
Jeder Website-Besitzer wird dir sagen, dass Datenverluste und Ausfallzeiten, selbst in minimalen Dosen, katastrophale Folgen haben können. Sie können den Unvorbereiteten jederzeit treffen und die Produktivität, Erreichbarkeit und das Vertrauen in das Produkt beeinträchtigen.
Um die Integrität deiner Website zu schützen, ist es wichtig, Vorkehrungen gegen mögliche Ausfallzeiten oder Datenverluste zu treffen.
Hier kommt die Datenreplikation ins Spiel.
Die Datenreplikation ist ein automatischer Sicherungsprozess, bei dem deine Daten wiederholt von der Hauptdatenbank an einen anderen, entfernten Ort kopiert und dort gesichert werden. Sie ist eine wichtige Technologie für jede Website oder Anwendung mit einem Datenbankserver. Du kannst die replizierte Datenbank auch nutzen, um schreibgeschütztes SQL zu verarbeiten, sodass mehr Prozesse im System ausgeführt werden können.
Die Replikation zwischen zwei Datenbanken bietet Fehlertoleranz gegen unerwartete Pannen. Sie gilt als die beste Strategie, um im Katastrophenfall eine hohe Verfügbarkeit zu erreichen.
In diesem Artikel befassen wir uns mit den verschiedenen Strategien, die Backend-Entwickler/innen für eine nahtlose PostgreSQL-Replikation einsetzen können.
Was ist PostgreSQL Replikation?
Unter PostgreSQL-Replikation versteht man den Prozess des Kopierens von Daten von einem PostgreSQL-Datenbankserver auf einen anderen Server. Der Quelldatenbankserver wird auch als „primärer“ Server bezeichnet, während der Datenbankserver, der die kopierten Daten erhält, als „Replikatserver“ bezeichnet wird.
Die PostgreSQL-Datenbank folgt einem einfachen Replikationsmodell, bei dem alle Schreibvorgänge an einen primären Knoten gehen. Der primäre Knoten kann dann die Änderungen übernehmen und sie an die sekundären Knoten weiterleiten.
Was ist automatisches Failover?
Failover ist eine Methode zur Wiederherstellung von Daten, wenn der Hauptserver aus irgendeinem Grund ausfällt. Solange du PostreSQL so konfiguriert hast, dass es deine physische Streaming-Replikation verwaltet, sind du – und deine Nutzer – vor Ausfällen aufgrund eines Ausfalls des Primärservers geschützt.
Beachte, dass es einige Zeit dauern kann, den Failover-Prozess einzurichten und zu starten. Es gibt keine eingebauten Tools, um Serverausfälle in PostgreSQL zu überwachen und zu erfassen, du musst also kreativ werden.
Zum Glück bist du beim Failover nicht auf PostgreSQL angewiesen. Es gibt spezielle Tools, die ein automatisches Failover und ein automatisches Umschalten auf den Standby-Server ermöglichen und so die Ausfallzeiten der Datenbank reduzieren.
Wenn du eine Failover-Replikation einrichtest, garantierst du praktisch Hochverfügbarkeit, indem du sicherstellst, dass der Standby-Server verfügbar ist, falls der primäre Server einmal ausfällt.
Vorteile der PostgreSQL-Replikation
Hier sind einige der wichtigsten Vorteile der PostgreSQL-Replikation:
- Datenmigration: Du kannst die PostgreSQL-Replikation für die Datenmigration nutzen, entweder durch einen Wechsel der Datenbankserver-Hardware oder durch eine Systembereitstellung.
- Fehlertoleranz: Wenn der Primärserver ausfällt, kann der Standby-Server als Server fungieren, da die enthaltenen Daten für Primär- und Standby-Server identisch sind.
- Leistung der Online-Transaktionsverarbeitung (OLTP): Du kannst die Transaktionsverarbeitungszeit und die Abfragezeit eines OLTP-Systems verbessern, indem du die Last der Berichtsabfragen entfernst. Die Transaktionsverarbeitungszeit ist die Dauer, die eine bestimmte Abfrage benötigt, bis eine Transaktion abgeschlossen ist.
- Parallele Systemtests: Wenn du ein neues System aktualisierst, musst du sicherstellen, dass das System mit den vorhandenen Daten gut zurechtkommt. Daher ist es notwendig, das System vor dem Einsatz mit einer Kopie der Produktionsdatenbank zu testen.
Wie PostgreSQL-Replikation funktioniert
Im Allgemeinen glauben die Leute, dass es nur einen Weg gibt, Backups und Replikationen einzurichten, wenn du mit einer primären und sekundären Architektur arbeitest. PostgreSQL-Implementierungen können jedoch jeder dieser drei Methoden folgen:
- Streaming-Replikation: Repliziert die Daten vom primären Knoten auf den sekundären und kopiert sie dann in Amazon S3 oder Azure Blob als Backup-Speicher.
- Replikation auf Volume-Ebene: Repliziert Daten auf der Speicherebene, beginnend vom primären Knoten zum sekundären Knoten, und kopiert die Daten dann in Amazon S3 oder Azure Blob als Backup-Speicher.
- Inkrementelle Backups: Repliziert die Daten des primären Knotens, während ein neuer sekundärer Knoten aus dem Amazon S3- oder Azure Blob-Speicher erstellt wird, was Streaming direkt vom primären Knoten ermöglicht.
Methode 1: Streaming
Die PostgreSQL-Streaming-Replikation, auch bekannt als WAL-Replikation, kann nahtlos nach der Installation von PostgreSQL auf allen Servern eingerichtet werden. Dieser Replikationsansatz basiert auf dem Verschieben der WAL-Dateien von der Primär- zur Zieldatenbank.
Du kannst die PostgreSQL-Streaming-Replikation mit einer Primär-Sekundär-Konfiguration implementieren. Der primäre Server ist die Hauptinstanz, die die primäre Datenbank und alle ihre Operationen verwaltet. Der sekundäre Server fungiert als zusätzliche Instanz und führt alle Änderungen an der primären Datenbank auf sich selbst aus, wobei er eine identische Kopie erzeugt. Der Primärserver ist der Lese-/Schreibserver, während der Sekundärserver nur Lesezugriff hat.
Bei dieser Methode musst du sowohl den primären als auch den Standby-Knoten konfigurieren. In den folgenden Abschnitten werden die Schritte erläutert, die für eine einfache Konfiguration erforderlich sind.
Konfiguration des primären Knotens
Du kannst den Primärknoten für die Streaming-Replikation konfigurieren, indem du die folgenden Schritte durchführst:
Schritt 1: Initialisierung der Datenbank
Um die Datenbank zu initialisieren, kannst du den Dienstprogrammbefehl initdb verwenden. Anschließend kannst du mit dem folgenden Befehl einen neuen Benutzer mit Replikationsrechten anlegen:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';Der Benutzer muss ein Passwort und einen Benutzernamen für die angegebene Abfrage angeben. Das Schlüsselwort replication wird verwendet, um dem Benutzer die erforderlichen Rechte zu geben. Eine Beispielabfrage würde etwa so aussehen:
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Schritt 2: Streaming-Eigenschaften konfigurieren
Als Nächstes kannst du die Streaming-Eigenschaften in der PostgreSQL-Konfigurationsdatei (postgresql.conf) konfigurieren, die wie folgt geändert werden kann:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onHier ein paar Hintergrundinformationen zu den Parametern, die im vorherigen Snippet verwendet wurden:
wal_log_hints: Dieser Parameter wird für die Funktionpg_rewindbenötigt, die nützlich ist, wenn der Standby-Server nicht mehr mit dem primären Server synchronisiert ist.wal_level: Mit diesem Parameter kannst du die PostgreSQL Streaming Replikation aktivieren. Mögliche Werte sindminimal,replicaoderlogical.max_wal_size: Mit diesem Parameter kannst du die Größe der WAL-Dateien angeben, die in den Logdateien aufbewahrt werden können.hot_standby: Du kannst diesen Parameter für eine Read-On-Verbindung mit dem sekundären Server nutzen, wenn er auf ON gesetzt ist.max_wal_senders: Mitmax_wal_senderskannst du die maximale Anzahl der gleichzeitigen Verbindungen festlegen, die mit den Standby-Servern hergestellt werden können.
Schritt 3: Neuen Eintrag erstellen
Nachdem du die Parameter in der Datei postgresql.conf geändert hast, kann ein neuer Replikationseintrag in der Datei pg_hba.conf dafür sorgen, dass die Server für die Replikation eine Verbindung zueinander aufbauen.
Du findest diese Datei normalerweise im Datenverzeichnis von PostgreSQL. Du kannst dafür den folgenden Codeausschnitt verwenden:
host replication rep_user IPaddress md5Sobald das Codeschnipsel ausgeführt wird, erlaubt der Primärserver einem Benutzer namens rep_user, sich zu verbinden und als Standby-Server zu fungieren, indem er die angegebene IP für die Replikation verwendet. Zum Beispiel:
host replication rep_user 192.168.0.22/32 md5Standby-Knoten konfigurieren
Um den Standby-Knoten für die Streaming-Replikation zu konfigurieren, befolgst du die folgenden Schritte:
Schritt 1: Sichern des primären Knotens
Um den Standby-Knoten zu konfigurieren, erstellst du mit dem Dienstprogramm pg_basebackup ein Backup des primären Knotens. Diese dient als Startpunkt für den Standby-Knoten. Du kannst dieses Dienstprogramm mit der folgenden Syntax verwenden:
pg_basebackp -D -h -X stream -c fast -U rep_user -WDie in der oben genannten Syntax verwendeten Parameter lauten wie folgt:
-h: Damit kannst du den primären Host angeben.-D: Dieser Parameter gibt das Verzeichnis an, in dem du gerade arbeitest.-C: Damit kannst du die Checkpoints setzen.-X: Mit diesem Parameter kannst du die notwendigen Transaktionsprotokolldateien einbinden.-W: Mit diesem Parameter kannst du den Benutzer zur Eingabe eines Passworts auffordern, bevor er sich mit der Datenbank verbindet.
Schritt 2: Replikationskonfigurationsdatei einrichten
Als Nächstes musst du prüfen, ob die Replikationskonfigurationsdatei existiert. Ist dies nicht der Fall, kannst du die Replikationskonfigurationsdatei als recovery.conf erstellen.
Du solltest diese Datei im Datenverzeichnis der PostgreSQL-Installation erstellen. Du kannst sie automatisch erstellen, indem du die Option -R im Dienstprogramm pg_basebackup verwendest.
Die Datei recovery.conf sollte die folgenden Befehle enthalten:
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'Die in den oben genannten Befehlen verwendeten Parameter lauten wie folgt:
primary_conninfo: Mit diesem Parameter kannst du eine Verbindung zwischen dem primären und dem sekundären Server herstellen, indem du einen Verbindungsstring verwendest.standby_mode: Dieser Parameter kann bewirken, dass der primäre Server als Standby-Server gestartet wird, wenn er eingeschaltet wird.recovery_target_timeline: Damit kannst du die Wiederherstellungszeit festlegen.
Um eine Verbindung einzurichten, musst du den Benutzernamen, die IP-Adresse und das Passwort als Werte für den Parameter primary_conninfo angeben. Zum Beispiel:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Schritt 3: Neustart des Sekundärservers
Zum Schluss kannst du den Sekundärserver neu starten, um den Konfigurationsprozess abzuschließen.
Die Streaming-Replikation bringt jedoch einige Herausforderungen mit sich, wie zum Beispiel:
- Verschiedene PostgreSQL-Clients (in verschiedenen Programmiersprachen geschrieben) kommunizieren mit einem einzigen Endpunkt. Wenn der primäre Knoten ausfällt, versuchen diese Clients immer wieder denselben DNS- oder IP-Namen. Dadurch wird das Failover für die Anwendung sichtbar.
- Die PostgreSQL-Replikation verfügt nicht über eine integrierte Ausfallsicherung und Überwachung. Wenn der Primärknoten ausfällt, musst du einen Sekundärknoten zum neuen Primärknoten ernennen. Diese Beförderung muss so durchgeführt werden, dass die Clients nur auf einen primären Knoten schreiben und keine Dateninkonsistenzen bemerken.
- PostgreSQL repliziert seinen gesamten Zustand. Wenn du einen neuen sekundären Knoten entwickeln musst, muss der sekundäre Knoten die gesamte Historie der Zustandsänderungen des primären Knotens rekapitulieren, was ressourcenintensiv ist und es kostspielig macht, Knoten im Kopf zu eliminieren und neue zu erstellen.
Methode 2: Repliziertes Blockgerät
Der Methode des replizierten Blockgeräts basiert auf der Spiegelung von Festplatten (auch bekannt als Volume-Replikation). Bei diesem Ansatz werden Änderungen auf ein persistentes Volume geschrieben, das synchron auf ein anderes Volume gespiegelt wird.
Der zusätzliche Vorteil dieses Methode ist die Kompatibilität und Datenbeständigkeit in Cloud-Umgebungen mit allen relationalen Datenbanken, wie PostgreSQL, MySQL und SQL Server, um nur einige zu nennen.
Bei der PostgreSQL-Replikation mit Disk-Mirroring musst du jedoch sowohl die WAL-Log- als auch die Tabellendaten replizieren. Da jeder Schreibvorgang in die Datenbank nun synchron über das Netzwerk erfolgen muss, kannst du es dir nicht erlauben, auch nur ein einziges Byte zu verlieren, da deine Datenbank sonst beschädigt werden könnte.
Dieser Methode wird normalerweise mit Azure PostgreSQL und Amazon RDS genutzt.
Methode 3: WAL
WAL besteht aus Segmentdateien (standardmäßig 16 MB). Jedes Segment enthält einen oder mehrere Datensätze. Ein Log Sequence Record (LSN) ist ein Zeiger auf einen Datensatz in der WAL, der dir die Position/den Ort angibt, an dem der Datensatz in der Logdatei gespeichert wurde.
Ein Standby-Server nutzt WAL-Segmente – in der PostgreSQL-Terminologie auch XLOGS genannt -, um Änderungen des Primärservers kontinuierlich zu replizieren. Du kannst Write-Ahead-Logging verwenden, um Haltbarkeit und Atomarität in einem DBMS zu gewährleisten, indem du Datenpakete aus Byte-Arrays (jedes mit einer eindeutigen LSN) in einen stabilen Speicher serialisierst, bevor sie auf eine Datenbank angewendet werden.
Die Anwendung einer Mutation auf eine Datenbank kann zu verschiedenen Dateisystemoperationen führen. Eine wichtige Frage, die sich stellt, ist, wie eine Datenbank die Atomarität im Falle eines Serverausfalls aufgrund eines Stromausfalls sicherstellen kann, während sie mitten in einer Dateisystemaktualisierung steckt. Wenn eine Datenbank hochfährt, startet sie einen Start- oder Replay-Prozess, der die verfügbaren WAL-Segmente lesen kann und sie mit der LSN vergleicht, die auf jeder Datenseite gespeichert ist (jede Datenseite ist mit der LSN des letzten WAL-Datensatzes markiert, der die Seite betrifft).
Log Shipping-basierte Replikation (Block Level)
Die Streaming-Replikation verfeinert den Log-Shipping-Prozess. Anstatt auf den WAL-Wechsel zu warten, werden die Datensätze gesendet, sobald sie erstellt werden.
Die Streaming-Replikation übertrumpft auch den Log-Versand, weil der Standby-Server über das Netzwerk mit dem Primärserver verbunden ist, indem er ein Replikationsprotokoll nutzt. Der Primärserver kann dann WAL-Datensätze direkt über diese Verbindung senden, ohne auf Skripte angewiesen zu sein, die vom Endbenutzer bereitgestellt werden.
Log Shipping-basierte Replikation (File Level)
Unter Log Shipping versteht man das Kopieren von Logdateien auf einen anderen PostgreSQL-Server, um einen weiteren Standby-Server durch die Wiedergabe von WAL-Dateien zu erzeugen. Dieser Server ist so konfiguriert, dass er im Wiederherstellungsmodus arbeitet, und sein einziger Zweck ist es, alle neuen WAL-Dateien anzuwenden, sobald sie auftauchen.
Dieser sekundäre Server wird dann zu einem Warm-Backup des primären PostgreSQL-Servers. Er kann auch als Read Replica konfiguriert werden, so dass er nur Leseabfragen durchführen kann, was auch als Hot Standby bezeichnet wird.
Kontinuierliche WAL-Archivierung
Das Duplizieren von WAL-Dateien, sobald sie erstellt werden, in ein anderes Verzeichnis als das Unterverzeichnis pg_wal, um sie zu archivieren, wird als WAL-Archivierung bezeichnet. PostgreSQL ruft jedes Mal, wenn eine WAL-Datei erstellt wird, ein vom Benutzer angegebenes Skript zur Archivierung auf.
Das Skript kann den Befehl scp nutzen, um die Datei an einen oder mehrere Speicherorte zu duplizieren, z. B. in ein NFS-Mount. Einmal archiviert, können die WAL-Segmentdateien genutzt werden, um die Datenbank zu einem beliebigen Zeitpunkt wiederherzustellen.
Weitere logbasierte Konfigurationen sind:
- Synchrone Replikation: Bevor ein synchroner Replikationsvorgang bestätigt wird, wartet der Primärserver, bis die Standbys bestätigen, dass sie die Daten erhalten haben. Der Vorteil dieser Konfiguration ist, dass es keine Konflikte durch parallele Schreibvorgänge gibt.
- Synchrone Multi-Master-Replikation: Hier kann jeder Server Schreibanfragen annehmen, und die geänderten Daten werden vom ursprünglichen Server an jeden anderen Server übertragen, bevor jede Transaktion bestätigt wird. Sie nutzt das 2PC-Protokoll und hält sich an die Alles-oder-Nichts-Regel.
Details zum WAL-Streaming-Protokoll
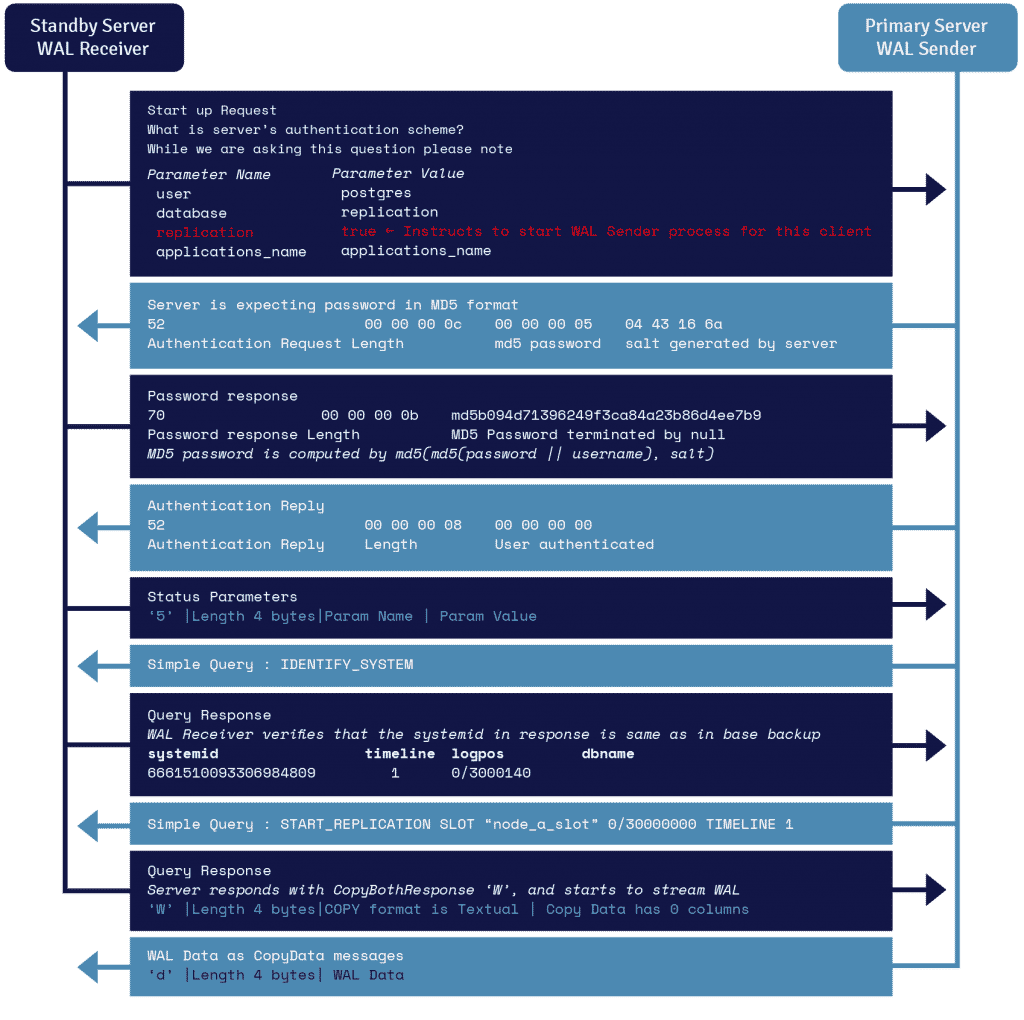
Ein Prozess, der als WAL-Receiver bezeichnet wird, und auf dem Standby-Server läuft, nutzt die Verbindungsdetails, die im Parameter primary_conninfo der recovery.conf angegeben sind, und verbindet sich über eine TCP/IP-Verbindung mit dem Primärserver.
Um die Streaming-Replikation zu starten, kann das Frontend den Replikationsparameter in der Startnachricht senden. Ein boolescher Wert von true, yes, 1 oder ON teilt dem Backend mit, dass es in den physischen Replikations-Walsender-Modus wechseln muss.
Der WAL-Sender ist ein weiterer Prozess, der auf dem Primärserver läuft und dafür zuständig ist, die WAL-Datensätze an den Standby-Server zu senden, sobald sie erzeugt werden. Der WAL-Receiver speichert die WAL-Datensätze in der WAL, als ob sie durch die Client-Aktivitäten der lokal verbundenen Clients erstellt worden wären.
Sobald die WAL-Datensätze die WAL-Segmentdateien erreicht haben, spielt der Standby-Server die WAL ständig neu ab, damit Primär- und Standby-Server auf dem neuesten Stand sind.
Elemente der PostgreSQL-Replikation
In diesem Abschnitt lernst du die gebräuchlichen Modelle (Single-Master- und Multi-Master-Replikation), Typen (physische und logische Replikation) und Modi (synchron und asynchron) der PostgreSQL-Replikation näher kennen.
Modelle der PostgreSQL Datenbankreplikation
Skalierbarkeit bedeutet, dass mehr Ressourcen/Hardware zu den bestehenden Knoten hinzugefügt werden, um die Fähigkeit der Datenbank zu verbessern, mehr Daten zu speichern und zu verarbeiten, was horizontal und vertikal erreicht werden kann. Die PostgreSQL-Replikation ist ein Beispiel für horizontale Skalierbarkeit, die viel schwieriger zu implementieren ist als vertikale Skalierbarkeit. Wir können horizontale Skalierbarkeit hauptsächlich durch Single-Master-Replikation (SMR) und Multi-Master-Replikation (MMR) erreichen.
Bei der Single-Master-Replikation können Daten nur auf einem einzigen Knoten geändert werden, und diese Änderungen werden auf einen oder mehrere Knoten repliziert. Die replizierten Tabellen in der Replikatdatenbank dürfen keine Änderungen annehmen, außer die vom Primärserver. Selbst wenn dies der Fall ist, werden die Änderungen nicht auf den Primärserver zurückrepliziert.
In den meisten Fällen ist SMR für die Anwendung ausreichend, da es weniger kompliziert zu konfigurieren und zu verwalten ist und keine Konflikte auftreten können. Die Single-Master-Replikation ist außerdem unidirektional, da die Replikationsdaten nur in eine Richtung fließen, nämlich vom Primärserver zur Replikatdatenbank.
In manchen Fällen ist SMR allein nicht ausreichend und du musst MMR implementieren. MMR ermöglicht es, dass mehr als ein Knoten als primärer Knoten fungiert. Änderungen an Tabellenzeilen in mehr als einer bestimmten primären Datenbank werden auf die entsprechenden Tabellen in jeder anderen primären Datenbank repliziert. Bei diesem Modell werden oft Konfliktlösungsschemata eingesetzt, um Probleme wie doppelte Primärschlüssel zu vermeiden.
Die Verwendung von MMR hat einige Vorteile, nämlich
- Fällt ein Server aus, können andere Server weiterhin Aktualisierungs- und Einfügedienste anbieten.
- Die primären Knotenpunkte sind auf mehrere Standorte verteilt, so dass die Wahrscheinlichkeit eines Ausfalls aller primären Knotenpunkte sehr gering ist.
- Die Möglichkeit, ein Wide Area Network (WAN) von Primärdatenbanken zu nutzen, die sich geografisch in der Nähe von Kundengruppen befinden können, wobei die Datenkonsistenz im gesamten Netzwerk erhalten bleibt.
Der Nachteil von MMR ist jedoch die Komplexität und die Schwierigkeit, Konflikte aufzulösen.
Verschiedene Branchen und Anwendungen bieten MMR-Lösungen an, da PostgreSQL sie nicht von Haus aus unterstützt. Diese Lösungen können Open-Source, kostenlos oder kostenpflichtig sein. Eine solche Erweiterung ist die bidirektionale Replikation (BDR), die asynchron ist und auf der logischen Dekodierungsfunktion von PostgreSQL basiert.
Da die BDR-Anwendung Transaktionen auf anderen Knoten wiedergibt, kann die Wiedergabe fehlschlagen, wenn es einen Konflikt zwischen der angewendeten Transaktion und der Transaktion gibt, die auf dem empfangenden Knoten übertragen wurde.
Arten der PostgreSQL-Replikation
Es gibt zwei Arten der PostgreSQL-Replikation: die logische und die physische Replikation.
Eine einfache logische Operation initdb würde die physische Operation der Erstellung eines Basisverzeichnisses für einen Cluster ausführen. Ebenso würde eine einfache logische Operation CREATE DATABASE die physische Operation der Erstellung eines Unterverzeichnisses im Basisverzeichnis durchführen.
Die physische Replikation befasst sich normalerweise mit Dateien und Verzeichnissen. Sie weiß nicht, was diese Dateien und Verzeichnisse darstellen. Diese Methoden werden verwendet, um eine vollständige Kopie der gesamten Daten eines einzelnen Clusters, in der Regel auf einem anderen Rechner, zu erhalten. Sie erfolgen auf Dateisystem- oder Festplattenebene und verwenden exakte Blockadressen.
Bei der logischen Replikation werden Dateneinheiten und ihre Änderungen auf der Grundlage ihrer Replikationsidentität (normalerweise ein Primärschlüssel) reproduziert. Im Gegensatz zur physischen Replikation bezieht sie sich auf Datenbanken, Tabellen und DML-Operationen und wird auf der Ebene des Datenbank-Clusters durchgeführt. Sie verwendet ein Publish-and-Subscribe-Modell, bei dem ein oder mehrere Subscriber eine oder mehrere Publikationen auf einem Publisher-Node abonnieren.
Der Replikationsprozess beginnt damit, dass ein Snapshot der Daten in der Publisher-Datenbank erstellt und dann auf den Subscriber kopiert wird. Die Subscriber ziehen die Daten aus den Publikationen, die sie abonniert haben, und können die Daten später erneut veröffentlichen, um eine kaskadierende Replikation oder komplexere Konfigurationen zu ermöglichen. Der Subscriber wendet die Daten in der gleichen Reihenfolge wie der Herausgeber an, so dass die transaktionale Konsistenz für die Publikationen innerhalb eines einzigen Abonnements gewährleistet ist, auch bekannt als transaktionale Replikation.
Die typischen Anwendungsfälle für die logische Replikation sind:
- Inkrementelle Änderungen in einer einzelnen Datenbank (oder einer Teilmenge einer Datenbank) an die Abonnenten weiterleiten, sobald sie auftreten.
- Gemeinsame Nutzung einer Teilmenge der Datenbank durch mehrere Datenbanken.
- Auslösen des Feuerns einzelner Änderungen, sobald sie beim Abonnenten ankommen.
- Konsolidierung mehrerer Datenbanken zu einer einzigen.
- Bereitstellung des Zugriffs auf replizierte Daten für verschiedene Benutzergruppen.
Die Abonnentendatenbank verhält sich wie jede andere PostgreSQL-Instanz und kann als Publisher für andere Datenbanken verwendet werden, indem sie ihre Publikationen definiert.
Wenn der Abonnent von der Anwendung als schreibgeschützt behandelt wird, gibt es keine Konflikte durch ein einzelnes Abonnement. Wenn jedoch andere Anwendungen oder andere Abonnenten auf dieselben Tabellen schreiben, kann es zu Konflikten kommen.
PostgreSQL unterstützt beide Mechanismen gleichzeitig. Die logische Replikation ermöglicht eine fein abgestufte Kontrolle sowohl über die Datenreplikation als auch über die Sicherheit.
Replikationsmodi
Es gibt hauptsächlich zwei Arten der PostgreSQL-Replikation: synchrone und asynchrone. Bei der synchronen Replikation können die Daten gleichzeitig auf den primären und den sekundären Server geschrieben werden, während bei der asynchronen Replikation die Daten zuerst auf den Host geschrieben und dann auf den sekundären Server kopiert werden.
Bei der synchronen Replikation gelten die Transaktionen in der primären Datenbank erst dann als abgeschlossen, wenn die Änderungen auf alle Replikate übertragen wurden. Die Replikationsserver müssen alle ständig verfügbar sein, damit die Transaktionen auf dem Primärserver abgeschlossen werden können. Der synchrone Replikationsmodus wird in High-End-Transaktionsumgebungen verwendet, in denen eine sofortige Ausfallsicherung erforderlich ist.
Im asynchronen Modus können Transaktionen auf dem Primärserver für abgeschlossen erklärt werden, wenn die Änderungen nur auf dem Primärserver durchgeführt wurden. Diese Änderungen werden dann zu einem späteren Zeitpunkt auf den Replikaten repliziert. Die Replikationsserver können für eine bestimmte Zeitspanne nicht synchronisiert sein, was als Replikationsverzögerung bezeichnet wird. Im Falle eines Absturzes kann es zu Datenverlusten kommen, aber der Overhead, den die asynchrone Replikation verursacht, ist gering, so dass er in den meisten Fällen akzeptabel ist (der Host wird nicht überlastet). Der Failover von der primären Datenbank zur sekundären Datenbank dauert länger als die synchrone Replikation.
So richtest du die PostgreSQL-Replikation ein
In diesem Abschnitt zeigen wir dir, wie du den PostgreSQL-Replikationsprozess auf einem Linux-Betriebssystem einrichtest. Für dieses Beispiel verwenden wir Ubuntu 18.04 LTS und PostgreSQL 10.
Legen wir los!
Installation
Du beginnst mit der Installation von PostgreSQL auf Linux mit diesen Schritten:
- Als Erstes musst du den PostgreSQL-Signierschlüssel importieren, indem du den folgenden Befehl in das Terminal eingibst:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - Dann fügst du das PostgreSQL-Repository hinzu, indem du den folgenden Befehl in das Terminal eingibst:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Aktualisiere den Repository Index, indem du den folgenden Befehl in das Terminal eingibst:
sudo apt-get update - Installiere das PostgreSQL-Paket mit dem Befehl apt:
sudo apt-get install -y postgresql-10 - Zum Schluss legst du das Passwort für den PostgreSQL-Benutzer mit dem folgenden Befehl fest:
sudo passwd postgres
Die Installation von PostgreSQL ist sowohl für den primären als auch für den sekundären Server obligatorisch, bevor du den PostgreSQL-Replikationsprozess startest.
Sobald du PostgreSQL auf beiden Servern eingerichtet hast, kannst du mit der Einrichtung der Replikation auf dem primären und dem sekundären Server fortfahren.
Einrichten der Replikation auf dem primären Server
Führe diese Schritte durch, sobald du PostgreSQL auf dem primären und sekundären Server installiert hast.
- Melde dich zunächst mit folgendem Befehl bei der PostgreSQL-Datenbank an:
su - postgres - Erstelle einen Replikationsbenutzer mit dem folgenden Befehl:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Bearbeite pg_hba.cnf mit einer beliebigen nano-Anwendung in Ubuntu und füge die folgende Konfiguration hinzu:
nano /etc/postgresql/10/main/pg_hba.confUm die Datei zu konfigurieren, verwende den folgenden Befehl:
host replication replication MasterIP/24 md5 - Öffne und bearbeite postgresql.conf und füge die folgende Konfiguration auf dem Primärserver ein:
nano /etc/postgresql/10/main/postgresql.confVerwende die folgenden Konfigurationseinstellungen:
listen_addresses = 'localhost,MasterIP' wal_level = replica wal_keep_segments = 64 max_wal_senders = 10 - Starte schließlich PostgreSQL auf dem Hauptserver neu:
systemctl restart postgresqlDamit hast du die Einrichtung auf dem primären Server abgeschlossen.
Einrichten der Replikation auf dem sekundären Server
Befolge diese Schritte, um die Replikation auf dem Sekundärserver einzurichten:
- Melde dich mit folgendem Befehl beim PostgreSQL RDMS an:
su - postgres - Halte den PostgreSQL-Dienst an, damit wir mit dem folgenden Befehl daran arbeiten können:
systemctl stop postgresql - Bearbeite die Datei pg_hba.conf mit diesem Befehl und füge die folgende Konfiguration hinzu:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Öffne und bearbeite die postgresql.conf auf dem sekundären Server und füge die folgende Konfiguration ein bzw. entferne die Kommentare, falls sie vorhanden sind:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPist die Adresse des sekundären Servers - Greife auf das PostgreSQL-Datenverzeichnis auf dem sekundären Server zu und entferne alles:
cd /var/lib/postgresql/10/main rm -rfv * - Kopiere die Dateien des PostgreSQL-Primärserver-Datenverzeichnisses in das PostgreSQL-Sekundärserver-Datenverzeichnis und schreibe diesen Befehl in den Sekundärserver:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Gib das PostgreSQL-Passwort für den Primärserver ein und drücke die Eingabetaste. Als nächstes fügst du den folgenden Befehl für die Wiederherstellungskonfiguration hinzu:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'YOUR_PASSWORDist hier das Passwort für den Replikationsbenutzer auf dem Primärserver, den PostgreSQL erstellt hat - Sobald das Passwort festgelegt ist, musst du die sekundäre PostgreSQL-Datenbank neu starten, da sie angehalten wurde:
systemctl start postgresqlTesten deiner Einrichtung
Nachdem wir nun die Schritte ausgeführt haben, wollen wir den Replikationsprozess testen und die Datenbank des sekundären Servers beobachten. Dazu erstellen wir eine Tabelle auf dem Primärserver und beobachten, ob diese auf dem Sekundärserver wiedergegeben wird.
Los geht’s.
- Da wir die Tabelle auf dem Primärserver erstellen, musst du dich auf dem Primärserver anmelden:
su - postgres psql - Jetzt erstellen wir eine einfache Tabelle namens „testtable“ und fügen Daten in die Tabelle ein, indem wir die folgenden PostgreSQL-Abfragen im Terminal ausführen:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Beobachte die PostgreSQL-Datenbank des Sekundärservers, indem du dich auf dem Sekundärserver anmeldest:
su - postgres psql - Jetzt überprüfen wir, ob die Tabelle „testtable“ existiert und können die Daten zurückgeben, indem wir die folgenden PostgreSQL-Abfragen im Terminal ausführen. Dieser Befehl zeigt im Wesentlichen die gesamte Tabelle an.
select * from testtable;
Das ist die Ausgabe der Testtabelle:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Du solltest die gleichen Daten wie auf dem Primärserver sehen können.
Wenn du das siehst, hast du den Replikationsprozess erfolgreich durchgeführt!
Was sind die Schritte beim manuellen PostgreSQL-Failover?
Schauen wir uns die Schritte für ein manuelles PostgreSQL-Failover an:
- Absturz des primären Servers.
- Promote den Standby-Server, indem du den folgenden Befehl auf dem Standby-Server ausführst:
./pg_ctl promote -D ../sb_data/ server promoting - Verbinde dich mit dem beförderten Standby-Server und füge eine Zeile ein:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Wenn die Einfügung funktioniert, wurde der Standby-Server, der zuvor ein Nur-Lese-Server war, zum neuen Primärserver befördert.
Wie man Failover in PostgreSQL automatisiert
Ein automatisches Failover einzurichten ist einfach.
Du brauchst den EDB PostgreSQL Failover Manager (EFM). Nachdem du den EFM heruntergeladen und auf jedem Primär- und Standby-Knoten installiert hast, kannst du einen EFM-Cluster erstellen, der aus einem Primärknoten, einem oder mehreren Standby-Knoten und einem optionalen Witness-Knoten besteht, der im Falle eines Ausfalls Assertions bestätigt.
Der EFM überwacht kontinuierlich den Systemzustand und sendet E-Mail-Warnungen bei Systemereignissen. Bei einem Ausfall schaltet er automatisch auf den aktuellsten Standby-Knoten um und konfiguriert alle anderen Standby-Server neu, um den neuen primären Knoten zu erkennen.
Es konfiguriert auch Load Balancer (wie pgPool) neu und verhindert „Split-Brain“ (wenn zwei Knoten denken, sie seien jeweils primär).
Zusammenfassung
Aufgrund der großen Datenmengen sind Skalierbarkeit und Sicherheit zu zwei der wichtigsten Kriterien in der Datenbankverwaltung geworden, insbesondere in einer Transaktionsumgebung. Wir können die Skalierbarkeit zwar vertikal verbessern, indem wir mehr Ressourcen/Hardware zu den vorhandenen Knoten hinzufügen, aber das ist nicht immer möglich, oft wegen der Kosten oder der Beschränkungen für das Hinzufügen neuer Hardware.
Daher ist eine horizontale Skalierbarkeit erforderlich, d. h. das Hinzufügen weiterer Knoten zu bestehenden Netzwerkknoten, anstatt die Funktionalität der bestehenden Knoten zu verbessern. An dieser Stelle kommt die PostgreSQL-Replikation ins Spiel.
In diesem Artikel haben wir die Arten von PostgreSQL-Replikationen, die Vorteile, die Replikationsmodi, die Installation und das PostgreSQL-Failover zwischen SMR und MMR besprochen. Jetzt wollen wir von dir hören:
Welche der beiden Methoden setzt du normalerweise ein? Welche Datenbankfunktion ist für dich am wichtigsten und warum? Wir würden gerne deine Gedanken lesen! Teile sie in den Kommentaren unten mit.

Salman Ravoof ist ein autodidaktischer Webentwickler, Autor, Kreativer und ein großer Bewunderer von Free and Open Source Software (FOSS). Neben Technik begeistert er sich für Wissenschaft, Philosophie, Fotografie, Kunst, Katzen und Essen. Erfahre mehr über ihn auf seiner Website und trete mit Salman auf X in Kontakt.

