
In de huidige wereld waarin data enorm belangrijk is, waarin het volume en de complexiteit van data in een ongekend tempo blijven toenemen, is de behoefte aan robuuste en schaalbare databaseoplossingen van het grootste belang geworden. Er wordt geschat dat er in 2025 180 zettabytes aan gegevens zullen zijn. Dat zijn aantallen die maar moeilijk te bevatten zijn!
Naarmate de vraag naar data toeneemt, wordt het onpraktisch om te vertrouwen op één enkele databaselocatie. Het vertraagt niet alleen je systeem en maar is ook onpraktisch voor developers. Je kunt echter gelukkig verschillende oplossingen toepassen om je database te optimaliseren, zoals database sharding.
In deze uitgebreide gids gaan we dieper in op MongoDB sharding, waarbij we de voordelen, componenten, best practices, veelgemaakte fouten en hoe je aan de slag kunt allemaal gaan bespreken.
Wat is database sharding?
Database sharding is een databasebeheertechniek waarbij een groeiende database horizontaal wordt opgedeeld in kleinere, beter beheersbare eenheden, ook wel shards genoemd.
Naarmate je database groter wordt, wordt het praktisch om deze op te delen in meerdere kleinere delen en elk deel apart op te slaan op verschillende machines. Deze kleinere delen, of shards, zijn onafhankelijke subsets van de totale database. Dit proces van opdelen en verdelen van gegevens is wat database sharding inhoudt.
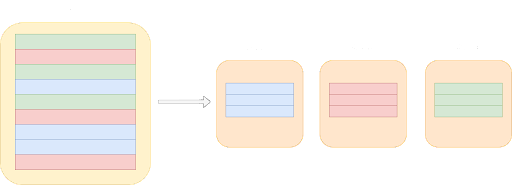
Bij het implementeren van een sharded database zijn er twee primaire benaderingen: het ontwikkelen van een eigen sharding oplossing of het betalen voor een bestaande oplossing. Dit roept dan natuurlijk de vraag op of het bouwen van een sharded oplossing of betalen beter is.

Om deze keuze te maken, moet je rekening houden met de kosten van externe integraties, waarbij je de volgende factoren in gedachten moet houden:
- Ontwikkelaarsvaardigheden en leercurve: De leercurve die bij het product hoort en hoe goed het aansluit bij de vaardigheden van je developers.
- Het datamodel en de API die door het systeem worden aangeboden: Elk datasysteem heeft zijn eigen manier om zijn gegevens te representeren. Het gemak en het gemak waarmee je je applicaties kunt integreren met het product is een belangrijke factor om rekening mee te houden.
- Klantenondersteuning en online documentatie: In gevallen waarin je uitdagingen kunt tegenkomen of hulp nodig hebt tijdens de integratie, worden de kwaliteit en beschikbaarheid van klantenondersteuning en uitgebreide online documentatie cruciaal.
- Beschikbaarheid van cloudimplementatie: Nu steeds meer bedrijven overgaan op de cloud, is het belangrijk om te bepalen of het product van derden kan worden ingezet in een cloudomgeving.
Op basis van deze factoren kun je nu beslissen om zelf een sharding oplossing te bouwen of te betalen voor een oplossing die het zware werk voor je doet.
Tegenwoordig ondersteunen de meeste databases die je kan vinden database sharding. Bijvoorbeeld relationele databases zoals MariaDB (een onderdeel van de high-performance server stack bij Kinsta) en NoSQL databases zoals MongoDB.
Wat is sharding in MongoDB?
Het primaire doel van het gebruik van een NoSQL database is het vermogen om te gaan met de computing- en opslagvereisten van het opvragen en opslaan van enorme hoeveelheden data.
Over het algemeen bevat een MongoDB database een groot aantal collecties. Elke collectie bestaat uit verschillende documenten die gegevens bevatten in de vorm van sleutelwaardeparen. Je kunt deze grote collectie opdelen in meerdere kleinere collecties met behulp van MongoDB sharding. Hierdoor kan MongoDB queries uitvoeren zonder de server veel te belasten.
Telefónica Tech beheert bijvoorbeeld meer dan 30 miljoen IoT apparaten wereldwijd. Om het steeds toenemende gebruik van apparaten bij te houden, hadden ze een platform nodig dat elastisch kon schalen en een snel groeiende dataomgeving kon beheren. De sharding technologie van MongoDB was de juiste keuze voor hen, omdat deze het beste paste bij hun kosten en capaciteitsbehoeften.
Met MongoDB sharding draait Telefónica Tech meer dan 115.000 queries per seconde. Dat zijn 30.000 database-inserts per seconde, met minder dan één milliseconde latency!
Voordelen van MongoDB sharding
Hier zijn een paar voordelen van MongoDB sharding voor grootschalige gegevens waarvan je kunt profiteren:
Opslagcapaciteit
We hebben al gezien dat sharding de data over de clustershards verdeelt. Door deze verdeling bevat elke shard een fragment van de totale clustergegevens. Extra shards vergroten de opslagcapaciteit van het cluster naarmate je dataset groter wordt.
Lezen/schrijven
MongoDB verdeelt lees- en schrijfwerk over shards in een sharded cluster, waardoor elke shard een subset van de clusterbewerkingen kan verwerken. Beide workloads kunnen horizontaal over het cluster worden geschaald door meer shards toe te voegen.
Hoge beschikbaarheid
De inzet van shards en config servers als replicasets bieden een verhoogde beschikbaarheid. Zelfs als een of meer shard replicasets volledig onbeschikbaar worden, kan het sharded cluster gedeeltelijk lezen en schrijven.
Bescherming tegen uitval
Veel gebruikers worden getroffen als een machine down gaat door een ongeplande storing. In een niet-geshard systeem is de impact enorm, omdat de hele database zou zijn uitgevallen. De straal van slechte gebruikerservaring/impact kan worden beperkt door MongoDB te sharden.
Geo-verdeling en prestaties
Gerepliceerde shards kunnen in verschillende regio’s worden geplaatst. Dit betekent dat klanten toegang tot hun gegevens kunnen krijgen met een lage latency, d.w.z. dat verzoeken van consumenten worden doorgestuurd naar de shard die het dichtst bij hen in de buurt is. Op basis van het gegevensbeheerbeleid van een regio kunnen specifieke shards worden geconfigureerd om in een specifieke regio te worden geplaatst.
Onderdelen van MongoDB sharded clusters
Nu we het concept van een MongoDB sharded cluster hebben uitgelegd, gaan we dieper in op de componenten waaruit dergelijke clusters bestaan.
1. Shard
Elke shard heeft een subset van de sharded data. Vanaf MongoDB 3.6 moeten shards worden ingezet als een replicaset om hoge beschikbaarheid en redundantie te bieden.
Elke database in het sharded cluster heeft een primaire shard (de primary) die alle niet-sharded collecties voor die database bevat. De primaire shard is niet gerelateerd aan de primaire shard binnen een replicaset.
Om de primaire shard voor een database te wijzigen, kun je het commando movePrimary gebruiken. Het migratieproces van de primaire shard kan een behoorlijke tijd in beslag nemen.
Gedurende die tijd wil je geen interactie hebben met de collecties die aan de database zijn gekoppeld totdat het migratieproces is voltooid. Dit proces kan namelijk de algehele werking van het cluster beïnvloeden, afhankelijk van de hoeveelheid gegevens die wordt gemigreerd.
Je kunt de methode sh.status() in mongosh gebruiken om het clusteroverzicht te bekijken. Deze methode geeft de primaire shard voor de database terug, samen met de verdeling van de chunk over de shards.
2. Config servers
Het inzetten van config servers voor sharded clusters als replicasets zou de consistentie over de config server verbeteren. Dit komt omdat MongoDB gebruik kan maken van de standaard replicaset lees- en schrijfprotocollen voor de config gegevens.
Om config servers in te zetten als een replicaset, moet je de WiredTiger storage-engine draaien. WiredTiger gebruikt concurrency control op documentniveau voor zijn schrijfoperaties. Daarom kunnen meerdere clients tegelijkertijd verschillende documenten van een collectie wijzigen.
Config servers slaan de metadata voor een sharded cluster op in de config database. Om toegang te krijgen tot de config database kun je het volgende commando gebruiken in de mongo shell:
use configHier zijn een paar beperkingen om in gedachten te houden:
- Een replicaset configuratie die gebruikt wordt voor config servers moet nul arbiters hebben. Een arbiter doet mee aan een verkiezing voor de primary, maar heeft geen kopie van de dataset en kan niet de primary worden.
- Deze replicaset kan geen delayed members hebben. Delayed members hebben kopieën van de dataset van de replicaset. Maar de dataset van een delayed member bevat een eerdere of vertraagde state van de dataset.
- Je moet indexen bouwen voor de config servers. Simpel gezegd, geen enkele member zou
members[n].buildIndexesmoeten hebben ingesteld opfalse.
Als de config server replicaset zijn primaire member verliest en er geen kan kiezen, worden de metadata van het cluster alleen-lezen. Je zult nog steeds kunnen lezen en schrijven vanaf de shards, maar er zullen geen chunk splits of migratie plaatsvinden totdat de replicaset een primaire member kan kiezen.
3. Query routers
MongoDB’s mongos instances kunnen dienen als query routers, waardoor client applicaties en de sharded clusters gemakkelijk met elkaar kunnen verbinden.
Vanaf MongoDB 4.4 kan mongos hedged reads ondersteunen om latencies te verlagen. Met hedged reads sturen de mongos instances leesbewerkingen naar twee replicaset members voor elke shard die wordt opgevraagd. De resultaten worden dan geretourneerd van de eerste respondent per shard.
Dit is hoe de drie componenten samenwerken binnen een sharded cluster:
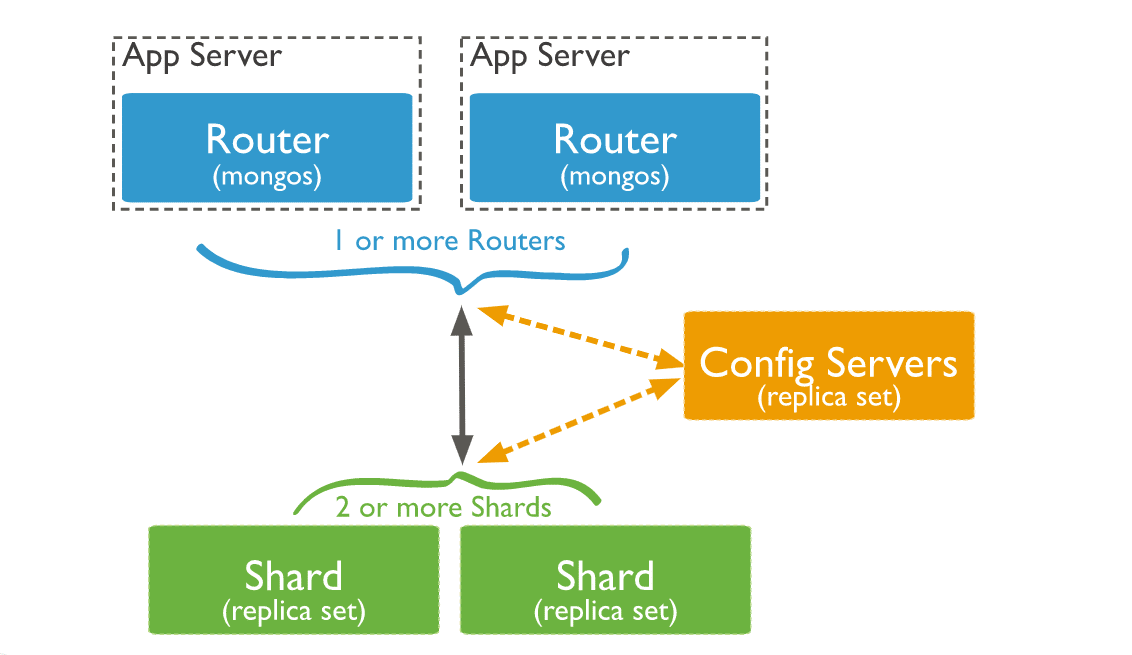
Een Mongo instance stuurt een query naar een cluster door:
- De lijst van shards te controleren die de query moeten ontvangen.
- Een cursor aan te maken op alle beoogde shards.
De mongos zal dan de gegevens van elke gerichte shard samenvoegen en het resultatendocument retourneren. Sommige query-aanpassingen, zoals sorteren, worden op elke shard uitgevoerd voordat mongo’s de resultaten ophalen.
In sommige gevallen, waar de shard key of een shard key prefix deel uitmaakt van de query, zal mongos een vooraf geplande operatie uitvoeren, waarbij queries naar een subklasse van shards in het cluster worden verwezen.
Voor een productiecluster moet je ervoor zorgen dat de gegevens redundant zijn en dat je systemen een hoge beschikbaarheid hebben. Je kunt de volgende configuratie kiezen voor een sharded clusterdeployment voor productie:
- Elke shard deployen als een 3-member replicaset
- Configuratieservers deployen als een 3-member replicaset
- Een of meer mongos routers deployen
Voor een niet-productiecluster kun je een sharded cluster deployen met de volgende componenten:
- Een enkele shard replicaset
- Een replicaset config server
- Eén mongos instance
Hoe werkt MongoDB sharding?
Nu we de verschillende onderdelen van een sharded cluster hebben besproken, is het tijd om in het proces te duiken.
Om de gegevens over meerdere servers te verdelen, gebruik je mongos. Wanneer je verbinding maakt om de query’s naar MongoDB te sturen, zal mongos opzoeken waar de gegevens zich bevinden. Het haalt het dan van de juiste server en voegt alles samen als het over meerdere servers is opgesplitst.
Omdat dit aan de backend wordt geregeld, hoef je aan de kant van de applicatie niets te doen. MongoDB gedraagt zich alsof het een normale query-verbinding is. Je client maakt verbinding met MongoDB en de config server doet de rest.
Zo stel je MongoDB sharding stap voor stap in
Het opzetten van MongoDB sharding is een proces dat verschillende stappen bevat om te zorgen voor een stabiel en efficiënt databasecluster. Hier volgt een gedetailleerde stap-voor-stap instructie over hoe je MongoDB sharding instelt.
Voordat we beginnen, is het belangrijk om te weten dat je minstens drie servers nodig hebt om sharding in MongoDB in te stellen: één voor de config server, één voor de mongos instance en één of meer voor de shards.
1. Een directory aanmaken vanaf de config server
Om te beginnen maken we een directory aan voor de gegevens van de config server. Dit kan worden gedaan door het volgende commando uit te voeren op de eerste server:
mkdir /data/configdb2. MongoDB starten in config modus
Vervolgens starten we MongoDB in configuratiemodus op de eerste server met het volgende commando:
mongod --configsvr --dbpath /data/configdb --port 27019Dit start de config server op port 27019 en slaat zijn gegevens op in de /data/configdb directory. Merk op dat we de flag --configsvr gebruiken om aan te geven dat deze server zal worden gebruikt als config server.
3. Mongos instance starten
De volgende stap is het starten van de mongos instance. Dit proces zal queries routen naar de juiste shards op basis van de sharding key. Gebruik het volgende commando om de mongos instancete starten:
mongos --configdb <config server>:27019Vervang <config server> door het IP-adres of de hostnaam van de machine waarop de config server draait.
4. Verbinding maken met de Mongos instance
Zodra de Mongos instance draait, kunnen we er verbinding mee maken met de MongoDB shell. Dit kan worden gedaan door het volgende commando uit te voeren:
mongo --host <mongos-server> --port 27017In dit commando moet <mongos-server> worden vervangen door de hostname of het IP adres van de server waarop de mongos instance draait. Dit opent de MongoDB shell, waardoor we kunnen communiceren met de mongos instance en servers kunnen toevoegen aan het cluster.
Vervang<mongos-server> door het IP-adres of de hostnaam van de machine waarop de mongos-instantie draait.
5. Servers toevoegen aan clusters
Nu we verbonden zijn met de mongos instance, kunnen we servers aan het cluster toevoegen door het volgende commando uit te voeren:
sh.addShard("<shard-server>:27017")In dit commando moet <shard-server> worden vervangen door de hostnaam of het IP adres van de server waarop de shard draait. Dit commando voegt de shard toe aan het cluster en maakt hem beschikbaar voor gebruik.
Herhaal deze stap voor elke shard die je aan het cluster wilt toevoegen.
6. Sharding inschakelen voor database
Tot slot schakelen we sharding in voor een database door het volgende commando uit te voeren:
sh.enableSharding("<database>")In dit commando moet <database> worden vervangen door de naam van de database die je wilt sharden. Dit schakelt sharding in voor de opgegeven database, waardoor je de gegevens kunt verdelen over meerdere shards.
En dat is het! Na deze stappen zou je nu een volledig functioneel MongoDB sharded cluster moeten hebben, klaar om horizontaal te schalen en hoge verkeersbelastingen aan te kunnen.
Best practices voor MongoDB sharding
Hoewel we ons sharded cluster hebben opgezet, is het regelmatig monitoren en onderhouden van het cluster essentieel voor optimale prestaties. Enkele best practices voor MongoDB sharding zijn:
1. Bepaal de juiste shard key
De shard key is een kritieke factor in MongoDB sharding die bepaalt hoe gegevens worden verdeeld over shards. Het is belangrijk om een shard key te kiezen die gegevens gelijkmatig verdeelt over de shards en die de meest voorkomende queries ondersteunt. Je moet voorkomen dat je een shard key kiest die hotspots veroorzaakt, of een ongelijkmatige verdeling van gegevens, omdat dit kan leiden tot prestatieproblemen.
Om de juiste shard key te kiezen, moet je je gegevens en de typen queries die je gaat uitvoeren analyseren en een key kiezen die aan die eisen voldoet.
2. Plan voor groei van data
Plan bij het opzetten van je sharded cluster voor toekomstige groei door te beginnen met voldoende shards om je huidige workload aan te kunnen en voeg er meer toe als dat nodig is. Zorg ervoor dat je hardware en netwerkinfrastructuur het aantal shards en de hoeveelheid gegevens die je in de toekomst verwacht te hebben, kunnen ondersteunen.
3. Gebruik dedicated hardware voor shards
Gebruik dedicated hardware voor elke shard voor optimale prestaties en betrouwbaarheid. Elke shard moet zijn eigen server of virtuele machine hebben, zodat het alle resources kan gebruiken zonder enige interferentie.
Het gebruik van gedeelde hardware kan leiden tot resource-conflicten en prestatievermindering, met gevolgen voor de betrouwbaarheid van het hele systeem.
4. Gebruik replicasets voor shard servers
Het gebruik van replicasets voor shard servers zorgt voor hoge beschikbaarheid en fouttolerantie voor je MongoDB sharded cluster. Elke replicaset moet drie of meer members hebben en elke member moet op een aparte fysieke machine staan. Deze opzet zorgt ervoor dat je sharded cluster het falen van een enkele server of replicaset kan overleven.
5. Monitor de prestaties van shards
Het monitoren van de prestaties van je shards is cruciaal voor het identificeren van problemen voordat het grote problemen worden. Je moet de CPU, het geheugen, de schijf-I/O en de netwerk-I/O voor elke shard server in de gaten houden om er zeker van te zijn dat de shard de werklast aankan.
Je kunt de ingebouwde monitoring tools van MongoDB gebruiken, zoals mongostat en mongotop, of externe monitoringtools, zoals Datadog, Dynatrace en Zabbix, om de prestaties van shards bij te houden.
6. Plan voor noodherstel
Plannen voor noodherstel is essentieel voor het handhaven van de betrouwbaarheid van je MongoDB sharded cluster. Je moet een noodherstelplan hebben dat regelmatige back-ups, het testen van back-ups om er zeker van te zijn dat ze geldig zijn en een plan voor het herstellen van back-ups in geval van storing omvat.
7. Gebruik hashed-based sharding wanneer nodig
Wanneer applicaties op bereik gebaseerde queries uitvoeren, is sharding op basis van hashed gunstig omdat de bewerkingen beperkt kunnen worden tot minder shards, meestal een enkele shard. Je moet je gegevens en de query patronen begrijpen om dit te kunnen implementeren.
Hashed sharding zorgt voor een uniforme verdeling van reads en writes. Het biedt echter geen efficiënte range-based bewerkingen.
Wat zijn de meest voorkomende fouten die je moet vermijden bij het sharden van je MongoDB database?
MongoDB sharding is een krachtige techniek die je kan helpen je database horizontaal te schalen en gegevens te verdelen over meerdere servers. Er zijn echter een aantal veelgemaakte fouten die je moet vermijden bij het sharden van je MongoDB database. Hieronder staan enkele van de meest voorkomende fouten en hoe je ze kunt vermijden.
1. De verkeerde sharding key kiezen
Een van de meest cruciale beslissingen die je maakt bij het sharden van je MongoDB database is het kiezen van de sharding key. De sharding key bepaalt hoe gegevens worden verdeeld over de shards en het kiezen van de verkeerde key kan resulteren in een ongelijke verdeling van data, hotspots en slechte prestaties.
Een veelgemaakte fout is het kiezen van een shard key waarde die alleen toeneemt voor nieuwe documenten bij gebruik van range-based sharding in tegenstelling tot hashed sharding. Bijvoorbeeld een tijdstempel (natuurlijk) of iets met een tijdcomponent als belangrijkste component, zoals ObjectID (de eerste vier bytes zijn een tijdstempel).
Als je een shard key selecteert, zullen alle inserts naar de chunk met de grootste range gaan. Zelfs als je nieuwe shards blijft toevoegen, zal je maximale schrijfcapaciteit nooit toenemen.
Als je van plan bent om te schalen voor schrijfcapaciteit, probeer dan een hash-gebaseerde shard key te gebruiken waarmee je hetzelfde veld kunt gebruiken en toch een goede schrijfschaalbaarheid hebt.
2. De waarde van de shard key proberen te veranderen
Shard keys zijn onveranderlijk voor een bestaand document, wat betekent dat je de key niet kunt veranderen. Je kunt bepaalde updates doen vóór het sharden, maar niet erna. Proberen om de shard key voor een bestaand document te wijzigen zal mislukken met de volgende foutmelding:
cannot modify shard key's value fieldid for collection: collectionnameJe kunt het document verwijderen en opnieuw invoegen om de shard key te vernieuwen in plaats van te proberen deze te wijzigen.
3. De cluster niet monitoren
Sharding introduceert extra complexiteit in de databaseomgeving, waardoor het essentieel is om het cluster goed te bewaken. Het niet monitoren van het cluster kan leiden tot prestatieproblemen, gegevensverlies en andere problemen.
Om deze fout te voorkomen moet je monitoring tools instellen om belangrijke statistieken zoals CPU-gebruik, geheugengebruik, schijfruimte en netwerkverkeer bij te houden. Je moet ook waarschuwingen instellen wanneer bepaalde drempels worden overschreden.
4. Te lang wachten om een nieuwe Shard toe te voegen (overbelast)
Een veelgemaakte fout bij het sharden van je MongoDB database is te lang wachten met het toevoegen van een nieuwe shard. Wanneer een shard overbelast raakt met gegevens of queries, kan dit leiden tot prestatieproblemen en het hele cluster vertragen.
Stel dat je een denkbeeldig cluster hebt dat bestaat uit 2 shards, met 20000 chunks (5000 worden beschouwd als “actief”), en we moeten een 3e shard toevoegen. Deze 3e shard zal uiteindelijk een derde van de actieve chunks (en totale chunks) opslaan.
De uitdaging is om uit te vinden wanneer de shard geen overhead meer toevoegt en een aanwinst wordt. We moeten de belasting berekenen die het systeem zou veroorzaken bij het migreren van de actieve chunks naar de nieuwe shard en wanneer deze verwaarloosbaar zou zijn ten opzichte van de totale systeemwinst.
In de meeste scenario’s is het relatief eenvoudig voor te stellen dat deze reeks migraties nog langer duurt op een overbelaste set shards, en dat het veel langer duurt voordat onze nieuw toegevoegde shard de drempel overschrijdt en een netto aanwinst wordt. Daarom is het het beste om proactief te zijn en capaciteit toe te voegen voordat het nodig is.
Mogelijke strategieën zijn het regelmatig monitoren van het cluster en proactief nieuwe shards toevoegen op tijden met weinig verkeer, zodat er minder concurrentie is voor resources. Het is aan te raden om gerichte “hot” chunks (die meer bezocht worden dan andere) handmatig te balanceren om de activiteit sneller naar de nieuwe shard te verplaatsen.
5. Config servers niet voldoende uitrusten
Als config servers niet voldoende uitgerust zijn, kan dat leiden tot prestatieproblemen en instabiliteit. Dit kan optreden door onvoldoende toewijzing van resources zoals CPU, geheugen of opslag.
Dit kan resulteren in trage queryprestaties, timeouts en zelfs crashes. Om dit te voorkomen is het toewijzen van voldoende resources aan de config servers essentieel, vooral in grotere clusters. Het regelmatig monitoren van het resourcegebruik van de config servers kan helpen om problemen met “under-provisioning” te identificeren.
Een andere manier om dit te voorkomen is om dedicated hardware te gebruiken voor de config servers, in plaats van resources te delen met andere clustercomponenten. Dit kan ervoor zorgen dat de configuratieservers voldoende bronnen hebben om hun werklast aan te kunnen.
6. Falen in het maken van backups en herstellen van gegevens
Back-ups zijn essentieel om ervoor te zorgen dat gegevens niet verloren gaan bij een storing. Gegevensverlies kan verschillende oorzaken hebben, waaronder hardwarefouten, menselijke fouten en kwaadaardige aanvallen.
Als je nalaat om een back-up te maken en gegevens te herstellen, kan dat leiden tot gegevensverlies en downtime. Om deze fout te voorkomen, moet je een back-up- en herstelstrategie opstellen die regelmatige back-ups, het testen van back-ups en het herstellen van gegevens naar een testomgeving omvat.
7. Niet testen van het sharded cluster
Voordat je je sharded cluster in productie neemt, moet je het grondig testen om er zeker van te zijn dat het de verwachte belasting en queries aankan. Het niet testen van het sharded cluster kan leiden tot slechte prestaties en crashes.
MongoDB sharding vs. geclusterde indexen: Wat is effectiever voor grote datasets?
Zowel MongoDB sharding als geclusterde indexen zijn effectieve strategieën voor het verwerken van grote datasets. Maar ze dienen verschillende doelen. Het kiezen van de juiste aanpak hangt af van de specifieke eisen van je applicatie.
Sharding is een horizontale schaaltechniek die gegevens over veel nodes verdeelt, waardoor het een effectieve oplossing is voor het verwerken van grote datasets met hoge schrijfsnelheden. Het is transparant voor applicaties, waardoor ze kunnen communiceren met MongoDB alsof het een enkele server is.
Aan de andere kant verbeteren geclusterde indexen de prestaties van query’s die gegevens ophalen uit grote datasets doordat MongoDB de gegevens efficiënter kan vinden wanneer een query overeenkomt met het geïndexeerde veld.
Dus, welke is effectiever voor grotere datasets? Het antwoord hangt af van de specifieke gebruikssituatie en vereisten van de workload.
Als de applicatie een hoge schrijf- en query-doorvoer vereist en horizontaal moet worden geschaald, dan is MongoDB sharding waarschijnlijk de betere optie. Geclusterde indexen kunnen echter effectiever zijn als de applicatie een zware leeslast heeft en vaak opgevraagde gegevens in een specifieke volgorde moeten worden georganiseerd.
Zowel sharding als geclusterde indexen zijn krachtige tools voor het beheren van grote datasets in MongoDB. De sleutel is het zorgvuldig evalueren van de eisen van je applicatie en karakteristieken van je workload om de beste aanpak te bepalen voor je specifieke use case.
Samenvatting
Een sharded cluster is een krachtige architectuur die grote hoeveelheden gegevens kan verwerken en horizontaal kan schalen om te voldoen aan de behoeften van groeiende applicaties. Het cluster bestaat uit shards, config servers, mongos processen en client applicaties, en gegevens worden gepartitioneerd op basis van een zorgvuldig gekozen shard key om efficiënte distributie en query’s te garanderen.
Door gebruik te maken van de kracht van sharding kunnen applicaties een hoge beschikbaarheid, betere prestaties en een efficiënt gebruik van hardware-resources bereiken. Het kiezen van de juiste sharding key is cruciaal voor het gelijkmatig verdelen van data.
Wat zijn jouw gedachten over MongoDB en database sharding? Is er een aspect van sharding dat we volgens jou hadden moeten behandelen? Laat het ons weten in de comments!


