
Negli ultimi 18 mesi, l’attenzione sul traffico dei bot si è spostata dal crawling e dall’indicizzazione al suo impatto sulle prestazioni di base del server, sulle fattura di hosting e sulla capacità di servire i clienti reali.
Lo sappiamo perché abbiamo analizzato oltre 10 miliardi di richieste sull’infrastruttura gestita da Kinsta, e quello che abbiamo scoperto non era una questione di attacchi. Era una questione di risorse.
«Dal punto di vista dell’infrastruttura, non esiste una cosa come il “semplice traffico dei bot”», afferma Daniel Pataki, CTO di Kinsta. «Ogni richiesta implica un vero consumo di risorse. Su larga scala, una scansione inefficiente smette di essere un problema di traffico e diventa un problema di risorse.»
Questo articolo spiega perché si è verificato questo cambiamento, quanto costa effettivamente ai proprietari di siti WordPress e come deve cambiare la narrativa.
Il vecchio modello non funziona più
La gestione tradizionale dei bot si basava su una premessa semplice: bloccare quelli cattivi e lasciar passare quelli buoni. Per anni, questo è bastato. Googlebot scansionava le pagine, indicizzava i contenuti e andava avanti. I bot dannosi cercavano di intrufolarsi nelle pagine di login. Due problemi molto diversi, due soluzioni molto diverse.
Ciò di cui nessuno dei due modelli teneva conto era una terza categoria: il traffico automatizzato che non è dannoso né viene bloccato, ma che sta causando un danno misurabile alle prestazioni dei siti su larga scala.
I crawler AI, ovvero bot progettati non solo per indicizzare le pagine ai fini dei risultati di ricerca, ma anche per acquisire contenuti per l’addestramento dei modelli, la generazione retrieval-augmented e le query degli utenti in tempo reale, operano su una scala fondamentalmente diversa rispetto a qualsiasi cosa vista in precedenza. Il solo GPTBot è cresciuto del 305% tra maggio 2024 e maggio 2025. All’inizio del 2025, circa una visita web su 200 era effettuata da un bot AI. Entro la fine dell’anno, quel rapporto era salito a una su 31.
Verso la fine del 2025, i crawler AI rappresentavano il 4,2% di tutte le richieste HTML sulla rete di Cloudflare, una cifra che è passata dal 2,4% all’inizio di aprile al 6,4% alla fine di giugno, quasi triplicandosi nel giro di un anno.
Questi crawler sono insistenti e frequenti, e non si comportano come i tradizionali bot dei motori di ricerca. Molti generano grandi volumi di richieste verso endpoint dinamici non memorizzati nella cache, il che comporta un “lavoro vero e proprio” per il tuo server.
Cosa significa “lavoro vero e proprio” per un sito WordPress
È qui che il problema dell’infrastruttura diventa evidente, ed è un aspetto che spesso viene trascurato nella maggior parte delle analisi sul traffico dei bot.
Quando un visitatore carica una pagina memorizzata nella cache su un sito WordPress, il server fa ben poco. Restituisce un file HTML già pronto, proprio come farebbe per servire un’immagine o un file CSS. Il server di origine se ne accorge a malapena. È proprio questo il senso della cache.
Ma una parte significativa delle richieste su un vero sito WordPress, e in particolare sugli store WooCommerce, non può essere gestita dalla cache. Queste richieste includono:
- Endpoint del carrello e del checkout (
?add-to-cart=,/cart,/checkout) - Pagine dei prodotti filtrate con parametri URL
- Query di ricerca
- Interazioni basate su AJAX (aggiunta alla lista dei desideri, aggiornamenti in tempo reale dei prezzi, popup dinamici)
- Pagine basate sulla sessione che richiedono al server di convalidare o creare un contesto utente
Quando un bot accede a questi endpoint, ecco cosa succede effettivamente sul server:
- Viene riservato un thread PHP. Ogni richiesta dinamica su WordPress occupa un thread PHP per tutta la durata dell’elaborazione, in genere 200–500 ms, o anche di più se la pagina è complessa. Quel thread non è disponibile per nessun’altra richiesta finché il lavoro non è finito. Ogni piano di hosting ne ha un numero fisso.
- Il database esegue una query. Le pagine dinamiche interrogano il database ad ogni singolo caricamento. Con un traffico umano normale, la situazione è gestibile. In caso di carico prolungato da parte dei bot su percorsi non memorizzati nella cache, il database esegue query costantemente. Se i bot accedono a varianti uniche di URL che non generano risultati nella cache, ognuna di esse innesca la propria catena di query.
- Si crea un sovraccarico di sessione. Le pagine del carrello e del checkout creano o convalidano le sessioni anche per i bot che non effettuano mai conversioni. Questo aggiunge un sovraccarico di elaborazione a ciascuna di queste richieste.
- I thread PHP si esauriscono. Quando tutti i thread PHP disponibili sono occupati, i visitatori legittimi non vengono serviti immediatamente, quindi le loro richieste finiscono in coda. Se la coda si riempie, iniziano a riscontrare caricamenti lenti delle pagine, checkout bloccati ed errori 504. A un cliente reale che sta cercando di completare un acquisto, il sito sembra non funzionare.
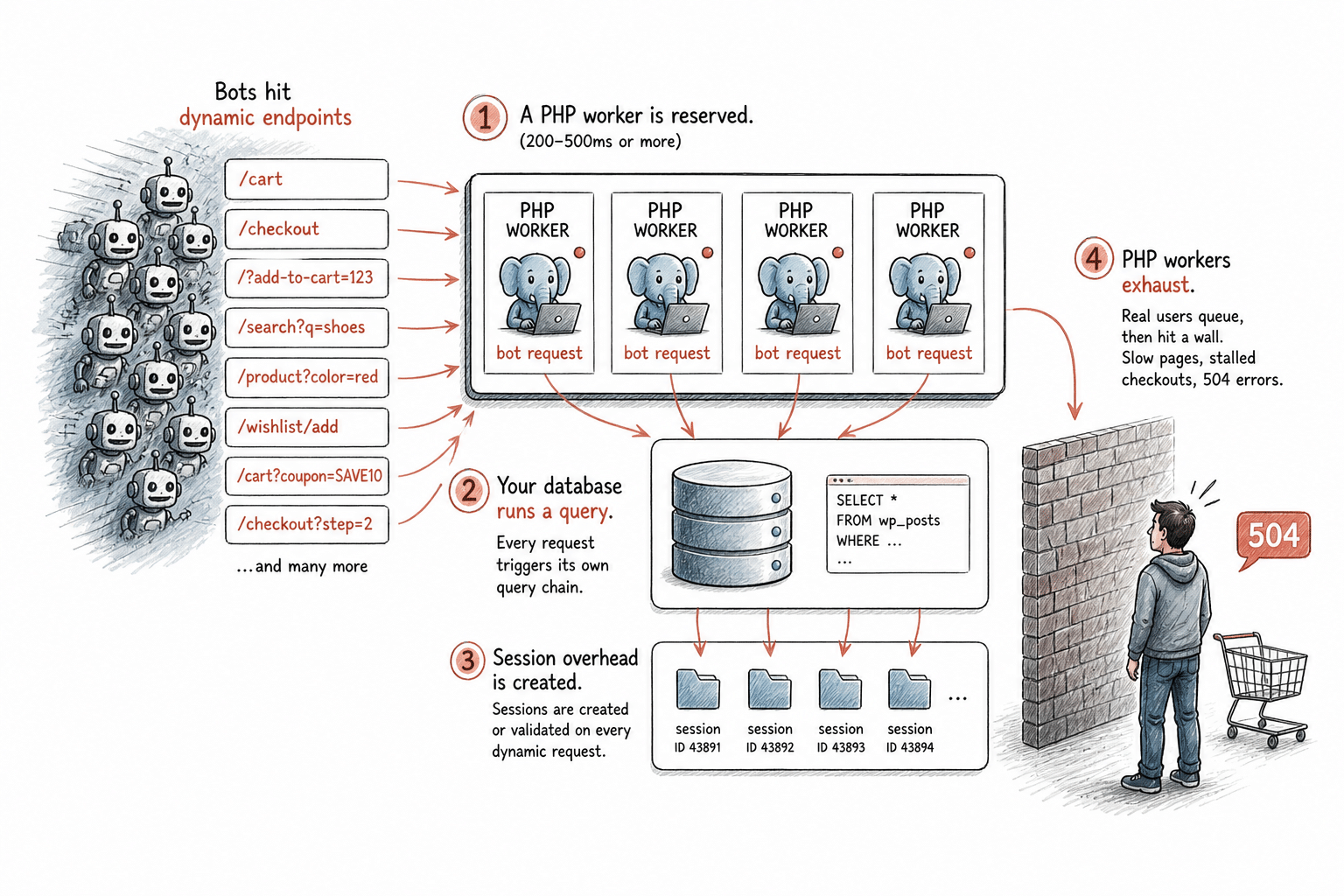
Questo è il meccanismo attraverso cui il traffico dei bot diventa un problema per l’infrastruttura. Non è una teoria. È la catena specifica di eventi che si verifica quando le richieste automatizzate inondano gli endpoint dinamici di un sito WordPress attivo.
Cosa mostrano effettivamente i dati sull’infrastruttura di Kinsta
L’astratto diventa concreto quando si osservano i dati reali provenienti dall’infrastruttura che gestiamo su larga scala.
Un dato che abbiamo trovato particolarmente sorprendente è che un singolo bot (ClaudeBot) ha generato 3,75 milioni di richieste di “aggiungi al carrello” nell’arco di 24 ore. Si tratta all’incirca di una richiesta ogni 23 millisecondi (giorno e notte), ognuna delle quali viene trattata dal server come una nuova richiesta perché gli endpoint del carrello sono intrinsecamente dinamici.
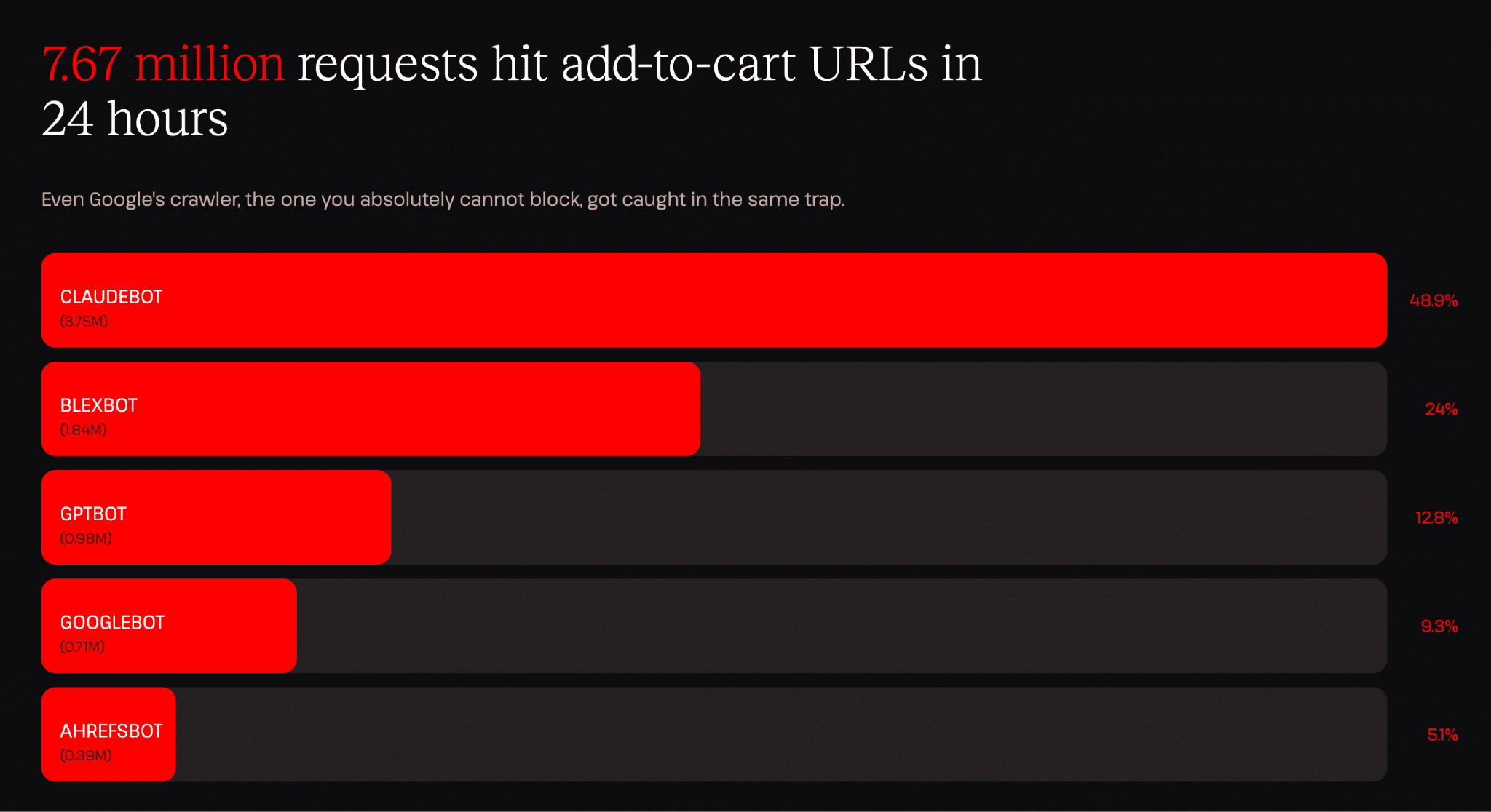
Per contestualizzare: le richieste di “aggiungi al carrello” sono tra gli endpoint più onerosi di un negozio WooCommerce. Creano sessioni, eseguono query e aggiornano lo stato del carrello. Ognuna di esse comporta un carico di lavoro reale. I 3,75 milioni di richieste che abbiamo rilevato da un’unica fonte in un solo giorno rappresentano il tipo di andamento del traffico che può mandare un sito fuori uso.
Un secondo dato sottolinea quanto questi modelli possano essere persistenti: un ciclo anomalo ha generato 550 milioni di richieste in 30 giorni, un traffico tale da giustificare una regola di mitigazione dedicata nella nostra infrastruttura. Non si tratta di un attacco DDoS né di una campagna di malware, ma di un bot bloccato in un ciclo di scansione, che richiede ripetutamente URL che ha già visto.
Questi non sono casi isolati. Sono modelli che osserviamo su tutta la nostra piattaforma.
Il problema del loop: i bot non stanno attaccando, sono bloccati
Uno degli aspetti più sottovalutati dell’attuale problema del traffico dei bot è che la maggior parte di ciò che causa danni all’infrastruttura non è affatto malevolo. Si tratta di automazione inefficiente su larga scala.
I siti web moderni, specialmente i negozi di e-commerce, generano URL leggermente diversi per pagine sostanzialmente identiche:
- Un prodotto con un filtro per colore aggiunto
- Una pagina del carrello con un token di sessione
- Una vista di categoria con un parametro di ordinamento
Per un essere umano, queste sono tutte “la stessa pagina”. Per un bot che segue gli URL, ognuna sembra una pagina nuova da scansionare.
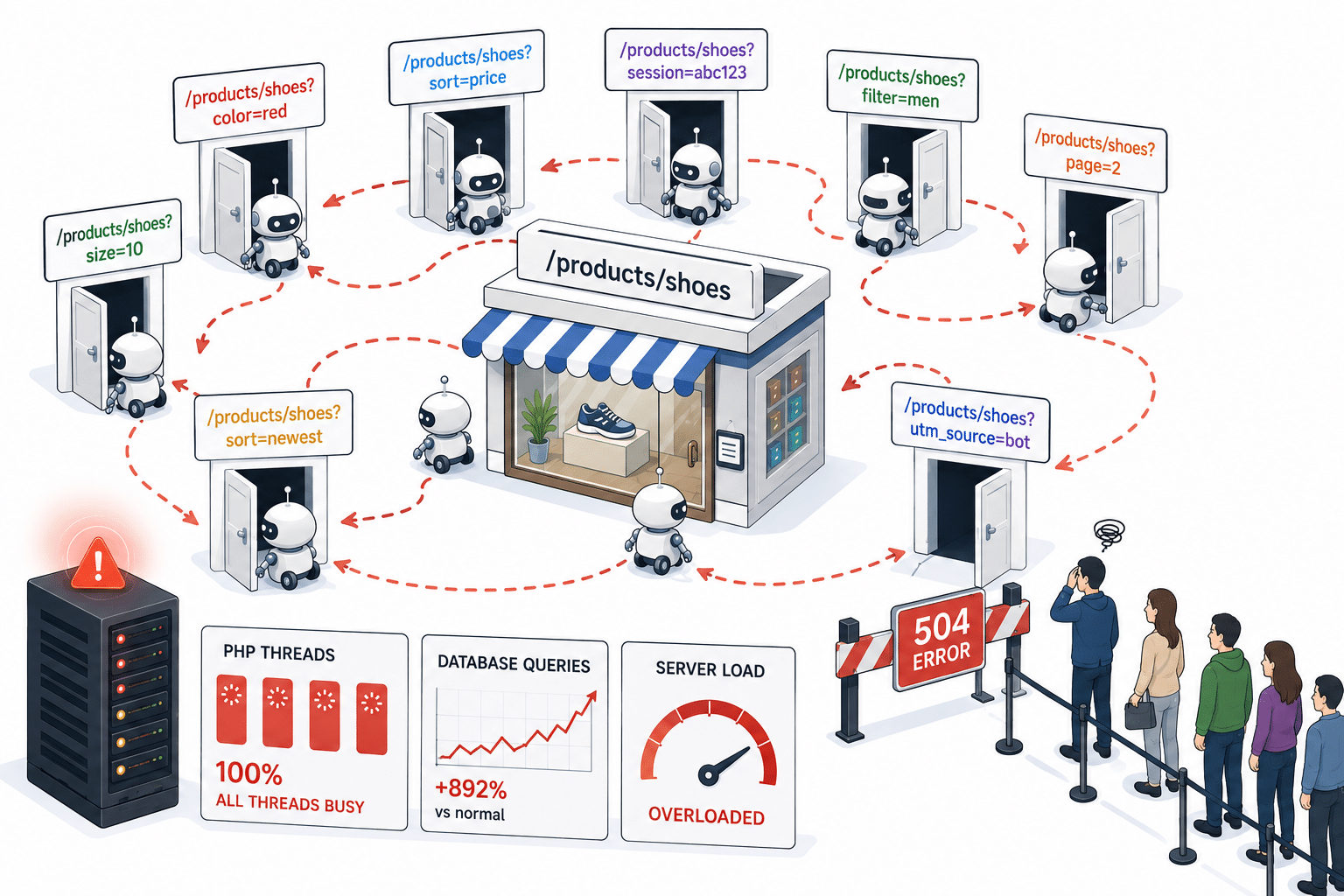
Quindi il bot segue il primo link. Quella pagina genera un’altra variante dell’URL, che il bot segue. Poi un’altra. E poi un’altra ancora. Non ha alcun meccanismo per rendersi conto che sta girando in tondo, e alcuni di questi loop sono rimasti inosservati sull’infrastruttura monitorata per diversi giorni prima che le regole di mitigazione li intercettassero.
Nel report sul traffico AI e bot che abbiamo pubblicato di recente, David Belson, ex responsabile di Data Insights presso Cloudflare, ha detto: «C’è chi ieri non sapeva nemmeno cosa diavolo stesse facendo, ma oggi ha programmato un bot al volo e l’ha lasciato libero. Non si prendono nemmeno la briga di controllare i file robots.txt».
Questo comportamento non viene sempre da utenti malintenzionati. Proviene da sistemi di crawler AI che non sono stati progettati tenendo conto della navigazione sfaccettata, della proliferazione dei parametri URL o degli URL generati dalle sessioni, che sono caratteristiche standard dei moderni siti WordPress.
Google stesso identifica esplicitamente la navigazione per faccette e gli URL basati su parametri come una fonte di inefficienza nella scansione, sottolineando che i bot possono esplorare variazioni quasi infinite della stessa pagina.
La fattura del server è ormai un problema di gestione dei bot
Fino a poco tempo fa, molti piani di hosting erano dimensionati in base al numero di visite, il che funzionava abbastanza bene come indicatore dell’utilizzo reale da parte degli utenti umani. Si partiva dal presupposto che le visite fossero più o meno correlate alle persone che interagivano con il sito.
Quel presupposto non regge più.
Il traffico automatizzato ha gonfiato il numero di visite in un modo che ha ben poco a che vedere con l’effettiva attività commerciale. Le richieste dei bot possono generare visite senza produrre il corrispondente coinvolgimento, conversioni o ricavi. I proprietari dei siti ricevevano avvisi di superamento del limite sui piani basati sulle visite, causati dall’attività dei bot che non potevano controllare e che non avevano invitato.
Questo fenomeno era talmente evidente come modello sistemico che Kinsta ha introdotto piani di hosting basati sulla larghezza di banda proprio in risposta a una categoria di siti le cui metriche sulle visite avevano iniziato a discostarsi in modo significativo dal loro effettivo consumo di risorse. Se le visite di un sito crescevano ma la larghezza di banda non riusciva a stare al passo, era quasi sempre un segnale della presenza di bot. Passare a un modello basato sulla larghezza di banda ha di fatto svincolato la fatturazione da una metrica che i bot avevano imparato a gonfiare.
Il problema della fatturazione è misurabile e risolvibile. Il problema più difficile è che la maggior parte dei proprietari di siti non si rende conto che tutto questo sta accadendo perché le loro dashboard non mostrano il quadro completo.
Cosa ti dicono (e cosa no) i tuoi dati di analisi
Una conseguenza del traffico generato dai bot su questa scala è che gli strumenti di analisi standard non sono più affidabili nel descrivere le reali prestazioni del tuo sito.
Se il numero delle visite sta aumentando ma le entrate, il tempo trascorso sulla pagina e il tasso di rimbalzo non seguono lo stesso andamento, probabilmente i bot c’entrano qualcosa. Se il tuo server mostra un calo delle prestazioni che non corrisponde ai picchi di traffico che ti aspetteresti da contenuti o attività di marketing, vale la pena indagare sul traffico dei bot verso endpoint non memorizzati nella cache.
Kinsta filtra automaticamente gli user agent noti come bot dalle analisi e dai calcoli sull’utilizzo del piano. Tuttavia, il traffico automatizzato che assomiglia molto al comportamento umano potrebbe comunque comparire nelle tue metriche.
Gli schemi da tenere d’occhio:
- Richieste ripetute verso gli stessi tipi di URL, specialmente percorsi con molti parametri o basati su sessioni
- Picchi di traffico in momenti che non corrispondono a nessuna attività di pubblicazione, promozionale o stagionale
- Deterioramento delle prestazioni del server ( TTFB più elevato, errori di esaurimento dei thread PHP) durante periodi di traffico elevato che non corrispondono a eventi reali
- Numero di visite in crescita più rapida rispetto alla larghezza di banda, alle conversioni o alle metriche di coinvolgimento
Nessuno di questi fattori è determinante di per sé, ma qualsiasi combinazione richiede un’analisi approfondita prima di attribuire questi numeri alla crescita del business.
Perché è un problema più complesso di quanto sembri
L’istinto più comune quando ci si trova di fronte ai dati sul traffico dei bot è quello di bloccare tutto. Altri, invece, potrebbero consentire tutto il traffico, perché “l’AI è il futuro”.
Nessuna delle due soluzioni funziona!
Bloccare indiscriminatamente significa bloccare anche i crawler verificati, compreso Googlebot, la cui copertura di scansione determina se i tuoi contenuti compaiono o meno nei risultati di ricerca. Significa bloccare i bot di scoperta AI che potrebbero far emergere i tuoi contenuti nei risultati di ricerca conversazionale, nei consigli AI o nei motori di risposta. Per un negozio WooCommerce o un editore di contenuti, si tratta di un costo di distribuzione significativo.
Lasciare passare tutto significa accettare costi di infrastruttura che non generano alcun ritorno. E per gli endpoint dinamici che i bot tendono a colpire con maggiore intensità, quei costi non sono marginali. Si accumulano e si aggravano, specialmente sotto un carico automatizzato prolungato.
La risposta giusta sta da qualche parte nel mezzo, e richiede di capire le differenze tra le categorie di traffico invece di trattare tutti i bot come un’unica classe.
Come ha spiegato Cristian Lopez, caporedattore di HostingAdvice, nel rapporto: «L’errore è pensare che il traffico dei bot sia un semplice problema di “bloccare o consentire”. In realtà, si tratta di politica, visibilità e controllo economico».
I bot verificati, tra cui Googlebot, Bing e gli strumenti di monitoraggio legittimi, dovrebbero generalmente essere consentiti, con eventuali restrizioni di percorso sugli endpoint che non hanno alcun valore di scansione (la pagina di checkout non contribuisce in alcun modo al tuo posizionamento nei risultati di ricerca). I bot non verificati, privi di informazioni identificative o di uno scopo preciso, meritano un esame più approfondito. I crawler di addestramento dell’AI che generano elevati volumi di richieste verso endpoint dinamici rappresentano una categoria specifica che potrebbe richiedere il blocco o la limitazione della frequenza, a seconda del tipo di sito e delle tue priorità.
Nel nostro rapporto sul traffico generato da AI e bot, abbiamo creato un modello decisionale interattivo che illustra l’approccio corretto per diversi tipi di siti. L’esempio qui sotto mostra la configurazione consigliata per un negozio WooCommerce incentrata sulle prestazioni e sulla stabilità del sito:
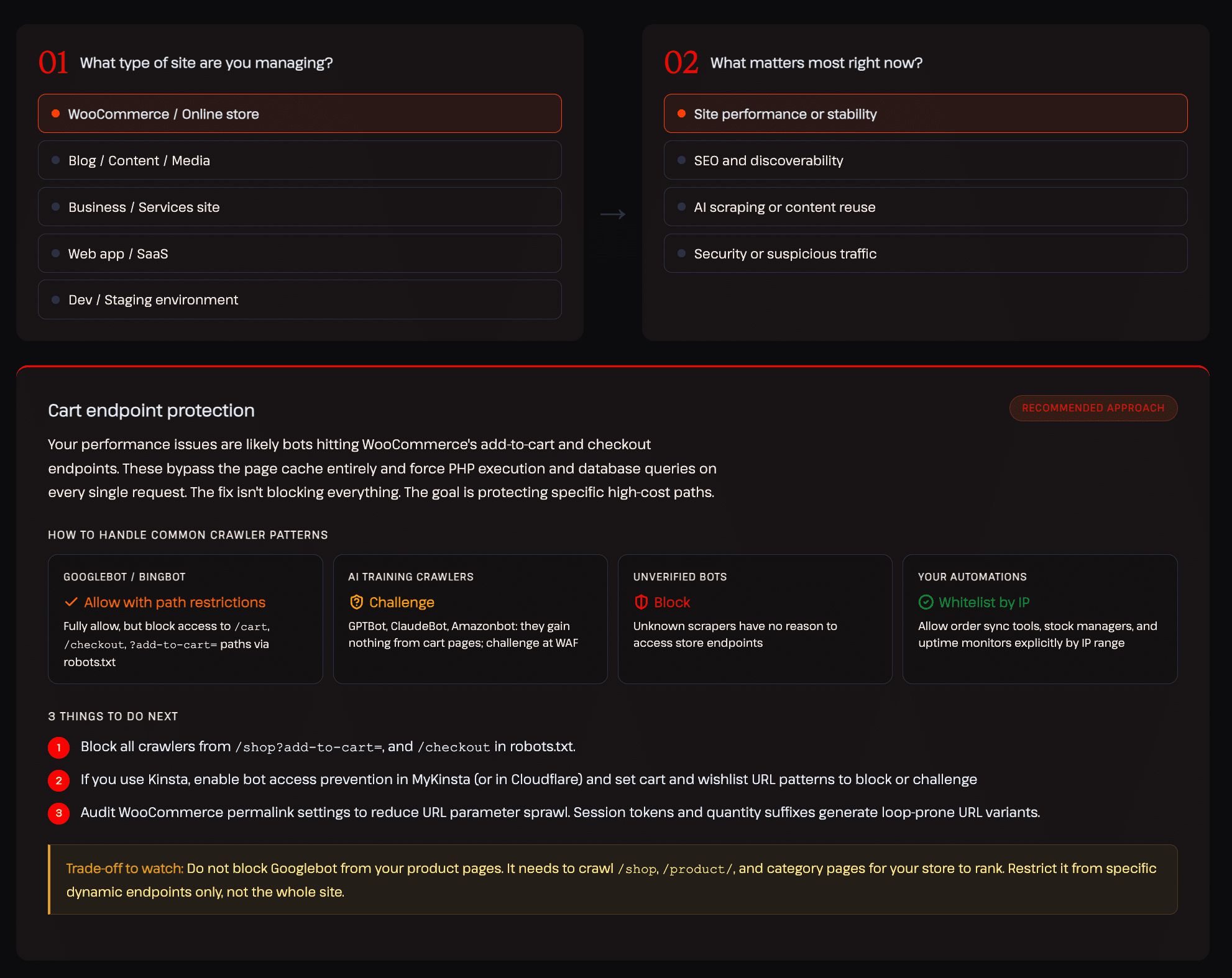
Questo tipo di controllo sfumato e sensibile alle categorie è esattamente ciò che la maggior parte degli strumenti esistenti non ti offre.
L’approccio di Kinsta alla protezione dai bot
Quello che abbiamo realizzato con Protezione bot di Kinsta è stato progettato specificamente per affrontare le sfide infrastrutturali descritte sopra.
Il sistema classifica il traffico in categorie quali bot verificati, probabili utenti umani, probabili bot, traffico automatizzato e traffico dannoso, e permette di impostare livelli di protezione che corrispondono alle reali esigenze del sito.

I livelli non sono binari. “Blocca le automazioni” prende di mira il traffico automatizzato confermato, lasciando inalterati i bot verificati. “Verifica bot” aggiunge una fase di verifica per le automazioni non verificate senza disturbare i visitatori legittimi. “Verifica tutti” è disponibile per i periodi di picco di traffico, ma comporta i compromessi che ti aspetteresti.
Fondamentalmente, lo strumento si basa sul sistema di valutazione dei bot di livello enterprise di Cloudflare, una classificazione in tempo reale basata sull’apprendimento automatico che assegna a ogni visitatore un punteggio da 1 a 99 in base a segnali comportamentali, non solo alle stringhe dell’user-agent. Questo è importante perché il solo confronto dell’user-agent sta diventando sempre meno efficace, dato che il 12,9% dei bot basati sull’intelligenza artificiale ora ignora le direttive robots.txt, in aumento rispetto al 3,3% di appena un trimestre fa. La classificazione comportamentale rileva ciò che le regole basate sull’user-agent non riescono a individuare.
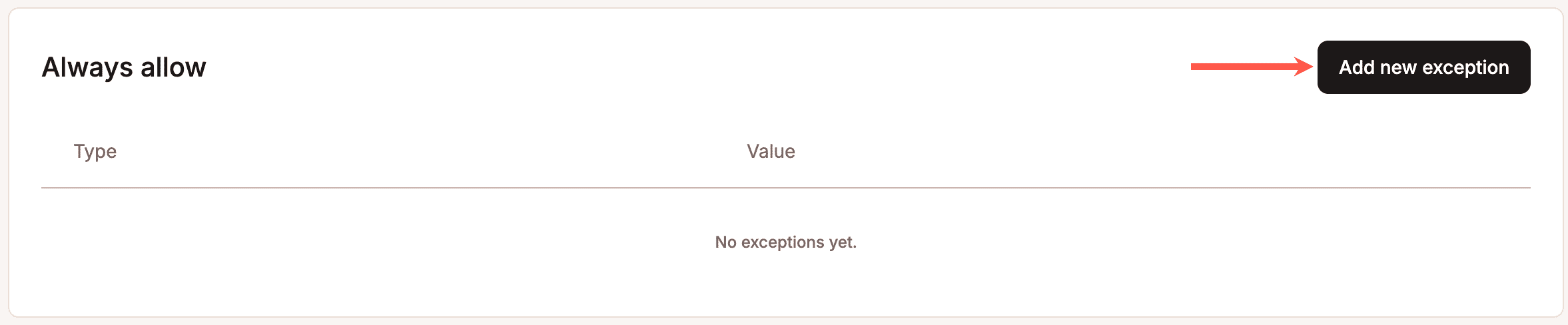
C’è anche un sistema di eccezioni “Consenti sempre” per integrazioni affidabili, servizi di monitoraggio e automazioni fondamentali per l’attività che non dovrebbero essere bloccate dalle regole di protezione, perché anche il blocco eccessivo comporta un costo reale, in particolare per i negozi WooCommerce che si affidano alla sincronizzazione automatica degli ordini, alle integrazioni con i gateway di pagamento o ai monitor di uptime.
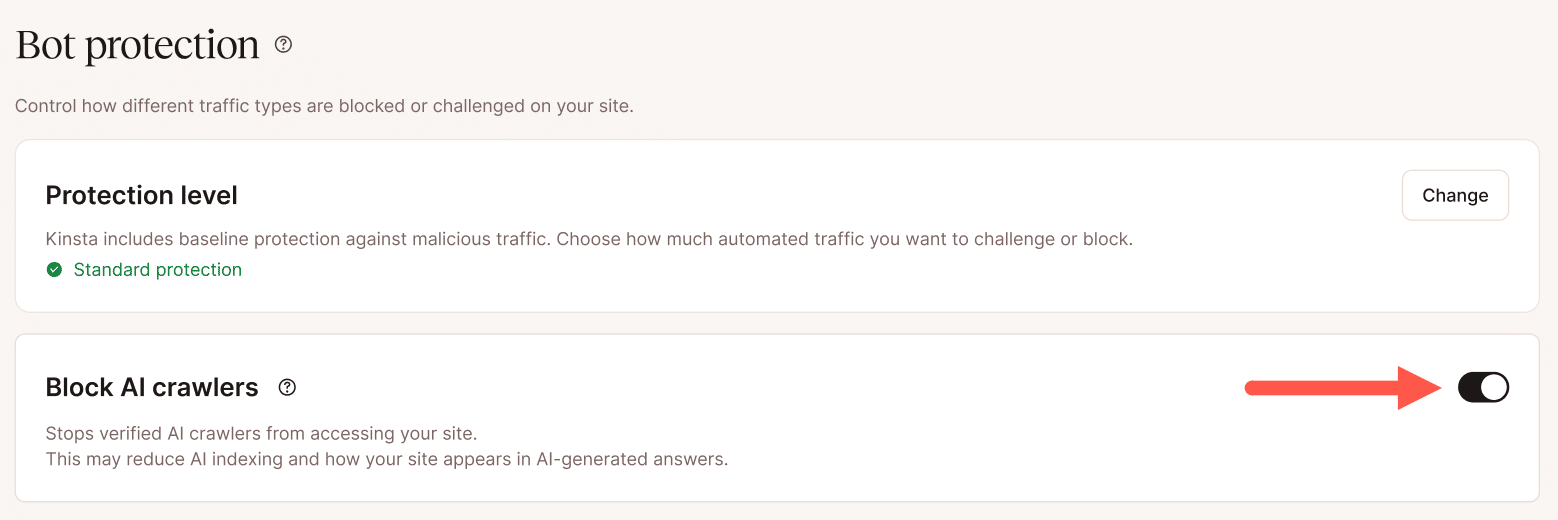
L’opzione di blocco dei crawler AI prende di mira specificatamente i bot di addestramento dell’AI senza influire sui crawler dei motori di ricerca come Googlebot o Bingbot. Per i siti che hanno identificato l’attività dei crawler AI come fattore di miglioramento delle prestazioni, questa è una misura di mitigazione in un solo passaggio che non richiede la configurazione di regole individuali.
Sapere che lo strumento esiste è una cosa. Sapere quando e come usarlo è un’altra.
Cosa fare se il traffico bot diventa un problema
Se noti gli schemi descritti sopra, ecco un punto di partenza pratico, ordinato in base all’impatto:
Primo: verifica la fonte. Usa il grafico di ripartizione delle richieste nella scheda Protezione dai bot di MyKinsta per capire come viene classificato il traffico verso il tuo sito.
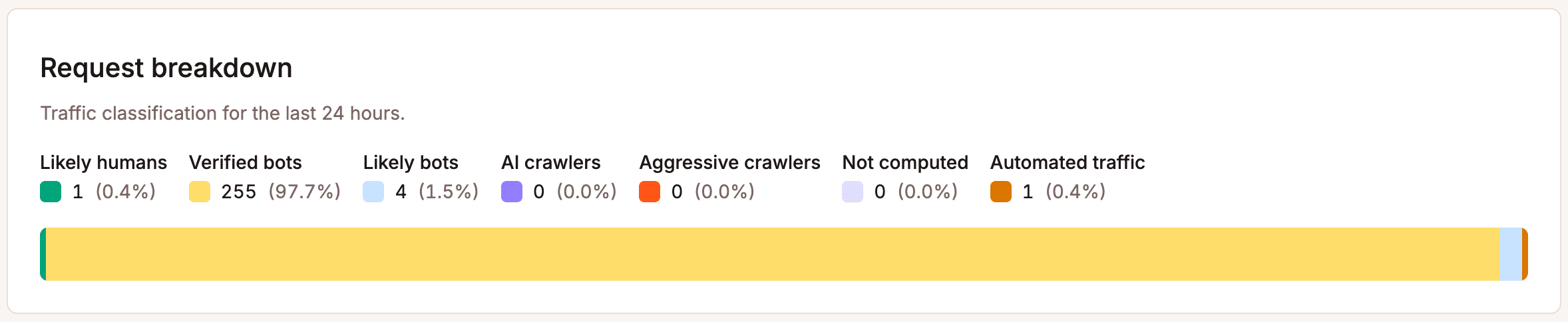
Se una parte consistente è automatizzata o non verificata, è il segnale che devi agire. Non saltare questo passaggio, perché apportare modifiche alla protezione senza sapere da cosa ti stai proteggendo porta a configurazioni errate.
Secondo: adatta il livello di protezione al tipo di sito. Un negozio WooCommerce ha priorità diverse rispetto a un sito di pubblicazione di contenuti, che a sua volta ha priorità diverse rispetto a un ambiente di staging. Bloccare il traffico automatizzato e mettere alla prova i potenziali bot ha senso per un negozio con endpoint dinamici. Un sito di contenuti potrebbe dare priorità all’accesso ai bot di discovery AI, bloccando al contempo i crawler di addestramento dell’AI. Un ambiente di staging dovrebbe comunque essere completamente bloccato.
Terzo: proteggi prima i percorsi più costosi. Prima di applicare regole di protezione generiche, valuta se i tuoi endpoint più costosi, come il carrello, il checkout e gli handler AJAX, siano accessibili a crawler che non hanno motivo di trovarsi lì. Bloccare gli user agent noti dei bot provenienti da /cart e ?add-to-cart= tramite robots.txt è un punto di partenza; applicarlo a livello di WAF (non solo segnalarlo) è ciò che impedisce effettivamente il sovraccarico.
Quarto: monitora, poi modifica. I modelli di traffico dei bot cambiano più velocemente di quanto la maggior parte dei proprietari di siti si renda conto. La quota di traffico di GPTBot è triplicata nel giro di un solo anno. Impostare le regole di protezione una volta sola e poi smettere di pensarci non è una strategia. Il grafico dei risultati della protezione bot in MyKinsta tiene traccia di ciò che viene bloccato, verificato e consentito nel tempo.
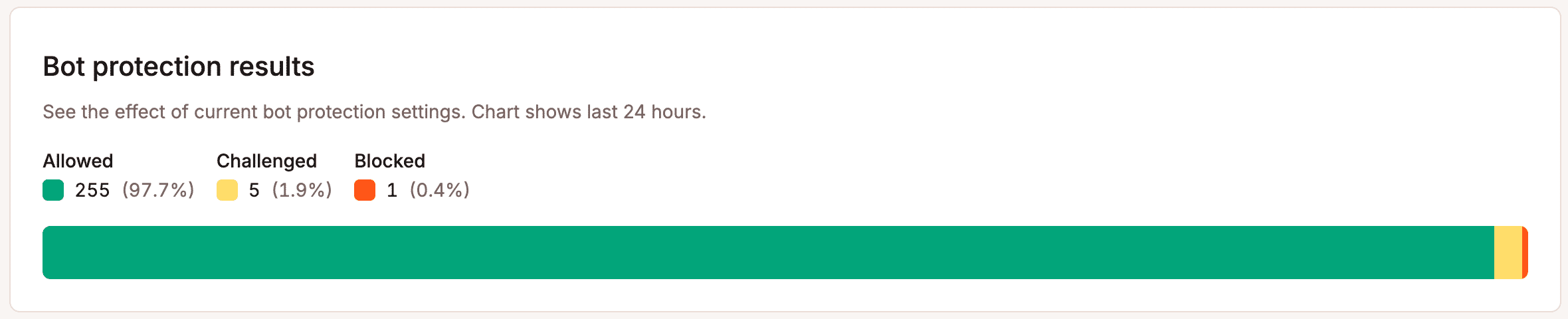
Questi dati dovrebbero guidarti nell’ottimizzazione delle tue impostazioni.
Se i bot stanno generando un superamento del limite di visite su un piano basato sulle visite, potrebbe valere la pena valutare parallelamente i piani di hosting basati sulla larghezza di banda di Kinsta. Passare a un piano basato sulla larghezza di banda non risolve il problema di fondo dei bot, ma può riflettere meglio il costo effettivo dell’infrastruttura per il tuo mix di traffico, che spesso è notevolmente inferiore a quanto suggerisce il conteggio delle visite.
Il quadro generale: questo problema diventerà più complesso
Il traffico agentico sta già comparendo nei log dell’infrastruttura. Google ha annunciato uno user agent dedicato per quando i suoi agenti AI interagiscono con i siti. Si tratta di sistemi automatizzati che cliccano sui link, compilano moduli ed effettuano richieste che assomigliano sempre di più al comportamento delle sessioni umane.
I segnali che attualmente funzionano per la classificazione dei bot, come le stringhe degli user agent, la frequenza delle richieste e il punteggio comportamentale, diventano più difficili da applicare in modo preciso man mano che il confine tra interazione automatizzata e umana continua a sfumarsi.
La maggior parte dei proprietari di siti non riesce a stare al passo da sola. Il comportamento dei bot si evolve più velocemente di quanto le regole manuali possano adattarsi. Ciò che funzionava tre mesi fa potrebbe già essere insufficiente. E il costo di un errore in termini di risorse del server, di costi aggiuntivi in fattura e di clienti reali che ricevono errori 504 durante il checkout è reale e immediato.
Ecco perché serve un’infrastruttura che se ne occupi al posto tuo. La piattaforma di Kinsta blocca il 15–20% del traffico dannoso prima ancora che raggiunga il tuo sito, si appoggia alla rete aziendale di Cloudflare e ti offre controlli di protezione dai bot che si adattano al comportamento effettivo del tuo sito. Man mano che il traffico dei bot continua a evolversi, la differenza tra una piattaforma di hosting che lo considera un problema di infrastruttura e una che lo tratta come una nota a margine diventerà sempre più difficile da ignorare.
I siti che gestiscono bene questa situazione non saranno quelli che bloccano di più. Saranno quelli che girano su un’infrastruttura costruita per gestire al meglio i bot.


