
Il concetto di archiviazione persistente (o storage persistente) si riferisce alla conservazione non volatile dei dati, in modo che rimangano disponibili anche dopo lo spegnimento di un dispositivo o il riavvio di un’applicazione. L’archiviazione e il recupero dei dati consentono alle applicazioni web di salvare le informazioni e gli stati degli utenti e di operare in modo affidabile.
Nelle applicazioni monolitiche, l’accesso all’archiviazione è semplice perché il server e l’archiviazione vivono insieme. Tuttavia, nei sistemi distribuiti geograficamente l’accesso è più complesso, poiché il sistema di archiviazione deve rimanere disponibile per tutti i componenti in tutto il mondo.
La piattaforma containerizzata di Hosting di Applicazioni di Kinsta utilizza i volumi persistenti di Kubernetes per associare l’archiviazione persistente con uno o più processi di un’applicazione. Gli utenti di Kinsta possono definire i propri requisiti di archiviazione persistente durante la creazione di applicazioni all’interno di MyKinsta.
In questo articolo analizzeremo lo storage persistente indipendentemente dalla piattaforma, esplorandone i tipi, l’architettura e i casi d’uso. In aggiunta, offriremo una dimostrazione pratica per illustrare la differenza tra archiviazione a volume e archiviazione a volume persistente in Docker.
Tipi di archiviazione persistente
Esistono diversi tipi di archiviazione non volatile, tra cui i tradizionali spinning disk (hard disk o HDD), i drive solid-state (SSD), i NAS (Network Attached Storage) e le SAN (Storage Area Network).
- Gli HDD sono dispositivi elettromeccanici di archiviazione dati che memorizzano e recuperano dati digitali utilizzando spinning disk di supporti magnetici. I dischi usano testine magnetiche su un braccio attuatore mobile che legge e scrive i dati.
- Le SSD, talvolta chiamate dispositivi di archiviazione a semiconduttore, dispositivi a stato solido o dischi a stato solido, usano circuiti integrati per memorizzare i dati in modo persistente, di solito tramite dispositivi flash interconnessi che non contengono parti in movimento. La loro natura stazionaria li rende più veloci e affidabili degli HDD.
- Il network-attached storage è un gruppo di HDD, SSD o entrambi, collegati attraverso una rete locale che usa un file system come il New Technology File System (NTFS) o il quarto file system esteso (EXT4).
- Le SAN sono dispositivi di archiviazione ad alta velocità e a livello di blocco collegate in rete, come librerie a nastro o array di dischi. La loro connessione appare al sistema operativo come un’archiviazione locale e non è accessibile attraverso la rete locale (LAN).
Architettura dell’archiviazione persistente
Esistono tre approcci all’archiviazione persistente, ognuno con casi d’uso e limitazioni particolari.
Architettura persistente a oggetti
L’approccio dell’architettura persistente a oggetti usa la mappatura oggetto-relazionale (ORM) per archiviare i dati come oggetti in un database relazionale o a chiave-valore. Questo approccio è utile quando i dati non hanno uno schema definito, in quanto l’ORM ne gestisce l’archiviazione e il recupero.
Architettura persistente a blocchi
L’architettura persistente a blocchi usa dispositivi di archiviazione a livello di blocco, utili per l’archiviazione di file di grandi dimensioni. Questo approccio è vantaggioso per l’archiviazione di grandi quantità di dati, in quanto è possibile usare più blocchi per aumentare la capacità di archiviazione.
Architettura persistente di filestore
Come suggerisce il nome, l’approccio dell’architettura persistente di filestore usa un file system per archiviare i dati. Un metodo prevede l’utilizzo di server di database, che forniscono una soluzione centralizzata di archiviazione dei dati. Le soluzioni di cloud hosting come quella di Kinsta impiegano server di database che possono essere facilmente collegati alle applicazioni e offrono persistenza.
L’architettura persistente di filestore è utile nelle applicazioni che richiedono il recupero frequente dei file e, quando è necessaria, un’interfaccia per gestirli.
Casi d’uso dell’archiviazione persistente
Questa sezione illustra alcuni casi d’uso di ciascun tipo di storage.
Archiviazione persistente a oggetti
- Cloud storage: L’archiviazione persistente a oggetti è spesso utilizzata nelle soluzioni di cloud storage per archiviare e recuperare grandi quantità di dati non strutturati, come immagini, video e documenti. I cloud provider utilizzano lo storage a oggetti per fornire ai clienti servizi di archiviazione scalabili, altamente disponibili e duraturi.
- Analisi di big data: L’archiviazione persistente a oggetti si usa nell’analisi dei big data per archiviare e gestire grandi set di dati spesso utilizzati per analisi dei dati, machine learning e intelligenza artificiale. L’archiviazione a oggetti consente di accedere ai dati in modo rapido ed efficiente, e questo lo rendende un componente chiave delle architetture di big data.
- Content Delivery Network: L’archiviazione persistente a oggetti viene utilizzata nelle Content Delivery Network (CDN) per archiviare e distribuire contenuti come immagini, video e file statici, attraverso una rete globale di server. L’archiviazione a oggetti consente alle CDN di fornire contenuti ad alta velocità agli utenti di tutto il mondo, indipendentemente dalla loro posizione.
Archiviazione persistente a blocchi
- High-performance computing (HPC): gli ambienti HPC elaborano in modo rapido ed efficiente grandi volumi di dati. L’archiviazione persistente a blocchi consente ai cluster HPC di archiviare e recuperare grandi insiemi di dati, come simulazioni scientifiche, modelli meteorologici e analisi finanziarie. L’archiviazione a blocchi è spesso preferita per l’HPC perché fornisce un accesso ai dati ad alte prestazioni e a bassa latenza e consente operazioni di input/output (I/O) parallele, che possono migliorare notevolmente i tempi di elaborazione.
- Editing video: le applicazioni di editing video richiedono accesso ad alte prestazioni e a bassa latenza a file video di grandi dimensioni. Devono inoltre gestire un numero significativo di operazioni di I/O al secondo e una bassa latenza per renderizzare e modificare i file video in tempo reale. L’archiviazione a blocchi offre queste funzionalità, e ciò la rendende una soluzione ideale per l’editing video.
- Gaming: anche le applicazioni di gaming richiedono prestazioni elevate e bassa latenza per accedere alle risorse di gioco e ai dati dei giocatori. L’archiviazione a blocchi memorizza e recupera rapidamente grandi quantità di dati, facendo in modo che gli ambienti di gioco carichino rapidamente e rimangano reattivi durante il gioco.
Archiviazione persistente di filestore
- Media e intrattenimento: l’archiviazione persistente è spesso utilizzata in applicazioni di editing video, animazione e rendering. Queste applicazioni richiedono un accesso ad alte prestazioni e a bassa latenza a file multimediali di grandi dimensioni, come video, audio e immagini. Il filestore offre un file system condiviso a cui possono accedere più client, il che lo rende una soluzione ideale di archiviazione per queste applicazioni.
- Gestione dei contenuti web: i sistemi di gestione dei contenuti web (CMS) impiegano l’archiviazione persistente di filestore in file system condivisi per archiviare e gestire i contenuti dei siti web, come testi, immagini e file multimediali. Il filestore fornisce una posizione centrale per i contenuti del sito, facilitandone la gestione e l’aggiornamento. Inoltre, consente a più utenti di lavorare contemporaneamente sugli stessi contenuti, migliorando le possibilità di collaborazione e la produttività.
Archiviazione persistente nei container
I container sono leggeri, portabili e sicuri e permettono la fusione di applicazioni diverse. Devono avere un meccanismo di persistenza dei dati tra il riavvio e la rimozione del container. I container hanno un archivio di file o un file system come le applicazioni tradizionali, ma ogni volta che vengono ricostruiti con nuove modifiche, si perdono tutti i dati non persistenti.
Ecco perché i container offrono la possibilità di includere o di montare un volume di archiviazione. I container trattano i volumi di archiviazione come una directory. Tutti i dati scritti sul volume finiscono nel file system dell’host.
È necessario che l’archiviazione persistente per i container funzioni in questo modo perché il riavvio di un container crea una nuova istanza e scarta quella vecchia. Se un container non ha una visione coerente dei dati, questi scompariranno al riavvio del container. Un volume di archiviazione conserva i dati tra le sessioni e i riavvii del container, consentendo di mantenerne lo stato anche se viene spostato o riavviato.
Volume vs. volume persistente
I container offrono due modi per memorizzare i dati persistenti: l’utilizzo di volumi e di volumi persistenti. C’è una differenza significativa tra i due. Un container gestisce i dati nell’archiviazione dei volumi. Quando si arresta un container, i dati rimangono disponibili per il riavvio. Tuttavia, quando si elimina o rimuove un container, i dati vengono persi perché viene eliminato anche il volume di archiviazione sottostante.
L’archiviazione persistente del volume, o bind mount, archivia i dati al di fuori del file system del container. In questo modo, i dati non vengono persi nemmeno eliminando il container. Sono persistenti fino a quando non vengono cancellati manualmente.
La sezione seguente illustra enrambi i tipi di volume con degli esempi.
Demo dell’archiviazione persistente del container
Abbiamo creato una piccola applicazione web per dimostrare l’archiviazione persistente con i container Docker. Per seguirla, basta installare Docker e scaricare il codice da questo repository GitHub.
L’applicazione è un modulo elementare con due campi per l’input dell’utente:
- Titolo
- Testo del documento
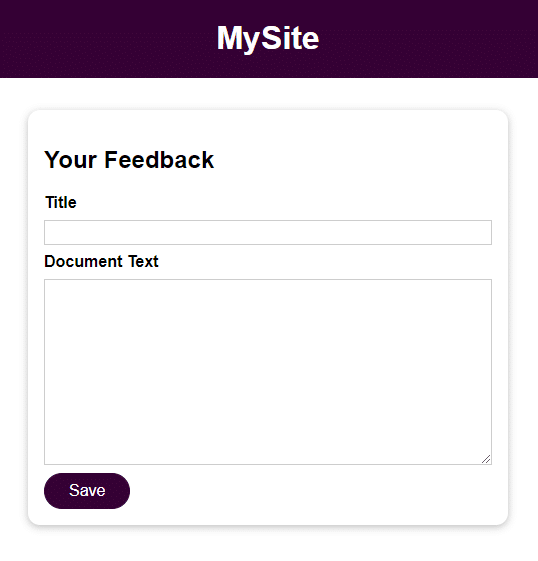
Una volta salvato l’input dell’utente, si potrà accedervi aprendo il file nella directory feedback con il nome indicato nel campo Titolo. I dati inseriti nel campo Testo del documento sono il contenuto del file.
Come utilizzare il volume di archiviazione
Una volta installata l’applicazione, questa può utilizzare il volume di archiviazione come mostrato nel Dockerfile.
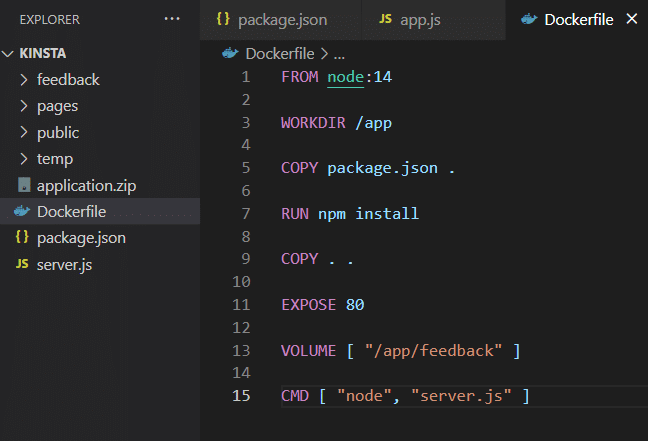
A questo punto, è possibile eseguire la build dell’immagine ed avviare il container:
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Una volta che l’applicazione è in esecuzione, si potrà andare su localhost:3000 per inviare il feedback.
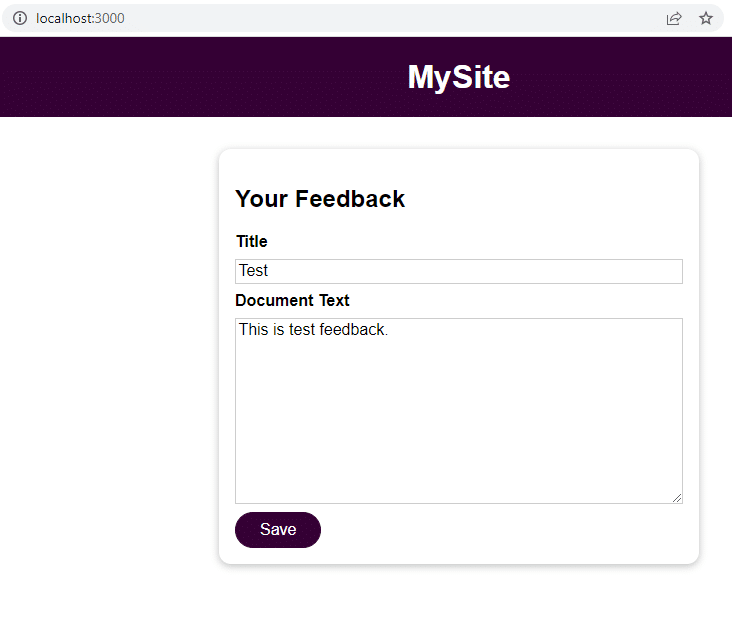
Ora bisogna far clic su Salva e andare su localhost:3000/feedback/test.txt per vedere se l’input è stato memorizzato correttamente.
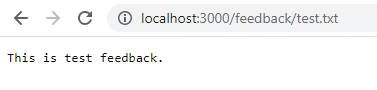
Ora si potrà rimuovere e riavviare il container per vedere se l’input persiste.
docker stop feedback-app
docker start feedback-appAccedendo allo stesso URL, si vedrà che il feedback è ancora presente. Ma cosa succede fermando e riavviando il container?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesUna volta riavviato, tornando a quell’URL, si vedrà che non esiste più perché i dati sono andati persi quando il container è stato rimosso. I dati del volume persistono solo quando si arresta il container, non quando lo si rimuove.
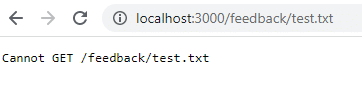
Per ovviare a questo problema e mantenere i dati anche quando si rimuove il container, è necessario utilizzare l’archiviazione persistente del volume o un named storage. Per prima cosa, bisogna pulire i container e le immagini:
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesCome utilizzare l’archiviazione a volume persistente
Prima di provare, dovete rimuovere l’attributo VOLUME dal file Docker e ricostruire l’immagine.
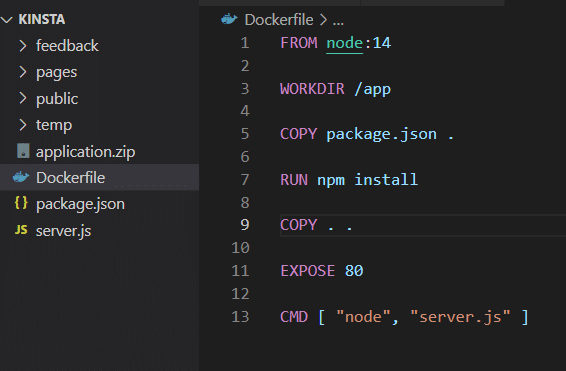
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesNel secondo comando si usa il flag -v per definire il volume persistente all’esterno del container, che persiste anche se si rimuove il container.
Come nel passaggio precedente, si può ora provare ad aggiungere un feedback e ad accedervi dopo aver fermato, rimosso e riavviato il container.
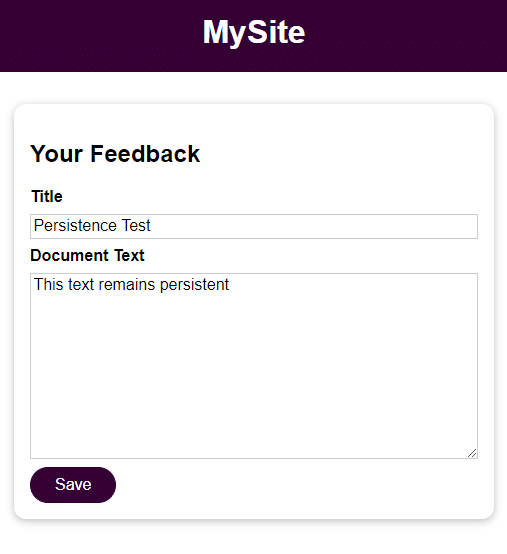
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesOra i dati rimangono accessibili anche dopo aver fermato e rimosso il container.
Riepilogo
L’archiviazione persistente è fondamentale per le applicazioni containerizzate perché permette di conservare i dati al di fuori del ciclo di vita del container. I due principali tipi di archiviazione persistente per le applicazioni containerizzate sono i volumi e i mount bind, ognuno con i suoi vantaggi e i suoi casi d’uso.
I volumi sono memorizzati all’interno del file system del container, mentre i bind mount sono direttamente accessibili sul computer host.
L’archiviazione persistente permette di condividere i dati tra i container, rendendo possibile la creazione di applicazioni complesse e multi-tier. L’archiviazione persistente è essenziale per garantire la stabilità e la continuità delle applicazioni containerizzate, fornendo una soluzione affidabile e flessibile per archiviare dati critici.
State sviluppando un’applicazione che richiede uno storage persistente? Date un’occhiata alla nostra libreria di esempi di avvio rapido per vedere come distribuire l’applicazione su Kinsta da host Git come GitHub, GitLab, e Bitbucket.
La nostra documentazione ufficiale sull’archiviazione persistente vi aiuterà a mettere online rapidamente la vostra applicazione e i relativi dati.

Steve Bonisteel è un Technical Editor di Kinsta che ha iniziato la sua carriera di scrittore come giornalista della carta stampata, inseguendo ambulanze e camion dei pompieri. Dalla fine degli anni '90 si occupa di tecnologia legata a Internet.

