
データ主導がもはや当たり前になった昨今。その量と複雑さがかつてないペースで拡大し、堅牢かつスケーラブルなデータベースソリューションの必要性が高まっています。2025年までに生成が予想されるデータ量は180ゼタバイトとのこと。これは途方もない数字です。
データとユーザーの需要が急増し、単一のデータベースロケーションに依存する手法はもはや非現実的なものに。システムの遅延を招き、開発者にとっての手間になります。そこで、シャーディングなどのデータベース最適化の出番です。
今回は、MongoDBのシャーディングを掘り下げ、その利点、構成要素、ベストプラクティス、よくある間違い、そして利用開始の要点をご紹介します。
データベースのシャーディングとは
データベースのシャーディングとは、データベースの管理手法のひとつで、増大するデータベースを水平方向に分割して、より小さく管理しやすい小さな単位にすることです。
データベースが拡大するにつれて、データベースを複数の小さな部分に分割し、各部位を別々のマシンに保存することが実用的になります。これらの小さな部分(シャード)は、データベース全体の独立したサブセットという位置づけです。このようにデータを分割して分散するプロセスこそが、データベースのシャーディングです。
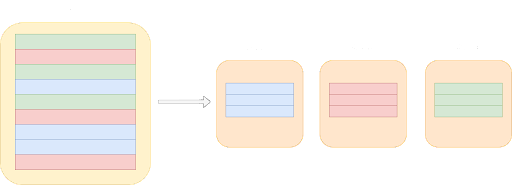
シャーディングデータベースを実装する場合、カスタムシャーディングソリューションを開発するか、既存のものを購入するかの2つのアプローチがあります。そのため「シャーディングソリューションを構築するのと、お金を払って導入するのとでは、どちらが適しているのか」という疑問が生じます。

この選択をするためには、以下の要素を念頭に置きながら、サードパーティの統合コストを検討する必要があります。
- 開発者のスキルと学習能力:製品に関連する学習にかかる手間と開発者のスキルにどの程度適合するか。
- システムが提供するデータモデルとAPI:どのデータシステムにも、データを表現する独自の方法がある。アプリケーションを製品に統合する際の利便性と容易さを考慮すべき。
- カスタマーサポートとオンラインドキュメント:統合中に問題が発生したり、サポートが必要になったりした場合、カスタマーサポートや包括的なオンラインドキュメントの質と可用性が非常に重要になる。
- クラウド展開の可用性:クラウドに移行する企業が増える中、サードパーティ製品がクラウド環境に導入可能かどうかを見極めることが重要。
これらの要因に基づいて、シャーディングソリューションを構築するか、ソリューションにお金を払うかを決めることができます。
データベースのほとんどは、シャーディングをサポートしています。例えば、MariaDB(Kinstaの高性能サーバースタックの一部)のようなリレーショナルデータベースや、MongoDBのようなNoSQLデータベースなどがあります。
MongoDBのシャーディングとは
NoSQLデータベースを使用する主な目的は、膨大なボリュームのデータをクエリしたり保存したりする際のコンピューティングとストレージの需要に対処することです。
一般的に、MongoDBのデータベースには多数のコレクションがあります。すべてのコレクションは、キーと値のペアの形式で、さまざまなドキュメントで構成されます。MongoDBでシャーディングを使うと、この大きなコレクションを複数の小さなコレクションに分割できます。これによって、MongoDBでサーバーに負担をかけずにクエリを実行できるようになります。
例えば、Telefónica Techは世界中で3000万台以上のIoTデバイスを管理しています。増え続けるデバイスの使用量に対応するには、弾力的に拡張でき、急成長するデータ環境を管理できるプラットフォームが必要になりました。そこでMongoDBのシャーディングです。コストと容量のニーズにぴったりと合致し優れた選択となりました。
MongoDBのシャーディングにより、Telefónica Techは毎秒11万5000を超えるクエリを実行しています。これは1秒あたり3万件のデータベースへのインサートに相当し、レイテンシは1ミリ秒未満です。
MongoDBシャーディングのメリット
大規模データに対してMongoDBシャーディングを行うメリットをいくつかご紹介します。
ストレージ容量
シャーディングによってデータが分散されることはすでにご説明しました。この分散により、各シャードにはクラスタ全体のデータの断片が格納されます。データセットのサイズが大きくなった時には、シャードを追加することでクラスタのストレージ容量を増やすことができます。
読み書き
MongoDBでは、読み込みと書き込みのワークロードをシャードクラスタ内のシャードに分散し、各シャードでクラスタオペレーションのサブセットを処理できます。どのワークロードも、シャードを追加することでクラスタ全体で水平方向に拡張できます。
高い可用性
シャードとコンフィグサーバをレプリカセットとして展開することで、可用性が向上します。1つまたは複数のシャードのレプリカセットが完全に利用できなくなった場合でも、シャード化したクラスタは部分的な読み取りと書き込みを実行できます。
障害からの保護
計画外の障害によってマシンが停止すると、多くのユーザーが影響を受けることになります。シャード化されていないシステムでは、データベース全体が停止するため、その影響は甚大です。MongoDBのシャーディングによって、ユーザー体験に悪影響が出る可能性をある程度抑制できます。
地理的分散とパフォーマンス
シャードをそれぞれ異なる地域に配置することができます。つまり、顧客へのレイテンシを下げ、リクエストを近い場所にあるシャードにリダイレクトすることが可能です。リージョンのデータガバナンスポリシーに基づいて、特定のシャードを特定のリージョンに配置するように設定することもできます。
MongoDBシャーディングクラスタの構成要素
MongoDBのシャーディングの概念を説明したところで、このようなクラスタを構成するコンポーネントを掘り下げてみましょう。
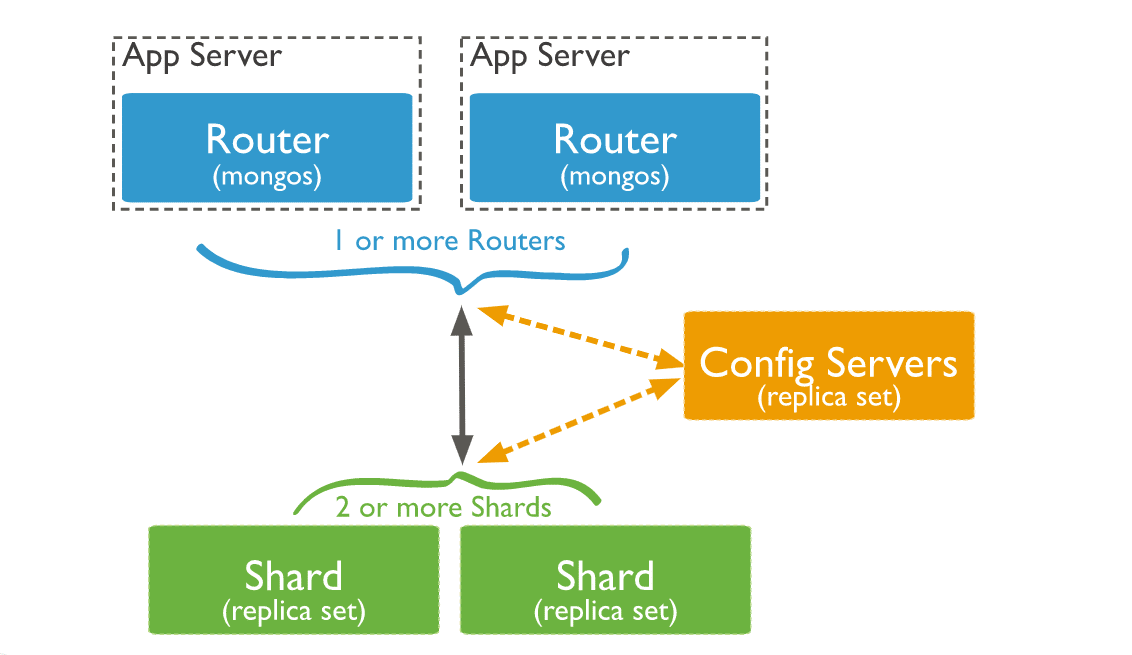
1. シャード
すべてのシャードにデータのサブセットが保存されます。MongoDB 3.6 以降では、シャードはレプリカセットとして用意し高可用性と冗長性を確保する必要があります。
シャードクラスタ内のすべてのデータベースにプライマリシャードがあり、そのデータベースのシャードされていないコレクションをすべて保持します。プライマリシャードはレプリカセットのプライマリとは別物です。
データベースのプライマリシャードを変更するには、movePrimaryコマンドを使用します。プライマリシャードの移行処理にはかなりの時間がかかる場合があります。
その間、移行プロセスが完了するまで、データベースに関連するコレクションにアクセスしないようにしてください。移行されるデータ量に基づいてクラスタ全体の運用に影響を与える可能性があります。
mongoshのsh.status()メソッドを使用すると、クラスタの概要を見ることができます。データベースのプライマリシャード、そしてシャード間のチャンク分布が返されます。
2. configサーバー
シャード化されたクラスタのconfigサーバーをレプリカセットとして配置すると、configサーバー間の一貫性が向上します。これは、MongoDBが設定データの標準的なレプリカセットの読み書きプロトコルを利用できるためです。
configサーバーをレプリカセットとしてデプロイするには、WiredTigerストレージエンジンを実行する必要があります。WiredTigerは書き込み操作にドキュメントレベルの同時実行制御を使用します。そのため、複数のクライアントがコレクションの異なるドキュメントを同時に変更することができます。
configサーバーは、シャード化されたクラスタのメタデータをconfigデータベースに格納します。configデータベースにアクセスするには、mongoシェルで次のコマンドを使います。
use configここで注意すべき制限がいくつかあります。
- congifサーバーに使うレプリカセットのコンフィギュレーションで、アービターはゼロにすること。アービターはプライマリの選挙に参加するものの、データセットのコピーを持っていないので、プライマリになることはできない。
- このレプリカセットは遅延(delayed)メンバーを持つことはできない。遅延メンバーはレプリカセットのデータのコピーを保持する。しかし、遅延メンバーのデータセットには、そのデータの以前の状態または遅延した状態が含まれる。
- configサーバー用にインデックスを構築する必要がある。簡単に言うと、どのメンバーも
members[n].buildIndexes設定をfalseに設定すべきでない。
configサーバーレプリカセットがプライマリメンバーを失い、1人を選出できない場合、クラスタのメタデータは読み取り専用になります。シャードからの読み書きは可能ですが、レプリカセットがプライマリを選べるようになるまでチャンクの分割やマイグレーションは行われません。
3. クエリルーター
MongoDB mongosインスタンスはクエリルーターとして機能し、クライアントアプリケーションとシャード化されたクラスタの接続を担います。
MongoDB 4.4 以降、mongosは遅延を減らすためにヘッジリードをサポートしています。ヘッジドリードを使うと、mongosインスタンスはクエリされたシャードごとに2つのレプリカセットメンバーにreadオペレーションを送信します。そしてシャードごとに最初の応答者から結果を返していきます。
シャードクラスタ内で3つのコンポーネントがどのように機能するかを以下に示します。
mongosインスタンスは次のようにしてクエリをクラスタに送ります。
- クエリを受け取る必要があるシャードの一覧をチェック
- 対象となるすべてのシャードにカーソルを確立
そして、mongosは対象となる各シャードのデータをマージし、結果のドキュメントを返します。ソートのようないくつかのクエリ修飾子は、momgosが結果を取得する前にすべてのシャードで実行されます。
シャードキーやシャードキープレフィックスがクエリの一部になっている場合、mongosはあらかじめ意図された処理を実行し、クラスタ内のシャードのサブクラスを指定します。
プロダクションクラスタでは、データを冗長化し、システムの可用性を高めることをお忘れなく。本番用シャードクラスタのデプロイには以下の構成を選択できます。
- 各シャードを3メンバーのレプリカセットとしてデプロイ
- configサーバーを3メンバーのレプリカセットとしてデプロイ
- 1台以上のmongosルーターをデプロイ
非プロダクションクラスタの場合、以下のコンポーネントでシャードクラスタをデプロイすることができます。
- 単一のシャードレプリカセット
- 1台のレプリカセットconfigサーバー
- 1つのmongosインスタンス
MongoDBシャーディングのしくみ
ここまでシャードクラスタのさまざまな構成要素について説明してきましたが、いよいよそのプロセスに進みます。
データを複数のサーバーに分割するにはmongosを使います。MongoDBへのクエリ送信のために接続すると、mongosがデータがどこにあるかを調べます。そして適切なサーバーからデータを取得し、複数のサーバーに分かれている場合はすべてをマージします。
この処理はバックエンドで行われるので、アプリケーション側では何もする必要はありません。MongoDBは通常のクエリ接続と同じように動作します。クライアントがmongosに接続し、あとはconfigサーバーが処理を行います。
MongoDBシャーディングを順を追って設定する
MongoDBでシャーディングを設定するには、いくつかのステップを踏まなければなりません。MongoDBでのシャーディングの設定方法をご説明します。
まず最初に、MongoDBでシャーディングを設定するには、少なくとも3台のサーバーが必要だということにご注意ください。1 台はconfigサーバー、もう1台はmongosインスタンス、そしてもう1台はシャード用です。
1. configサーバーからディレクトリを作る
まず始めに、configサーバーのデータ用のディレクトリを作ります。これは、最初のサーバーで以下のコマンドを実行することで可能になります。
mkdir /data/configdb2. 設定モードでMongoDBを起動する
次に、最初のサーバーで次のコマンドを使ってMongoDBを設定モードで起動します。
mongod --configsvr --dbpath /data/configdb --port 27019これでport 27019でconfigサーバーが起動し、/data/configdbディレクトリにデータが保存されます。--configsvrを使って、このサーバーがconfigサーバーとして使われることを示している点にご注意ください。
3. Mongosインスタンスの起動
次のステップはmongosインスタンスの起動です。このプロセスで、シャーディングキーに基づいてクエリを対応するシャードにルーティングします。mongosインスタンスを起動するには、次のコマンドを使います。
mongos --configdb <config server>:27019<config server>の部分はconfigサーバーが動いているマシンのIPアドレスかホスト名に置き換えてください。
4. Mongosインスタンスに接続する
mongosインスタンスが起動したら、MongoDBシェルを使って接続します。それには次のコマンドを実行します。
mongo --host <mongos-server> --port 27017このコマンドでは、<mongos-server>をmongosインスタンスを動かしているサーバーのホスト名あるいはIPアドレスに置き換えます。これでMongoDBシェルが開き、mongosインスタンスとやりとりしたりクラスタにサーバーを追加したりできるようになります。
<mongos-server>をmongosインスタンスが動いているマシンのIPアドレスかホスト名に置き換えることをお忘れなく。
5. サーバーをクラスタに追加する
mongosインスタンスに接続できたので、次のコマンドを実行してサーバーをクラスタに追加できます。
sh.addShard("<shard-server>:27017")このコマンドでは、<shard-server>をシャードを実行しているサーバーのホスト名かIPアドレスに置き換えてください。シャードをクラスタに追加し、使えるようにします。
クラスタに追加したいシャードごとにこの手順を繰り返します。
6. データベースのシャーディングの有効化
最後に、以下のコマンドを実行してデータベースのシャーディングを有効にします。
sh.enableSharding("<database>")このコマンドでは、<database>をシャーディングしたいデータベースの名前に置き換えてください。これで指定したデータベースのシャーディングが有効になり、データを複数のシャードに分散できるようになります。
以上です。これで、MongoDBシャーディングクラスタが機能するはずです。
MongoDBシャーディングのベストプラクティス
シャードクラスタをセットアップしましたが、最適なパフォーマンスを確保するためには定期的な監視とメンテナンスが欠かせません。MongoDBシャーディングのベストプラクティスには以下のようなものがあります。
1. 適切なシャードキーを決める
シャードキーはMongoDBシャーディングの重要な要素です。シャード間でデータを一様に(偏りなく)分散させ、もっともよく使われるクエリをサポートするシャードキーを選ぶことが重要です。ホットスポットを作ったり、データを不均一に分散させたりするようなキーは避けるべきです。
適切なシャードキーを選択するには、データと実行するクエリのタイプを分析し、その要件を満たすキーを選択する必要があります。
2. データ増加を見越した計画
シャードクラスタをセットアップする際には、現在のワークロードを処理するのに十分な数のシャードから始め、必要に応じて追加することで、将来の成長を計画していきましょう。ハードウェアとネットワークインフラが、将来的に予想されるシャードの数とデータ量をサポートできる必要があります。
3. シャード専用ハードウェアの使用
パフォーマンスと信頼性を最適化するために、各シャードに専用のハードウェアを使用することも重要です。各シャードに専用のサーバーまたは仮想マシンを用意し、干渉を受けずにすべてのリソースを利用できるようにしましょう。
共有型のハードウェアを使用すると、リソースの競合やパフォーマンスの低下を招き、システム全体の信頼性に悪影響が出る可能性があります。
4. シャードサーバーにレプリカセットを使用する
シャードサーバーにレプリカセットを使うと、MongoDBシャードクラスタに高い可用性とフォールトトレランスを確保できます。各レプリカセットを3つ以上のメンバーで構成し、それぞれのメンバーは別々の物理マシンに置くようにします。こうすることで、シャード化したクラスタがひとつのサーバーやレプリカセットのメンバーの障害に耐えられるようになります。
5. シャードのパフォーマンスの監視
大きな問題になる前に特定できるように、シャードのパフォーマンスを監視することが非常に重要です。各シャードサーバーのCPU、メモリ、ディスクI/O、ネットワークI/Oを監視して、シャードがワークロードを処理できることを確認する必要があります。
mongostatやmongotopなどのMongoDB組み込みの監視ツールや、Datadog、Dynatrace、Zabbixなどのサードパーティの監視ツールを使ってシャードのパフォーマンスを追跡できます。
6. ディザスタリカバリの計画
ディザスタリカバリの計画は、MongoDBシャーデッドクラスタの信頼性を維持するために不可欠です。定期的なバックアップ、バックアップが有効かどうかのテスト、障害発生時のバックアップのリストア計画など、ディザスタリカバリ計画を立てる必要があります。
7. 状況を鑑みハッシュベースのシャーディングを使用する
アプリケーションが範囲を限定したクエリを発行する場合、操作をより少ないシャード(ほとんどは単一のシャード)に限定できるため範囲ベースのシャーディングが有用です。これを実装するには、データとクエリパターンを理解する必要があります。
ハッシュシャーディングは、読み取りと書き込みの均一な分散に使えます。しかし、効率的な範囲ベースの操作はできません。
MongoDBデータベースをシャーディングするときに避けるべきこと
MongoDBシャーディングは、データベースを水平方向に拡張して複数のサーバーにデータを分散させる強力なテクニックです。しかし、典型的な間違いもいくつかあります。MongoDBデータベースをシャーディングするときに避けるべきこととその方法をご紹介します。
1. 間違ったシャーディングキーの選択
MongoDBデータベースをシャーディングするときに最も重要な決断のひとつが、シャーディングキーの選択です。間違ったキーを選ぶと、データの分散にムラができたり、ホットスポットができたり、パフォーマンスが低下したりします。
よくある間違いは(ハッシュシャーディングではなく)範囲ベースのシャーディングを使用する際に、新しいドキュメントに対して数量の増加する性質のシャードキー値を選択することです。例えば、タイムスタンプ(当然増えていく)や、ObjectID(最初の4バイトがタイムスタンプなど)のように、時間に紐付いたものが考えられます。
そのような状況では、すべてのインサートが最も対象範囲の広いチャンクに向けられます。新しいシャードを追加し続けても、最大書き込み容量が増えるわけではありません。
書き込み容量の拡張を計画しているのであれば、ハッシュベースのシャードキーを使ってみるのがいいでしょう。
2. シャードキーの値を変更しようとする
シャードキーは既存のドキュメントに対して不変であり、キーを変更することはできません。シャーディングの前に特定の調整を行うことはできますが、シャーディングの後にはできません。既存のドキュメントのシャードキーを変更しようとすると、以下のエラーで失敗します。
cannot modify shard key's value fieldid for collection: collectionnameシャードキーを修正しようとする代わりに、ドキュメントを削除して再び挿入することで、シャードキーを刷新することができます。
3. クラスタの監視の失敗
シャーディングはデータベース環境に一定の複雑さをもたらすため、クラスタを綿密に監視することが不可欠になります。クラスタの監視を怠ると、パフォーマンスの問題、データの損失、その他の問題につながる可能性があります。
この失敗を避けるために、CPU使用率、メモリ使用率、ディスク容量、ネットワークトラフィックなどの主要な指標を追跡する監視ツールを設定する必要があります。また、特定のしきい値を超えた場合にアラートを設定することも有効です。
4. 新しいシャードの追加を怠る(過負荷の発生)
MongoDBデータベースをシャーディングするときによくある間違いとして、新しいシャードの追加を怠る(またはそれを先延ばしにする)ことも挙げられます。シャードがデータやクエリで過負荷になると、パフォーマンスの問題につながり、クラスタ全体の速度が低下します。
2つのシャードで構成される架空のクラスタがあり、20000チャンク(5000チャンクが「アクティブ(アクセスが頻繁にある)」)があるとして、3つ目のシャードを追加する必要があるとします。この3番目のシャードは、最終的に「アクティブ」なチャンク(およびチャンク合計)の3分の1を保存することになります。
ここでの課題は、いつシャードがオーバーヘッドを追加しなくなり実際に価値あるアセットになるか、絶妙なタイミングを見極めることです。「アクティブ」なチャンクを新しいシャードに移行する際にシステムで発生する負荷を計算し、それがシステム全体の利益と比較して「許容できる」ようになるタイミングを計算する必要があります。
ほとんどの状況で、過負荷のシャードではこの一連の移行にさらに時間がかかり、新しく追加したシャードがしきい値を超えて正味の利益になるまでにはるかに時間がかかることが想像できます。そのため、必要になる前に積極的に容量を追加するのが最善です。
可能な緩和策としては、クラスタを定期的に監視し、トラフィックの少ない時間帯に新しいシャードを積極的に追加して、リソースの競合を少なくすることが挙げられます。ターゲットを絞った「ホット」チャンク(他のチャンクよりもアクセスが多い)のバランスを手動でとり、アクティビティを新しいシャードに素早く移動することをお勧めします。
5. configサーバーのプロビジョニング不足
configサーバーのプロビジョニングが不足していると、パフォーマンスの問題や不安定さにつながる可能性があります。プロビジョニングの問題は、CPU、メモリ、ストレージなどのリソースの割り当て不足が原因で発生することがあります。
その結果、クエリのパフォーマンスが低下したり、タイムアウトやクラッシュが発生したりします。これを避けるためには、特に大規模クラスタでは、configサーバーに十分なリソースを割り当てることが不可欠です。configサーバーのリソース使用量を定期的に監視することで、プロビジョニング不足の問題を特定することができます。
これを防ぐもう1つの方法は、他のクラスタコンポーネントとリソースを共有するのではなく、configサーバーに専用のハードウェアを使用することです。これは、configサーバーのワークロードを処理するのに十分なリソースを確保するのに有用です。
6. データのバックアップとリストアの失敗
バックアップは、障害時にデータが失われないようにするために不可欠です。データの損失は、ハードウェアの故障、人為的ミス、悪意のある攻撃など、さまざまな理由で発生する可能性があります。
データのバックアップと復元を怠ると、損失やダウンが発生するかもしれません。このような失敗を避けるためには、定期的なバックアップ、テストバックアップ、テスト環境へのデータのリストアなど、バックアップとリストアの戦略が必要です。
7. シャードクラスタのテストの失敗
シャードクラスタを本番環境にデプロイする前に、想定される負荷とクエリを処理できることを確認するために、徹底的にテストを行ってください。シャードクラスタのテストを怠ると、パフォーマンスが低下したりクラッシュしたりする危険性があります。
MongoDBシャーディングとクラスタ化インデックスの比較─大規模データセットとの相性
MongoDBシャーディングとクラスタインデックスは、どちらも大きなデータセットを扱うのに効果的な戦略です。しかし、その目的は異なります。適切なアプローチを選択できるかどうかは、アプリケーションの具体的な要件に依存します。
シャーディングは多数のノードにデータを分散させる水平スケーリング技術で、書き込みレートが高い大きなデータセットを扱うのに効果的です。アプリケーションにとっては透過的で、あたかも一つのサーバーであるかのようにMongoDBとやりとりできます。
一方、クラスタ化インデックスは、大きなデータセットからデータを取得するクエリのパフォーマンスを引き上げます。クエリがインデックス化したフィールドにマッチしたときに、MongoDBでより効率的にデータを見つけられる仕組みです。
では、大きなデータセットにはどちらが効果的なのでしょうか。その答えは、特定の状況や処理の要件次第です。
アプリケーションで高い書き込みとクエリのスループットが必要で、水平方向に拡張する必要がある場合は、MongoDBのシャーディングが有効でしょう。しかし、読み込みが多く、頻繁にクエリされるデータを特定の順序で整理する必要がある場合には、クラスタ化インデックスのほうが効果的かもしれません。
シャーディングもクラスタ化インデックスも、MongoDBで大きなデータセットを管理するのに有用な選択肢です。重要なのは、アプリケーションの要件とワークロードの特性を慎重に評価し、特定のケースにぴったりの手法を決定することです。
まとめ
シャード化クラスタは、大量のデータを扱うことができる強力なアーキテクチャで、成長するアプリケーションの要件に合わせて水平方向に拡張することができます。クラスタはシャード、configサーバー、mongosプロセス、クライアントアプリケーションで構成され、データがシャードキーに基づきパーティショニングされます。
シャーディングのパワーを活用することで、アプリケーションでの高可用性、パフォーマンスの向上、ハードウェアリソースの効率的な利用を実現できます。適切なシャーディングキーを選択することが、データを均等に分散するために非常に重要です。
あなたはMongoDBとデータベースのシャーディングについてどう思いますか?シャーディングについて、扱って欲しい内容はありましたでしょうか?コメント欄でお聞かせください。


