
サイトの所有者であれば誰でも身に覚えがあるかもしれませんが、データの損失やダウンは、たとえそれが少量であっても、壊滅的な打撃をもたらす可能性があります。これの発生は是非とも避けたいところ。最終的には、生産性、可用性が低下するだけでなく、製品やサービスのイメージダウンも懸念されます。
サイトの完全性を守るべく、ダウンやデータ損失の可能性を常に考え策を講じることが重要です。
そこで登場するのが、データのレプリケーションです。
データレプリケーションは、言うなればバックアップの自動化で、データをメインのデータベースから別の遠隔地にある安全な場所にコピーすることができます。データベースサーバーを使用しているサイトやアプリには欠かせない技術です。また、複製したデータベースを活用して読み取り専用のSQLを処理することで、システム内でより多くのプロセスを実行することができます。
2つのデータベース間でレプリケーションを設定することで、これが不測の事態に対するフォールトトレランスとして機能します。災害時の高可用性を確保する優れた方策です。
この記事では、バックエンド開発者がPostgreSQLのレプリケーションをシームレスに行うために知っておきたい、さまざまな側面についてご説明します。
PostgreSQLレプリケーションとは
PostgreSQLのレプリケーションとは、PostgreSQLデータベースサーバーから別のサーバーにデータをコピーすることです。コピー元のデータベースサーバーは「プライマリ」サーバーとも呼ばれ、コピーデータを受け取るデータベースサーバーは「レプリカ」サーバーと呼ばれます。
PostgreSQLデータベースにおけるレプリケーションモデルはどちらかと言えば単純です。すべての書き込みがプライマリノードに対して行われ、変更点が適用され、その後セカンダリノードに送られます。
自動フェイルオーバーとは
フェイルオーバーとは、プライマリサーバーが何らかの理由で停止した場合にデータを復旧する策です。物理的なストリーミングレプリケーションをPostreSQLで管理するように設定しておけば、プライマリサーバーの不具合によるダウンに備えることができます。
フェイルオーバーのセットアップと開始までには時間がかかることがあります。PostgreSQLには、サーバーの障害を監視し範囲指定する機能が標準で搭載されていないため、工夫が必要です。
とは言え、フェイルオーバーの実行をPostgreSQLに依存する必要はありません。自動フェイルオーバー、または、スタンバイへの自動切り替えを可能にする専用ツールがあり、データベースのダウンに備えることができます。
フェイルオーバーレプリケーションを設定することで、プライマリサーバーが停止した場合であっても、スタンバイを利用できるようになり、高可用性がほぼ保証されるという仕組みです。
PostgreSQLレプリケーションの利点
PostgreSQLのレプリケーションを利用する主なメリットは以下のとおりです。
- データ移行:PostgreSQLレプリケーションは、データベースサーバーのハードウェアの変更、またはシステム展開によるデータ移行に活用することができます。
- フォールトトレランス:プライマリサーバーに障害が発生しても、プライマリサーバーとスタンバイサーバーの格納データが同じであるため、スタンバイサーバーをメインのサーバーとして利用することができます。
- オンライントランザクション処理(OLTP)性能:レポートクエリの負荷を取り除くことで、OLTPシステムのトランザクション処理時間とクエリ時間を改善することができます。トランザクション処理時間とは、トランザクションが終了するまでに、所定のクエリ実行にかかる時間のことです。
- システムテストの並行実施:システムをアップグレードする際には、既存のデータでシステムがうまく動作するかどうか確認する必要があります。つまり、導入前に本番用データベースのコピーを使ったテストが必要になります。
PostgreSQLレプリケーションの仕組み
一般的に、プライマリとセカンダリのアーキテクチャを扱う際、バックアップとレプリケーションをセットアップする方法は1つしかないと思われがちです。しかし、PostgreSQLでは、以下の3つの方法のいずれも使うことができます。
- ストリーミングレプリケーション:プライマリノードからセカンダリノードへデータを複製し、バックアップストレージとしてAmazon S3またはAzure Blobへデータをコピーする
- ボリュームレベルレプリケーション:プライマリノードからセカンダリノードへストレージ層でデータを複製し、バックアップ用ストレージとしてAmazon S3またはAzure Blobにデータをコピーする
- インクリメンタルバックアップ:プライマリノードからデータを複製しながら、Amazon S3またはAzure Blobストレージから新しいセカンダリノードを構築し、プライマリノードから直接ストリーミングできるようにする
方法1. ストリーミング
PostgreSQLのストリーミングレプリケーションはWALレプリケーションとしても知られており、すべてのサーバーにPostgreSQLインストール後にシームレスに設定することが可能です。この方法では、プライマリデータベースからターゲットデータベースにWALファイルを移動してレプリケーションを行います。
PostgreSQLのストリーミングレプリケーションには、プライマリ─セカンダリの構成を用います。プライマリサーバーは、プライマリデータベースとそのすべての操作を処理するプライマリインスタンスです。セカンダリサーバーは補助的なインスタンスとして機能し、プライマリデータベースに加えられたすべての変更を自分自身で実行し、その過程で同一のコピーを生成します。プライマリサーバーは読み書き可能なサーバーであるのに対し、セカンダリサーバーは単に読み取り専用となります。
この方法を採用するには、プライマリノードとスタンバイノードの両方を設定する必要があります。以下のセクションでは、これらのノードを簡単に設定する方法をご説明します。
プライマリノードの設定
ストリーミングレプリケーション実行のためのプライマリノードの設定は、以下の手順で行います。
ステップ1. データベースの初期化
データベースを初期化するには、initdbユーティリティコマンドを使用します。次に、以下のコマンドを使用して、レプリケーション権限を持つユーザーを新規作成します。
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';ここではクエリに対するパスワードとユーザー名が必要になります。レプリケーションキーワードは、ユーザーに必要な権限を与えるのに使用します。クエリの例は、次のようになります。
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';ステップ2. ストリーミングプロパティの設定
次に、以下のようにPostgreSQL設定ファイル(postgresql.conf)を使用して、ストリーミングプロパティを設定します。
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onここで、先ほどのスニペットで使用したパラメータの背景を少し説明します。
wal_log_hints:このパラメータは、スタンバイサーバーがプライマリサーバーと同期していないときに便利なpg_rewind機能を利用するのに必要です。wal_level:このパラメータは、PostgreSQLのストリーミングレプリケーションを有効にするために使用します。使用できる値は、minimal、replica、またはlogicalです。max_wal_size:ログファイルに保持できるWALファイルのサイズを指定します。hot_standby:このパラメータをONに設定し、セカンダリとのリードオン接続を有効にできます。max_wal_senders:スタンバイサーバーとの間で確立できる最大同時接続数を指定できます。
ステップ3. 新規エントリーの作成
postgresql.confファイルのパラメータ変更後、pg_hba.confファイルに新しいレプリケーションエントリを作成することで、サーバー間の接続を確立することができます。
このファイルは通常、PostgreSQLのデータディレクトリにあります。以下のコードを使用します。
host replication rep_user IPaddress md5このコードが実行されると、プライマリサーバーがrep_user というユーザーに接続を許可し、指定された IPを使ってスタンバイサーバーとしてレプリケーションを行うことができるようになります。たとえば、以下のようになります。
host replication rep_user 192.168.0.22/32 md5スタンバイノードの設定
ストリーミングレプリケーションを行うスタンバイノードを設定するには、以下の手順に従ってください。
ステップ1. プライマリノードのバックアップ
スタンバイノードを設定するには、pg_basebackupユーティリティを使用してプライマリノードのバックアップを生成します。これをスタンバイノードの出発点として使用します。このユーティリティは、以下のようにして使用できます。
pg_basebackp -D -h -X stream -c fast -U rep_user -W上記の構文で使用されているパラメータはそれぞれ以下のとおりです。
-h:プライマリホストについて言及-D:現在作業中のディレクトリを示す-C:チェックポイントの設定に利用-X:トランザクションログファイルを含めるのに使用-W:データベースへの接続前に、ユーザーにパスワードの入力を求める
ステップ2. レプリケーション設定ファイルのセットアップ
次に、レプリケーション設定ファイルが存在するかどうかを確認する必要があります。存在しない場合は、recovery.confとしてレプリケーション設定ファイルを生成します。
このファイルはPostgreSQLインストール先のデータディレクトリに作成してください。pg_basebackupユーティリティの-Rオプションを使用すれば、自動生成できます。
recovery.confファイルに、以下のコマンドを記述してください。
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'前述のコマンドで使用しているパラメータは以下のとおりです。
primary_conninfo:文字列を利用してプライマリサーバーとセカンダリサーバー間の接続を行うstandby_mode:スイッチONの時にプライマリーサーバーをスタンバイとして起動recovery_target_timeline:リカバリタイムを設定
接続を設定するには、primary_conninfoパラメータの値として、ユーザー名、IP アドレス、パスワードを指定する必要があります。例えば次の通りです。
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'ステップ3. セカンダリサーバーの再起動
最後に、セカンダリサーバーを再起動することで、設定作業が完了します。
しかし、ストリーミングレプリケーションには、次のような課題があります。
- 様々なPostgreSQLクライアント(別々のプログラミング言語で書かれている)が1つのエンドポイントを利用。プライマリノードに障害が発生した場合、クライアントが同じDNSまたはIP名を再試行し続けることで、アプリケーションにてフェイルオーバーが見えるようになる。
- PostgreSQLのレプリケーションには、フェイルオーバーと監視が組み込まれていない。別途、プライマリノードに障害が発生した場合、セカンダリノードを新しいプライマリに昇格させる必要がある。この昇格を実装する際には、クライアントが1つのプライマリノードだけに書き込みを行い、データの不整合が発生しないようにする必要がある。
- PostgreSQLは状態全体をレプリケートする。新しいセカンダリノードを開発する際には、セカンダリノードがプライマリノードから変更点の履歴をすべて再現する必要があり、これはリソース集約的で、ヘッド内のノードを排除して新しいノードを作成する際のコストが高くつく。
方法2. 複製ブロックデバイス
複製ブロックデバイスは、ディスクミラーリング(ボリュームのレプリケーションとも呼ばれる)に基づく手法です。変更内容が永続ボリュームに書き込まれ、それが別のボリュームに同期的にミラーリングされます。
この方法の強みとして、PostgreSQL、MySQL、SQL Serverなど、すべてのリレーショナルデータベースとクラウド環境での互換性とデータの耐久性が確保できます。
しかし、PostgreSQLのレプリケーションにおけるディスクミラーリングでは、WALログとテーブルデータの両方をレプリケートする必要があります。データベースへの書き込みはネットワーク上で同期的に行われる必要があるため、1バイトでも失われるとデータベースが破損した状態になる可能性があります。
この方法は通常、Azure PostgreSQLとAmazon RDSを使用して実行されます。
方法3. WAL
WALはセグメントファイル(デフォルトでは16MB)で構成されています。各セグメントには1つまたは複数のレコードが格納されます。WAL内のレコードを識別するLSN(ログシーケンス番号)というものがあり、これを使ってログファイル内のレコードが保存されている位置/場所を知ることができます。
スタンバイサーバーは、WALセグメント(PostgreSQL用語ではXLOGSとも呼ばれます)を利用して、プライマリサーバーからの変更を継続的に複製します。WALを使用して、バイト配列のデータチャンク(それぞれが一意のLSNを持つ)をデータベースへの適用前に安定したストレージにシリアライズすることによって、DBMSに耐久性と原子性を付与することができます。
データベースへの変更の適用は、様々なファイルシステムの操作につながる可能性があります。そこで考えるべきが、ファイルシステムの編集中に停電などでサーバーが故障した場合、データベースがどのようにして原子性を保証できるのかということです。データベース起動に際し、起動プロセスまたは再生プロセスが開始され、利用可能なWALセグメントを読み込み、各データページに保存されているLSNと比較します(各データページには、そのページに影響する最新のWALレコードのLSNが記録されています)。
ログ配布ベースのレプリケーション(ブロックレベル)
ストリーミングレプリケーションは、ログ配布を改良したものです。WALの切り替えを待つのとは対照的に、レコードが作成されると同時に送信されるため、レプリケーションの遅延が少なくなります。
また、スタンバイサーバーはレプリケーションプロトコルを利用してネットワーク上でプライマリサーバーとリンクしている点で、ストリーミングレプリケーションはログ配布に勝ります。プライマリサーバーは、エンドユーザーが提供するスクリプトに依存することなく、この接続を介して直接WALレコードを送信することができます。
ログ配布ベースのレプリケーション(ファイルレベル)
ログ配布とは、ログファイルを別のPostgreSQLサーバーにコピーし、WALファイルを再生することによって別のスタンバイサーバーを生成することです。このサーバーはリカバリモードで動作するように設定されており、その唯一の目的は新しいWALファイルが現れたときにそれを適用することです。
このセカンダリサーバーは、プライマリPostgreSQLサーバーのウォームアップとなります。また、ホットスタンバイと呼ばれる、読み取り専用のクエリを提供する読み取りレプリカとして構成することもできます。
継続的WALアーカイブ
WALファイルを作成する際に、pg_walサブディレクトリ以外の場所に複製し、アーカイブする手法があり、これはWALアーカイブと呼ばれます。PostgreSQLでは、WALファイルが作成されるたびに、ユーザーが指定したアーカイブ用のスクリプトが呼び出されます。
このスクリプトは、scpコマンドを利用し、NFSマウントのような1つ、または複数の場所にファイルを複製することができます。アーカイブしたWALセグメントファイルは、特定の時点のデータベースの復旧に利用可能です。
その他のログベースの構成は以下のとおりです。
- 同期レプリケーション:同期レプリケーションのトランザクションをコミットする前に、プライマリサーバーはスタンバイがデータを取得したことを確認するまで待機します。この構成の利点は、並列の書き込み処理によるコンフリクトが発生しないことです。
- 同期マルチマスターレプリケーション:各サーバーが書き込みのリクエストを受け付け、変更されたデータは各トランザクションがコミットされる前に元のサーバーから他のサーバーに送信されます。2PCプロトコルを利用し、all-or-noneルール(全か無かの法則)に従います。
WALストリーミングプロトコルの詳細
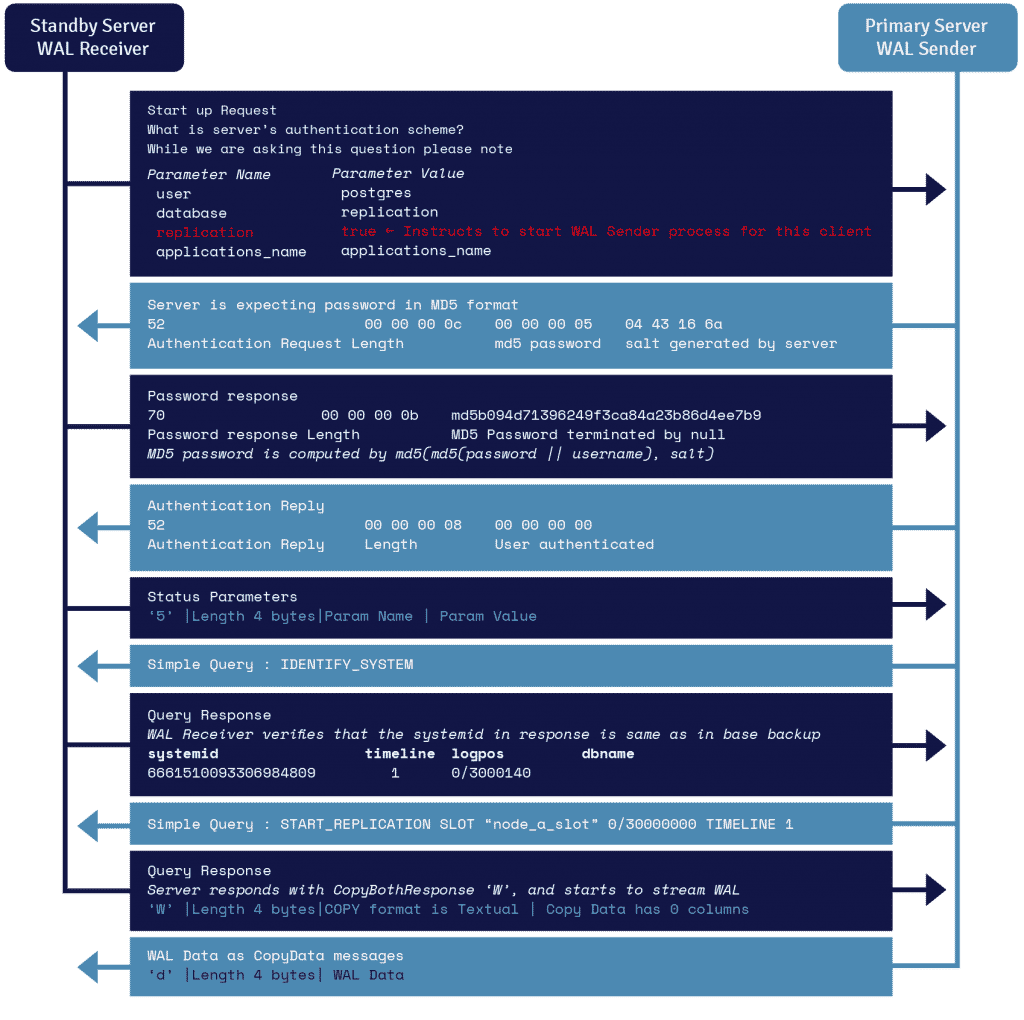
スタンバイサーバー上で動作するWALレシーバーと呼ばれるプロセスでは、recovery.confの primary_conninfoパラメータで指定された接続情報を利用し、TCP/IP接続を利用してプライマリサーバーに接続します。
ストリーミングレプリケーションを開始するには、フロントエンドから起動メッセージ内でreplicationパラメータを送信することができます。「true」、「yes」、「1」、「ON」のいずれかのブール値によって、バックエンド側での物理レプリケーションwalsenderモード移行の必要性を把握します。
WALセンダーはプライマリサーバー上で動作する別のプロセスであり、WALレコードが生成されるとスタンバイサーバーに送信する役割を担います。WALレシーバーは、ローカルで接続したクライアントの操作によって作成されたかのようにWALレコードをWALに保存します。
WALレコードがWALセグメントファイルに到達すると、スタンバイサーバーはWALを再生し続け、これによりプライマリとスタンバイ両方で最新の状態が維持されます。
PostgreSQLレプリケーションの要素
このセクションでは、PostgreSQLのレプリケーションでよく使われるモデル(シングルマスター、マルチマスターレプリケーション)、タイプ(物理レプリケーション、論理レプリケーション)、モード(同期、非同期)について理解を深めていきましょう。
PostgreSQLデータベースレプリケーションのモデル
まずはスケーラビリティについてです。これは、既存のノードにさらにリソースやハードウェアを追加して、データベースの能力を強化し、水平方向と垂直方向により多くのデータを保存、処理できるようにすることを意味します。PostgreSQLのレプリケーションは水平スケーラビリティの典型例であり、垂直スケーラビリティよりも実装がはるかに困難です。水平方向のスケーラビリティの実現には、主にシングルマスターレプリケーション(SMR)とマルチマスターレプリケーション(MMR)を使用します。
シングルマスターレプリケーションでは、データは1つのノードでのみ変更可能であり、その変更は1つ、または、複数のノードに複製されます。レプリカデータベース内の複製されたテーブルは、プライマリサーバーからの変更以外を受け入れることは許可されていません。たとえ変更を受け入れたとしても、その変更はプライマリサーバーにレプリケートされない仕様です。
ほとんどの場合、SMRの使用で事足ります。というのも、設定や管理がそれほど複雑ではなく、コンフリクトの可能性もないからです。シングルマスターレプリケーションは、プライマリデータベースからレプリカデータベースへの一方向にしかデータを流さないため、単方向のレプリケーションとなります。
場合によっては、SMRだけでは不十分で、MMRを導入が必要になることもあります。MMRでは、複数のノードをプライマリノードとして機能させることができます。複数の指定したプライマリデータベース内のテーブル行の変更が、他のすべてのプライマリデータベース内の対応するテーブルにレプリケートされます。ちなみにこのモデルでは、プライマリキーの重複などの問題を回避するために、よく競合解消の方策が採用されます。
MMRの強みは以下の通りです。
- ホストに障害が発生しても、他のホストが更新や挿入といった操作を担うことができる
- プライマリノードが複数の場所に分散するため、すべてのプライマリノードが故障する可能性が非常に低い
- プライマリデータベースの広域通信網(WAN)を採用することで、クライアントグループに地理的に近づけることができ、しかもネットワーク全体でデータの一貫性を保つことができる
しかし、MMR導入のデメリットとして、その複雑さとコンフリクトの解消の難しさが挙げられます。
PostgreSQLはMMRをネイティブにサポートしておらず、ブランチやアプリケーションを介したMMRソリューションを利用するのが便利です。オープンソース、無料、有料など、その中身は多岐にわたります。そのような拡張を支援する選択肢の1つが双方向レプリケーション(BDR)です。これは非同期を特徴とし、PostgreSQLの論理デコード機能をベースにしています。
BDRは他のノード上のトランザクションを複製するため、適用中のトランザクションと受信ノードでコミットされたトランザクションの間に競合があると、この操作が失敗する可能性があります。
PostgreSQLレプリケーションの種類
PostgreSQLのレプリケーションには、論理レプリケーションと物理レプリケーションの2種類があります。
単純な論理操作initdbは、クラスタのベースディレクトリを作成するという物理的な操作を実行します。同様に、単純な論理操作CREATE DATABASEは、ベースディレクトリの中にサブディレクトリを作成するという物理的な操作を行います。
物理レプリケーションでは、通常、ファイルとディレクトリを扱います。レプリケーションは、そのようなファイルやディレクトリが何を表しているかまでは把握しません。この方法は、通常、別のマシンにある1つのクラスタを対象としたデータ全体の完全なコピーを保持するのに使用されます。ファイルシステムレベルまたはディスクレベルで実施し、正確に一致するブロックアドレスを使用します。
論理レプリケーションは、レプリケーションID(通常はプライマリキー)に基づいて、データエンティティとその変更内容を再現するものです。物理レプリケーションとは異なり、データベース、テーブル、DML操作を扱い、データベースクラスターレベルでの実行となります。「パブリッシュ」と「サブスクライブ」という方式が採用されており、サブスクライバーがパブリッシャーノード上のパブリケーションを対象にしてサブスクライブ処理を実行します。
レプリケーションプロセスは、パブリッシャーデータベース上のデータのスナップショットを取得し、それをサブスクライバーにコピーすることから始まります。サブスクライバーはサブスクライブしているパブリケーションからデータを取り出し、カスケードレプリケーションやより複雑な構成を可能にするために、後からデータを再びパブリッシュすることができます。サブスクライバーはパブリッシャーと同じ順序でデータを適用するため、1つのサブスクリプション内のパブリケーションでトランザクションの一貫性が保証されます(これはトランザクションレプリケーションとも呼ばれます)。
論理レプリケーションの典型的な使用例は次のとおりです。
- 1つのデータベース(またはデータベースのサブセット)の増分変更が発生したときに、サブスクライバーに送信する
- 複数のデータベース間でデータベースのサブセットを共有する
- 個々の変更がサブスクライバーに到着したときに、その変更をトリガーする
- 複数のデータベースを1つに統合する
- 複製されたデータへのアクセスを、複数グループのユーザーに提供する
サブスクライバーデータベースは他のPostgreSQLインスタンスと同じように動作し、そのパブリケーションを定義することによって他のデータベースのパブリッシャーとして使用することができます。
サブスクライバーがアプリケーションによって読み取り専用として扱われる場合、1つのサブスクリプションから競合が発生することはないでしょう。一方、アプリケーションや他のサブスクライバーが同じテーブルに対して書き込みを行うと、競合が発生する可能性があります。
PostgreSQLは両方の機構を同時にサポートしています。論理レプリケーションでは、データレプリケーションとセキュリティの両方をきめ細かく制御することが可能です。
レプリケーションモード
PostgreSQLのレプリケーションには、主に同期と非同期の2つのモードがあります。同期レプリケーションでは、プライマリサーバーとセカンダリサーバーの両方に同時にデータを書き込むことができますが、非同期レプリケーションでは、まずホストにデータを書き込み、その後セカンダリサーバーにコピーする流れになります。
同期モードでは、プライマリデータベースのトランザクションは、その変更がすべてのレプリカにレプリケートされた時点で完了したとみなされます。プライマリでトランザクションが完了するためには、レプリカサーバーがすべて常時利用可能である必要があります。同期モードのレプリケーションは、即時フェイルオーバーが要求されるハイエンドなトランザクション環境で使用されます。
一方、非同期モードでは、プライマリサーバー上のトランザクションは、プライマリサーバーだけで変更が行われた時点で完了とみなすことができます。この変更は、その後レプリカに複製されます。レプリカサーバーは、レプリケーションラグと呼ばれる一定の期間、同期していない状態を維持することができます。クラッシュするとデータ損失が発生する可能性がありますが、非同期レプリケーションのオーバーヘッドは小さく、ほとんどの場合許容範囲(ホストに過度の負担をかけることはない)だと言えます。プライマリデータベースからセカンダリデータベースへのフェイルオーバーは、同期レプリケーションよりも時間がかかります。
PostgreSQLレプリケーションの設定方法
このセクションでは、Linuxオペレーティングシステム上でPostgreSQLのレプリケーションプロセスをセットアップする方法をご説明します。ここではUbuntu 18.04 LTSとPostgreSQL 10を使用します。
それでは、早速インストールから始めましょう。
インストール
まず、LinuxにPostgreSQLをインストールする手順を説明します。
- PostgreSQLの署名キーをターミナルでインポートします。以下のコマンドを入力してください。
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - 次に、ターミナルで以下のコマンドを入力し、PostgreSQLのリポジトリを追加します。
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - ターミナルで以下のコマンドを入力し、リポジトリのインデックスを更新します。
sudo apt-get update - aptコマンドを使用してPostgreSQLパッケージをインストールします。
sudo apt-get install -y postgresql-10 - 最後に、以下のコマンドでPostgreSQLのユーザーのパスワードを設定します。
sudo passwd postgres
PostgreSQLのレプリケーションを開始する前に、プライマリサーバーとセカンダリサーバーの両方にPostgreSQLをインストールすることが必須となります。
両サーバーでのPostgreSQLのセットアップが完了したら、プライマリーサーバーとセカンダリーサーバーのレプリケーションのセットアップに移りましょう。
プライマリサーバーでのレプリケーションの設定
プライマリサーバーとセカンダリサーバーの両方にPostgreSQLをインストールしたら、以下のステップを実行してください。
- まず、PostgreSQLのデータベースに以下のコマンドでログインしてください。
su - postgres - 以下のコマンドでレプリケーションユーザーを作成します。
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Ubuntuの任意のnanoアプリケーションでpg_hba.cnfを編集し、以下の設定を追加してください。
nano /etc/postgresql/10/main/pg_hba.confこのファイルを設定するには、以下のコマンドを使用します。
host replication replication MasterIP/24 md5 - postgresql.confを開いて編集し、プライマリサーバーに以下の設定を入れます。
nano /etc/postgresql/10/main/postgresql.conf以下のコンフィギュレーション設定を使用してください。
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - 最後に、プライマリメインサーバーでPostgreSQLを再起動します。
systemctl restart postgresqlこれでプライマリサーバーでの設定は完了です。
セカンダリーサーバーでのレプリケーションの設定
以下の手順で、セカンダリーサーバーにレプリケーションを設定します。
- 以下のコマンドでPostgreSQL RDMSにログインしてください。
su - postgres - 以下のコマンドで、PostgreSQL のサービスを停止し、作業できるようにします。
systemctl stop postgresql - このコマンドでpg_hba.confファイルを編集し、以下の設定を追加してください。
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - セカンダリサーバーのpostgresql.confを開いて編集し、以下の設定を入れるか、コメントになっている場合はアンコメントしてください。
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPはセカンダリサーバーのアドレス - セカンダリサーバーのPostgreSQLのデータディレクトリにアクセスし、すべて削除する。
cd /var/lib/postgresql/10/main rm -rfv * - PostgreSQLプライマリサーバーのデータディレクトリのファイルをPostgreSQLセカンダリサーバーのデータディレクトリにコピーし、セカンダリサーバーに以下のコマンドを記述します。
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - プライマリーサーバーのPostgreSQLパスワードを入力し、「Enter」キーを押します。次に、リカバリ設定として、以下のコマンドを追加します。
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'ここで、
YOUR_PASSWORDは、プライマリサーバーPostgreSQLで作成したレプリケーションユーザーのパスワードです。 - パスワードが設定できたら、セカンダリPostgreSQLデータベースが停止しているので、再起動する必要があります。
systemctl start postgresqlセットアップのテスト
それでは、レプリケーションのテストとセカンダリサーバーのデータベースを見てみましょう。プライマリサーバーでテーブルを作成し、セカンダリサーバーに同じものが反映されるかどうかを確認します。
早速やってみましょう。
- プライマリサーバーにテーブルを作成するので、プライマリサーバーにログインする必要があります。
su - postgres psql - ここで、「testtable」という名前の簡単なテーブルを作成し、ターミナルで以下のPostgreSQLのクエリを実行して、テーブルにデータを挿入します。
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - セカンダリサーバーにログインして、セカンダリサーバーのPostgreSQLデータベースを確認します。
su - postgres psql - テーブル「testtable」が存在するかどうかを確認します。ターミナルで以下のPostgreSQLクエリを実行することで、データを返すことができます。このコマンドは、テーブル全体を表示するものです。
select * from testtable;
テストテーブルの出力は以下のようになります。
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------プライマリサーバーと同じデータを確認できるはずです。
上記のように表示されれば、レプリケーションの実行は成功です。
PostgreSQLの手動フェイルオーバーの手順
それでは、PostgreSQLの手動フェイルオーバーの手順を説明します。
- プライマリサーバーをクラッシュさせます。
- スタンバイサーバーで以下のコマンドを実行しスタンバイサーバーの昇格を行います。
./pg_ctl promote -D ../sb_data/ server promoting - 昇格したスタンバイサーバーに接続し、行を挿入します。
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
挿入が正常に行われていれば、これまで読み取り専用だったスタンバイが新しいプライマリサーバーとして昇格したことになります。
PostgreSQLでフェイルオーバーを自動化する方法
自動フェイルオーバーを設定するのは簡単です。
EDB PostgreSQLフェイルオーバーマネージャー(EFM)が必要です。EFMをダウンロードし、プライマリノードとスタンバイノードにインストールした後、EFMクラスタを作成します。
EFMはシステムの健全性を継続的に監視し、システムイベントに基づいてメールによる警告を送信してくれます。障害が発生すると、自動的に最新のスタンバイに切り替わり、他のすべてのスタンバイサーバーを再構成して新しいプライマリノードを認識する仕様です。
また、ロードバランサー(pgPoolなど)の再設定も行い、「スプリットブレイン」(2つのノードがそれぞれプライマリだと思い込んでしまう状態のこと)の発生を防ぎます。
まとめ
大量のデータを扱うため、スケーラビリティとセキュリティはデータベース管理、特にトランザクション環境において最も重要な2つの要素となっています。既存のノードにリソース/ハードウェアを追加することで、垂直方向にスケーラビリティを向上させることができますが、多くの場合、新しいハードウェアを追加するためのコストや制限があるため、どんな状況でも可能というわけではありません。
したがって、水平方向のスケーラビリティが求められます。これは、既存のノードの機能を強化するのではなく、既存のネットワークノードにさらにノードを追加することを意味します。そこで、PostgreSQLのレプリケーションの出番です。
今回は、PostgreSQLのレプリケーションの種類、メリット、レプリケーションモード、インストール、PostgreSQLのフェイルオーバー(SMRとMMR)について解説しました。
あなたは普段、どんな方法を導入していますか?あなたにとって最も重要なデータベースの機能は何ですか?そして、その理由は?以下のコメント欄でお聞かせください。


