
Een website is geen losse verzameling van content en metadata, maar een samenhangend geheel dat is ontworpen om ontdekt te worden. Jarenlang liep vrijwel alle online zichtbaarheid via Google Search, grotendeels dankzij de webcrawlers.
Sinds eind jaren 90 zijn Googlebot en andere traditionele crawlers continu bezig met het scannen van websites, het ophalen van HTML-pagina’s en deze te indexeren om mensen te helpen vinden wat ze zoeken. In januari 2024 was Google goed voor 63% van al het Amerikaanse webverkeer, aangedreven door de top 170 domeinen.
Maar volgens een onderzoek van McKinsey wendt de helft van de klanten zich nu tot AI tools zoals ChatGPT, Claude, Gemini of Perplexity voor directe antwoorden, en zelfs Google voegt AI gegenereerde samenvattingen toe aan de zoekresultaten via features zoals AI overzichten.
Achter deze nieuwe AI-gestuurde ervaringen zit een groeiende klasse bots die bekend staat als AI crawlers. Als je een WordPress site beheert, is het belangrijker dan ooit om te begrijpen hoe deze crawlers je content openen en gebruiken.
Wat zijn AI crawlers?
AI crawlers zijn geautomatiseerde bots die openbaar toegankelijke webpagina’s scannen, vergelijkbaar met zoekmachinecrawlers, maar met een ander doel. In plaats van pagina’s te indexeren voor de traditionele ranking, verzamelen ze inhoud om grote taalmodellen te trainen of nieuwe informatie te leveren aan AI-gegenereerde antwoorden.
Over het algemeen vallen AI crawlers in twee groepen uiteen:
- Training crawlers, zoals GPTBot (OpenAI) en ClaudeBot (Anthropic), verzamelen gegevens om grote taalmodellen te leren hoe ze vragen nauwkeuriger kunnen beantwoorden.
- Live retrieval crawlers zoals ChatGPT-User openen websites in realtime wanneer iemand iets vraagt waarvoor de meest recente gegevens nodig zijn, zoals het controleren van een productbeschrijving of het lezen van documentatie.
Andere crawlers, bijvoorbeeld PerplexityBot of AmazonBot, bouwen hun eigen indexen of systemen om minder afhankelijk te zijn van bronnen van derden. En hoewel hun doelen verschillen, hebben ze allemaal één ding gemeen: ze halen en lezen inhoud van websites zoals die van jou.
Hoe AI crawlers werken
Wanneer een AI crawler je site bezoekt, doet hij meestal het volgende:
- Stuurt een eenvoudig GET verzoek naar de URL van de pagina (geen interactie, scrollen of DOM-gebeurtenissen).
- Haalt alleen de initiële HTML op die door de server wordt teruggestuurd. Er wordt niet gewacht tot JavaScript aan de clientzijde is geladen of uitgevoerd.
- Haalt alle
<a href="">,<img src="">,<script src="">, en andere resource links op en voegt vervolgens interne (en soms externe) URL’s toe aan de crawl wachtrij. In veel gevallen worden ook dode links gevonden die een 404 foutmelding geven. - Kan proberen om gelinkte bronnen zoals afbeeldingen, CSS bestanden of scripts op te halen, maar alleen als ruwe bronnen, niet om de pagina te renderen.
- Herhaalt dit proces recursief over ontdekte links om de site in kaart te brengen.
Hoe AI crawlers omgaan met WordPress websites
WordPress is een server-rendered platform dat PHP gebruikt om volledige HTML pagina’s te genereren voordat deze naar de browser worden gestuurd. Wanneer een crawler een WordPress site bezoekt, krijgt hij meestal alles (inhoud, koppen, metadata, navigatie) wat hij nodig heeft in de HTML respons.
Deze server-rendered structuur maakt de meeste WordPress sites van nature crawler-vriendelijk. Of het nu Googlebot is of een AI crawler, ze kunnen je site meestal scannen en je inhoud gemakkelijk begrijpen. Gemakkelijk te crawlen inhoud is zelfs een van de redenen waarom WordPress goed presteert in zowel traditionele zoekmachines als nieuwere AI-gestuurde platforms.
Moet je AI crawlers toegang geven tot je content?
AI crawlers kunnen de meeste WordPress sites standaard al lezen. De echte vraag is wat je wilt dat ze kunnen lezen – en hoe je die zichtbaarheid kunt regelen.
Voor content-gedreven bedrijven is dit momenteel een belangrijk onderwerp. Het onderwerp raakt vrijwel alle vormen van geschreven webcontent, van blogs tot documentatie en landingspagina’s. Je hebt waarschijnlijk adviezen gehoord als “schrijf voor de machines” sinds AI platforms steeds meer live gegevens ophalen en in sommige gevallen nu ook links naar bronnen bevatten. We willen allemaal verschijnen in de output van LLM, net zoals we willen verschijnen in de zoekresultaten van Google.
In de schermafbeelding hieronder vragen we ChatGPT bijvoorbeeld om ons enkele van de nieuwste features van Kinsta te vertellen. Het doorzoekt het web, scant changelogs en gelinkte pagina’s en geeft een samengevat antwoord met directe links terug naar de bron.
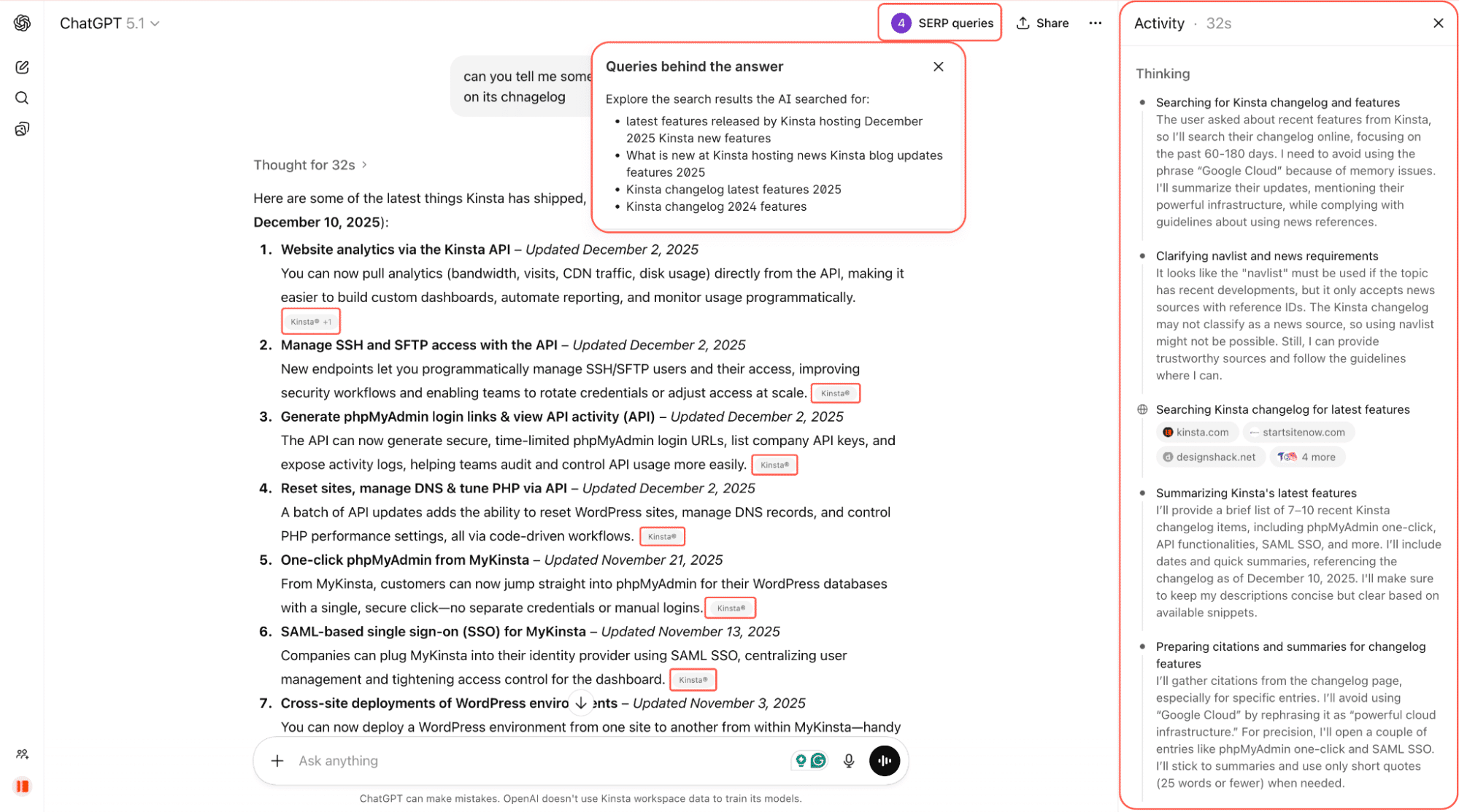
Het is nog vroeg, maar AI crawlers beïnvloeden al wat mensen zien als ze online vragen stellen. En dat bereik kan belangrijk zijn.
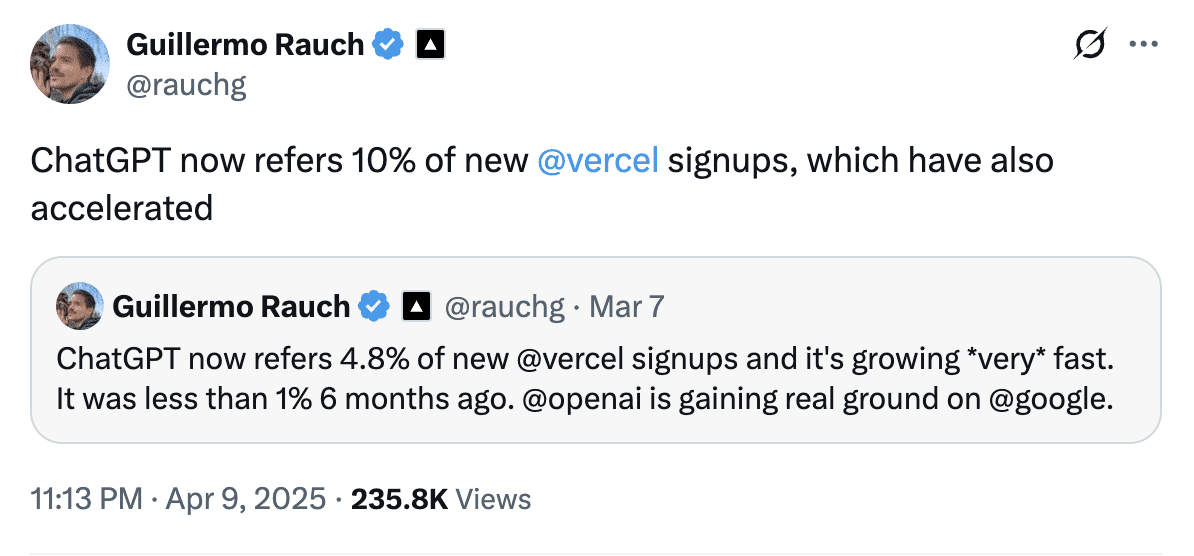
Guillermo Rauch, CEO van Vercel, deelde in april dat ChatGPT goed is voor bijna 10% van de nieuwe aanmeldingen bij Vercel, tegenover minder dan 1% zes maanden eerder. Dat laat zien hoe snel AI-gestuurde verwijzingen kunnen uitgroeien tot een belangrijk acquisitiekanaal.
En AI crawlers zijn wijdverspreid. Volgens Cloudflare hadden AI-bots toegang tot ongeveer 39% van de top 1 miljoen websites, maar slechts ongeveer 3% van die sites blokkeerde of betwistte dat verkeer daadwerkelijk.
Dus zelfs als je nog geen beslissing hebt genomen, is het bijna zeker dat AI crawlers je site al bezoeken.
Moet je AI crawlers toestaan of blokkeren?
Er is geen pasklaar antwoord. Er is geen universeel antwoord, maar hier is een raamwerk:
- Blokkeer crawlers op gevoelige of laagwaardige routes zoals
/login,/checkout,/admin, of dashboards. Deze helpen niet bij het ontdekken en verspillen alleen bandbreedte. - Sta crawlers toe op “ontdekkingscontent” zoals blogberichten, documentatie, productpagina’s en prijsinformatie. Deze pagina’s hebben de meeste kans om te worden aangehaald in AI reacties en om gekwalificeerd verkeer te genereren.
- Kies strategisch voor premium of gated content. Als je inhoud je product is (bijv. nieuws, onderzoek, cursussen), kan onbeperkte toegang tot AI je bedrijf ondermijnen.
Er komen nieuwe tools om te helpen. Cloudflare experimenteert bijvoorbeeld met een model genaamd Pay Per Crawl, waarmee site-eigenaren AI bedrijven kunnen laten betalen voor toegang. Het is nog steeds in private beta en de adoptie in de echte wereld is nog vroeg, maar het idee heeft veel steun gekregen van grote uitgevers die meer controle willen over hoe hun content wordt gebruikt.
Anderen in de zoek- en marketinggemeenschap zijn voorzichtiger, omdat standaard blokkeren onbedoeld de zichtbaarheid in de AI zoekresultaten zou kunnen verminderen voor sites die juist die zichtbaarheid willen. Voorlopig is het eerder een veelbelovend experiment dan een volwassen inkomstenstroom.
Totdat deze systemen volwassen zijn, is de meest praktische aanpak selectieve openheid, waarbij je ontdekkingcontent crawlable houdt, gevoelige gebieden blokkeert en je regels herziet naarmate het ecosysteem zich ontwikkelt.
Hoe controleer je de toegang van AI crawlers op WordPress
Als je het niet prettig vindt dat AI crawlers toegang krijgen tot je WordPress site en de inhoud scannen, dan is het goede nieuws dat je de controle terug kunt nemen.
Hier zijn drie manieren om AI crawler toegang op WordPress te beheren:
- Handmatig je
robots.txtbestand bewerken. - Een plugin gebruiken om dit voor je te doen.
- De botbeveiliging van Cloudflare gebruiken.
Laten we alle drie de opties doorlopen.
Optie 1: AI crawlers handmatig blokkeren met robots.txt
Je robots.txt bestand vertelt bots welke delen van je site ze mogen crawlen. De meeste bekende AI crawlers, zoals OpenAI’s GPTBot, Anthropic’s Claude-Web en Google-Extended, respecteren deze regels.
Je kunt specifieke bots volledig blokkeren, ze volledige toegang geven of de toegang tot bepaalde delen van je site beperken. Om bijvoorbeeld alles te blokkeren, kun je dit toevoegen aan je robots.txt bestand, hoewel dit voor de meeste sites niet wordt aanbevolen:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Google-Extended
Disallow: /Om volledige toegang te verlenen aan OpenAI’s GPTBot:
User-agent: GPTBot
Disallow:Om slechts een deel van je site te blokkeren voor OpenAI’s GPTBot. Bijvoorbeeld je inlogpagina, waar crawlers geen waarde toevoegen:
User-agent: GPTBot
Disallow: /login/Dit soort selectieve blokkering is de sleutel. Gevoelige routes zoals /login, /checkout, of /admin helpen niet bij de vindbaarheid en moeten bijna altijd worden geblokkeerd. Aan de andere kant zijn productpagina’s, feature-overzichten of je helpcentrum goede kandidaten om open te houden voor crawlers omdat ze kunnen zorgen voor citaties en verwijzingen.
Je kunt dit robots.txt bestand handmatig toevoegen door:
- Een SEO plugin zoals Yoast te gebruiken (Tools > File editor).
- Een bestandsbeheer plugin zoals WP File Manager te gebruiken.
- Of door je
robots.txtbestand rechtstreeks op de server te bewerken via FTP.
Optie 2: Een WordPress plugin gebruiken
Als je het niet prettig vindt om het bestand robots.txt rechtstreeks te bewerken of als je gewoon een snellere, veiligere manier wilt om de toegang voor AI crawlers te beheren, dan kunnen plugins het werk met een paar klikken voor je doen.
Raptive Ads
De Raptive Ads WordPress plugin bevat ingebouwde ondersteuning voor het blokkeren van AI crawlers:
- Je kunt direct vanuit de instellingen van de plugin kiezen welke bots je wilt blokkeren.
- De meeste AI bots (zoals GPTBot en Claude) worden standaard geblokkeerd.
- Google-Extended wordt niet standaard geblokkeerd, maar je kunt het vakje aanvinken als je de AI-training van Google wilt uitschakelen.
Een belangrijk voordeel van het gebruik van deze plugin is dat het blokkeren van Google-Extended geen invloed heeft op je Google rankings of zichtbaarheid in de reguliere zoekresultaten.
AI crawlers blokkeren
De Block AI Crawlers plugin is speciaal gemaakt om WordPress site-eigenaren meer controle te geven over hoe AI crawlers omgaan met hun inhoud. Dit is hoe:
- Blokkeert 75+ bekende AI bots door automatisch de juiste
Disallowregels toe te voegen aan derobots.txtvan je site. - Configuratie is niet nodig. Installeer de plugin, ga naar Settings > Reading en vink het vakje aan met het label Block AI crawlers.
- Lichtgewicht en open-source, met regelmatige updates van GitHub.
- Ontworpen om out of the box te werken op de meeste WordPress installaties.
De Block AI Crawlers plugin is een van de eenvoudigste manieren om ongewenste AI bots van je site te houden, vooral als je geen geavanceerde SEO plugins gebruikt.
Optie 3: Cloudflare’s one-click AI Blocker gebruiken
Als je WordPress site Cloudflare gebruikt (en veel doen dat), dan kun je tientallen bekende en onbekende AI bots blokkeren met één schakelaar.
Medio 2024 lanceerde Cloudflare een speciale AI Scrapers en Crawlers feature, die zelfs beschikbaar is in het gratis pakket. Deze feature vertrouwt niet alleen op robots.txt, maar blokkeert bots op netwerkniveau, zelfs bots die liegen over wie ze zijn.
Je kunt deze feature inschakelen door het volgende te doen:
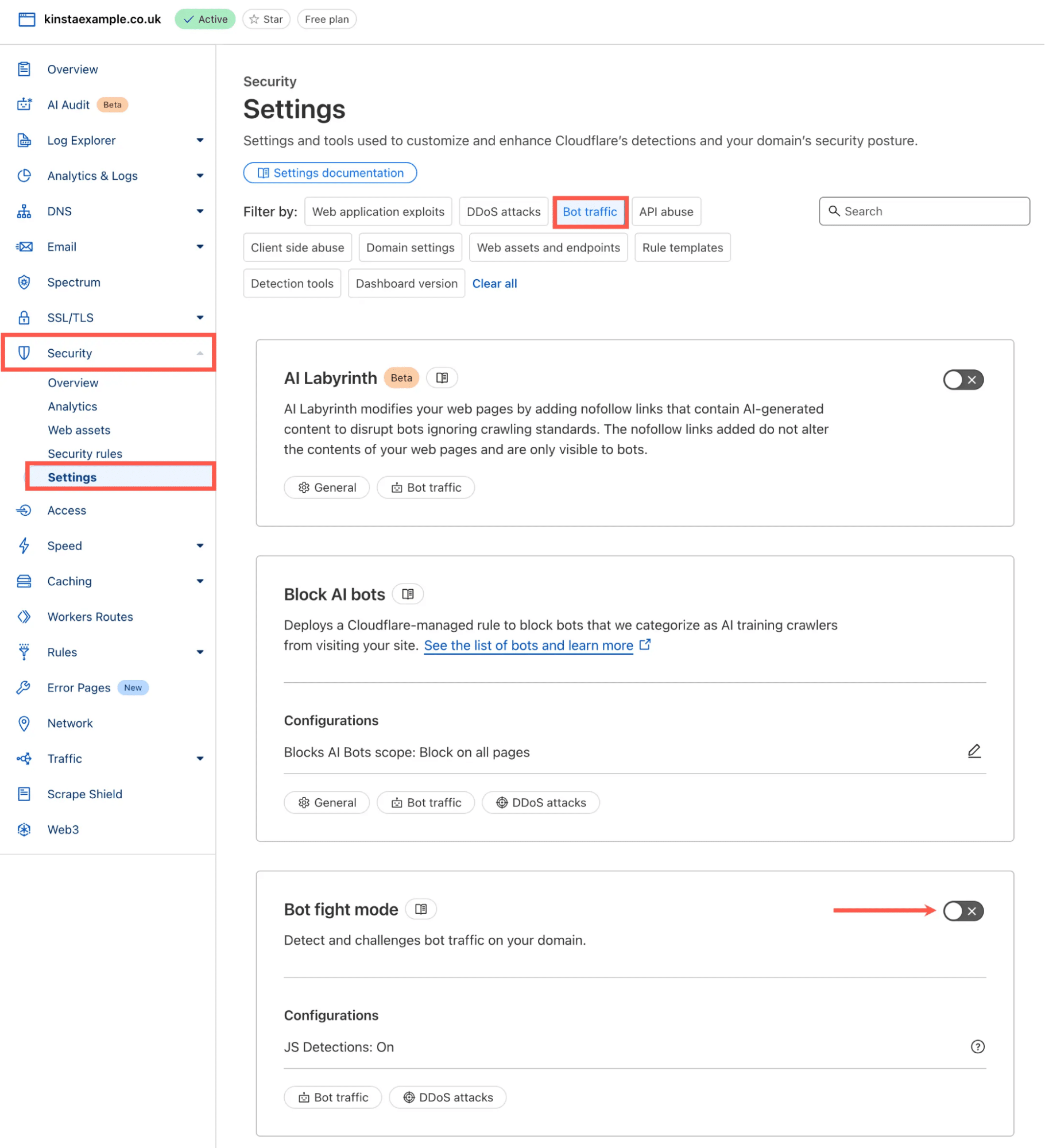
- Log in op je Cloudflare Dashboard
- Ga naar Security > Settings
- Kies onder de sectie Filter by voor Bot traffic.
- Zoek de Bot fight mode en schakel deze in.
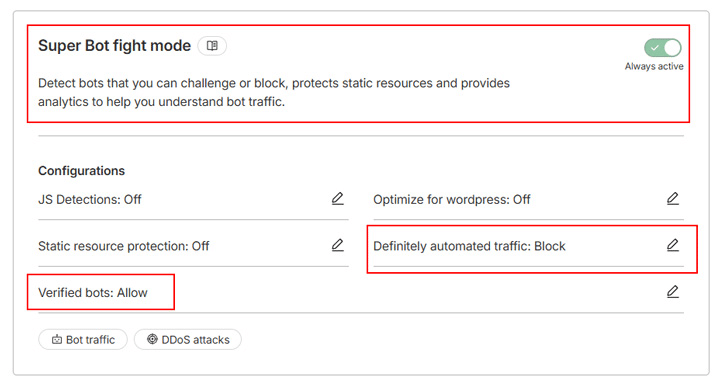
Als je een betaald Cloudflare abonnement gebruikt, heb je toegang tot de Super Bot fight mode, een verbeterde versie van de Bot fight mode met meer flexibiliteit. Het bouwt voort op dezelfde technologie, maar laat je kiezen hoe om te gaan met verschillende soorten verkeer, waardoor JavaScript-detecties mogelijk zijn om headless browsers, onzichtbare scrapers en ander kwaadaardig verkeer te vangen.
In plaats van bijvoorbeeld alle crawlers te blokkeren, kun je de tool zo instellen dat alleen “beslist geautomatiseerd verkeer” wordt geblokkeerd en “geverifieerde bots” zoals zoekmachinecrawlers worden toegelaten:
Dat was het. Cloudflare blokkeert automatisch verzoeken van AI-bots.
Als je dieper wilt ingaan op hoe deze tools samenwerken, inclusief Bot Fight Mode, Super Bot Fight Mode en gerichte uitdagingsregels, kun je onze volledige gids lezen over het beschermen van je WordPress site tegen ongewenst botverkeer met Cloudflare.
Wat deze verschuiving betekent voor je WordPress site
AI crawlers maken nu deel uit van de manier waarop mensen online informatie ontdekken. De technologie is nieuw, de regels zijn nog in ontwikkeling en site-eigenaren beslissen hoeveel van hun inhoud ze beschikbaar willen stellen.
Het goede nieuws is dat WordPress sites al een sterke positie hebben. Omdat WordPress volledig gerenderde HTML uitvoert, kunnen de meeste AI crawlers je inhoud duidelijk interpreteren zonder speciale handelingen. De echte strategische beslissing is niet of AI crawlers toegang kunnen krijgen tot je site – het is hoeveel toegang je doelen helpt.
En omdat de mix van verkeerstypen evolueert, is het handig om hostingopties te hebben die het gebruik van bronnen makkelijker te begrijpen en te beheren maken. De nieuwe op bandbreedte gebaseerde pakketten van Kinsta bieden een meer voorspelbare manier om rekening te houden met de totale gegevensoverdracht, ongeacht de bron van de aanvragen. In combinatie met de botbescherming van Cloudflare en je eigen crawlerregels heb je volledige controle over hoe je site wordt benaderd.


