
Voor de meeste marketeers zijn constante updates nodig om hun site up-to-date te houden en hun SEO rankings te verbeteren.
Sommige sites hebben echter honderden of zelfs duizenden pagina’s, waardoor het een uitdaging wordt voor teams die de updates handmatig naar de zoekmachines pushen. Als de content zo vaak wordt bijgewerkt, hoe kunnen teams er dan voor zorgen dat deze verbeteringen hun SEO rankings beïnvloeden?
Daar komen crawler bots om de hoek kijken. Een webcrawlerbot zal je sitemap scrapen op nieuwe updates en indexeert de content in zoekmachines.
In dit artikel schetsen we een uitgebreide crawlerlijst met alle webcrawlerbots die je moet kennen. Voordat we verder gaan, laten we eerst een definitie geven van webcrawlerbots en laten we zien hoe ze functioneren.
Bekijk onze videogids over de meest voorkomende webcrawlers
Wat is een webcrawler?
Een webcrawler is een computerprogramma dat automatisch webpagina’s scant en systematisch leest om ze te indexeren voor zoekmachines. Webcrawlers worden ook wel spiders of bots genoemd.
Om zoekmachines actuele, relevante webpagina’s te laten presenteren aan gebruikers die een zoekopdracht starten, moet een crawl van een webcrawlerbot plaatsvinden. Dit proces kan soms automatisch gebeuren (afhankelijk van de instellingen van de crawler en jouw site), of het kan direct worden geïnitieerd.
Veel factoren beïnvloeden de SEO ranking van je pagina’s, waaronder relevantie, backlinks, webhosting en meer. Maar geen van deze factoren is van belang als je pagina’s niet worden gecrawld en geïndexeerd door zoekmachines. Daarom is het zo belangrijk om ervoor te zorgen dat je site de juiste crawls toelaat en alle hindernissen uit de weg ruimt.
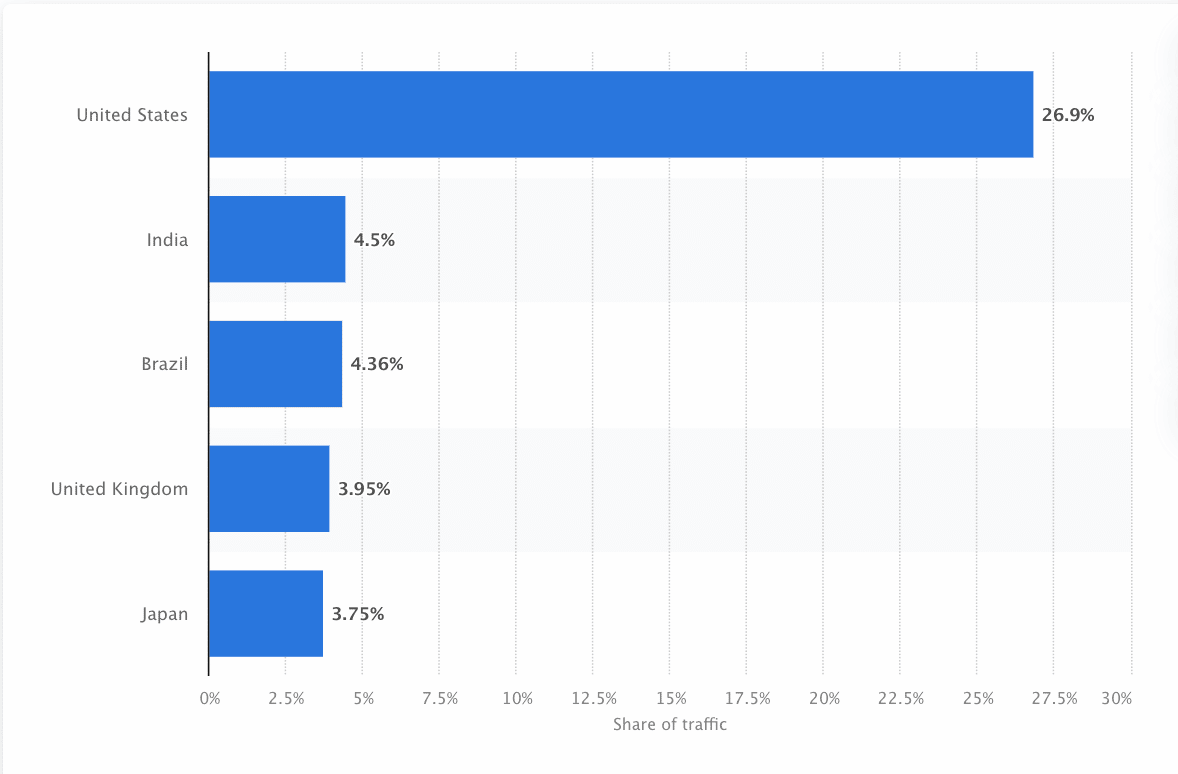
Bots moeten voortdurend het web scannen en scrapen om ervoor te zorgen dat de meest accurate informatie wordt gepresenteerd. Google is de meest bezochte website in de Verenigde Staten, en ongeveer 26,9% van de zoekopdrachten komt van Amerikaanse gebruikers:
Er is echter niet één webcrawler die voor elke zoekmachine crawlt. Elke zoekmachine heeft unieke sterke punten, dus stellen developers en marketeers soms een “crawlerlijst” samen Deze crawlerlijst helpt hen verschillende crawlers in hun sitelog te identificeren om te accepteren of te blokkeren.
Marketeers moeten dus idealiter een crawlerlijst samenstellen vol met de verschillende webcrawlers en begrijpen hoe ze hun site evalueren (in tegenstelling tot contentscrapers die de content stelen) om ervoor te zorgen dat ze hun landingspagina’s correct optimaliseren voor zoekmachines.
Hoe werkt een webcrawler?
Een webcrawler scant automatisch je webpagina nadat die is gepubliceerd en indexeert je gegevens.
Webcrawlers zoeken naar specifieke trefwoorden die bij de webpagina horen en indexeren die informatie voor relevante zoekmachines als Google, Bing en meer.
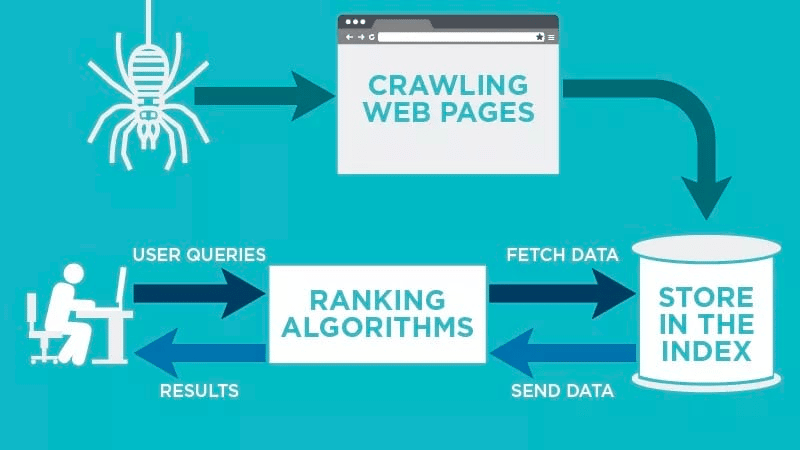
Algoritmen van zoekmachines halen die gegevens op als een gebruiker een aanvraag indient voor het relevante trefwoord dat ermee verbonden is.
Crawls beginnen met bekende URL’s. Dat zijn gevestigde webpagina’s met verschillende signalen die webcrawlers naar die pagina’s leiden. Deze signalen kunnen zijn:
- Backlinks: Het aantal keren dat er naar een site wordt gelinkt
- Bezoekers: Hoeveel verkeer er naar die pagina gaat
- Domeinautoriteit: De algemene kwaliteit van het domein
Vervolgens slaan ze de gegevens op in de index van de zoekmachine. Als de gebruiker een zoekopdracht uitvoert, haalt het algoritme de gegevens op uit de index, en verschijnen ze op de resultatenpagina van de zoekmachine. Dit proces kan binnen enkele milliseconden plaatsvinden, en daarom verschijnen de resultaten vaak snel.
Als webmaster kun je zelf bepalen welke bots je site crawlen. Daarom is het belangrijk om een crawlerlijst te hebben. Dit is het robots.txt protocol dat te vinden is binnen de servers van elke site en dat crawlers naar nieuwe content leidt die geïndexeerd moet worden.
Afhankelijk van wat je in je robots.txt protocol op elke webpagina invoert, kun je een crawler vertellen om die pagina in de toekomst te scannen of juist niet te indexeren.
Door te begrijpen waar een webcrawler op let bij het scannen, kun je begrijpen hoe je je content beter kunt positioneren voor zoekmachines.
Je crawlerlijst samenstellen: wat zijn de verschillende soorten webcrawlers?
Bij het nadenken over het samenstellen van je crawlerlijst, zijn er drie hoofdtypen crawlers waar je op moet letten. Dit zijn:
- In-house crawlers: Dit zijn crawlers ontworpen door het ontwikkelingsteam van een bedrijf om een site te scannen. Gewoonlijk worden ze gebruikt voor site-audits en optimalisatie.
- Commerciële crawlers: Dit zijn op maat gemaakte crawlers zoals Screaming Frog die bedrijven kunnen gebruiken om hun content te crawlen en efficiënt te evalueren.
- Open-source crawlers: Dit zijn gratis te gebruiken crawlers die worden gebouwd door allerlei developers en hackers over de hele wereld.
Het is belangrijk om de verschillende soorten crawlers te begrijpen, zodat je weet welk type je moet gebruiken voor je eigen bedrijfsdoelen.
De 14 meest voorkomende webcrawlers om toe te voegen aan je crawlerlijst
Er is niet één crawler die al het werk doet voor elke zoekmachine.
In plaats daarvan zijn er verschillende webcrawlers die je webpagina’s evalueren en de content scannen voor alle zoekmachines die beschikbaar zijn voor gebruikers over de hele wereld.
Laten we eens kijken naar enkele van de meest voorkomende webcrawlers van dit moment.
1. Googlebot
Googlebot is Google’s algemene webcrawler die verantwoordelijk is voor het crawlen van sites die in Google’s zoekmachine zullen verschijnen.

Hoewel er technisch gezien twee versies van Googlebot zijn – Googlebot Desktop en Googlebot Smartphone (Mobiel) – beschouwen de meeste experts Googlebot als één enkele crawler.
Dit komt omdat beide dezelfde unieke producttoken (bekend als een user agent token) volgen die in de robots.txt van elke site is geschreven. De user agent van Googlebot is simpelweg “Googlebot”
Googlebot gaat aan het werk en opent gewoonlijk elke paar seconden je site (tenzij je hem hebt geblokkeerd in de robots.txt van je site). Een backup van de gescande pagina’s wordt opgeslagen in een gezamenlijke database die Google Cache heet. Hierdoor kun je oude versies van je site bekijken.
Daarnaast is Google Search Console een ander tool dat webmasters gebruiken om te begrijpen hoe Googlebot hun site crawlt en om hun pagina’s te optimaliseren voor zoekopdrachten.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot is in 2010 door Microsoft gemaakt om URL’s te scannen en te indexeren om ervoor te zorgen dat Bing relevante, actuele zoekmachineresultaten biedt voor de gebruikers van het platform.
Net als Googlebot kunnen developers of marketeers in hun robots.txt op hun site aangeven of ze de agent-identificatie “bingbot” toestaan of weigeren om hun site te scannen.
Bovendien hebben ze de mogelijkheid om onderscheid te maken tussen mobile-first indexing crawlers en desktopcrawlers, omdat Bingbot onlangs is overgestapt op een nieuw agenttype. Dit, samen met Bing Webmaster Tools, biedt webmasters meer flexibiliteit om te laten zien hoe hun site wordt ontdekt en getoond in de zoekresultaten.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Bot is een crawler speciaal voor de Russische zoekmachine Yandex. Dit is een van de grootste en populairste zoekmachines in Rusland.

Webmasters kunnen hun site pagina’s toegankelijk maken voor Yandex Bot via hun robots.txt bestand.
Daarnaast kunnen ze ook een Yandex.Metrica tag toevoegen aan specifieke pagina’s, pagina’s herindexeren in de Yandex Webmaster of een IndexNow protocol uitbrengen, een uniek rapport dat wijst op nieuwe, gewijzigde of gedeactiveerde pagina’s.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple Bot
Apple heeft de Apple Bot opdracht gegeven om webpagina’s te crawlen en te indexeren voor Apple’s Siri en Spotlight Suggesties.
Apple Bot houdt rekening met meerdere factoren bij de beslissing welk materiaal in Siri en Spotlight Suggesties wordt opgenomen. Deze factoren zijn gebruikersbetrokkenheid, de relevantie van zoektermen, aantal/kwaliteit van links, locatiegebonden signalen en zelfs het ontwerp van de webpagina.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
De DuckDuckBot is de webcrawler voor DuckDuckGo, die “Naadloze privacybescherming op je webbrowser” biedt.
Webmasters kunnen de DuckDuckBot API gebruiken om te zien of de DuckDuck Bot hun site heeft gecrawld. Terwijl hij crawlt, werkt hij de DuckDuckBot API database bij met recente IP adressen en user agents.
Dit helpt webmasters eventuele bedriegers of kwaadaardige bots te identificeren die proberen geassocieerd te worden met de DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu is de belangrijkste Chinese zoekmachine, en de Baidu Spider is de enige crawler van de site.

Google is verboden in China, dus het is belangrijk om de Baidu Spider in te schakelen om je site te crawlen als je de Chinese markt wilt bereiken.
Om de Baidu Spider die je site crawlt te identificeren, zoek je naar de volgende user agents: baiduspider, baiduspider-image, baiduspider-video, en meer.
Als je geen zaken doet in China, kan het zinvol zijn om de Baidu Spider te blokkeren in je robots.txt script. Dit voorkomt dat de Baidu Spider je site crawlt, waardoor de kans verdwijnt dat je pagina’s verschijnen op Baidu’s zoekmachine resultaten pagina’s (SERP’s).
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou is een Chinese zoekmachine die naar verluidt de eerste zoekmachine is met 10 miljard geïndexeerde Chinese pagina’s.

Als je zaken doet op de Chinese markt, is dit een andere populaire zoekmachinecrawler die je moet kennen. De Sogou Spider volgt de parameters uitsluitingstekst en crawlvertraging van de robot.
Net als bij de Baidu Spider moet je, als je geen zaken wilt doen op de Chinese markt, deze spider uitschakelen om trage laadtijden van sites te voorkomen.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook External Hit
Facebook External Hit, ook wel bekend als de Facebook Crawler, crawlt de HTML van een app of website die op Facebook wordt gedeeld.

Hierdoor kan het social platform een deelbare preview genereren van elke link die op het platform wordt geplaatst. De titel, beschrijving en thumbnail afbeelding verschijnen dankzij de crawler.
Als de crawl niet binnen enkele seconden wordt uitgevoerd, toont Facebook de content niet in de aangepaste snippet die voor het delen wordt gegenereerd.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead is een in 2000 opgericht softwarebedrijf met hoofdkantoor in Parijs, Frankrijk. Het bedrijf levert zoekplatforms voor consumenten en zakelijke klanten.
Exabot is de crawler voor hun kernzoekmachine gebouwd op hun CloudView product.
Net als de meeste zoekmachines houdt Exalead bij de rangschikking rekening met zowel backlinking als de content van webpagina’s. Exabot is de user agent van de robot van Exalead. De robot maakt een “hoofdindex” die de resultaten samenstelt die de gebruikers van de zoekmachine te zien krijgen.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype is een aangepaste zoekmachine voor je website. Het combineert “de beste zoektechnologie, algoritmen, content ingestion framework, clients en analytics tools“.
Als je een complexe site hebt met veel pagina’s, biedt Swiftype een handige interface om al je pagina’s voor je te catalogiseren en te indexeren.
Swiftbot is de webcrawler van Swiftype. Maar in tegenstelling tot andere bots, crawlt Swiftbot alleen sites waar hun klanten om vragen.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot is de Yahoo zoekrobot die pagina’s voor Yahoo crawlt en indexeert.
Deze crawl is essentieel voor zowel Yahoo.com als zijn partnersites, waaronder Yahoo News, Yahoo Finance en Yahoo Sports. Zonder deze robot zouden relevante sitelijsten niet verschijnen.
De geïndexeerde content draagt bij aan een meer gepersonaliseerde webervaring voor gebruikers met relevantere resultaten.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot is een op Nutch gebaseerde webcrawler ontwikkeld door Common Crawl, een non-profit organisatie gericht op het (gratis) aanbieden van een kopie van het internet aan bedrijven, particulieren en iedereen die geïnteresseerd is in online onderzoek. De bot gebruikt MapReduce, een programmeerframework waarmee hij grote hoeveelheden gegevens kan condenseren tot waardevolle geaggregeerde resultaten.
Dankzij CCBot kunnen mensen de gegevens van Common Crawl gebruiken om vertaalprogramma’s te verbeteren en trends te voorspellen. GPT-3 is overigens grotendeels getraind op de gegevens uit deze dataset.
| User Agent |
CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
Dit is een nieuwe. GoogleOther werd in april 2023 door Google gelanceerd en het werkt net als Googlebot.
Ze delen allebei dezelfde infrastructuur en hebben dezelfde features en beperkingen. Het enige verschil is dat GoogleOther intern zal worden gebruikt door Google teams om publiek toegankelijke content van sites te crawlen.
De reden achter de creatie van deze nieuwe crawler is om de crawlcapaciteit van Googlebot wat te ontlasten en zijn webcrawlprocessen te optimaliseren.
GoogleOther zal bijvoorbeeld worden gebruikt voor crawls voor onderzoek en ontwikkeling (R&D), zodat Googlebot zich kan richten op taken die direct verband houden met zoekindexering.
| User Agent | GoogleOther |
14. Google-InspectionTool
Mensen die de crawling- en botactiviteit in hun logbestanden bekijken, gaan op iets nieuws stuiten.
Een maand na de lancering van GoogleOther hebben we een nieuwe crawler onder ons die ook Googlebot nabootst: Google-InspectionTool.
Deze crawler wordt gebruikt door Search testing tools in Search Console, zoals URL inspectie, en andere Google eigenschappen, zoals de Rich Result Test.
| User Agent | Google-InspectionTool Googlebot |
| Full User Agent String | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0) Mozilla/5.0 (compatible; Google-InspectionTool/1.0) |
De 8 commerciële crawlers die SEO professionals moeten kennen
Nu je 13 van de meest populaire bots op je crawlerlijst hebt staan, laten we eens kijken naar enkele veel voorkomende commerciële crawlers en SEO tools voor professionals.
1. Ahrefs Bot
De Ahrefs Bot is een webcrawler die de database met 12 biljoen links samenstelt en indexeert die de populaire SEO software Ahrefs aanbiedt.
De Ahrefs Bot bezoekt dagelijks 6 miljard websites en wordt beschouwd als “de tweede meest actieve crawler” achter Googlebot.
Net als andere bots volgt de Ahrefs Bot de robots.txt functies, evenals het toestaan/afwijzen van regels in de code van elke site.
2. Semrush Bot
De Semrush Bot stelt Semrush, een toonaangevende SEO software, in staat om sitegegevens te verzamelen en te indexeren voor gebruik door haar klanten op haar platform.
De gegevens worden gebruikt in Semrush’s openbare backlink zoekmachine, de site audittool, de backlink audittool, link buildingtool, en schrijfassistent.
Het crawlt je site door een lijst van webpagina URL’s samen te stellen, deze te bezoeken en bepaalde hyperlinks op te slaan voor toekomstige bezoeken.
3. Moz’s Rogerbot
Rogerbot is de crawler voor de toonaangevende SEO site, Moz. Deze crawler verzamelt specifiek content voor Moz Pro Campaign site audits.

Rogerbot volgt alle regels uit de robots.txt bestanden, dus je kunt zelf beslissen of je Rogerbot wilt blokkeren/toestaan om je site te scannen.
Webmasters kunnen niet zoeken naar een statisch IP adres om te zien welke pagina’s Rogerbot heeft gecrawld, vanwege zijn veelzijdige aanpak.
4. Screaming Frog
Screaming Frog is een crawler die SEO professionals gebruiken om hun eigen site door te lichten en verbeterpunten op te sporen die van invloed zijn op hun zoekmachinerankings.

Zodra een crawl is gestart, kun je real-time gegevens bekijken en dode links of verbeteringen identificeren die nodig zijn voor je paginatitels, metadata, robots, dubbele content en meer.
Om de crawlparameters te configureren moet je een Screaming Frog licentie kopen.
5. Lumar (voorheen Deep Crawl)
Lumar is een “gecentraliseerde hub voor het onderhouden van de technische gezondheid van je site” Met dit platform kun je een crawl van je site starten om je te helpen je sitearchitectuur te plannen.
Lumar prijst zichzelf aan als de “snelste website crawler op de markt” en stelt dat het tot 450 URL’s per seconde kan crawlen.
6. Majestic
Majestic richt zich vooral op het volgen en identificeren van backlinks op URL’s.

Het bedrijf stelt “een van de meest uitgebreide bronnen van backlinkgegevens op het internet” te hebben, en wijst daarbij op zijn historische index die in 2021 is uitgebreid van 5 naar 15 jaar aan links.
De crawler van de site maakt al deze gegevens beschikbaar voor de klanten van het bedrijf.
7. cognitiveSEO
cognitiveSEO is een andere belangrijke SEO software die veel professionals gebruiken.
Met de cognitiveSEO crawler kunnen gebruikers uitgebreide site-audits uitvoeren die hun site-architectuur en overkoepelende SEO strategie informeren.
De bot zal alle pagina’s crawlen en “een volledig aangepaste set gegevens” leveren die uniek is voor de eindgebruiker. Deze gegevensset zal ook aanbevelingen bevatten voor de gebruiker over hoe hij zijn site kan verbeteren voor andere crawlers – zowel om rankings te beïnvloeden als om crawlers te blokkeren die onnodig zijn.
8. Oncrawl
Oncrawl is een “toonaangevende SEO crawler en log analyzer” voor klanten op bedrijfsniveau.
Gebruikers kunnen “crawlprofielen” instellen om specifieke parameters voor de crawl te maken. Je kunt deze instellingen opslaan (inclusief de start URL, crawllimieten, maximale crawlsnelheid en meer) om de crawl gemakkelijk opnieuw uit te voeren met dezelfde vastgestelde parameters.
Moet ik mijn site beschermen tegen kwaadaardige webcrawlers?
Niet alle crawlers hebben goede bedoelingen. Sommige kunnen je paginasnelheid negatief beïnvloeden, terwijl andere kunnen proberen je site te hacken of simpelweg kwade bedoelingen hebben.
Daarom is het belangrijk te weten hoe je crawlers kunt blokkeren om je site binnen te komen.
Door een crawlerlijst op te stellen, weet je welke crawlers de goede zijn om voor uit te kijken. Vervolgens kun je de onbetrouwbare crawlers doorzoeken en toevoegen aan je blokkadelijst.
Zo blokkeer je schadelijke webcrawlers te
Met je crawlerlijst in de hand kun je bepalen welke bots je wilt goedkeuren en welke je moet blokkeren.
De eerste stap is het doorlopen van je crawlerlijst en het definiëren van de user agent en full agent string die bij elke crawler horen en het specifieke IP adres. Dit zijn belangrijke identificatiefactoren die bij elke bot horen.
Met de user agent en het IP adres kun je ze matchen in je site records via een DNS lookup of IP match. Als ze niet precies overeenkomen, heb je misschien een kwaadaardige bot die zich probeert voor te doen als de echte.
Dan kun je de bedrieger blokkeren door de rechten aan te passen met je robots.txt sitetag.
Samenvatting
Webcrawlers zijn nuttig voor zoekmachines en belangrijk voor marketeers om te begrijpen.
Ervoor zorgen dat je site correct wordt gecrawld door de juiste crawlers is belangrijk voor het succes van je bedrijf. Door een crawlerlijst bij te houden, kun je weten op welke crawlers je moet letten als ze in het logboek van je site verschijnen.
Als je de aanbevelingen van commerciële crawlers opvolgt en de content en snelheid van je site verbetert, maak je het voor crawlers gemakkelijker om je site te bezoeken en de juiste informatie te indexeren voor zoekmachines en de consumenten die die informatie zoeken.


