
Nel mondo di oggi incentrato sui dati, in cui il volume e la complessità dei dati stessi continuano a crescere a un ritmo senza precedenti, la necessità di soluzioni di database robuste e scalabili è diventata fondamentale. Si stima che entro il 2025 verranno creati 180 zettabyte di dati. Si tratta di numeri importanti su cui riflettere.
Con l’aumento dei dati e della domanda degli utenti, affidarsi a un unico database diventa impraticabile. Rallenta il sistema e mette in difficoltà gli sviluppatori. Fortunatamente, si possono adottare diverse soluzioni per ottimizzare il proprio database, come ad esempio lo sharding del database.
In questa guida, ci addentreremo nelle profondità dello sharding di MongoDB, analizzandone i vantaggi, i componenti, le best practice, gli errori più comuni e le modalità per iniziare a usarlo.
Cos’è lo sharding dei database?
Lo sharding dei database è una tecnica di gestione dei database che prevede la suddivisione orizzontale di un database in crescita in unità più piccole e gestibili, note come shard.
Quando un database si espande, diventa pratico dividerlo in diverse parti più piccole e memorizzare ciascuna parte separatamente su macchine diverse. Queste parti più piccole sono sottoinsiemi indipendenti del database complessivo. Questo processo di divisione e distribuzione dei dati costituisce lo sharding del database.
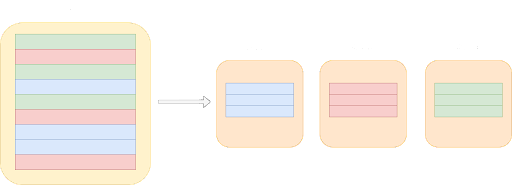
Quando si implementa un database shardato, esistono due approcci principali: sviluppare una soluzione di sharding personalizzata o pagarne una esistente. Questo porta a domandarsi se sia più opportuno creare una soluzione di sharding o pagarne una.

Per fare questa scelta, è necessario considerare il costo dell’integrazione di terze parti, tenendo presente i seguenti fattori:
- Capacità degli sviluppatori e apprendimento: la curva di apprendimento associata al prodotto e il suo grado di allineamento con le competenze dei propri sviluppatori.
- Il modello di dati e le API offerte dal sistema: ogni sistema di dati ha un proprio modo di rappresentare i dati. La convenienza e la facilità con cui si possono integrare le applicazioni con il prodotto è un fattore chiave da considerare.
- Assistenza clienti e documentazione online: nei casi in cui si incontrassero delle difficoltà o si dovesse richiedere assistenza durante l’integrazione, la qualità e la disponibilità del supporto clienti e di una documentazione online completa diventano fondamentali.
- Disponibilità di implementazione nel cloud: dato che sempre più aziende passano al cloud, è importante stabilire se il prodotto di terze parti può essere implementato in un ambiente cloud.
In base a questi fattori, si può decidere di creare una soluzione di sharding o di pagare una soluzione che faccia il lavoro pesante al posto vostro.
Oggi la maggior parte dei database presenti sul mercato supporta lo sharding dei database. Ad esempio, i database relazionali come MariaDB (parte dello stack di server ad alte prestazioni di Kinsta) e i database NoSQL come MongoDB.
Cos’è lo sharding in MongoDB?
Lo scopo principale dell’utilizzo di un database NoSQL è la sua capacità di gestire le richieste di calcolo e di archiviazione di volumi enormi di dati.
In genere, un database MongoDB contiene un gran numero di raccolte. Ogni raccolta è composta da vari documenti che contengono dati sotto forma di coppie chiave-valore. È possibile suddividere questa grande raccolta in diverse raccolte più piccole utilizzando lo sharding di MongoDB. Questo permette a MongoDB di eseguire le query senza gravare troppo sul server.
Ad esempio, Telefónica Tech gestisce oltre 30 milioni di dispositivi IoT in tutto il mondo. Per stare al passo con l’utilizzo sempre crescente dei dispositivi, avevano bisogno di una piattaforma in grado di scalare in modo elastico e di gestire un ambiente di dati in rapida crescita. La tecnologia di sharding di MongoDB è stata la scelta giusta per l’azienda, poiché era la più adatta alle sue esigenze di costo e capacità.
Con lo sharding di MongoDB, Telefónica Tech esegue oltre 115.000 query al secondo. Si tratta di 30.000 inserimenti nel database al secondo, con meno di un millisecondo di latenza!
Vantaggi dello sharding di MongoDB
Ecco alcuni vantaggi dello sharding di MongoDB per i dati su larga scala di cui poter usufruire:
Capacità di archiviazione
Abbiamo già visto che lo sharding distribuisce i dati tra gli shard del cluster. Questa distribuzione permette a ogni shard di contenere un frammento dei dati totali del cluster. Gli shard in più aumentano la capacità di archiviazione del cluster quando i dati crescono di dimensioni.
Letture/Scritture
MongoDB distribuisce il carico di lavoro in lettura e scrittura tra gli shard di un cluster sharded, o soggetto a sharding, consentendo a ogni shard di elaborare un sottoinsieme di operazioni del cluster. Entrambi i carichi di lavoro possono essere scalati orizzontalmente nel cluster aggiungendo altri shard.
Alta disponibilità
L’implementazione di shard e server di configurazione come set di replica offre una maggiore disponibilità. Ora, anche se uno o più set di replica shard diventano completamente non disponibili, il cluster sharded può eseguire letture e scritture parziali.
Protezione dalle interruzioni
Gli utenti colpiti quando una macchina si rompe a causa di un’interruzione non pianificata possono essere davvero molti. In un sistema non soggetto a sharding l’impatto sarebbe enorme, dato che l’intero database andrebbe fuori uso. Il raggio d’azione di una cattiva esperienza/impatto sugli utenti può essere contenuto grazie allo sharding di MongoDB.
Distribuzione geografica e prestazioni
Gli shard replicati possono essere collocati in regioni diverse. Ciò significa che i clienti possono accedere ai loro dati a bassa latenza, ovvero reindirizzare le richieste dei consumatori allo shard più vicino a loro. In base alla politica di governance dei dati di una regione, è possibile configurare shard specifici da collocare in una regione specifica.
Componenti dei cluster soggetti a sharding di MongoDB
Dopo aver spiegato il concetto di cluster shardati di MongoDB, analizziamone i componenti.
1. Shard
Ogni shard ha un sottoinsieme di dati shardati. A partire da MongoDB 3.6, gli shard devono essere distribuiti come set di repliche per garantire alta disponibilità e ridondanza.
Ogni database nel cluster soggetto a sharding ha uno shard primario che conterrà tutte le raccolte non shardate di quel database. Lo shard primario non è collegato al primario in un set di replica.
Per cambiare lo shard primario di un database, si può usare il comando movePrimary. Il processo di migrazione dello shard primario potrebbe richiedere molto tempo per essere completato.
Durante questo periodo, sarebbe meglio non tentare di accedere alle raccolte associate al database fino al completamento del processo di migrazione. Questo processo potrebbe avere un impatto sulle operazioni complessive del cluster in base alla quantità di dati da migrare.
È possibile usare il metodo sh.status() di mongosh per vedere la panoramica del cluster. Questo metodo restituisce lo shard primario del database e la distribuzione dei pezzi tra gli shard.
2. Server di configurazione
Distribuire i server di configurazione per i cluster sharded come set di repliche migliorerebbe la coerenza del server di configurazione. Questo perché MongoDB può sfruttare i protocolli standard di lettura e scrittura dei set di replica per i dati di configurazione.
Per distribuire i server di configurazione come set di replica, sarà necessario eseguire il motore di archiviazione WiredTiger. WiredTiger utilizza il controllo della concorrenza a livello di documento per le sue operazioni di scrittura. Pertanto, più client possono modificare contemporaneamente documenti diversi di una raccolta.
I server di configurazione memorizzano i metadati di un cluster sharded nel database di configurazione. Per accedere al database di configurazione, si può utilizzare il seguente comando nella shell di mongo:
use configCi sono alcune restrizioni da tenere a mente:
- La configurazione di un set di replica utilizzato per i server di configurazione deve avere zero arbitri. Un arbitro partecipa alle elezioni per il primario, ma non ha una copia del dataset e non può diventare primario.
- Questo set di replica non può avere membri delayed. I membri delayed hanno copie del set di dati della replica. Ma il set di dati di un membro delayed contiene uno stato precedente o delayed del set di dati.
- È necessario creare degli indici per i server di configurazione. In poche parole, nessun membro dovrebbe avere l’impostazione
members[n].buildIndexesimpostata sufalse.
Se il set di replica del server di configurazione perde il suo membro primario e non può eleggerne uno, i metadati del cluster diventano di sola lettura. Sarete ancora in grado di leggere e scrivere dagli shard, ma non si verificheranno suddivisioni o migrazioni di chunk fino a quando il replica set non sarà in grado di eleggere un membro primario.
3. Router di query
Le istanze MongoDB mongos possono fungere da router di query, consentendo alle applicazioni client e ai cluster sharded di connettersi facilmente.
A partire da MongoDB 4.4, mongos può supportare le letture con copertura per ridurre le latenze. Con la lettura con copertura, le istanze mongos invieranno le operazioni di lettura a due membri del set di replica per ogni shard interrogato. I risultati verranno quindi restituiti dal primo rispondente per ogni shard.
Ecco come interagiscono i tre componenti in un cluster shardato:
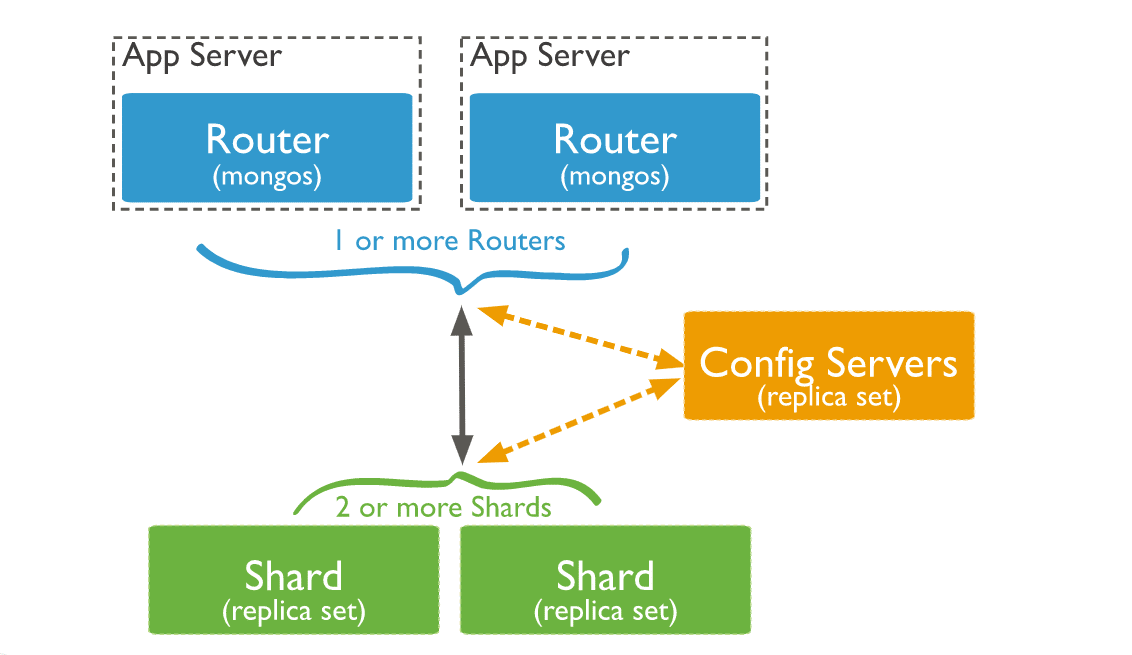
Un’istanza di MongoDB indirizza una query a un cluster:
- Controllando l’elenco degli shard che devono ricevere la query.
- Stabilendo un cursore su tutti gli shard interessati.
Il mongos unirà quindi i dati provenienti da ogni shard e restituirà il documento risultato. Alcuni modificatori della query, come l’ordinamento, vengono eseguiti su ogni shard prima che i mongos recuperino i risultati.
In alcuni casi, quando la chiave dello shard o un prefisso della chiave dello shard fa parte della query, mongos eseguirà un’operazione pre-pianificata, indirizzando le query a una sottoclasse di shard nel cluster.
Per un cluster di produzione, assicuratevi che i dati siano ridondanti e che i sistemi siano altamente disponibili. Potete scegliere la seguente configurazione per l’implementazione di un cluster con shard in produzione:
- Distribuzione di ogni shard come set di replica a 3 membri
- Distribuzione dei server di configurazione come set di replica a 3 membri
- Distribuzione di uno o più router mongos
Per un cluster non di produzione, è possibile distribuire un cluster sharded con i seguenti componenti:
- Un singolo set di replica shard
- Un server di configurazione del set di repliche
- Un’istanza di mongos
Come funziona lo sharding di MongoDB?
Ora che abbiamo parlato dei diversi componenti di un cluster sharded, è il momento di immergerci nel processo.
Per suddividere i dati su più server, utilizzeremo mongos. Quando ci connetteremo per inviare le query a MongoDB, mongos cercherà e troverà dove risiedono i dati. Quindi li prenderà dal server giusto e unirà tutto insieme se sono stati suddivisi su più server.
Dato che il backend si occuperà di questo, non dovremo fare nulla dal lato dell’applicazione. MongoDB si comporterà come una normale connessione di interrogazione. Il client si connetterà a MongoDB e il server di configurazione si occuperà del resto.
Quali sono i passaggi per impostare lo sharding di MongoDB?
L’impostazione dello sharding di MongoDB è un processo che prevede diversi passaggi per garantire un cluster di database stabile ed efficiente. Ecco le istruzioni dettagliate su come impostare lo sharding di MongoDB.
Prima di iniziare, è importante notare che per configurare lo sharding in MongoDB è necessario disporre di almeno tre server: uno per il server di configurazione, uno per l’istanza mongos e uno o più per gli shard.
1. Creare una directory dal server di configurazione
Per iniziare, creeremo una directory per i dati del server di configurazione. Questo può essere fatto con il seguente comando sul primo server:
mkdir /data/configdb2. Avviare MongoDB in modalità Config
Successivamente, avvieremo MongoDB in modalità di configurazione sul primo server utilizzando il seguente comando:
mongod --configsvr --dbpath /data/configdb --port 27019Questo avvierà il server di configurazione su port 27019 e memorizzerà i suoi dati nella directory /data/configdb. Notate che stiamo utilizzando il flag --configsvr per indicare che questo server sarà utilizzato come server di configurazione.
3. Avviare l’istanza Mongos
Il passo successivo consiste nell’avviare l’istanza mongos. Questo processo instraderà le query verso gli shard corretti in base alla chiave di sharding. Per avviare l’istanza mongos, usiamo il seguente comando:
mongos --configdb <config server>:27019Sostituite <config server> con l’indirizzo IP o l’hostname del computer su cui è in esecuzione il server di configurazione.
4. Connettersi all’istanza Mongos
Una volta che l’istanza di Mongos è in esecuzione, possiamo collegarci ad essa utilizzando la shell di MongoDB. Questo può essere fatto con il seguente comando:
mongo --host <mongos-server> --port 27017In questo comando, <mongos-server> deve essere sostituito con il nome dell’host o l’indirizzo IP del server che esegue l’istanza mongos. In questo modo si aprirà la shell di MongoDB, che ci permetterà di interagire con l’istanza di mongos e di aggiungere server al cluster.
Sostituite <mongos-server> con l’indirizzo IP o l’hostname della macchina su cui è in esecuzione l’istanza di mongos.
5. Aggiungere server ai cluster
Ora che siamo connessi all’istanza mongos, possiamo aggiungere i server al cluster con il seguente comando:
sh.addShard("<shard-server>:27017")In questo comando, <shard-server> deve essere sostituito dal nome dell’host o dall’indirizzo IP del server che gestisce lo shard. Questo comando aggiungerà lo shard al cluster e lo renderà disponibile all’uso.
Ripetiamo questo passaggio per ogni shard che vogliamo aggiungere al cluster.
6. Abilitare lo sharding per il database
Infine, abilitiamo lo sharding per un database con il seguente comando:
sh.enableSharding("<database>")In questo comando, <database> deve essere sostituito dal nome del database che volete shardare. In questo modo si abilita lo sharding per il database specificato, permettendoci di distribuire i suoi dati su più shard.
E questo è tutto! Seguendo questi passaggi, dovreste avere un cluster MongoDB shardato perfettamente funzionante e pronto a scalare orizzontalmente e a gestire carichi di traffico elevati.
Le best practice per lo sharding di MongoDB
Dopo aver creato il nostro cluster sharded, il monitoraggio e la manutenzione regolare del cluster sono essenziali per garantire prestazioni ottimali. Alcune best practice per lo sharding di MongoDB includono:
1. Determinare la giusta chiave shard
La chiave di shard è un fattore critico dello sharding di MongoDB che determina la distribuzione dei dati tra gli shard. È importante scegliere una chiave di shard che distribuisca uniformemente i dati tra gli shard e che supporti le query più comuni. Dovreste evitare di scegliere una chiave di shard che provochi hotspot o una distribuzione non uniforme dei dati, in quanto ciò può causare problemi di prestazioni.
Per scegliere la chiave shard giusta, analizzate i dati e i tipi di query che eseguirete e selezionate una chiave che soddisfi questi requisiti.
2. Pianificare la crescita dei dati
Quando configurate il vostro cluster sharded, pianificate la crescita futura iniziando con un numero di shard sufficiente a gestire il carico di lavoro attuale e aggiungendone altri se necessario. Assicuratevi che l’infrastruttura hardware e di rete sia in grado di supportare il numero di shard e la quantità di dati che prevedete di avere in futuro.
3. Usare un hardware dedicato per gli shard
Utilizzate un hardware dedicato per ogni shard per ottenere prestazioni e affidabilità ottimali. Ogni shard dovrebbe avere il proprio server o macchina virtuale, in modo da poter utilizzare tutte le risorse senza alcuna interferenza.
L’utilizzo di hardware condivisi può portare alla contesa delle risorse e al degrado delle prestazioni, con un impatto sull’affidabilità complessiva del sistema.
4. Usare i set di replica per i server shard
L’utilizzo di set di repliche per i server shard offre un’elevata disponibilità e tolleranza agli errori per il cluster sharded di MongoDB. Ogni set di replica dovrebbe avere tre o più membri e ogni membro dovrebbe risiedere su una macchina fisica separata. Questa configurazione garantisce che il cluster shardato possa sopravvivere al guasto di un singolo server o di un membro del replica set.
5. Monitorare le prestazioni degli shard
Il monitoraggio delle prestazioni degli shard è fondamentale per identificare i problemi prima che diventino gravi. Dovreste monitorare la CPU, la memoria, l’I/O del disco e l’I/O di rete di ogni server shard per assicurarvi che lo shard sia in grado di gestire il carico di lavoro.
Per monitorare le prestazioni degli shard si possono utilizzare gli strumenti di monitoraggio integrati di MongoDB, come mongostat e mongotop, oppure strumenti di monitoraggio di terze parti, come Datadog, Dynatrace e Zabbix.
6. Pianificare il disaster recovery
La pianificazione del disaster recovery è essenziale per mantenere l’affidabilità del proprio cluster sharded MongoDB. Dovreste avere un piano di disaster recovery che includa backup regolari, test dei backup per verificarne la validità e un piano per il ripristino dei backup in caso di guasto.
7. Usare lo sharding basato su hashed quando è opportuno
Quando le applicazioni eseguono query basate su intervalli, lo sharding a intervalli è vantaggioso perché le operazioni possono essere limitate a un numero minore di shard, per lo più a un singolo shard. Per implementare questa soluzione è necessario conoscere i dati e i modelli di query.
L’hashed sharding garantisce una distribuzione uniforme delle letture e delle scritture. Tuttavia, non fornisce operazioni efficienti basate sul range.
Quali sono gli errori più comuni da evitare durante lo sharding del database MongoDB?
Lo sharding di MongoDB è una tecnica potente che può aiutarvi a scalare il database in orizzontale e a distribuire i dati su più server. Tuttavia, ci sono diversi errori comuni da evitare quando si esegue lo sharding del proprio database MongoDB. Di seguito elenchiamo alcuni degli errori più comuni e come evitarli.
1. Scegliere la chiave di sharding sbagliata
Una delle decisioni più cruciali che prenderete al momento dello sharding del database MongoDB è la scelta della chiave di sharding. La chiave di sharding determina il modo in cui i dati vengono distribuiti tra gli shard e la scelta di una chiave sbagliata può causare una distribuzione dei dati non uniforme, hotspot e scarse prestazioni.
Un errore comune è quello di scegliere un valore di chiave di shard che aumenti solo per i nuovi documenti quando si utilizza uno sharding basato su un intervallo rispetto a uno sharding con hash. Ad esempio, un timestamp (naturalmente) o qualsiasi cosa che abbia un componente temporale come componente principale, come ObjectID (i primi quattro byte sono un timestamp).
Se selezionate una chiave di shard, tutti gli inserimenti andranno al chunk con l’intervallo maggiore. Anche se continuate ad aggiungere nuovi shard, la capacità massima di scrittura non aumenterà mai.
Se intendete scalare la capacità di scrittura, provate a utilizzare una chiave shard basata su hash, che vi permetterà di utilizzare lo stesso campo e di avere una buona scalabilità in scrittura.
2. Cercare di cambiare il valore della chiave shard
Le chiavi shard sono immutabili per un documento esistente, il che significa che non è possibile cambiare la chiave. È possibile effettuare alcuni aggiornamenti prima dello sharding, ma non dopo. Se provate a modificare la chiave shard per un documento esistente, l’errore sarà il seguente:
cannot modify shard key's value fieldid for collection: collectionnamePotete rimuovere e reinserire il documento per rinnovare la chiave shard invece di provare a modificarla.
3. Mancato monitoraggio del cluster
Lo sharding introduce un’ulteriore complessità nell’ambiente del database, rendendo essenziale un attento monitoraggio del cluster. Il mancato monitoraggio del cluster può causare problemi di prestazioni, perdita di dati e altri problemi.
Per evitare questo errore, è bene impostare degli strumenti di monitoraggio per tenere traccia delle metriche chiave come l’utilizzo della CPU, della memoria, dello spazio su disco e del traffico di rete. Dovreste anche impostare degli avvisi quando vengono superate determinate soglie.
4. Aspettare troppo a lungo per aggiungere un nuovo shard (sovraccarico)
Un errore comune da evitare quando si esegue lo sharding del database MongoDB è aspettare troppo a lungo per aggiungere un nuovo shard. Quando uno shard si sovraccarica di dati o di query, può causare problemi di prestazioni e rallentare l’intero cluster.
Supponiamo di avere un cluster immaginario composto da 2 shard, con 20000 chunk (5000 considerati “attivi”), e di dover aggiungere un terzo shard. Questo terzo shard memorizzerà un terzo dei chunk attivi (e dei chunk totali).
La sfida consiste nel capire quando lo shard smette di aggiungere spese generali e diventa una risorsa. Dovremmo calcolare il carico che il sistema produrrebbe durante la migrazione dei chunk attivi al nuovo shard e quando sarebbe trascurabile rispetto al guadagno complessivo del sistema.
Nella maggior parte degli scenari, è relativamente facile immaginare che questa serie di migrazioni richieda ancora più tempo su un insieme di shard sovraccarichi e che ci voglia molto più tempo perché il nostro shard appena aggiunto superi la soglia e diventi un guadagno netto. Per questo motivo, è meglio essere proattivi e aggiungere capacità prima che sia necessario.
Le possibili strategie di mitigazione includono il monitoraggio regolare del cluster e l’aggiunta proattiva di nuovi shard in momenti di basso traffico, in modo da ridurre la competizione per le risorse. Si suggerisce di bilanciare manualmente i chunk “caldi” (a cui si accede più spesso di altri) per spostare l’attività sul nuovo shard più rapidamente.
5. Risorse dei server di configurazione insufficienti
Se i server di configurazione non sono alimentati a dovere, possono verificarsi problemi di prestazioni e instabilità. L’under-provisioning può verificarsi a causa dell’insufficiente allocazione di risorse come CPU, memoria o storage.
Questo può causare prestazioni lente delle query, timeout e persino crash. Per evitare questo problema, è essenziale allocare risorse sufficienti ai server di configurazione, soprattutto nei cluster più grandi. Monitorare regolarmente l’utilizzo delle risorse dei server di configurazione può aiutare a identificare i problemi di sottoprovvigionamento.
Un altro modo per evitare questo problema è utilizzare un hardware dedicato per i server di configurazione, piuttosto che condividere le risorse con altri componenti del cluster. Questo può aiutare a garantire che i server di configurazione abbiano risorse sufficienti per gestire il loro carico di lavoro.
6. Mancato backup e ripristino dei dati
I backup sono essenziali per garantire che i dati non vadano persi in caso di guasto. La perdita di dati può avvenire per vari motivi, tra cui guasti hardware, errori umani e attacchi malevoli.
Se non si esegue il backup e il ripristino dei dati, questi possono andare persi e subire un’interruzione. Per evitare questo errore, è necessario impostare una strategia di backup e ripristino che includa backup regolari, backup di test e ripristino dei dati in un ambiente di test.
7. Mancato test del cluster shardati
Prima di distribuire il cluster shardato in produzione, è necessario testarlo a fondo per assicurarsi che sia in grado di gestire il carico e le query previste. Il mancato collaudo del cluster sharded può causare scarse prestazioni e crash.
MongoDB Sharding vs indici clusterizzati: qual è il più efficace per i dataset di grandi dimensioni?
Sia lo sharding che gli indici clusterizzati di MongoDB sono strategie efficaci per gestire grandi insiemi di dati. Ma hanno scopi diversi. La scelta dell’approccio giusto dipende dai requisiti specifici dell’applicazione.
Lo sharding è una tecnica di scalatura orizzontale che distribuisce i dati su molti nodi, rendendola una soluzione efficace per la gestione di grandi insiemi di dati con tassi di scrittura elevati. È trasparente per le applicazioni e consente loro di interagire con MongoDB come se fosse un unico server.
D’altra parte, gli indici clusterizzati migliorano le prestazioni delle query che recuperano i dati da grandi insiemi di dati, consentendo a MongoDB di individuare i dati in modo più efficiente quando una query corrisponde al campo indicizzato.
Quindi, quale dei due è più efficace per i dataset di grandi dimensioni? La risposta dipende dallo specifico caso d’uso e dai requisiti del carico di lavoro.
Se l’applicazione richiede un’elevata velocità di scrittura e di interrogazione e deve scalare orizzontalmente, allora lo sharding di MongoDB è probabilmente l’opzione migliore. Tuttavia, gli indici clusterizzati possono essere più efficaci se l’applicazione ha un carico di lavoro pesante in lettura e richiede che i dati interrogati di frequente siano organizzati in un ordine specifico.
Sia lo sharding che gli indici clusterizzati sono strumenti molto efficaci per gestire grandi insiemi di dati in MongoDB. La chiave è valutare attentamente i requisiti dell’applicazione e le caratteristiche del carico di lavoro per determinare l’approccio migliore per il caso d’uso specifico.
Riepilogo
Un cluster shardato è una potente architettura in grado di gestire grandi quantità di dati e di scalare orizzontalmente per soddisfare le esigenze di applicazioni in crescita. Il cluster è composto da shard, server di configurazione, processi mongos e applicazioni client e i dati sono partizionati in base a una chiave shard scelta con cura per garantire una distribuzione e un’interrogazione efficienti.
Sfruttando la potenza dello sharding, le applicazioni possono ottenere un’elevata disponibilità, migliori prestazioni e un uso efficiente delle risorse hardware. La scelta della giusta chiave di sharding è fondamentale per una distribuzione uniforme dei dati.
Cosa pensate di MongoDB e della pratica dello sharding dei database? C’è qualche aspetto dello sharding che ritienete avremmo dovuto trattare? Fatecelo sapere nei commenti!


