
Avec l’évolution du développement d’applications, les bases de données constituent le cœur de la plupart des applications, car elles stockent et gèrent des données cruciales pour les entreprises numériques. À mesure que ces données augmentent et deviennent plus complexes, il est essentiel de garantir l’efficacité de votre base de données pour répondre aux besoins de votre application.
C’est là que la notion de maintenance des bases de données entre en jeu. La maintenance des bases de données comprend des tâches telles que le nettoyage, les sauvegardes et l’optimisation des indices pour augmenter les performances.
Cet article offre des informations précieuses sur les déclencheurs de maintenance et présente des instructions de configuration pratiques. Il explique le processus de mise en œuvre de diverses tâches de maintenance de base de données telles que la sauvegarde des données, la reconstruction des index, l’archivage et le nettoyage des données à l’aide de PostgreSQL, intégré à un déclencheur API dans une application Node.js.
Comprendre les déclencheurs
Avant de construire des opérations de maintenance pour votre base de données, il est important de comprendre les différentes façons dont elles peuvent être déclenchées. Chaque déclencheur a des fonctions distinctes pour faciliter les tâches de maintenance. Les trois principaux déclencheurs couramment utilisés sont les suivants
- Manuel, basé sur l’API : Ce déclencheur vous permet d’exécuter des opérations ponctuelles à l’aide d’un appel API. Il est utile dans des situations telles que la restauration d’une sauvegarde de base de données ou la reconstruction d’index lorsque les performances chutent soudainement.
- Planification (comme CRON) : Ce déclencheur vous permet d’automatiser les activités de maintenance planifiées pendant les périodes de faible trafic utilisateur. Il est idéal pour exécuter des opérations gourmandes en ressources telles que l’archivage et le nettoyage. Vous pouvez utiliser des packages tels que node-schedule pour configurer des planifications dans Node.js qui déclenchent automatiquement les opérations lorsque cela est nécessaire.
- Notifications de base de données : Ce déclencheur vous permet d’effectuer des opérations de maintenance en réponse à des modifications de la base de données. Par exemple, lorsqu’un utilisateur publie un commentaire sur une plateforme, les données enregistrées peuvent instantanément déclencher des vérifications concernant les caractères irréguliers, le langage offensant ou les emojis. La mise en œuvre de cette fonctionnalité dans Node.js est possible à l’aide de packages tels que pg-listen.
Pré-requis
Pour suivre ce guide, vous devez disposer des outils suivants sur votre ordinateur local :
- Git : Pour gérer le contrôle de version du code source de votre application
- Node.js : pour construire votre application backend
- psql : Pour interagir avec votre base de données PostgreSQL distante en utilisant votre terminal
- PGAdmin (optionnel) : Pour interagir avec votre base de données PostgreSQL distante en utilisant une interface utilisateur graphique (GUI).
Créer et héberger une application Node.js
Mettons en place un projet Node.js, livrons-le sur GitHub et mettons en place un pipeline de déploiement automatique vers Kinsta. Vous devez également provisionner une base de données PostgreSQL sur Kinsta pour y tester vos routines de maintenance.
Commencez par créer un nouveau répertoire sur votre système local en utilisant la commande suivante :
mkdir node-db-maintenanceEnsuite, allez dans le dossier nouvellement créé et exécutez la commande suivante pour créer un nouveau projet :
cd node-db-maintenance
yarn init -y # or npm init -yCeci initialise un projet Node.js pour vous avec la configuration par défaut. Vous pouvez maintenant installer les dépendances nécessaires en exécutant la commande suivante :
yarn add express pg nodemon dotenvVoici une description rapide de chaque paquet :
express: vous permet de mettre en place une API REST basée sur Express.pg: le paquet REST : vous permet d’interagir avec une base de données PostgreSQL à travers votre application Node.js.nodemon: permet à votre build de développement d’être mis à jour au fur et à mesure que vous développez votre application, vous libérant ainsi du besoin constant d’arrêter et de démarrer votre application à chaque fois que vous effectuez un changement.dotenv: vous permet de charger des variables d’environnement depuis un fichier .env dans votre objetprocess.env.
Ensuite, ajoutez les scripts suivants dans votre fichier package.json pour pouvoir démarrer facilement votre serveur de développement et l’exécuter également en production :
{
// ...
"scripts": {
"start-dev": "nodemon index.js",
"start": "NODE_ENV=production node index.js"
},
// …
}Vous pouvez maintenant créer un fichier index.js qui contient le code source de votre application. Collez le code suivant dans le fichier :
const express = require("express")
const dotenv = require('dotenv');
if (process.env.NODE_ENV !== 'production') dotenv.config();
const app = express()
const port = process.env.PORT || 3000
app.get("/health", (req, res) => res.json({status: "UP"}))
app.listen(port, () => {
console.log(`Server running at port: ${port}`);
});Ce code initialise un serveur Express et configure les variables d’environnement en utilisant le paquetage dotenv si vous n’êtes pas en mode production. Il met également en place une route /health qui renvoie un objet JSON {status: "UP"}. Enfin, il démarre l’application à l’aide de la fonction app.listen() pour écouter sur le port spécifié, par défaut 3000 si aucun port n’est fourni via la variable d’environnement.
Maintenant que vous avez une application de base prête, initialisez un nouveau dépôt git avec votre fournisseur git préféré (BitBucket, GitHub, ou GitLab) et poussez votre code. Kinsta prend en charge le déploiement d’applications à partir de tous ces fournisseurs git. Pour cet article, nous utiliserons GitHub.
Lorsque votre dépôt est prêt, suivez les étapes suivantes pour déployer votre application sur Kinsta :
- Connectez-vous ou créez un compte pour afficher votre tableau de bord MyKinsta.
- Autorisez Kinsta avec votre fournisseur Git.
- Dans la colonne latérale de gauche, cliquez sur Applications, puis sur Ajouter une application.
- Sélectionnez le dépôt et la branche à partir desquels vous souhaitez effectuer le déploiement.
- Sélectionnez l’un des centres de données disponibles dans la liste des 28 options. Kinsta détecte automatiquement les paramètres de construction de vos applications via Nixpacks.
- Choisissez les ressources de votre application, telles que la mémoire vive et l’espace disque.
- Cliquez sur Créer une application.
Une fois le déploiement terminé, copiez le lien de l’application déployée et naviguez vers /health. Vous devriez voir le JSON suivant dans votre navigateur :
{status: "UP"}Cela indique que l’application a été correctement configurée.
Configurer une instance PostgreSQL sur Kinsta
Kinsta fournit une interface facile pour provisionner des instances de base de données. Commencez par créer un nouveau compte Kinsta si vous n’en avez pas déjà un. Ensuite, suivez les étapes ci-dessous :
- Connectez-vous à votre tableau de bord MyKinsta.
- Dans la colonne latérale de gauche, cliquez sur Bases de données, puis sur Ajouter une base de données.
- Sélectionnez PostgreSQL comme type de base de données et choisissez votre version préférée. Choisissez un nom pour votre base de données et modifiez le nom d’utilisateur et le mot de passe si vous le souhaitez.
- Sélectionnez un emplacement de centre de données dans la liste des 28 options.
- Choisissez la taille de votre base de données.
- Cliquez sur Créer une base de données.
Une fois la base de données créée, veillez à récupérer l’hôte, le port, le nom d’utilisateur et le mot de passe de la base de données.
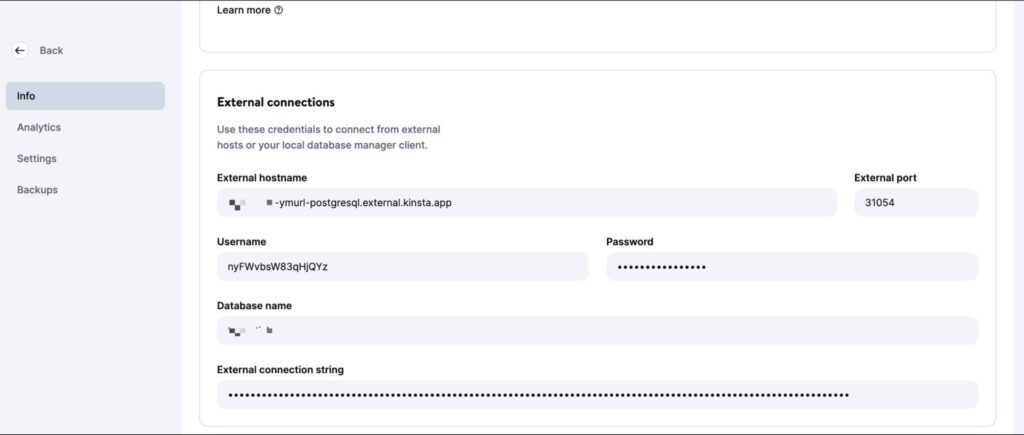
Vous pouvez ensuite insérer ces valeurs dans votre CLI psql (ou l’interface graphique PGAdmin) pour gérer la base de données. Pour tester votre code localement, créez un fichier .env dans le répertoire racine de votre projet et stockez-y les secrets suivants :
DB_USER_NAME=your database user name
DB_HOST=your database host
DB_DATABASE_NAME=your database’s name
DB_PORT=your database port
PGPASS=your database passwordLors du déploiement sur Kinsta, vous devez ajouter ces valeurs en tant que variables d’environnement au déploiement de votre application.
Pour préparer les opérations de base de données, téléchargez et exécutez ce script SQL pour créer des tables (utilisateurs, messages, commentaires) et insérer des données d’exemple. Utilisez la commande ci-dessous, en remplaçant les espaces réservés par vos propres données, pour ajouter les données à votre base de données PostgreSQL nouvellement créée :
psql -h <host> -p <port> -U <username> -d <db_name> -a -f <sql file e.g. test-data.sql>Veillez à saisir le nom et le chemin d’accès exacts du fichier dans la commande ci-dessus. L’exécution de cette commande vous invite à saisir le mot de passe de votre base de données pour autorisation.
Une fois cette commande exécutée, vous êtes prêt à écrire des opérations pour la maintenance de votre base de données. N’hésitez pas à pousser votre code vers votre dépôt Git lorsque vous avez terminé chaque opération pour le voir en action sur la plateforme Kinsta.
Écrire des routines de maintenance
Cette section explique plusieurs opérations couramment utilisées pour la maintenance des bases de données PostgreSQL.
1. Créer des sauvegardes
Sauvegarder régulièrement les bases de données est une opération courante et essentielle. Elle consiste à créer une copie de l’ensemble du contenu de la base de données, qui est stockée dans un endroit sûr. Ces sauvegardes sont cruciales pour restaurer les données en cas de perte accidentelle ou d’erreurs affectant l’intégrité des données.
Bien que des plateformes comme Kinsta proposent des sauvegardes automatisées dans le cadre de leurs services, il est important de savoir comment mettre en place une routine de sauvegarde personnalisée si nécessaire.
PostgreSQL propose l’outil pg_dump pour créer des sauvegardes de bases de données. Cependant, il doit être exécuté directement depuis la ligne de commande, et il n’existe pas de paquetage npm pour cet outil. Vous devez donc utiliser le paquet @getvim/execute pour exécuter la commande pg_dump dans l’environnement local de votre application Node.
Installez le paquetage en exécutant la commande suivante :
yarn add @getvim/executeEnsuite, importez le paquetage dans votre fichier index.js en ajoutant cette ligne de code en haut :
const {execute} = require('@getvim/execute');Les sauvegardes sont générées sous forme de fichiers sur le système de fichiers local de votre application Node. Il est donc préférable de créer un répertoire dédié à ces sauvegardes sous le nom de backup dans le répertoire racine du projet.
Vous pouvez maintenant utiliser la route suivante pour générer et télécharger des sauvegardes de votre base de données lorsque cela est nécessaire :
app.get('/backup', async (req, res) => {
// Create a name for the backup file
const fileName = "database-backup-" + new Date().valueOf() + ".tar";
// Execute the pg_dump command to generate the backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_dump -U " + process.env.DB_USER_NAME
+ " -d " + process.env.DB_DATABASE_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -f backup/" + fileName + " -F t"
).then(async () => {
console.log("Backup created");
res.redirect("/backup/" + fileName)
}).catch(err => {
console.log(err);
res.json({message: "Something went wrong"})
})
})Vous devez également ajouter la ligne suivante au début de votre fichier index.js après l’initialisation de l’application Express :
app.use('/backup', express.static('backup'))Cela permet au dossier backup d’être servi statiquement en utilisant la fonction middleware express.static, permettant à l’utilisateur de télécharger les fichiers de sauvegarde générés à partir de l’application Node.
2. Restauration à partir d’une sauvegarde
Postgres permet de restaurer des sauvegardes à l’aide de l’outil de ligne de commande pg_restore. Cependant, vous devez l’utiliser via le paquetage execute de la même manière que vous avez utilisé la commande pg_dump. Voici le code de la route :
app.get('/restore', async (req, res) => {
const dir = 'backup'
// Sort the backup files according to when they were created
const files = fs.readdirSync(dir)
.filter((file) => fs.lstatSync(path.join(dir, file)).isFile())
.map((file) => ({ file, mtime: fs.lstatSync(path.join(dir, file)).mtime }))
.sort((a, b) => b.mtime.getTime() - a.mtime.getTime());
if (!files.length){
res.json({message: "No backups available to restore from"})
}
const fileName = files[0].file
// Restore the database from the chosen backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_restore -cC "
+ "-U " + process.env.DB_USER_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -d postgres backup/" + fileName
)
.then(async ()=> {
console.log("Restored");
res.json({message: "Backup restored"})
}).catch(err=> {
console.log(err);
res.json({message: "Something went wrong"})
})
})L’extrait de code ci-dessus recherche d’abord les fichiers stockés dans le répertoire backup local. Ensuite, il les trie en fonction de leur date de création pour trouver le fichier de sauvegarde le plus récent. Enfin, il utilise le paquet execute pour restaurer le fichier de sauvegarde choisi.
Veillez à ajouter les importations suivantes à votre fichier index.js afin que les modules nécessaires à l’accès au système de fichiers local soient importés, ce qui permettra à la fonction de s’exécuter correctement :
const fs = require('fs')
const path = require('path')3. Reconstruction d’un index
Les index des tables Postgres sont parfois corrompus, ce qui dégrade les performances de la base de données. Cela peut être dû à des bogues ou à des erreurs logicielles. Parfois, les index peuvent également devenir trop volumineux en raison d’un trop grand nombre de pages vides ou presque vides.
Dans ce cas, vous devez reconstruire l’index pour vous assurer que vous obtenez les meilleures performances de votre instance Postgres.
Postgres propose la commande REINDEX à cette fin. Vous pouvez utiliser le paquetage node-postgres pour exécuter cette commande (et pour exécuter d’autres opérations plus tard également), donc installez-le en exécutant d’abord la commande suivante :
yarn add pgEnsuite, ajoutez les lignes suivantes au début du fichier index.js, sous les importations, afin d’initialiser correctement la connexion à la base de données :
const {Client} = require('pg')
const client = new Client({
user: process.env.DB_USER_NAME,
host: process.env.DB_HOST,
database: process.env.DB_DATABASE_NAME,
password: process.env.PGPASS,
port: process.env.DB_PORT
})
client.connect(err => {
if (err) throw err;
console.log("Connected!")
})La mise en œuvre de cette opération est assez simple :
app.get("/reindex", async (req, res) => {
// Run the REINDEX command as needed
await client.query("REINDEX TABLE Users;")
res.json({message: "Reindexed table successfully"})
})La commande présentée ci-dessus réindexe l’ensemble de la table Utilisateurs. Vous pouvez personnaliser la commande en fonction de vos besoins pour reconstruire un index particulier ou même pour réindexer la base de données complète.
4. Archivage et purge des données
Pour les bases de données qui deviennent volumineuses au fil du temps (et dont les données historiques sont rarement consultées), il peut être judicieux de mettre en place des routines qui déchargent les anciennes données dans un lac de données où elles peuvent être stockées et traitées plus facilement.
Les fichiers Parquet sont une norme courante pour le stockage et le transfert de données dans de nombreux lacs de données. Grâce à la bibliothèque ParquetJS, vous pouvez créer des fichiers Parquet à partir de vos données Postgres et utiliser des services comme AWS Athena pour les lire directement sans avoir à les recharger dans la base de données à l’avenir.
Installez la bibliothèque ParquetJS en exécutant la commande suivante :
yarn add parquetjsLorsque vous créez des archives, vous devez interroger un grand nombre d’enregistrements de vos tables. Le stockage d’une telle quantité de données dans la mémoire de votre application peut être gourmand en ressources, coûteux et source d’erreurs.
C’est pourquoi il est judicieux d’utiliser des curseurs pour charger des morceaux de données depuis la base de données et les traiter. Installez le module cursors du paquetage node-postgres en exécutant la commande suivante :
yarn add pg-cursorVeillez ensuite à importer les deux bibliothèques dans votre fichier index.js:
const Cursor = require('pg-cursor')
const parquet = require('parquetjs')Vous pouvez maintenant utiliser l’extrait de code ci-dessous pour créer des fichiers parquet à partir de votre base de données :
app.get('/archive', async (req, res) => {
// Query all comments through a cursor, reading only 10 at a time
// You can change the query here to meet your requirements, such as archiving records older than at least a month, or only archiving records from inactive users, etc.
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
// Define the schema for the parquet file
let schema = new parquet.ParquetSchema({
comment_id: { type: 'INT64' },
post_id: { type: 'INT64' },
user_id: { type: 'INT64' },
comment_text: { type: 'UTF8' },
timestamp: { type: 'TIMESTAMP_MILLIS' }
});
// Open a parquet file writer
let writer = await parquet.ParquetWriter.openFile(schema, 'archive/archive.parquet');
let rows = await cursor.read(10)
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Write each row from table to the parquet file
await writer.appendRow(rows[i])
}
rows = await cursor.read(10)
}
await writer.close()
// Once the parquet file is generated, you can consider deleting the records from the table at this point to free up some space
// Redirect user to the file path to allow them to download the file
res.redirect("/archive/archive.parquet")
})Ensuite, ajoutez le code suivant au début de votre fichier index.js après l’initialisation de l’application Express :
app.use('/archive', express.static('archive'))Cela permet au dossier d’archive d’être servi statiquement, ce qui vous permet de télécharger les fichiers parquet générés depuis le serveur.
N’oubliez pas de créer un répertoire d’archives dans le répertoire du projet pour stocker les fichiers d’archives.
Vous pouvez personnaliser davantage cet extrait de code pour télécharger automatiquement les fichiers de parquet vers un seau AWS S3 et utiliser des tâches CRON pour déclencher automatiquement l’opération sur une routine.
5. Nettoyage des données
Les opérations de maintenance des bases de données ont souvent pour but de nettoyer les données qui deviennent obsolètes ou non pertinentes avec le temps. Cette section aborde deux cas courants de nettoyage de données dans le cadre de la maintenance.
En réalité, vous pouvez mettre en place votre propre routine de nettoyage des données en fonction des modèles de données de votre application. Les exemples ci-dessous ne sont donnés qu’à titre de référence.
Suppression d’enregistrements en fonction de leur âge (dernière modification ou dernier accès)
Le nettoyage des enregistrements en fonction de leur ancienneté est relativement simple par rapport aux autres opérations de cette liste. Vous pouvez écrire une requête de suppression qui supprime les enregistrements antérieurs à une date donnée.
Voici un exemple de suppression de commentaires antérieurs au 9 octobre 2023 :
app.get("/clean-by-age", async (req, res) => {
// Filter and delete all comments that were made on or before 9th October, 2023
const result = await client.query("DELETE FROM COMMENTS WHERE timestamp < '09-10-2023 00:00:00'")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Vous pouvez l’essayer en envoyant une requête GET à la route /clean-by-age.
Suppression d’enregistrements sur la base de conditions personnalisées
Vous pouvez également mettre en place des nettoyages basés sur d’autres conditions, comme la suppression d’enregistrements qui ne sont pas liés à d’autres enregistrements actifs dans le système (ce qui crée une situation d’orphelin ).
Par exemple, vous pouvez mettre en place une opération de nettoyage qui recherche les commentaires liés à des articles supprimés et les supprime car ils ne feront probablement plus jamais surface dans l’application :
app.get('/conditional', async (req, res) => {
// Filter and delete all comments that are not linked to any active posts
const result = await client.query("DELETE FROM COMMENTS WHERE post_id NOT IN (SELECT post_id from Posts);")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Vous pouvez définir vos propres conditions en fonction de votre cas d’utilisation.
6. Manipulation des données
Les opérations de maintenance des bases de données sont également utilisées pour effectuer des manipulations et des transformations de données, telles que la censure d’un langage obscène ou la conversion de combinaisons de texte en emoji.
Contrairement à la plupart des autres opérations, il est préférable d’exécuter ces opérations lors des mises à jour de la base de données (plutôt que de les exécuter sur toutes les lignes à un moment fixe de la semaine ou du mois).
Cette section présente deux de ces opérations, mais la mise en œuvre de toute autre opération de manipulation personnalisée reste assez similaire à celles-ci.
Convertir du texte en Emoji
Vous pouvez envisager de convertir des combinaisons de texte telles que « 🙂 » et « xD » en véritables emojis afin d’offrir une meilleure expérience à l’utilisateur et de maintenir la cohérence des informations. Voici un extrait de code qui vous aidera à le faire :
app.get("/emoji", async (req, res) => {
// Define a list of emojis that need to be converted
const emojiMap = {
xD: '😁',
':)': '😊',
':-)': '😄',
':jack_o_lantern:': '🎃',
':ghost:': '👻',
':santa:': '🎅',
':christmas_tree:': '🎄',
':gift:': '🎁',
':bell:': '🔔',
':no_bell:': '🔕',
':tanabata_tree:': '🎋',
':tada:': '🎉',
':confetti_ball:': '🎊',
':balloon:': '🎈'
}
// Build the SQL query adding conditional checks for all emojis from the map
let queryString = "SELECT * FROM COMMENTS WHERE"
queryString += " COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[0] + "%' "
if (Object.keys(emojiMap).length > 1) {
for (let i = 1; i < Object.keys(emojiMap).length; i++) {
queryString += " OR COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[i] + "%' "
}
}
queryString += ";"
const result = await client.query(queryString)
if (result.rowCount === 0) {
res.json({message: "No rows to clean up!"})
} else {
for (let i = 0; i < result.rows.length; i++) {
const currentRow = result.rows[i]
let emoji
// Identify each row that contains an emoji along with which emoji it contains
for (let j = 0; j < Object.keys(emojiMap).length; j++) {
if (currentRow.comment_text.includes(Object.keys(emojiMap)[j])) {
emoji = Object.keys(emojiMap)[j]
break
}
}
// Replace the emoji in the text and update the row before moving on to the next row
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + currentRow.comment_text.replace(emoji, emojiMap[emoji]) + "' WHERE COMMENT_ID = " + currentRow.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "All emojis cleaned up successfully!"})
}
})Cet extrait de code vous demande tout d’abord de définir une liste d’emojis et leurs représentations textuelles. Ensuite, il interroge la base de données pour rechercher ces combinaisons textuelles et les remplacer par des emojis.
Censurer le langage obscène
Une opération assez courante dans les applications qui autorisent le contenu généré par les utilisateurs consiste à censurer tout langage indécent. L’approche ici est similaire : identifiez les cas de langage obscène et remplacez-les par des astérisques. Vous pouvez utiliser le paquetage bad-words pour vérifier et censurer facilement les grossièretés.
Installez le paquetage en exécutant la commande suivante :
yarn add bad-wordsEnsuite, initialisez le paquet dans votre fichier index.js :
const Filter = require('bad-words');
filter = new Filter();Maintenant, utilisez l’extrait de code suivant pour censurer le contenu obscène dans votre tableau de commentaires :
app.get('/obscene', async (req, res) => {
// Query all comments using a cursor, reading only 10 at a time
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
let rows = await cursor.read(10)
const affectedRows = []
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Check each comment for profane content
if (filter.isProfane(rows[i].comment_text)) {
affectedRows.push(rows[i])
}
}
rows = await cursor.read(10)
}
cursor.close()
// Update each comment that has profane content with a censored version of the text
for (let i = 0; i < affectedRows.length; i++) {
const row = affectedRows[i]
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + filter.clean(row.comment_text) + "' WHERE COMMENT_ID = " + row.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "Cleanup complete"})
})Vous pouvez trouver le code complet de ce tutoriel dans ce dépôt GitHub.
Comprendre l’aspiration de PostgreSQL et son but
En plus de mettre en place des routines de maintenance personnalisées telles que celles discutées ci-dessus, vous pouvez également utiliser l’une des fonctionnalités de maintenance natives que PostgreSQL offre pour assurer la santé et la performance de votre base de données : le processus Vacuum.
Le processus Vacuum permet d’optimiser les performances de la base de données et de récupérer de l’espace disque. PostgreSQL exécute les opérations de vide selon un calendrier en utilisant son démon auto-vacuum, mais vous pouvez également le déclencher manuellement si nécessaire. Voici quelques exemples de l’utilité d’une mise à vide fréquente :
- Récupération de l’espace disque bloqué : L’un des principaux objectifs de Vacuum est de récupérer l’espace disque bloqué dans la base de données. Comme les données sont constamment insérées, mises à jour et supprimées, PostgreSQL peut être encombré par des lignes « mortes » ou obsolètes qui occupent encore de l’espace sur le disque. Vacuum identifie et supprime ces lignes mortes, rendant l’espace disponible pour les nouvelles données. Sans Vacuum, l’espace disque s’épuiserait progressivement, ce qui pourrait entraîner une dégradation des performances, voire un blocage du système.
- Mise à jour des mesures du planificateur de requêtes : L’aspiration aide également PostgreSQL à maintenir à jour les statistiques et les métriques utilisées par son planificateur de requêtes. Le planificateur de requêtes s’appuie sur une distribution précise des données et des informations statistiques pour générer des plans d’exécution efficaces. En exécutant régulièrement Vacuum, PostgreSQL s’assure que ces métriques sont à jour, ce qui lui permet de prendre de meilleures décisions sur la façon de récupérer les données et d’optimiser les requêtes.
- Mise à jour de la carte de visibilité : La carte de visibilité est un autre aspect crucial du processus de Vacuum de PostgreSQL. Elle aide à identifier les blocs de données d’une table qui sont entièrement visibles par toutes les transactions, ce qui permet à Vacuum de cibler uniquement les blocs de données nécessaires au nettoyage. Cela améliore l’efficacité du processus de Vacuum en minimisant les opérations d’entrées-sorties inutiles, qui seraient coûteuses en temps et en argent.
- Prévention des échecs de contournement de l’ID de transaction : Vacuum joue également un rôle essentiel dans la prévention des échecs de contournement des identifiants de transaction. PostgreSQL utilise un compteur d’ID de transaction de 32 bits, qui peut conduire à un dépassement lorsqu’il atteint sa valeur maximale. Vacuum marque les anciennes transactions comme « gelées », empêchant le compteur d’ID de s’emballer et de provoquer une corruption des données. Négliger cet aspect peut conduire à des défaillances catastrophiques de la base de données.
Comme mentionné précédemment, PostgreSQL offre deux options pour exécuter Vacuum : Autovacuum et Manual Vacuum.
Autovacuum est le choix recommandé pour la plupart des scénarios car il gère automatiquement le processus de Vacuum en fonction des réglages prédéfinis et de l’activité de la base de données. Manual Vacuum, quant à lui, offre plus de contrôle mais nécessite une compréhension plus approfondie de la maintenance des bases de données.
Le choix entre les deux dépend de facteurs tels que la taille de la base de données, la charge de travail et les ressources disponibles. Les bases de données de petite ou moyenne taille peuvent souvent compter sur Autovacuum, tandis que les bases de données plus importantes ou plus complexes peuvent nécessiter une intervention manuelle.
Résumé
La maintenance des bases de données n’est pas seulement une question d’entretien de routine ; c’est le fondement d’une application saine et performante. En optimisant, nettoyant et organisant régulièrement vos données, vous vous assurez que votre base de données PostgreSQL continue à fournir des performances optimales, reste exempte de corruption et fonctionne efficacement, même lorsque votre application évolue.
Dans ce guide complet, nous avons exploré l’importance critique d’établir des plans de maintenance de base de données bien structurés pour PostgreSQL lorsque vous travaillez avec Node.js et Express.
Avons-nous oublié des opérations de maintenance de routine que vous avez mises en œuvre pour votre base de données ? Ou connaissez-vous une meilleure façon de mettre en œuvre l’une de ces opérations ? N’hésitez pas à nous en faire part dans les commentaires !

Kumar est un développeur de logiciels et un auteur technique basé en Inde. Il est spécialisé dans le JavaScript et le DevOps. Vous pouvez en apprendre plus sur son travail sur son site web.

