
För de flesta marknadsförare så krävs det ständiga uppdateringar för att hålla sin webbplats fräsch och förbättra sina SEO-placeringar.
Vissa webbplatser har dock hundratals eller till och med tusentals sidor, vilket gör att det blir en utmaning för de team som driver uppdateringarna till sökmotorerna manuellt. Om innehållet uppdateras så ofta, hur kan teamet då se till att förbättringarna påverkar deras SEO-placeringar?
Det är där som genomsökande bots kommer in i bilden. En bot som kör genomsökningar skrapar din webbplatskarta efter nya uppdateringar och indexerar innehållet i sökmotorerna.
I det här inlägget så kommer vi att ge dig en omfattande lista över genomsökande bots som täcker alla de bots som du behöver känna till. Innan vi djupdyker i ämnet så ska vi dock definiera vad webcrawlers är och visa hur de fungerar.
Kolla in vår videoguide om de vanligaste sökrobotarna
Vad är en webcrawler?
En webcrawler är ett datorprogram som skannar och läser webbsidor automatiskt och systematiskt för att indexera sidorna för sökmotorer. Webcrawlers kallas även för spindlar eller bots.
För att sökmotorerna ska kunna presentera aktuella och relevanta webbsidor för användare som påbörjar en sökning så måste en webcrawler göra en genomsökning. Denna process kan ibland ske automatiskt (beroende på inställningarna för både genomsökaren och din webbplats), eller så kan den initieras direkt.
Många faktorer påverkar dina sidors SEO-ranking, bland annat relevans, bakåtlänkar, hosting med mera. Ingen av dessa spelar dock någon roll om dina sidor inte kryssas och indexeras av sökmotorerna. Det är därför som det är så viktigt att se till att din webbplats tillåter att rätt genomsökning äger rum och tar bort alla hinder i deras väg.
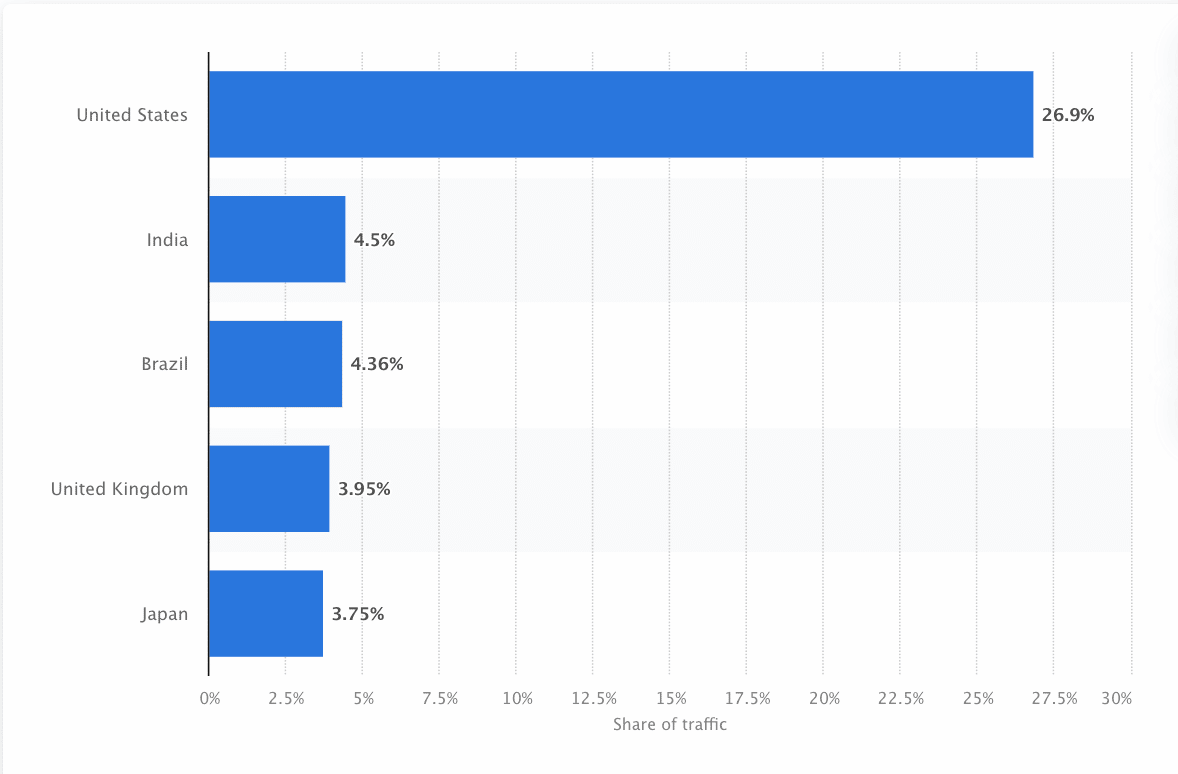
Bots måste ständigt skanna och skrapa webben för att se till att den mest korrekta informationen presenteras. Google är den mest besökta webbplatsen i USA, och cirka 26,9 % av sökningarna kommer från amerikanska användare:
Det finns dock inte en enda webcrawler som jobbar för alla sökmotorer. Varje sökmotor har unika styrkor, så utvecklare och marknadsförare sammanställer ibland en ”botlista” Denna botlista hjälper dem att identifiera olika bots i sin webbplatslogg för att acceptera eller blockera dem.
Marknadsförare måste sammanställa en bot-lista som är full av olika bots och förstå hur de utvärderar sin webbplats (till skillnad från innehållsskrapare som stjäl innehållet) för att se till att de optimerar sina landningssidor korrekt för sökmotorer.
Hur fungerar en webcrawler?
En webcrawler skannar din webbsida automatiskt efter att den har publicerats och indexerar dina data.
Webcrawlers letar efter specifika nyckelord som är kopplade till webbsidan och indexerar informationen för relevanta sökmotorer som Google, Bing med flera.
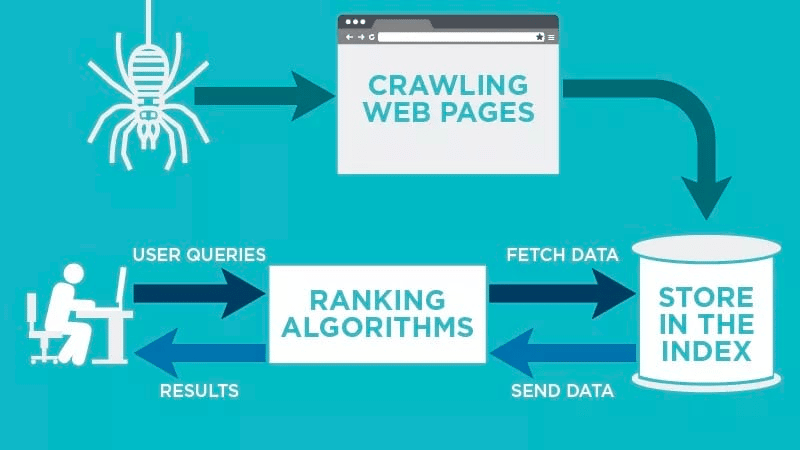
Sökmotorernas algoritmer hämtar dessa uppgifter när en användare skickar in en förfrågan om det relevanta nyckelordet som är kopplat till den.
Bots börjar med kända webbadresser. Dessa är etablerade webbsidor med olika signaler som leder webcrawlers till dessa sidor. Dessa signaler kan vara följande:
- Bakåtlänkar: Antal gånger som en webbplats länkar till den
- Besökare: Hur mycket trafik som går till sidan
- Domänbehörighet: Domänens övergripande kvalitet
De lagrar sedan uppgifterna i sökmotorns index. När användaren ställer en sökfråga så hämtar algoritmen uppgifterna från indexet och de visas på sökmotorns resultatsida. Denna process kan ske inom några millisekunder, vilket är anledningen till att resultaten ofta visas snabbt.
Som webbansvarig så kan du styra vilka bots som genomsöker din webbplats. Det är därför viktigt att ha en lista över bots. Här kommer protokollet robots.txt in i bilden. Det finns på varje webbplats servrar och leder bots till nytt innehåll som behöver indexeras.
Beroende på vad du anger i ditt robots.txt-protokoll på varje webbsida så kan du tala om för en bot att den ska skanna eller undvika att indexera den sidan i framtiden.
Genom att förstå vad en webcrawler letar efter i sin genomsökning så kan du förstå hur du bättre kan positionera ditt innehåll för sökmotorerna.
Sammanställning av din lista över bots: Vilka är de olika typerna av webcrawlers?
När du börjar tänka på att sammanställa din botlista så finns det tre huvudtyper av bots att leta efter. Dessa är följande:
- Interna bots: Dessa är bots som har utformats av ett företags utvecklingsteam för att skanna dess webbplats. De används vanligtvis för granskning och optimering av webbplatsen.
- Kommersiella bots: Dessa är specialbyggda bots som Screaming Frog som företag kan använda för att genomsöka och utvärdera sitt innehåll effektivt.
- Bots med öppen källkod: Dessa är bots som är kostnadsfria att använda och som byggs av en mängd olika utvecklare och hackers runt om i världen.
Det är viktigt att förstå vilka typer av bots som finns så att du vet vilken typ som du behöver utnyttja för dina egna affärsmål.
De 13 vanligaste webcrawlerna att lägga till i din crawlerlista
Det finns inte en enda bot som jobbar för alla sökmotorer.
Det finns istället en mängd olika webcrawlers som utvärderar dina webbsidor och skannar innehållet för alla sökmotorer som finns tillgängliga för användare runt om i världen.
Låt oss titta på några av dagens vanligaste bots.
1. Googlebot
Googlebot är Google’s generiska webcrawler som ansvarar för att söka efter webbplatser som ska visas i Google’s sökmotor.

Även om det tekniskt sett finns två versioner av Googlebot – Googlebot Desktop och Googlebot Smartphone (Mobil) – så anser de flesta experter att Googlebot är en enda bot.
Detta beror på att båda följer samma unika produkt-token (känd som en user agent token) som skrivs i varje webbplats robots.txt. Googlebot’s användaragent är helt enkelt ”Googlebot.”
Googlebot får vanligtvis tillgång till din webbplats med några sekunders mellanrum (om du inte har blockerat den i din webbplats robots.txt). En säkerhetskopia av de skannade sidorna sparas i en enhetlig databas som kallas Google Cache. På så sätt kan du titta på gamla versioner av din webbplats.
Google Search Console är ett annat verktyg som webbansvariga använder för att förstå hur Googlebot kryssar deras webbplats och för att optimera sina sidor för sökningar.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot skapades år 2010 av Microsoft för att skanna och indexera webbadresser för att se till att Bing erbjuder relevanta, uppdaterade sökmotorresultat för plattformens användare.
I likhet med Googlebot så kan utvecklare eller marknadsförare definiera om de godkänner eller nekar agentidentifieraren ”bingbot” att skanna deras webbplats. Detta görs i robots.txt på deras webbplats
De har dessutom möjlighet att skilja mellan bots för mobil först-indexering och bots för datorer eftersom Bingbot nyligen bytte till en ny agenttyp. Detta, ihop med Bing Webmaster Tools, ger webmasters större flexibilitet för att visa hur deras webbplats upptäcks och presenteras i sökresultaten.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) “W.X.Y.Z” will be substituted with the latest Microsoft Edge version Bing is using, for eg. “100.0.4896.127″ |
3. Yandex Bot
Yandex Bot är en bot som jobbar specifikt för den ryska sökmotorn Yandex. Detta är en av de största och mest populära sökmotorerna i Ryssland.

Webmasters kan göra sina webbsidor tillgängliga för Yandex Bot genom sin robots.txt-fil.
De kan dessutom lägga till en Yandex.Metrica-tagg till specifika sidor, indexera om sidor i Yandex Webmaster eller utfärda ett IndexNow-protokoll, en unik rapport som visar på nya, ändrade eller inaktiverade sidor.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple-bot
Apple gav Apple Bot i uppdrag att gå igenom och indexera webbsidor för Apple’s Siri och Spotlight Suggestions.
Apple Bot tar hänsyn till flera faktorer när den bestämmer vilket innehåll som ska lyftas fram i Siri och Spotlight Suggestions. Dessa faktorer är bland annat användarnas engagemang, söktermernas relevans, antalet/kvaliteten på länkarna, platsbaserade signaler och till och med webbsidans utformning.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
DuckDuckBot är en bot för DuckDuckGo, som erbjuder ”sömlöst integritetsskydd i din webbläsare”
Webbansvariga kan använda DuckDuckBots API för att se om DuckDuck Bot har kryssat deras webbplats. När den genomsöker så uppdaterar den DuckDuckBot API-databasen med aktuella IP-adresser och användaragenter.
Detta hjälper webbansvariga att identifiera eventuella bedragare eller skadliga bots som försöker associeras med DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu är den ledande kinesiska sökmotorn och Baidu Spider är webbplatsens enda bot.

Google är förbjudet i Kina, så det är viktigt att aktivera Baidu Spider för att genomsöka din webbplats om du vill nå den kinesiska marknaden.
För att identifiera Baidu Spider som genomsökare av din webbplats, så letar du efter följande användaragenter: baiduspider, baiduspider-image, baiduspider-video, med flera.
Om du inte gör affärer i Kina så kan det vara klokt att blockera Baidu Spider i ditt robots.txt-skript. På så sätt så förhindras Baidu Spider från att kryssa din webbplats och därmed försvinner alla chanser att dina sidor visas på Baidus sökmotorresultatsidor (SERP).
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou är en kinesisk sökmotor som enligt uppgift är den första sökmotorn med 10 miljarder indexerade kinesiska sidor.

Om du gör affärer på den kinesiska marknaden så är detta en annan populär bot som du bör känna till. Sogou Spider följer parametrarna för uteslutningstext och genomsökningsfördröjning.
Precis som med Baidu Spider så bör du, om du inte vill göra affärer på den kinesiska marknaden, inaktivera denna bot för att undvika långsamma laddningstider för webbplatsen.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook External Hit
Facebook External Hit, även känd som Facebook Crawler, går igenom HTML-koden för en app eller webbplats som delas på Facebook.

Detta gör det möjligt för den sociala plattformen att generera en förhandsgranskning för delning av varje länk som läggs upp på plattformen. Titeln, beskrivningen och miniatyrbilden visas tack vare denna bot.
Om genomsökningen inte utförs inom några sekunder så kommer Facebook inte att visa innehållet i det anpassade utdraget som genereras före delning.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead är ett mjukvaruföretag som grundades år 2000 och har sitt huvudkontor i Paris, Frankrike. Företaget tillhandahåller sökplattformar för konsument- och företagskunder.
Exabot är bot för deras centrala sökmotor som är byggd på deras CloudView-produkt.
Precvis som de flesta sökmotorer så tar Exalead hänsyn till både bakåtlänkar och innehållet på webbsidorna när de rankar. Exabot är användaragent för Exaleads bot. Denna bot skapar ett ”huvudindex” som sammanställer de resultat som sökmotorns användare kommer att se.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype är en anpassad sökmotor för din webbplats. Den kombinerar ”den bästa söktekniken, algoritmerna, Det bästa ramverket för innehållsintagning, de bästa klienterna och analysverktygen.”
Om du har en komplex webbplats med många sidor så erbjuder Swiftype ett användbart gränssnitt som katalogiserar och indexerar alla dina sidor åt dig.
Swiftbot är Swiftype’s bot. Men till skillnad från andra bots så genomsöker Swiftbot endast sidor som deras kunder begär.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot är Yahoos bot som genomsöker och indexerar sidor för Yahoo.
Denna genomsökning är viktig för både Yahoo.com och dess partnerwebbplatser som Yahoo News, Yahoo Finance och Yahoo Sports. Utan den så skulle relevanta platsannonser inte visas.
Det indexerade innehållet bidrar till en mer personlig webbupplevelse för användarna med mer relevanta resultat.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot är en Nutch-baserad sökrobot som har utvecklats av Common Crawl. Det är en ideell organisation som fokuserar på att tillhandahålla (helt kostnadsfritt) en kopia av internet till företag, privatpersoner och alla som är intresserade av online-forskning. Boten använder MapReduce, ett programmerings-ramverk som gör att den kan kondensera stora mängder data till värdefulla samlingar av resultat.
Tack vare CCBot så kan människor använda Common Crawl’s data för att förbättra programvara för språköversättning och förutsäga trender. Faktum är att GPT-3 till stor del tränades på data från deras dataset.
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
Det här är en ny och fräsch en. GoogleOther lanserades av Google i april 2023 och fungerar precis som Googlebot.
De delar båda samma infrastruktur och har samma funktioner och begränsningar. Den enda skillnaden är att GoogleOther kommer att användas internt av Googles team för att genomsöka allmänt tillgängligt innehåll från webbplatser.
Anledningen till skapandet av den här nya sökroboten är att avlasta Googlebots genomsökningskapacitet och optimera dess webbgenomsökningsprocesser.
GoogleOther kommer till exempel att användas för genomsökningar av forskning och utveckling (R&D), vilket gör att Googlebot kan fokusera på uppgifter som är direkt relaterade till sökindexering.
| User Agent | GoogleOther |
14. Google-InspectionTool
Människor som tittar på genomsökningen och bot-aktiviteten i sina logg-filer kommer nu att snubbla över något nytt.
En månad efter lanseringen av GoogleOther har vi en ny sökrobot som även den efterliknar Googlebot: Google-InspectionTool.
Den här sökroboten används av söktestverktyg i Search Console, som URL inspection, och andra Google-tjänster, exempelvis Rich Result Test.
| User Agent | Google-InspectionTool Googlebot |
| Full User Agent String | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Google-InspectionTool/1.0) Mozilla/5.0 (compatible; Google-InspectionTool/1.0) |
De 8 kommersiella genomsökarna som SEO-specialister behöver känna till
Nu när du har 13 av marknadens mest populära bots på din genomsökarlista så ska vi titta på några av marknadens vanligaste kommersiella bots och SEO-verktyg för yrkesverksamma.
1. Ahrefs-bot
Ahrefs Bot är en bot som sammanställer och indexerar den 12 biljoner stora länkdatabas som den populära SEO-programvaran Ahrefs erbjuder.
Ahrefs Bot besöker 6 miljarder webbplatser varje dag och anses vara ”den näst mest aktiva genomsökaren” efter Googlebot.
I likhet med andra bots så följer Ahrefs Bot robots.txt-funktionerna och reglerna för tillåtelse/avvisning i varje webbplats kod.
2. Semrush-bot
Semrush Bot gör det möjligt för Semrush, en ledande SEO-programvara, att samla in och indexera webbplatsdata för sina kunders användning på sin plattform.
Uppgifterna används i Semrush’s offentliga sökmotor för bakåtlänkar, verktyget för granskning av webbplatser, verktyget för granskning av bakåtlänkar, verktyget för länkbyggande och skrivassistenten.
Den genomsöker din webbplats genom att sammanställa en lista över webbsidans webbadresser, besöka dem och spara vissa hyperlänkar för framtida besök.
3. Mozs kampanjgenomsökare Rogerbot
Rogerbot är genomsökaren för den ledande SEO-webbplatsen Moz. Denna bot samlar specifikt in innehåll för Moz Pro Kampanjers webbplatsrevisioner.

Rogerbot följer alla regler som anges i robots.txt-filen, så du kan bestämma om du vill blockera/tillåta Rogerbot att skanna din webbplats.
Webbansvariga kommer inte att kunna söka efter en statisk IP-adress för att se vilka sidor som Rogerbot har genomsökt. Detta beror på dess mångfacetterade tillvägagångssätt.
4. Screaming Frog
Screaming Frog är en genomsökare som SEO-proffs använder för att granska sin egen webbplats och identifiera förbättringsområden som kommer att påverka deras sökmotorrankning.

När en genomsökning har påbörjats så kan du granska data i realtid och identifiera trasiga länkar eller förbättringar som behövs i sidtitlar, metadata, bots, duplicerat innehåll med mera.
För att kunna konfigurera genomsökningsparametrarna så måste du köpa en Screaming Frog-licens.
5. Lumar (tidigare Deep Crawl)
Lumar är en ”centraliserad kommandocentral för att upprätthålla din webbplats tekniska hälsa” Med den här plattformen så kan du initiera en genomsökning av din webbplats för att kunna planera din webbplatsarkitektur.
Lumar stoltserar med att vara den ”marknadens snabbaste webbplatsbot” och skryter med att den kan genomsöka upp till 450 webbadresser per sekund.
6. Majestic
Majestic fokuserar främst på att spåra och identifiera bakåtlänkar på webbadresser.

Företaget är stolt över att ha ”en av de mest omfattande källorna till bakåtlänk-data på Internet” och lyfter fram sitt historiska index som har ökat från 5 till 15 års länkar år 2021.
Webbplatsens genomsökare gör all denna data tillgänglig för företagets kunder.
7. cognitiveSEO
cognitiveSEO är en annan viktig SEO-programvara som många yrkesverksamma använder.
Genomsökningsprogrammet cognitiveSEO gör det möjligt för användare att utföra omfattande webbplatsrevisioner som ger information om deras webbplatsarkitektur och övergripande SEO-strategi.
Denna bot går igenom alla sidor och ger ”en helt anpassad uppsättning data” som är unik för slutanvändaren. Denna datamängd kommer även att innehålla rekommendationer till användaren om hur de kan förbättra sin webbplats för andra genomsökare – både för att påverka rankningen och för att blockera bots som är onödiga.
8. Oncrawl
Oncrawl är en ”branschledande SEO-genomsökare och logganalysator” för kunder på enterprise-nivå.
Användare kan ställa in ”genomsökningsprofiler” för att skapa specifika parametrar för genomsökningen. Du kan spara dessa inställningar (inklusive start-webbadress, begränsningar för genomsökning, maximal genomsökningshastighet med mera) för att enkelt köra genomsökningen igen med samma fastställda parametrar.
Behöver jag skydda min webbplats från skadliga bots?
Alla bots är inte bra. Vissa kan ha en negativ inverkan på din sidhastighet, medan andra kan försöka hacka din webbplats eller ha illasinnade avsikter.
Det är därför viktigt att förstå hur man blockerar bots från att komma in på din webbplats.
Genom att upprätta en lista över bots så vet du vilka bots som är bra att hålla utkik efter. Du kan sedan rensa ut de oseriösa och lägga till dem i din blocklista.
Hur man blockerar skadliga bots
Med din botlista i handen så kan du identifiera vilka bots som du vill godkänna och vilka som du behöver blockera.
Det första steget är att gå igenom din lista över genomsöknings-bots och definiera den användaragent och den fullständiga agentsträng som är associerad med varje genomsökare samt dess specifika IP-adress. Detta är viktiga identifieringsfaktorer som är kopplade till varje bot.
Med användaragenten och IP-adressen så kan du matcha dem i dina webbplatsregister genom en DNS-sökning eller en IP-matchning. Om de inte stämmer exakt överens så kan du ha en illasinnad bot som försöker uppträda som den riktiga.
Då kan du blockera bedragaren genom att justera behörigheterna med hjälp av webbplatstaggen robots.txt.
Sammanfattning
Webcrawlers är användbara för sökmotorer och viktiga för marknadsförare att förstå.
Att se till att din webbplats kryssas korrekt av rätt bot är viktigt för att ditt företag ska lyckas. Genom att föra en lista över bots så kan du veta vilka du ska hålla utkik efter när de dyker upp i din webbplatslogg.
När du följer rekommendationerna från kommersiella bots och förbättrar innehållet och hastigheten på din webbplats så gör du det lättare för bots att komma åt din webbplats och indexera rätt information för sökmotorer och konsumenterna som söker efter den.


