
I siti web non sono costruiti solo per pubblicare contenuti e i metadati non sono messi a punto per divertimento; tutte queste attività lavorano insieme per far sì che le tue pagine possano essere scoperte più facilmente. Per anni, Google Search è stata la porta d’accesso principale a questa visibilità, grazie soprattutto ai suoi crawler web.
Dalla fine degli anni ’90, Googlebot e altri crawler tradizionali hanno scansionato i siti web, recuperato le pagine HTML e le hanno indicizzate per aiutare le persone a trovare ciò che cercano. A gennaio 2024, Google rappresentava il 63% di tutto il traffico web degli Stati Uniti, guidato dai 170 domini principali.
Ma ora, secondo un’indagine di McKinsey, la metà dei clienti si rivolge a strumenti di intelligenza artificiale come ChatGPT, Claude, Gemini o Perplexity per ottenere risposte immediate, e persino Google sta inserendo i riassunti generati dall’intelligenza artificiale nei risultati di ricerca grazie a funzioni come AI Overviews.
Dietro a queste nuove esperienze guidate dall’intelligenza artificiale c’è una classe crescente di bot noti come crawler AI. Se gestisci un sito WordPress, capire come questi crawler accedono e utilizzano i tuoi contenuti è più importante che mai.
Cosa sono gli AI crawler?
Gli AI crawler sono bot automatizzati che scansionano le pagine web accessibili al pubblico, simili ai crawler dei motori di ricerca, ma con uno scopo diverso. Invece di indicizzare le pagine per il ranking tradizionale, raccolgono contenuti per addestrare modelli linguistici di grandi dimensioni o per fornire nuove informazioni alle risposte generate dall’intelligenza artificiale.
In linea di massima, gli AI crawler si dividono in due gruppi:
- I crawler di formazione, come GPTBot (OpenAI) e ClaudeBot (Anthropic), raccolgono dati per insegnare ai modelli linguistici di grandi dimensioni come rispondere alle domande in modo più accurato.
- I crawler di recupero in tempo reale, come ChatGPT-User, accedono ai siti web in tempo reale quando qualcuno chiede qualcosa che richiede dati aggiornati, come controllare la descrizione di un prodotto o leggere la documentazione.
Altri crawler, come PerplexityBot o AmazonBot, stanno costruendo i propri indici o sistemi per ridurre la loro dipendenza da fonti di terze parti. Sebbene i loro obiettivi siano diversi, hanno tutti una cosa in comune: recuperano e leggono i contenuti di siti web come il tuo.
Come funzionano gli AI crawler
Quando un crawler di intelligenza artificiale visita il tuo sito, in genere esegue le seguenti operazioni:
- Invia una richiesta GET di base all’URL della pagina (senza interazione, scorrimento o eventi DOM).
- Recupera solo l’HTML iniziale restituito dal server. Non attende il caricamento o l’esecuzione di JavaScript lato client.
- Estrae tutti i link a
<a href="">,<img src="">,<script src="">e altre risorse, quindi aggiunge gli URL interni (e talvolta esterni) alla sua coda di crawl. In molti casi, colpisce anche i link non funzionanti che restituiscono errori 404. - Può tentare di recuperare risorse collegate come immagini, file CSS o script, ma solo come risorse grezze, non per renderizzare la pagina.
- Ripete questo processo in modo ricorsivo sui link scoperti per mappare il sito.
Come i crawler AI interagiscono con i siti web WordPress
WordPress è una piattaforma renderizzata su server che utilizza PHP per generare pagine HTML complete prima di inviarle al browser. Quando un crawler visita un sito WordPress, di solito ottiene tutto ciò di cui ha bisogno (contenuti, titoli, metadati, navigazione) nella risposta HTML.
Questa struttura renderizzata dal server rende la maggior parte dei siti WordPress naturalmente crawler-friendly. Che si tratti di Googlebot o di un crawler AI, di solito possono scansionare il tuo sito e comprenderne facilmente i contenuti. Infatti, i contenuti facilmente scansionabili sono uno dei motivi per cui WordPress ottiene buoni risultati sia con la ricerca tradizionale che con le più recenti piattaforme basate sull’intelligenza artificiale.
È necessario permettere ai crawler dell’intelligenza artificiale di accedere ai propri contenuti?
I crawler dell’intelligenza artificiale possono già leggere la maggior parte dei siti WordPress per impostazione predefinita. La vera domanda è a cosa vuoi che accedano e come poter controllare questa visibilità.
Le aziende orientate ai contenuti sono in fermento in questo momento. L’argomento si estende ai post del blog, alla documentazione, alle landing page… a tutto ciò che viene scritto per il web. Probabilmente avrai sentito consigli del tipo “scrivi per le macchine”, dal momento che le piattaforme di intelligenza artificiale raccolgono sempre più dati in tempo reale e, in alcuni casi, includono anche link alle fonti. Tutti noi vogliamo apparire nei risultati di LLM, così come vogliamo apparire nei risultati di ricerca di Google.
Ad esempio, nella schermata qui sotto, chiediamo a ChatGPT di indicarci alcune delle ultime funzionalità rilasciate da Kinsta. ChatGPT cerca sul web, analizza i changelog e le pagine collegate e fornisce una risposta sintetica con link diretti alla fonte.
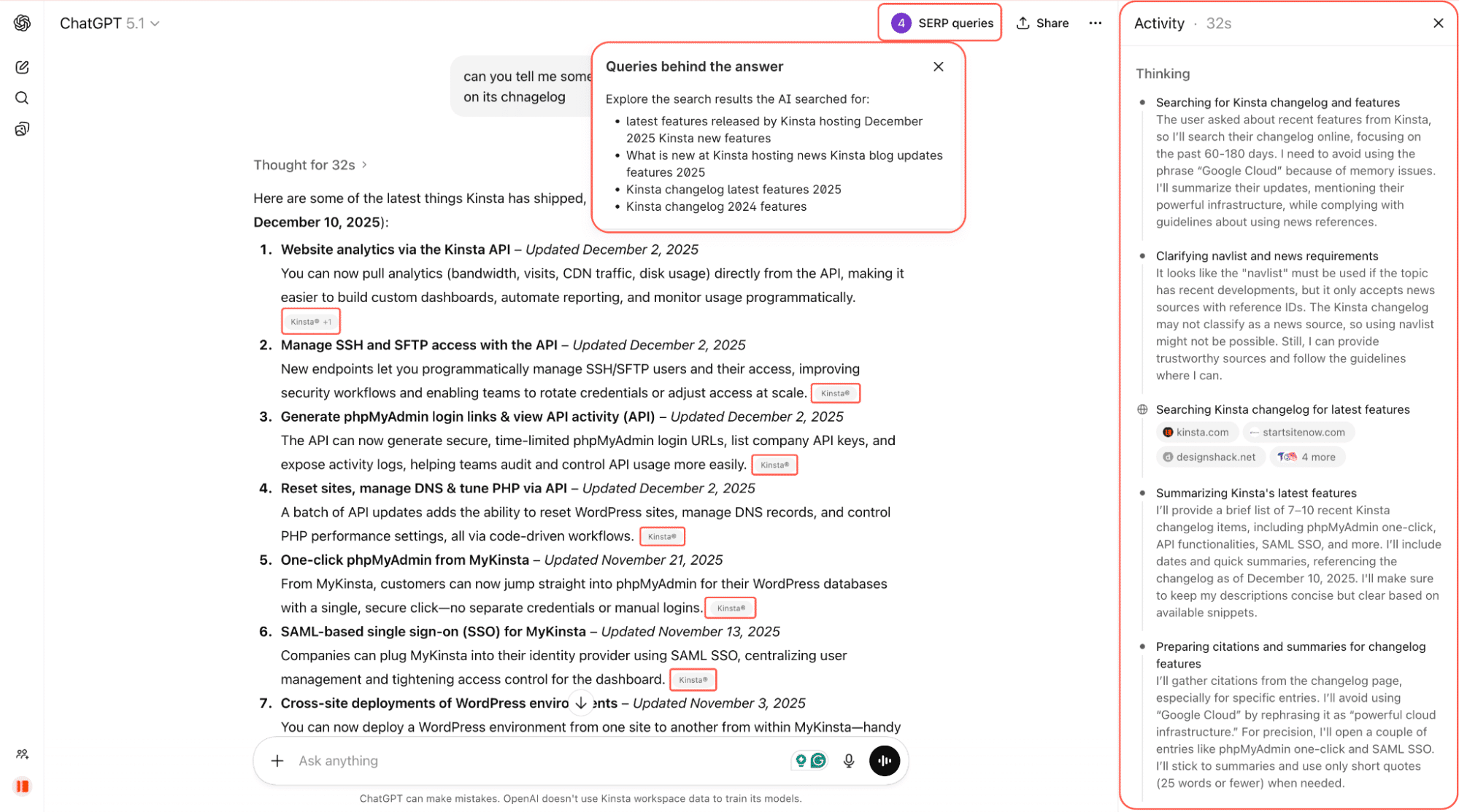
È ancora presto, ma i crawler dell’AI influenzano già ciò che le persone vedono quando fanno domande online. E questa diffusione potrebbe rivelarsi importante.
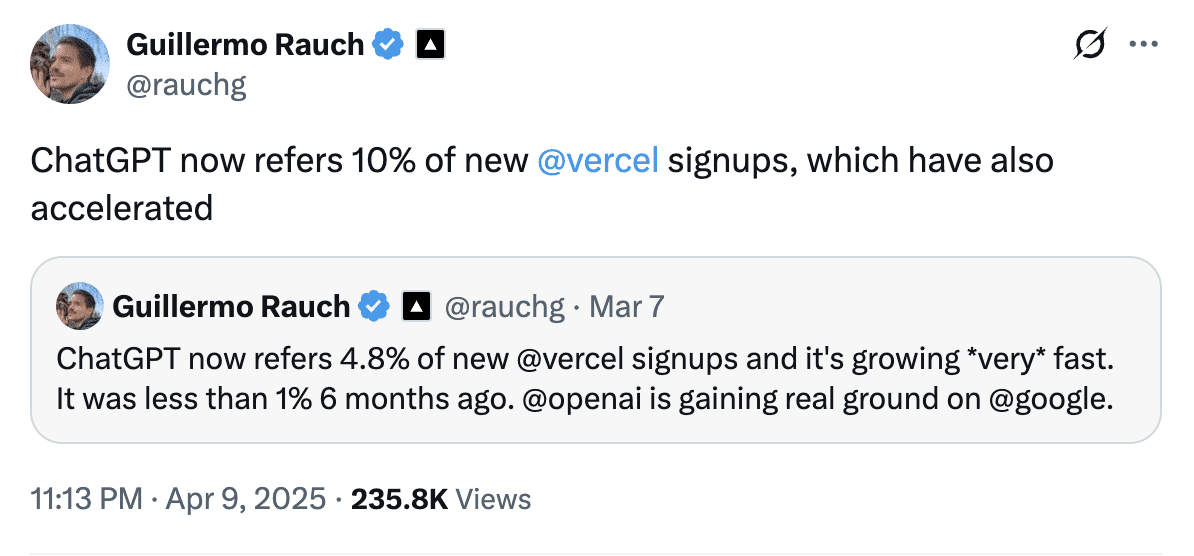
Guillermo Rauch, CEO di Vercel, ha dichiarato ad aprile che ChatGPT rappresenta quasi il 10% delle nuove iscrizioni a Vercel, rispetto a meno dell’1% di sei mesi prima. Questo dimostra quanto velocemente i referral guidati dall’intelligenza artificiale possano evolvere in un canale di acquisizione significativo.
I crawler AI sono molto diffusi. Secondo Cloudflare, i bot AI hanno avuto accesso a circa il 39% del primo milione di siti web, ma solo il 3% di questi siti ha effettivamente bloccato o contestato il traffico.
Quindi, anche se non hai ancora preso una decisione, quasi sicuramente i crawler AI stanno già visitando il tuo sito.
È meglio consentire o bloccare i crawler AI?
Non esiste una risposta univoca. Non c’è una risposta universale, ma ecco un quadro di riferimento:
- Blocca i crawler su percorsi sensibili o di scarso valore come
/login,/checkout,/admin, o dashboard. Questi non aiutano la scoperta e sprecano solo larghezza di banda. - Consenti i crawler sui “contenuti di scoperta” come i post del blog, la documentazione, le pagine dei prodotti e le informazioni sui prezzi. Queste pagine sono quelle che hanno maggiori probabilità di essere citate nelle risposte dell’AI e di generare traffico qualificato.
- Decidi strategicamente per i contenuti premium o gated. Se i tuoi contenuti sono il tuo prodotto (ad esempio, notizie, ricerche, corsi), l’accesso illimitato all’IA può compromettere la tua attività.
Stanno nascendo nuovi strumenti per aiutarti. Cloudflare, ad esempio, sta sperimentando un modello chiamato Pay Per Crawl, che consente ai proprietari dei siti di far pagare l’accesso alle aziende di intelligenza artificiale. È ancora in fase di beta privata e l’adozione nel mondo reale è ancora agli inizi, ma l’idea ha ottenuto un forte sostegno da parte dei grandi editori che vogliono avere un maggiore controllo sull’utilizzo dei loro contenuti.
Altri esponenti della comunità della ricerca e del marketing sono più cauti, in quanto il blocco predefinito potrebbe ridurre involontariamente la visibilità nei risultati di ricerca dell’intelligenza artificiale per i siti che desiderano effettivamente ottenere visibilità. Per ora si tratta di un esperimento promettente piuttosto che di un flusso di entrate mature.
Fino a quando questi sistemi non matureranno, l’approccio più pratico è quello dell’apertura selettiva, in cui si mantiene il crawling dei contenuti di scoperta, si bloccano le aree sensibili e si rivedono le regole in base all’evoluzione dell’ecosistema.
Come controllare l’accesso dei crawler AI su WordPress
Se non ti piace l’idea che i crawler dell’intelligenza artificiale accedano al tuo sito WordPress e ne scansionino i contenuti, la buona notizia è che puoi riprendere tu il controllo.
Ecco tre modi per gestire l’accesso dei crawler AI su WordPress:
- Modificare manualmente il file
robots.txt. - Usare un plugin che lo faccia per te.
- Usare la protezione bot di Cloudflare.
Vediamo tutte e tre le opzioni.
Opzione 1: bloccare manualmente i crawler AI con robots.txt
Il file robots.txt indica ai bot quali parti del sito sono autorizzati a visitare. La maggior parte dei crawler AI noti, come GPTBot di OpenAI, Claude-Web di Anthropic e Google-Extended, rispettano queste regole.
Puoi bloccare completamente determinati bot, consentire loro l’accesso completo o limitare l’accesso a determinate sezioni del sito. Ad esempio, per bloccare tutto, puoi aggiungere questa opzione al file robots.txt, anche se non è consigliabile per la maggior parte dei siti:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Google-Extended
Disallow: /Per consentire l’accesso completo al GPTBot di OpenAI:
User-agent: GPTBot
Disallow:Per impedire l’accesso a una sola sezione del tuo sito al GPTBot di OpenAI. Ad esempio, la pagina di login, dove i crawler non aggiungono alcun valore:
User-agent: GPTBot
Disallow: /login/Questo tipo di blocco selettivo è fondamentale. I percorsi sensibili come /login, /checkout o /admin non aiutano la scopribilità e dovrebbero essere quasi sempre bloccati. D’altro canto, le pagine dei prodotti, le panoramiche delle funzionalità o il centro assistenza sono ottimi candidati per essere aperti ai crawler, in quanto possono generare citazioni e rinvii.
Puoi aggiungere manualmente il file robots.txt con le seguenti modalità:
- Utilizzando un plugin SEO come Yoast (Strumenti > Editor di file).
- Utilizzando un plugin per la gestione dei file come WP File Manager.
- Oppure modificando il file
robots.txtdirettamente sul server tramite FTP.
Opzione 2: utilizzare un plugin per WordPress
Se preferisci evitare di modificare direttamente il file robots.txt o semplicemente vuoi un modo più veloce e sicuro per gestire l’accesso dell’AI crawler, i plugin possono fare questo lavoro per te con pochi clic.
Raptive Ads
Il plugin WordPress Raptive Ads include un supporto integrato per bloccare i crawler AI:
- Puoi scegliere quali bot bloccare direttamente dalle impostazioni del plugin.
- La maggior parte dei bot AI (come GPTBot e Claude) sono bloccati per impostazione predefinita.
- Google-Extended non è bloccato per impostazione predefinita, ma puoi selezionare la casella se vuoi escludere l’addestramento AI di Google.
Uno dei vantaggi principali dell’utilizzo di questo plugin è che il blocco di Google-Extended non influisce sul tuo posizionamento su Google o sulla visibilità nei risultati di ricerca regolari.
Block AI Crawlers
Il plugin Block AI Crawlers è stato creato appositamente per dare ai proprietari di siti WordPress un maggiore controllo sulle modalità di interazione dei crawler AI con i loro contenuti. Ecco come fare:
- Blocca 75+ bot AI conosciuti aggiungendo automaticamente le giuste regole
Disallowal sitorobots.txt. - Non è richiesta alcuna configurazione. Installa il plugin, vai su Impostazioni > Lettura e seleziona la casella Block AI Crawlers.
- Leggero e open-source, con aggiornamenti periodici da GitHub.
- Progettato per funzionare subito sulla maggior parte delle installazioni di WordPress.
Il plugin Block AI Crawlers è uno dei modi più semplici per tenere lontani i bot AI indesiderati dal sito, soprattutto se non utilizzi plugin SEO avanzati.
Opzione 3: utilizza il blocco dei bot AI di Cloudflare con un solo clic
Se il tuo sito WordPress utilizza Cloudflare (e molti lo fanno), puoi bloccare decine di bot AI conosciuti e sconosciuti con un solo clic.
A metà del 2024, Cloudflare ha lanciato una funzione dedicata agli AI Scrapers e Crawlers, disponibile anche sul piano gratuito. Questa funzione non si basa solo su robots.txt; blocca i bot a livello di rete, anche quelli che mentono sulla propria identità.
Puoi attivarla procedendo come segue:
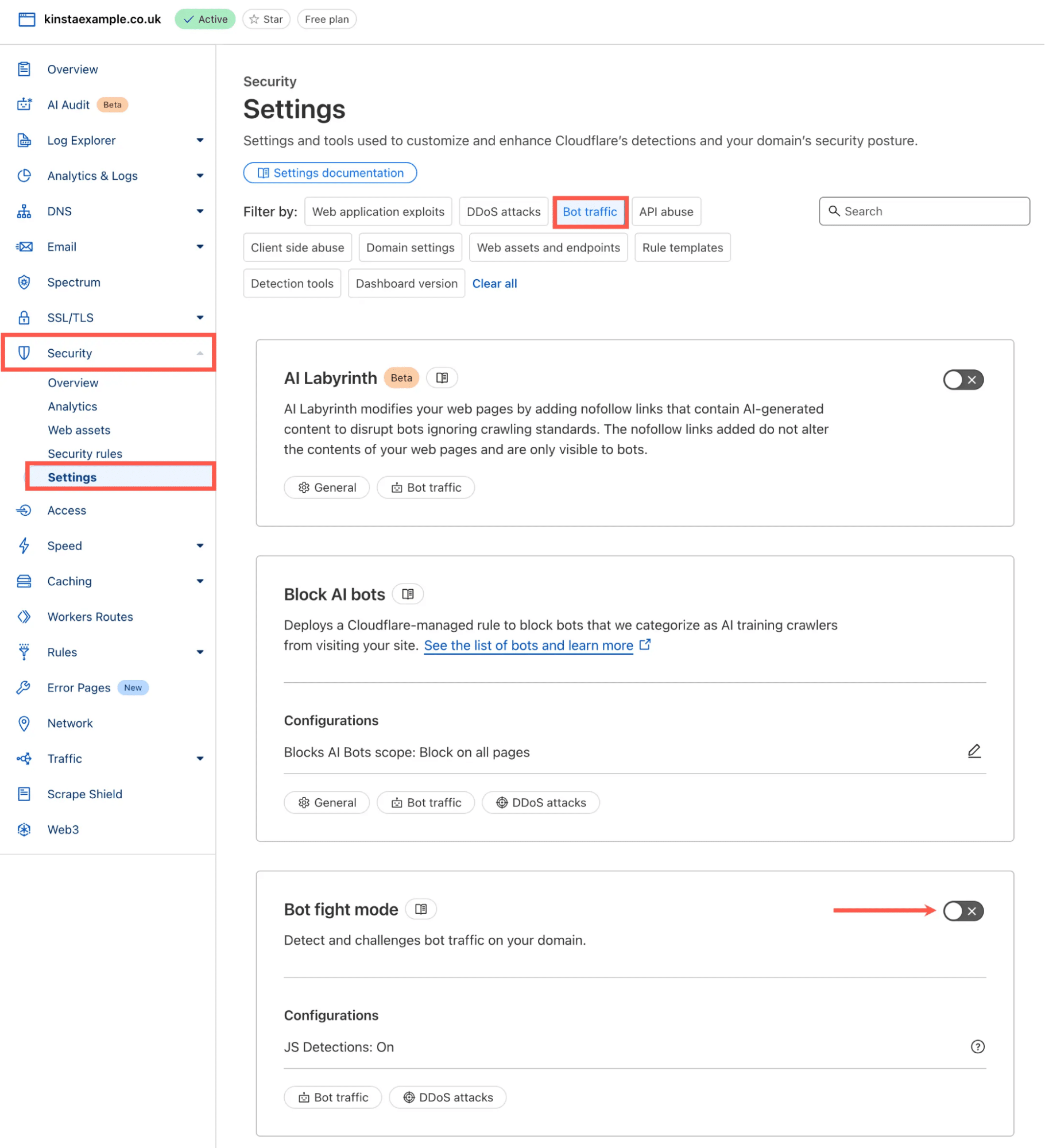
- Accedi alla tua dashboard Cloudflare
- Vai su Sicurezza > Impostazioni
- Nella sezione Filtra per, seleziona Traffico bot.
- Trova la modalità di lotta ai bot e attivala.
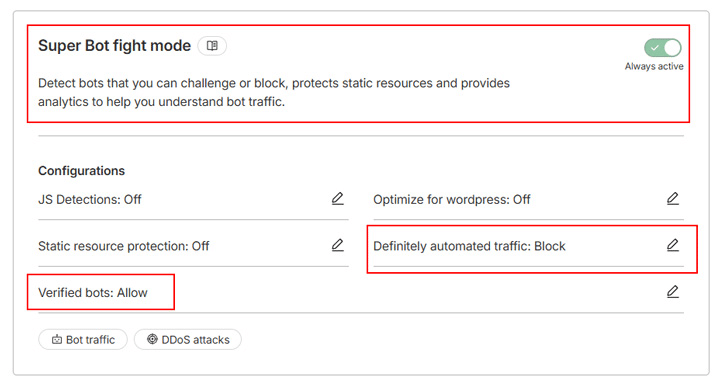
Se utilizzi un piano Cloudflare a pagamento, hai accesso alla modalità lotta ai Super Bot, una versione migliorata della modalità lotta ai bot, con maggiore flessibilità. Si basa sulla stessa tecnologia ma permette di scegliere come gestire diversi tipi di traffico, abilitando i rilevamenti JavaScript per catturare i browser headless, gli scraper stealthy e altro traffico dannoso.
Ad esempio, invece di bloccare tutti i crawler, puoi configurare lo strumento in modo da bloccare solo il “traffico sicuramente automatizzato” e consentire i “bot verificati” come i crawler dei motori di ricerca:
Ecco come funziona. Cloudflare blocca automaticamente le richieste dei bot AI.
Se vuoi approfondire il funzionamento di questi strumenti, tra cui la modalità lotta ai bot, la modalità lotta ai Super Bot e le regole di sicurezza mirate, puoi leggere la nostra guida completa su come proteggere un sito WordPress dal traffico bot indesiderato con Cloudflare.
Cosa significa questo cambiamento per il tuo sito WordPress
I crawler AI fanno ormai parte del modo in cui le persone scoprono le informazioni online. La tecnologia è nuova, le regole si stanno ancora formando e i proprietari dei siti stanno decidendo quanto dei loro contenuti vogliono rendere disponibili.
La buona notizia è che i siti WordPress sono già in una posizione di forza. Dato che WordPress produce un HTML completamente renderizzato, la maggior parte dei crawler AI è in grado di interpretare i tuoi contenuti in modo chiaro senza doverli gestire in modo particolare. La vera decisione strategica non è se i crawler dell’intelligenza artificiale possono accedere al tuo sito, ma quanto l’accesso potrà aiutare i tuoi obiettivi.
Inoltre, con l’evoluzione del mix di tipi di traffico, è utile disporre di opzioni di hosting che rendano l’utilizzo delle risorse più facile da comprendere e gestire. I nuovi piani basati sulla larghezza di banda di Kinsta offrono un modo più prevedibile per tenere conto del trasferimento totale dei dati, indipendentemente dalla fonte delle richieste. In combinazione con le protezioni bot di Cloudflare e con le tue regole di crawler, hai il pieno controllo sulle modalità di accesso al tuo sito.


