
Comme tout propriétaire de site vous le dira, les pertes de données et les temps d’arrêt, même à doses minimes, peuvent être catastrophiques. Elles peuvent frapper à tout moment les personnes non préparées, entraînant une réduction de la productivité, de l’accessibilité et de la confiance dans les produits.
Pour protéger l’intégrité de votre site, il est essentiel de mettre en place des protections contre l’éventualité d’un temps d’arrêt ou d’une perte de données.
C’est là que la réplication des données entre en jeu.
La réplication de données est un processus de sauvegarde automatisé dans lequel vos données sont copiées de manière répétée depuis sa base de données principale vers un autre emplacement distant pour être conservées en sécurité. Il s’agit d’une technologie intégrale pour tout site ou application utilisant un serveur de base de données. Vous pouvez également exploiter la base de données répliquée pour traiter le SQL en lecture seule, ce qui permet d’exécuter davantage de processus dans le système.
La mise en place d’une réplication entre deux bases de données offre une tolérance aux pannes contre les imprévus. Elle est considérée comme la meilleure stratégie pour obtenir une haute disponibilité en cas de sinistre.
Dans cet article, nous allons nous plonger dans les différentes stratégies qui peuvent être mises en œuvre par les développeurs backend pour une réplication PostgreSQL transparente.
Qu’est-ce que la réplication PostgreSQL ?
La réplication PostgreSQL est définie comme le processus de copie des données d’un serveur de base de données PostgreSQL vers un autre serveur. Le serveur de base de données source est également connu sous le nom de serveur « primaire », tandis que le serveur de base de données recevant les données copiées est connu sous le nom de serveur « réplique ».
La base de données PostgreSQL suit un modèle de réplication simple, où toutes les écritures vont vers un nœud primaire. Le nœud primaire peut ensuite appliquer ces modifications et les diffuser aux nœuds secondaires.
Qu’est-ce que le basculement automatique ?
Le basculement est une méthode permettant de récupérer les données si le serveur primaire s’arrête pour une raison quelconque. Tant que vous avez configuré PostreSQL pour gérer la réplication de votre flux physique, vous – et vos utilisateurs – serez protégés des temps d’arrêt dus à une défaillance du serveur primaire.
Notez que le processus de basculement peut prendre un certain temps à configurer et à lancer. Il n’existe pas d’outils intégrés pour la surveillance et la portée des pannes de serveur dans PostgreSQL, vous devrez donc faire preuve de créativité.
Heureusement, vous ne devez pas être dépendant de PostgreSQL pour le basculement. Il existe des outils dédiés qui permettent le basculement automatique et la commutation automatique sur le serveur de secours, réduisant ainsi les temps d’arrêt de la base de données.
En mettant en place la réplication par basculement, vous garantissez pratiquement la haute disponibilité en vous assurant que les serveurs de secours sont disponibles si le serveur primaire s’effondre un jour.
Avantages de l’utilisation de la réplication PostgreSQL
Voici quelques avantages clés de l’utilisation de la réplication PostgreSQL :
- Migration des données : Vous pouvez exploiter la réplication PostgreSQL pour la migration des données, soit par un changement de matériel du serveur de base de données, soit par le déploiement du système.
- Tolérance aux pannes : Si le serveur primaire tombe en panne, le serveur de secours peut faire office de serveur car les données contenues dans les serveurs primaire et de secours sont les mêmes.
- Performances du traitement transactionnel en ligne (OLTP) : Vous pouvez améliorer le temps de traitement des transactions et le temps de requête d’un système OLTP en supprimant la charge de requête de reporting. Le temps de traitement des transactions est la durée nécessaire à l’exécution d’une requête donnée avant qu’une transaction ne soit terminée.
- Test du système en parallèle : Lors de la mise à niveau d’un nouveau système, vous devez vous assurer que le système se comporte bien avec les données existantes, d’où la nécessité de tester avec une copie de la base de données de production avant le déploiement.
Comment fonctionne la réplication PostgreSQL
En général, les gens pensent que quand on s’amuse avec une architecture primaire et secondaire, il n’y a qu’une seule façon de configurer les sauvegardes et la réplication. Les déploiements PostgreSQL, cependant, peuvent suivre n’importe laquelle de ces trois méthodes :
- Réplication en continu : Réplique les données depuis le nœud primaire vers le secondaire, puis copie les données sur Amazon S3 ou Azure Blob pour le stockage de sauvegarde.
- Réplication au niveau du volume : Réplique les données au niveau de la couche de stockage, depuis le nœud primaire vers le nœud secondaire, puis copie les données vers Amazon S3 ou Azure Blob pour le stockage de sauvegarde.
- Sauvegardes incrémentielles : Réplique les données depuis le nœud primaire tout en construisant un nouveau nœud secondaire à partir du stockage Amazon S3 ou Azure Blob, ce qui permet le streaming directement depuis le nœud primaire.
Méthode 1 : Streaming
La réplication en continu PostgreSQL, également connue sous le nom de réplication WAL, peut être configurée de manière transparente après l’installation de PostgreSQL sur tous les serveurs. Cette approche de la réplication est basée sur le déplacement des fichiers WAL de la base de données primaire vers la base de données cible.
Vous pouvez implémenter la réplication en continu PostgreSQL en utilisant une configuration primaire-secondaire. Le serveur primaire est l’instance principale qui gère la base de données primaire et toutes ses opérations. Le serveur secondaire agit en tant qu’instance supplémentaire et exécute toutes les modifications apportées à la base de données primaire sur lui-même, générant une copie identique dans le processus. Le serveur primaire est le serveur de lecture/écriture tandis que le serveur secondaire est simplement en lecture seule.
Pour cette méthode, vous devez configurer à la fois le nœud primaire et le nœud de secours. Les sections suivantes expliquent les étapes à suivre pour les configurer facilement.
Configuration du nœud primaire
Vous pouvez configurer le nœud primaire pour la réplication en continu en effectuant les étapes suivantes :
Étape 1 : initialiser la base de données
Pour initialiser la base de données, vous pouvez utiliser la commande utilitaire initdb. Ensuite, vous pouvez créer un nouvel utilisateur avec des privilèges de réplication en utilisant la commande suivante :
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';L’utilisateur devra fournir un mot de passe et un nom d’utilisateur pour la requête donnée. Le mot-clé de réplication est utilisé pour donner à l’utilisateur les privilèges requis. Un exemple de requête ressemblerait à ceci :
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Étape 2 : Configuration des propriétés de streaming
Ensuite, vous pouvez configurer les propriétés de streaming avec le fichier de configuration de PostgreSQL (postgresql.conf) qui peut être modifié comme suit :
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onVoici un peu de contexte autour des paramètres utilisés dans le snippet précédent :
wal_log_hints: Ce paramètre est nécessaire pour la fonctionpg_rewindqui s’avère utile lorsque le serveur en attente n’est pas synchronisé avec le serveur principal.wal_level: Vous pouvez utiliser ce paramètre pour activer la réplication PostgreSQL en continu, avec des valeurs possibles telles queminimal,replica, oulogical.max_wal_size: Vous pouvez utiliser ce paramètre pour spécifier la taille des fichiers WAL qui peuvent être conservés dans les fichiers journaux.hot_standby: Vous pouvez utiliser ce paramètre pour une connexion en lecture seule avec le secondaire lorsqu’il est défini sur ON.max_wal_senders: Vous pouvez utilisermax_wal_senderspour spécifier le nombre maximum de connexions simultanées qui peuvent être établies avec les serveurs en attente.
Étape 3 : Créer une nouvelle entrée
Après avoir modifié les paramètres dans le fichier postgresql.conf, une nouvelle entrée de réplication dans le fichier pg_hba.conf peut permettre aux serveurs d’établir une connexion entre eux pour la réplication.
Vous pouvez généralement trouver ce fichier dans le répertoire de données de PostgreSQL. Vous pouvez utiliser l’extrait de code suivant pour ce faire :
host replication rep_user IPaddress md5Une fois que le bout de code est exécuté, le serveur primaire permet à un utilisateur appelé rep_user de se connecter et d’agir en tant que serveur de secours en utilisant l’IP spécifiée pour la réplication. Par exemple :
host replication rep_user 192.168.0.22/32 md5Configuration du nœud de standby
Pour configurer le nœud de standby pour la réplication en continu, suivez ces étapes :
Étape 1 : sauvegarder le nœud primaire
Pour configurer le nœud de secours, exploitez l’utilitaire pg_basebackup pour générer une sauvegarde du nœud primaire. Celle-ci servira de point de départ pour le nœud de secours. Vous pouvez utiliser cet utilitaire avec la syntaxe suivante :
pg_basebackp -D -h -X stream -c fast -U rep_user -WLes paramètres utilisés dans la syntaxe mentionnée ci-dessus sont les suivants :
-h: Vous pouvez utiliser ce paramètre pour mentionner l’hôte primaire.-D: Ce paramètre indique le répertoire sur lequel vous travaillez actuellement.-C: Vous pouvez l’utiliser pour définir les points de contrôle.-X: Ce paramètre peut être utilisé pour inclure les fichiers journaux transactionnels nécessaires.-W: Vous pouvez utiliser ce paramètre pour demander à l’utilisateur un mot de passe avant de se connecter à la base de données.
Étape 2 : Configurer le fichier de configuration de réplication
Ensuite, vous devez vérifier si le fichier de configuration de réplication existe. S’il n’existe pas, vous pouvez générer le fichier de configuration de réplication en tant que recovery.conf.
Vous devez créer ce fichier dans le répertoire de données de l’installation PostgreSQL. Vous pouvez le générer automatiquement en utilisant l’option -R dans l’utilitaire pg_basebackup.
Le fichier recovery.conf doit contenir les commandes suivantes :
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name= "host_name"''
recovery_target_timeline = 'latest' (dernier)Les paramètres utilisés dans les commandes susmentionnées sont les suivants :
primary_conninfo: Vous pouvez utiliser ce paramètre pour établir une connexion entre les serveurs primaire et secondaire en exploitant une chaîne de connexion.standby_mode: Ce paramètre peut faire en sorte que le serveur primaire démarre en tant que serveur de secours lorsqu’il est allumé.recovery_target_timeline: Vous pouvez utiliser ce paramètre pour définir le temps de récupération.
Pour établir une connexion, vous devez fournir le nom d’utilisateur, l’adresse IP et le mot de passe comme valeurs pour le paramètre primary_conninfo. Par exemple :
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Étape 3 : Redémarrer le serveur secondaire
Enfin, vous pouvez redémarrer le serveur secondaire pour terminer le processus de configuration.
Cependant, la réplication en continu s’accompagne de plusieurs défis, tels que :
- Divers clients PostgreSQL (écrits dans différents langages de programmation) conversent avec un seul point de terminaison. Lorsque le nœud primaire tombe en panne, ces clients continuent à réessayer le même nom DNS ou IP. Cela rend le basculement visible pour l’application.
- La réplication PostgreSQL n’est pas fournie avec un basculement et une surveillance intégrés. Lorsque le nœud primaire tombe en panne, vous devez promouvoir un secondaire pour qu’il devienne le nouveau primaire. Cette promotion doit être exécutée de manière à ce que les clients n’écrivent que sur un seul nœud primaire et qu’ils n’observent pas d’incohérences de données.
- PostgreSQL réplique l’intégralité de son état. Lorsque vous devez développer un nouveau nœud secondaire, ce dernier doit récapituler tout l’historique des changements d’état du nœud primaire, ce qui demande beaucoup de ressources et rend coûteux l’élimination des nœuds de tête et la création de nouveaux nœuds.
Méthode 2 : Dispositif de bloc répliqué
La méthode du dispositif de blocs répliqués dépend de la mise en miroir des disques (également connue sous le nom de réplication de volume). Dans cette approche, les modifications sont écrites sur un volume persistant qui est mis en miroir de manière synchrone sur un autre volume.
L’avantage supplémentaire de cette méthode est sa compatibilité et la durabilité des données dans les environnements de cloud avec toutes les bases de données relationnelles, y compris PostgreSQL, MySQL et SQL Server, pour n’en citer que quelques-unes.
Cependant, méthode de la réplication PostgreSQL par miroir de disque nécessite que vous répliquiez à la fois le journal WAL et les données de table. Comme chaque écriture dans la base de données doit maintenant passer par le réseau de manière synchrone, vous ne pouvez pas vous permettre de perdre un seul octet, car cela pourrait laisser votre base de données dans un état corrompu.
Cette méthode est normalement exploitée en utilisant Azure PostgreSQL et Amazon RDS.
Méthode 3 : WAL
WAL se compose de fichiers de segments (16 Mo par défaut). Chaque segment comporte un ou plusieurs enregistrements. Un enregistrement de séquence de journal (LSN) est un pointeur vers un enregistrement dans WAL, vous permettant de connaître la position/l’emplacement où l’enregistrement a été sauvegardé dans le fichier journal.
Un serveur de secours exploite les segments WAL – également connus sous le nom de XLOGS dans la terminologie PostgreSQL – pour répliquer en continu les modifications de son serveur primaire. Vous pouvez utiliser la journalisation write-ahead pour garantir la durabilité et l’atomicité d’un SGBD en sérialisant des morceaux de données de type byte-array (chacun avec un LSN unique) dans un stockage stable avant qu’ils ne soient appliqués à une base de données.
L’application d’une mutation à une base de données peut entraîner diverses opérations sur le système de fichiers. Une question pertinente qui se pose est de savoir comment une base de données peut assurer l’atomicité en cas de défaillance du serveur due à une panne de courant alors qu’elle est en pleine mise à jour du système de fichiers. Lorsqu’une base de données démarre, elle lance un processus de démarrage ou de relecture qui peut lire les segments WAL disponibles et les compare avec le LSN stocké sur chaque page de données (chaque page de données est marquée avec le LSN du dernier enregistrement WAL qui affecte la page).
Réplication en continu des journaux (niveau bloc)
La réplication en continu affine le processus d’expédition des journaux. Au lieu d’attendre le changement de WAL, les enregistrements sont envoyés au fur et à mesure de leur création, ce qui réduit le délai de réplication.
La réplication en continu l’emporte également sur l’expédition de journaux, car le serveur en attente se lie au serveur primaire sur le réseau en tirant parti d’un protocole de réplication. Le serveur primaire peut alors envoyer des enregistrements WAL directement sur cette connexion sans avoir à dépendre de scripts fournis par l’utilisateur final.
Réplication basée sur l’expédition de journaux (niveau fichier)
L’expédition de journaux est définie comme la copie des fichiers journaux vers un autre serveur PostgreSQL pour générer un autre serveur de secours en rejouant les fichiers WAL. Ce serveur est configuré pour fonctionner en mode de récupération, et son seul but est d’appliquer tous les nouveaux fichiers WAL au fur et à mesure qu’ils apparaissent.
Ce serveur secondaire devient alors une sauvegarde à chaud du serveur PostgreSQL primaire. Il peut également être configuré pour être une réplique en lecture, où il peut offrir des requêtes en lecture seule, également appelé hot standby.
Archivage WAL continu
Dupliquer les fichiers WAL à mesure qu’ils sont créés dans un emplacement autre que le sous-répertoire pg_wal pour les archiver est connu sous le nom d’archivage WAL. PostgreSQL appellera un script donné par l’utilisateur pour l’archivage, chaque fois qu’un fichier WAL sera créé.
Le script peut s’appuyer sur la commande scp pour dupliquer le fichier vers un ou plusieurs emplacements tels qu’un montage NFS. Une fois archivés, les fichiers de segments WAL peuvent être exploités pour récupérer la base de données à un moment donné.
D’autres configurations basées sur les journaux incluent :
- Réplication synchrone : Avant que chaque transaction de réplication synchrone ne soit engagée, le serveur primaire attend que les standbys confirment qu’ils ont obtenu les données. L’avantage de cette configuration est qu’il n’y aura pas de conflits causés par des processus d’écriture parallèles.
- Réplication synchrone multi-maître : Ici, chaque serveur peut accepter des demandes d’écriture, et les données modifiées sont transmises du serveur d’origine à tous les autres serveurs avant que chaque transaction ne soit validée. Elle exploite le protocole 2PC et adhère à la règle du tout ou rien.
Détails du protocole de diffusion WAL
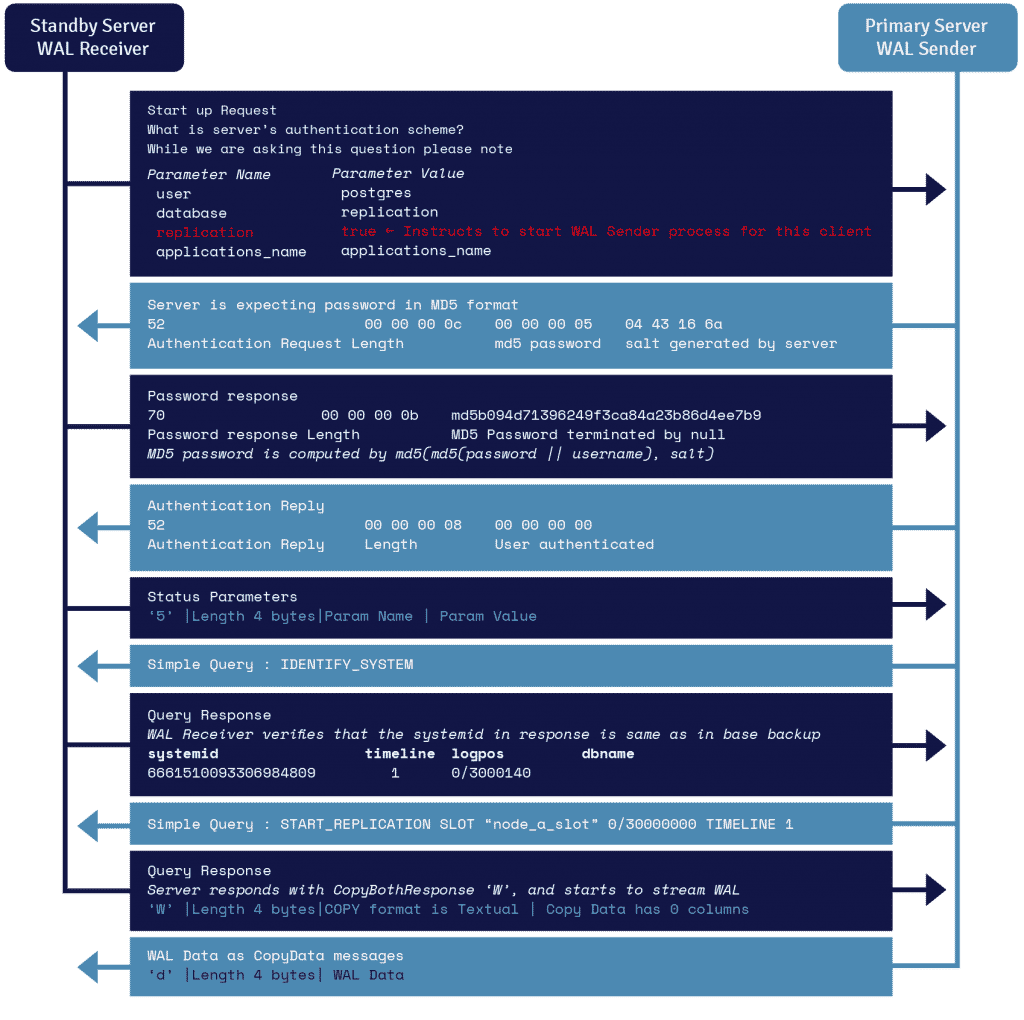
Un processus connu sous le nom de récepteur WAL, exécuté sur le serveur de secours, exploite les détails de connexion fournis dans le paramètre primary_conninfo de recovery.conf et se connecte au serveur primaire en exploitant une connexion TCP/IP.
Pour lancer la réplication en continu, le frontend peut envoyer le paramètre de réplication dans le message de démarrage. Une valeur booléenne de true, yes, 1, ou ON permet au backend de savoir qu’il doit passer en mode walsender de réplication physique.
L’expéditeur WAL est un autre processus qui s’exécute sur le serveur primaire et qui est chargé d’envoyer les enregistrements WAL au serveur de secours au fur et à mesure qu’ils sont générés. Le récepteur WAL enregistre les enregistrements WAL dans le WAL comme s’ils étaient créés par l’activité des clients connectés localement.
Une fois que les enregistrements WAL atteignent les fichiers de segment WAL, le serveur de standby continue de rejouer constamment le WAL afin que le primaire et le standby soient à jour.
Éléments de réplication PostgreSQL
Dans cette section, vous allez acquérir une compréhension plus approfondie des modèles (réplication mono-maître et multi-maître), des types (réplication physique et logique) et des modes (synchrone et asynchrone) couramment utilisés pour la réplication PostgreSQL.
Modèles de réplication des bases de données PostgreSQL
L’évolutivité consiste à ajouter plus de ressources/matériel aux nœuds existants afin d’améliorer la capacité de la base de données à stocker et à traiter plus de données, ce qui peut être réalisé horizontalement et verticalement. La réplication PostgreSQL est un exemple d’évolutivité horizontale qui est beaucoup plus difficile à mettre en œuvre que l’évolutivité verticale. Nous pouvons réaliser l’extensibilité horizontale principalement par la réplication à maître unique (SMR) et la réplication à maître multiple (MMR).
La réplication à maître unique permet aux données d’être modifiées uniquement sur un seul nœud, et ces modifications sont répliquées sur un ou plusieurs nœuds. Les tables répliquées dans la base de données répliquée ne sont pas autorisées à accepter des modifications, sauf celles provenant du serveur primaire. Même si elles le font, les modifications ne sont pas répliquées vers le serveur primaire.
La plupart du temps, SMR est suffisant pour l’application car il est moins compliqué à configurer et à gérer, sans risque de conflits. La réplication à maître unique est également unidirectionnelle, puisque les données de réplication circulent dans une seule direction principalement, de la base de données primaire à la base de données réplique.
Dans certains cas, SMR seul peut ne pas être suffisant, et vous pouvez avoir besoin de mettre en œuvre MMR. MMR permet à plus d’un nœud d’agir en tant que nœud primaire. Les modifications apportées aux lignes des tables dans plus d’une base de données primaire désignée sont répliquées vers leurs tables homologues dans toutes les autres bases de données primaires. Dans ce modèle, des schémas de résolution de conflits sont souvent employés pour éviter les problèmes tels que les clés primaires dupliquées.
L’utilisation du modèle MMR présente quelques avantages, à savoir :
- En cas de défaillance d’un hôte, les autres hôtes peuvent toujours fournir des services de mise à jour et d’insertion.
- Les nœuds primaires sont répartis sur plusieurs sites différents, de sorte que le risque de défaillance de tous les nœuds primaires est très faible.
- Possibilité d’utiliser un réseau étendu (WAN) de bases de données primaires qui peuvent être géographiquement proches de groupes de clients, tout en maintenant la cohérence des données sur le réseau.
Cependant, l’inconvénient de la mise en œuvre de MMR est sa complexité et sa difficulté à résoudre les conflits.
Plusieurs branches et applications fournissent des solutions MMR car PostgreSQL ne le supporte pas nativement. Ces solutions peuvent être open source, gratuites ou payantes. Une de ces extensions est la réplication bidirectionnelle (BDR) qui est asynchrone et qui est basée sur la fonction de décodage logique de PostgreSQL.
Puisque l’application BDR réplique les transactions sur d’autres nœuds, l’opération de réplication peut échouer s’il y a un conflit entre la transaction appliquée et la transaction commise sur le nœud récepteur.
Types de réplication PostgreSQL
Il existe deux types de réplication PostgreSQL : la réplication logique et la réplication physique.
Une simple opération logique initdb effectuerait l’opération physique de création d’un répertoire de base pour un cluster. De même, une simple opération logique CREATE DATABASE effectuerait l’opération physique de création d’un sous-répertoire dans le répertoire de base.
La réplication physique traite généralement des fichiers et des répertoires. Elle ne sait pas ce que ces fichiers et répertoires représentent. Ces méthodes sont utilisées pour maintenir une copie complète de l’ensemble des données d’un seul cluster, généralement sur une autre machine. Elles sont effectuées au niveau du système de fichiers ou du disque et utilisent des adresses de bloc exactes.
La réplication logique est un moyen de reproduire des entités de données et leurs modifications, sur la base de leur identité de réplication (généralement une clé primaire). Contrairement à la réplication physique, elle traite des bases de données, des tables et des opérations DML et se fait au niveau du cluster de base de données. Elle utilise un modèle de publication et d’abonnement où un ou plusieurs abonnés sont abonnés à une ou plusieurs publications sur un nœud éditeur.
Le processus de réplication commence par prendre un instantané des données sur la base de données de l’éditeur, puis le copie sur l’abonné. Les abonnés tirent les données des publications auxquelles ils sont abonnés et peuvent republier les données ultérieurement pour permettre une réplication en cascade ou des configurations plus complexes. L’abonné applique les données dans le même ordre que l’éditeur, de sorte que la cohérence transactionnelle est garantie pour les publications au sein d’un même abonnement ; c’est ce qu’on appelle la réplication transactionnelle.
Les cas d’utilisation typiques de la réplication logique sont les suivants :
- Envoi des modifications incrémentielles d’une seule base de données (ou d’un sous-ensemble d’une base de données) aux abonnés au fur et à mesure qu’elles se produisent.
- Partage d’un sous-ensemble de la base de données entre plusieurs bases de données.
- Déclenchement de l’envoi de changements individuels au fur et à mesure qu’ils arrivent sur l’abonné.
- Consolidation de plusieurs bases de données en une seule.
- Fournir un accès aux données répliquées à différents groupes d’utilisateurs.
La base de données de l’abonné se comporte de la même manière que toute autre instance PostgreSQL et peut être utilisée comme éditeur pour d’autres bases de données en définissant ses publications.
Lorsque l’abonné est traité en lecture seule par l’application, il n’y aura pas de conflits à partir d’un seul abonnement. Par contre, s’il y a d’autres écritures effectuées soit par une application, soit par d’autres abonnés sur le même ensemble de tables, des conflits peuvent survenir.
PostgreSQL supporte les deux mécanismes simultanément. La réplication logique permet un contrôle fin à la fois de la réplication des données et de la sécurité.
Modes de réplication
Il existe principalement deux modes de réplication PostgreSQL : synchrone et asynchrone. La réplication synchrone permet d’écrire des données sur le serveur primaire et secondaire en même temps, tandis que la réplication asynchrone garantit que les données sont d’abord écrites sur l’hôte, puis copiées sur le serveur secondaire.
Dans la réplication en mode synchrone, les transactions sur la base de données primaire sont considérées comme terminées uniquement lorsque ces modifications ont été répliquées sur toutes les répliques. Les serveurs répliques doivent tous être disponibles en permanence pour que les transactions soient terminées sur le primaire. Le mode synchrone de réplication est utilisé dans les environnements transactionnels haut de gamme avec des exigences de basculement immédiat.
En mode asynchrone, les transactions sur le serveur primaire peuvent être déclarées complètes lorsque les changements ont été effectués sur le seul serveur primaire. Ces changements sont ensuite répliqués dans les répliques plus tard dans le temps. Les serveurs répliques peuvent rester désynchronisés pendant une certaine durée, appelée décalage de réplication. En cas de panne, une perte de données peut se produire, mais la surcharge fournie par la réplication asynchrone est faible, elle est donc acceptable dans la plupart des cas (elle ne surcharge pas l’hôte). Le basculement de la base de données primaire vers la base de données secondaire prend plus de temps que la réplication synchrone.
Comment configurer la réplication PostgreSQL
Dans cette section, nous allons montrer comment configurer le processus de réplication PostgreSQL sur un système d’exploitation Linux. Pour cette instance, nous utiliserons Ubuntu 18.04 LTS et PostgreSQL 10.
Commençons !
Installation
Vous commencerez par installer PostgreSQL sur Linux en suivant ces étapes :
- Tout d’abord, vous devez importer la clé de signature PostgreSQL en tapant la commande ci-dessous dans le terminal :
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Ensuite, ajoutez le référentiel PostgreSQL en saisissant la commande ci-dessous dans le terminal :
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Mettez à jour l’index du référentiel en tapant la commande suivante dans le terminal :
sudo apt-get update - Installez le paquet PostgreSQL en utilisant la commande apt :
sudo apt-get install -y postgresql-10 - Enfin, définissez le mot de passe de l’utilisateur PostgreSQL à l’aide de la commande suivante :
sudo passwd postgres
L’installation de PostgreSQL est obligatoire pour le serveur primaire et le serveur secondaire avant de lancer le processus de réplication PostgreSQL.
Une fois que vous avez configuré PostgreSQL pour les deux serveurs, vous pouvez passer à la configuration de la réplication du serveur primaire et du serveur secondaire.
Configuration de la réplication dans le serveur primaire
Effectuez ces étapes une fois que vous avez installé PostgreSQL sur les deux serveurs primaire et secondaire.
- Tout d’abord, connectez-vous à la base de données PostgreSQL à l’aide de la commande suivante :
su - postgres - Créez un utilisateur de réplication avec la commande suivante :
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Modifiez pg_hba.cnf avec n’importe quelle application nano dans Ubuntu et ajoutez la configuration suivante :
nano /etc/postgresql/10/main/pg_hba.confPour configurer le fichier, utilisez la commande suivante :
host replication replication MasterIP/24 md5 - Ouvrez et modifiez postgresql.conf et mettez la configuration suivante dans le serveur primaire :
nano /etc/postgresql/10/main/postgresql.confUtilisez les paramètres de configuration suivants :
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - Enfin, redémarrez PostgreSQL dans le serveur principal primaire :
systemctl restart postgresqlVous avez maintenant terminé la configuration dans le serveur primaire.
Configuration de la réplication dans le serveur secondaire
Suivez ces étapes pour configurer la réplication dans le serveur secondaire :
- Connectez-vous au SGBD PostgreSQL avec la commande ci-dessous :
su - postgres - Arrêtez le fonctionnement du service PostgreSQL pour nous permettre de travailler dessus avec la commande ci-dessous :
systemctl stop postgresql - Modifiez le fichier pg_hba.conf avec cette commande et ajoutez la configuration suivante :
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Ouvrez et modifiez postgresql.conf dans le serveur secondaire et mettez la configuration suivante ou décommentez-la si elle est commentée :
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPest l’adresse du serveur secondaire - Accédez au répertoire de données PostgreSQL dans le serveur secondaire et supprimez tout :
cd /var/lib/postgresql/10/main rm -rfv * - Copiez les fichiers du répertoire de données du serveur primaire PostgreSQL dans le répertoire de données du serveur secondaire PostgreSQL et écrivez cette commande dans le serveur secondaire :
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Saisissez le mot de passe PostgreSQL du serveur primaire et appuyez sur la touche Entrée. Ensuite, ajoutez la commande suivante pour la configuration de récupération :
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'</code>Ici,
YOUR_PASSWORDest le mot de passe de l’utilisateur de réplication dans le serveur primaire créé par PostgreSQL - Une fois le mot de passe défini, vous devrez redémarrer la base de données PostgreSQL secondaire puisqu’elle a été arrêtée :
systemctl start postgresqlTestez votre installation
Maintenant que nous avons effectué les étapes, testons le processus de réplication et observons la base de données du serveur secondaire. Pour cela, nous créons une table dans le serveur primaire et observons si la même chose se reflète sur le serveur secondaire.
Allons-y.
- Puisque nous créons la table dans le serveur primaire, vous devez vous connecter au serveur primaire :
su - postgres psql - Maintenant, nous créons une table simple nommée « testtable » et insérons des données dans la table en exécutant les requêtes PostgreSQL suivantes dans le terminal :
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observez la base de données PostgreSQL du serveur secondaire en vous connectant au serveur secondaire :
su - postgres psql - Maintenant, nous vérifions si la table « testtable » existe, et pouvons retourner les données en exécutant les requêtes PostgreSQL suivantes dans le terminal. Cette commande affiche essentiellement la table entière.
select * from testtable;
Voici la sortie de la table de test :
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Vous devriez être en mesure d’observer les mêmes données que celles du serveur primaire.
Si vous voyez ce qui précède, alors vous avez bien effectué le processus de réplication !
Quelles sont les étapes du basculement manuel PostgreSQL ?
Passons en revue les étapes d’un basculement manuel PostgreSQL :
- Crasher le serveur primaire.
- Promouvoir le serveur de secours en exécutant la commande suivante sur le serveur de secours :
./pg_ctl promote -D ../sb_data/ server promoting - Connectez-vous au serveur standby promu et insérez une rangée :
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Si l’insertion fonctionne bien, alors le standby, qui était auparavant un serveur en lecture seule, a été promu comme nouveau serveur primaire.
Comment automatiser le basculement dans PostgreSQL
La configuration du basculement automatique est simple.
Vous aurez besoin du gestionnaire de basculement EDB PostgreSQL (EFM). Après avoir téléchargé et installé EFM sur chaque nœud primaire et standby, vous pouvez créer un cluster EFM, qui se compose d’un nœud primaire, d’un ou plusieurs nœuds standby et d’un nœud témoin facultatif qui confirme les assertions en cas de défaillance.
EFM surveille en permanence la santé du système et envoie des alertes par e-mail en fonction des événements système. Lorsqu’une défaillance se produit, il bascule automatiquement sur le standby le plus récent et reconfigure tous les autres serveurs standby pour reconnaître le nouveau nœud primaire.
Il reconfigure également les équilibreurs de charge (tels que pgPool) et empêche le « split-brain » (lorsque deux noeuds pensent chacun être le noeud primaire) de se produire.
Résumé
En raison des grandes quantités de données, l’évolutivité et la sécurité sont devenues deux des critères les plus importants dans la gestion des bases de données, surtout dans un environnement transactionnel. Bien que nous puissions améliorer l’évolutivité verticalement en ajoutant plus de ressources/matériel aux nœuds existants, ce n’est pas toujours possible, souvent en raison du coût ou des limites de l’ajout de nouveau matériel.
Par conséquent, l’évolutivité horizontale est nécessaire, ce qui signifie ajouter plus de nœuds aux nœuds existants du réseau plutôt que d’améliorer la fonctionnalité des nœuds existants. C’est là que la réplication PostgreSQL entre en jeu.
Dans cet article, nous avons abordé les types de réplications PostgreSQL, les avantages, les modes de réplication, l’installation et le basculement PostgreSQL entre SMR et MMR. Maintenant, écoutons ce que vous avez à dire.
Laquelle implémentez-vous habituellement ? Quelle fonctionnalité de base de données est la plus importante pour vous et pourquoi ? Nous serions ravis de lire vos réflexions ! Partagez-les dans la section des commentaires ci-dessous.

Salman Ravoof est un développeur web autodidacte, un écrivain, un créateur et un grand admirateur des logiciels libres. Outre la technologie, il est passionné par la science, la philosophie, la photographie, les arts, les chats et la nourriture. Apprenez-en plus sur son site web, et connectez-vous avec Salman sur X.

