
Avete mai sentito il termine robots.txt e vi siete mai chiesti cosa ha a che fare con il vostro sito web? La maggior parte dei siti web ha un file robots.txt, ma questo non significa che la maggior parte dei proprietari di siti web capisca come funzioni. In questo post speriamo di cambiare questa situazione, offrendo un approfondimento sul file robots.txt di WordPress e su come può controllare e limitare l’accesso al vostro sito.
C’è molto da dire, quindi iniziamo!
Cos’è il file robots.txt di WordPress?
Prima di parlare del file robots.txt di WordPress, è importante definire cosa sia un “robot” in questo caso. I robot sono qualsiasi tipo di “bot” che visita i siti web su Internet. L’esempio più comune sono i crawler dei motori di ricerca. Questi bot “strisciano” sul web per aiutare i motori di ricerca come Google a indicizzare e classificare i miliardi di pagine presenti su Internet.
In generale, quindi, i bot sono una buona cosa per Internet… o almeno una cosa necessaria. Ma ciò non significa necessariamente che voi, o altri proprietari di siti, vogliate che i bot girino liberamente. Il desiderio di controllare il modo in cui i web robot interagiscono con i siti web ha portato alla creazione dello standard di esclusione dei robot a metà degli anni Novanta. Il file Robots.txt è l’implementazione pratica di questo standard: permette di controllare il modo in cui i bot partecipanti interagiscono con il vostro sito. Potete bloccare completamente i bot, limitare il loro accesso a determinate aree del vostro sito e altro ancora.
La parte “partecipante” è importante, però. Il file Robots.txt non può obbligare un bot a seguire le sue direttive. Inoltre, i bot malintenzionati possono ignorare il file robots.txt. Inoltre, anche le organizzazioni più affidabili ignorano alcuni comandi che è possibile inserire nel file robots.txt. Ad esempio, Google ignorerà qualsiasi regola aggiunta al file robots.txt sulla frequenza delle visite dei suoi crawler.
Se avete molti problemi con i bot, una soluzione di sicurezza come Cloudflare o Sucuri può esserti utile.
Come trovare il file robots.txt?
Il file robots.txt si trova nella root del vostro sito web, quindi aggiungendo /robots.txt dopo il vostro dominio dovreste caricare il file (se ne avete uno). Ad esempio, https://kinsta.com/robots.txt.
Quando usare un file robots.txt?
Per la maggior parte dei proprietari di siti, i vantaggi di un file robots.txt ben strutturato si riducono a due categorie:
- Ottimizzare le risorse di crawl dei motori di ricerca, indicando loro di non perdere tempo sulle pagine che non volete che vengano indicizzate. Questo aiuta a garantire che i motori di ricerca si concentrino sul crawling delle pagine a cui tenete di più.
- Ottimizzare l’utilizzo del server bloccando i bot che sprecano risorse.
Il Robots.txt non è specifico per controllare quali pagine vengono indicizzate dai motori di ricerca
Il file Robots.txt non è un modo infallibile per controllare quali pagine vengono indicizzate dai motori di ricerca. Se il vostro obiettivo principale è quello di impedire che alcune pagine vengano incluse nei risultati dei motori di ricerca, l’approccio corretto è quello di utilizzare un tag meta noindex o una password di protezione.
Questo perché il vostro robots.txt non dice direttamente ai motori di ricerca di non indicizzare i contenuti, ma dice loro di non scansionarli. Sebbene Google non effettuerà il crawling delle aree contrassegnate all’interno del vostro sito, Google stesso afferma che se un sito esterno rimanda a una pagina che avete escluso con il file robots.txt, Google potrebbe comunque indicizzare quella pagina.
Anche John Mueller, un analista per i webmaster di Google, ha confermato che se una pagina ha dei link che puntano ad essa, anche se è bloccata dal file robots.txt, potrebbe comunque essere indicizzata. Di seguito riportiamo ciò che ha detto in un hangout di Webmaster Central:
Una cosa da tenere presente è che se queste pagine sono bloccate da robots.txt, in teoria potrebbe accadere che qualcuno si colleghi casualmente a una di queste pagine. E se lo facesse, potremmo indicizzare questo URL senza alcun contenuto perché bloccato da robots.txt. Quindi non sapremmo che non volete che queste pagine vengano indicizzate.
Se invece non sono bloccate da robots.txt, potete inserire un meta tag noindex su queste pagine. Se qualcuno dovesse linkarle e noi dovessimo scansionare quel link e pensare che forse c’è qualcosa di utile, allora sapremmo che queste pagine non devono essere indicizzate e potremmo escluderle completamente dall’indicizzazione.
Quindi, a questo proposito, se in queste pagine c’è qualcosa che non volete che venga indicizzato, non disabilitatelo, ma usate noindex.
C’è bisogno di un file robots.txt?
È importante ricordare che non è necessario avere un file robots.txt sul proprio sito. Se non avete problemi a far sì che tutti i bot abbiano libero accesso a tutte le vostre pagine, allora potreste decidere di non aggiungere un file robots.txt, dato che non avete istruzioni reali da dare ai crawler.
In alcuni casi potreste anche non essere in grado di aggiungere un file robots.txt a causa delle limitazioni del CMS che state utilizzando. Anche questo va bene, e ci sono altri metodi per indicare ai bot come effettuare il crawling delle pagine senza utilizzare un file robots.txt.
Quale codice di stato HTTP deve essere restituito per il file robots.txt?
Il file robots.txt deve restituire un codice di stato HTTP 200 OK affinché i crawler possano accedervi.
Se avete problemi a far indicizzare le pagine dai motori di ricerca, vale la pena controllare due volte il codice di stato restituito dal file robots.txt. Qualsiasi codice di stato diverso da 200 potrebbe impedire ai crawler di accedere al vostro sito.
Alcuni proprietari di siti hanno segnalato la deindicizzazione di pagine a causa del file robots.txt che restituisce un codice di stato diverso da 200. Un proprietario di un sito web ha chiesto informazioni su un problema di indicizzazione in un hangout dell’ufficio SEO di Google nel marzo 2022 e John Mueller ha spiegato che il file robots.txt dovrebbe restituire uno stato 200 se è presente, oppure uno stato 4XX se il file non esiste. In questo caso, veniva restituito un errore 500 internal server, che secondo Mueller avrebbe potuto portare Googlebot a escludere il sito dall’indicizzazione.
Lo stesso si può notare in questo Tweet, in cui il proprietario di un sito ha segnalato che il suo intero sito è stato deindicizzato a causa di un file robots.txt che ha restituito un errore 500.
[Quick SEO tip]
If you are having issue with indexing, make sure your robots.txt file is returning either 200 or 404.
If your file returns 500, Google will eventually deindex your website, as I've seen with this project. pic.twitter.com/8KiYLgDVRo
— Antoine Eripret (@antoineripret) November 14, 2022
Il meta tag robots può essere usato al posto del file robots.txt?
Il meta tag robots permette di controllare quali pagine vengono indicizzate, mentre il file robots.txt permette di controllare quali pagine vengono scansionate. I bot devono prima effettuare il crawling delle pagine per poter vedere i meta tag, quindi dovreste evitare di utilizzare sia il meta tag disallow che il meta tag noindex, in quanto il noindex non verrebbe rilevato.
Se il vostro obiettivo è escludere una pagina dai motori di ricerca, il meta tag noindex è di solito l’opzione migliore.
Come creare e modificare il file robots.txt di WordPress
Per impostazione predefinita, WordPress crea automaticamente un file robots.txt virtuale per il vostro sito. Quindi, anche senza muovere un dito, il vostro sito dovrebbe già avere il file robots.txt predefinito. Potete verificare se è così aggiungendo “/robots.txt” alla fine del nome del vostro dominio. Ad esempio, “https://kinsta.com/robots.txt” mostra il file robots.txt che utilizziamo noi di Kinsta.
Esempio di file robots.txt
Ecco un esempio del file robots.txt di Kinsta:
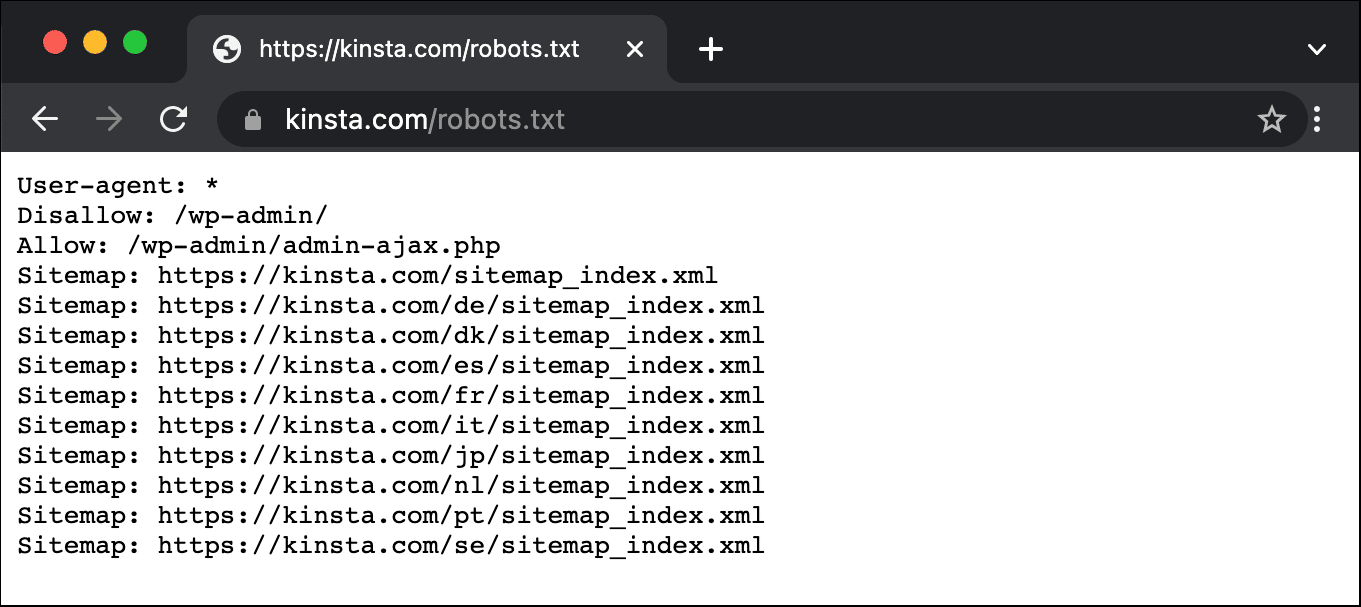
Questo file fornisce a tutti i robot le istruzioni sui percorsi da ignorare (ad esempio il percorso wp-admin), con eventuali eccezioni (ad esempio il file admin-ajax.php), insieme alle posizioni della sitemap XML di Kinsta.
Poiché questo file è virtuale, non potete modificarlo. Se volete modificare il vostro file robots.txt, dovrete creare un file fisico sul vostro server che potrete manipolare a seconda delle necessità. Ecco tre semplici modi per farlo:
Come creare e modificare un file robots.txt in WordPress con Yoast SEO
Se utilizzate il famoso plugin Yoast SEO, potete creare (e successivamente modificare) il vostro file robots.txt direttamente dall’interfaccia di Yoast. Prima di potervi accedere, però, dovrete andare su SEO → Strumenti e cliccare su Editor di file
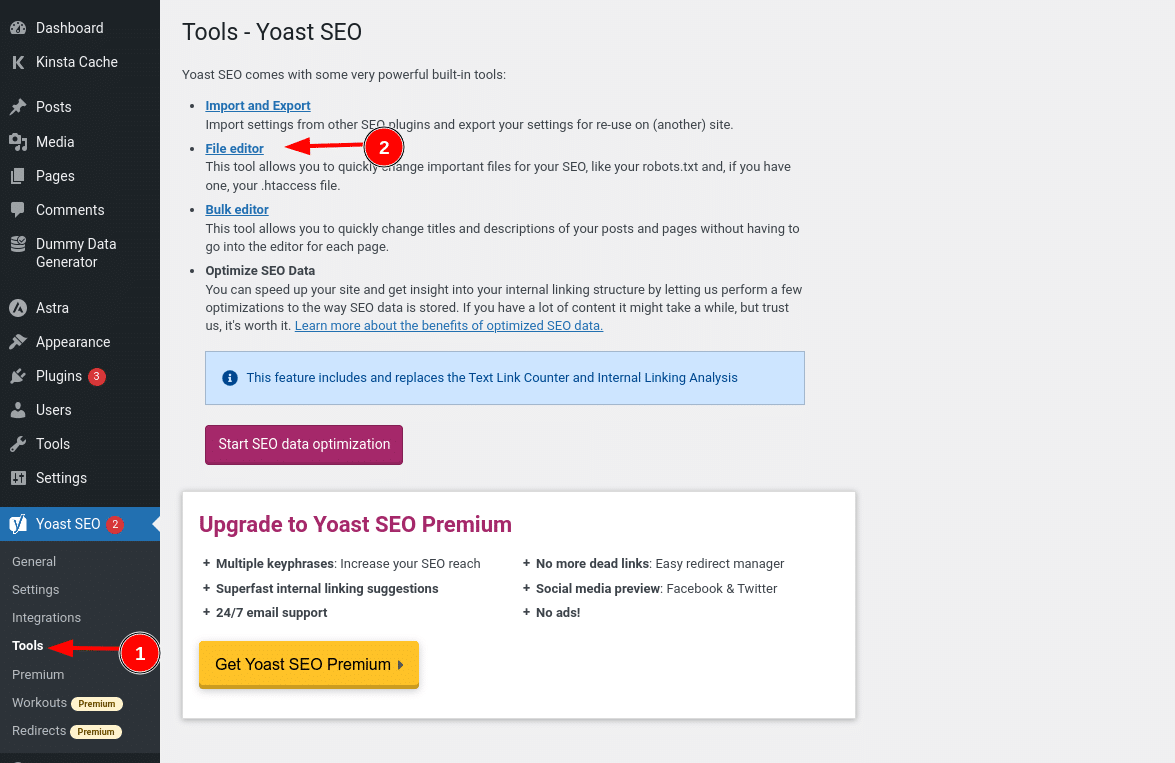
Una volta cliccato su questo pulsante, potrete modificare il contenuto del vostro file robots.txt direttamente dalla stessa interfaccia e salvare le modifiche apportate.
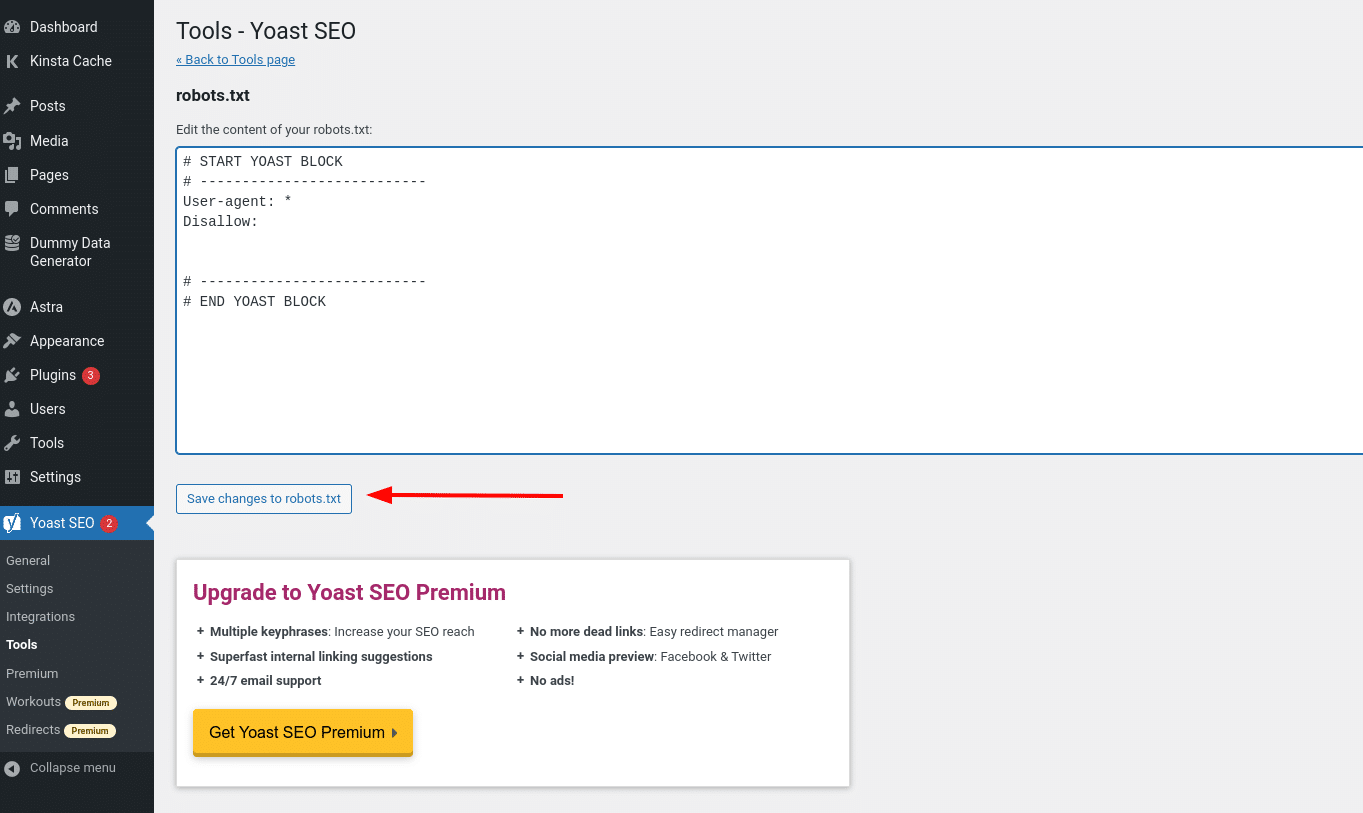
Se non avete già un file robots.txt fisico, Yoast vi darà la possibilità di creare un file robots.txt:
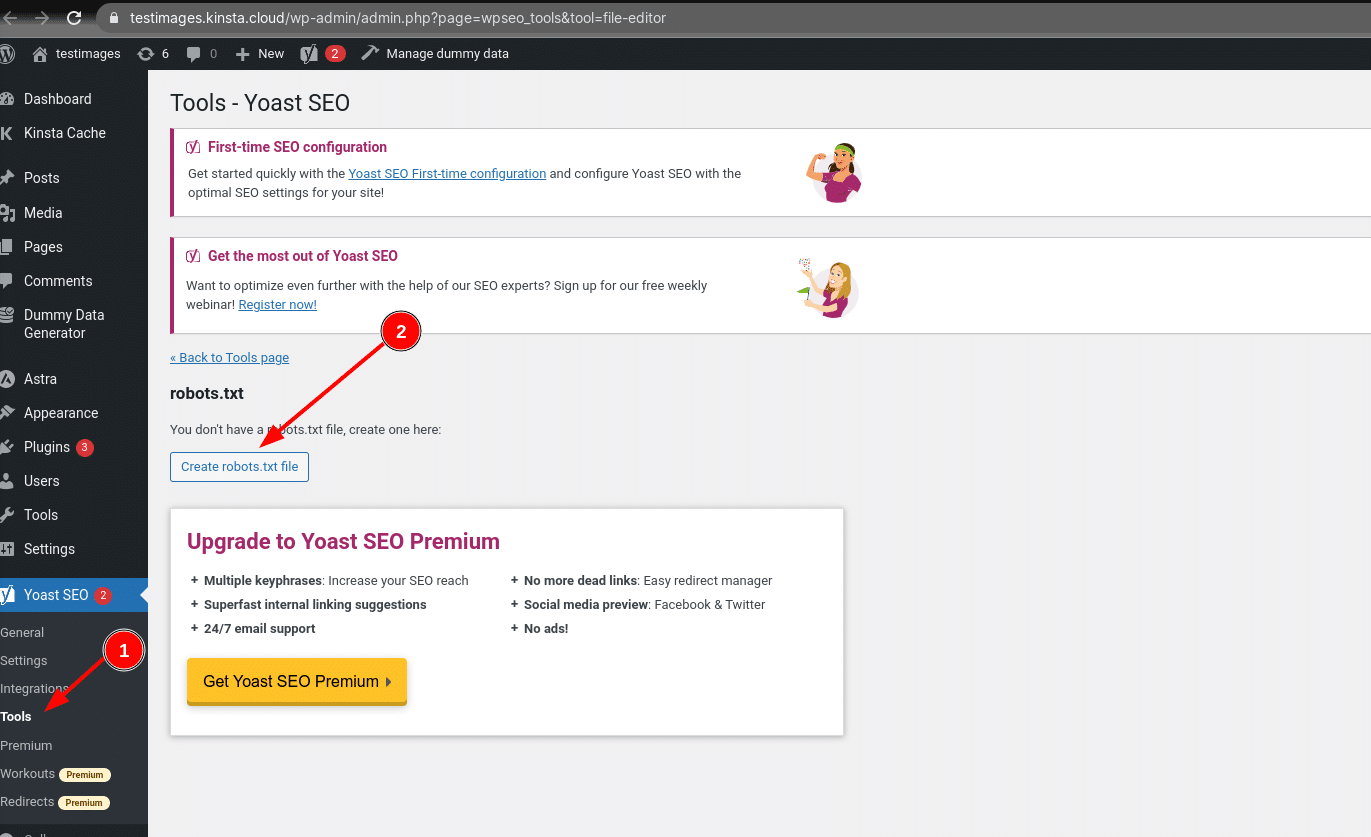
Continuando a leggere, approfondiremo quali tipi di direttive inserire nel file robots.txt di WordPress.
Come creare e modificare un file robots.txt con All in One SEO
Se utilizzate il plugin All in One SEO Pack, quasi altrettanto popolare, potete creare e modificare il file robots.txt di WordPress direttamente dall’interfaccia del plugin. Tutto ciò che dovrete fare è andare su All in One SEO → Strumenti:
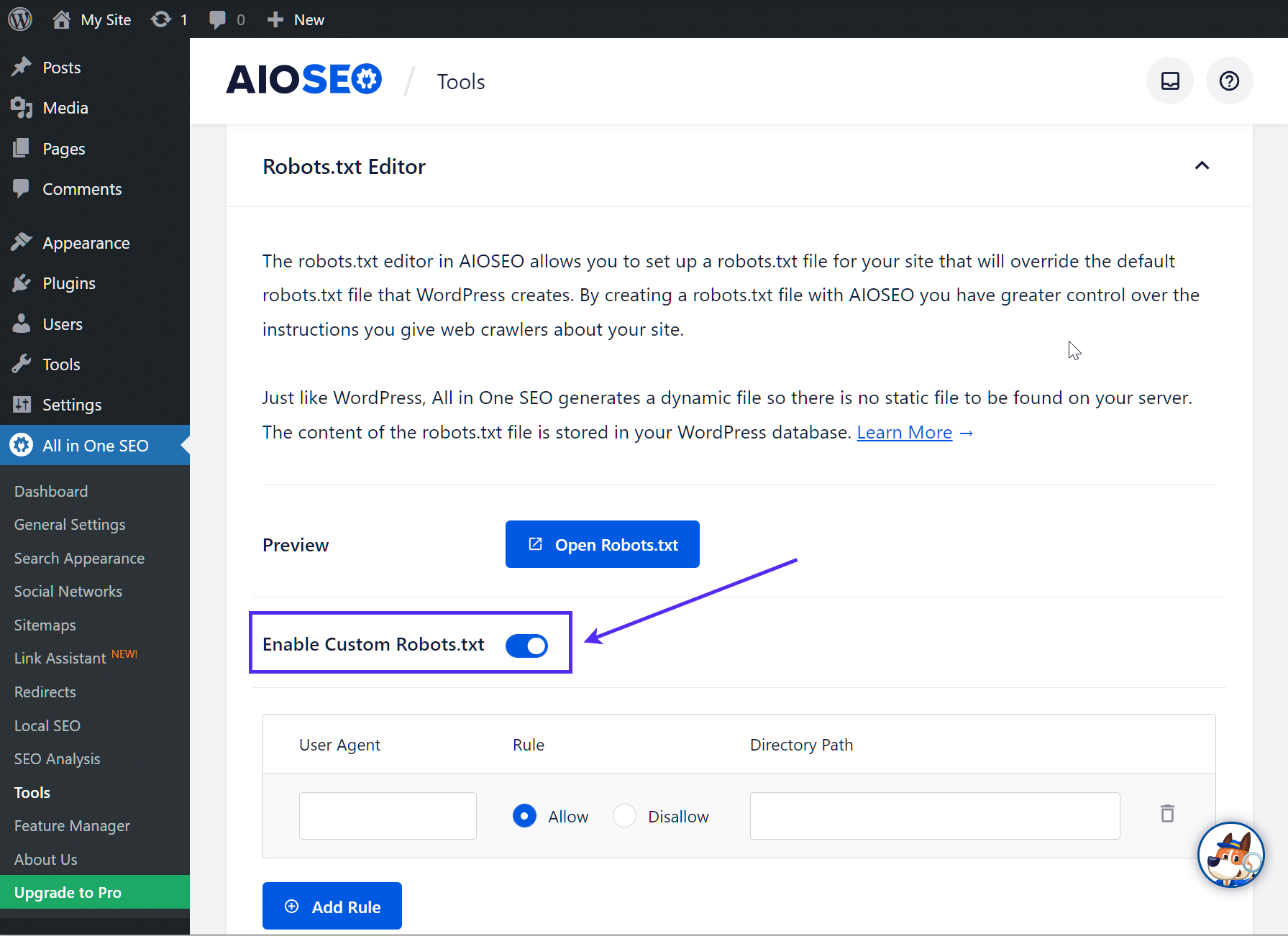
Quindi, attivate il pulsante di opzione Abilita robots.txt personalizzato. In questo modo potrete creare regole personalizzate e aggiungerle al vostro file robots.txt:
Come creare e modificare un file robots.txt tramite FTP
Se non utilizzate un plugin SEO che offre la funzionalità robots.txt, potete comunque creare e gestire il vostro file robots.txt tramite SFTP. Per prima cosa, utilizzate un qualsiasi editor di testo per creare un file vuoto chiamato “robots.txt”:
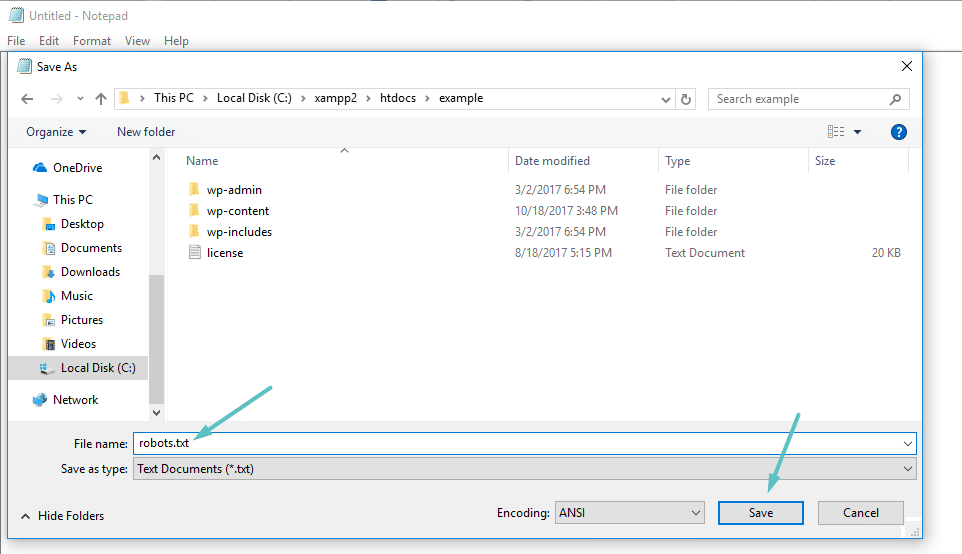
Quindi, collegatevi al vostro sito tramite SFTP e caricate il file nella cartella principale del vostro sito. Potete apportare ulteriori modifiche al file robots.txt modificandolo tramite SFTP o caricando nuove versioni del file.
Cosa inserire nel file robots.txt
Ok, ora avete un file robots.txt fisico sul vostro server che potete modificare a seconda delle necessità. Ma cosa fare con quel file? Come avete imparato nella prima sezione, il file robots.txt permette di controllare il modo in cui i robot interagiscono con il vostro sito. Lo fai con due comandi fondamentali:
- User-agent: permette di indirizzare bot specifici. Gli user agent sono gli strumenti che i bot utilizzano per identificarsi. Con questi comandi potete, ad esempio, creare una regola che si applica a Bing, ma non a Google.
- Disallow: permette di dire ai robot di non accedere a determinate aree del vostro sito.
Esiste anche un comando Allow che potrete utilizzare in situazioni di nicchia. Per impostazione predefinita, tutto ciò che è presente sul vostro sito è contrassegnato da Allow, quindi non è necessario utilizzare il comando Allownel 99% delle situazioni. Tuttavia, può essere utile quando volete abilitare Disallow per una cartella e per le sue cartelle child, ma mantenere Allow per una cartella child specifica.
Le regole si aggiungono specificando prima quale User-agent deve essere applicato e poi elencando le regole da applicare utilizzando Disallow e Allow. Esistono anche altri comandi come Crawl-delay e Sitemap, ma questi sono entrambi:
- Ignorati dalla maggior parte dei principali crawler o interpretati in modi molto diversi (nel caso di crawl delay)
- Sono resi superflui da strumenti come Google Search Console (per le sitemap)
Esaminiamo alcuni casi d’uso specifici per mostrarvi come tutto questo si traduce.
Come utilizzare Robots.txt Disallow All per bloccare l’accesso a tutto il sito
Supponiamo che vogliate bloccare l’accesso di tutti i crawler al vostro sito. È improbabile che questo accada su un sito attivo, ma è utile per un sito di sviluppo. Per farlo, dovrete aggiungere il codice robots.txt disallow all al vostro file robots.txt di WordPress:
User-agent: *
Disallow: /Cosa succede in questo codice?
L’*asterisco accanto a User-agent significa “tutti gli user agent”. L’asterisco è un carattere jolly, cioè si applica a ogni singolo user agent. Lo /slash accanto a Disallow indica che volete impedire l’accesso a tutte le pagine che contengono “yourdomain.com/” (ovvero tutte le pagine del vostro sito).
Come utilizzare Robots.txt per bloccare l’accesso al vostro sito da parte di un singolo bot
Cambiamo le cose. In questo esempio, faremo finta che non vi piaccia il fatto che Bing effettui il crawling delle vostre pagine. Siete un Team Google a tutti gli effetti e non volete nemmeno che Bing guardi il vostro sito. Per bloccare solo Bing dal crawling del vostro sito, sostituite il carattere jolly *asterisco con Bingbot:
User-agent: Bingbot
Disallow: /In sostanza, il codice di cui sopra dice di applicare la regola Disallow solo ai bot con l’User-agent “Bingbot”. Ora, è improbabile che vogliate bloccare l’accesso a Bing, ma questo scenario è utile se c’è un bot specifico che non volete che acceda al vostro sito. Questo sito contiene un buon elenco dei nomi degli User-agent conosciuti dalla maggior parte dei servizi.
Come usare Robots.txt per bloccare l’accesso a una cartella o a un file specifico
Per questo esempio, supponiamo che vogliate bloccare l’accesso solo a un file o a una cartella specifica (e a tutte le sue sottocartelle). Per applicare questo esempio a WordPress, diciamo che volete bloccare:
- L’intera cartella wp-admin
- wp-login.php
Potreste utilizzare i seguenti comandi:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpCome usare Allow all nel Robots.txt per dare ai robot pieno accesso al sito
Se al momento non avete motivo di bloccare l’accesso dei crawler a nessuna delle vostre pagine, potete aggiungere il seguente comando.
User-agent: *
Allow: /
O in alternativa:
User-agent: *
Disallow:
Come utilizzare Robots.txt per consentire l’accesso a un file specifico in una cartella non consentita
Ok, supponiamo che vogliate bloccare un’intera cartella, ma che vogliate comunque consentire l’accesso a un file specifico all’interno di quella cartella. È qui che il comando Allow si rivela utile. Ed è molto utile per WordPress. Infatti, il file robots.txt virtuale di WordPress illustra perfettamente questo esempio:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpQuesto snippet blocca l’accesso all’intera cartella /wp-admin/ ad eccezione del file /wp-admin/admin-ajax.php.
Come utilizzare il file Robots.txt per impedire ai bot di scansionare i risultati di ricerca di WordPress
Una modifica specifica di WordPress che potreste voler apportare è quella di impedire ai crawler di ricerca di eseguire il crawling delle pagine dei risultati di ricerca. Per impostazione predefinita, WordPress utilizza il parametro di query “?s=”. Per bloccare l’accesso, dovete solo aggiungere la seguente regola:
User-agent: *
Disallow: /?s=
Disallow: /search/Questo può essere un modo efficace per bloccare anche gli errori soft 404 se li ricevete. Assicuratevi di leggere la nostra guida approfondita su come velocizzare la ricerca su WordPress.
Come creare regole diverse per i diversi bot nel file Robots.txt
Finora tutti gli esempi hanno riguardato una regola alla volta. Ma cosa succede se volete applicare regole diverse a bot diversi? Dovete semplicemente aggiungere ogni serie di regole sotto la dichiarazione User-agent per ogni bot. Ad esempio, se volete creare una regola che si applichi a tutti i bot e un’altra che si applichi solo a Bingbot, potete procedere in questo modo:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /In questo esempio, tutti i bot saranno bloccati dall’accesso a /wp-admin/, ma Bingbot sarà bloccato dall’accesso all’intero sito.
Testare i file robots.txt
Per assicurarvi che il vostro file robots.txt sia stato configurato correttamente e che funzioni come previsto, dovete testarlo accuratamente. Un singolo carattere fuori posto può essere catastrofico per le prestazioni di un sito nei motori di ricerca, quindi i test possono aiutare a evitare potenziali problemi.
Il tester robots.txt di Google
Lo strumento robots.txt Tester di Google (precedentemente parte di Google Search Console) è facile da usare e mette in evidenza i potenziali problemi del vostro file robots.txt.
Basta navigare nello strumento e selezionare la proprietà del sito che si desidera testare, quindi scorrere fino alla fine della pagina e inserire un URL qualsiasi nel campo, quindi fare clic sul pulsante rosso TEST:
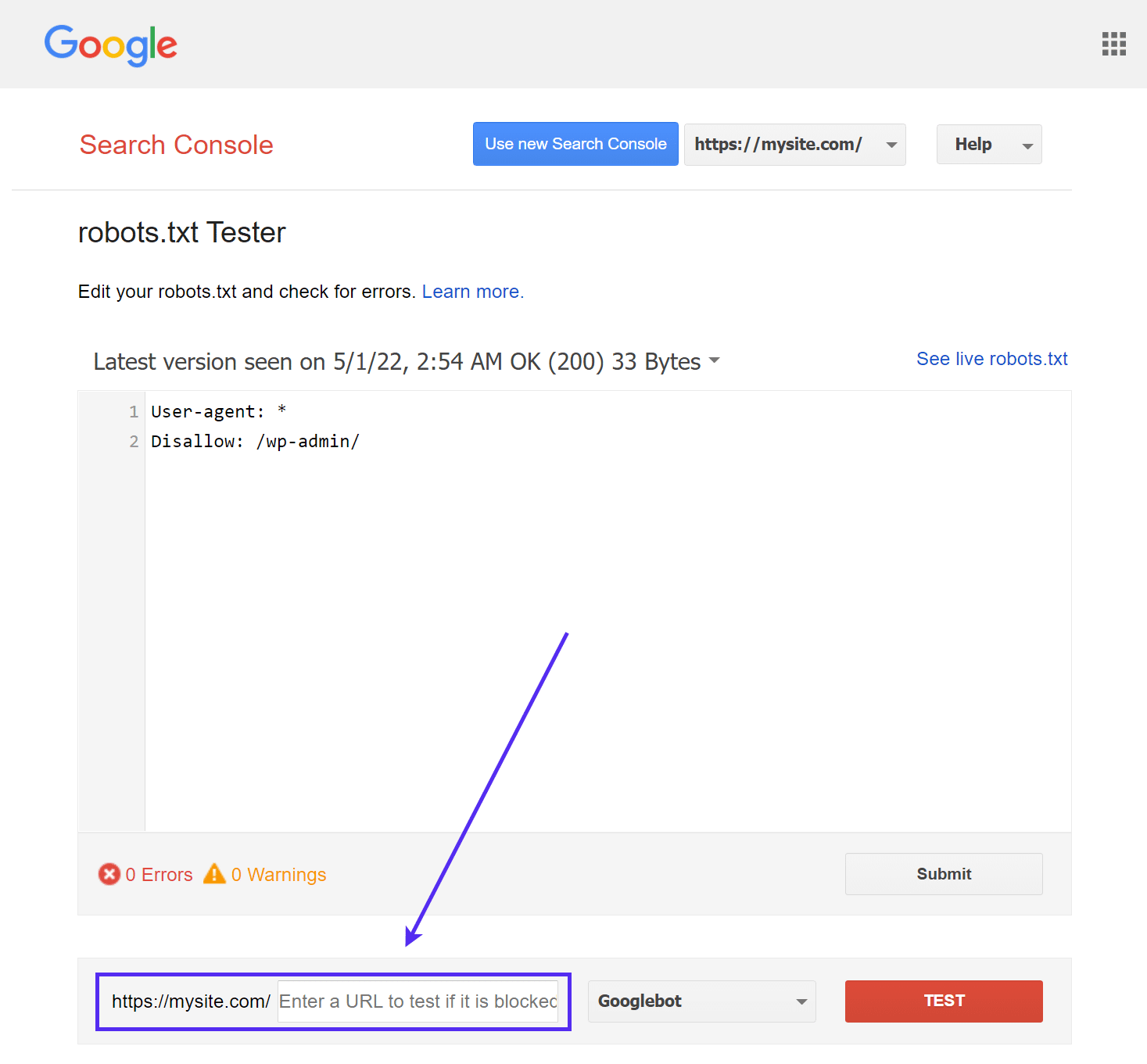
Vedrete una risposta Allowed verde se tutto è crawlabile.
Potete anche selezionare la versione di Googlebot con cui eseguire il test, scegliendo tra Googlebot, Googlebot-News, Googlebot-Image, Googlebot-Video, Googlebot-Mobile, Mediapartners-Google o Adsbot-Google.
Potete anche testare ogni singolo URL che avete bloccato per assicurarvi che siano effettivamente bloccati e/o Disallowed.
Attenzione al BOM UTF-8
BOM è l’acronimo di byte order mark ed è un carattere invisibile che a volte viene aggiunto ai file dai vecchi editor di testo e simili. Se questo accade al vostro file robots.txt, Google potrebbe non leggerlo correttamente. Per questo motivo è importante controllare che il file non contenga errori. Ad esempio, come si vede qui sotto, il nostro file presenta un carattere invisibile e Google segnala che la sintassi non viene compresa. In sostanza, questo invalida la prima riga del nostro file robots.txt, il che non è positivo! Glenn Gabe ha pubblicato un eccellente articolo su come un UTF-8 Bom possa uccidere la vostra SEO.

Googlebot è prevalentemente statunitense
È importante anche non bloccare il Googlebot dagli Stati Uniti, anche se vi state rivolgendo a una regione locale al di fuori degli Stati Uniti. A volte effettuano un crawling locale, ma il Googlebot è principalmente basato negli Stati Uniti.
Googlebot is mostly US-based, but we also sometimes do local crawling. https://t.co/9KnmN4yXpe
— Google Search Central (@googlesearchc) November 13, 2017
Cosa mettono i siti WordPress più famosi nel loro file Robots.txt
Per fornire un contesto ai punti sopra elencati, ecco come alcuni dei siti WordPress più popolari utilizzano i loro file robots.txt.
TechCrunch
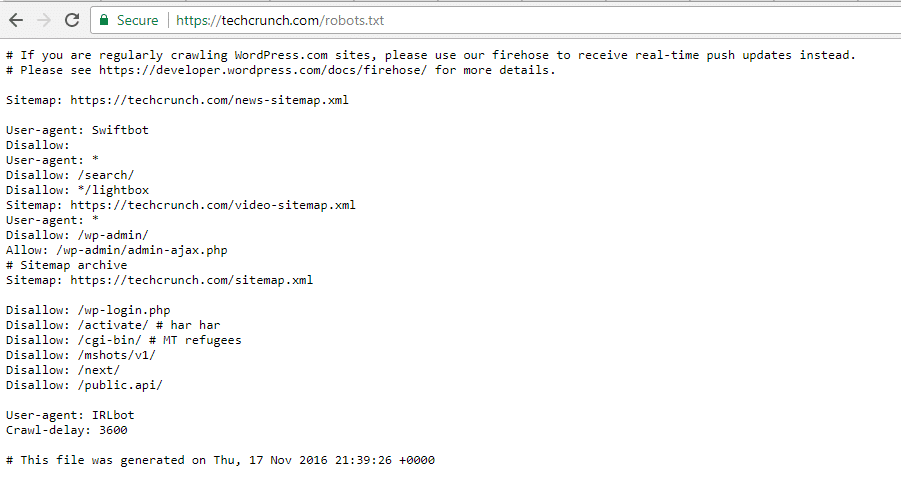
Oltre a limitare l’accesso a un certo numero di pagine uniche, TechCrunch in particolare impedisce ai crawler l’accesso a di:
- /wp-admin/
- /wp-login.php
Inoltre, ha imposto restrizioni speciali a due bot:
- Swiftbot
- IRLbot
Nel caso vi interessi, IRLbot è un crawler di un progetto di ricerca della Texas A&M University. Che strano!
The Obama Foundation
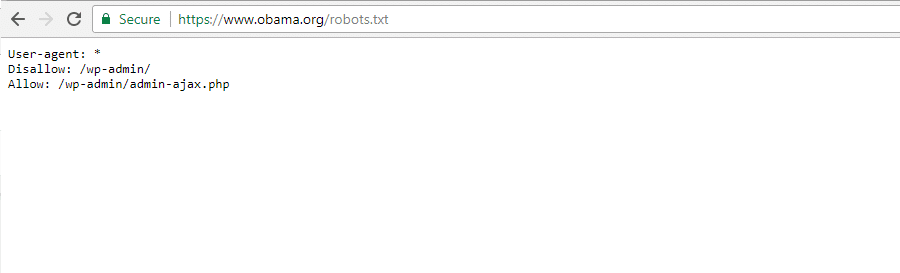
La Obama Foundation non ha fatto alcuna aggiunta particolare, scegliendo esclusivamente di limitare l’accesso a /wp-admin/.
Angry Birds
Angry Birds ha la stessa configurazione predefinita di The Obama Foundation. Non viene aggiunto nulla di speciale.
Drift

Infine, Drift sceglie di definire le sue sitemap nel file Robots.txt, ma per il resto lascia le stesse restrizioni predefinite di The Obama Foundation e Angry Birds.
Usare Robots.txt nel modo giusto
Per concludere la nostra guida su robots.txt, vogliamo ricordarvi ancora una volta che utilizzare un comando Disallow nel file robots.txt non è la stessa cosa che utilizzare un tag noindex. Il robots.txt blocca il crawling, ma non necessariamente l’indicizzazione. Potete usarlo per aggiungere regole specifiche per modellare il modo in cui i motori di ricerca e altri bot interagiscono con il vostro sito, ma non controlla esplicitamente se i vostri contenuti vengono indicizzati o meno.
Per la maggior parte degli utenti occasionali di WordPress, non è necessario modificare il file robots.txt virtuale predefinito. Tuttavia, se avete problemi con un bot specifico o volete cambiare il modo in cui i motori di ricerca interagiscono con un determinato plugin o tema che state utilizzando, potreste aggiungere le vostre regole.
Speriamo che questa guida vi sia piaciuta e vi invitiamo a lasciare un commento se avete altre domande sull’uso del file robots.txt di WordPress.

Brian ha una grande passione per WordPress, lo usa da più di dieci anni e sviluppa anche un paio di plugin premium. Brian ama i blog, i film e le escursioni. Entra in contatto con Brian su Twitter.

