
Het beheren van je resources is cruciaal voor het optimaliseren van de prestaties en stabiliteit van je site. Een WordPress site moet pieken in het verkeer aankunnen, resources op het juiste moment kunnen schalen en prestatieafwijkingen snel kunnen detecteren.
Natuurlijk is het implementeren van al deze taken ook noodzakelijk. De Kinsta API heeft een paar endpoints die kunnen helpen bij het voorspellen van het schalen van resources en het detecteren van afwijkingen.
In dit artikel onderzoeken we de concepten van voorspellende resource scaling en anomaliedetectie en hoe de Kinsta API in je workflow past. We bespreken enkele realistische scenario’s van dit soort schalen, onderzoeken de mogelijkheden van de API en bekijken hoe je deze strategieën kunt integreren in je workflow.
Als eerste stap moeten we echter proberen te begrijpen met welke taken we te maken krijgen.
Voorspellende resource scaling en anomaliedetectie
We gaan zo meteen in op waar de Kinsta API bij kan helpen. Laten we eerst eens kijken wat voorspellend schalen van je resources je kan opleveren. Van daaruit behandelen we ook de voordelen van het kunnen detecteren van anomalieën in de prestaties van je site.
De voordelen van voorspellend schalen van resources
In een notendop is voorspellend schalen van resources een manier om de resources van je site te beheren op basis van de vraag die je verwacht. Het is een proactieve benadering waarbij gegevens worden geanalyseerd, gebruikspatronen worden bestudeerd en andere relevante factoren worden bekeken.
Door te voorspellen wanneer je site waarschijnlijk meer verkeer of resources gaat gebruiken, kun je schalen om aan de vraag te voldoen. Het nettoresultaat is geoptimaliseerde prestaties en een betere algehele gebruikerservaring (UX).
Er zijn echter veel voordelen van voorspellend schalen van resources die het geheel vormen:
- Verbeterde siteprestaties. Het opschalen van je resources kan helpen om prestatieproblemen te voorkomen. Dit kan er weer voor zorgen dat je site responsief blijft tijdens drukke verkeersperioden.
- Kostenoptimalisatie. Door voorspellend te schalen kun je resources efficiënter toewijzen. Zo voorkom je dat je te veel resources beschikbaar stelt en verlaag je onnodige kosten.
- Verbeterde gebruikerservaring. Verkeerspieken kunnen worden beperkt, wat leidt tot een betere UX. Je site zal die pieken met minder belasting aankunnen, waardoor je een consistente, soepele en snelle front-end ervaring krijgt.
Het combineren van voorspellend schalen met de mogelijkheid om prestatieafwijkingen op je server te detecteren is een geweldige combinatie. Vervolgens bespreken we de voordelen van het detecteren van deze inconsistenties.
Het belang van anomaliedetectie
Een aspect dat vaak hand in hand gaat met een schaalstrategie is het detecteren van onregelmatigheden in de prestatiecijfers van je site. Je statistieken hebben een basislijn en extreme uitschieters als het gaat om CPU-gebruik, geheugengebruik en responstijden, die een bron van problemen en potentiële optimalisatie kunnen zijn.
Als je deze afwijkingen in een vroeg stadium ontdekt, kun je potentiële problemen aanpakken voordat ze de beschikbaarheid en UX van je site beïnvloeden en een groot probleem worden. Bovendien zijn er nog veel meer voordelen:
- Proactief problemen oplossen. Als je inconsistenties kunt ontdekken voordat het grotere problemen worden, kun je snel actie ondernemen om ze op te lossen. Dit kan downtime minimaliseren en de continue beschikbaarheid van je site garanderen.
- Verbeteringen van de stabiliteit van de site. Met anomaliedetectie kun je huidige prestatieproblemen identificeren en aanpakken. Het oplossen hiervan kan bijdragen aan de algehele stabiliteit en betrouwbaarheid van je site.
- Inzichten in optimalisatie. Door de anomalieën die zich voordoen te analyseren, kun je waardevolle inzichten krijgen in gebieden van je site die mogelijk verder geoptimaliseerd moeten worden.
Zowel het opsporen van anomalieën als het schalen van de prestaties zijn twee kanten van dezelfde medaille. Dit betekent dat je de strategieën samen gebruikt om een robuuste prestatiebasis voor je site te creëren. In de volgende sectie zullen we zien hoe dit eruit ziet in een aantal typische scenario’s.
Real-world scenario’s voor voorspellende resource scaling en detectie van afwijkingen
De noodzaak om de serverresources die je tot je beschikking hebt te verhogen, heeft veel praktische toepassingen. Je kunt wel stellen dat bijna elke site een vorm van deze strategie nodig heeft.
Om beter te begrijpen hoe je voorspellend schalen van resources en anomaliedetectie in een echte omgeving kunt gebruiken, laten we er een paar de revue passeren. Onze eerste is waarschijnlijk een van de populairste scenario’s.
1. E-commercesites tijdens piekseizoenen
In een ideale wereld heeft je e-commercesite het hele jaar door consistent verkeer en betrokkenheid. In werkelijkheid zal je activiteit echter fluctueren. Denk bijvoorbeeld aan een e-commercesite met grote verkeerspieken tijdens feestdagen of uitverkoop.
Hier is het nodig om een goed analytisch onderzoek uit te voeren. Je begint met je statistieken en kijkt naar historische gegevens over je verkeersniveaus. Als je deze statistieken kunt gebruiken om te anticiperen op verwachte verkeerspieken, kun je gaan nadenken over hulpmiddelen.
De taak is om proactief om te gaan met het schalen van resources op basis van je verwachte verkeersniveaus op specifieke momenten in het jaar. Je zou bijvoorbeeld de toewijzing van CPU en geheugen kunnen verhogen om een verhoogde belasting aan te kunnen. Aan de front-end kan de winkelervaring daarom stabiel en soepel blijven voor je klanten. Dit kan je niet alleen inkomsten besparen, maar ook opleveren.
2. Nieuws- en mediasites tijdens grote evenementen
Sites die zich bezighouden met tijdgerichte inhoud, zoals nieuwswebsites, hebben te maken met dezelfde uitdagingen als e-commercesites. In dit geval treden die verkeerspieken op wanneer er grote evenementen of brekend nieuws zijn.
Het verschil is hier echter groter, omdat de pieken vaker voorkomen en ook grilliger zijn. Toegang tot relevante content is vaak ook cruciaal. Denk bijvoorbeeld aan weerwaarschuwingen.
Dit is waar voorspellende resource scaling kan uitblinken. Net als bij e-commerce kan het analyseren van verkeerspatronen uit het verleden tijdens vergelijkbare gebeurtenissen je helpen om weloverwogen beslissingen te nemen over wanneer je moet schalen en met hoeveel. Het monitoren van actuele nieuwstrends kan ook nuttig zijn. Het primaire doel is hier om ervoor te zorgen dat je site toegankelijk en responsief blijft. Hoewel een soepele UX ook belangrijk is, is toegang zonder onderbrekingen het belangrijkst.
3. Software as a Service (SaaS) applicaties met wisselende gebruikspatronen
SaaS-apps kunnen veranderlijk zijn, met fluctuerende gebruikspatronen op basis van zowel het gedrag van de klant als de algehele vraag naar de dienst. Een goed voorbeeld hiervan is tijdens de uitbraak van Covid-19 in maart 2020. 16 miljoen kenniswerkers moesten thuisblijven en Slack had in die eerste twee weken een stijging van 20% in gebruikers.
Anomaliedetectie kan je helpen begrijpen wat er mis kan gaan bij het schalen van je resources. Dit maakte veel uit voor Slack omdat het belangrijk was om mensen te helpen door te werken tijdens de pandemie.
Voorspellend schalen van resources is ook van vitaal belang, omdat het een manier is om je infrastructuur te optimaliseren voor gebruikspatronen. Nogmaals, het bekijken van historische gegevens en het implementeren van een proactieve schaalstrategie kan UX helpen, kosten minimaliseren en vertrouwen en externe reputatie opbouwen onder je gebruikers.
De mogelijkheden van de Kinsta API voor resourcebeheer
Een manier hebben om het schalen van resources te implementeren en afwijkingen te detecteren is net zo belangrijk als kennis over de strategieën. Voor Kinsta gebruikers heb je het MyKinsta dashboard, dat een schat aan statistieken bevat:
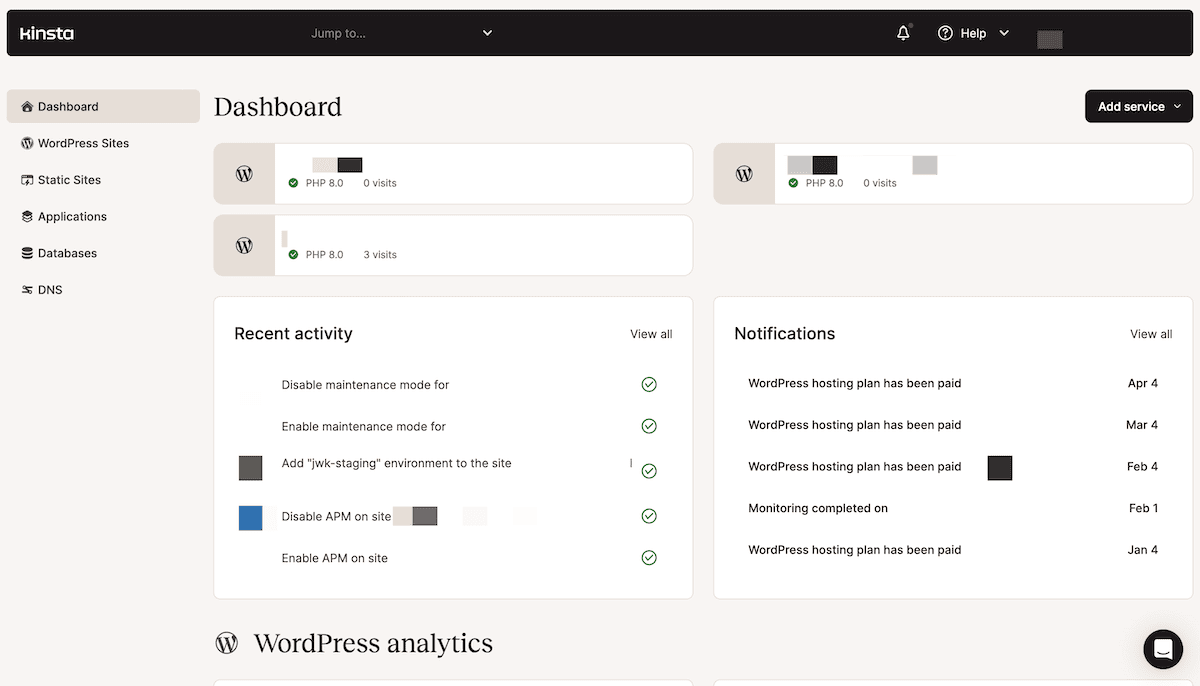
Dit helpt echter niet in situaties waarin je meer flexibiliteit nodig hebt. In plaats daarvan is de Kinsta API het juiste gereedschap. Dit geeft je een aantal endpoints om in te haken op onze functionaliteiten, waarvan sommige heel belangrijk zijn voor schaalbaarheid en analyse:
CPU Usage.Je kunt het CPU gebruik van je server in de loop van de tijd in de gaten houden, waardoor je trends en potentiële knelpunten kunt identificeren voordat ze een probleem worden.Memory Usage.Je kunt het geheugengebruik bijhouden om er zeker van te zijn dat je site voldoende resources heeft om de werklast aan te kunnen en deze zo nodig opvoeren.Bandwidth.Het analyseren van de totale gegevens die je verstuurt kan een goede indicator zijn voor het implementeren van je schaalstrategie.Slowest Requests.Dit is een van de vele andere endpoints die je kunnen laten zien welke verzoeken en reacties de grootste invloed hebben op de prestaties van je site.
We zullen hier later dieper op ingaan. Het is echter belangrijk om te begrijpen dat de Kinsta API slechts de basisprincipes van het schalen van resources en het opsporen van anomalieën dekt:
- Je moet eventuele toekomstige problemen zelf voorspellen. De Kinsta API kan alleen gegevens jouw kant op sturen; jij moet ze interpreteren.
- In het verlengde daarvan is elke schaling die je moet implementeren jouw verantwoordelijkheid. De Kinsta API kan dit niet voor je doen.
- Hoewel de Kinsta API veel manieren biedt om je site te monitoren, heb je misschien niet alle endpoints die je nodig hebt om aan je doelen te voldoen (hoewel we er wel aan werken!).
Hoe dan ook, de API heeft veel in huis en zijn programmatische aard betekent dat je hem kunt koppelen aan andere systemen, je eigen functies en klassen kunt implementeren en bijna alles wat je maar wilt.
Afwijkingen detecteren met de Kinsta API
Je zult schaalvergroting niet elke dag gebruiken en je zult misschien maar een paar keer per jaar besluiten om de trekker over te halen. Laten we daarom eens kijken naar iets wat je veel regelmatiger zult doen – inconsistenties detecteren in de statistieken van je server.
Monitoring en waarschuwingen instellen
Je monitoringsysteem vormt de ruggengraat van je proactiviteit. Er zijn veel overwegingen, maar ons advies is om het in het begin eenvoudig te houden:
- Beslis wat je wilt monitoren. Je kunt vertrouwen op je eigen rapportage om de belangrijkste statistieken aan te geven of je kunt gewoon naar je MyKinsta dashboard kijken om te zien wat je vaak controleert.
- Bepaal hoe je waarschuwingen wilt ontvangen. Je zou bijvoorbeeld Slack meldingen of een eenvoudige e-mail kunnen ontvangen wanneer je een drempel bereikt.
- Bepaal een basislijn. Je moet de tijd nemen om het typische gedrag van je server te begrijpen. Dit is waar je kijkt naar historische metrische gegevens en eventuele toekomstige indicaties of trends.
Zodra je deze kennis hebt, kun je beginnen met het gebruik van de Kinsta API om de endpoints in te stellen die je nodig hebt.
Kinsta API endpoints voor het detecteren van afwijkingen
Er zijn een paar endpoints die je hierbij kunnen helpen. We hebben er al een paar eerder genoemd, maar voor de volledigheid is hier een lijst waarvan we denken dat die voldoet:
Bandwidth.We hebben het hier al over gehad, in die zin dat dit de manier is waarop je de totale gegevens meet die je verstuurt.HTTP Requests Per Minute.Dit is een eenvoudige: het meet letterlijk hoeveel HTTP verzoeken je site elke minuut krijgt!
Er zijn een paar endpoints die goed zijn voor trendanalyse:
CPU Usage.Onze metric toont het gemiddelde totale CPU-gebruik voor een geselecteerde tijdsperiode.Memory Usage.Op dezelfde manier is dit het gemiddelde van het totale geheugengebruik voor een geselecteerde periode.
Als je advies nodig hebt over de mogelijkheden om te schalen, dan zijn er enkele endpoints die je daarbij kunnen helpen:
Build Time.Het bijhouden hiervan laat je zien hoe lang het duurt om je app te bouwen. Gecombineerd met statistieken over je CPU- en geheugengebruik (onder andere), kun je je een mening vormen over of je moet schalen.Run Time.De totale tijd dat je applicatie draait kan je helpen om te beslissen waar je prioriteit aan moet geven, knelpunten in de prestaties te vinden en nog veel meer.
Laten we een voorbeeld geven van het gebruik van een endpoint voor anomaliedetectie. Hier gebruiken we Node.js om de bandbreedte van een site te controleren. Merk op dat je API sleutelvalidatie moet gebruiken – waarschijnlijk met behulp van omgevingsvariabelen – en een manier om constant de bandbreedte te controleren.
import fetch from 'node-fetch';
const API_TOKEN = <YOUR-API-TOKEN>;
const APPLICATION_ID = <YOUR-COMPANY-ID>;
async function checkBandwidth(token, id, timeframeStart, timeframeEnd, intervalInSeconds) {
const query = new URLSearchParams({
interval_in_seconds: intervalInSeconds,
timeframe_start: timeframeStart,
timeframe_end: timeframeEnd,
}).toString();
const resp = await fetch(`https://api.kinsta.com/v2/applications/${id}/metrics/bandwidth?${query}`, {
method: 'GET',
headers: {
Authorization: 'Bearer <YOUR-API-KEY>',
},
});
const data = await resp.json();
if (!resp.ok) {
console.error('Error checking bandwidth:', data);
return;
}
console.log('Bandwidth data:', data);
}
async function run() {
const timeframeStart = '2021-07-22T18:10:45.511Z';
const timeframeEnd = '2021-07-22T18:10:45.511Z';
const intervalInSeconds = '3600';
await checkBandwidth(API_TOKEN, APPLICATION_ID, timeframeStart, timeframeEnd, intervalInSeconds);
}
run().catch(error => {
console.error('An error occurred', error);
process.exit(1);
});
Wat betreft meldingen zou je een Slack-kanaal kunnen opzetten om een chat te starten wanneer je bandbreedte een bepaalde limiet bereikt.
Om eventuele afwijkingen op te sporen, zou je de gegevens die je ophaalt willen bekijken op uitschieters – hoewel je ook een programmatische manier zou kunnen ontwikkelen om te zoeken naar afwijkende statistieken. Van daaruit kun je beginnen met het formuleren van een reactie.
Reageren op afwijkingen
In een notendop: je script detecteert een onregelmatigheid, stuurt een ping naar Slack en je kunt dan in actie komen. Hoe je dit doet, hangt af van je reactieplan. Dit proces bepaalt hoe je het probleem verder onderzoekt, diagnosticeert en de hoofdoorzaak oplost.
Als het bijvoorbeeld gaat om een site van een klant, kun je een serviceovereenkomst hebben waarin staat dat je binnen een bepaalde tijd moet reageren. Voor je eigen site kun je eenvoudigweg naar je analytics gaan en je logboeken bekijken.

Voorspellend schalen van resources implementeren met de Kinsta API
Als je eenmaal je basisgegevens kent, kun je beslissen of je je resources gaat schalen of niet. Zoals we in een eerdere paragraaf hebben beschreven, is geautomatiseerde voorspelling iets dat je kunt implementeren. De applicatiehosting van Kinsta biedt dit voor elk pakket. Je vindt de optie in het MyKinsta dashboard onder het tabblad Applicaties.
De Kinsta API kan je echter de tools geven om je voorspellingen nauwkeurig en met vertrouwen te doen.
Er zijn een paar strategieën die je hier kunt toepassen:
- Merk mogelijkheden op om te profiteren van schaalvergroting.
- Beoordeel je totale en macro resourceverbruik.
- Zoek knelpunten als doelen voor het schalen van je middelen.
Als je kijkt naar de endpoints bandwidth, HTTP requests per minute en average response time, dan zijn dit geweldige manieren om opschalingsruimte te vinden. Je zult merken dat het controleren van bandbreedte en HTTP verzoeken ‘dubbele diensten’ verricht voor het schalen van resources en het opsporen van afwijkingen.
Dezelfde endpoints die je gebruikt voor het analyseren van trends zijn ook geweldig voor het voorspellen van het schalen van resources. In feite zijn CPU-gebruik en geheugengebruik beide signalen die aangeven dat je de kracht van je server moet verhogen.
Tenslotte kunnen knelpunten in de laadprocessen van je pagina’s je resources teisteren en een ideaal doel zijn voor het schalen. Het slowest requests endpoint is er een om in de gaten te houden. Het markeert de ergste “overtreders” voor je site en het MyKinsta dashboard geeft je daar een grafiek van:

Dit kan echter een teken zijn dat je moet opschalen en het kan ook een punt van optimalisatie aangeven. Dit is (in theorie) laaghangend fruit, omdat het oplossen van deze ingekapselde problemen de hoeveelheid resources die je aan je site toewijst vermindert en dus vrijmaakt.
Tips en trucs voor het integreren van voorspellend schalen en anomaliedetectie in je workflow
Voordat we afsluiten, bespreken we een aantal tactieken, typische werkwijzen en tips om voorspellend schalen en anomaliedetectie in je workflow te integreren. Proactiviteit is iets waar we het in dit stuk veel over hebben en er zijn een paar manieren waarop je op dit gebied een stap voor kunt zijn:
- Zoek een aantal duidelijke basislijnen en drempelwaarden voor de prestaties van je site om je schaal- en detectiestrategieën te helpen sturen.
- Maak tijd vrij om je voorspellende modellen regelmatig op nauwkeurigheid en relevantie te controleren en bij te werken.
- Implementeer waar mogelijk geautomatiseerde monitoring met waarschuwingen die het hele team kan zien. Je wilt het aantal handmatige interventies tot een minimum beperken.
Wat betreft het balanceren tussen automatische en handmatige interventies, zijn er een paar tips die we ook hier kunnen doorgeven:
- Er moet een balans zijn tussen geautomatiseerde schaalacties en handmatig toezicht. Dit is belangrijker dan je denkt voor het juiste niveau van controle en verantwoordelijkheid voor je strategie.
- Waar je geautomatiseerd schalen implementeert, moeten er duidelijke richtlijnen en regels zijn over wanneer het in werking moet treden en wanneer er handmatig moet worden ingegrepen.
- Herzie en verfijn je automatiseringsregels regelmatig. Dit zal je helpen om de efficiëntie te verhogen en valse positieven in je rapportage te minimaliseren.
We hebben nog een laatste tip met betrekking tot analyse en monitoring. Dit deel van het proces houdt in dat je voortdurend je statistieken controleert en reageert op eventuele veranderingen. Er zijn een paar manieren om dit gemakkelijker te maken.
De belangrijkste is volgens ons om de uitkomsten van alle beslissingen die je neemt regelmatig te analyseren. Dit kan belangrijk zijn voor de volgende cyclus, omdat een beter inzicht in hoe je beslissingen neemt, je volgende beslissingen effectiever maakt.
Samenvatting
Voorspellende resource scaling en anomaliedetectie zijn twee uitstekende manieren om proactief te zijn als het gaat om het beheren van de prestaties en responsiviteit van je WordPress website. De Kinsta API kan je helpen om deze technieken programmatisch te implementeren en verder te ontwikkelen.
Er zijn bijvoorbeeld veel endpoints waarmee je de prestaties van je site kunt monitoren. Met de juiste scripts kun je basislijnen en benchmarks instellen. Als je dit koppelt aan een platform zoals Slack, kun je geautomatiseerde waarschuwingen krijgen die je helpen om je reactieplan in werking te zetten.
Heb jij een strategie nodig voor predictive resource monitoring en anomaliedetectie, en zo ja, wat is voor jou belangrijk? Laat het ons weten in de comments hieronder!


