
Con l’evoluzione dello sviluppo delle app, i database rappresentano il fulcro della maggior parte delle applicazioni, in quanto immagazzinano e gestiscono dati fondamentali per le aziende digitali. Poiché questi dati crescono e diventano sempre più complessi, garantire l’efficienza del database è fondamentale per soddisfare le esigenze di un’applicazione.
È qui che entra in gioco il concetto di manutenzione del database. La manutenzione del database comprende attività come la pulizia, il backup e l’ottimizzazione degli indici per aumentare le prestazioni.
Questo articolo offre preziose informazioni sui trigger di manutenzione e presenta istruzioni pratiche per la loro configurazione. Spiega il processo di implementazione di varie attività di manutenzione del database come il backup dei dati, la ricostruzione degli indici, l’archiviazione e la pulizia dei dati utilizzando PostgreSQL, integrato con un trigger API in un’applicazione Node.js.
Capire i trigger
Prima di creare operazioni di manutenzione per il proprio database, è importante capire i vari modi in cui possono essere attivate. Ogni trigger serve a scopi diversi per facilitare le attività di manutenzione. I tre trigger principali comunemente utilizzati sono:
- Manuale, basato su API: questo trigger permette di eseguire operazioni una tantum utilizzando una chiamata API. È utile in situazioni come il ripristino del backup di un database o la ricostruzione degli indici quando le prestazioni calano improvvisamente.
- Pianificato (come CRON): questo trigger permette di automatizzare le attività di manutenzione programmata durante i periodi di scarso traffico di utenti. È ideale per eseguire operazioni ad alta intensità di risorse come l’archiviazione e la pulizia. Si possono utilizzare pacchetti come node-schedule per impostare pianificazioni in Node.js che attivano automaticamente le operazioni quando necessario.
- Notifiche del database: questo trigger permette di eseguire operazioni di manutenzione in risposta alle modifiche del database. Ad esempio, quando un utente pubblica un commento su una piattaforma, i dati salvati possono attivare istantaneamente i controlli per caratteri irregolari, linguaggio offensivo o le emoji. L’implementazione di questa funzionalità in Node.js è possibile utilizzando pacchetti come pg-listen.
Prerequisiti
Per seguire questa guida, è necessario disporre dei seguenti strumenti sul proprio computer locale:
- Git: per gestire il controllo di versione del codice sorgente dell’applicazione
- Node.js: per costruire l’applicazione backend
- psql: per interagire con il database PostgreSQL remoto utilizzando il terminale
- PGAdmin (opzionale): per interagire con il database PostgreSQL remoto utilizzando un’interfaccia grafica (GUI).
Creare e ospitare un’applicazione Node.js
Creiamo un progetto Node.js, effettuiamo il commit su GitHub e impostiamo una pipeline di auto-deploy su Kinsta. Dovremo anche creare un database PostgreSQL su Kinsta per testare le routine di manutenzione.
Iniziamo creando una nuova directory sul nostro sistema locale con il seguente comando:
mkdir node-db-maintenanceQuindi, entriamo nella cartella appena creata ed eseguiamo il comando qui sotto per creare un nuovo progetto:
cd node-db-maintenance
yarn init -y # or npm init -yQuesto inizializza un progetto Node.js con la configurazione predefinita. Ora possiamo installare le dipendenze necessarie eseguendo il comando:
yarn add express pg nodemon dotenvEcco una rapida descrizione di ogni pacchetto:
express: permette di creare un’API REST basata su Express.pg: permette di interagire con un database PostgreSQL attraverso l’applicazione Node.js.nodemon: consente alla build dev di essere aggiornata durante lo sviluppo dell’applicazione, liberando dalla necessità costante di fermare e avviare l’applicazione ogni volta che si apporta una modifica.dotenv: permette di caricare le variabili d’ambiente da un file .env nell’oggettoprocess.env.
Quindi, aggiungiamo i seguenti script nel file package.json in modo da poter avviare facilmente il server dev ed eseguirlo anche in produzione:
{
// ...
"scripts": {
"start-dev": "nodemon index.js",
"start": "NODE_ENV=production node index.js"
},
// …
}Ora possiamo creare un file index.js che contiene il codice sorgente dell’applicazione. Incolliamo il seguente codice nel file:
const express = require("express")
const dotenv = require('dotenv');
if (process.env.NODE_ENV !== 'production') dotenv.config();
const app = express()
const port = process.env.PORT || 3000
app.get("/health", (req, res) => res.json({status: "UP"}))
app.listen(port, () => {
console.log(`Server running at port: ${port}`);
});Questo codice inizializza un server Express e configura le variabili d’ambiente utilizzando il pacchetto dotenv se non è in modalità di produzione. Inoltre, imposta una route /health che restituisce un oggetto JSON {status: "UP"}. Infine, avvia l’applicazione utilizzando la funzione app.listen() per ascoltare sulla porta specificata, con l’impostazione predefinita di 3000 se non viene fornita alcuna porta tramite la variabile d’ambiente.
Ora che abbiamo un’applicazione di base pronta, inizializziamo un nuovo repository git con il nostro provider git preferito (BitBucket, GitHub o GitLab) e inviamo il codice. Kinsta supporta il deploy delle applicazioni da tutti questi provider git. Per questo articolo, usiamo GitHub.
Quando il repository è pronto, seguiamo questi passaggi per distribuire l’applicazione su Kinsta:
- Accediamo o creiamo un account per visualizzare la dashboard MyKinsta.
- Autorizziamo Kinsta con il provider Git.
- Nella barra laterale di sinistra, clicchiamo su Applicazioni e poi su Aggiungi applicazione.
- Selezioniamo il repository e il branch da cui desideriamo effettuare il deploy.
- Selezioniamo uno dei data center disponibili dalla lista delle 29 opzioni. Kinsta rileva automaticamente le impostazioni di build delle applicazioni tramite Nixpacks.
- Scegliamo le risorse dell’applicazione, come la RAM e lo spazio su disco.
- Clicchiamo su Crea applicazione.
Una volta completata la distribuzione, copiamo il link dell’applicazione distribuita e navighiamo su /health. Dovremmo vedere il seguente JSON nel browser:
{status: "UP"}Questo indica che l’applicazione è stata configurata correttamente.
Impostazione di un’istanza PostgreSQL su Kinsta
Kinsta offre un’interfaccia semplice per fornire istanze di database. Iniziamo creando un nuovo account Kinsta se non ne abbiamo già uno. Poi, seguiamo questi passaggi:
- Accediamo alla dashboard MyKinsta.
- Nella barra laterale di sinistra, clicchiamo su Database e poi su Aggiungi database.
- Selezioniamo PostgreSQL come tipo di database e scegliamo la versione che preferiamo. Scegliamo un nome per il database e modifichiamo il nome utente e la password se lo desideriamo.
- Selezioniamo un data center dalla lista di 29 opzioni.
- Scegliamo le dimensioni del database.
- Clicchiamo su Crea database.
Una volta creato il database, assicuriamoci di recuperare l’host, la porta, il nome utente e la password del database.
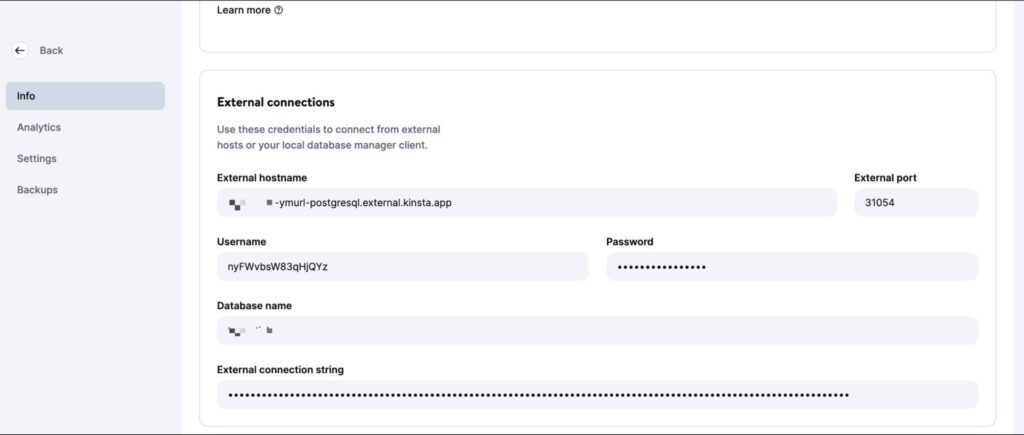
Potremo quindi inserire questi valori nella CLI psql (o nella GUI PGAdmin) per gestire il database. Per testare il codice a livello locale, creiamo un file .env nella directory principale del progetto e inseriamo i seguenti segreti:
DB_USER_NAME=your database user name
DB_HOST=your database host
DB_DATABASE_NAME=your database’s name
DB_PORT=your database port
PGPASS=your database passwordQuando effettuiamo il deploy su Kinsta, dobbiamo aggiungere questi valori come variabili d’ambiente al deploy dell’applicazione.
Per prepararci alle operazioni sul database, scarichiamo ed eseguiamo questo script SQL per creare tabelle (utenti, post, commenti) e inserire dati di esempio. Usiamo il comando qui sotto, sostituendo i placeholder con le nostre specifiche, per aggiungere i dati al database PostgreSQL appena creato:
psql -h <host> -p <port> -U <username> -d <db_name> -a -f <sql file e.g. test-data.sql>Assicuriamoci di inserire il nome e il percorso esatto del file nel comando qui sopra. L’esecuzione di questo comando richiede l’inserimento della password del database per l’autorizzazione.
Una volta completata l’esecuzione di questo comando, saremo pronti a iniziare a scrivere le operazioni di manutenzione del database. Non esitate a inviare il codice al vostro repository Git al termine di ogni operazione per vederlo in azione sulla piattaforma Kinsta.
Scrivere le routine di manutenzione
Questa sezione analizza diverse operazioni comunemente utilizzate per la manutenzione dei database PostgreSQL.
1. Creare backup
Eseguire regolarmente il backup dei database è un’operazione comune ed essenziale. Si tratta di creare una copia dell’intero contenuto del database, che viene conservata in un luogo sicuro. Questi backup sono fondamentali per ripristinare i dati in caso di perdita accidentale o di errori che ne compromettono l’integrità.
Anche se piattaforme come Kinsta offrono backup automatici come parte dei loro servizi, è importante sapere come impostare una routine di backup personalizzata, se necessario.
PostgreSQL offre lo strumento pg_dump per creare backup dei database. Tuttavia, deve essere eseguito direttamente dalla riga di comando e non esiste un pacchetto npm per questo strumento. Quindi, è necessario utilizzare il pacchetto @getvim/execute per eseguire il comando pg_dump nell’ambiente locale dell’applicazione Node.
Installiamo il pacchetto eseguendo il comando:
yarn add @getvim/executeSuccessivamente, importiamo il pacchetto nel file index.js aggiungendo questa riga di codice all’inizio:
const {execute} = require('@getvim/execute');I backup vengono generati come file sul filesystem locale dell’applicazione Node. Per questo motivo, è meglio creare una cartella dedicata con il nome backup nella directory principale del progetto.
Ora possiamo utilizzare il seguente percorso per generare e scaricare i backup del database quando necessario:
app.get('/backup', async (req, res) => {
// Create a name for the backup file
const fileName = "database-backup-" + new Date().valueOf() + ".tar";
// Execute the pg_dump command to generate the backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_dump -U " + process.env.DB_USER_NAME
+ " -d " + process.env.DB_DATABASE_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -f backup/" + fileName + " -F t"
).then(async () => {
console.log("Backup created");
res.redirect("/backup/" + fileName)
}).catch(err => {
console.log(err);
res.json({message: "Something went wrong"})
})
})Inoltre, dovremo aggiungere la seguente riga all’inizio del file index.js dopo l’inizializzazione dell’applicazione Express:
app.use('/backup', express.static('backup'))Questo permette alla cartella backup di essere servita staticamente utilizzando la funzione middleware express.static, consentendo all’utente di scaricare i file di backup generati dall’applicazione Node.
2. Ripristino da un backup
Postgres consente di ripristinare da un backup utilizzando lo strumento da linea di comando pg_restore. Tuttavia, è necessario usarlo tramite il pacchetto execute, in modo simile a come abbiamo usato il comando pg_dump. Ecco il codice della route:
app.get('/restore', async (req, res) => {
const dir = 'backup'
// Sort the backup files according to when they were created
const files = fs.readdirSync(dir)
.filter((file) => fs.lstatSync(path.join(dir, file)).isFile())
.map((file) => ({ file, mtime: fs.lstatSync(path.join(dir, file)).mtime }))
.sort((a, b) => b.mtime.getTime() - a.mtime.getTime());
if (!files.length){
res.json({message: "No backups available to restore from"})
}
const fileName = files[0].file
// Restore the database from the chosen backup file
execute("PGPASSWORD=" + process.env.PGPASS + " pg_restore -cC "
+ "-U " + process.env.DB_USER_NAME
+ " -h " + process.env.DB_HOST
+ " -p " + process.env.DB_PORT
+ " -d postgres backup/" + fileName
)
.then(async ()=> {
console.log("Restored");
res.json({message: "Backup restored"})
}).catch(err=> {
console.log(err);
res.json({message: "Something went wrong"})
})
})Il frammento di codice qui sopra cerca innanzitutto i file memorizzati nella directory di backup locale. Poi li ordina in base alla data di creazione per trovare il file di backup più recente. Infine, utilizza il pacchetto execute per ripristinare il file di backup scelto.
Assicuriamoci di aggiungere le seguenti importazioni al file index.js in modo da importare i moduli necessari per accedere al filesystem locale e permettere alla funzione di essere eseguita correttamente:
const fs = require('fs')
const path = require('path')3. Ricostruire un indice
Gli indici delle tabelle Postgres a volte si corrompono e le prestazioni del database si riducono. Ciò può essere dovuto a bug o errori del software. A volte, gli indici possono anche gonfiarsi a causa di un numero eccessivo di pagine vuote o quasi vuote.
In questi casi, sarà neccesario ricostruire l’indice per assicurarci di ottenere le migliori prestazioni dall’istanza Postgres.
A questo scopo, Postgres offre il comando REINDEX. Possiamo utilizzare il pacchetto node-postgres per eseguire questo comando (e anche per eseguire altre operazioni in seguito), quindi installiamolo eseguendo prima il seguente comando:
yarn add pgQuindi, aggiungiamo le seguenti righe all’inizio del file index.js sotto le importazioni per inizializzare correttamente la connessione al database:
const {Client} = require('pg')
const client = new Client({
user: process.env.DB_USER_NAME,
host: process.env.DB_HOST,
database: process.env.DB_DATABASE_NAME,
password: process.env.PGPASS,
port: process.env.DB_PORT
})
client.connect(err => {
if (err) throw err;
console.log("Connected!")
})L’implementazione di questa operazione è piuttosto semplice:
app.get("/reindex", async (req, res) => {
// Run the REINDEX command as needed
await client.query("REINDEX TABLE Users;")
res.json({message: "Reindexed table successfully"})
})Il comando mostrato sopra reindicizza l’intera tabella Utenti. Possiamo personalizzare il comando in base alle esigenze per ricostruire un indice particolare o per reindicizzare l’intero database.
4. Archiviazione e pulizia dei dati
Per i database che diventano grandi con il passare del tempo (e i cui dati storici vengono consultati raramente), potrebbe essere utile impostare delle routine che scaricano i vecchi dati in un data lake dove possono essere archiviati ed elaborati più comodamente.
I file Parquet sono uno standard comune per l’archiviazione e il trasferimento dei dati in molti data lake. Utilizzando la libreria ParquetJS, si possono creare file parquet dai dati Postgres e utilizzare servizi come AWS Athena per leggerli direttamente senza doverli caricare nuovamente nel database in futuro.
Installiamo la libreria ParquetJS eseguendo questo comando:
yarn add parquetjsQuando creiamo degli archivi, dobbiamo interrogare un gran numero di record dalle tabelle. Memorizzare una tale quantità di dati nella memoria dell’applicazione può essere dispendioso in termini di risorse, costoso e soggetto a errori.
Per questo motivo, ha senso utilizzare dei cursori per caricare pezzi di dati dal database ed elaborarli. Installiamo il modulo cursors del pacchetto node-postgres eseguendo il comando:
yarn add pg-cursorSuccessivamente, assicuriamoci di importare entrambe le librerie nel file index.js:
const Cursor = require('pg-cursor')
const parquet = require('parquetjs')Ora possiamo usare lo snippet di codice qui sotto per creare file di parquet dal database:
app.get('/archive', async (req, res) => {
// Query all comments through a cursor, reading only 10 at a time
// You can change the query here to meet your requirements, such as archiving records older than at least a month, or only archiving records from inactive users, etc.
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
// Define the schema for the parquet file
let schema = new parquet.ParquetSchema({
comment_id: { type: 'INT64' },
post_id: { type: 'INT64' },
user_id: { type: 'INT64' },
comment_text: { type: 'UTF8' },
timestamp: { type: 'TIMESTAMP_MILLIS' }
});
// Open a parquet file writer
let writer = await parquet.ParquetWriter.openFile(schema, 'archive/archive.parquet');
let rows = await cursor.read(10)
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Write each row from table to the parquet file
await writer.appendRow(rows[i])
}
rows = await cursor.read(10)
}
await writer.close()
// Once the parquet file is generated, you can consider deleting the records from the table at this point to free up some space
// Redirect user to the file path to allow them to download the file
res.redirect("/archive/archive.parquet")
})Quindi, aggiungiamo il seguente codice all’inizio del file index.js dopo che l’applicazione Express è stata inizializzata:
app.use('/archive', express.static('archive'))Questo permette di servire la cartella dell’archivio in modo statico, consentendo di scaricare i file di parquet generati dal server.
Non dimenticate di creare una cartella di archivio nella directory del progetto per memorizzare i file di archivio.
Possiamo personalizzare ulteriormente questo snippet di codice per caricare automaticamente i file di parquet in un bucket AWS S3 e utilizzare i job CRON per attivare automaticamente l’operazione su una routine.
5. Pulizia dei dati
Uno scopo comune dell’esecuzione di operazioni di manutenzione del database è quello di ripulire i dati che diventano vecchi o irrilevanti con il passare del tempo. In questa sezione vengono illustrati due casi comuni in cui la pulizia dei dati viene effettuata come parte della manutenzione.
In realtà, possiamo impostare una routine di pulizia dei dati come richiesto dai modelli di dati dell’applicazione. Gli esempi riportati di seguito sono solo di riferimento.
Eliminare i record per età (ultima modifica o ultimo accesso)
La pulizia dei record in base all’età è relativamente semplice rispetto alle altre operazioni di questo elenco. Possiamo scrivere una query di cancellazione che elimina i record precedenti a una data stabilita.
Ecco un esempio di cancellazione di commenti fatti prima del 9 ottobre 2023:
app.get("/clean-by-age", async (req, res) => {
// Filter and delete all comments that were made on or before 9th October, 2023
const result = await client.query("DELETE FROM COMMENTS WHERE timestamp < '09-10-2023 00:00:00'")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})Potete provarlo inviando una richiesta GET alla route /clean-by-age.
Eliminare i record in base a condizioni personalizzate
Possiamo anche impostare le pulizie in base ad altre condizioni, come ad esempio la rimozione dei record che non sono collegati ad altri record attivi nel sistema (creando una situazione di orphan ).
Ad esempio, possiamo impostare un’operazione di pulizia che cerchi i commenti collegati ai post cancellati e li elimini perché probabilmente non verranno mai più visualizzati nell’applicazione:
app.get('/conditional', async (req, res) => {
// Filter and delete all comments that are not linked to any active posts
const result = await client.query("DELETE FROM COMMENTS WHERE post_id NOT IN (SELECT post_id from Posts);")
if (result.rowCount > 0) {
res.json({message: "Cleaned up " + result.rowCount + " rows successfully!"})
} else {
res.json({message: "Nothing to clean up!"})
}
})È possibile creare delle condizioni specifiche per ciascun caso d’uso.
6. Manipolazione dei dati
Le operazioni di manutenzione del database sono utilizzate anche per effettuare manipolazioni e trasformazioni dei dati, come la censura del linguaggio osceno o la conversione di combinazioni di testo in emoji.
A differenza della maggior parte delle altre operazioni, è meglio eseguirle quando si verificano gli aggiornamenti del database (piuttosto che eseguirle su tutte le righe in un periodo fisso della settimana o del mese).
Questa sezione elenca due di queste operazioni, ma l’implementazione di qualsiasi altra operazione di manipolazione personalizzata rimane abbastanza simile a queste.
Convertire il testo in Emoji
Possiamo convertire combinazioni di testo come “:)” e “xD” in vere e proprie emoji per offrire una migliore esperienza all’utente e mantenere la coerenza delle informazioni. Ecco uno snippet di codice che ci aiuterà a farlo:
app.get("/emoji", async (req, res) => {
// Define a list of emojis that need to be converted
const emojiMap = {
xD: '😁',
':)': '😊',
':-)': '😄',
':jack_o_lantern:': '🎃',
':ghost:': '👻',
':santa:': '🎅',
':christmas_tree:': '🎄',
':gift:': '🎁',
':bell:': '🔔',
':no_bell:': '🔕',
':tanabata_tree:': '🎋',
':tada:': '🎉',
':confetti_ball:': '🎊',
':balloon:': '🎈'
}
// Build the SQL query adding conditional checks for all emojis from the map
let queryString = "SELECT * FROM COMMENTS WHERE"
queryString += " COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[0] + "%' "
if (Object.keys(emojiMap).length > 1) {
for (let i = 1; i < Object.keys(emojiMap).length; i++) {
queryString += " OR COMMENT_TEXT LIKE '%" + Object.keys(emojiMap)[i] + "%' "
}
}
queryString += ";"
const result = await client.query(queryString)
if (result.rowCount === 0) {
res.json({message: "No rows to clean up!"})
} else {
for (let i = 0; i < result.rows.length; i++) {
const currentRow = result.rows[i]
let emoji
// Identify each row that contains an emoji along with which emoji it contains
for (let j = 0; j < Object.keys(emojiMap).length; j++) {
if (currentRow.comment_text.includes(Object.keys(emojiMap)[j])) {
emoji = Object.keys(emojiMap)[j]
break
}
}
// Replace the emoji in the text and update the row before moving on to the next row
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + currentRow.comment_text.replace(emoji, emojiMap[emoji]) + "' WHERE COMMENT_ID = " + currentRow.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "All emojis cleaned up successfully!"})
}
})Questo snippet di codice richiede innanzitutto di definire un elenco di emoji e le loro rappresentazioni testuali. Poi, interroga il database per cercare queste combinazioni testuali e le sostituisce con le emoji.
Censurare il linguaggio osceno
Un’operazione piuttosto comune utilizzata nelle app che permettono di creare contenuti generati dagli utenti è quella di censurare il linguaggio offensivo. In questo caso l’approccio è simile: identifichiamo le istanze di linguaggio osceno e sostituiamole con dei caratteri asterisco. Possiamo utilizzare il pacchetto bad-words per verificare e censurare facilmente le espressioni volgari.
Installiamo il pacchetto eseguendo il seguente comando:
yarn add bad-wordsQuindi, inizializziamo il pacchetto nel file index.js:
const Filter = require('bad-words');
filter = new Filter();Ora, utilizziamo il seguente frammento di codice per censurare i contenuti osceni nella tabella dei commenti:
app.get('/obscene', async (req, res) => {
// Query all comments using a cursor, reading only 10 at a time
const queryString = "SELECT * FROM COMMENTS;"
const cursor = client.query(new Cursor(queryString))
let rows = await cursor.read(10)
const affectedRows = []
while (rows.length > 0) {
for (let i = 0; i < rows.length; i++) {
// Check each comment for profane content
if (filter.isProfane(rows[i].comment_text)) {
affectedRows.push(rows[i])
}
}
rows = await cursor.read(10)
}
cursor.close()
// Update each comment that has profane content with a censored version of the text
for (let i = 0; i < affectedRows.length; i++) {
const row = affectedRows[i]
const updateQuery = "UPDATE COMMENTS SET COMMENT_TEXT = '" + filter.clean(row.comment_text) + "' WHERE COMMENT_ID = " + row.comment_id + ";"
await client.query(updateQuery)
}
res.json({message: "Cleanup complete"})
})Il codice completo di questo tutorial si trova in questo repo GitHub.
Cos’è e a cosa serve il processo Vacuum di PostgreSQL
Oltre a impostare routine di manutenzione personalizzate come quelle discusse sopra, possiamo anche utilizzare una delle funzionalità di manutenzione native che PostgreSQL offre per garantire la salute e le prestazioni del database: il processo Vacuum.
Il processo Vacuum aiuta a ottimizzare le prestazioni del database e a recuperare spazio su disco. PostgreSQL esegue le operazioni di Vacuum in modo programmato grazie all’auto-vacuum daemon, ma è anche possibile attivarlo manualmente se necessario. Ecco alcuni modi in cui eseguire un processo Vacuum frequentemente può rivelarsi utile:
- Recupero dello spazio su disco bloccato: uno degli obiettivi principali di Vacuum è quello di recuperare lo spazio su disco bloccato all’interno del database. Poiché i dati vengono costantemente inseriti, aggiornati e cancellati, PostgreSQL può essere ingombrato da righe “morte” o obsolete che occupano ancora spazio sul disco. Vacuum identifica e rimuove queste righe morte, rendendo lo spazio disponibile per i nuovi dati. Senza Vacuum, lo spazio su disco si esaurirebbe gradualmente, portando potenzialmente a un calo delle prestazioni e persino a un crash del sistema.
- Aggiornamento delle metriche del Query Planner: Vacuum aiuta anche PostgreSQL a mantenere aggiornate le statistiche e le metriche utilizzate dal query planner. Il query planner si basa su un’accurata distribuzione dei dati e su informazioni statistiche per generare piani di esecuzione efficienti. Eseguendo regolarmente Vacuum, PostgreSQL si assicura che queste metriche siano aggiornate, consentendogli di prendere decisioni migliori su come recuperare i dati e ottimizzare le query.
- Aggiornamento della mappa di visibilità: La mappa di visibilità è un altro aspetto cruciale del processo Vacuum di PostgreSQL. Aiuta a identificare quali blocchi di dati in una tabella sono completamente visibili a tutte le transazioni, consentendo a Vacuum di indirizzare solo i blocchi di dati necessari per la pulizia. Questo migliora l’efficienza del processo Vacuum riducendo al minimo le operazioni di I/O non necessarie, che sarebbero costose e richiederebbero molto tempo.
- Prevenzione dei fallimenti di Transaction ID Wraparound: Vacuum svolge anche un ruolo fondamentale nella prevenzione dei fallimenti dell’ID transazione. PostgreSQL utilizza un contatore di ID transazione a 32 bit, che può causare un wraparound quando raggiunge il suo valore massimo. Vacuum contrassegna le vecchie transazioni come “congelate”, impedendo al contatore ID di avvolgersi e causare la corruzione dei dati. Trascurare questo aspetto può portare a guasti catastrofici del database.
Come già detto, PostgreSQL offre due opzioni per l’esecuzione di Vacuum: Autovacuum e Manual Vacuum.
Autovacuum è la scelta consigliata per la maggior parte degli scenari, in quanto gestisce automaticamente il processo Vacuum in base alle impostazioni predefinite e all’attività del database. Il Vacuum manuale, invece, offre un maggiore controllo ma richiede una conoscenza più approfondita della manutenzione del database.
La scelta tra le due opzioni dipende da fattori quali le dimensioni del database, il carico di lavoro e le risorse disponibili. I database di piccole e medie dimensioni possono spesso affidarsi all’Autovacuum, mentre quelli più grandi o più complessi possono richiedere un intervento manuale.
Riepilogo
La manutenzione dei database non è solo una questione di pulizia ordinaria, ma è la base di un’applicazione sana e performante. Ottimizzando, pulendo e organizzando regolarmente i dati, ci si assicura che il database PostgreSQL continui a fornire prestazioni massime, rimanga libero da corruzione e operi in modo efficiente, anche quando l’applicazione scala.
In questa guida completa abbiamo analizzato l’importanza fondamentale di stabilire piani di manutenzione del database PostgreSQL ben strutturati quando si lavora con Node.js ed Express.
Ci siamo persi qualche operazione di manutenzione ordinaria del database che avete implementato per il vostro database? Oppure conoscete un modo migliore per implementare una delle operazioni sopra descritte? Fatecelo sapere nei commenti!

Kumar è software developer e autore tecnico con sede in India. È specializzato in JavaScript e DevOps. Per saperne di più sul suo lavoro, visitate il suo sito web.

