sont plus performants pour l’optimisation des moteurs de recherche (Search Engine Optimization ou SEO).
L’écriture dans une base de données ajoute de la latence car les bases de données écrivent généralement les données sur un disque au lieu de les conserver en mémoire. Il est courant que les bases de données appliquent la compression et le cryptage, ce qui ajoute de la latence lors de la lecture et de l’écriture des données. Pour surmonter ces difficultés, vous pouvez utiliser une base de données en mémoire pour un stockage et une récupération rapides des données à partir de la RAM plutôt que d’un disque.
Cet article présente le fonctionnement des bases de données en mémoire, certaines options populaires et certains compromis par rapport à une base de données standard.
Que sont les bases de données en mémoire ?
Les bases de données en mémoire utilisent la RAM au lieu de disques durs (HDD) ou de disques à semi-conducteurs (SSD) pour stocker les données, ce qui réduit considérablement la latence de lecture et d’écriture des données. La réduction de la latence est due à deux raisons principales. Premièrement, l’accès aux données à partir de la mémoire est plus rapide qu’à partir d’un disque, et deuxièmement, les structures de données utilisées pour stocker les données en mémoire sont plus simples que le stockage sur disque. Par conséquent, la surcharge du CPU est plus faible lors de la lecture et de l’écriture des données.
Cette faible latence a un coût car les données stockées en mémoire seront perdues si un serveur tombe en panne. Contrairement au stockage sur disque, la mémoire ne conserve pas son contenu en cas de coupure de courant, ce qui implique un compromis entre résilience et vitesse.
Les bases de données en mémoire sont une excellente option pour les applications qui nécessitent des données rapides ou en temps réel, comme les tableaux de classement ou les analyses en temps réel. Elles sont également utiles pour mettre en cache des données que vous stockez habituellement dans une base de données sur disque afin de réduire le nombre de lectures et d’écritures sur le disque et de minimiser la latence.
La réduction de la latence est particulièrement importante pour les sites web. Les utilisateurs qui trouvent le site web réactif sont plus susceptibles de continuer à l’utiliser. En outre, Google et d’autres moteurs de recherche utilisent également la vitesse de chargement des sites comme facteur de référencement. Les sites web rapides sont mieux classés dans les résultats de recherche, ce qui augmente les chances des utilisateurs de visiter votre site.
Les bases de données en mémoire expliquées
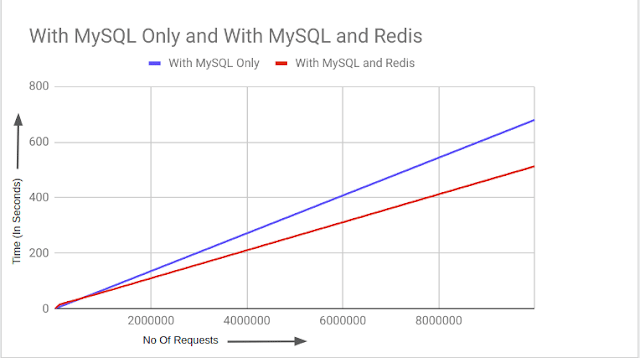
Comme les bases de données en mémoire stockent les données dans la RAM, leur latence est bien plus faible que celle d’un disque dur, qui utilise des pièces mécaniques et mobiles pour accéder à l’emplacement correct du disque. Le disque dur doit ensuite lire les données et les transférer via l’interface entre le périphérique de stockage et l’ordinateur. En outre, même avec les disques SSD, la RAM est toujours jusqu’à 30 fois plus rapide en raison de ses puces mémoire et de son interface CPU plus performantes. Certains tests de benchmarking ont montré que l’utilisation de MySQL avec Redis – une base de données en mémoire populaire – comme couche de mise en cache peut réduire la latence des requêtes jusqu’à 25 % par rapport à l’utilisation d’une base de données MySQL autonome.
Il y a une deuxième raison pour laquelle les bases de données en mémoire sont rapides. Vous pouvez optimiser les structures de données utilisées par les bases de données en mémoire pour une récupération plus rapide. Par exemple, les bases de données relationnelles utilisent souvent des arbres B pour les index, permettant des recherches rapides tout en supportant la lecture et l’écriture de gros blocs de données sur le disque. Les bases de données en mémoire n’ont pas besoin d’écrire des blocs de données sur le disque et peuvent choisir des structures de données plus performantes, ce qui réduit encore la latence. Les bases de données en mémoire stockent et utilisent souvent les données telles quelles, sans transformation ni analyse au niveau de la couche de base de données. Cela contribue également à la réduction de la latence, car cela accélère les temps de lecture et d’écriture.
Les bases de données en mémoire sont devenues plus populaires en raison des améliorations technologiques. Tout d’abord, le prix par gigaoctet (Go) de mémoire vive a considérablement diminué au cours des 20 dernières années, ce qui a rendu l’utilisation de la mémoire pour le stockage des données plus abordable. Les améliorations apportées aux solutions de bases de données en mémoire et aux services cloud gérés ont également contribué à atténuer certains de leurs principaux inconvénients.
En outre, les bases de données en mémoire telles que Redis peuvent désormais faire des instantanés de données de la mémoire vers le disque, ce qui permet de restaurer les données en cas de défaillance d’un serveur. Les services de cloud computing fournissent une géo-réplication, ce qui signifie que les applications peuvent rester en ligne en basculant en cas de problème. Cette réduction des coûts et cette amélioration de la fiabilité ont fait des bases de données en mémoire des options réalisables pour les applications et les sites web modernes.
Avantages et inconvénients des bases de données en mémoire
Les principaux avantages des bases de données en mémoire sont les suivants :
- Elles améliorent les performances.
- Elles sont plus simples à mettre à l’échelle en raison de la façon dont ils stockent les données.
- Elles améliorent souvent la fiabilité d’une application.
Les bases de données en mémoire stockent généralement des données non structurées ou semi-structurées au lieu de les stocker dans des modèles relationnels complexes. Les données non structurées rendent la mise à l’échelle de la base de données plus simple, car les frais généraux de transfert de données sur le réseau pour joindre des données qui vivent sur plusieurs nœuds sont inutiles.
Améliorer la fiabilité d’une application peut sembler contre-intuitif en raison de la volatilité des données stockées en mémoire vive. Cependant, lorsqu’elles sont utilisées comme couche de mise en cache, les bases de données en mémoire réduisent la charge sur la base de données principale lors des pics de requêtes. Une couche de mise en cache peut également contribuer à réduire les coûts, car il est souvent plus coûteux de faire évoluer une base de données traditionnelle qu’une base de données en mémoire pour accélérer les demandes fréquentes, puis d’utiliser la base de données centrale pour le stockage à plus long terme.
Les principaux inconvénients des bases de données en mémoire sont les suivants :
- Augmentation du coût si elles sont utilisées comme seule base de données
- Taille de stockage limitée
- Moins de fonctions de sécurité
Les bases de données en mémoire n’utilisent généralement pas de fonctions de sécurité telles que le cryptage, car tout doit être en mémoire – y compris les clés de cryptage. Ces caractéristiques rendent le cryptage des données inefficace car toute entité malveillante ayant accès à la mémoire peut, en théorie, également accéder à la clé de cryptage.
Les bases de données en mémoire peuvent réduire les coûts lorsqu’elles sont utilisées avec des bases de données traditionnelles. Cependant, elles sont souvent plus coûteuses lorsqu’elles sont utilisées comme seule base de données, surtout si elles stockent de grandes quantités de données, en raison du prix plus élevé de la mémoire par rapport au stockage sur disque. Ce coût limite également la quantité de données que vous pouvez conserver, car le stockage de grands ensembles de données en mémoire devient coûteux et nécessite souvent plusieurs serveurs.
Pourquoi toutes les bases de données ne sont-elles pas en mémoire ?
Le principal inconvénient qui empêche les bases de données en mémoire d’être omniprésentes est le coût. Bien que les prix de la RAM aient considérablement baissé, ils sont toujours beaucoup plus élevés par Go que ceux des disques durs et des disques SSD. Ce coût rend les bases de données en mémoire trop chères pour les applications plus étendues avec des empreintes de données colossales.
Si le prix de la RAM continue à baisser, il se pourrait qu’un jour les bases de données en mémoire deviennent la solution par défaut et que les bases de données sur disque ne soient utilisées que dans des circonstances particulières.
Cas d’utilisation des bases de données en mémoire
L’une des utilisations les plus courantes des bases de données en mémoire est la mise en cache. Vous pouvez utiliser la base de données en mémoire comme une couche de mise en cache en conjonction avec une base de données traditionnelle. La base de données en mémoire stocke les données fréquemment consultées, ce qui évite les recherches répétées et coûteuses dans la base de données sur disque et offre une expérience utilisateur plus rapide.
Les bases de données en mémoire sont également devenues célèbres pour les sites de commerce électronique, les forums et les blogs à fort trafic avec des sections de commentaires. Cela s’explique par le fait qu’il s’agit de sites hautement dynamiques. Les sites eCommerce veulent personnaliser l’expérience utilisateur et afficher la disponibilité des produits en temps réel. Les blogs et les forums peuvent avoir des centaines ou des milliers d’utilisateurs qui publient et commentent simultanément. Cela signifie qu’un site devra gérer un débit d’écriture élevé et être capable de servir rapidement les derniers contenus et commentaires aux utilisateurs. Les bases de données en mémoire réduisent la latence dans le stockage du contenu généré par les utilisateurs et fournissent une expérience actualisée et personnalisée.
Les bases de données en mémoire sont également d’excellents candidats pour les classements de jeux. Elles peuvent mettre à jour et récupérer des données en temps réel et trier efficacement les données pour fournir une vue actuelle du classement au fur et à mesure de la progression du jeu.
Vous pouvez également les utiliser pour les analyses en temps réel. Elles vous permettent d’envoyer des données en continu dans la base de données et d’exécuter des requêtes sur la version la plus récente des données pour des tableaux de bord en temps réel, des analyses de risques et des modèles d’apprentissage automatique.
Exemples de bases de données en mémoire
Il existe de nombreux choix lors de la sélection d’une base de données en mémoire. Parmi les plus populaires, citons Redis, Memgraph et Hazelcast. Redis est le plus utilisé et est disponible en tant que service géré sur la plupart des plateformes dans le cloud. Memgraph fournit des calculs graphiques de données en continu, le tout en mémoire, et Hazelcast offre une fonctionnalité similaire à Redis mais avec des modèles de mise en cache différents.
Redis est généralement une couche de mise en cache entre les sites web et les applications pour améliorer les performances en évitant les lectures coûteuses des bases de données. Cette augmentation des performances est également possible pour les sites WordPress avec l’aide du module Redis de Kinsta. En plus de ce module, Kinsta fournit également l’outil Kinsta APM pour aider à résoudre tout problème de performance avec les requêtes Redis.
Les sites web fonctionnant sur Kinsta utilisent la mise en cache par défaut. Cependant, les sites avec des requêtes de base de données fréquentes bénéficieront toujours grandement de Redis. La latence de la base de données est l’un des facteurs les plus importants qui ralentissent un site web, mais Redis aide à réduire cette charge et permet au site d’évoluer rapidement.
Résumé
La latence des bases de données peut affecter de manière significative la latence globale d’un site web ou d’une application. La lecture et l’écriture sur les disques durs augmentent la latence. Les bases de données en mémoire réduisent la latence des bases de données car elles stockent les données dans la RAM. Même en utilisant des disques SSD, la RAM reste plus rapide car elle utilise des puces mémoire plus rapides et une interface plus rapide avec le CPU. En outre, vous pouvez optimiser les structures de données utilisées par les bases de données en mémoire pour une récupération plus rapide.
Les bases de données en mémoire peuvent accélérer les sites web et les applications lorsqu’elles sont utilisées comme couche de mise en cache entre le site web et une base de données traditionnelle. En effet, la mémoire est plus rapide d’accès que le disque, et cette réduction des frais généraux se traduit par des temps de chargement plus rapides du site et peut contribuer à améliorer le référencement.
Redis est l’une des options de base de données en mémoire les plus populaires, et vous pouvez facilement l’ajouter aux sites WordPress à l’aide du module Kinsta. Essayez le module Redis pour votre site hébergé par Kinsta.

Salman Ravoof est un développeur web autodidacte, un écrivain, un créateur et un grand admirateur des logiciels libres. Outre la technologie, il est passionné par la science, la philosophie, la photographie, les arts, les chats et la nourriture. Apprenez-en plus sur son site web, et connectez-vous avec Salman sur X.

