
Persistente Speicherung bedeutet, dass Daten nichtflüchtig gespeichert werden, so dass sie auch dann noch verfügbar sind, wenn ein Gerät oder eine Anwendung ausgeschaltet oder neu gestartet wird. Die Speicherung und der Abruf von Daten ermöglichen es Webanwendungen, Benutzerinformationen und Zustände zu speichern und zuverlässig zu arbeiten.
Bei monolithischen Anwendungen ist der Zugriff auf den Speicher einfach, da Server und Speicher gemeinsam genutzt werden. Bei geografisch verteilten Systemen wird der Zugriff jedoch komplexer, da das Speichersystem für alle Komponenten weltweit verfügbar bleiben muss.
Die Containerisierung verkompliziert das Problem zusätzlich, da Container leichtgewichtig, zustandslos und kurzlebig sind – ungeeignete Eigenschaften für die Speicherung von Daten. Daher muss jede persistente Speicherlösung nahtlos mit Containern zusammenarbeiten können, was die Komplexität noch erhöht.
Die Plattform für containerisiertes Anwendungs-Hosting von Kinsta nutzt persistente Kubernetes-Volumes, um persistenten Speicher mit einem oder mehreren Prozessen einer Anwendung zu verknüpfen. Kinsta-Benutzer können ihre Anforderungen an den persistenten Speicher bei der Erstellung von Anwendungen im MyKinsta Dashboard definieren.
Dieser Artikel wirft einen plattformunabhängigen Blick auf persistenten Speicher, indem er dessen Arten, Architektur und Anwendungsfälle entdeckt. Außerdem bietet er eine praktische Demonstration, die den Unterschied zwischen Volume Storage und persistentem Volume Storage in Docker verdeutlicht.
Arten von persistentem Speicher
Es gibt verschiedene Arten von nichtflüchtigem Speicher, darunter herkömmliche Festplatten (HDDs), Solid-State-Laufwerke (SSDs), Netzwerkspeicher (NAS) und Speichernetzwerke (SANs).
- HDDs sind elektromechanische Datenspeicher, die digitale Daten mit Hilfe von sich drehenden Magnetscheiben speichern und abrufen. Die Festplatten verwenden Magnetköpfe auf einem beweglichen Antriebsarm, die Daten lesen und schreiben.
- SSDs, manchmal auch Halbleiterspeicher, Solid-State-Geräte oder Solid-State-Disks genannt, verwenden integrierte Schaltkreise, um Daten dauerhaft zu speichern. Durch ihren stationären Charakter sind sie schneller und zuverlässiger als HDDs.
- Netzwerkspeicher sind eine Gruppe von HDDs, SSDs oder beidem, die über ein lokales Netzwerk mit einem Dateisystem wie dem New Technology File System (NTFS) oder dem vierten erweiterten Dateisystem (EXT4) verbunden sind.
- SANs sind vernetzte Hochgeschwindigkeits-Speichergeräte auf Blockebene, wie z. B. Bandbibliotheken oder Festplatten-Arrays. Ihre Verbindung erscheint für das Betriebssystem als lokaler Speicher und ist nicht über das lokale Netzwerk (LAN) zugänglich.
Architektur des persistenten Speichers
Es gibt drei Ansätze für persistenten Speicher, jeder mit eigenen Anwendungsfällen und Einschränkungen.
Objektbezogene persistente Architektur
Der Ansatz der objektpersistenten Architektur nutzt das objektrelationale Mapping (ORM), um Daten als Objekte in einer relationalen oder Key-Value-Datenbank zu speichern. Dieser Ansatz ist nützlich, wenn die Daten kein definiertes Schema haben, da das ORM die Speicherung und den Abruf der Daten übernimmt.
Persistente Blockarchitektur
Die Block-Persistent-Architektur verwendet Speichergeräte auf Blockebene, die für die Speicherung großer Dateien nützlich sind. Dieser Ansatz ist bei der Speicherung großer Datenmengen von Vorteil, da du mehrere Blöcke verwenden kannst, um die Speicherkapazität zu erhöhen.
Persistente Filestore-Architektur
Wie der Name schon sagt, wird bei der persistenten Dateispeicherarchitektur ein Dateisystem für die Datenspeicherung verwendet. Eine Methode ist die Verwendung von Datenbankservern, die eine zentrale Speicherung von Daten ermöglichen. Cloud-Hosting-Lösungen wie die von Kinsta verwenden Datenbankserver, die leicht mit Anwendungen verbunden werden können und Persistenz bieten.
Die persistente Architektur eines Dateispeichers ist hilfreich für Anwendungen, bei denen häufig Dateien abgerufen werden müssen, und wenn du eine Schnittstelle für die Verwaltung dieser Dateien brauchst.
Anwendungsfälle für persistenten Speicher
In diesem Abschnitt werden einige Anwendungsfälle für jeden Speichertyp erläutert.
Persistenter Objektspeicher
- Cloud-Speicher: Object Persistent Storage wird häufig in Cloud-Speicherlösungen verwendet, um große Mengen unstrukturierter Daten wie Bilder, Videos und Dokumente zu speichern und abzurufen. Cloud-Anbieter nutzen Objektspeicher, um ihren Kunden skalierbare, hochverfügbare und dauerhafte Speicherdienste anzubieten.
- Big Data-Analysen: Objektspeicher werden in der Big-Data-Analytik eingesetzt, um große Datensätze zu speichern und zu verwalten, die häufig für Datenanalysen, maschinelles Lernen und KI verwendet werden. Objektspeicher ermöglicht einen schnellen und effizienten Datenzugriff und ist damit ein wichtiger Bestandteil von Big-Data-Architekturen.
- Content Delivery Networks: Objektspeicher wird in Content Delivery Networks (CDNs) eingesetzt, um Inhalte wie Bilder, Videos und statische Dateien zu speichern und über ein globales Netzwerk von Servern zu verteilen. Objektspeicher ermöglicht es CDNs, Inhalte in hoher Geschwindigkeit an Nutzer/innen weltweit zu liefern, unabhängig von ihrem Standort.
Persistente Blockspeicher
- High-Performance-Computing (HPC): In HPC-Umgebungen werden große Datenmengen schnell und effizient verarbeitet. Mit Blockspeicher können HPC-Cluster große Datenmengen speichern und abrufen, z. B. bei wissenschaftlichen Simulationen, Wettermodellen und Finanzanalysen. Blockspeicher werden für HPC häufig bevorzugt, weil sie einen leistungsstarken Zugriff auf Daten mit geringer Latenz ermöglichen und parallele Ein-/Ausgabeoperationen (E/A) erlauben, was die Verarbeitungszeiten erheblich verbessern kann.
- Videobearbeitung: Videobearbeitungsanwendungen erfordern einen leistungsstarken Zugriff auf große Videodateien mit geringer Latenzzeit. Außerdem müssen sie eine große Anzahl von E/A-Vorgängen pro Sekunde und eine geringe Latenzzeit bewältigen, um Videodateien in Echtzeit zu rendern und zu bearbeiten. Blockspeicher bieten diese Fähigkeiten und sind damit die ideale Lösung für Videobearbeitungs-Workflows.
- Spiele: Spieleanwendungen erfordern ebenfalls eine hohe Leistung und niedrige Latenzzeiten für den Zugriff auf Spielinhalte und Spielerdaten. Blockspeicher speichert und ruft große Datenmengen schnell ab und sorgt dafür, dass Spielumgebungen schnell geladen werden und während des Spiels reaktionsschnell bleiben.
Filestore Persistenter Speicher
- Medien und Unterhaltung: Anwendungen für Videobearbeitung, Animation und Rendering nutzen häufig persistenten Speicher. Diese Anwendungen erfordern einen leistungsstarken und latenzarmen Zugriff auf große Mediendateien wie Video, Audio und Bilder. Filestore bietet ein gemeinsames Dateisystem, auf das mehrere Clients zugreifen können, und ist damit eine ideale Speicherlösung für diese Anwendungen.
- Web Content Management: Web-Content-Management-Systeme (CMS) nutzen Filestore als dauerhaften Speicher in gemeinsamen Dateisystemen, um Website-Inhalte wie Texte, Bilder und Multimedia-Dateien zu speichern und zu verwalten. Filestore bietet einen zentralen Speicherort für Website-Inhalte und erleichtert so deren Verwaltung und Aktualisierung. Außerdem können so mehrere Nutzer/innen gleichzeitig an denselben Inhalten arbeiten, was die Zusammenarbeit und Produktivität verbessert.
Dauerhafte Speicherung in Containern
Container sind leichtgewichtig, portabel, sicher und unkompliziert und bieten eine Verschmelzung zwischen verschiedenen Anwendungen. Sie müssen über einen Mechanismus verfügen, um Daten zwischen Neustarts und Entfernung des Containers aufrechtzuerhalten. Container haben einen Dateispeicher oder ein Dateisystem wie herkömmliche Anwendungen, aber wenn du sie mit neuen Änderungen neu aufbaust, verlierst du alle nicht-persistenten Daten.
Deshalb bieten Container die Möglichkeit, Volume-Storage einzubinden oder ein Storage-Volume zu mounten. Container behandeln Speichervolumes wie ein Verzeichnis. Alle Daten, die auf das Volume geschrieben werden, landen im Host-Dateisystem.
Der persistente Speicher für Container muss auf diese Weise funktionieren, weil der Neustart eines Containers eine neue Instanz erzeugt und die alte Instanz verwirft. Wenn ein Container keine konsistente Sicht auf die Daten hat, werden die Daten beim Neustart des Containers gelöscht. Ein Speichervolumen bewahrt die Daten über Sitzungen und Neustarts des Containers hinweg, so dass der Container seinen Zustand beibehält, auch wenn er verschoben oder neu gestartet wird.
Volume vs. Persistent Volume
In Containern gibt es 2 Möglichkeiten, persistente Daten zu speichern: mit Volumes und persistenten Volumes. Zwischen beiden gibt es einen wesentlichen Unterschied. Ein Container verwaltet die Daten im Volume-Speicher. Wenn du einen Container anhältst, bleiben die Daten erhalten und sind verfügbar, wenn du den Container neu startest. Wenn du jedoch einen Container löschst oder entfernst, gehen die Daten verloren, da du auch den zugrunde liegenden Volume-Speicher löschst.
Persistent Volume Storage oder Bind Mounts sind eine Möglichkeit, die Daten außerhalb des Dateisystems des Containers zu speichern. Auf diese Weise gehen die Daten nicht verloren, selbst wenn du den Container löschst. Sie bleiben so lange erhalten, bis du sie manuell löschst.
Im folgenden Abschnitt werden beide Volume-Typen anhand von Beispielen demonstriert.
Beispiel für persistenten Container-Speicher
Wir haben eine kleine Webanwendung erstellt, um die persistente Speicherung mit Docker-Containern zu demonstrieren. Du kannst sie nachbauen, indem du Docker installierst und dir den Code aus diesem GitHub-Repository holst.
Die Anwendung ist ein einfaches Formular mit 2 Feldern für Benutzereingaben:
- Titel
- Text des Dokuments
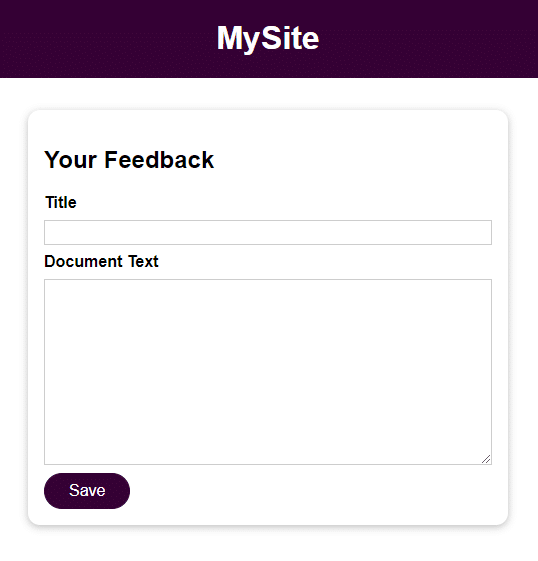
Sobald du die Benutzereingabe gespeichert hast, kannst du darauf zugreifen, indem du die Datei im Feedback-Verzeichnis mit dem im Feld Titel angegebenen Namen öffnest. Die Eingabe im Feld Dokumententext ist der Inhalt der Datei.
So verwendest du den Volumenspeicher
Wenn du die Anwendung auf deinem eigenen Rechner installiert hast, kann sie, wie in der Dockerdatei gezeigt, Volume Storage verwenden.
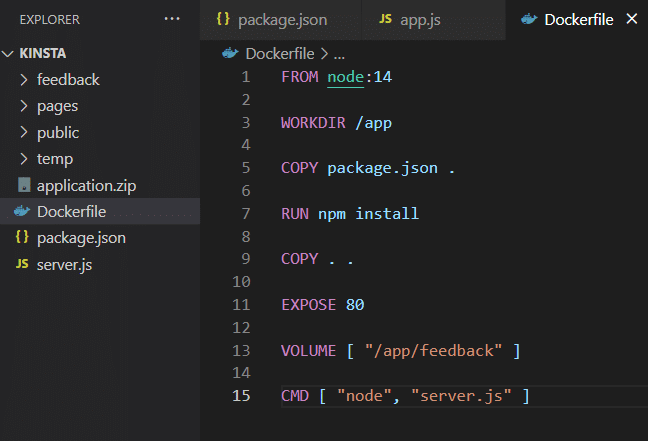
Jetzt erstellst du das Image und startest den Container. Dazu führst du die folgenden Befehle aus.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Sobald die Anwendung läuft, navigiere zu localhost:3000, um Feedback zu geben.
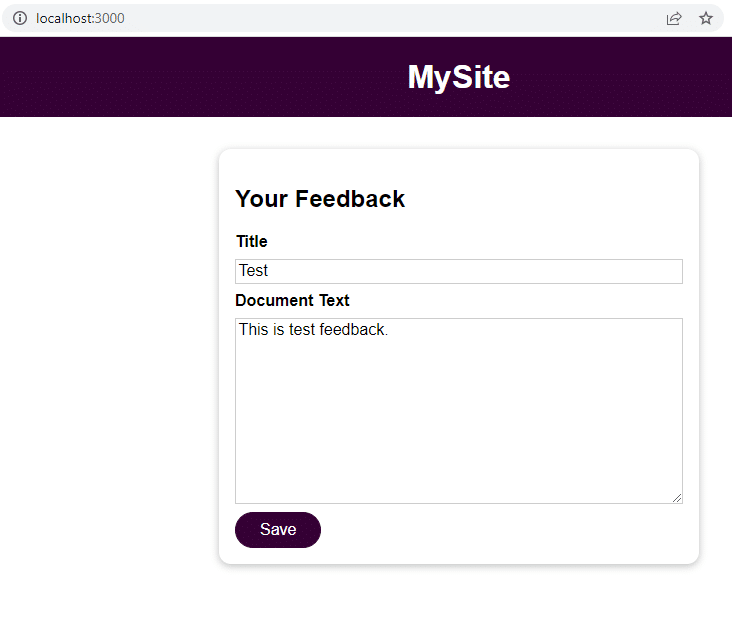
Klicke auf Speichern und navigiere zu localhost:3000/feedback/test.txt, um zu sehen, ob die Eingabe erfolgreich gespeichert wurde oder nicht.
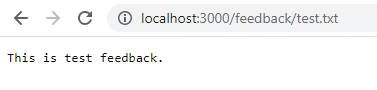
Entferne den Container und starte ihn neu, um zu sehen, ob die Eingabe bestehen bleibt.
docker stop feedback-app
docker start feedback-appWenn du jetzt die gleiche URL aufrufst, siehst du, dass die Rückmeldung immer noch da ist. Aber was passiert, wenn du den Container entfernst und ihn neu startest?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesWenn du nach dem Neustart zu dieser URL zurückkehrst, ist sie nicht mehr vorhanden, weil die Daten beim Entfernen des Containers verloren gegangen sind. Die Volumendaten bleiben nur erhalten, wenn du den Container stoppst, nicht wenn du ihn entfernst.
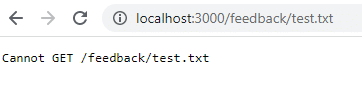
Um dieses Problem zu entschärfen und die Daten auch dann zu erhalten, wenn du den Container entfernst, musst du persistenten Volume-Speicher oder benannten Speicher verwenden. Zuerst solltest du die Container und Images aufräumen.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesSo verwendest du persistenten Volumenspeicher
Bevor du dies testest, musst du das VOLUME-Attribut aus der Dockerdatei entfernen und das Image neu erstellen.
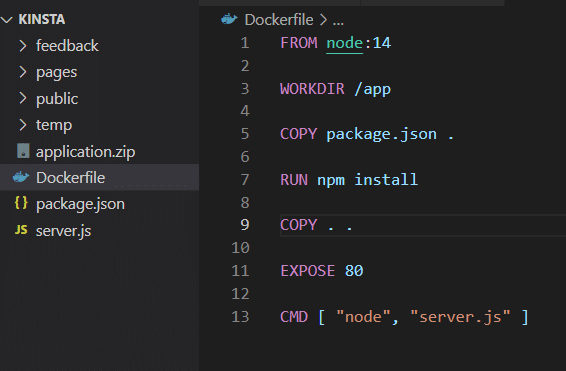
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesWie du siehst, verwendest du im zweiten Befehl das -v Flag, um das persistente Volume außerhalb des Containers zu definieren, das auch dann bestehen bleibt, wenn du den Container entfernst.
Wie im vorherigen Schritt kannst du versuchen, Feedback hinzuzufügen und darauf zuzugreifen, wenn du den Container stoppst, entfernst und neu startest.
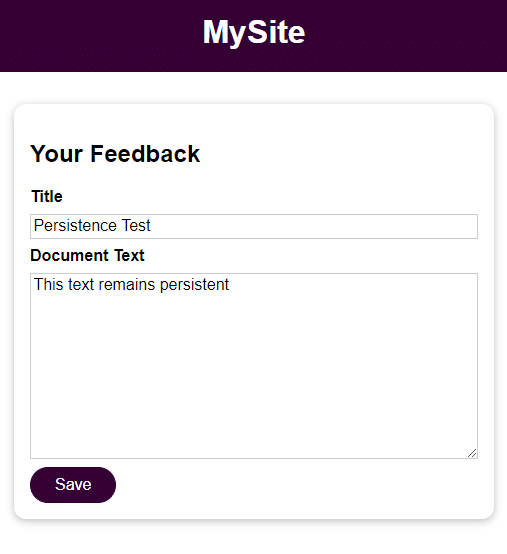
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesWie du siehst, sind die Daten auch nach dem Stoppen und Entfernen des Containers zugänglich und bleiben erhalten.
Zusammenfassung
Persistenter Speicher ist für containerisierte Anwendungen unerlässlich, da er es ermöglicht, Daten auch außerhalb des Lebenszyklus eines Containers zu speichern. Die beiden wichtigsten Arten von persistentem Speicher für containerisierte Anwendungen sind Volumes und Bind-Mounts, die jeweils ihre Vorteile und Anwendungsfälle haben.
Volumes werden im Dateisystem des Containers gespeichert, während Bind-Mounts direkt auf dem Host-Rechner zugänglich sind.
Persistenter Speicher ermöglicht die gemeinsame Nutzung von Daten zwischen Containern und damit den Aufbau komplexer, mehrschichtiger Anwendungen. Persistenter Speicher ist wichtig, um die Stabilität und Kontinuität von containerisierten Anwendungen zu gewährleisten und bietet eine zuverlässige und flexible Möglichkeit, wichtige Daten zu speichern.
Entwickelst du eine Anwendung, die persistenten Speicher benötigt? In unserer Bibliothek mit Schnellstartbeispielen erfährst du, wie du deine Anwendung von Git-Hosts wie GitHub, GitLab und Bitbucket auf Kinsta bereitstellst.
Unsere offizielle Dokumentation zu persistentem Speicher hilft dir, deine Anwendung und ihre Daten schnell online zu stellen.

Steve Bonisteel is Technical Editor bij Kinsta. Hij begon zijn schrijverscarrière als verslaggever en achtervolgde ambulances en brandweerwagens. Sinds eind jaren negentig schrijft hij over internetgerelateerde technologie.

