
Content-Scraping oder das, was wir gerne als „Content-Diebstahl“ bezeichnen, ist ein Problem, seit es das Internet gibt. Für jeden, der regelmäßig publiziert oder mit Suchmaschinenoptimierung (SEO) arbeitet, kann es sogar regelrecht ärgerlich sein. 😠 Je größer man wird, desto mehr merkt man, wie viele Content-Scraping-Farmen es da draußen gibt. Wir veröffentlichen hier bei Kinsta eine Menge Inhalte, und Content Scraping ist ein Thema, mit dem wir uns regelmäßig beschäftigen. Die Frage ist, solltest du versuchen, dich zu wehren oder sie einfach ignorieren und weitermachen? Heute werden wir uns mit einigen der Vor- und Nachteile beider Seiten befassen.
Was ist Content Scraping?
Content-Scraping ist im Grunde genommen, wenn jemand deine Inhalte nimmt und es auf seiner eigenen Webseite benutzt (entweder manuell oder automatisch mit einem Plugin oder Bot), ohne dir ein Attribut oder einen Credit zu geben. Dies geschieht normalerweise in der Hoffnung, irgendwie Traffic, SEO oder neue Benutzer zu gewinnen. Dies verstößt eigentlich gegen die Urheberrechtsgesetze in den Vereinigten Staaten und einigen anderen Ländern. Google duldet dies ebenfalls nicht und empfiehlt, dass du deinen eigenen individuellen Inhalt erstellen solltest.
Hier sind ein paar Beispiele für gestohlene Inhalte, die Google erwähnt:
- Webseiten, die Inhalte von anderen Webseiten kopieren und neu veröffentlichen, ohne originalen Inhalt oder Wert hinzuzufügen
- Webseiten, die Inhalte von anderen Webseiten kopieren, sie leicht modifizieren (z.B. durch das Ersetzen von Synonymen oder durch automatisierte Techniken), und sie neu veröffentlichen
- Seiten, die Inhalte von anderen Webseiten reproduzieren, ohne eine Art von einzigartiger Organisation oder Nutzen für den Nutzer zu bieten
- Seiten, die dazu dienen, Inhalte wie Videos, Bilder oder andere Medien von anderen Webseiten ohne wesentlichen Mehrwert für den Nutzer einzubinden
Dies ist nicht zu verwechseln mit der Content Syndication, bei der man in der Regel seine eigenen Inhalte neu veröffentlicht, um eine größere Reichweite zu erzielen. Die Syndizierung von Inhalten könnte auch von Dritten durchgeführt werden, aber es gibt einen schmalen Grat zwischen diesem und dem Content-Scraping. Wenn jemand Inhalte syndiziert, sollten immer spezielle Tags wie rel=canonical oder noindex verwendet werden.
Es gibt inzwischen eine Menge WordPress-Plugins von Drittanbietern, mit denen man automatisch RSS-Feeds von Drittanbietern abrufen kann. Und obwohl die Entwickler gute Absichten haben, werden diese leider manchmal missbraucht und zum Content-Scraping verwendet. Einer der Gründe, warum WordPress so beliebt ist, ist die Benutzerfreundlichkeit, aber manchmal kann das auch nach hinten losgehen.
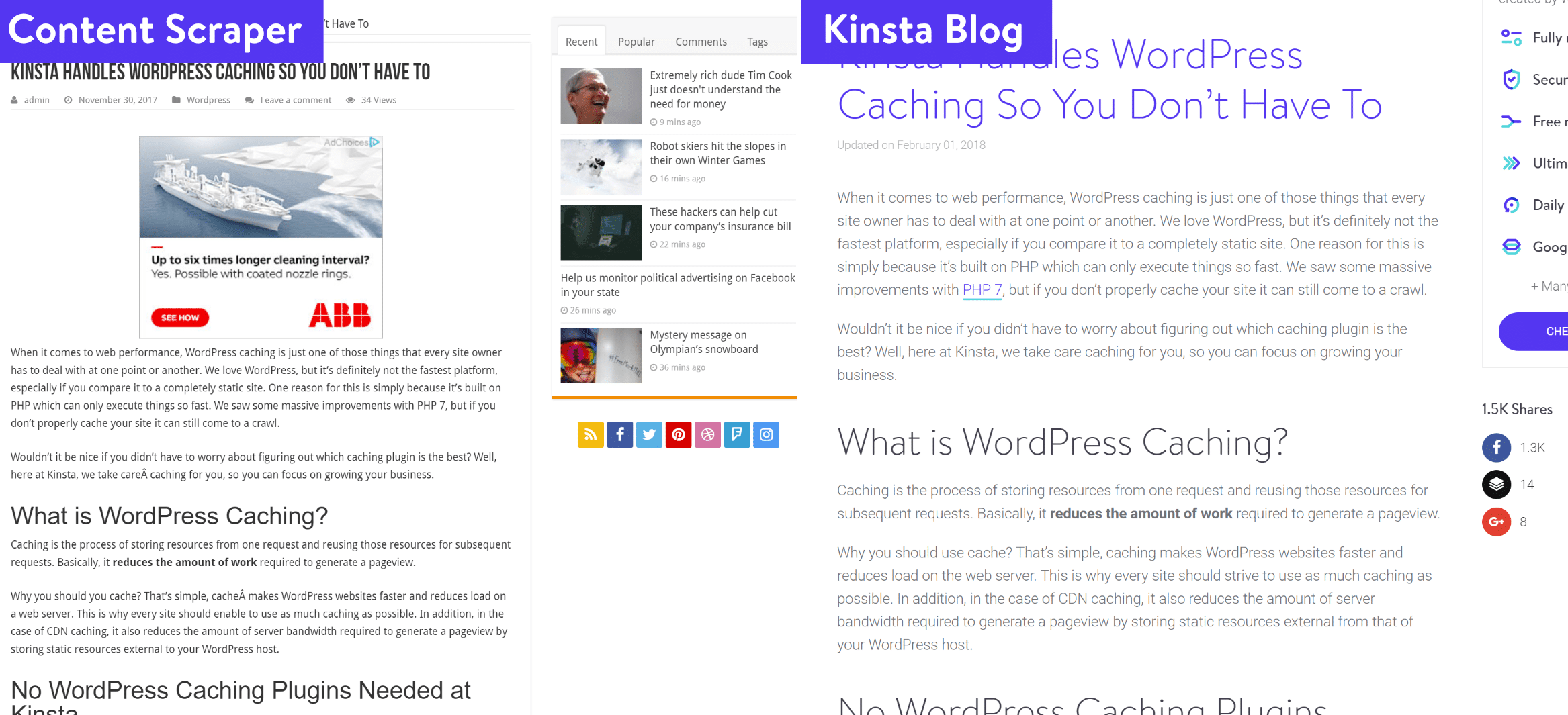
Live-Beispiel einer Content Scraping Farm
Wir nennen sie „Farmen“, wenn ein und derselbe Betreiber Inhalte über Dutzende von Webseiten streut. Diese sind in der Regel leicht zu erkennen, da der Betreiber einer Seite normalerweise das gleiche Theme auf allen Seiten verwendet und sogar nur eine leichte Abweichung zwischen den Domainnamen hat.
In unserem heutigen Beitrag verwenden wir ein Live-Beispiel! Wir schämen uns nicht, diese Art von Webseiten zu nennen, da sie keinen Wert bieten und nur die harte Arbeit der Herausgeber von Inhalten zunichte machen. Hier ist ein Beispiel für eine Content Scraping Farm. Wir haben jeden Link archiviert, für den Fall, dass die Webseiten in Zukunft nicht mehr funktionieren. Du kannst auf jede einzelne Seite klicken und siehst, dass sie alle dasselbe Theme und denselben Gestohlenen-Inhalt verwenden. Normalerweise schnappt sich ein Scraper Inhalte aus vielen verschiedenen Quellen, unser Blog ist einer davon.
- thetechworld.xyz (archivierter Link)
- mytechnewstoday.org (archivierter Link)
- mytechcrunch.com (archivierter Link)
- technewssites.xyz (archivierter Link)
- technewssites.info (archivierter Link)
- thetechworld.info (archivierter Link)
- mytechnewstoday.xyz (archivierter Link)
- futuretechnologynews.info (archivierter Link)
- futuretechnologynews.xyz (archivierter Link)
Wie ihr unten sehen könnt, werden unsere Blog-Posts einfach Wort für Wort übernommen, zusammen mit all unseren Artikeln über alle Domains oben.
Wie man sie findet?
Einer der einfachsten Wege, sie zu finden, ist, ein Tool wie Copyscape oder Ahrefs zu benutzen (wenn sie auch deine internen Links kopieren). Copyscape erlaubt es dir sogar, deine Sitemapdatei zu übermitteln und sich automatisch benachrichtigen zu lassen, wenn es das Web scannt und Inhalte findet.

Du kannst Google auch manuell mit dem „allintitle“-Tag durchsuchen. Gib einfach den Tag zusammen mit dem Titel deines Beitrags ein. Beispiel: allintitle: Kinsta beherrscht das WordPress-Caching, damit du es nicht tun musst

Das Schlüsselwort allintitle veranlasst Google, nur in den Titeln der Beiträge nach diesen Wörtern zu suchen. Der zweite und effektivere Weg ist die Suche nach einem Text in deinem Beitrag, wobei der Suchbegriff in Anführungszeichen gesetzt wird. Durch das Setzen der Anführungszeichen wird Google angewiesen, nach genau demselben Text zu suchen. Es kann sein, dass du bei der Titelsuche falsch-positive Ergebnisse erhältst, da jemand denselben Titel verwenden könnte, aber der zweite Weg ist weitaus effektiver, da es sehr unwahrscheinlich ist, dass jemand genau dieselben Sätze oder Absätze hat.
Beeinflusst Content Diebstahl SEO?
Die nächste Frage, die du wahrscheinlich hast, ist, wie wirkt sich das auf SEO aus? Weil im obigen Beispiel die Content-Scraping-Farm keine rel=canonical-Tags verwendet und keine Credit- oder noindex-Tags vergibt. Das bedeutet, dass der Google-Bot, wenn er es crawlt, denken wird, dass es ihr ursprünglicher Inhalt ist. Das ist nicht fair, was du vielleicht denkst. Du hast recht, das ist es nicht. Wir haben den Inhalt veröffentlicht und dann wird es einfach gecrawlt. Bevor du jedoch in Panik gerätst, ist es wichtig zu verstehen, was wirklich hinter den Kulissen vor sich geht.
Erstens: Auch wenn der Google-Crawler es vielleicht als ihren Inhalt ansieht, sieht der Google-Algorithmus es höchstwahrscheinlich nicht. Google ist nicht dumm und hat viele Regeln und Überprüfungen eingeführt, um sicherzustellen, dass die ursprünglichen Betreiber der Inhalte trotzdem die Anerkennung erhalten. Woher wissen wir das? Nun, sehen wir uns jeden dieser Beiträge aus der SEO-Perspektive an.
Diese Person hat unseren Blogeintrag im November 2017 erstellt, so dass es genug Zeit hatte, ein Ranking zu erstellen, falls es das tun würde. Also rufen wir unser praktisches Ahrefs Tool auf und sehen nach, für welche aktuellen Keywords ihr Beitrag gerankt ist. Und wir können sehen, dass es kein Ranking für irgendwelche Schlüsselwörter gibt. Was den organischen Traffic angeht, profitieren sie also überhaupt nicht von diesem Beitrag.
Wenn wir unseren ursprünglichen Blog-Post in Ahrefs aufrufen, können wir sehen, dass wir für 96 Schlüsselwörter ranken.

Wenn Google sieht, was du vielleicht für doppelten Inhalt hältst, verwendet es eine Menge verschiedener Signale und Datenpunkte, um herauszufinden, wer den Inhalt ursprünglich geschrieben hat und was gerankt werden sollte. Hier sind ein paar Beispiele:
- Daten veröffentlichen (obwohl in diesem Fall der Inhalt am selben Tag gestrichen wurde)
- Domain Autorität und Page Rank. Ja, Google verwendet den Page Rank wahrscheinlich immer noch intern.
- Soziale Signale
- Traffic
- Backlinks
Auch dies sind alles sichere Annahmen, da niemand wirklich weiß, was Google verwendet. Aber der Punkt hier ist, dass du wahrscheinlich nicht den Schlaf verlieren musst, wenn jemand deine Inhalte stiehlt. Trotzdem solltest du vielleicht trotzdem etwas dagegen unternehmen. Es ist auch nicht unmöglich, dass jemand anderes dich mit deinen eigenen Inhalten übertrifft. Wir werden weiter unten darauf eingehen.
Was wir gegen Content Diebstahl tun
Nützliche, einzigartige und teilungswürdige Inhalte zu erstellen ist nicht einfach, es nimmt viel deiner wertvollen Zeit in Anspruch (und kostet oft viel Geld), also solltest du es auf jeden Fall schützen. Aber hier sind einige zusätzliche Gründe, warum du Diebe nicht ignorieren solltest.
- Wenn eine Webseite mit einer erheblichen Menge an Traffic deine Inhalte streicht und sie als Ergänzung zu ihren anderen Inhalten verwendet, könnte es sehr gut sein, dass sie davon profitiert. Das ist definitiv nicht richtig, da du der ursprüngliche Betreiber des Inhalts bist.
- Dinge wie diese können die Daten in deinen Reporting Tools ernsthaft verzerren und dir das Leben erschweren. Diese werden zum Beispiel in Backlink-Berichten in Tools wie Ahrefs oder Majestic auftauchen. Je größer du bist, desto unordentlicher wird es.
- Willst du dich ausschließlich auf Google verlassen, um herauszufinden, ob deren oder deine Inhalte die Originalinhalte sind? Auch wenn sie diesbezüglich ziemlich schlau sind, wir sicher nicht. Und obwohl ihr Beitrag für kein Keyword in den Suchmaschinen platziert ist, wird er von Google indiziert (siehe unten).

Kontaktiere den Betreiber der Webseite und reiche eine DMCA-Beschwerde ein
Um sicherzugehen, dass wir Credits bekommen, wo Credits zustehen, kontaktieren wir normalerweise zuerst den Betreiber der Webseite und bitten um Entfernung. Wir empfehlen, ein paar E-Mail-Templates zu erstellen, die du wiederverwenden kannst, um diesen Prozess zu beschleunigen und deine Zeit nicht zu verschwenden. Wenn wir nach ein paar Versuchen nichts von ihnen hören, gehen wir einen Schritt weiter und reichen eine DMCA-Beschwerde ein.
DMCA-Beschwerden können ein wenig knifflig sein, da du die IP der Webseite nachschlagen musst, den Host finden musst, etc. Aber keine Sorge, wir haben alle Schritte dokumentiert, wie man ganz einfach eine DMCA-Beschwerde einreicht und auch den Betreiber ausfindig macht. Du kannst auch direkt bei Google einen Antrag auf legale Entfernung stellen.
Was das obige Beispiel der Live-Fallstudie betrifft, sieht es so aus, als wäre es an der Zeit, den nächsten Schritt zu tun, da wir den Betreiber der Webseite nicht erreichen konnten. 😩
Update Verleugnungsdatei
Um sicherzustellen, dass diese unsere Webseite in keiner Weise beeinflussen (unabhängig davon, was mit der DMCA-Beschwerde passiert), fügen wir auch diese ganzen Domains in unsere Verleugnungsdatei ein. Dies sagt Google, dass wir nichts mit ihnen zu tun haben wollen, und dass wir nicht versuchen, die SERPs in irgendeiner Weise zu manipulieren.
Wenn du dies für eine qualitativ hochwertigere Webseite tust, kannst du statt der gesamten Domain auch nur die URL zur Verleugnung einreichen. Obwohl wir typischerweise nicht sehen, dass qualitativ hochwertige Webseiten den Inhalt stehlen.
Schritt 1
In Ahrefs wählen wir die fragliche Domain aus und klicken auf “ Disavow Domains“. Dadurch wird sichergestellt, dass alles, was von dieser inhaltlich gestohlenen Webseite stammt, uns niemals beeinträchtigt.

Das Tolle an Ahrefs, wenn es um diese Art von Problemen geht, ist ihre Option „Hide disavowed links“. Es versteckt dann automatisch die Domains und URLs, damit sie in Zukunft nicht mehr in deinem Hauptbericht erscheinen. Das ist super hilfreich für die Organisation und die Aufrechterhaltung deiner Vernunft, besonders wenn du ausschließlich Ahrefs zur Verwaltung deiner Backlinks verwendest. 👍

Schritt 2
Wie ihr unten seht, haben wir alle Domains aus der Content Scraping Farm zu unserer Verleugnungslinks-Sektion in Ahrefs hinzugefügt. Der nächste Schritt ist, auf „Export“ zu klicken und die Verleugnungsdatei (TXT), die wir einreichen müssen, in der Google Search Console zu erhalten.

Schritt 3
Dann gehst du zu Googles Disavow Tool. Wähle dein Profil in der Google Search Console aus und klicke auf „Links verleugnen“.

Schritt 4
Wähle deine Verleugnungsdatei, die du von Ahrefs exportiert hast, und schicke es ab. Dadurch wird deine bisherige Verleugnungsdatei überschrieben. Wenn du Ahrefs in der Vergangenheit noch nie benutzt hast und bereits eine Verleugnungsdatei existiert, ist es empfehlenswert, die aktuelle herunterzuladen, sie mit deiner neuen zusammenzuführen und sie dann hochzuladen. Von da an kannst du, wenn du nur Ahrefs benutzt, einfach hochladen und überschreiben.

IPs von Dieben blockieren
Du könntest auch noch einen Schritt weiter gehen und die IPs der Diebe blockieren. Sobald du ungewöhnlichen Traffic festgestellt hast (was manchmal schwierig sein kann), könntest du es auf deinem Server mit Hilfe von .htaccess-Dateien oder Nginx-Regeln blockieren. Wenn du ein Kinsta-Client bist, kann unser Support Team auch IPs für dich blockieren. Oder wenn du eine WAF von Drittanbietern wie Sucuri oder Cloudflare verwendest, haben diese ebenfalls Optionen, um IPs zu blockieren.
Zusammenfassung
Content Scraping Farmen haben vielleicht nicht immer Einfluss auf dein SEO, aber sie bringen definitiv keinen Mehrwert für die Nutzer. Wir empfehlen dir dringend, dir ein paar Minuten Zeit zu nehmen, um sie abzubauen. Wir haben eine ganze Trello-Karte, die den „Takedown“-Anfragen gewidmet ist. Dies hilft dabei, das Web zu einem besseren Ort für alle zu machen und stellt sicher, dass dein einzigartiger Inhalt nur auf deiner Webseite gesehen und eingestuft wird.
Was denkst du über Content Diebstahl? Versucht ihr, sie zu bekämpfen oder ignoriert ihr sie einfach? Wir würden uns freuen, deine Gedanken unten in den Kommentaren zu hören.

Brian hat eine große Leidenschaft für WordPress, verwendet es seit über einem Jahrzehnt und entwickelt sogar einige Premium-Plugins. Brian liebt Blogging, Filme und Wandern. Verbinde dich mit Brian auf Twitter.

