
Met zijn groeiende marktaandeel is – en blijft – WordPress het populairste CMS om websites te maken, te beheren en te ontwikkelen.
Toch vertegenwoordigt WordPress slechts een klein deel in de wereld van webdevelopment. Hoe zit het dan met alle developers die WordPress niet gebruiken? Zij maken, draaien en beheren ook webapplicaties voor hun bedrijf, klanten, opdrachtgevers of zichzelf.
Bij Kinsta hebben we inmiddels samengewerkt met duizenden developers en honderden webbureaus waarvan de klanten projecten hebben die op WordPress zijn gebouwd. Velen hebben ook projecten die niet worden aangedreven dit het beroemde CMS.
Tot vandaag richtte Kinsta zich op het bouwen van managed WordPress hostingoplossingen – wat betekende dat klanten (en hun klanten) niet in staat waren om de voordelen van ons platform voor niet-WordPress projecten te benutten en alle projecten onder “één dak” te hosten. Dit maakte hun werk moeilijker en minder efficiënt.
Dus gingen we op zoek naar manieren waarop we hun leven gemakkelijker konden maken.
Hoe meer feedback we kregen en hoe meer we met onze klanten en betatesters spraken over hun projecten, hoe meer we ons realiseerden dat onze klanten worstelden met één onderliggend pijnpunt.
Maar er is een plottwist: het waren niet alleen onze klanten.
We realiseerden ons dat dit pijnpunt wordt ervaren door bijna elke developer, DevOps team en webbureau dat webprojecten beheert. Iedereen worstelt ermee en wil graag een betere oplossing vinden.
Developers moeten geen tijd verspillen aan zorgen over hosting; ze moeten zich richten op development
Maar wat is het probleem precies?
Kort zegegd: gebrek aan eenvoud in een cloudhostingplatform.
Developers willen hun applicaties snel klaar hebben en afleveren. Developers hebben een platform nodig waarmee ze alles op één plek hebben, onder één dak.
Een platform dat eenvoudig, overzichtelijk en gemakkelijk te gebruiken is – op een manier die het ontwikkelingswerk niet beperkt tot één technologie, framework of bibliotheek.
Een platform dat gemakkelijk te leren en te gebruiken is vanaf de eerste dag, zonder de noodzaak van speciale cursussen of platform-specifieke certificeringen.
Een platform met een eenvoudig en transparant prijsmodel. (Heb je ooit geprobeerd de prijzen van AWS te begrijpen? Uitdagend!)
We wisten dat de gecontaineriseerde architectuur van Kinsta ons in staat zou stellen aan deze behoeften tegemoet te komen en het platform en de tools te leveren waarmee developers hun beste werk kunnen doen.
Bovendien wisten we dat we het volgende hebben:
- 8+ jaar ervaring in de hostingindustrie
- Ongeëvenaarde ondersteuning
- Getalenteerde developers en engineeringteams die elk technisch probleem kunnen oplossen
- DevOps teams die ongeëvenaard zijn als het gaat om het orkestreren, beheren en schalen van ons hostingplatform
Daarom bouwden we onze nieuwe, verbeterde hostingoplossingen bovenop hetzelfde platform dat onze WordPress diensten zo krachtig maakt. Nu, na meer dan een jaar hard werken waarbij 320+ Kinstanians, 750+ bètatesters en talloze iteraties betrokken waren, hebben we het beschikbaar gesteld voor het publiek.
Introductie van applicatiehosting- en databasehostingoplossingen
De visie van Kinsta is om de status quo te veranderen. We doen dit door onze sterke betrokkenheid bij het leveren van de beste ervaring voor developers:
We ontwikkelen ons voortdurend om toonaangevende tools en diensten te bieden voor de moderne developer. We zetten ons in voor de beste ervaring voor developers en bedrijven, door producten te bouwen die zijn geoptimaliseerd voor prestaties en gebruiksgemak.
Door nieuwe diensten aan ons aanbod toe te voegen, hebben developers en DevOps teams van alle soorten en maten nu een overvloed aan hostingoplossingen om uit te kiezen voor hun applicaties, databases, diensten en WordPress sites, met meer flexibiliteit dan ooit.
Specifiek biedt Kinsta nu:
Laten we ze stuk voor stuk beter bekijken.
Managed WordPress hosting (in het kort)
Aangedreven door Google Cloud Platform en zijn Premium Tier Network hebben we een managed WordPress hostingdienst gebouwd die 25.000+ bedrijven en 100.000 websites voorziet van alles wat ze nodig hebben om te blijven draaien en groeien.
Dankzij het gebruik van de meest geavanceerde CPU’s en de wereldwijde beschikbaarheid van Google’s compute-optimalised C2 VM’s, 27 beschikbare datacenters en het razendsnelle Kinsta CDN met 300 PoP’s om statische en dynamische content te serveren aan een wereldwijd verspreid publiek, merken klanten die migreren van een elke andere host naar Kinsta vrijwel direct een gemiddelde van 20% snellere laadtijden.
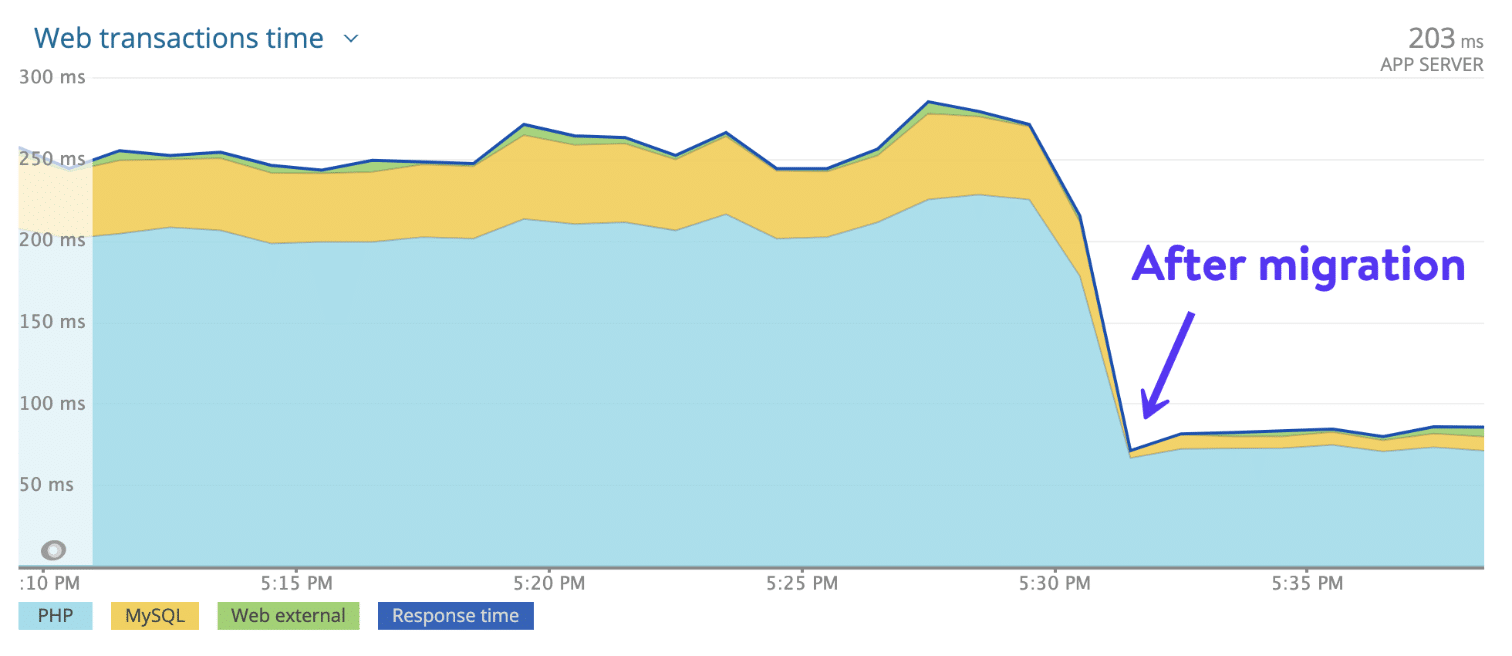
Maar daar houden de voordelen niet op.
Dankzij automatische backups, MyKinsta (ons aangepaste en gebruiksvriendelijke dashboard voor sitebeheer), ingebouwde tool voor applicatiebewaking en firewall en DDoS bescherming op ondernemingsniveau van Cloudflare, helpt onze managed WordPress hostingoplossing sitebeheerders en -developers ’s nachts goed te slapen in de wetenschap dat hun sites veilig zijn.
Ze weten ook dat Kinsta hen elke maand uren werk bespaart. Minder tijd besteden aan herhalende maar kritische taken betekent minder overhead en minder onderhoudskosten voor je bedrijf.
Draait jouw bedrijf op WordPress? Ben je een WordPress developer die op zoek is naar een host met tools die je kunnen helpen je werk te stroomlijnen? Bekijk dan onze Managed WordPress hostingoplossingen.
Applicatiehosting (in het kort)
Webdevelopment bevindt zich momenteel in een interessant moment, en laat zien hoe gearticuleerd, genuanceerd en complex deze wereld tegenwoordig is. Onze nieuwe applicatiehostingoplossing vereenvoudigt het werk van moderne webdevelopers.
Wij maken het eenvoudig door je te bevrijden van het opzetten van containers, het beheren van servers, zorgen over het OS, het beheren van backups, het installeren van SSL certificaten en het toevoegen van aangepaste domeinen – alles wat je zou kunnen verhinderen om je uitsluitend op development te richten.
We hebben een ontwikkelplatform gebouwd dat ontworpen is om je te helpen je applicaties zo snel mogelijk naar de gebruikers te krijgen.
Kinsta’s applicatiehosting is wat de markt gewoonlijk een Platform-as-a-Service (PaaS) noemt, met tools die de implementatie van je applicaties vanuit codehostingdiensten zoals GitHub snel en eenvoudig maken en de capaciteit om ze soepel te laten draaien in een geoptimaliseerde omgeving die gebouwd is om te schalen.
Zo deploy je een applicatie op Kinsta
Onze engineers en productmanagers hebben zich gericht op het bouwen van een gestroomlijnd proces voor je deployments. Het proces vereist slechts 3 stappen:
- Maak verbinding met je GitHub account en kies een repository
- Deploy je applicatie automatisch (bij elke commit) of handmatig
- Bouw, schaal en draai je processen afzonderlijk
Zo eenvoudig is het!
Je hoeft je geen zorgen te maken over het opzetten van containerimages, omdat we automatisch applicaties detecteren en deployen die gebouwd zijn in deze groeiende lijst van talen of frameworks:
- Node.js
- PHP
- Django
- Rails
- Java
- Scala
- Go
(Opmerking: We hebben een lijst samengesteld van basis “Hello World” repositories die je kunt forken en inzetten op Kinsta om de dienst uit te proberen)
Als je liever meer controle hebt met een eigen Docker image, kun je je eigen Dockerfile in de repository gebruiken. Hierdoor kun je bijna elke taal/framework gebruiken en ben je niet beperkt tot die welke door onze huidige Buildpacks worden ondersteund.
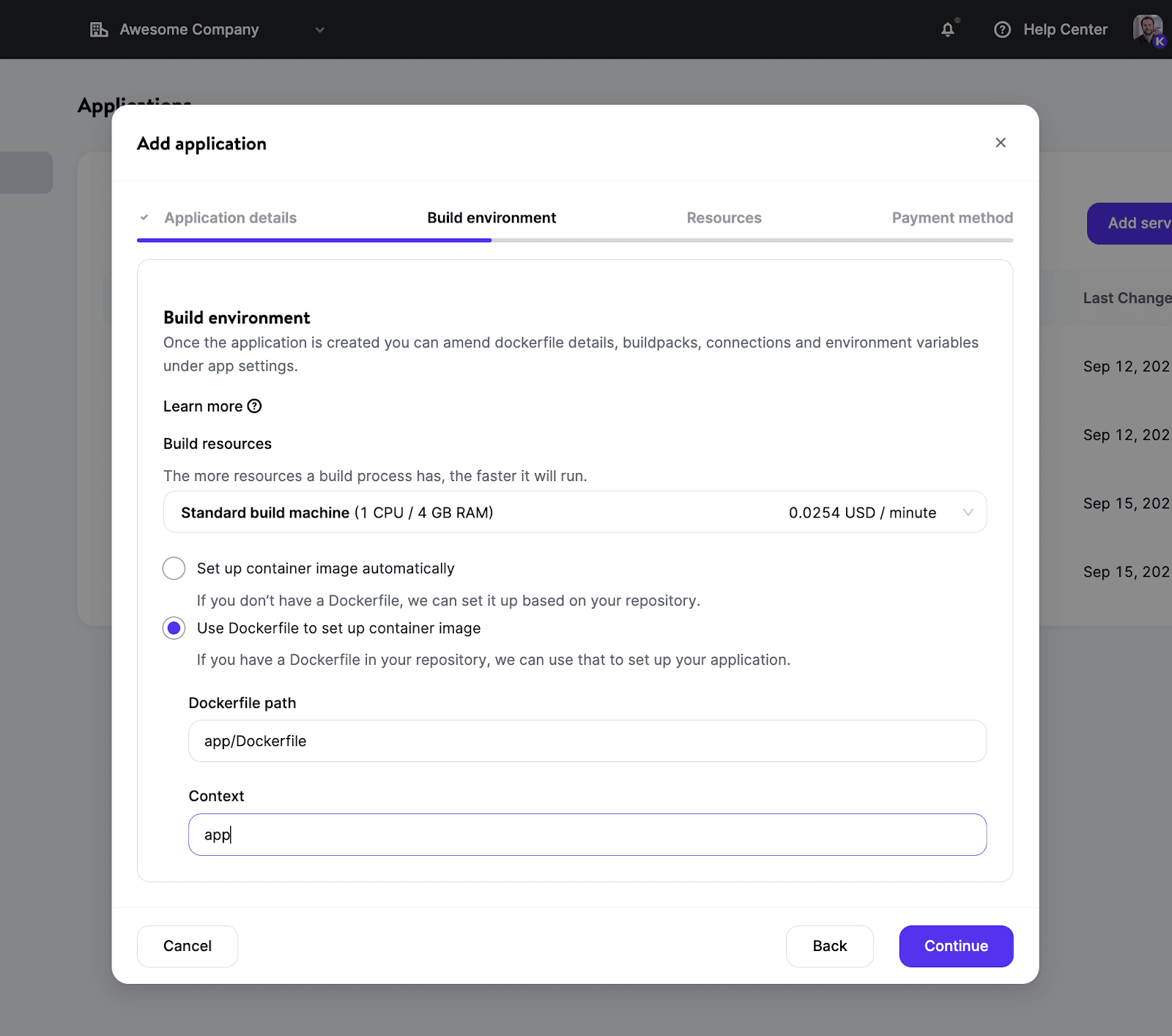
Zodra je bouwomgeving is ingesteld, heb je volop mogelijkheden om resourcegroottes te kiezen (dankzij verschillende podtypes) die passen bij je behoeften en het instance nummer te definiëren voor een betere schaalbaarheid.
Lees voor een diepgaande blik op alle features zeker onze documentatie over applicatiehosting.
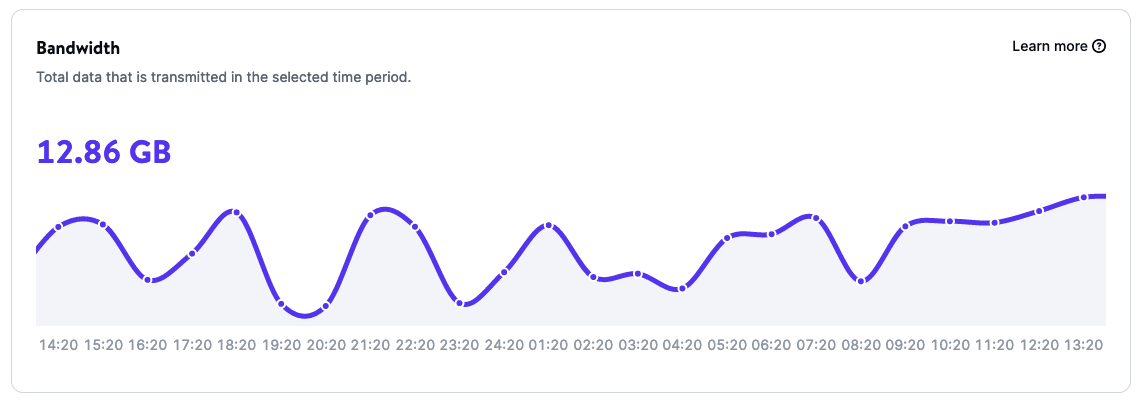
Krachtige analytics om je applicaties te monitoren
Dankzij de Analytics pagina ’s voor je applicaties kun je rapporten krijgen over het gebruik van applicaties, waaronder:
- Bandbreedte
- Bouwtijd
- Runtime
- CPU gebruik
- Geheugengebruik
Hoe zit het met de prijzen?
Applicatiehosting biedt resource-based opties, wat betekent dat je uitsluitend voor je gebruik betaalt en niets meer. En de eerste $20 is voor onze rekening – voor zowel nieuwe als bestaande klanten.
Leer meer over Applicatie Hosting bij Kinsta en zet je eerste applicatie in op een van onze 24 datacenterlocaties.
Databasehosting (in het kort)
Databases zijn een belangrijk onderdeel van veel webprojecten. Hoewel er applicaties zijn die er geen nodig hebben, heeft de overgrote meerderheid een database nodig.
Dankzij Kinsta’s databasehostingoplossing kun je met een paar klikken een database opzetten, en je kunt verbinding maken met je database met een door Kinsta gehoste applicatie of een externe dienst.
We ondersteunen momenteel verschillende databasetypen, waarvoor je de versie kunt kiezen die het beste past bij je projectbehoeften. Specifiek kun je hosten:
- MySQL
- MariaDB
- Redis
- PostgreSQL
En we werken eraan om er in de nabije toekomst meer toe te voegen!
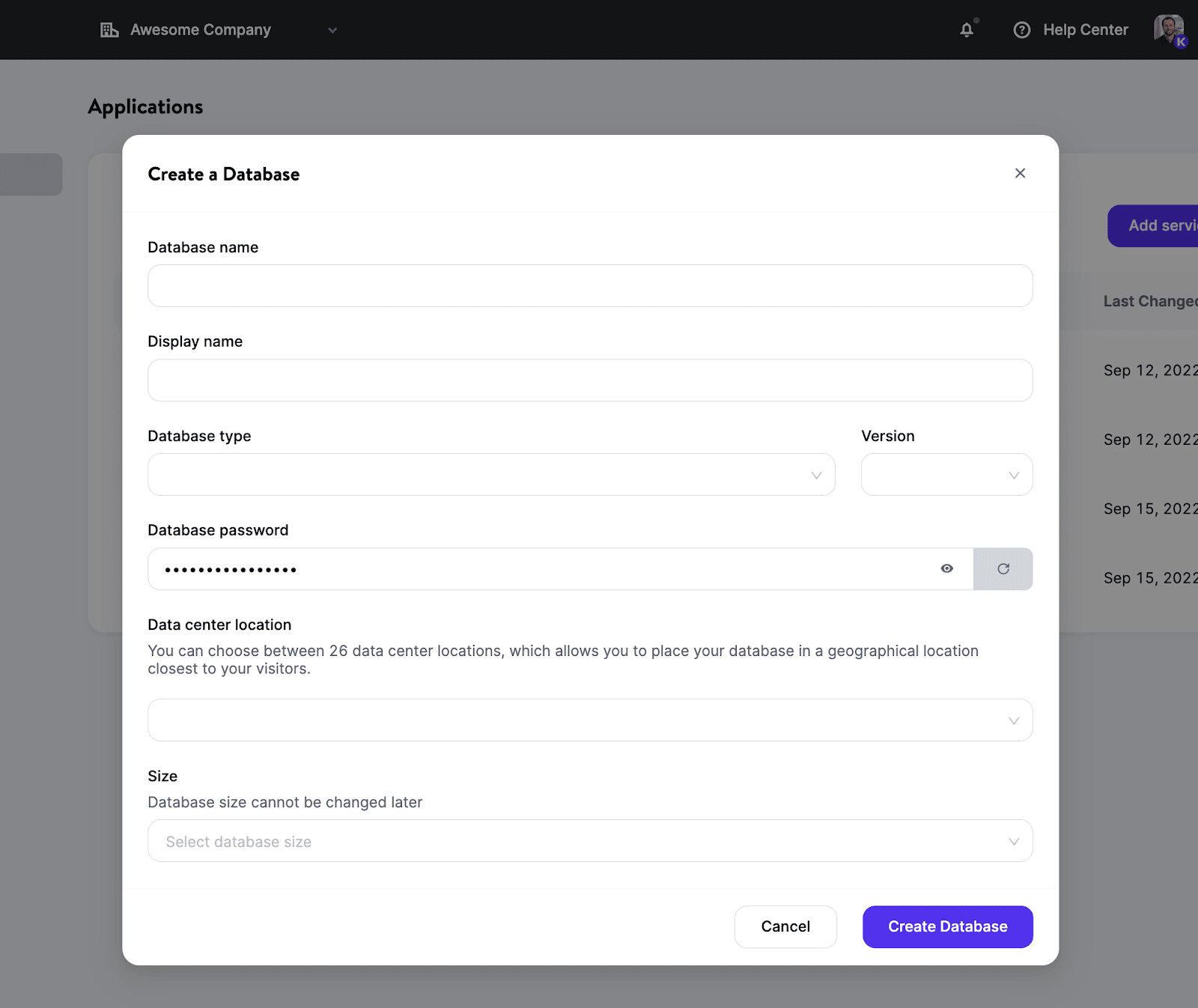
Zo deploy je een database bij Kinsta
Je kunt een nieuwe database opzetten en binnen enkele minuten beschikbaar hebben. Je hoeft geen servers te beheren, clusters en containers te hanteren, of je zorgen te maken over andere taken waarvoor DevOps gewoonlijk verantwoordelijk is.
Dit is het proces:
- Selecteer het databasetype en de versie die je wil.
- Kies een locatie uit de 24 datacenterlocaties die momenteel beschikbaar zijn.
- Configureer de resources voor je database.
Voilà: Je hebt nu een nieuwe, gecontaineriseerde database (zonder gedeelde resources!) voor je projecten.
Als je een interne verbinding maakt tussen je applicatie en je database, leven ze allebei in hetzelfde cluster en communiceren ze via een beveiligde verbinding, wat betere prestaties oplevert dan externe verbindingen.
Bovendien word je niet belast voor intern verkeer, omdat de verzoeken binnen hetzelfde netwerk blijven!
Lees voor meer informatie onze documentatie over databasehosting.
Krachtige analyses om je database te bewaken
Dankzij database Analytics kun je inzicht krijgen in de gebruiksgegevens van je database, waaronder:
- Opslag
- Runtime
- CPU gebruik
- Geheugengebruik
Hoe zit het met de prijzen?
Net als bij applicatiehosting biedt databasehosting een factureringssysteem per gebruik dat je factureert op basis van de grootte en looptijd van je database.
Kom meer te weten over databasehosting bij Kinsta en zet je eerste database in op een van onze 24 datacenterlocaties. Vergeet niet: je krijgt $20 aan tegoed voor je eerste maand.
Wat is de volgende stap?
Dit is nog maar het prille begin van Kinsta’s nieuwe tijdperk. Onze development- en engineeringteams werken hard aan nieuwe features, repareren bugs en bouwen verder door goed te luisteren naar de feedback die je hebt gedeeld.
Een paar van de nieuwe oplossingen waar we aan werken zijn statische sitehosting, machine learning, cloudapplicaties en Function-as-a-Service (in de edge) – om maar een paar van de spannende dingen op onze roadmap te noemen. Bovendien blijven we ons richten op het nog beter maken en verbeteren van onze managed WordPress oplossingen met het uitbrengen van features, zoals edge caching, die de tijd die nodig is om gecachete WordPress HTML te leveren met gemiddeld meer dan 50% vermindert!
Dit zijn geweldige tijden om als developer te werken, en we kunnen niet enthousiaster zijn over wat er hier bij Kinsta in het verschiet ligt!
Samenvatting
Door Kinsta’s hostingoplossingen uit te breiden, verrijken we de manieren waarop we bedrijven en developers ondersteunen, ongeacht de technologie waarmee ze werken. Zoals de voorzitter van de Raad van Bestuur van Kinsta heeft samengevat:
We bouwen een platform waar developers alles kunnen vinden wat ze nodig hebben om met gemak een webdienst te draaien, zodat ze zich kunnen concentreren op het maken en delen van hun beste werk met de wereld.
Om dit nieuwe hoofdstuk in de geschiedenis van Kinsta te vieren, kan iedereen – nieuwe en bestaande klanten – onze applicatiehosting en databasehosting uitproberen met $20 tegoed voor je eerste maand.
Welkom bij het nieuwe Kinsta – het platform gebouwd voor moderne developers om ideeën om te zetten in live, schaalbare applicaties – op de manier die je je altijd hebt gewild.
Eenvoudig, snel, met alles op één plek.
Dank aan al onze geweldige klanten voor het vertrouwen in ons met je bedrijf en het steunen van ons op deze reis!

Hoofdredacteur bij Kinsta en content marketing consultant voor WordPress plugin-ontwikkelaars. Verbind met <a href="">Matteo op Twitter.

