
Quest’anno, la stampa generalista ha dato ampio risalto a un cambiamento storico: il traffico automatizzato ha superato quello generato dagli utenti online. E i numeri alla base di questo cambiamento sono più difficili da ignorare rispetto alla maggior parte dei momenti salienti nella storia di Internet.
Il dato più citato proviene dal 2025 Bad Bot Report di Imperva, la dodicesima edizione della loro serie annuale che monitora le tendenze del traffico automatizzato dal 2013. Analizzando i modelli di traffico del 2024, il rapporto ha rilevato che l’attività automatizzata ha rappresentato per la prima volta nella storia più del 50% di tutto il traffico web, raggiungendo il 51%. Vale la pena notare che Imperva si era già avvicinata a questa soglia in passato. Il loro rapporto del 2024 registrava i bot al 49,6%, quindi non si tratta tanto di un superamento improvviso quanto della conferma di una tendenza che si è consolidata negli anni tra diversi fornitori e sistemi di misurazione.
Imperva non è l’unica a documentarlo. Cloudflare, Akamai, TollBit e Human Security hanno tutti pubblicato dati che puntano nella stessa direzione. Qui da Kinsta, la nostra analisi su oltre 10 miliardi di richieste nell’infrastruttura gestita racconta una storia coerente: il traffico dei bot basati sull’IA è aumentato del 300% in un solo anno, e gli effetti non sono più astratti.
E anche se il divario tra traffico umano e automatizzato è ancora piccolo, le implicazioni sono enormi. Diamo uno sguardo a lungo termine su come questo cambiamento nel traffico dei bot stia plasmando il web.
Cosa sono i bot e perché le vecchie definizioni non funzionano più
Tradizionalmente, i bot (abbreviazione di robot) sono applicazioni software progettate per eseguire attività automatizzate senza l’intervento umano. Il più noto è Googlebot, il crawler automatizzato di Google che scansiona e indicizza le pagine web per la ricerca. Altri bot comuni si occupano del monitoraggio dell’uptime, dell’indicizzazione, dell’analisi dei dati, delle scansioni di sicurezza e di altre funzioni utili che aiutano a mantenere il web efficiente.
Sebbene molti di questi bot siano innocui (anzi, persino utili), nel tempo si è evoluta un’altra categoria di bot che è ben più problematica. Si tratta dei crawler AI che operano su una scala tale da mettere a dura prova l’infrastruttura, indipendentemente dalle loro intenzioni.
Nel nostro rapporto sul traffico generato da AI e bot, David Belson, ex responsabile di Data Insights presso Cloudflare, ha spiegato che «La maggior parte di ciò che osserviamo non è dannoso. Si tratta di bot che si comportano in modo inefficiente su larga scala, ed è proprio lì che iniziano i veri problemi».
In passato, i bot erano relativamente facili da identificare perché in genere non riuscivano a eseguire JavaScript, simulare il movimento del puntatore, mantenere sessioni del browser realistiche o alternare gli indirizzi IP in modo efficace. La situazione è cambiata radicalmente. L’automazione basata sull’intelligenza artificiale ora permette ai bot di imitare il comportamento umano con una sofisticatezza sorprendente, mascherando i segnali tradizionali usati per il rilevamento.
Come dice Belson: «C’è chi ieri non sapeva nemmeno cosa diavolo stesse facendo, ma oggi ha programmato un bot al volo e l’ha lasciato libero di agire, senza nemmeno prendersi la briga di controllare il file robots.txt».
Il risultato è che i sistemi si stanno sempre più allontanando dal rilevamento basato sull’identità per orientarsi verso l’analisi comportamentale.
Cosa intendiamo per traffico umano?
Per evitare qualsiasi confusione, quando parliamo di traffico umano non ci riferiamo semplicemente ai clic o alle interazioni evidenti degli utenti. Il traffico umano comprende le numerose richieste generate durante la consegna e il rendering di una pagina web o di un’esperienza applicativa.
Una singola visita umana a una pagina può generare decine (a volte centinaia) di richieste. Queste possono includere richieste di HTML, CSS, JavaScript, font, immagini, API, script di analisi, risorse pubblicitarie e altre risorse necessarie per visualizzare una pagina web moderna.
Questa distinzione è importante perché le discussioni sul traffico generato dai bot rispetto a quello umano si basano in genere sulle richieste e sull’attività di rete, piuttosto che sul numero di persone reali online. Un numero relativamente esiguo di bot aggressivi può generare enormi volumi di traffico richiedendo ripetutamente pagine, estraendo dati dalle API, scaricando risorse o eseguendo azioni automatizzate su larga scala.
Perché proprio adesso?
Diversi fattori stanno accelerando la crescita del traffico generato dai bot, al di là della sola AI generativa.
1. Guadagno economico
I tempi in cui gli scherzi, la curiosità o l’abilità tecnica erano le motivazioni principali dietro le attività online dannose sono ormai in gran parte finiti. L’Internet di oggi favorisce un ambiente in cui le operazioni illegali condotte da singoli individui o da grandi organizzazioni criminali possono generare profitti nell’ordine di milioni di dollari.
Frodi, furti di dati, sfruttamento e distruzione di sistemi, manipolazione del mercato, scraping di contenuti su larga scala, distribuzione di ransomware e altre forme di generazione di entrate illecite vengono ora portate avanti su scala enorme da sistemi automatizzati e bot dannosi.
L’accesso non autorizzato e illegale ai dati personali è diventato un business enorme, e i bot basati sull’intelligenza artificiale stanno rendendo queste attività sempre più difficili da individuare, rintracciare e fermare.
2. Contesto normativo debole
Internet è un ambiente frammentato a livello globale, in cui leggi, applicazione delle norme e giurisdizione variano notevolmente da un paese all’altro e da una regione all’altra. Questa frammentazione crea un terreno fertile per la proliferazione dell’automazione dannosa.
I contesti normativi deboli permettono ai bot dannosi basati sull’AI di prosperare perché leggi, applicazione delle norme e coordinamento internazionale non hanno tenuto il passo con la rapida evoluzione dell’automazione guidata dall’AI. Anche se questa è stata a lungo una sfida nel campo della tecnologia, la velocità e la portata dello sviluppo dell’AI hanno intensificato drasticamente il problema.
3. Gli user agent non forniscono più segnali affidabili
Per anni, gli user agent hanno fornito uno dei segnali di identità più affidabili sul web. Uno user agent identificava in modo affidabile il browser, il sistema operativo e, a volte, il dispositivo da cui proveniva una richiesta. I sistemi si basavano fortemente su questi identificatori per distinguere tra browser legittimi, crawler dei motori di ricerca, dispositivi mobili e bot automatizzati.
Quel modello sta crollando. I bot moderni sono in grado di mascherarsi, falsificare o manipolare gli user agent in modo così efficace che il segnale stesso sta diventando sempre meno affidabile. Un bot dannoso ora può fingersi un browser legittimo, imitare un dispositivo mobile o persino travestirsi da crawler affidabile. L’automazione basata sull’intelligenza artificiale ha accelerato questa tendenza, rendendo più facile ed economico implementare su larga scala sofisticate tecniche di impersonificazione.
Di conseguenza, i moderni sistemi di sicurezza si basano sempre più sul comportamento piuttosto che sulla sola identità.
Come individuare i bot oggi
Dato che la reputazione dell’IP e altri segnali tradizionali non sono più del tutto affidabili, i sistemi di rilevamento cercano sempre più spesso modelli comportamentali che suggeriscano automazione o attività dannose.
Le richieste che arrivano a velocità, su scala e con una frequenza impossibili da riprodurre per un essere umano rimangono uno dei segnali di allarme più evidenti. Tentativi di accesso ripetuti, comportamenti di scraping altamente sequenziali, uso aggressivo delle API e grandi picchi di richieste spesso indicano che c’è dell’automazione in atto.
I dati dell’infrastruttura di Kinsta hanno registrato un singolo bot che ha generato 3,75 milioni di richieste verso URL di “aggiungi al carrello” su un sito in 24 ore, ovvero circa una richiesta ogni 23 millisecondi, per tutto il giorno, ognuna delle quali raggiungeva il server come una nuova richiesta non memorizzabile nella cache.
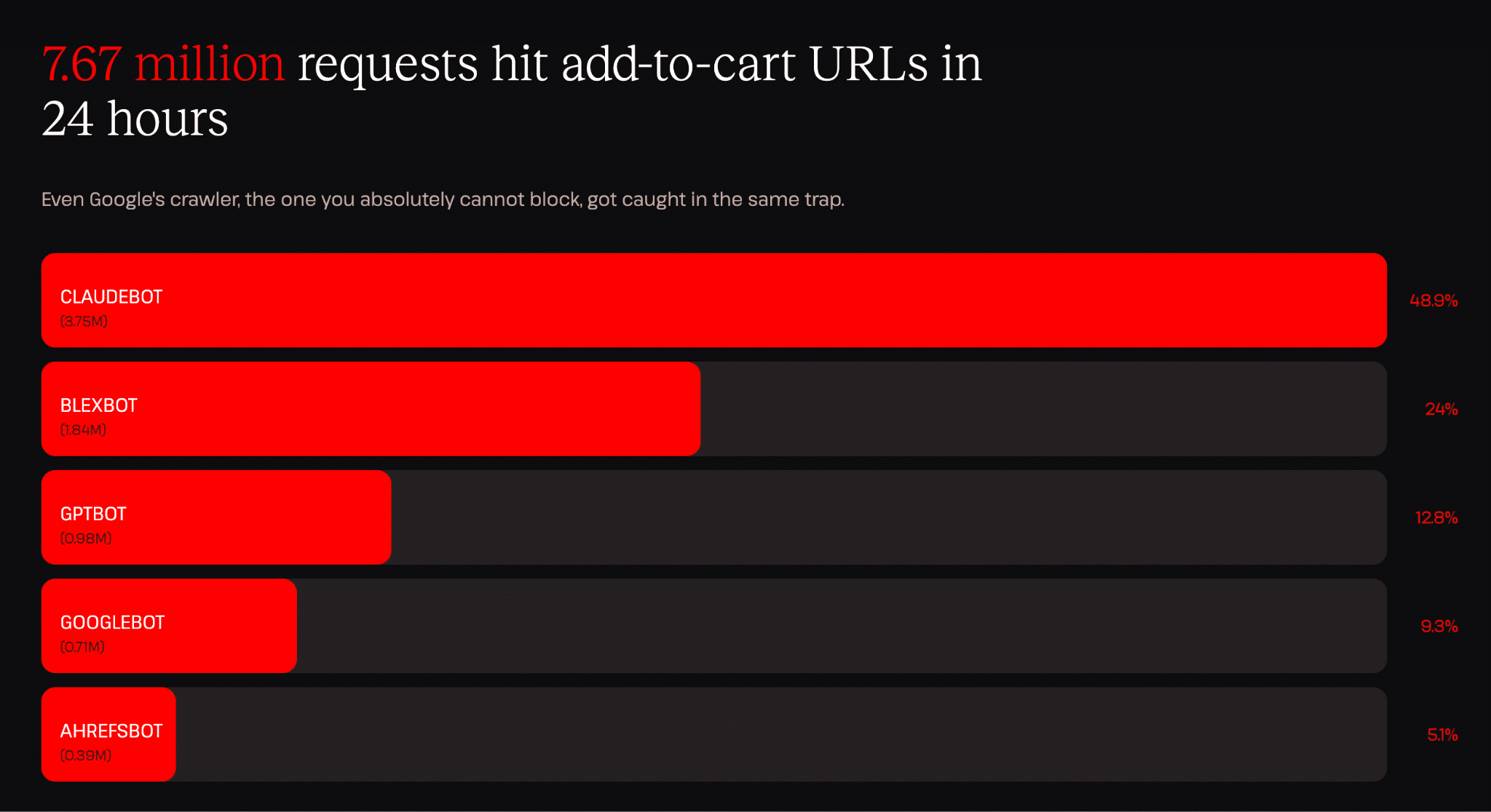
Il comportamento di navigazione umano tende ad essere piuttosto imprevedibile. I bot, anche quelli sofisticati, spesso producono modelli di interazione altamente ripetitivi, flussi di navigazione prevedibili o un’estrazione insolitamente sistematica, anche quando riescono a imitare con successo l’esecuzione di JavaScript, sessioni di navigazione realistiche e i movimenti del mouse. Ecco perché il rilevamento si è orientato verso la valutazione dell’intento comportamentale piuttosto che dell’identità dichiarata.
Noi di Kinsta usiamo proprio questa logica per classificare il traffico sui siti gestiti. Anziché una semplice distinzione binaria “umano o bot”, il nostro sistema di protezione dai bot opera su sei categorie: bot verificati, probabilmente persone, probabilmente bot, traffico automatizzato, traffico non classificato e traffico dannoso, con una designazione separata per i crawler AI a frequenza eccessiva che, pur essendo verificati, generano un carico che mette a dura prova l’infrastruttura indipendentemente dall’intento.
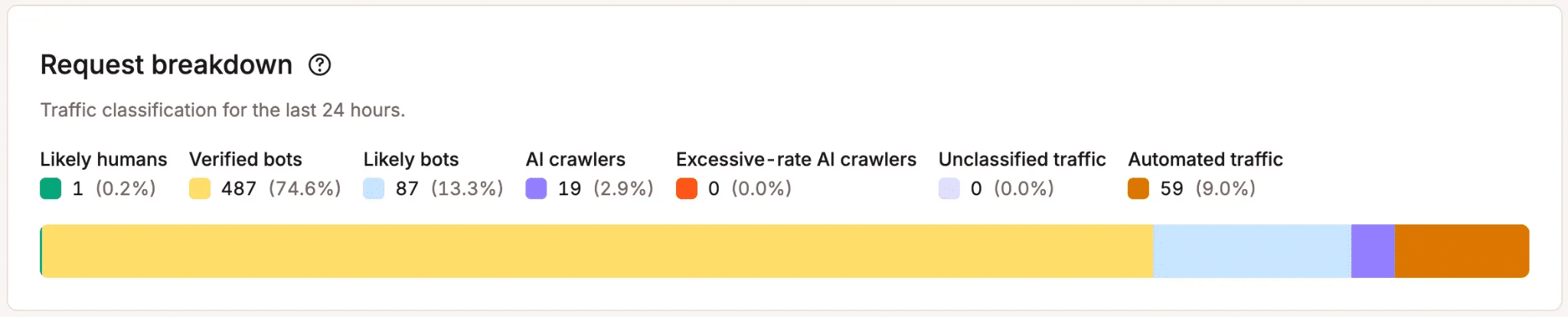
Ogni categoria viene gestita in modo diverso perché la risposta giusta a un crawler di addestramento AI configurato male non è la stessa che si darebbe a un attacco di credential stuffing. Per impostazione predefinita, le difese a livello di piattaforma di Kinsta bloccano circa il 15–20% del traffico classificato come dannoso prima ancora che raggiunga il tuo sito. I livelli di protezione dai bot che vanno oltre questa soglia di base permettono ai proprietari dei siti di mettere in discussione o bloccare ulteriori categorie in base ai propri modelli di traffico e alla propria tolleranza al rischio.

Implicazioni e tendenze da tenere d’occhio
Man mano che questi sistemi si evolvono, le implicazioni vanno ben oltre la sola sicurezza informatica e iniziano a influenzare le infrastrutture, l’editoria, l’analisi dei dati, l’e-commerce e la qualità complessiva del web stesso.
C’è qualcosa all’orizzonte che potrebbe rallentare la crescita del traffico dei bot? I dati suggeriscono di no. Il traffico dei bot basati sull’intelligenza artificiale è aumentato del 300% in un solo anno, e il rapporto tra le visite dei bot basati sull’intelligenza artificiale è passato da 1 su 200 a 1 su 31 in meno di 12 mesi. Come dice Daniel Pataki, CTO di Kinsta: «Su larga scala, il crawling inefficiente smette di essere un problema di traffico e diventa un problema di risorse». Le condizioni che determinano questa crescita non stanno migliorando.
Costi dell’infrastruttura di hosting
Uno degli effetti più immediati dell’aumento del traffico dei bot è l’aumento dei costi dell’infrastruttura. Ogni richiesta a un sito web consuma larghezza di banda, risorse di calcolo, query al database, memoria, sistemi di caching e infrastruttura di archiviazione.
Il problema è particolarmente grave sui siti WordPress che utilizzano WooCommerce, funzioni di ricerca o plugin molto pesanti. A differenza delle pagine statiche fornite dalla cache, gli endpoint dinamici richiedono al server di svolgere un lavoro effettivo su ogni singola richiesta. Un bot intrappolato in un ciclo di stringhe di query non è in grado di distinguere tra una pagina memorizzabile nella cache e una che richiede molte risorse. Un singolo ciclo di questo tipo su un sito gestito da Kinsta ha generato 550 milioni di richieste in 30 giorni prima che una regola di mitigazione dedicata lo intercettasse.
Come dice Daniel Pataki: «Non esiste una cosa come il “semplice traffico dei bot”. Ogni richiesta è un lavoro vero e proprio. Su larga scala, il crawling inefficiente smette di essere un problema di traffico e diventa un problema di risorse».
Gli editori più piccoli e i proprietari di siti indipendenti sono particolarmente vulnerabili perché spesso non dispongono dei sistemi di mitigazione di livello aziendale a disposizione delle organizzazioni più grandi.
Analisi distorte
Il traffico dei bot basati sull’intelligenza artificiale distorce sempre più le metriche analitiche in modi che possono essere altamente fuorvianti. Visualizzazioni di pagina gonfiate, engagement falso, traffico di provenienza artificiale e interazioni automatizzate possono portare chi prende le decisioni a trarre conclusioni errate da dati inaffidabili.
Il problema si aggrava man mano che i bot diventano sempre più simili agli esseri umani. Gli strumenti che si basano sul tracciamento JavaScript, come Google Analytics, tendono a sottostimare l’attività dei bot perché molti di essi non eseguono JavaScript. Le analisi a livello di server, che contano ogni richiesta basata sull’IP, tendono invece a sovrastimarla perché rilevano i bot che JavaScript non rileva.
Da Kinsta, le statistiche di MyKinsta si basano sui log di accesso a livello di server ed escludono esplicitamente gli user agent noti dei bot dal conteggio delle visite fatturabili, ma anche questa distinzione ha i suoi limiti, perché il traffico automatizzato che imita da vicino il comportamento umano può comunque comparire nei numeri riportati.
Da novembre 2025, le classifiche delle richieste più frequenti di Kinsta hanno iniziato a riflettere tutto il traffico, compresi i bot, proprio per dare ai proprietari dei siti un quadro più chiaro di ciò che sta effettivamente gravando sulla loro infrastruttura rispetto a ciò che viene fatturato.
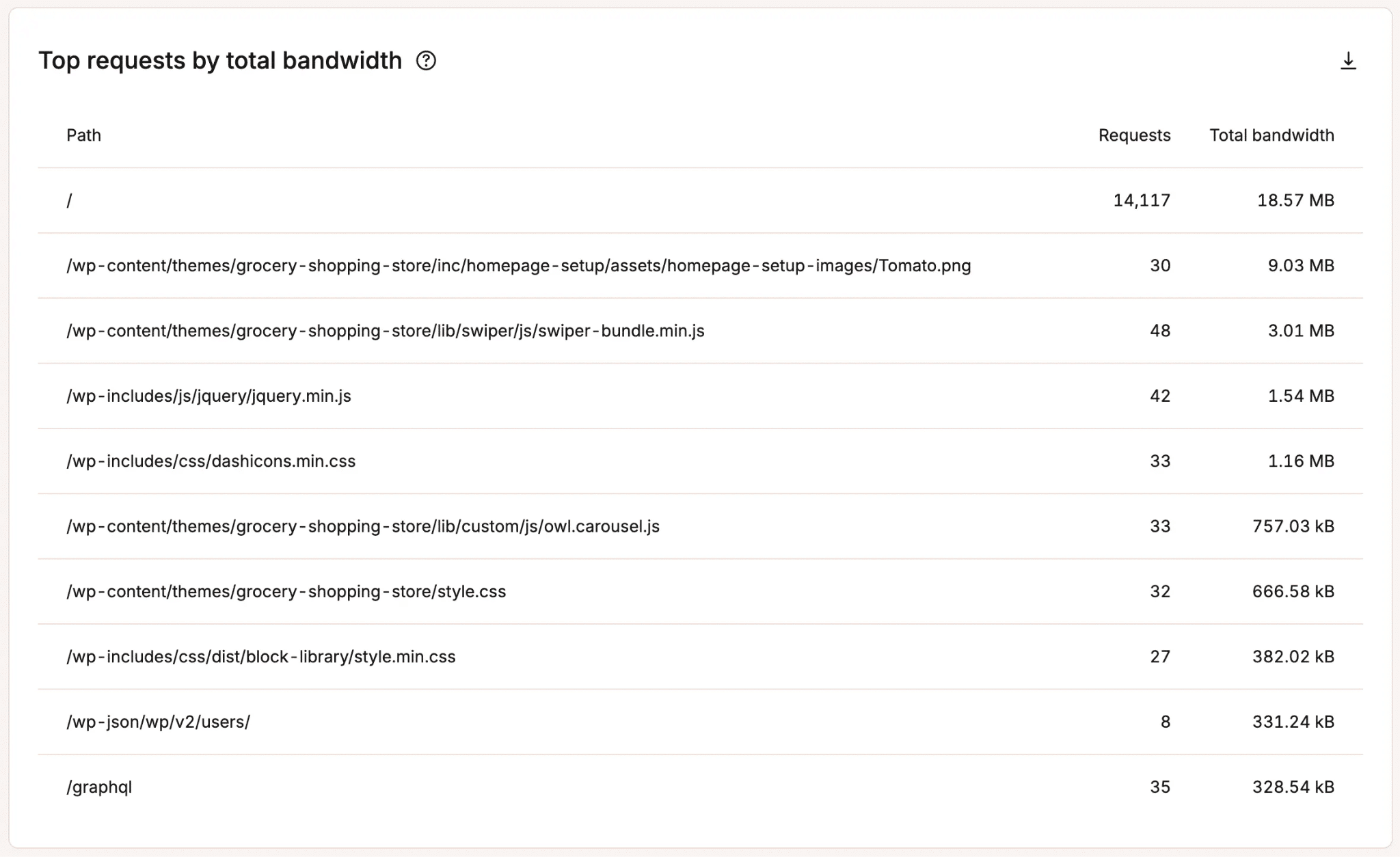
Quando le visualizzazioni delle tue pagine sono in aumento ma il volume delle ricerche relative al tuo brand, le conversioni e il traffico diretto rimangono stabili, quasi sicuramente sono i bot a causare questo divario.
L’avvento del “web morto”
Il cosiddetto fenomeno del “web morto” si riferisce alla crescente marea di contenuti di bassa qualità generati automaticamente che invadono Internet. Sebbene alcune delle versioni più estreme di questa teoria scivolino nella speculazione, non c’è dubbio che l’intelligenza artificiale stia rendendo incredibilmente più facile generare articoli sintetici, recensioni false, blog spam, contenuti multimediali automatizzati e contenuti di scarso valore su vasta scala.
Il risultato potrebbe essere un web inquinato in cui trovare informazioni affidabili e davvero utili diventa sempre più difficile.
Maggiori rischi per la sicurezza causati dai bot dannosi
I bot basati sull’AI stanno aumentando notevolmente la sofisticazione degli attacchi informatici. Gli attacchi di credential stuffing, le prese di controllo degli account, l’abuso delle API, le campagne di phishing, la scansione delle vulnerabilità e la diffusione di ransomware stanno diventando più veloci, più scalabili e più adattabili grazie all’automazione.
Poiché i sistemi di AI sono in grado di imparare dagli errori e perfezionare continuamente i propri metodi, le difese tradizionali basate su regole faticano sempre di più a tenere il passo.
L’economia degli scraper e l’inversione economica
Storicamente, i crawler di ricerca come Googlebot hanno creato un rapporto economico relativamente equilibrato con gli editori. Esploravano i contenuti, li indicizzavano e poi reindirizzavano il traffico verso i siti web di origine.
I moderni sistemi di scraping basati sull’AI stanno cambiando questo rapporto. Sempre più spesso, i sistemi di AI estraggono i contenuti, riassumono le informazioni altrove e forniscono risposte direttamente senza necessariamente reindirizzare il traffico alla fonte originale. Questo crea una crescente “economia degli scraper”, in cui editori e creatori si fanno carico dei costi di produzione dei contenuti e di manutenzione dell’infrastruttura, mentre i sistemi automatizzati si appropriano di gran parte del valore a valle.
Browser basati sull’AI e agenti autonomi
Questi sistemi stanno andando ben oltre la semplice scansione del web. Gli agenti basati sull’AI ora possono navigare sul web, interagire con le applicazioni, fare ricerche, fare acquisti online, fissare appuntamenti, compilare moduli e prendere decisioni con un coinvolgimento umano minimo o nullo.
Man mano che questi sistemi continuano a migliorare, il confine tra l’attività umana e quella guidata dalle macchine sta diventando sempre più difficile da distinguere. Questo cambiamento potrebbe modificare radicalmente il significato stesso di “traffico web” in futuro.
Internet è stato originariamente costruito partendo dal presupposto che gli esseri umani fossero i protagonisti principali. Questo presupposto si sta rapidamente sgretolando. Man mano che l’automazione basata sull’intelligenza artificiale diventa sempre più autonoma, il futuro del web potrebbe dipendere meno dalla distinzione tra esseri umani e bot e più dalla decisione su quale tipo di Internet guidato dalle macchine siamo disposti ad accettare.
Il confine tra uomo e macchina è scomparso
L’impatto di questo cambiamento va ben oltre quanto la maggior parte di chi gestisce di siti si renda conto. I costi delle infrastrutture stanno aumentando. È sempre più difficile fidarsi dei dati analitici. L’economia degli scraper sta spostando il valore dagli editori che creano contenuti verso i sistemi che li estraggono. E man mano che gli agenti basati sull’intelligenza artificiale diventano capaci di navigare, ricercare e prendere decisioni in modo autonomo, la domanda non è più «come gestisco il traffico dei bot», ma diventa qualcosa di più ampio.
Internet è stato costruito partendo dal presupposto che ci fosse una persona dall’altra parte di ogni richiesta. Questo presupposto si sta sgretolando più velocemente di quanto le infrastrutture, le normative e i modelli di business costruiti su di esso riescano ad adattarsi.
Siamo ormai in piena era in cui le macchine comunicano tra loro senza bisogno dell’intervento umano.
Per un’analisi più approfondita dei dati alla base di questo cambiamento, leggi il rapporto completo di Kinsta sul traffico AI e bot. Se stai già notando gli effetti sul tuo sito, Protezione bot di Kinsta ti offre gli strumenti necessari per gestirli.

Bud Kraus has been working with WordPress as an in-class and online instructor, site developer, and content creator since 2009. He has produced instructional videos and written many articles for WordPress businesses.

