
De afgelopen 18 maanden is de aandacht voor botverkeer verschoven van crawlen en indexeren naar de invloed ervan op de prestaties van je server, je hostingkosten en je vermogen om echte klanten te bedienen.
We weten dit omdat we meer dan 10 miljard verzoeken hebben geanalyseerd binnen de door Kinsta beheerde infrastructuur, en wat we ontdekten was geen verhaal over aanvallen. Het was een verhaal over resources.
“Vanuit infrastructuurperspectief bestaat er niet zoiets als ‘alleen maar botverkeer'”, aldus Daniel Pataki, CTO van Kinsta. “Elk verzoek is echt werk. Op grote schaal is inefficiënt crawlen geen verkeersprobleem meer, maar een probleem met de beschikbare resources.”
In dit artikel leggen we uit waarom die verschuiving heeft plaatsgevonden, wat het WordPress-site-eigenaren daadwerkelijk kost en hoe het verhaal moet veranderen.
Het oude model werkt niet meer
Traditioneel botbeheer was gebaseerd op een simpel uitgangspunt: blokkeer de slechte en laat de goede door. Jarenlang was dat genoeg. Googlebot crawlde je pagina’s, indexeerde je content en ging weer verder. Kwaadaardige bots probeerden in te breken op je inlogpagina. Twee heel verschillende problemen, twee heel verschillende oplossingen.
Waar geen van beide modellen rekening mee hield, was een derde categorie: geautomatiseerd verkeer dat niet kwaadaardig is en niet wordt geblokkeerd, maar op grote schaal meetbare schade toebrengt aan de prestaties van je site.
AI-crawlers – bots die niet alleen zijn ontworpen om pagina’s te indexeren voor zoekresultaten, maar ook om content te verzamelen voor het trainen van modellen, retrieval-augmented generation en realtime zoekopdrachten van gebruikers – opereren op een fundamenteel andere schaal dan alles wat er eerder was. GPTBot alleen al groeide met 305% tussen mei 2024 en mei 2025. Begin 2025 was ongeveer één op de 200 webbezoeken afkomstig van een AI-bot. Tegen het einde van het jaar was die verhouding gestegen naar één op de 31.
Eind 2025 waren AI-crawlers goed voor 4,2% van alle HTML-verzoeken op het netwerk van Cloudflare, een cijfer dat schommelde van 2,4% begin april tot 6,4% eind juni – bijna een verdrievoudiging binnen een jaar.
Deze crawlers zijn hardnekkig en komen vaak langs, en ze gedragen zich niet zoals traditionele zoekmachinebots. Veel ervan genereren grote hoeveelheden verzoeken naar niet-gecachete, dynamische endpoints, wat je server ‘echt werk’ bezorgt.
Wat ‘echt werk’ betekent voor een WordPress-site
Hier wordt het infrastructuurprobleem duidelijk, en dat is een aspect dat in de meeste analyses van botverkeer over het hoofd wordt gezien.
Als een bezoeker een in de cache opgeslagen pagina op een WordPress-site laadt, hoeft je server bijna niets te doen. Hij stuurt een vooraf opgebouwd HTML-bestand terug, net zoals hij een afbeelding of een CSS-bestand zou serveren. De oorspronkelijke server merkt er nauwelijks iets van. Dat is juist het hele punt van caching.
Maar een aanzienlijk deel van de verzoeken op een echte WordPress-site, en met name op WooCommerce-winkels, kan niet vanuit de cache worden verwerkt. Deze verzoeken omvatten:
- Winkelwagen- en afrekenpagina’s (
?add-to-cart=,/cart,/checkout) - Gefilterde productpagina’s met URL-parameters
- Zoekopdrachten
- AJAX-gestuurde interacties (items toevoegen aan verlanglijstje, live prijsupdates, dynamische pop-ups)
- Sessiegebaseerde pagina’s waarbij de server een gebruikerscontext moet valideren of aanmaken
Als een bot deze endpoints bezoekt, gebeurt er het volgende op je server:
- Er wordt een PHP-thread gereserveerd. Elk dynamisch verzoek op WordPress neemt één PHP-thread in beslag voor de volledige duur van de verwerking, meestal 200–500 ms, langer als de pagina complex is. Die thread is niet beschikbaar voor andere verzoeken totdat de taak is voltooid. Je hostingpakket bevat een vast aantal PHP-threads.
- Je database voert een query uit. Dynamische pagina’s doen bij elke laadbeurt een query naar je database. Bij normaal menselijk verkeer is dit te behappen. Bij aanhoudende botbelasting op niet-gecachete paden voert de database constant queries uit. Als bots unieke URL-variaties raken die geen cache-hits opleveren, triggert elke variant zijn eigen queryketen.
- Er ontstaat sessie-overhead. Winkelwagen- en afrekenpagina’s maken of valideren sessies, zelfs voor bots die nooit converteren. Dit zorgt voor extra verwerkingskosten bij elk van die verzoeken.
- PHP-threads raken vol. Als alle beschikbare PHP-threads bezet zijn, worden legitieme bezoekers niet meteen bediend, waardoor hun verzoeken in de wachtrij terechtkomen. Als de wachtrij vol raakt, krijg je te maken met traag ladende pagina’s, vastgelopen afrekenprocessen en 504-fouten. Voor een echte klant die een aankoop wil afronden, lijkt je site kapot.
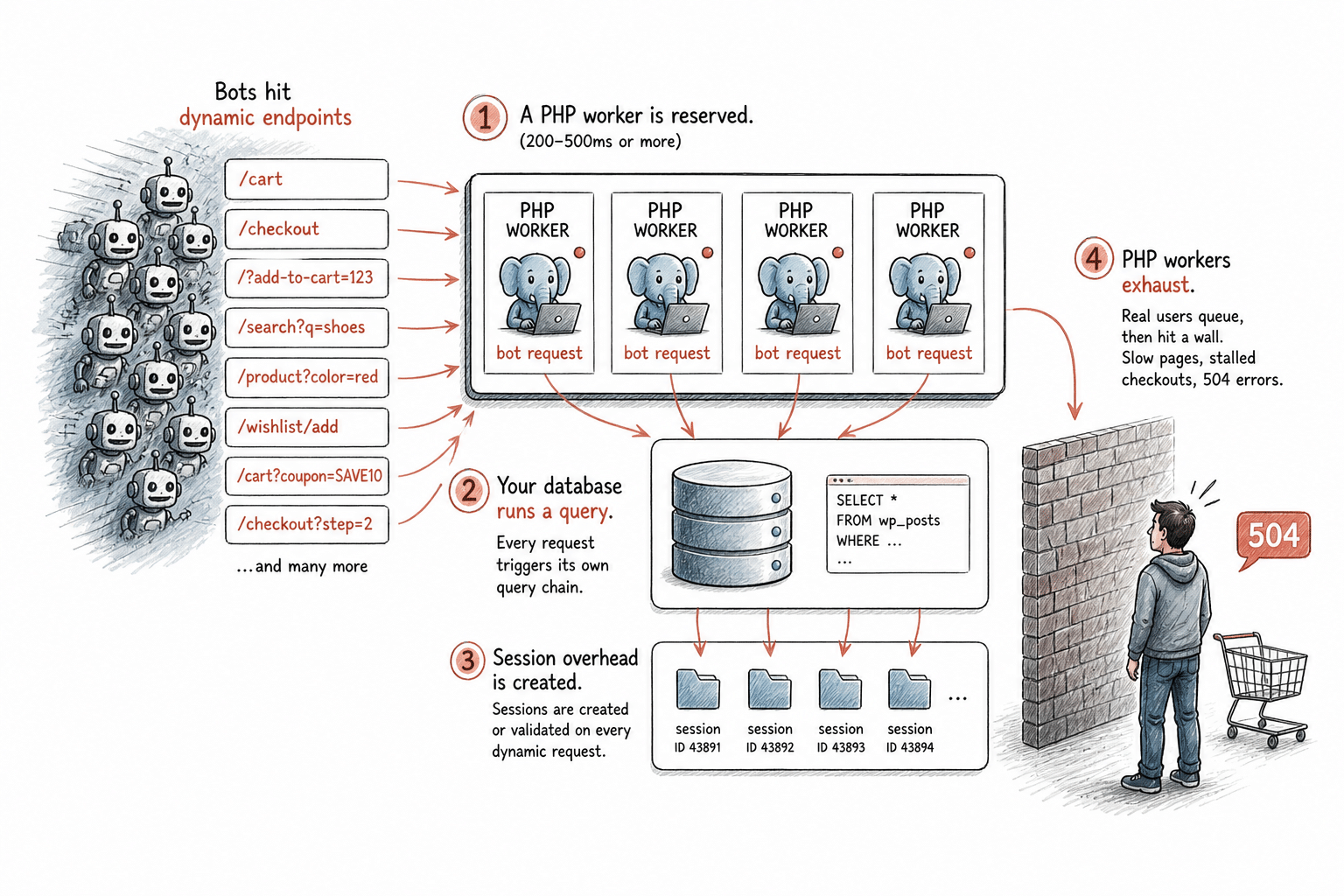
Dit is het mechanisme waardoor botverkeer een infrastructuurprobleem wordt. Het is geen theorie. Het is de specifieke reeks gebeurtenissen die plaatsvindt wanneer geautomatiseerde verzoeken dynamische endpoints op een live WordPress-site overspoelen.
Wat de infrastructuurgegevens van Kinsta daadwerkelijk laten zien
Het abstracte wordt concreet als je kijkt naar echte gegevens van de infrastructuur die we op grote schaal beheren.
Een gegeven dat ons bijzonder opviel, is dat één enkele bot (ClaudeBot) binnen 24 uur 3,75 miljoen ’toevoegen aan winkelwagen’-verzoeken genereerde. Dat is ongeveer één verzoek per 23 milliseconden (de hele dag, de hele nacht), die allemaal door de server als een nieuw verzoek worden behandeld omdat winkelwagen-endpoints van nature dynamisch zijn.
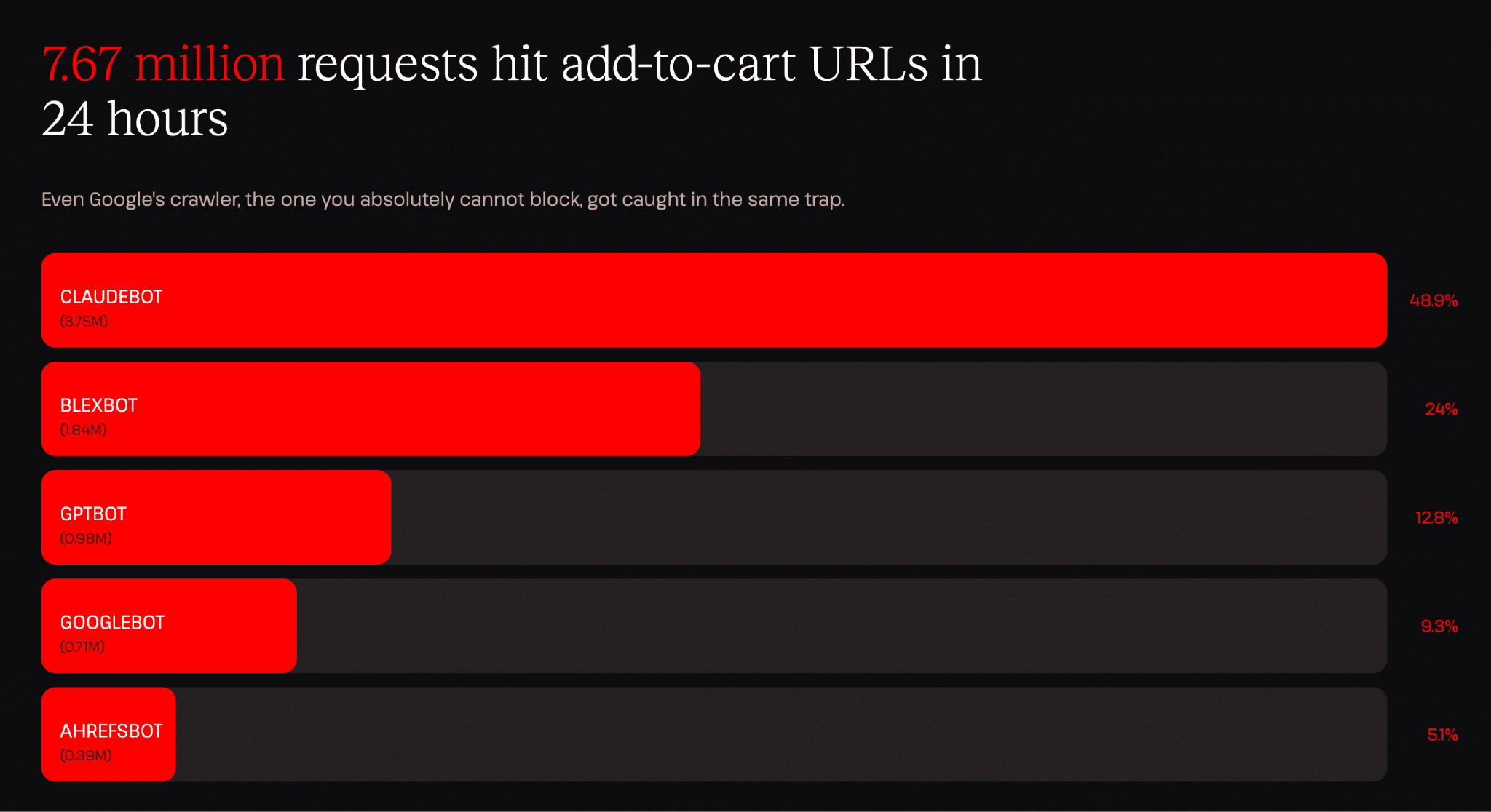
Om dat even in perspectief te zetten: verzoeken om iets aan de winkelwagen toe te voegen behoren tot de duurste endpoints die een WooCommerce-winkel heeft. Ze maken sessies aan, voeren query’s uit en werken de status van de winkelwagen bij. Elk verzoek kost echt werk. De 3,75 miljoen verzoeken die we op één dag vanuit één bron zagen, is het soort verkeerspatroon dat een site offline kan halen.
Een tweede voorbeeld laat zien hoe hardnekkig deze patronen kunnen zijn: één foutief werkende loop genereerde 550 miljoen verzoeken in 30 dagen, genoeg verkeer om een eigen, speciale afschermingsregel in onze infrastructuur te rechtvaardigen. Dit is geen DDoS-aanval of een malwarecampagne, maar een bot die vastzit in een crawlingloop en herhaaldelijk URL’s opvraagt die hij al heeft gezien.
Dit zijn geen uitzonderlijke gevallen. Het zijn patronen die we overal op ons platform zien.
Het loopprobleem: bots vallen niet aan, ze zitten vast
Een van de meest onderschatte aspecten van het huidige botverkeerprobleem is dat het grootste deel van wat schade aan de infrastructuur veroorzaakt helemaal niet kwaadaardig is. Het is inefficiënte automatisering op grote schaal.
Moderne websites, vooral e-commercewinkels, genereren net iets andere URL’s voor in wezen dezelfde pagina:
- Een product met een kleurfilter toegevoegd
- Een winkelwagenpagina met een sessietoken
- Een categorieoverzicht met een parameter voor de sorteervolgorde
Voor een mens zijn dit allemaal “dezelfde pagina”. Voor een bot die URL’s volgt, lijkt elke URL een gloednieuwe pagina die gecrawld moet worden.
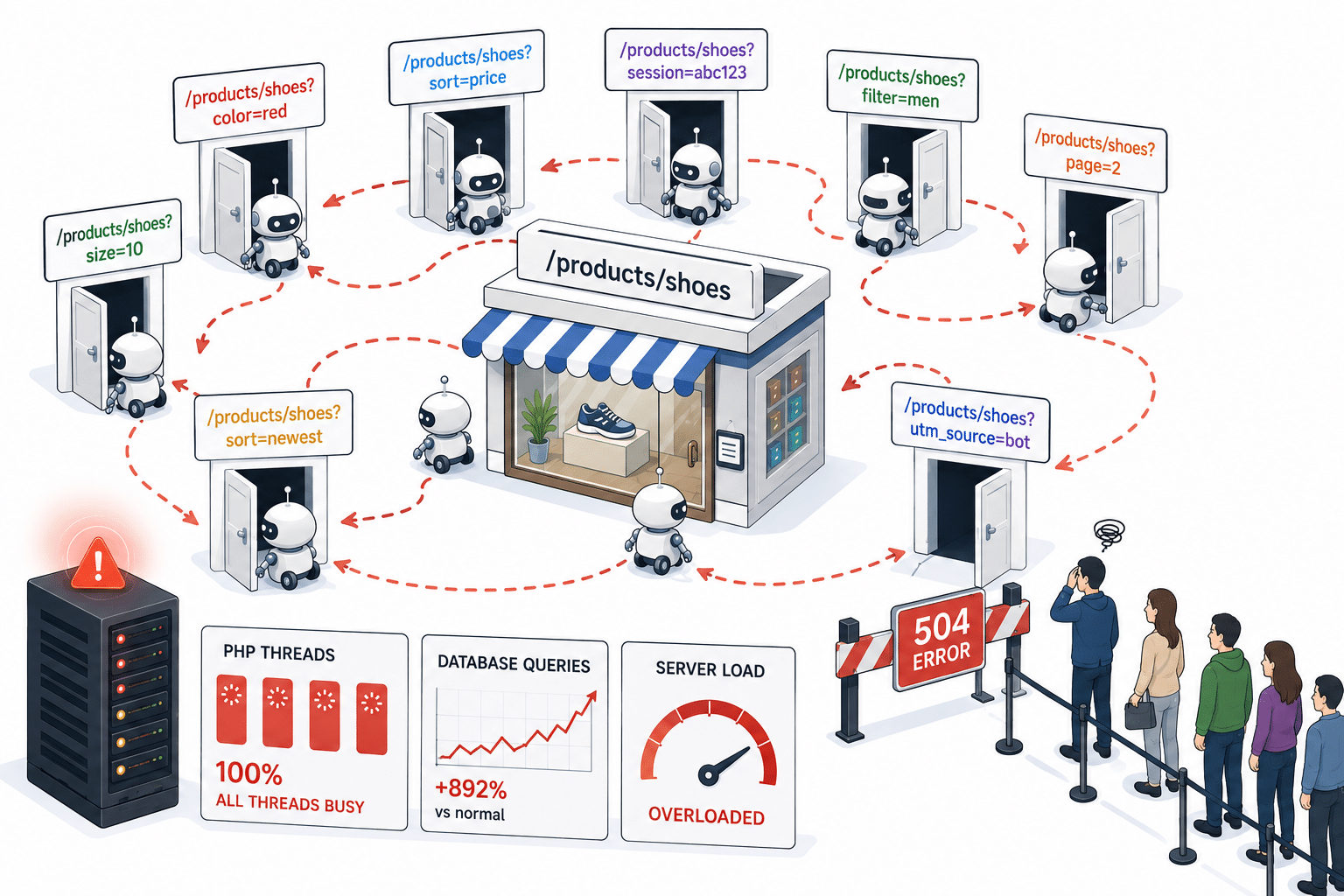
Dus de bot volgt de eerste link. Die pagina genereert weer een andere URL-variant, die de bot volgt. En dan nog een. En nog een. Hij heeft geen mechanisme om te herkennen dat hij in cirkels ronddraait, en sommige van deze loops bleven dagenlang onopgemerkt op de managed infrastructuur voordat de beveiligingsregels ze opmerkten.
In het rapport over AI- en botverkeer dat we onlangs publiceerden, zei David Belson, voormalig hoofd Data Insights bij Cloudflare: „Er is iemand die gisteren geen idee had waar hij mee bezig was, maar vandaag zomaar even een bot in elkaar heeft geknutseld en losgelaten. Die neemt niet eens de moeite om robots.txt te checken.”
Dit gedrag komt niet altijd van kwaadwillende actoren. Het komt van AI-crawlersystemen die niet zijn ontworpen met kennis van gefacetteerde navigatie, wildgroei aan URL-parameters of door sessies gegenereerde URL’s, wat standaardfuncties zijn op moderne WordPress-sites.
Google zelf noemt gefacetteerde navigatie en op parameters gebaseerde URL’s expliciet als een bron van inefficiëntie bij het crawlen, en merkt op dat bots bijna oneindig veel variaties van dezelfde pagina kunnen verkennen.
Je serverfactuur is nu een botbeheerprobleem
Tot voor kort waren veel hostingpakketten afgestemd op het aantal bezoeken, wat redelijk goed werkte als maatstaf voor echt menselijk gebruik. De aanname was dat het aantal bezoeken grofweg overeenkwam met het aantal mensen dat actief met je site bezig was.
Die aanname gaat niet meer op.
Geautomatiseerd verkeer heeft de bezoekersaantallen opgeblazen op een manier die weinig te maken heeft met daadwerkelijke bedrijfsactiviteit. Botverzoeken kunnen bezoekersaantallen genereren zonder dat dit leidt tot bijbehorende betrokkenheid, conversies of omzet. Site-eigenaren kregen overschrijdingsmeldingen bij op bezoekersaantallen gebaseerde pakketten, veroorzaakt door botactiviteit waar ze geen controle over hadden en waar ze niet om hadden gevraagd.
Dit was zo duidelijk een systematisch patroon dat Kinsta hostingpakketten op basis van bandbreedte introduceerde, als directe reactie op een categorie sites waarvan de bezoekcijfers aanzienlijk begonnen af te wijken van hun daadwerkelijke verbruik van resources. Als het aantal bezoeken aan een site groeide maar de bandbreedte geen gelijke tred hield, was dat bijna altijd een teken van bots. Door over te stappen op een bandbreedtemodel werd de facturering effectief losgekoppeld van een statistiek die bots hadden leren opblazen.
Het factureringsprobleem is meetbaar en oplosbaar. Het lastigere probleem is dat de meeste site-eigenaren zich hier helemaal niet van bewust zijn, omdat hun dashboards niet het volledige plaatje laten zien.
Wat je analytics je wel (en niet) vertellen
Een gevolg van botverkeer op deze schaal is dat standaardanalyses geen betrouwbare weergave meer zijn van de werkelijke prestaties van je site.
Als je bezoekersaantallen stijgen, maar je omzet, de tijd op de pagina en het bounce-gedrag niet evenredig meegroeien, spelen bots waarschijnlijk een rol. Als je server prestatieverlies vertoont dat niet overeenkomt met de verkeerspieken die je zou verwachten van content of marketingactiviteiten, is het de moeite waard om botverkeer naar niet-gecachete endpoints te onderzoeken.
Kinsta filtert automatisch bekende bot-user-agents uit de statistieken en berekeningen van je abonnementsgebruik. Maar geautomatiseerd verkeer dat sterk op menselijk gedrag lijkt, kan nog steeds in je statistieken opduiken.
De patronen waar je op moet letten:
- Herhaalde verzoeken naar dezelfde URL-types, vooral paden met veel parameters of op sessies gebaseerde paden
- Verkeerspieken op momenten die niet samenvallen met publicaties, promoties of seizoensgebonden activiteiten
- Verslechtering van de serverprestaties (hogere TTFB, PHP-thread-uitputtingsfouten) tijdens periodes van verhoogd verkeer die niet overeenkomen met echte gebeurtenissen
- Het aantal bezoeken groeit sneller dan de bandbreedte, conversies of betrokkenheidsstatistieken
Geen van deze factoren is op zichzelf doorslaggevend, maar elke combinatie is reden voor nader onderzoek voordat je de cijfers toeschrijft aan bedrijfsgroei.
Waarom dit een moeilijker probleem is dan het lijkt
De meest voorkomende reactie bij het zien van botverkeersgegevens is om alles te blokkeren. Anderen laten misschien alles toe, omdat „AI de toekomst is”.
Geen van beide werkt!
Zomaar alles blokkeren betekent dat je ook geverifieerde crawlers blokkeert, waaronder Googlebot, waarvan de crawl-dekking bepaalt of je content überhaupt in de zoekresultaten verschijnt. Het betekent dat je AI-ontdekkingsbots blokkeert die je content misschien naar voren halen in conversatiegerichte zoekresultaten, AI-aangedreven aanbevelingen of antwoordengines. Voor een WooCommerce-winkel of een contentuitgever zijn dat aanzienlijke distributiekosten.
Alles doorlaten betekent dat je infrastructuurkosten accepteert die geen enkel rendement opleveren. En voor de dynamische endpoints die bots het vaakst raken, zijn die kosten niet marginaal. Ze stapelen zich op en worden steeds groter, vooral bij aanhoudende geautomatiseerde belasting.
Het echte antwoord ligt ergens tussenin, en daarvoor moet je de verschillen tussen verkeerscategorieën begrijpen in plaats van alle bots als één groep te behandelen.
Zoals Cristian Lopez, hoofdredacteur bij HostingAdvice, in het rapport zei: „De misvatting is dat je denkt dat botverkeer een simpel ‘blokkeren of toestaan’-probleem is. In werkelijkheid gaat het om beleid, zichtbaarheid en economische controle.”
Geverifieerde bots, zoals Googlebot, Bing en legitieme monitoringtools, moeten over het algemeen worden toegestaan, met eventueel padbeperkingen voor endpoints die geen crawlwaarde hebben (je afrekenpagina draagt bijvoorbeeld niets bij aan je zoekresultaten). Niet-geverifieerde bots zonder identificatiegegevens of duidelijk doel verdienen meer aandacht. AI-trainingscrawlers die grote hoeveelheden verzoeken naar dynamische endpoints genereren, vormen een specifieke categorie die mogelijk geblokkeerd of aan een snelheidsbeperking onderworpen moet worden, afhankelijk van je type website en prioriteiten.
In ons rapport over AI- en botverkeer hebben we een interactief besluitvormingskader opgesteld dat de juiste aanpak voor verschillende soorten websites uitlegt. Het onderstaande voorbeeld toont de aanbevolen configuratie voor een WooCommerce-winkel die zich richt op siteprestaties en stabiliteit:
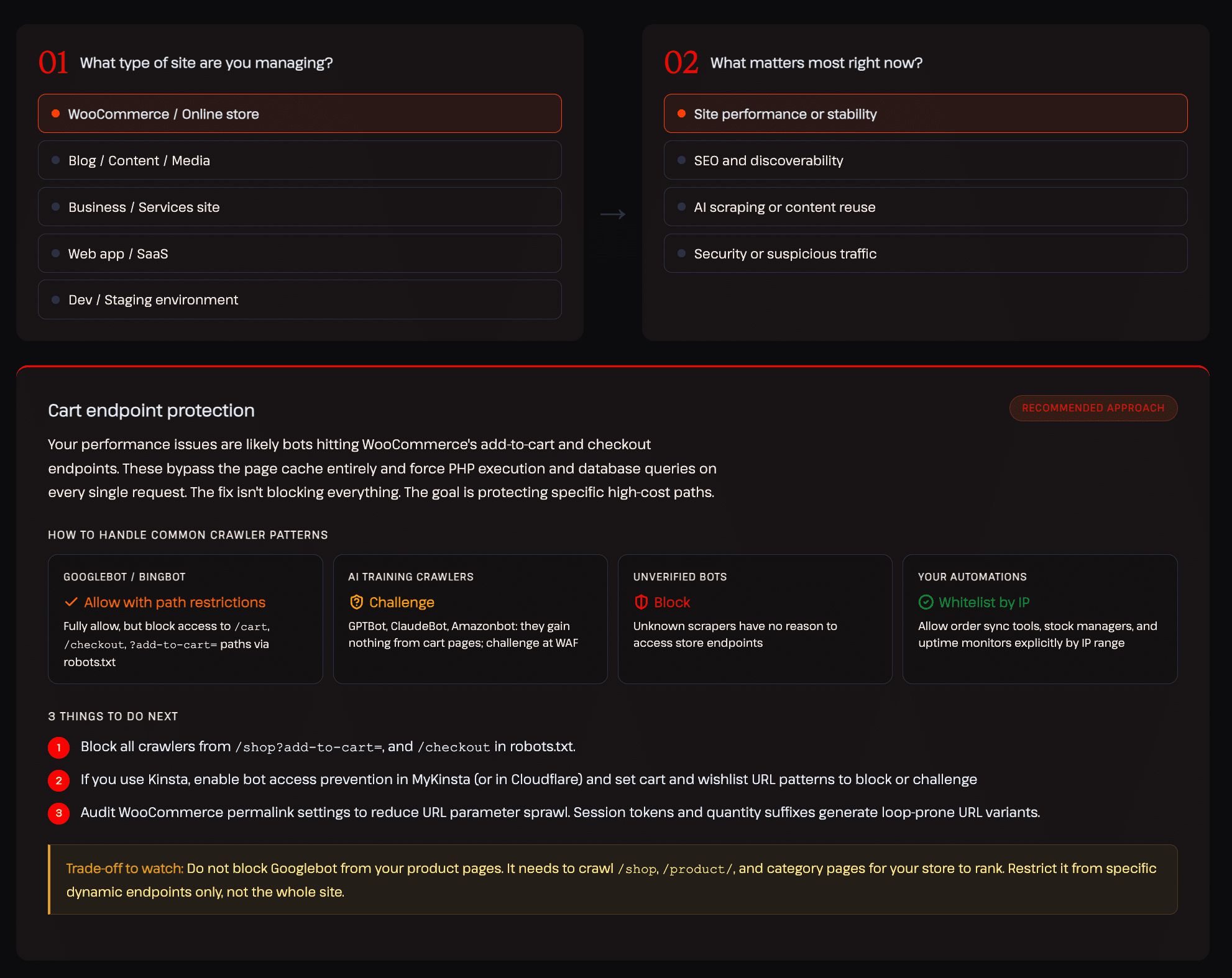
Dat soort genuanceerde, categoriegerichte controle is precies wat de meeste bestaande tools je niet bieden.
De aanpak van Kinsta voor botbescherming
De botbescherming van Kinsta is speciaal ontworpen voor de infrastructuuruitdagingen die we hierboven beschreven.
Het systeem deelt het verkeer in in categorieën, zoals geverifieerde bots, waarschijnlijk mensen, waarschijnlijk bots, geautomatiseerd verkeer en kwaadaardig verkeer, en laat je beschermingsniveaus instellen die aansluiten bij de daadwerkelijke behoeften van je site.

De niveaus zijn niet zwart-wit. ‘Blokkeer automatiseringen’ richt zich op bevestigd geautomatiseerd verkeer, terwijl geverifieerde bots met rust worden gelaten. ‘Daag bots uit’ voegt een verificatiestap toe voor niet-geverifieerde automatisering zonder legitieme bezoekers te hinderen. ‘Daag iedereen uit’ is beschikbaar voor periodes van acute verkeersdruk, maar brengt de te verwachten nadelen met zich mee.
Cruciaal is dat de tool is gebaseerd op Cloudflare’s bot-scoring op zakelijk niveau, een realtime classificatie via machine learning die elke bezoeker een score van 1 tot 99 toekent op basis van gedragssignalen, niet alleen op basis van user-agent-strings. Dit is belangrijk omdat het matchen van user-agents alleen steeds minder effectief is: 12,9% van de AI-bots negeert nu robots.txt-richtlijnen, een stijging ten opzichte van 3,3% slechts één kwartaal eerder. Gedragsclassificatie vangt op wat op user-agents gebaseerde regels missen.
Er is ook een ‘Altijd toestaan’-uitzonderingssysteem voor vertrouwde integraties, monitoringdiensten en bedrijfskritische automatiseringen die niet door de beveiligingsregels mogen worden tegengehouden, want te veel blokkeren kost ook echt geld, vooral voor WooCommerce-winkels die afhankelijk zijn van geautomatiseerde ordersynchronisatie, betalingsgateway-integraties of uptime-monitors.
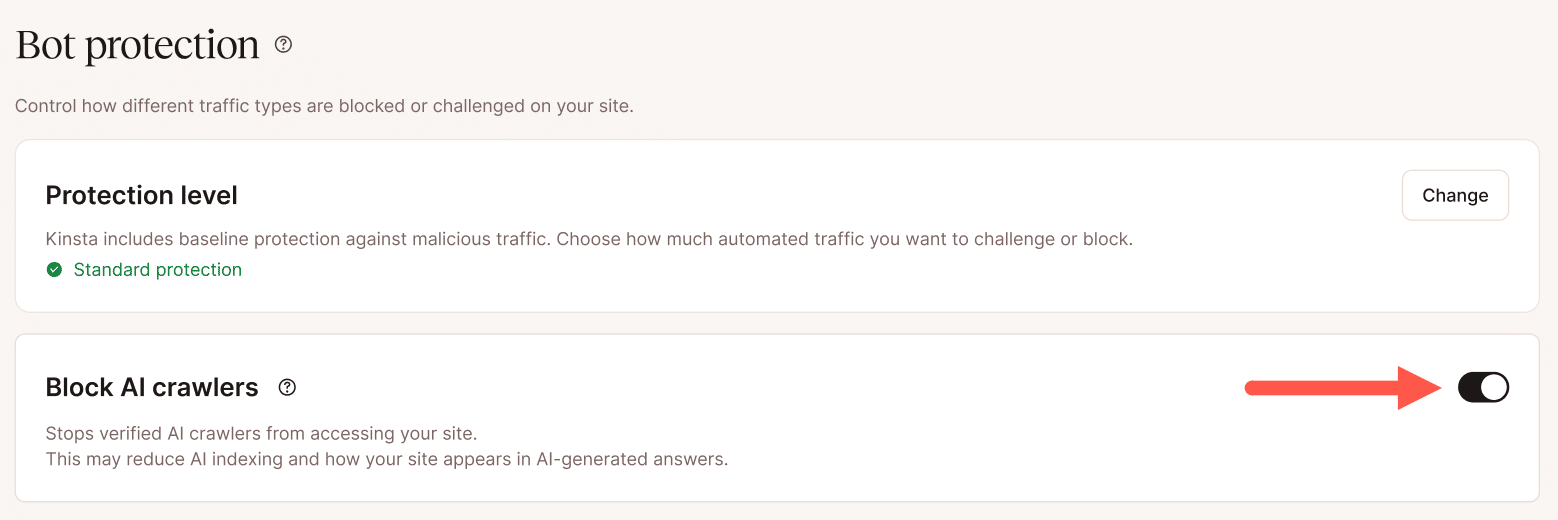
De schakelaar voor het blokkeren van AI-crawlers richt zich specifiek op AI-trainingsbots, zonder dat dit invloed heeft op crawlers van zoekmachines zoals Googlebot of Bingbot. Voor sites die last hebben van de impact van AI-crawleractiviteit op de prestaties, is dit een eenvoudige oplossing in één stap, waarvoor je geen individuele regels hoeft in te stellen.
Weten dat de tool bestaat, is één ding. Weten wanneer en hoe je hem moet gebruiken, is iets anders.
Wat te doen als botverkeer je probleem is
Als je de hierboven beschreven patronen ziet, is dit een praktisch startpunt, gerangschikt op impact:
Ten eerste: controleer de bron. Gebruik de grafiek met verzoekuitsplitsing in het botbeschermingsoverzicht van MyKinsta om te begrijpen hoe het verkeer naar je site wordt ingedeeld.
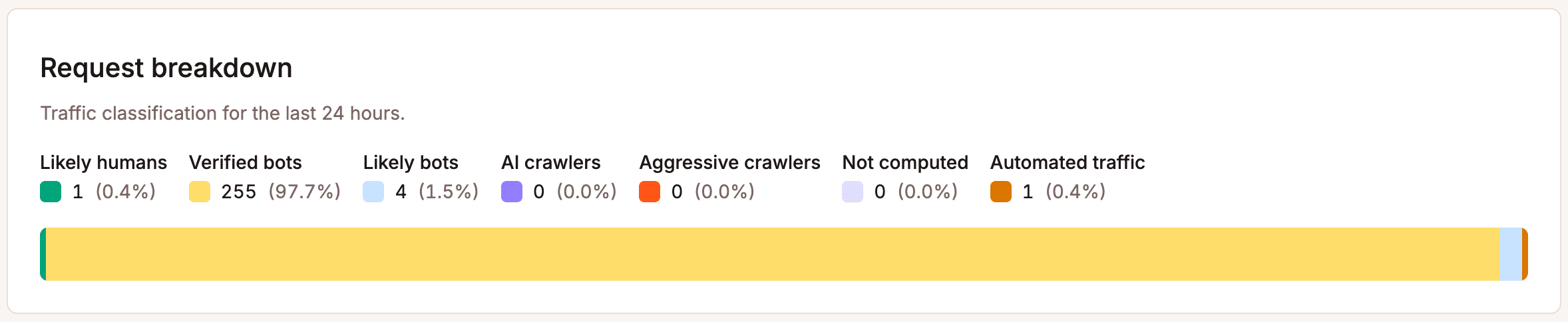
Als een aanzienlijk deel geautomatiseerd of niet-geverifieerd is, is dat voor jou het teken om in actie te komen. Sla deze stap niet over, want beschermingswijzigingen doorvoeren zonder te weten waartegen je je beschermt, leidt tot verkeerde configuraties.
Ten tweede: stem het beveiligingsniveau af op het type site. Een WooCommerce-winkel heeft andere prioriteiten dan een contentwebsite, die weer andere prioriteiten heeft dan een testomgeving. Het blokkeren van geautomatiseerd verkeer en het controleren van vermoedelijke bots is logisch voor een winkel met dynamische endpoints. Een contentwebsite zou er bijvoorbeeld voor kunnen kiezen om AI-ontdekkingsbots toe te laten, terwijl AI-trainingscrawlers worden geblokkeerd. Een testomgeving moet sowieso volledig worden afgesloten.
Ten derde: bescherm eerst de kostbare paden. Voordat je brede beveiligingsregels toepast, moet je nagaan of je duurste endpoints, zoals de winkelwagen, de kassa en AJAX-handlers, toegankelijk zijn voor crawlers die daar niets te zoeken hebben. Het blokkeren van bekende bot-user-agents van /cart en ?add-to-cart= via robots.txt is een begin; door dit op WAF-niveau af te dwingen (en niet alleen te signaleren) voorkom je daadwerkelijk de belasting.
Ten vierde: blijf monitoren en pas aan. De patronen van botverkeer veranderen sneller dan de meeste site-eigenaren beseffen. Het aandeel van GPTBot in het verkeer verdrievoudigde binnen één jaar. Beschermingsregels één keer instellen en ze daarna negeren is geen strategie. De grafiek met botbeschermingsresultaten in MyKinsta houdt bij wat er in de loop van de tijd wordt geblokkeerd, gecontroleerd en toegestaan.
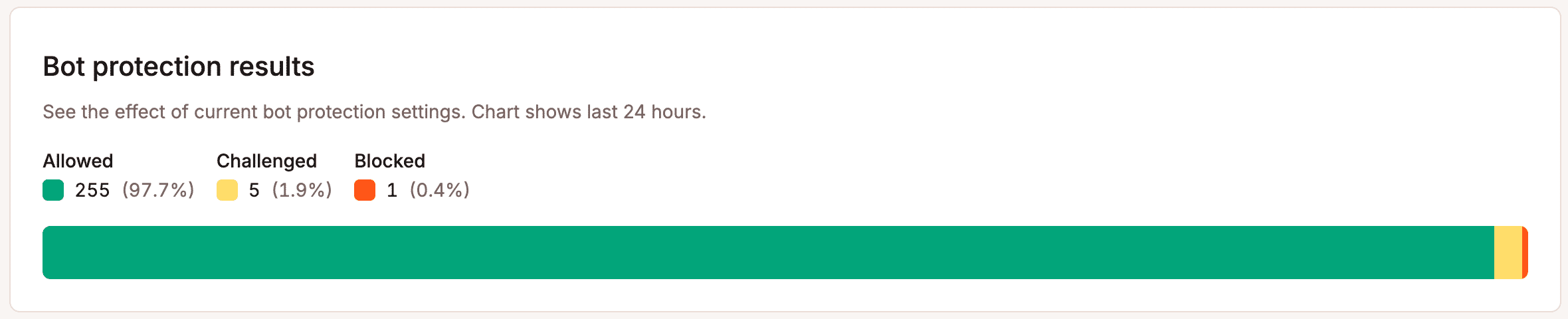
Deze gegevens moeten je helpen bij het afstemmen van je instellingen.
Als bots zorgen voor overschrijdingen van het aantal bezoeken bij een op bezoeken gebaseerd pakket, kan het de moeite waard zijn om tegelijkertijd de op bandbreedte gebaseerde hostingpakketten van Kinsta te bekijken. Overstappen naar een pakket op basis van bandbreedte lost het onderliggende botprobleem niet op, maar het geeft wel een beter beeld van de werkelijke infrastructuurkosten van je verkeersmix, die vaak aanzienlijk lager zijn dan het aantal bezoeken doet vermoeden.
Het grotere plaatje: dit probleem wordt alleen maar lastiger
Er verschijnt al ‘agentic’-verkeer in infrastructuurlogs. Google heeft een speciale user agent aangekondigd voor wanneer zijn AI-agenten met websites communiceren. Dit zijn geautomatiseerde systemen die op links klikken, formulieren invullen en verzoeken doen die steeds meer op menselijk sessiegedrag lijken.
De signalen die nu werken voor het classificeren van bots, zoals user-agent-strings, de frequentie van verzoeken en gedragsscores, worden steeds moeilijker duidelijk toe te passen naarmate de grens tussen geautomatiseerde en menselijke interactie steeds vager wordt.
De meeste site-eigenaren kunnen dat niet in hun eentje bijhouden. Botgedrag evolueert sneller dan handmatige regels kunnen bijblijven. Wat drie maanden geleden nog werkte, is nu misschien al niet meer voldoende. En de kosten van fouten – in servercapaciteit, in te hoge facturen, in echte klanten die tijdens het afrekenen een 504-foutmelding krijgen – zijn reëel en hebben rechtstreeks impact.
Daarom is het belangrijk dat je infrastructuur dit voor je regelt. Het platform van Kinsta blokkeert 15–20% van het kwaadaardige verkeer nog voordat het je site bereikt, draait op het zakelijke netwerk van Cloudflare en biedt je botbeschermingsinstellingen die zich aanpassen aan hoe je site zich daadwerkelijk gedraagt. Naarmate botverkeer zich blijft ontwikkelen, wordt het onderscheid steeds groter: een hostingplatform dat dit als infrastructuurprobleem behandelt versus een platform dat het als bijzaak beschouwt.
De sites die hier goed mee omgaan, zijn niet de sites die het meeste blokkeren. Het zijn de sites die draaien op een infrastructuur die speciaal is gebouwd om dit soort verkeer aan te kunnen.


