
For some of us, February 28th, 2017 will be remembered as the day that felt like half the internet went down to due to a major AWS outage. It felt vaguely familiar to the DNS Doomsday back in October 2016. Even those who don’t use AWS felt the effects as scripts, dependencies, and CDN resources began to timeout across the web, bringing thousands of sites, APIs, and apps to a standstill. This is a very important reminder of why the web needs more cloud computing providers for storage and delivery. Large companies aren’t even taking advantage of cross-region replication. Healthy competition in this space is always a good thing, as it drives costs down for businesses and consumers, and means a wider distribution of services and solutions across multiple providers.
AWS Outage
On the morning of February 28th, 2017 services from Amazon S3, part of Amazon Web Services, started to fail. BuiltWith shows that over 600,000 websites currently rely on AWS to power their sites, storage, or services. Amazon Cloud has also been reported to have over 1 million customers. While that might not even seem like that many in the scope of the entire internet, it had a huge ripple effect across the web due to the fact that many services that we all use on a daily basis rely on Amazon S3.
Update March 3rd, 2017 – Amazon has published a summary about the disruption, which was due to human error.
We're aware of issues with functionality of the https://t.co/dGuVluPt9A site, such as My Downloads. This is related to the @awscloud outage
— Woo (@WooCommerce) February 28, 2017
We use a lot of SaaS products at Kinsta and we first noticed this here as Intercom, our customer support and ticketing system began experiencing issues with their API connectivity, of which they soon had an announcement on their status page. This means we could no longer answer tickets for our customers. To put this into perspective, Intercom powers over 15,000 businesses with over 100,000 users, and then their customers. For Intercom to suddenly stop loading is a very big deal!

The ironic thing here is that their status page was also timing out on a few elements/scripts, due to the fact that they are using StatusPage, which relies on Amazon CloudFront. Many companies have the exact same setup. Trello is another one which had issue with AWS and also their status page going offline. We think this is a good lesson to not utilize the same cloud computing providers for both your API or services as well as your status page. Having both go down suddenly defeats the purpose of having a status page.

Amazon soon after that posted up a message on their status page:
We continue to experience high error rates with S3 in US-EAST-1, which is impacting various AWS services. We are working hard at repairing S3, believe we understand root cause, and are working on implementing what we believe will remediate the issue.
The ironic part here is that other than the small error message above that they posted, the rest of the service indicators all showed everything operating normally.
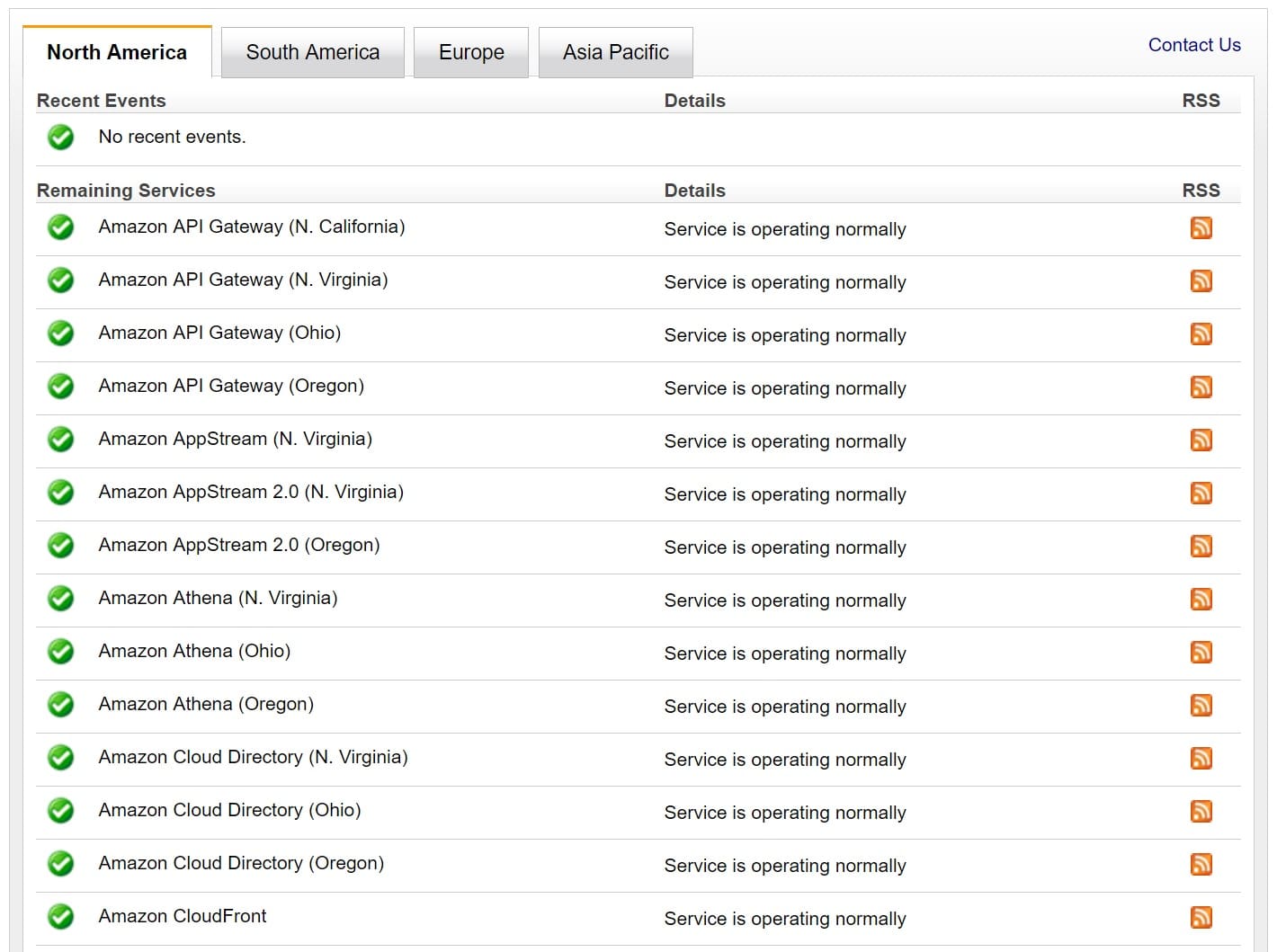
What happened was that the status page actually relied upon AWS S3 working properly. So technically AWS broke AWS, if you can wrap your head around that one.
The dashboard not changing color is related to S3 issue. See the banner at the top of the dashboard for updates.
— Amazon Web Services (@awscloud) February 28, 2017
The AWS S3 outage affected thousands of websites, services, apps, and APIs across the web. Many of our customers here at Kinsta utilize CloudFront or have plugins that are loading resources from Amazon S3. We noticed that WordPress sites started to time out due to external resources not being able to load, which then appeared for some as 502 bad gateway errors. Nothing was wrong with our servers, and yet the AWS outage did indeed affect our customers. This is something to keep in mind when you are choosing a CDN provider and 3rd party object storage. External integrations can bring your site down and you can meet with the famous 502 bad gateway error!

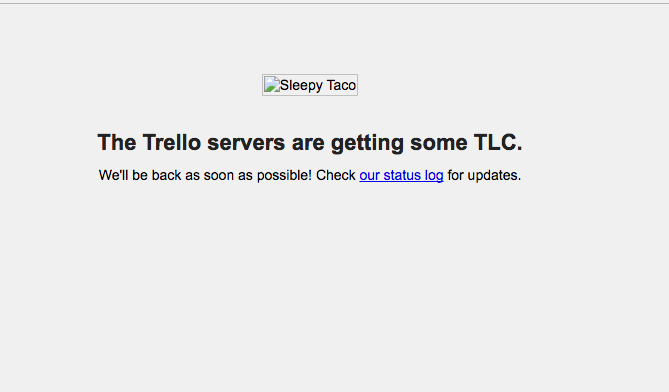
We also use Trello here at Kinsta and for those of us in the US, we could no longer access our boards but were met with a message saying the Trello servers are getting some TLC. And ironically the Sleep Taco image is broken due to it trying to load from CloudFront. Suggested reading: Trello vs Asana.
I can't do the work thing without the Trello thing. *headdesk*
— Brenda – Digital Inkwell (@digitalinkwell) February 28, 2017
Some other popular sites that either went down or had issues were Quora, Business Insider, Giphy, Hacker News, BaseCamp, Buffer, Imgur, Netlix, Docker, Github, Twitch, Adobe, HipChat, Flippa, Expedia, New Relic, PagerDuty, Pantheon, Sprout Social, Elastic, Citrix, Zendesk, Brightcloud, IFTTT, Heroku, Slack (file sharing and GIFs), Typeform, and many others. Perhaps the most ironic one of all is “Is It Down Right Now?” also had issues staying up. Of course, whenever this happens, you have people heading to Twitter to voice their feedback.
Amazon S3 is down and the internet is burning pic.twitter.com/PZ6sU54UK6
— G (@govinbhai) February 28, 2017
https://twitter.com/Schmidt_RB/status/836641520321179648
You know it's bad when #isitdownrightnow is down. Right now. https://t.co/h1Rik46FYQ #internetdown #apocolyps3 #aws #s3 pic.twitter.com/3EYe6opXjm
— Alex Chaucer (@geoparadigm) February 28, 2017
#1 Programmer excuse for legitimately slacking off: AWS outage https://t.co/poA9w3v3J2 #aws #s3 pic.twitter.com/iTzKU6e4zj
— Jeff Geerling (@geerlingguy) February 28, 2017
And there are thousands more where that came from. While memes and Tweets can be fun, the scary part here really is just how much of the cloud computing market that Amazon owns and how much of an effect it has when it goes down. You really have just a couple battling it out for the market share. According to a 2017 study by the Synergy Research Group, AWS market share makes up little over 40% of the cloud computing provider’s space. You then have Microsoft Azure, Google, and IBM competing at around 20%. And of course, there are thousands of other smaller providers all fighting for the rest.
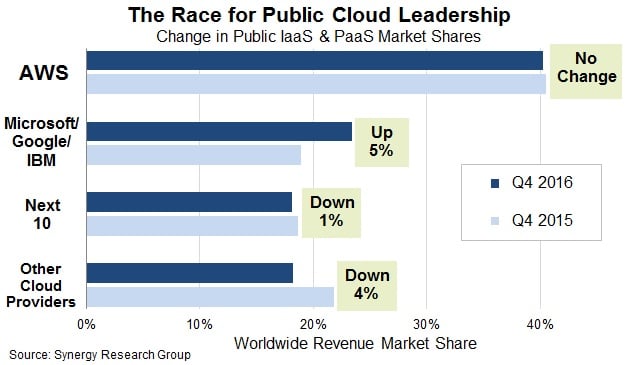
Even though Google Cloud Platform has only about half the market share of Amazon, it’s grown by over 5%. And we would love to see more providers enter the space as it is a win for everyone involved. Spreading out services among multiple providers could solve some of these days where it feels like the entire web has gone down.
There Are Alternative Cloud Computing Providers
Below are a few alternative cloud computing providers you want to check out for file delivery, APIs, and apps. We aren’t saying Amazon is bad, in fact they normally have great uptime. But many companies and customers go with AWS because everyone else appears to be using them, which is not a good reason to choose a cloud provider. After seeing what happened today, it might be wise to distribute them. Such as hosting your public facing website’s assets with one provider and utilizing another for your API. This way you can at least build in some simple redundancy so that everything doesn’t go offline.
Many providers also have multi-regional support or cross-region replication, in which you should be hosting your critical applications. However, it appears that many companies are not utilizing these features. This can be more of a complex setup, which could be one reason they aren’t taking advantage of this configuration. Or due to the extra cost. But more cloud providers in the market would simply be an easy way to force wider distribution of services across multiple providers.
Here is a list of providers that also offer computing capabilities along with storage solutions:
- Google Cloud Platform
- Microsoft Azure
- IBM
- Rackspace (they now utilize other 3rd party providers)
- Cisco
- Digital Ocean
- Linode
- Vultr
Additional Updates from Amazon S3
Amazon S3 services have since been restored and everything is operational again. See the additional status updates:
- Update at 2:08 PM PST: As of 1:49 PM PST, we are fully recovered for operations for adding new objects in S3, which was our last operation showing a high error rate. The Amazon S3 service is operating normally.
- Update at 1:12 PM PST: S3 object retrieval, listing and deletion are fully recovered now. We are still working to recover normal operations for adding new objects to S3.
- Update at 12:52 PM PST: We are seeing recovery for S3 object retrievals, listing and deletions. We continue to work on recovery for adding new objects to S3 and expect to start seeing improved error rates within the hour.
Summary
We think everyone can take away a few lessons from what happened with AWS. There is no cloud provider that is perfect, and that is more of a reason why we hope to see more competition in this space. It would be awesome to one day see 10 or more providers equally sharing market share, as this would mean more distributed services across the web. If one went down, we wouldn’t feel as much of a ripple effect as we did today. What are your thoughts? Do you think we need more cloud computing providers in the space?

Brian has a huge passion for WordPress, has been using it for over a decade, and even develops a couple of premium plugins. Brian enjoys blogging, movies, and hiking. Connect with Brian on Twitter.

