
Você já quis comparar preços de vários sites ao mesmo tempo? Ou talvez extrair automaticamente uma coleção de artigos do seu blog favorito? Tudo isso é possível com o web scraping.
Web scraping refere-se ao processo de extração de conteúdo e dados de sites usando software. Por exemplo, a maioria dos serviços de comparação de preços usa raspadores da web para ler informações de preços de várias lojas on-line. Outro exemplo é o Google, que rotineiramente raspa ou “rastreia” a web para indexar sites.
É claro que estes são apenas dois dos muitos casos de uso do web scraping. Neste artigo, explorar o mundo dos raspadores da web, aprender como eles funcionam e ver como alguns sites tentam bloqueá-los.
O que é web scraping?
Web scraping é uma coleção de práticas usadas para extrair automaticamente – ou “extrair” – dados da web.
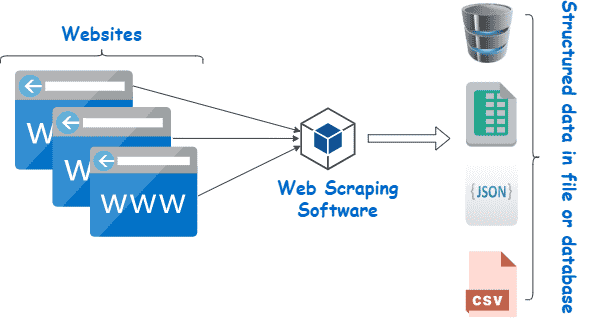
Outros termos para web scraping incluem “raspagem da web”, “raspagem de conteúdo” ou “raspagem de dados” Independentemente do que é chamado, o “web scraping” é uma ferramenta extremamente útil para a coleta de dados on-line. Aplicativos de web scraping incluem pesquisa de mercado, comparações de preços, monitoramento de conteúdo, e muito mais.
Mas o que exatamente a raspagem da web – e como isso é possível? É legal fazer isso? Um site não iria querer evitar que alguém colete seus dados?
As respostas dependem de vários fatores. Antes de abordarmos os métodos e casos de uso, no entanto, vamos dar uma olhada mais de perto sobre web scraping ou raspagem da web e se é ético ou não.
O que podemos “extrair/copiar” da web?
É possível extrair todos os tipos de dados da web. Desde mecanismos de pesquisa e feeds RSS até informações governamentais, a maioria dos sites torna seus dados publicamente disponíveis para raspadores (scrapers), rastreadores (crawlers) e outras formas de coleta automatizada de dados.
Aqui estão alguns exemplos comuns.
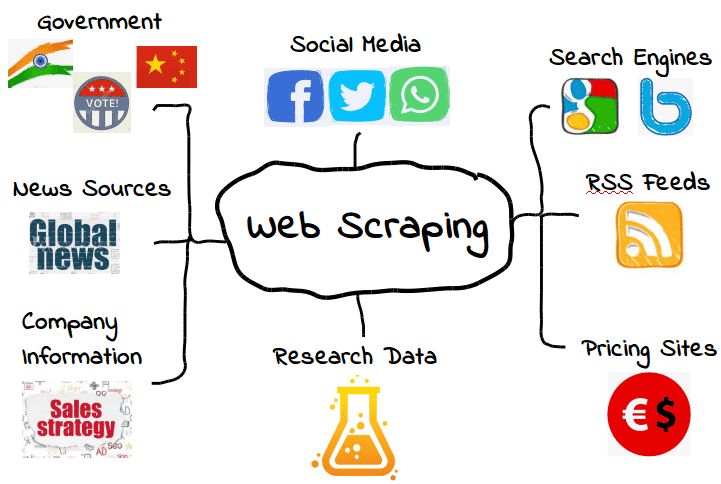
No entanto, isso não significa que esses dados estejam sempre disponíveis. Dependendo do site, você pode precisar empregar algumas ferramentas e truques para obter exatamente o que você precisa – assumindo que os dados estejam acessíveis em primeiro lugar. Por exemplo, muitos web scraping não conseguem extrair dados significativos do conteúdo visual.
Nos casos mais simples, web scraping pode ser feita através de uma API de um site ou interface de programação de aplicativos. Quando um site disponibiliza sua API, os desenvolvedores web podem usá-la para extrair automaticamente dados e outras informações úteis em um formato conveniente. É quase como se o provedor do site estivesse fornecendo a você seu próprio “pipeline” para os dados deles. Fale sobre hospitalidade!
É claro que nem sempre é assim – e muitos sites que você quer extrair não terão uma API que você possa usar. Além disso, mesmo os sites que têm uma API nem sempre fornecem dados no formato correto.
Como resultado, o web scraping é necessário apenas quando os dados da web que você quer não estão disponíveis na(s) forma(s) que você precisa. Seja porque os formatos que você quer não estão disponíveis, ou o site simplesmente não está fornecendo o escopo completo de dados, o web scraping torna possível obter o que você quer.
Embora isso seja interessante, surge uma questão importante: se alguns dados na internet são limitados, seria legal coletá-los? Como vamos discutir em breve, essa questão pode ser um pouco complexa e não tão clara.
O Web Scraping é Legal?
Para algumas pessoas, a ideia de fazer web scraping pode parecer quase como roubo. Afinal, quem é você para simplesmente “pegar” os dados de outra pessoa?
Felizmente, não há nada inerentemente ilegal sobre o web scraping. Quando um site publica dados, eles geralmente estão disponíveis para o público e, como resultado, livres para serem coletados.
Por exemplo, já que a Amazon disponibiliza os preços dos produtos ao público, é perfeitamente legal fazer o scraping desses dados de preços. Muitos aplicativos populares de compras e extensões de navegador usam o web scraping para esse propósito exato, para que os usuários saibam que estão obtendo o preço correto.
No entanto, nem todos os dados da web são feitos para o público, o que significa que nem todos os dados da web são legais para coletar. Quando se trata de dados pessoais e propriedade intelectual, o web scraping pode rapidamente se transformar em web scraping mal-intencionado, resultando em penalidades como um aviso de retirada do DMCA.
O que é Web Scraping mal-intencionado?
O web scraping mal-intencionado é a coleta de dados que o editor não pretendia ou consentiu em compartilhar. Embora esses dados sejam geralmente pessoais ou propriedade intelectual, o scraping mal-intencionado pode se aplicar a qualquer coisa que não seja destinada ao público.
Como você pode imaginar, essa definição tem uma área cinzenta. Enquanto muitos tipos de dados pessoais são protegidos por leis como o Regulamento Geral de Proteção de Dados (GDPR) e a Lei de Privacidade do Consumidor da Califórnia (CCPA), outros não são. Mas isso não significa que não existam situações em que não seja legal fazer o scrape desses dados.

Por exemplo, vamos supor que um provedor de serviços de internet “acidentalmente” torne as informações de seus usuários disponíveis ao público. Isso pode incluir uma lista completa de nomes, e-mails e outras informações que tecnicamente são públicas, mas talvez não destinadas a serem compartilhadas.
Embora também seja tecnicamente legal coletar esses dados, provavelmente não é a melhor ideia. Só porque os dados são públicos, não significa necessariamente que o provedor de serviços de internet consentiu que eles fossem coletados, mesmo que sua falta de supervisão tenha tornado isso público.
Essa “área cinzenta” deu ao web scraping uma reputação um tanto mista. Embora o web scraping seja definitivamente legal, ele pode ser facilmente usado para fins mal-intencionados ou antiéticos. Como resultado, muitos provedores de serviços de internet não apreciam ter seus dados coletados – independentemente de ser legal ou não.
Outro tipo de web scraping mal-intencionado é o “over-scraping”, onde os scrapers enviam muitas solicitações em um determinado período. Muitas solicitações podem sobrecarregar os provedores de serviços de internet, que preferem gastar recursos de servidor com pessoas reais do que com bots de scraping.
Como regra geral, use o web scraping com moderação e apenas quando você tiver certeza absoluta de que os dados são destinados ao uso público. Lembre-se, só porque os dados estão disponíveis publicamente, não significa que seja legal ou ético coletá-los.
Para que serve o Web Scraping?
No seu melhor, o web scraping serve a muitos propósitos úteis em diversas indústrias. Até 2021, quase metade de todo o web scraping é usado para reforçar estratégias de eCommerce.
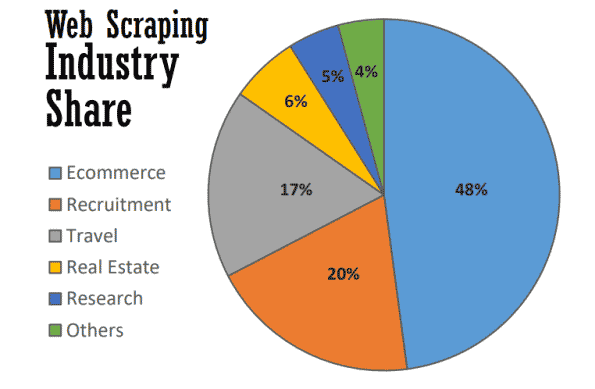
O Web scraping se tornou a base de muitos processos orientados por dados, desde o rastreamento de marcas e fornecimento de comparações de preços atualizadas até a realização de pesquisas de mercado valiosas. Aqui estão algumas das mais comuns.
Pesquisa de mercado
O que seus clientes estão fazendo? E os seus leads? Como está o preço dos seus concorrentes comparado ao seu? Você tem informações para criar uma campanha de marketing de conteúdo ou de marketing inbound bem-sucedida?
Estas são apenas algumas das perguntas que formam as bases da pesquisa de mercado – e as mesmas que podem ser respondidas com o web scraping. Como muitos destes dados estão disponíveis publicamente, a “web scraping” se tornou uma ferramenta inestimável para as equipes de marketing que procuram manter um olho em seu mercado sem ter que realizar pesquisas manuais demoradas.
Automação de negócios
Muitos dos benefícios do “web scraping” para pesquisa de mercado também se aplicam à automação de negócios.
Em tarefas de automação de negócios que exigem a coleta e análise de grandes quantidades de dados, o web scraping pode ser inestimável – especialmente se a realização da tarefa seria de outra forma onerosa.
Por exemplo, vamos dizer que você precisa reunir dados de dez sites diferentes. Mesmo que você esteja coletando o mesmo tipo de dados de cada um, cada site pode requerer um método de extração diferente. Ao invés de passar manualmente por diferentes processos internos em cada site, você pode usar um scraper da web para fazer isso automaticamente.
Geração de leads
Como se a pesquisa de mercado e a automação de negócios não fossem suficientes, o web scraping também pode gerar listas de leads valiosos com pouco esforço.
Embora você precise definir seus alvos com alguma precisão, você pode usar o web scraping para gerar dados de usuário suficientes para criar listas de leads estruturadas. Os resultados podem variar, é claro, mas é mais conveniente (e mais promissor) do que construir listas de leads por conta própria.
Monitoramento de preços
A extração de preços – também conhecida como scraping de preços – é um dos aplicativos mais comuns do web scraping.
Aqui está um exemplo do popular aplicativo de rastreamento de preços da Amazon Camelcamelcamel. O aplicativo regularmente faz scraping dos preços dos produtos e, em seguida, compara-os em um gráfico ao longo do tempo.
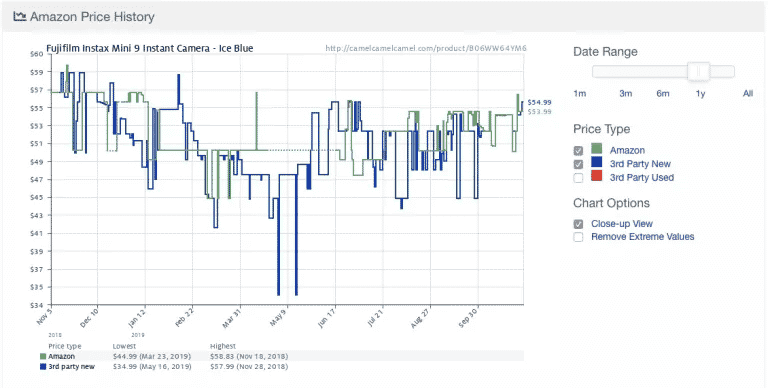
Os preços podem flutuar drasticamente, até mesmo diariamente (observe a queda repentina nos preços por volta de 9 de maio!). Com acesso às tendências históricas de preços, os usuários podem verificar se o preço que estão pagando é ideal. Neste exemplo, o usuário pode optar por esperar uma semana ou mais na esperança de economizar $10.
Apesar de sua utilidade, o scraping de preços vem com alguma controvérsia. Como muitas pessoas querem atualizações de preços em tempo real, alguns aplicativos de monitoramento de preços rapidamente se tornam mal-intencionados ao sobrecarregar certos sites com solicitações ao servidor.
Como resultado, muitos sites de comércio eletrônico começaram a tomar medidas extras para bloquear totalmente os scrapers da web, o que abordaremos na próxima seção.
Notícias e conteúdo
Não há nada mais valioso do que se manter informado. Desde o monitoramento de reputações até o rastreamento de tendências do setor, o web scraping é uma ferramenta valiosa para se manter informado.
Enquanto alguns sites de notícias e blogs já fornecem feeds RSS e outras interfaces fáceis, eles nem sempre são a norma – nem são tão comuns como costumavam ser. Como resultado, a agregação das notícias e conteúdo exato que você precisa muitas vezes requer alguma forma de web scraping.
Monitoramento da marca
Enquanto você está fazendo o scraping de notícias, por que não verificar sua marca? Com marcas que recebem muita cobertura de notícias, o web scraping é uma ferramenta inestimável para se manter atualizado sem ter que percorrer inúmeros artigos e sites de notícias.
O web scraping também é útil para verificar o preço mínimo disponível (MAP) de um produto ou serviço de uma marca. Embora isso seja tecnicamente uma forma de scraping de preços, é um insight chave que pode ajudar as marcas a determinar se seus preços estão alinhados com as expectativas dos clientes.
Imóveis
Se você já procurou um apartamento ou comprou uma casa, sabe o quanto há para analisar. Com milhares de listas espalhadas por vários sites de imóveis, pode ser difícil encontrar exatamente o que você está procurando.
Muitos sites utilizam o web scraping para agregar listas de imóveis em um único banco de dados para tornar o processo mais fácil. Exemplos populares incluem Zillow e Trulia, embora haja muitos outros que seguem um modelo similar.
No entanto, a agregação de listagens não é a única utilidade do web scraping no setor imobiliário. Por exemplo, corretores imobiliários podem usar aplicativos de scraping para acompanhar os valores médios de aluguel e venda, tipos de propriedades sendo vendidas e outras tendências valiosas.
Como funciona o Web Scraping?
Web scraping pode parecer complicado, mas na verdade é muito simples.
Embora os métodos e ferramentas possam variar, tudo o que você precisa fazer é encontrar uma maneira de (1) navegar automaticamente no(s) site(s) de destino e (2) extrair os dados uma vez que estiver lá. Geralmente, essas etapas são realizadas com o uso de scrapers e crawlers.
Scrapers e Crawlers
Em princípio, o web scraping funciona quase da mesma forma que um cavalo e um arado.

Assim como o cavalo guia o arado, o arado revira e fragmenta a terra, ajudando a abrir caminho para novas sementes enquanto reintegra plantas daninhas indesejadas e resíduos de culturas ao solo.
Exceto pelo cavalo, o web scraping não é muito diferente. Aqui, um crawler desempenha o papel do cavalo, guiando o scraper — efetivamente nosso arado — por nossos campos digitais.
Aqui está o que ambos fazem.
- Crawlers (às vezes conhecidos como spiders) são programas básicos que navegam na web enquanto pesquisam e indexam conteúdo. Enquanto os crawlers guiam os scrapers, eles não são usados exclusivamente para este propósito. Por exemplo, mecanismos de pesquisa como o Google usam crawlers para atualizar índices e rankings de sites. Os rastreadores estão normalmente disponíveis como ferramentas pré-construídas que permitem que você especifique um determinado site ou termo de pesquisa.
- Scrapers fazem o trabalho sujo de extrair rapidamente informações relevantes de sites. Como os sites são estruturados em HTML, os raspadores usam expressões regulares (regex), XPath, seletores CSS e outros localizadores para rapidamente encontrar e extrair determinado conteúdo. Por exemplo, você pode dar ao seu raspador da web uma expressão regular especificando um nome de marca ou uma palavra-chave.
Se isso parece um pouco assustador, não se preocupe. A maioria das ferramentas de web scraping inclui crawlers e scrapers integrados, facilitando realizar até mesmo os trabalhos mais complicados.
Processo básico de web scraping
Em seu nível mais básico, o web scraping se resume a apenas alguns passos simples:
- Especifique URLs de sites e páginas que você deseja extrair
- Faça uma solicitação HTML para as URLs (ou seja, “visite” as páginas)
- Use localizadores como expressões regulares para extrair as informações desejadas do HTML
- Salve os dados em um formato estruturado (como CSV ou JSON)
Como veremos na próxima seção, uma grande variedade de ferramentas de web scraping pode ser usada para realizar estas etapas automaticamente.
No entanto, nem sempre é tão simples — especialmente quando se realiza web scraping em larga escala. Um dos maiores desafios do web scraping é manter seu scraper atualizado conforme os sites alteram layouts ou adotam medidas anti-scraping (nem tudo pode ser Evergreen). Embora isso não seja muito difícil se você estiver coletando dados de apenas alguns sites de cada vez, coletar mais pode rapidamente se tornar um incômodo.
Para minimizar o trabalho extra, é importante entender como os sites tentam bloquear os scrapers – algo que vamos aprender na próxima seção.
Ferramentas de web scraping
Muitas funções do web scraping estão prontamente disponíveis na forma de ferramentas de web scraping. Embora muitas ferramentas estejam disponíveis, elas variam muito em qualidade, preço e (infelizmente) ética.
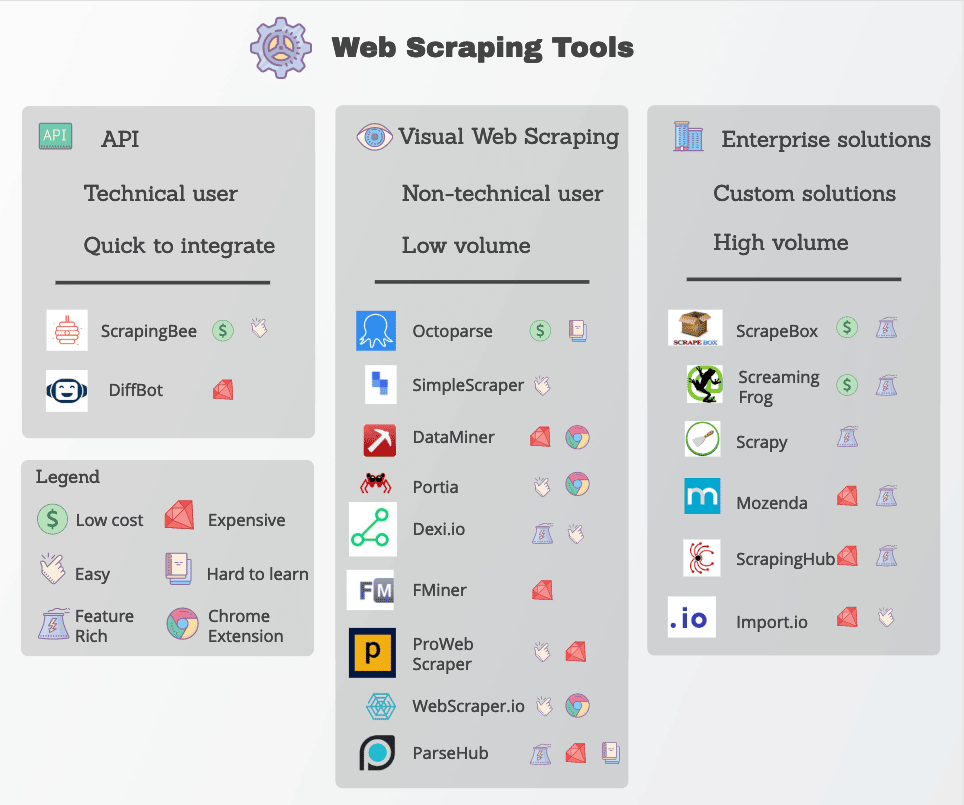
De qualquer forma, um bom web scraper será capaz de extrair de forma confiável os dados de que você precisa sem encontrar muitas medidas anti-scraping. Aqui estão algumas características-chave para procurar.
- Localizadores precisos: Web scrapers usam localizadores como expressões regulares e seletores CSS para extrair dados específicos. A ferramenta que você escolher deve permitir várias opções para especificar o que você está procurando.
- Qualidade dos dados: A maioria dos dados da web não são estruturadas — mesmo que seja apresentada claramente ao olho humano. Trabalhar com dados não estruturados não é apenas confuso, mas raramente entrega bons resultados. Certifique-se de procurar ferramentas de scraping que limpem e classifiquem os dados brutos antes da entrega.
- Entrega de dados: Dependendo de suas ferramentas existentes ou fluxos de trabalho, você provavelmente precisará dos dados raspados em um formato específico, como JSON, XML ou CSV. Em vez de converter os dados brutos você mesmo, procure por ferramentas com opções de entrega de dados nos formatos de que você precisa.
- Manuseio anti-scraping: O web scraping é tão eficaz quanto sua capacidade de contornar bloqueios. Embora você possa precisar empregar ferramentas adicionais como proxies e VPNs para desbloquear sites, muitas ferramentas de web scraping fazem isso fazendo pequenas modificações em seus crawlers.
- Preços transparentes: Embora algumas ferramentas de web scraping sejam gratuitas para usar, opções mais robustas têm um preço. Preste muita atenção ao esquema de preços, especialmente se você pretende escalar e coletar dados de muitos sites.
- Suporte ao cliente: Embora usar uma ferramenta pré-construída seja extremamente conveniente; nem sempre você será capaz de resolver problemas sozinho. Como resultado, certifique-se de que seu provedor também oferece suporte ao cliente confiável e recursos para solução de problemas.
As ferramentas populares de web scraping incluem Octoparse, Import.io, e Parsehub.
Protegendo contra web scraping
Vamos inverter um pouco a situação: imagine que você é o administrador de um site, mas não quer que outras pessoas utilizem todas essas técnicas avançadas para extrair seus dados. O que você pode fazer para garantir sua proteção?
Além dos plugins de segurança, existem alguns métodos eficazes para bloquear web scrapers e crawlers.
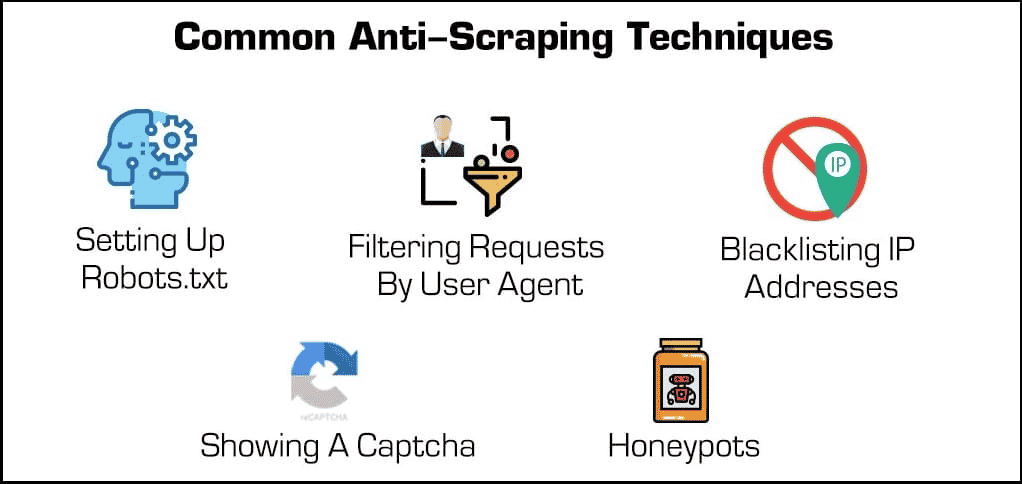
- Bloqueio de endereços IP: Muitos donos de sites acompanham os endereços IP de seus visitantes. Se o dono perceber que um visitante específico está gerando muitas solicitações ao servidor (como no caso de alguns web scrapers ou bots), eles podem bloquear o IP totalmente. No entanto, os scrapers podem superar esses bloqueios alterando seus endereços IP através de um proxy ou VPN.
- Configurando o arquivo robots.txt: Um arquivo robots.txt permite que o dono do site diga aos scrapers, crawlers e outros bots o que eles podem e não podem acessar. Por exemplo, alguns sites usam um arquivo robots.txt para se manterem privados, dizendo aos mecanismos de pesquisa para não indexá-los. Embora a maioria dos mecanismos de pesquisa respeitem esses arquivos, muitas formas maliciosas de web scrapers não o fazem.
- Filtragem de solicitações: Sempre que alguém visita um site, está “solicitando” uma página HTML ao servidor da web. Essas solicitações são frequentemente visíveis para os donos de sites, que podem visualizar certos fatores identificadores, como endereços IP e agentes de usuário, como navegadores da web. Embora já tenhamos abordado o bloqueio de IPs, o dono do site podem filtrar por agente de usuário.
Por exemplo, se um provedor de hospedagem de sites perceber muitas solicitações do mesmo usuário executando uma versão muito desatualizada do Mozilla Firefox, então eles poderiam simplesmente bloquear essa versão e, ao fazer isso, bloquear o bot. Essas capacidades de bloqueio estão disponíveis na maioria dos planos de hospedagem gerenciadas.
- Mostrando um Captcha: Já teve que digitar uma sequência estranha de texto ou clicar em pelo menos seis barcos à vela antes de acessar uma página? Então você encontrou um “Captcha” ou teste público de Turing completamente automatizado para diferenciar computadores e humanos. Embora possam ser simples, eles são incrivelmente eficazes para filtrar web scrapers e outros bots.
- Honeypots: Um “honeypot” é um tipo de armadilha usada para atrair e identificar visitantes indesejados. No caso de web scrapers, um dono do site pode incluir links invisíveis em sua página de internet. Embora os usuários humanos não percebam, os bots visitarão automaticamente esses links enquanto navegam, permitindo que os donos de sites coletem (e bloqueiem) seus endereços IP ou agentes de usuário.
Agora vamos inverter a situação novamente. O que um scraper pode fazer para superar essas proteções?
Embora algumas medidas anti-scraping sejam difíceis de contornar, existem alguns métodos que costumam funcionar. Estes envolvem mudar as características identificadoras do seu scraper de alguma forma.
- Use um proxy ou VPN: Como muitos donos de sites bloqueiam web scrapers com base em seu endereço IP, é frequentemente necessário usar uma variedade de endereços IP para garantir o acesso. Proxies e redes privadas virtuais (VPNs) são ideais para essa tarefa, embora tenham algumas diferenças-chave.
- Visite regularmente seus alvos: A maioria (se não todos) dos web scrapers irá informá-lo quando eles foram bloqueados. Como resultado, é importante verificar regularmente de onde você está coletando dados para ver se você foi bloqueado ou se a formatação do site mudou. Note que uma dessas situações é praticamente garantida em algum momento.
Naturalmente, nenhuma dessas medidas é necessária se você usar o web scraping de forma responsável. Se você decidir implementar o web scraping, lembre-se de fazer isso com moderação e respeitar os donos dos sites!
Resumo
Embora o web scraping seja uma ferramenta poderosa, ele também representa uma grande ameaça para muitos donos de sites. Não importa de que lado do servidor você esteja, todos têm um interesse em garantir que o web scraping seja usado de maneira responsável e, claro, para o bem.
Se você é dono de sites procurando controlar os web scrapers, não procure mais que os planos de hospedagem gerenciada da Kinsta. Você pode limitar bots e proteger dados e recursos valiosos com muitas ferramentas de controle de acesso disponíveis.
Para mais informações, agende uma demonstração gratuita ou entre em contato com um especialista em hospedagem de sites da Kinsta hoje mesmo!


