
Node.js è un runtime JavaScript lato server che utilizza un modello di input-output (I/O) non bloccante e guidato dagli eventi. È ampiamente riconosciuto per la creazione di applicazioni web veloci e scalabili. Ha anche una grande community e una ricca libreria di moduli che semplificano diversi compiti e processi.
Il clustering migliora le prestazioni delle applicazioni Node.js consentendo loro di essere eseguite su più processi. Questa tecnica consente di sfruttare appieno il potenziale di un sistema multi-core.
Questo articolo offre una panoramica completa sul clustering in Node.js e su come influisce sulle prestazioni di un’applicazione.
Cos’è il clustering?
Per impostazione predefinita, le applicazioni Node.js vengono eseguite su un singolo thread. Questa natura a thread singolo significa che Node.js non può utilizzare tutti i core di un sistema multi-core, come avviene attualmente nella maggior parte dei sistemi.
Node.js può comunque gestire più richieste contemporaneamente sfruttando le operazioni di I/O non bloccanti e le tecniche di programmazione asincrona.
Tuttavia, le attività di calcolo pesanti possono bloccare il ciclo degli eventi e causare la mancata risposta dell’applicazione. Di conseguenza, Node.js è dotato di un modulo cluster nativo – a prescindere dalla sua natura single-thread – per sfruttare la potenza di elaborazione totale di un sistema multi-core.
L’esecuzione di più processi sfrutta la potenza di elaborazione di più core dell’unità di elaborazione centrale (CPU) per consentire l’elaborazione parallela, ridurre i tempi di risposta e aumentare il throughput. Questo, a sua volta, migliora le prestazioni e la scalabilità delle applicazioni Node.js.
Come funziona il clustering?
Il modulo cluster di Node.js permette a un’applicazione Node.js di creare un cluster di processi figli in esecuzione simultanea, ognuno dei quali gestisce una parte del carico di lavoro dell’applicazione.
Al momento dell’inizializzazione del modulo cluster, l’applicazione crea il processo primario, che poi divide i processi figli in processi worker. Il processo primario agisce come bilanciatore di carico, distribuendo il carico di lavoro ai processi worker mentre ogni processo worker attende le richieste in arrivo.
Il modulo cluster di Node.js ha due metodi per distribuire le connessioni in entrata.
- L’approccio round-robin: il processo primario ascolta su una porta, accetta le nuove connessioni e distribuisce uniformemente il carico di lavoro per garantire che nessun processo sia sovraccarico. Questo è l’approccio predefinito su tutti i sistemi operativi tranne Windows.
- Il secondo approccio: il processo primario crea il socket di ascolto e lo invia ai worker “interessati”, che accettano direttamente le connessioni in arrivo.
In teoria, il secondo approccio, più complicato, dovrebbe garantire prestazioni migliori. In pratica, però, la distribuzione delle connessioni è molto sbilanciata. La documentazione di Node.js indica che il 70% di tutte le connessioni finisce in soli due processi su otto.
Come clusterizzare le applicazioni Node.js
Ora esaminiamo gli effetti del clustering in un’applicazione Node.js. Questo tutorial utilizza un’applicazione Express che esegue intenzionalmente un’attività di calcolo pesante per bloccare il ciclo degli eventi.
Per prima cosa, eseguiremo questa applicazione senza clustering. Poi, registreremo le prestazioni con uno strumento di benchmarking. Successivamente, il clustering verrà implementato nell’applicazione e il benchmarking verrà ripetuto. Infine, confronteremo i risultati per vedere come il clustering è in grado di migliorare le prestazioni dell’applicazione.
Come iniziare
Per seguire questo tutorial, è necessario avere familiarità con Node.js ed Express. Per configurare il nostro server Express:
- Iniziamo creando il progetto.
mkdir cluster-tutorial - Navighiamo nella directory dell’applicazione e creiamo due file, no-cluster.js e cluster.js, eseguendo questo comando:
cd cluster-tutorial && touch no-cluster.js && touch cluster.js - Inizializziamo NPM nel nostro progetto:
npm init -y - Infine, installiamo Express eseguendo questo comando:
npm install express
Creare un’applicazione non cluster
Nel file no-cluster.js, aggiungiamo il blocco di codice sottostante:
const express = require("express");
const PORT = 3000;
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
//Start timer
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});Il blocco di codice precedente crea un server express che gira sulla porta 3000. Il server ha due percorsi, un percorso root (/) e un percorso /slow. La route principale invia una risposta al client con il messaggio: “Risposta dal server”.
Tuttavia, la route /slow esegue intenzionalmente alcuni calcoli pesanti per bloccare il ciclo degli eventi. Questo percorso avvia un timer e poi riempie un array con 100.000 numeri casuali utilizzando un ciclo for.
Poi, usando un altro ciclo for, eleva al quadrato ogni numero dell’array generato e li somma. Il timer termina al termine dell’operazione e il server risponde con i risultati.
Avviamo il server eseguendo il comando:
node no-cluster.jsPoi facciamo una richiesta GET a localhost:3000/slow.
Durante questo frangente, se proviamo a fare altre richieste al server, ad esempio alla route principale (/), le risposte sono lente perché la route /slow sta bloccando il ciclo degli eventi.
Creare un’applicazione clusterizzata
Creiamo dei processi figli utilizzando il modulo cluster per evitare che l’applicazione diventi poco reattiva e che le richieste successive vadano in stallo durante le attività di calcolo più pesanti.
Ogni processo figlio esegue il proprio ciclo di eventi e condivide la porta del server con il processo genitore, consentendo un migliore utilizzo delle risorse disponibili.
Per prima cosa, importiamo il modulo Node.js cluster e os nel file cluster.js. Il modulo cluster consente di creare processi figli per distribuire il carico di lavoro su più core della CPU.
Il modulo os fornisce informazioni sul sistema operativo del nostro computer. Questo modulo serve per recuperare il numero di core disponibili sul sistema e per assicurarci di non creare più processi figli rispetto ai core presenti sul nostro sistema.
Aggiungiamo il blocco di codice qui sotto per importare questi moduli e recuperare il numero di core presenti sul sistema:
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;Successivamente, aggiungiamo il blocco di codice sottostante al file cluster.js:
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
}Il blocco di codice qui sopra controlla se il processo corrente è il processo primario o il processo worker. Se è vero, il blocco di codice genera processi figli in base al numero di core presenti nel sistema. Successivamente, ascolta l’evento di uscita dei processi e li sostituisce generando nuovi processi.
Infine, racchiudiamo tutta la logica express in un blocco else. Il file cluster.js finito dovrebbe essere simile al blocco di codice qui sotto.
//cluster.js
const express = require("express");
const PORT = 3000;
const cluster = require("node:cluster");
const numCores = require("node:os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
console.log(`This machine has ${numCores} cores`);
// Fork workers.
for (let i = 0; i {
console.log(`worker ${worker.process.pid} died`);
// Replace the dead worker
console.log("Starting a new worker");
cluster.fork();
});
} else {
const app = express();
app.get("/", (req, res) => {
res.send("Response from server");
});
app.get("/slow", (req, res) => {
console.time("slow");
// Generate a large array of random numbers
let arr = [];
for (let i = 0; i < 100000; i++) {
arr.push(Math.random());
}
// Perform a heavy computation on the array
let sum = 0;
for (let i = 0; i {
console.log(`Server listening on port ${PORT}`);
});
}Dopo aver implementato il clustering, più processi gestiranno le richieste. Ciò significa che l’applicazione rimarrà reattiva anche durante un’attività di calcolo pesante.
Come fare un benchmark delle prestazioni con loadtest
Per dimostrare e visualizzare con precisione gli effetti del clustering in un’applicazione Node.js, usiamo il pacchetto npm loadtest per confrontare le prestazioni dell’applicazione prima e dopo il clustering.
Eseguiamo il comando qui sotto per installare loadtest a livello globale:
npm install -g loadtestIl pacchetto loadtest esegue un test di carico su un URL HTTP/WebSockets specificato.
Quindi, avviamo il file no-cluster.js su un’istanza del terminale. Poi, apriamo un’altra istanza di terminale ed eseguiamo il test di carico qui sotto:
loadtest http://localhost:3000/slow -n 100 -c 10Il comando precedente invia 100 richieste con una concurrency di 10 all’applicazione non clusterizzata. L’esecuzione di questo comando produce i risultati riportati di seguito:
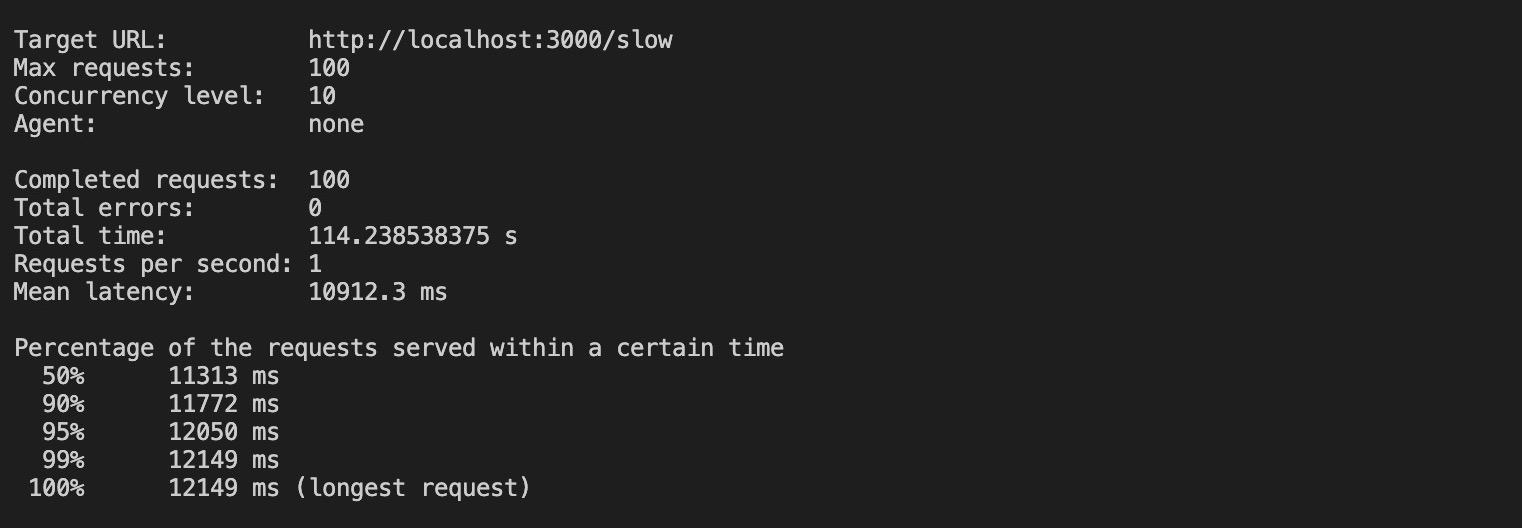
In base ai risultati, sono stati necessari circa 100 secondi per completare tutte le richieste senza clustering e la richiesta più estesa ha richiesto fino a 12 secondi.
I risultati variano in base al proprio sistema.
Successivamente, interrompiamo l’esecuzione del file no-cluster.js e avviamo il file cluster.js su un’istanza del terminale. Quindi, apriamo un’altra istanza di terminale ed eseguiamo questo test di carico:
loadtest http://localhost:3000/slow -n 100 -c 10Il comando qui sopra invierà all’applicazione in cluster 100 richieste con una concurrency 10.
L’esecuzione di questo comando produce i risultati riportati di seguito:
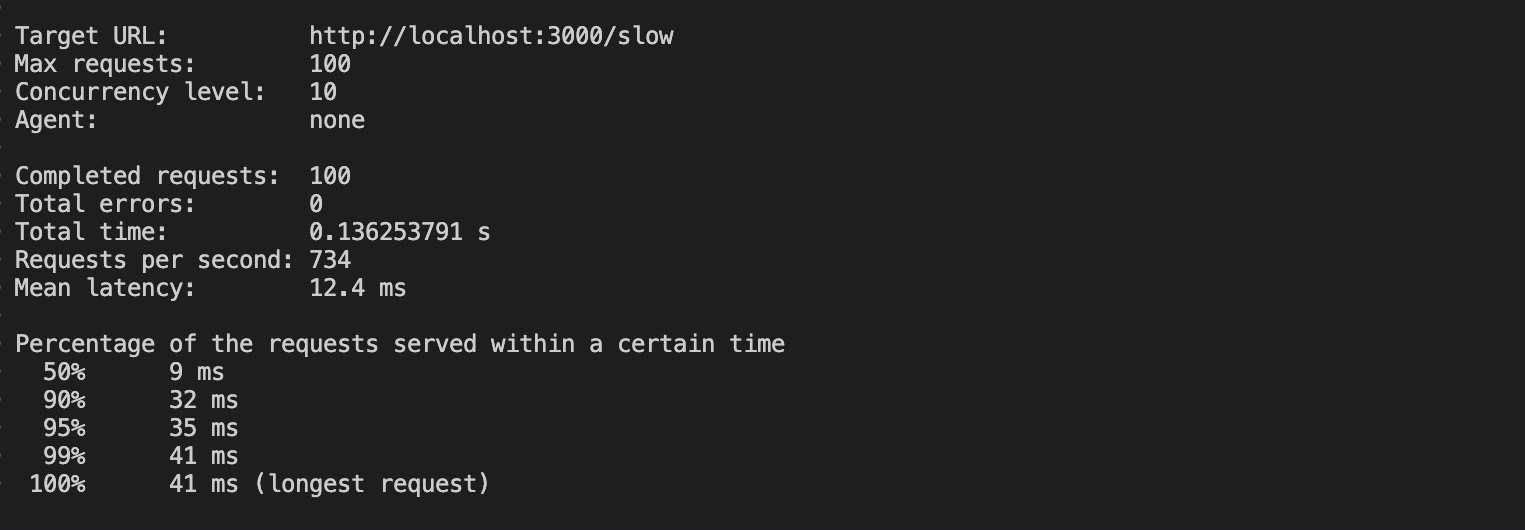
Con il clustering, le richieste hanno impiegato 0,13 secondi (136 ms) per essere completate, un’enorme riduzione rispetto ai 100 secondi richiesti dall’app non clusterizzata. Inoltre, la richiesta più lunga dell’app in cluster ha richiesto 41 ms per essere completata.
Questi risultati dimostrano che l’implementazione del clustering migliora significativamente le prestazioni dell’applicazione. Tenete presente che dovreste utilizzare un software di gestione dei processi come PM2 per gestire il clustering negli ambienti di produzione.
Utilizzare Node.js con l’Hosting di Applicazioni di Kinsta
Kinsta è una società di hosting che semplifica la distribuzione delle applicazioni Node.js. La sua piattaforma di hosting è costruita su Google Cloud Platform, che fornisce un’infrastruttura affidabile progettata per gestire un traffico elevato e supportare applicazioni complesse. In definitiva, questo migliora le prestazioni delle applicazioni Node.js.
Kinsta offre diverse funzionalità per le implementazioni Node.js, come le connessioni al database interno, l’integrazione con Cloudflare, le implementazioni GitHub e le Google C2 Machines.
Queste funzionalità semplificano la distribuzione e la gestione delle applicazioni Node.js e snelliscono il processo di sviluppo.
Per distribuire la vostra applicazione Node.js sull’Hosting di Applicazioni di Kinsta, è fondamentale inviare il codice e i file dell’applicazione al provider Git scelto (Bitbucket, GitHub o GitLab).
Una volta impostato il repository, seguite i passaggi qui sotto per distribuire la vostra applicazione Express su Kinsta:
- Accedete o create un account per visualizzare la dashboard MyKinsta.
- Autorizzate Kinsta con il vostro provider Git.
- Cliccate su Applicazioni nella barra laterale di sinistra, quindi su Aggiungi applicazione.
- Selezionate il repository e il branch da cui desiderate effettuare il deploy.
- Assegnate un nome unico all’applicazione e scegliete la posizione del Data Center.
- Configurate poi l’ambiente di build. Selezionate la configurazione della build machine standard con l’opzione Nixpacks consigliata per questa demo.
- Usate tutte le configurazioni predefinite e poi cliccate su Crea applicazione.
Riepilogo
Il clustering in Node.js consente di creare più processi worker per distribuire il carico di lavoro, migliorando le prestazioni e la scalabilità delle applicazioni Node.js. La corretta implementazione del clustering è fondamentale per sfruttare appieno il potenziale di questa tecnica.
La progettazione dell’architettura, la gestione dell’allocazione delle risorse e la minimizzazione della latenza di rete sono fattori vitali per l’implementazione del clustering in Node.js. L’importanza e la complessità di questa implementazione sono il motivo per cui i process manager come PM2 dovrebbero essere utilizzati negli ambienti di produzione.
Cosa ne pensate del clustering in Node.js? L’avete già utilizzato? Fatecelo sapere condividendolo nella sezione commenti!


