
Heutzutage benötigt fast jede Software oder Webanwendung eine Datenbank im Backend. Die steigende Anzahl von Transaktionen pro Sekunde und die Terabytes an gespeicherten Daten erfordern ein stabiles und flexibles Framework für die Speicherung und Bereitstellung dieser Daten.
Für Start-ups stellt sich natürlich auch die Frage nach den Kosten. Aber was wäre, wenn wir dir sagen würden, dass du auf diese Datenbank kostenlos zugreifen und sie sogar kostenlos aufbauen kannst?
Ja, du hast richtig gehört – die PostgreSQL-Datenbank garantiert alles, was wir oben erwähnt haben, einschließlich einiger zusätzlicher Vorteile! In diesem Artikel gehen wir auf die verschiedenen Aspekte von PostgreSQL ein, die es ihr ermöglichen, sich in einem sich schnell entwickelnden Segment zu behaupten.
Kommen wir gleich zur Sache.
Was ist PostgreSQL?
PostgreSQL ist ein quelloffenes, sehr stabiles Datenbanksystem, das verschiedene SQL-Funktionen wie Fremdschlüssel, Unterabfragen, Trigger und verschiedene benutzerdefinierte Typen und Funktionen unterstützt. Es erweitert die SQL-Sprache um verschiedene Funktionen, die eine genaue Skalierung und Reservierung von Daten-Workloads ermöglichen. Sie wird vor allem zur Datenspeicherung für viele mobile, Web-, Geodaten- und Analyseanwendungen verwendet.
In diesem Artikel werden wir uns mit allen Aspekten von PostgreSQL befassen und im nächsten Abschnitt mit den wichtigsten Funktionen beginnen. Los geht’s.
Hauptmerkmale von PostgreSQL
Es gibt einige wichtige Eigenschaften der PostgreSQL-Datenbank, die sie einzigartig und im Vergleich zu anderen Datenbanken sehr beliebt machen. Derzeit ist sie die am zweithäufigsten genutzte Datenbank, nur noch hinter MySQL.
Schauen wir uns diese Eigenschaften genauer an.
Verlässlichkeit und Einhaltung von Standards
PostgreSQL bietet echte ACID-Semantik für Transaktionen und unterstützt Fremdschlüssel, Joins, Views, Triggers und Stored Procedures in vielen verschiedenen Sprachen. Die meisten SQL-Datentypen wie INTEGER, VARCHAR, TIMESTAMP und BOOLEAN werden unterstützt. Es unterstützt auch die Speicherung von großen binären Objekten wie Bildern, Videos oder Tönen. PostgreSQL ist zuverlässig, da es über ein großes Community-Support-Netzwerk verfügt. PostgreSQL ist eine fehlertolerante Datenbank dank des Write-Ahead-Loggings.
Erweiterungen
PostgreSQL verfügt über mehrere robuste Funktionen wie Point-in-Time Recovery, Multi-Version Concurrency Control (MVCC), Tablespaces, granulare Zugriffskontrollen, asynchrone Replikation, einen verfeinerten Query Planner/Optimizer und Write-Ahead Logging. Die Multi-Version Concurrency Control ermöglicht das gleichzeitige Lesen und Schreiben von Tabellen und blockiert nur gleichzeitige Aktualisierungen derselben Zeile. Auf diese Weise werden Überschneidungen vermieden.
Skalierbarkeit
PostgreSQL unterstützt Unicode, internationale Zeichensätze, Multi-Byte-Zeichencodierungen und ist in Bezug auf Sortierung, Groß- und Kleinschreibung und Formatierung ortsabhängig. PostgreSQL ist hoch skalierbar – sowohl in Bezug auf die Anzahl der gleichzeitigen Benutzer als auch auf die Datenmenge, die es verwalten kann. Außerdem ist PostgreSQL plattformübergreifend und kann auf vielen Betriebssystemen laufen, darunter Linux, Microsoft Windows, OS X, FreeBSD und Solaris.
Dynamisches Laden
Der PostgreSQL-Server kann auch vom Benutzer geschriebenen Code über dynamisches Laden in sich aufnehmen. Der Benutzer kann eine Objektcodedatei angeben, z. B. eine Shared Library, die eine neue Funktion oder einen neuen Typ implementiert, und PostgreSQL lädt sie bei Bedarf. Durch die Möglichkeit, seine Arbeitsweise im laufenden Betrieb zu ändern, eignet sich PostgreSQL hervorragend für die schnelle Implementierung neuer Speicherstrukturen und Anwendungen.
Architektur von PostgreSQL
Der PostgreSQL-Server hat eine einfache Struktur, die aus einem gemeinsamen Speicher, Hintergrundprozessen und einer Datenverzeichnisstruktur besteht. In diesem Abschnitt gehen wir auf die einzelnen Komponenten ein und erläutern, wie sie miteinander interagieren. Nachfolgend siehst du eine Abbildung der PostgreSQL-Architektur. Zu Beginn wird eine Anfrage vom Client an den Server gesendet. Dann verarbeitet der PostgreSQL-Server die Daten mithilfe von gemeinsamen Puffern und Hintergrundprozessen. Die physische Datei des PostgreSQL-Datenbankservers wird im Datenverzeichnis gespeichert.
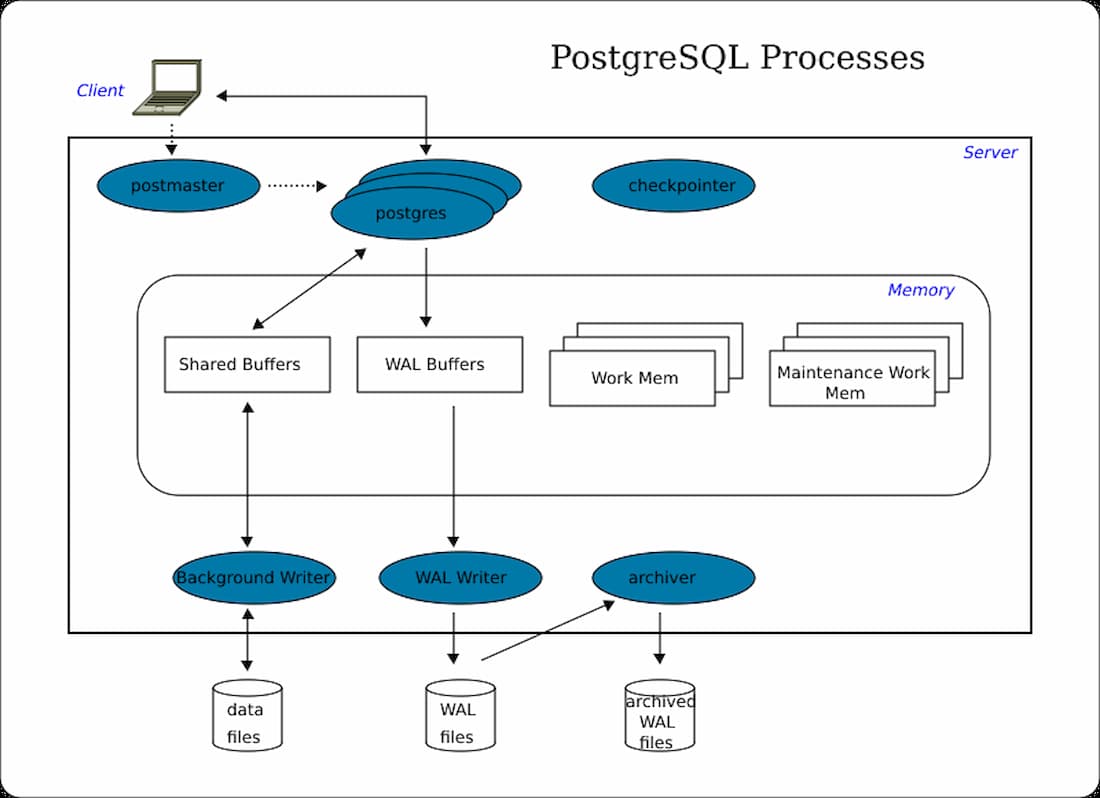
Shared Memory
Shared Memory ist für das Caching des Transaktionslogs und der Datenbank reserviert. Es umfasst außerdem Elemente wie Shared Buffers, WAL Buffers, Work Memory und Maintenance Work Memory. Im Folgenden gehen wir auf die einzelnen Elemente ein.
Shared Buffers
Diese Puffer dienen dazu, die DISK IO des Servers zu minimieren. Um dieses Ziel zu erreichen, ist es angemessen, den Wert des Shared Buffers auf 25% des Gesamtspeichers festzulegen, wenn wir einen dedizierten Server für PostgreSQL haben. Der Standardwert für den gemeinsamen Puffer ist ab Version 9.3 128 MB. Wenn mehrere Benutzer gleichzeitig darauf zugreifen, muss unbedingt versucht werden, die Konflikte zu minimieren. Häufig verwendete Blöcke sollten so lange wie möglich im Puffer verbleiben. So kann er so schnell wie möglich auf die Daten zugreifen.
WAL-Puffer
In WAL-Puffern werden Änderungen an der Datenbank vorübergehend gespeichert. Die WAL-Datei besteht aus Inhalten, die der WAL-Puffer zu einem bestimmten Zeitpunkt schreibt. WAL-Dateien und WAL-Puffer sind wichtig, um die Daten bei Baclup und Recovery wiederherzustellen.
Arbeitsspeicher
Dieser Speicherplatz wird für Bitmap-Operationen, Sortierung, Merging-Joins und Hash-Joins verwendet, um Daten in temporäre Plattendateien zu schreiben. Die Standardeinstellung ab Version 9.3 ist 4 MB.
Maintenance Work Memory
Dieser Speicherplatz wird für Datenbankoperationen wie ANALYZE, VACUUM, ALTER TABLE und CREATE INDEX verwendet. Die Standardeinstellung ab Version 9.4 ist 64 MB.
Hintergrundprozesse
Jeder Hintergrundprozess ist ein integraler Bestandteil des Servers und führt eine bestimmte Funktion aus, um den Server zu verwalten. Einige wichtige Hintergrundprozesse werden im Folgenden näher erläutert:
Checkpointer-Prozess
Wenn ein Checkpoint auftritt, wird der Dirty Buffer in die Datei geschrieben. Der Checkpointer schreibt im Wesentlichen alle schmutzigen Seiten aus dem Speicher auf die Festplatte und bereinigt den gemeinsamen Pufferbereich. Wenn die Datenbank abstürzt, kann der Datenverlust gemessen werden, indem die Differenz zwischen der letzten Checkpoint-Zeit und der Zeit, zu der PostgreSQL gestoppt wurde, ermittelt wird.
Background-Writer-Prozess
Er aktualisiert die Protokolle und Sicherungsinformationen. Bis zur Version 9.1 war dieser Prozess in den Checkpointer-Prozess integriert, der regelmäßig durchgeführt wurde. Ab Version 9.2 wurde der Checkpointer-Prozess jedoch vom Background Writer-Prozess getrennt.
WAL Writer
Dieser Prozess schreibt die WAL-Daten in den WAL-Puffer und überträgt sie regelmäßig in den persistenten Speicher.
Archiver
Falls aktiviert, ist dieser Prozess dafür verantwortlich, die WAL-Logdateien in ein bestimmtes Verzeichnis zu kopieren.
Logger/Protokollsammler
Dieser Prozess schreibt einen WAL-Puffer in die WAL-Datei.
Datendateien/Datenverzeichnisstruktur
PostgreSQL hat mehrere Datenbanken, die zusammen einen Datenbank-Cluster bilden. Bei der Initialisierung werden die Datenbanken template0, template1 und Postgres erstellt. Die neue Datenbankerstellung des Benutzers erfolgt über Template-Datenbanken, die aus den Systemkatalogtabellen bestehen. Obwohl die Liste der Tabellen in template0 und template1 nach der Initialisierung identisch ist, kann nur die template1-Datenbank die Objekte erstellen, die der Benutzer benötigt, daher wird die Benutzerdatenbank durch Klonen der template1-Datenbank erstellt.
Die für den Cluster benötigten Daten werden im Datenverzeichnis des Clusters gespeichert, das auch als „PGDATA“ bezeichnet wird. Es besteht aus mehreren Unterverzeichnissen. Ein paar wichtige sind im Folgenden aufgeführt:
- Global: Das globale Unterverzeichnis besteht aus clusterweisen Tabellen wie z.B. der Benutzerdatenbank.
- Base: Das Unterverzeichnis Base ist der physische Speicherort des Standard-Tablespaces. Es enthält mehrere datenbankbezogene Unterverzeichnisse, in denen die Systemkataloge gespeichert sind.
- PID: Die PID-Datei enthält die aktuelle Postmaster-Prozess-ID (PID).
- PG_VERSION: Dieses Unterverzeichnis enthält die Informationen zur Datenbankversion.
- PG_NOTIFY: Dieses Unterverzeichnis enthält die LISTEN/NOTIFY-Statusdaten. Diese Dateien können bei der Fehlersuche nützlich sein.
Warum PostgreSQL verwenden?
PostgreSQL bietet nicht nur eine Reihe von Funktionen wie Indizes, Views und Stored Procedures, sondern hat noch viel mehr zu bieten, nämlich
- Sprachunterstützung
- Open-Source
- Objekt-Relationale Datenbank
- Leistung
- Erweiterbarkeit
- Load Balancing-Fähigkeiten
- Verlässlichkeit
- Internationalisierung
Schauen wir uns diese im Detail an.
Sprachunterstützung
PL/PGSQL ist eine systemeigene prozedurale Sprache, die von PostgreSQL bereitgestellt wird und über verschiedene moderne Funktionen verfügt. Sie unterstützt den JSON-Datentyp, der leichtgewichtig ist und die Flexibilität in einem einzigen Paket gewährleistet. PostgreSQL unterstützt daher verschiedene Programmiersprachen und Protokolle wie Perl, Ruby, Python, .Net, C/C++, Java, ODBC und Go.
Open-Source
PostgreSQL ist kostenlos und quelloffen – das ist bei weitem der größte Vorteil von PostgreSQL. Die Software wird seit mehr als 20 Jahren von der Community entwickelt, was wiederum zu ihrer hohen Integrität beigetragen hat. Sein Quellcode ist unter einer Open-Source-Lizenz verfügbar, die es dir erlaubt, ihn nach Belieben zu nutzen, zu verändern und zu implementieren – ohne zusätzliche Kosten.
Objektrelationale Datenbank
Objekte, Klassen und Funktionsüberladungen werden in PostgreSQL direkt unterstützt. Aufgrund der objektorientierten Eigenschaften ist es möglich, Datentypen zu erweitern, um eigene Datentypen zu erstellen. Dies garantiert eine hohe Flexibilität für Entwickler, die mit komplexen Datenmodellen arbeiten, die eine Datenbankintegration erfordern.
Die Tabellenvererbung ist eine weitere Funktion, die PostgreSQL aufgrund seiner objektorientierten Eigenschaften unterstützt. Die untergeordnete Tabelle kann die Spalten ihrer übergeordneten Tabelle erben, zusätzlich zu den anderen Spalten, die die untergeordnete Tabelle besitzt und die sie von sich selbst unterscheidet.
Leistung
Schreibvorgänge in PostgreSQL können gleichzeitig ausgeführt werden, ohne dass Lese-/Schreibsperren erforderlich sind. Indizes werden verwendet, um Abfragen bei großen Datenmengen zu beschleunigen. So können Datenbanken eine bestimmte Zeile finden, ohne die gesamten Daten durchsuchen zu müssen.
Mit PostgreSQL kannst du sogar einen Ausdrucksindex erstellen, der sich auf das Ergebnis eines Ausdrucks oder einer Funktion bezieht und nicht nur auf den Wert einer Spalte. Es wird auch eine partielle Indexierung unterstützt, bei der nur ein Teil der Tabelle indexiert wird. Die Software unterstützt außerdem die Parallelisierung von Leseabfragen, die Just-in-Time-Kompilierung (JIT) von Ausdrücken und verschachtelte Transaktionen (über Savepoints), die eine hohe Leistung und Effizienz gewährleisten.
Erweiterbarkeit
PostgreSQL ist in hohem Maße erweiterbar, da es katalogbasiert arbeitet, d.h. Informationen werden in Datenbanken, Spalten, Tabellen usw. gespeichert. PostgreSQL speichert nicht nur eine große Menge an Informationen in seinen Katalogen, sondern auch Details zu den Datentypen, Zugriffsmethoden, Funktionen und so weiter. Du kannst sogar so weit gehen, dass du deinen Code in verschiedenen Programmiersprachen schreiben kannst, ohne deine Datenbank neu zu kompilieren, und deine Datentypen definieren.
Load Balancing-Fähigkeiten
PostgreSQL garantiert Hochverfügbarkeit und Load Balancing durch den Betrieb von Standby-Servern, kontinuierliche Planung, Vorbereitung des Primären für Standby-Server, Einrichtung eines Standby-Servers, Streaming-Replikation, Replikations-Slots, kaskadierende Replikation und kontinuierliche Archivierung im Standby. Darüber hinaus unterstützt PostgreSQL die synchrone Replikation, bei der zwei Datenbankinstanzen gleichzeitig laufen können und die Master-Datenbank gleichzeitig mit einer Slave-Datenbank synchronisiert wird, was die Hochverfügbarkeit weiter erhöht.
Verlässlichkeit
PostgreSQL speichert die Daten nicht nur sicher und ermöglicht es dem Benutzer, die Daten abzurufen, wenn die Anfrage bearbeitet wird, sondern wird auch von einer Gemeinschaft von Mitwirkenden unterstützt, die regelmäßig Fehler finden und versuchen, die Software zu verbessern, was PostgreSQL zuverlässig macht.
Internationalisierung
Der Prozess, Software so zu gestalten, dass sie in verschiedenen Regionen genutzt werden kann, wird als Internationalisierung bezeichnet. PostgreSQL unterstützt internationale Zeichensätze durch Multi-Byte-Zeichencodierungen, ICU-Kollationen und Unicode und ist in Bezug auf Sortierung, Formatierung und Groß- und Kleinschreibung ortsabhängig. Die Anzeige von PostgreSQL-generierten Nachrichten in der Sprache deiner Wahl ist ein Beispiel für Internationalisierung.
(cta)
Wann du PostgreSQL verwenden solltest
Musst du komplexe Abfragen und Beziehungen erstellen, die häufig aktualisiert und auf möglichst kostengünstige Weise gepflegt werden müssen? Dann könnte PostgreSQL eine geeignete Option sein. PostgreSQL ist nicht nur kostenlos, sondern auch plattformübergreifend und nicht nur auf das Windows-Betriebssystem beschränkt. Wenn du Daten analysieren willst, bietet PostgreSQL eine riesige Menge an regulären Ausdrücken als Grundlage für die analytische Arbeit.
Sie ist auch eine der besten Datenbanken, wenn es um CSV-Unterstützung geht. Einfache Befehle wie „copy from“ und „copy to“ helfen bei der schnellen Verarbeitung von Daten. Bei einem Importproblem wird eine Fehlermeldung ausgegeben und der Import sofort abgebrochen. In den folgenden Abschnitten werden einige der häufigsten Anwendungen von PostgreSQL in der modernen Welt behandelt. Fangen wir an.
Geodaten der Regierung
Die PostGIS Geospatial Datenbankerweiterung für PostgreSQL ist zweifelsohne nützlich. In Verbindung mit der PostGIS-Erweiterung unterstützt PostgreSQL geografische Objekte und kann als Geodatenspeicher für geografische Informationssysteme (GIS) und standortbezogene Dienste genutzt werden.
Finanzindustrie
PostgreSQL ist ein ideales DBMS-System für die Finanzindustrie. Da es vollständig ACID-konform ist, ist es die ideale Wahl für OLTP (Online Transaction Processing), da diese Datenbanken häufig geschrieben, gelesen und aktualisiert werden müssen, wobei der Schwerpunkt auf einer schnellen Verarbeitung liegt. Sie eignet sich auch für die Durchführung von Datenbank-Analysen. Sie kann mit jeder Software integriert werden, die mathematische Operationen ausführt, wie z. B. Matlab und R.
Wissenschaftliche Daten
Wissenschaftliche Daten erfordern Terabytes an Daten. Es ist unerlässlich, diese Daten so effizient wie möglich zu verarbeiten. PostgreSQL bietet wunderbare Analysemöglichkeiten und eine leistungsstarke SQL-Engine. Damit lassen sich große Datenmengen mühelos verwalten.
Web-Technologie
Webseiten haben oft mit Hunderten oder Tausenden von Anfragen pro Sekunde zu tun. Wenn der Entwickler nach einer kostengünstigen und skalierbaren Lösung sucht, ist PostgreSQL die beste Wahl. PostgreSQL kann dynamische Webseiten und Anwendungen als Teil einer robusten Alternative zum LAMP-Stack, dem LAPP-Stack, betreiben. (Linux, Apache, PostgreSQL, PHP, Python und Perl)
Herstellung
Viele Startups und große Unternehmen nutzen PostgreSQL als Hauptdatenspeicher für Produkte, Lösungen und Anwendungen im Internet. Die Leistung der Lieferkette kann durch den Einsatz dieses Open-Source-DBMS als Speicher-Backend optimiert werden. Dadurch können Unternehmen die Betriebskosten ihres Unternehmens senken.
Betriebliche Herausforderungen von PostgreSQL
Da wir in diesem Artikel bisher nur Lobeshymnen auf PostgreSQL gesungen haben, ist es nur fair, dass wir dir auch ein paar Schwachstellen aufzeigen, über die du stolpern könntest, wenn du dich mit PostgreSQL beschäftigst. Hier sind ein paar betriebliche Herausforderungen, auf die du bei der Einführung von PostgreSQL stoßen könntest.
- Mangel an einem ausgereiften Datenbank-Ökosystem: PostgreSQL verfügt über eine der am schnellsten wachsenden Communities, aber im Gegensatz zu traditionellen Datenbankanbietern hat die PostgreSQL-Community nicht den Komfort eines entwickelten Datenbank-Ökosystems.
- Der Mangel an Fachwissen: PostgreSQL wird oft mit verschiedenen Datenbanken gekoppelt, z. B. mit MongoDB. Jede Datenbank erfordert spezielle Kenntnisse, und es kann schwierig sein, technisches Personal mit den gewünschten PostgreSQL-Kenntnissen einzustellen. Neben den Verwaltungstools für PostgreSQL müssen sich Datenbankexperten und DevOps-Teams auch mit verschiedenen Datenbanken von unterschiedlichen Anbietern auseinandersetzen. Das kann schwierig zu handhaben sein, wenn man nicht zwischen bestehenden Prozessen wechseln kann.
- Inkonsistenz: Da PostgreSQL ein Open-Source-Tool ist, können verschiedene IT-Entwicklungsteams innerhalb einer Organisation es organisch nutzen. Dies kann zu einem weiteren Hindernis führen – dem Fehlen einer zentralen Anlaufstelle für alle PostgreSQL-Instanzen innerhalb der IT-Umgebung. Ein weiteres Problem, das dadurch entstehen kann, dass verschiedene Teams versuchen, dasselbe Problem zu lösen, ist Doppelarbeit und Redundanz.
Wichtige Alternativen zu PostgreSQL
Hier sind ein paar wichtige Alternativen zu PostgreSQL, die du für deine WordPress-Webseite nutzen kannst.
MySQL
Wenn du an Datenbanken denkst, kommt dir sofort MySQL in den Sinn. Es war lange Zeit eine allgegenwärtige Option für Entwickler/innen, bevor Alternativen auftauchten. Im Jahr 2019 wurde sie von mehr als 39 % der Entwickler/innen genutzt. Auch wenn sie nicht so vielseitig ist wie PostgreSQL, kann sie für verschiedene Anwendungsfälle wie skalierbare Webanwendungen sehr nützlich sein.
MySQL wird seit seiner Einführung im Jahr 1995 von Oracle betreut. Oracle bietet auch Elite-Versionen von MySQL mit proprietären Plugins, zusätzlichen Diensten, Erweiterungen und robuster Benutzerunterstützung an. Um MySQL besser verstehen zu können, musst du ein besseres Verständnis für Client-Server-Modelle und relationale Datenbanken haben. Einfach ausgedrückt, sind deine Daten in verschiedene separate Speicherbereiche aufgeteilt, die auch als Tabellen bezeichnet werden, anstatt alles in einer einzigen großen Speichereinheit zu speichern. Das ist das Wesentliche einer relationalen Datenbank.
Abgesehen davon, dass es sich um eine zuverlässige und solide Datenbankplattform handelt, ist sie recht einfach zu beherrschen. Die Lernkurve ist nicht so steil wie bei anderen Datenbanken, denn du musst keine umfassenden SQL-Kenntnisse haben, um mit MySQL zu arbeiten.
Wenn du WordPress für deine Webseite verwendest und wissen willst, wie du MySQL schneller zum Laufen bringst, solltest du deine Datenbank so anpassen, dass sie mit deiner WordPress-Nutzung übereinstimmt. In der Fachsprache nennt man das einen MySQL Performance Tune. Der offensichtliche Vorteil der MySQL-Optimierung sind kürzere Ladezeiten und eine insgesamt schnellere Webseite. Außerdem solltest du, wenn du deine Datenbank richtig pflegst, eine stetige Verbesserung deines Wachstums sehen, auch wenn sie wächst.
MariaDB
MariaDB ist ein kommerziell unterstützter Fork des relationalen Datenbankmanagementsystems MySQL, der sich durch einen grundlegend anderen Ansatz auszeichnet, um den Anforderungen der modernen Welt gerecht zu werden. MariaDBs zweckbestimmte und steckbare Speicher-Engine bietet Unterstützung für Workloads, für die früher eine Vielzahl von Spezialdatenbanken erforderlich war. So können Unternehmen alles aus einer Hand erhalten, egal ob in der Cloud oder auf Standard-Hardware, die sie mögen.
MariaDB kann innerhalb weniger Minuten für analytische, transaktionale oder hybride Anwendungsfälle eingesetzt werden und bietet unübertroffene betriebliche Flexibilität, ohne auf wichtige Unternehmensfunktionen verzichten zu müssen. Dazu gehören vollständige SQL- und echte ACID-Konformität.
MariaDB bietet seinen Nutzern die folgenden Produkte an:
- MariaDB Enterprise: MariaDB Enterprise ist eine absolute, produktionstaugliche Open-Source-Datenbanklösung, die analytische, transaktionale oder hybride analytische/transaktionale Arbeitslasten mit Eleganz bewältigen kann. MariaDB Enterprise besitzt außerdem die Fähigkeit, von spaltenbasierten und eigenständigen Datenbanken bis hin zu vollständig verteilten SQL-Datenbanken zu skalieren, die Millionen von Transaktionen pro Sekunde durchführen können. Außerdem kannst du mit ihr interaktive, behelfsmäßige Analysen für Milliarden von Zeilen durchführen.
- MariaDB Community Server: MariaDB Community Server ist die relationale Open-Source-Datenbank, die heute von den meisten Entwicklern genutzt wird. Der MariaDB Community Server ist nicht nur mit Oracle, MySQL und anderen Datenbanken kompatibel, sondern wird auch garantiert für immer Open Source bleiben. Zu den wichtigsten Merkmalen gehören die spaltenorientierte Speicherung für Analysen, modernes SQL, erweiterbare Speicher-Engines und hohe Verfügbarkeit.
- MariaDB SkySQL: SkySQL ist als Database-as-a-Service (DBaaS) Angebot bekannt, das die gesamte Leistungsfähigkeit von MariaDB Enterprise in die Cloud bringt und analytische, transaktionale und hybride Workloads unterstützt. SkySQL basiert auf Kubernetes und wurde für Cloud-Dienste und -Infrastrukturen überarbeitet. SkySQL hat sich in diesem Bereich einen Namen gemacht, indem es Self-Service und Benutzerfreundlichkeit mit erstklassigen Support-Funktionen und der Zuverlässigkeit von Unternehmen kombiniert. Wie aus der letzten Aussage ersichtlich, umfasst dies alles, was für den sicheren Betrieb von zentralen Datenbanken in der Cloud in Verbindung mit einer Unternehmens-Governance erforderlich ist.
Dank der Kompatibilität mit MySQL kannst du MariaDB praktisch ohne Nachteile als „Ersatz“ für MySQL einsetzen.
Best Practices für deine Datenbank
Wenn du an einsteigerfreundliche Plattformen für Webseiten-Neulinge denkst, denkst du wahrscheinlich an WordPress. Mit WordPress kannst du auch ohne Programmierkenntnisse eine Menge erreichen. Um den größtmöglichen Nutzen aus WordPress zu ziehen, musst du jedoch wissen, wie einige der grundlegenden Elemente des Systems funktionieren. Wenn du zum Beispiel schon seit einiger Zeit WordPress für deine Webseite verwendest, ist es wahrscheinlich an der Zeit zu verstehen, wie WordPress-Datenbanken funktionieren.
Das führt sofort zu einer häufigen Frage: Warum braucht WordPress überhaupt eine Datenbank? Es sieht vielleicht nicht so aus, aber hinter WordPress steckt mehr, als man auf den ersten Blick sieht. Hinter den Kulissen steckt eine Menge Arbeit, damit es effizient funktioniert, unabhängig von der Größe deiner Webseite.
Um tiefer einzusteigen, musst du wissen, dass eine WordPress-Webseite aus vielen verschiedenen Datentypen besteht. Es liegt auf der Hand, dass all diese Informationen in einer konsolidierten WordPress-Datenbank gespeichert werden. Diese Datenbank ist das Herzstück deiner WordPress-Webseite. Sie speichert alle Änderungen, die du oder deine Besucher/innen vornehmen, und sorgt dafür, dass deine Webseite reibungslos funktioniert. Hier sind einige Daten, die in deiner WordPress-Datenbank gesammelt werden:
- Organisatorische Informationen wie Tags und Kategorien.
- Standortweite Einstellungen.
- Seiten, Beiträge und verwandte Inhalte.
- Theme- und Plugin-bezogene Daten.
- Nutzerkommentare und -daten.
Wenn du eine WordPress-Webseite installierst, wird unter anderem eine Datenbank für sie angelegt. Normalerweise geschieht dies automatisch. Es gibt aber auch die Möglichkeit, eine Datenbank manuell zu erstellen oder eine bestehende Datenbank mit einer neuen Webseite zu nutzen.
Im folgenden Abschnitt geht es um die empfohlenen Vorgehensweisen für deine WordPress-Datenbank.
Verwendung eines Datenbank-Management-Tools
Die grundlegende Funktion von Datenbank-Verwaltungstools besteht darin, dass du den Inhalt deiner Datenbank einsehen kannst. Damit eine Datenbank reibungslos funktioniert, ist der Einsatz eines Datenbankverwaltungstools die beste Lösung. In der Regel vereinen Datenbankmanagement-Tools Funktionen, die die Bedürfnisse von drei verschiedenen Datenbankprofis erfüllen:
- Datenbankanalysten können die Daten aus verschiedenen Quellen extrahieren. Anschließend werden die Daten bereinigt, integriert und für die Analyse vorbereitet. Für Datenbankanalysten ist die Möglichkeit, gemeinsam an Datensätzen und Abfragen zu arbeiten, ohne auf die IT-Abteilung angewiesen zu sein, eine wichtige Voraussetzung.
- Datenbankentwickler/innen brauchen Werkzeuge, die es ihnen ermöglichen, gleich beim ersten Mal hochwertigen Code zu schreiben und ihn nahtlos zu pflegen. Datenbankentwickler/innen schätzen Kollaborations- und Automatisierungstools für die Programmierung. So können sie die Entwicklungszyklen verkürzen, ohne das Risiko zu erhöhen.
- Datenbankadministratoren nutzen Werkzeuge, mit denen sie die Leistung und den Zustand der Datenbank überwachen können. Ihre Aufgaben reichen vom Aufdecken und Diagnostizieren von Leistungshindernissen bis hin zum Ausführen von Änderungen im Datenbankschema.
Wenn du dich auf dem Markt nach einem Datenbankmanagement-Tool umsiehst, das deinen Anforderungen entspricht, solltest du nach Tools suchen, die Tests, Datenbankentwicklung und Deployment-Aufgaben in den kontinuierlichen Bereitstellungs- und Integrationsprozess einbinden und es so einfacher machen, mit der Anwendungsentwicklung Schritt zu halten.
Ein effektives Datenbankmanagement-Tool sollte auch die Visualisierung von Daten in Form von Tabellen, Histogrammen und Diagrammen ermöglichen, die leicht an Entscheidungsträger/innen weitergegeben werden können. Außerdem sollte es Admins dabei helfen, Probleme zu erkennen, bevor sie in der Produktion auftreten, indem es SQL-Anweisungen und Anwendungen ausfindig macht, die mit dem Anstieg des Transaktionsvolumens nicht gut skalieren.
Adminer (früher bekannt als phpMinAdmin) ist ein kostenloses Open-Source-Datenbankmanagement-Tool, das viele nützliche Funktionen und eine elegante Benutzeroberfläche (UI) bietet. Du kannst dieses praktische Datenbankverwaltungstool ganz einfach auf deinem Server installieren. Du musst nur eine einzige PHP-Datei hochladen, deinen Browser darauf richten und dich einloggen.
Ein Datenbank-Plugin verwenden
Wenn du die Qualität einer Webseite beurteilen willst, brauchst du nur in ihre Datenbank zu schauen. Jede Information, die mit deiner Webseite zu tun hat, findet ihren Weg in deine WordPress-Datenbank. Einige davon sind wichtig, während andere dich nur aufhalten. Dazu gehören fehlerhafte Tabellen, alte Entwürfe und Spam-Kommentare. Um zu verhindern, dass sie deine Webseite behindern, musst du WordPress-Datenbank-Plugins einführen.
Datenbank-Plugins gibt es in verschiedenen Formen. Einige Plugins können verwendet werden, um die Datenbank monatlich oder wöchentlich von überflüssigen Dateien zu befreien. Andere Plugins dienen dazu, deine Datenbank zu sichern, bevor du Änderungen vornimmst, z. B. bei einer Migration. Mit Datenbank-Plugins kannst du nicht nur die Geschwindigkeit deiner Webseite erhöhen, sondern auch die Benutzerfreundlichkeit verbessern und deine Chancen auf eine bessere Platzierung in den Suchmaschinen erhöhen.
Diagnostizieren und Reparieren deiner Datenbank
Als WordPress-Benutzer/in hast du wahrscheinlich schon mit einigen lästigen WordPress-Fehlern zu kämpfen gehabt. Hier ist eine der häufigsten Fehlermeldungen, die dir begegnet sein könnte:
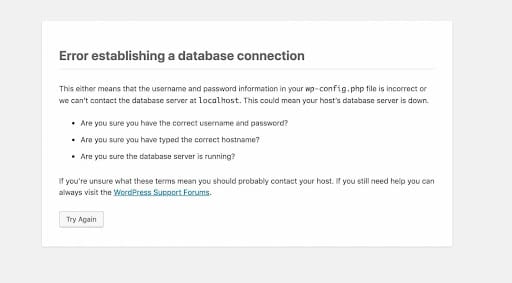
Wie wichtig es ist, deine Datenbank zu reparieren, sollte ziemlich offensichtlich sein. WordPress-Fehler behindern nicht nur das ordnungsgemäße Funktionieren deiner Webseite, sondern können sich auch nachteilig auf das Nutzererlebnis auswirken. Fehlgeschlagene Installationen und Updates, Ausfallzeiten und fehlende Ressourcen können eine Delle in deinem Verdienstpotenzial hinterlassen und deine Glaubwürdigkeit beeinträchtigen.
Zusammenfassung
PostgreSQL ist ein quelloffenes und kostenloses relationales Datenbankmanagementsystem, das sich auf SQL-Konformität und Erweiterbarkeit konzentriert. Nach über 30 Jahren aktiver Entwicklung ist PostgreSQL eines der weltweit am häufigsten verwendeten Open-Source-Datenbank-Tools.
In diesem Artikel haben wir uns mit den wichtigsten Merkmalen von PostgreSQL, der Architektur von PostgreSQL, den Anwendungsfällen, den Vorteilen, den betrieblichen Herausforderungen und den wichtigsten Alternativen beschäftigt. Zum Schluss haben wir noch ein paar Tipps gegeben, wie du deine WordPress-Datenbank in Topform halten kannst, während du sie weiter ausbaust.

Salman Ravoof ist ein autodidaktischer Webentwickler, Autor, Kreativer und ein großer Bewunderer von Free and Open Source Software (FOSS). Neben Technik begeistert er sich für Wissenschaft, Philosophie, Fotografie, Kunst, Katzen und Essen. Erfahre mehr über ihn auf seiner Website und trete mit Salman auf X in Kontakt.


{kind=link}