
Les sites web ne sont pas construits uniquement pour publier du contenu, et les métadonnées ne sont pas peaufinées pour le plaisir ; c’est l’ensemble de ces activités qui fonctionnent ensemble pour que vos pages puissent être découvertes plus facilement. Pendant des années, Google Search a été la principale voie d’accès à cette visibilité, en grande partie grâce à ses robots d’indexation.
Depuis la fin des années 1990, Googlebot et d’autres robots d’indexation traditionnels parcourent les sites web, récupèrent les pages HTML et les indexent pour aider les internautes à trouver ce qu’ils cherchent. En janvier 2024, Google représentait 63 % de l’ensemble du trafic web aux États-Unis, alimenté par les 170 premiers domaines.
Mais aujourd’hui, selon une enquête de McKinsey, la moitié des clients se tournent vers des outils d’IA tels que ChatGPT, Claude, Gemini ou Perplexity pour obtenir des réponses instantanées, et même Google intègre des résumés générés par l’IA dans les résultats de recherche grâce à des fonctionnalités telles que les aperçus d’IA.
Derrière ces nouvelles expériences basées sur l’IA se cache une classe croissante de robots connus sous le nom de crawlers IA. Si vous gérez un site WordPress, il est plus important que jamais de comprendre comment ces robots accèdent à votre contenu et l’utilisent.
Qu’est-ce qu’un robot d’indexation ?
Les robots d’indexation sont des robots automatisés qui analysent les pages web accessibles au public, à l’instar des robots des moteurs de recherche, mais dans un but différent. Au lieu d’indexer les pages pour un classement traditionnel, ils collectent du contenu pour entraîner de grands modèles de langage ou fournir des informations fraîches aux réponses générées par l’IA.
D’une manière générale, les robots d’IA se répartissent en deux groupes :
- Les crawlers de formation, tels que GPTBot (OpenAI) et ClaudeBot (Anthropic), collectent des données pour enseigner à de grands modèles de langage comment répondre aux questions avec plus de précision.
- Les crawlers de recherche en direct, comme ChatGPT-User, accèdent aux sites web en temps réel lorsque quelqu’un pose une question nécessitant les données les plus récentes, comme la vérification d’une description de produit ou la lecture d’une documentation.
D’autres robots, comme PerplexityBot ou AmazonBot, construisent leurs propres index ou systèmes pour réduire leur dépendance à l’égard de sources tierces. Bien que leurs objectifs diffèrent, ils ont tous un point commun : ils récupèrent et lisent le contenu de sites web comme le vôtre.
Fonctionnement des robots d’indexation
Lorsqu’un crawler IA visite votre site, il effectue généralement les opérations suivantes :
- Il envoie une requête GET de base à l’URL de la page (pas d’interaction, de défilement ou d’événements DOM).
- Il ne récupère que le code HTML initial renvoyé par le serveur. Il n’attend pas que le JavaScript côté client se charge ou s’exécute.
- Il extrait tous les liens
<a href="">,<img src="">,<script src="">et autres ressources, puis ajoute les URL internes (et parfois externes) à sa file d’attente. Dans de nombreux cas, il trouve également les liens brisés qui renvoient des erreurs 404. - Il peut tenter de récupérer des ressources liées telles que des images, des fichiers CSS ou des scripts, mais uniquement en tant que ressources brutes, et non pour rendre la page.
- Il répète ce processus de manière récursive sur les liens découverts afin de cartographier le site.
Comment les robots d’indexation interagissent avec les sites WordPress
WordPress est une plateforme de rendu serveur qui utilise PHP pour générer des pages HTML complètes avant de les envoyer au navigateur. Lorsqu’un crawler visite un site WordPress, il obtient généralement tout ce dont il a besoin (contenu, titres, métadonnées, navigation) dans la réponse HTML.
Grâce à cette structure, la plupart des sites WordPress sont naturellement adaptés aux robots d’indexation. Qu’il s’agisse de Googlebot ou d’un robot d’indexation, ils peuvent généralement scanner votre site et comprendre facilement votre contenu. En fait, le contenu facilement explorable est l’une des raisons pour lesquelles WordPress est performant à la fois dans la recherche traditionnelle et dans les nouvelles plateformes basées sur l’IA.
Devriez-vous autoriser les robots d’indexation à accéder à votre contenu ?
Les robots d’indexation peuvent déjà lire la plupart des sites WordPress par défaut. La vraie question est de savoir ce à quoi vous voulez qu’ils accèdent – et comment vous pouvez contrôler cette visibilité.
Les entreprises axées sur le contenu sont actuellement en pleine effervescence. Le sujet s’étend aux articles de blog, à la documentation, aux pages de destination… à tout ce qui est écrit pour le web, en fait. Vous avez probablement entendu des conseils tels que « écrire pour les machines », car les plateformes d’IA tirent de plus en plus de données en direct et, dans certains cas, incluent désormais des liens vers les sources. Nous voulons tous apparaître dans les résultats du LLM, tout comme nous voulons apparaître dans les résultats de recherche de Google.
Par exemple, dans la capture d’écran ci-dessous, nous demandons à ChatGPT de nous indiquer les dernières fonctionnalités de Kinsta. Il recherche sur le web, analyse les changelogs et les pages liées, et fournit une réponse résumée avec des liens directs vers la source.
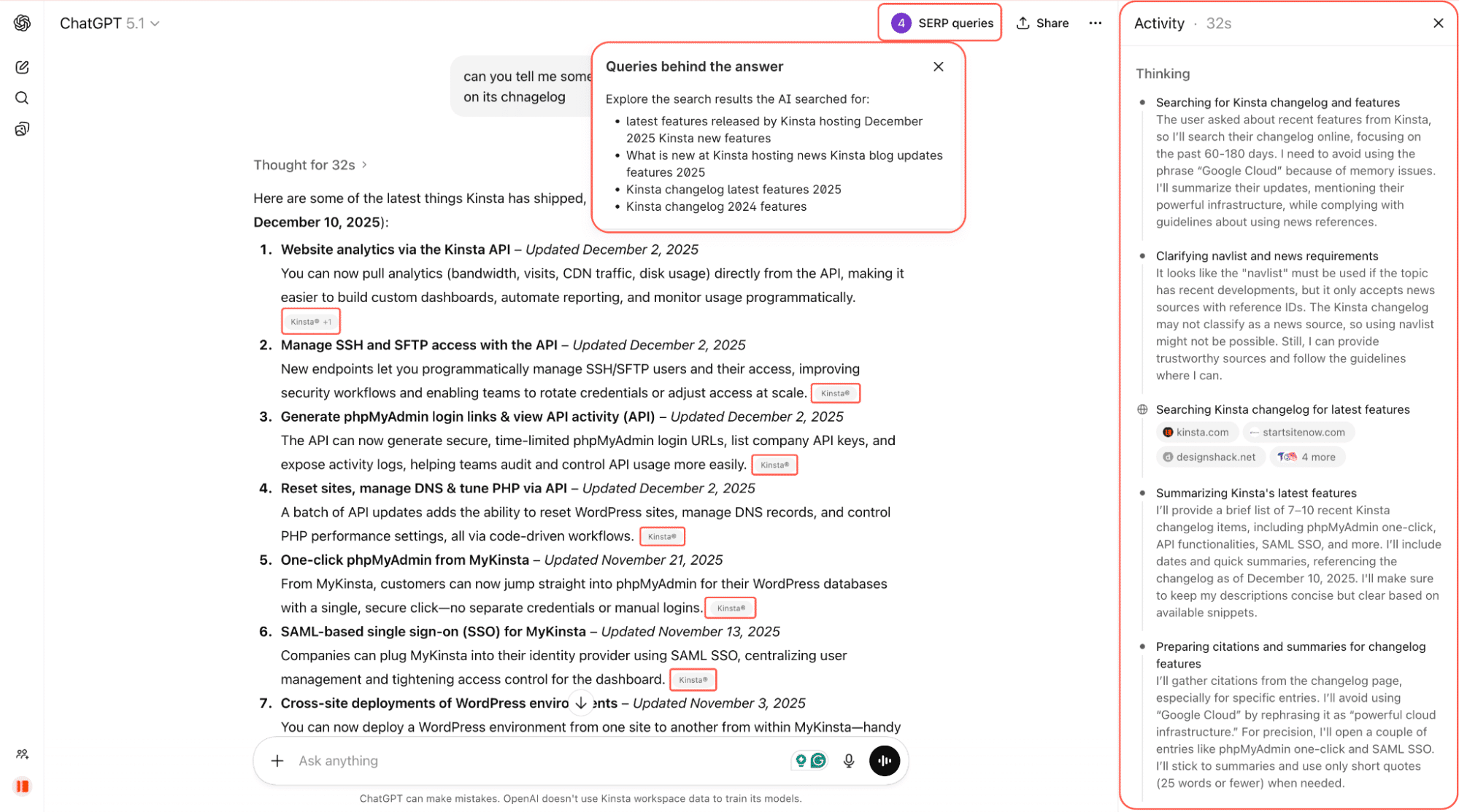
Il est encore tôt, mais les robots d’indexation influencent déjà ce que les internautes voient lorsqu’ils posent des questions en ligne. Et cette influence peut être importante.
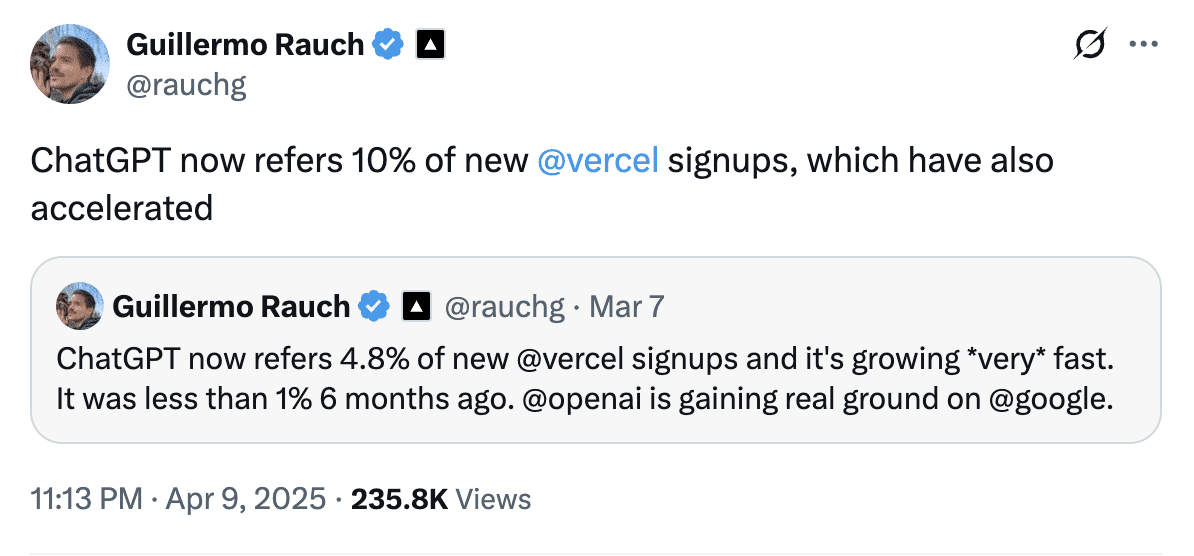
Guillermo Rauch, PDG de Vercel, a indiqué en avril que ChatGPT représentait près de 10 % des nouvelles inscriptions à Vercel, contre moins de 1 % six mois plus tôt. Cela montre à quel point les recommandations basées sur l’IA peuvent rapidement devenir un canal d’acquisition important.
Et les crawlers d’IA sont très répandus. Selon Cloudflare, les robots d’IA ont accédé à environ 39 % du million de sites web les plus fréquentés, mais seulement 3 % de ces sites ont réellement bloqué ou contesté ce trafic.
Par conséquent, même si vous n’avez pas encore pris de décision, il est presque certain que des robots d’indexation visitent déjà votre site.
Faut-il autoriser ou bloquer les robots d’indexation par IA ?
Il n’y a pas de réponse unique. Il n’y a pas de réponse universelle, mais voici un cadre :
- Bloquez les robots sur les itinéraires sensibles ou de faible valeur comme
/login,/checkout,/admin, ou les tableaux de bord. Ces itinéraires ne contribuent pas à la découverte et ne font que gaspiller de la bande passante. - Autorisez les robots sur les « contenus de découverte » tels que les articles de blog, la documentation, les pages de produits et les informations sur les prix. Ces pages sont les plus susceptibles d’être citées dans les réponses de l’IA et de générer un trafic qualifié.
- Décidez stratégiquement d’un contenu premium ou à accès restreint. Si votre contenu est votre produit (par exemple, les actualités, la recherche, les cours), l’accès illimité à l’IA peut nuire à votre activité.
De nouveaux outils apparaissent pour vous aider. Cloudflare, par exemple, expérimente un modèle appelé Pay Per Crawl, qui permet aux propriétaires de sites de faire payer l’accès aux sociétés d’IA. Il s’agit encore d’une version bêta privée et l’adoption dans le monde réel n’en est qu’à ses débuts, mais l’idée a été fortement soutenue par les grands éditeurs qui souhaitent mieux contrôler la manière dont leur contenu est utilisé.
D’autres membres de la communauté de la recherche et du marketing sont plus prudents, car le blocage par défaut pourrait involontairement réduire la visibilité dans les résultats de recherche de l’IA pour les sites qui souhaitent réellement être exposés. Pour l’instant, il s’agit d’une expérience prometteuse plutôt que d’une source de revenus mature.
Jusqu’à ce que ces systèmes arrivent à maturité, l’approche la plus pratique est celle de l’ouverture sélective, qui consiste à garder le contenu de découverte accessible par crawl, à bloquer les zones sensibles et à revoir vos règles au fur et à mesure de l’évolution de l’écosystème.
Comment contrôler l’accès des robots d’indexation sur WordPress ?
Si vous n’êtes pas à l’aise avec l’idée que des robots d’indexation puissent accéder à votre site WordPress et en analyser le contenu, la bonne nouvelle est que vous pouvez reprendre le contrôle.
Voici trois façons de gérer l’accès des robots d’indexation sur WordPress :
- Modifier manuellement votre fichier
robots.txt. - Utiliser une extension pour le faire à votre place.
- Utiliser la protection contre les robots de Cloudflare.
Voyons ces trois options.
Option 1 : bloquer manuellement les robots d’indexation de l’IA à l’aide du fichier robots.txt
Votre fichier robots.txt indique aux robots les parties de votre site qu’ils sont autorisés à explorer. La plupart des robots d’exploration bien connus, comme GPTBot d’OpenAI, Claude-Web d’Anthropic et Google-Extended, respectent ces règles.
Vous pouvez bloquer complètement certains robots, leur accorder un accès complet ou restreindre l’accès à certaines sections de votre site. Par exemple, pour tout bloquer, vous pouvez ajouter ceci à votre fichier robots.txt, bien que cela ne soit pas recommandé pour la plupart des sites :
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Google-Extended
Disallow: /Pour permettre un accès complet au GPTBot d’OpenAI :
User-agent: GPTBot
Disallow:Pour bloquer une section de votre site au GPTBot d’OpenAI. Par exemple, votre page de connexion, où les crawlers n’apportent aucune valeur ajoutée :
User-agent: GPTBot
Disallow: /login/Ce type de blocage sélectif est essentiel. Les itinéraires sensibles tels que /login, /checkout, ou /admin ne contribuent pas à la découvrabilité et devraient presque toujours être bloqués. En revanche, les pages de produits, les aperçus de fonctionnalités ou votre centre d’aide sont de bons candidats pour rester ouverts aux robots car ils peuvent générer des citations et des références.
Vous pouvez ajouter ce fichier robots.txt manuellement en procédant comme suit :
- En utilisant une extension SEO comme Yoast (Outils > Éditeur de fichiers).
- En utilisant une extension de gestion de fichiers comme WP File Manager.
- Ou en modifiant votre fichier
robots.txtdirectement sur le serveur via FTP.
Option 2 : Utiliser un plugin WordPress
Si vous n’êtes pas à l’aise pour éditer le fichier robots.txt directement ou si vous voulez juste un moyen plus rapide et plus sûr de gérer l’accès des robots d’indexation, les extensions peuvent faire le travail pour vous en quelques clics.
Raptive Ads
L’extension WordPress Raptive Ads comprend un support intégré pour bloquer les robots d’indexation :
- Vous pouvez choisir les robots à bloquer directement dans les réglages de l’extension.
- La plupart des robots d’indexation (comme GPTBot et Claude) sont bloqués par défaut.
- Google-Extended n’ est pas bloqué par défaut, mais vous pouvez cocher la case si vous souhaitez ne pas bénéficier de l’entraînement à l’IA de Google.
L’un des principaux avantages de cette extension est que le blocage de Google-Extended n’ affecte pas votre classement dans Google ni votre visibilité dans les résultats de recherche habituels.
Block AI Crawlers
L’extension Block AI Crawlers a été spécialement conçue pour permettre aux propriétaires de sites WordPress de mieux contrôler la manière dont les robots d’indexation interagissent avec leur contenu. Voici comment procéder :
- Bloquez plus de 75 bots IA connus en ajoutant automatiquement les bonnes règles
Disallowà votre siterobots.txt. - Aucune configuration n’est nécessaire. Installez l’extension, allez dans Réglages > Lecture et cochez la case Bloquer les robots d’IA.
- Légère et open-source, avec des mises à jour régulières tirées de GitHub.
- Conçue pour fonctionner dès le départ sur la plupart des installations WordPress.
L’extension Block AI Crawlers est l’un des moyens les plus simples d’empêcher les robots indésirables d’accéder à votre site, en particulier si vous n’utilisez pas d’extensions de référencement avancées.
Option 3 : Utilisez le bloqueur de robots AI en un clic de Cloudflare
Si votre site WordPress utilise Cloudflare (et beaucoup le font), vous pouvez bloquer des dizaines de robots connus et inconnus avec un simple bouton.
Au milieu de l’année 2024, Cloudflare a lancé une fonction dédiée aux scrapeurs et aux crawlers d’IA, disponible même sur le plan gratuit. Cette fonction ne s’appuie pas uniquement sur robots.txt; elle bloque les robots au niveau du réseau, même ceux qui mentent sur leur identité.
Vous pouvez l’activer en procédant comme suit :
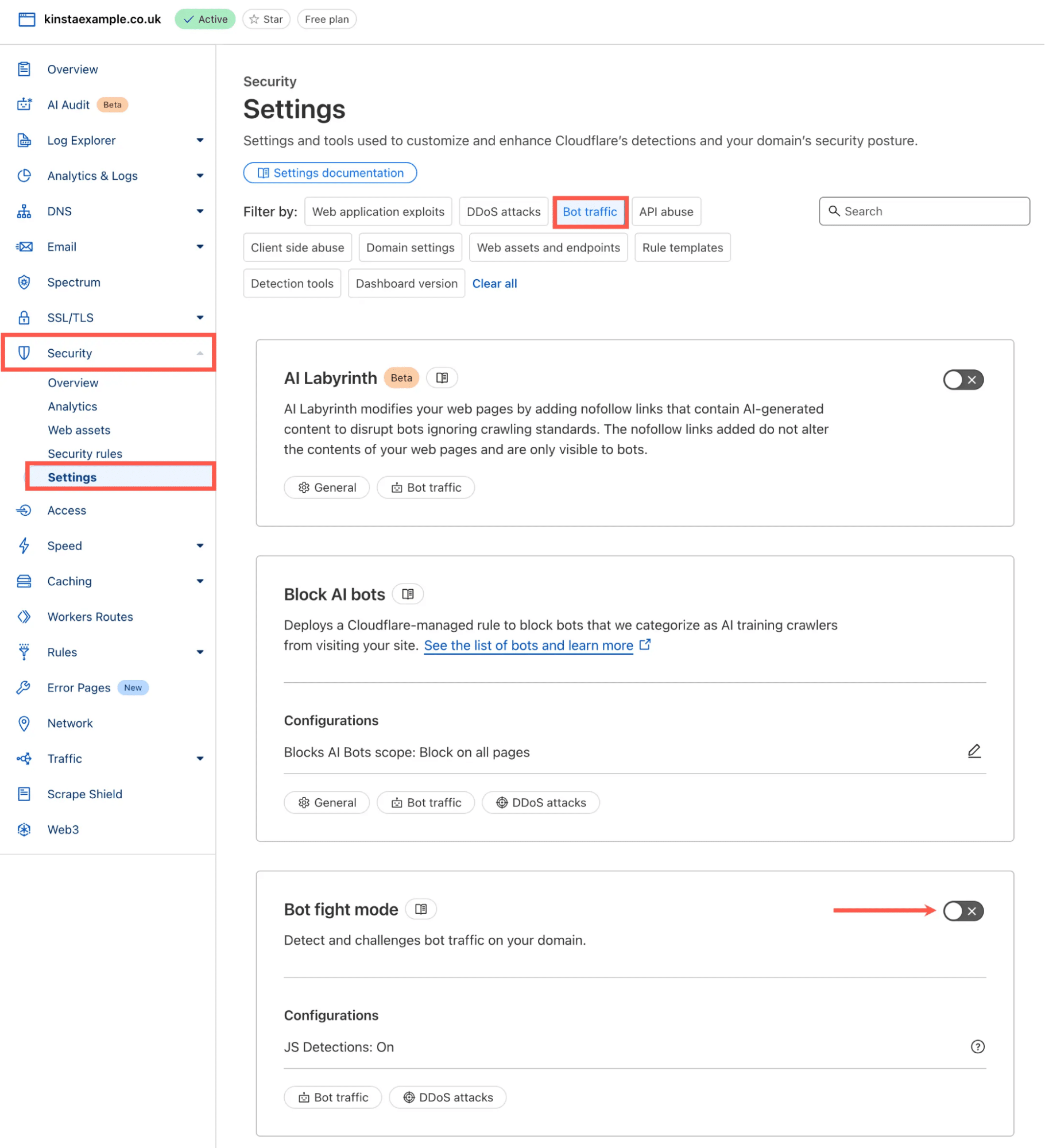
- Connectez-vous à votre tableau de bord Cloudflare
- Allez dans Sécurité > Réglages
- Dans la section Filtrer par, choisissez Trafic de robots.
- Recherchez le mode de lutte contre les robots et activez-le.
Si vous utilisez un plan Cloudflare payant, vous avez accès au Super Bot fight mode, une version améliorée du Bot fight mode avec plus de flexibilité. Il s’appuie sur la même technologie mais vous permet de choisir comment traiter différents types de trafic, en activant les détections JavaScript pour attraper les navigateurs sans tête, les scrapers furtifs et d’autres trafics malveillants.
Par exemple, au lieu de bloquer tous les robots, vous pouvez configurer l’outil pour qu’il ne bloque que le « trafic automatisé certain » et autorise les « robots vérifiés » tels que les robots des moteurs de recherche :
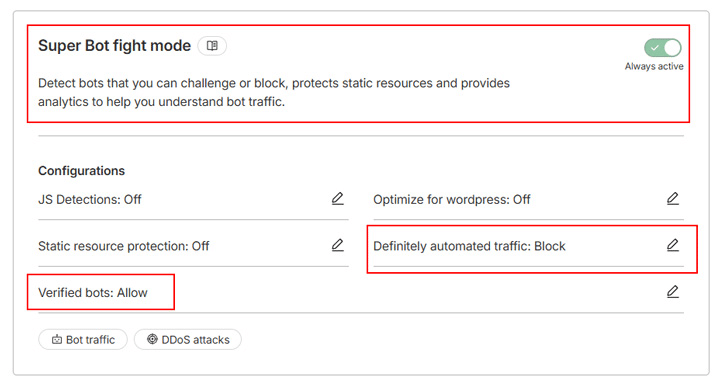
C’est le mode « Super Bot Fight » de Cloudflare. Cloudflare bloque automatiquement les requêtes des robots d’intelligence artificielle.
Si vous voulez en savoir plus sur la façon dont ces outils fonctionnent ensemble, y compris le Bot Fight Mode, le Super Bot Fight Mode et les règles de défi ciblées, vous pouvez lire notre guide complet sur la protection de votre site WordPress contre le trafic indésirable des bots avec Cloudflare.
Ce que ce changement signifie pour votre site WordPress
Les robots d’indexation font désormais partie de la manière dont les internautes découvrent les informations en ligne. La technologie est nouvelle, les règles sont encore en cours d’élaboration et les propriétaires de sites décident de la part de leur contenu qu’ils souhaitent rendre accessible.
La bonne nouvelle, c’est que les sites WordPress sont déjà en position de force. Comme WordPress produit un code HTML entièrement rendu, la plupart des robots d’indexation peuvent interpréter clairement votre contenu sans manipulation particulière. La véritable décision stratégique n’est pas de savoir si les robots d’indexation peuvent accéder à votre site, mais plutôt de déterminer dans quelle mesure cet accès peut contribuer à la réalisation de vos objectifs.
Et comme le mélange des types de trafic évolue, il est utile de disposer d’options d’hébergement qui facilitent la compréhension et la gestion de l’utilisation des ressources. Les nouveaux plans de Kinsta basés sur la bande passante offrent un moyen plus prévisible de comptabiliser le transfert total de données, quelle que soit la source des requêtes. Combiné aux protections contre les robots de Cloudflare et à vos propres règles d’exploration, vous avez un contrôle total sur l’accès à votre site.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

