
In der heutigen datengesteuerten Welt, in der das Volumen und die Komplexität der Daten in einem noch nie dagewesenen Tempo wachsen, ist der Bedarf an robusten und skalierbaren Datenbanklösungen von größter Bedeutung. Schätzungen zufolge werden bis 2025 180 Zettabyte an Daten erzeugt. Das sind große Zahlen, die du dir vorstellen sollst.
Wenn die Datenmenge und die Nachfrage der Nutzer/innen in die Höhe schießen, ist es unpraktisch, sich auf eine einzige Datenbank zu verlassen. Es verlangsamt dein System und überfordert die Entwickler. Es gibt verschiedene Lösungen, um deine Datenbank zu optimieren, wie z.B. das Sharding von Datenbanken.
In diesem umfassenden Leitfaden tauchen wir in die Tiefen des MongoDB-Shardings ein und erläutern seine Vorteile, Komponenten, Best Practices, häufige Fehler und wie du loslegen kannst.
Was ist Datenbank-Sharding?
Datenbank-Sharding ist eine Datenbankverwaltungstechnik, bei der eine wachsende Datenbank horizontal in kleinere, besser zu verwaltende Einheiten, sogenannte Shards, aufgeteilt wird.
Wenn deine Datenbank größer wird, ist es sinnvoll, sie in mehrere kleinere Teile aufzuteilen und jeden Teil separat auf verschiedenen Rechnern zu speichern. Diese kleineren Teile, auch Shards genannt, sind unabhängige Teilmengen der Gesamtdatenbank. Dieser Prozess des Aufteilens und Verteilens von Daten ist das Sharding der Datenbank.
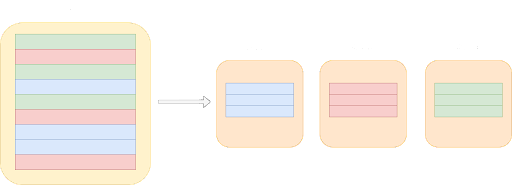
Bei der Implementierung einer Sharded-Datenbank gibt es zwei Hauptansätze: die Entwicklung einer eigenen Sharding-Lösung oder die Bezahlung für eine bestehende Lösung. Dabei stellt sich die Frage, ob es sinnvoller ist, eine Sharding-Lösung zu entwickeln oder zu bezahlen.

Um diese Entscheidung zu treffen, musst du die Kosten für die Integration von Drittanbietern abwägen und dabei die folgenden Faktoren berücksichtigen:
- Entwicklerfähigkeiten und Lernfähigkeit: Die Lernkurve, die mit dem Produkt verbunden ist, und wie gut es mit den Fähigkeiten deiner Entwickler übereinstimmt.
- Das Datenmodell und die API, die das System anbietet: Jedes Datensystem hat seine eigene Art, seine Daten darzustellen. Die Bequemlichkeit und Leichtigkeit, mit der du deine Anwendungen in das Produkt integrieren kannst, ist ein wichtiger Faktor, den du berücksichtigen solltest.
- Kundensupport und Online-Dokumentation: Wenn du bei der Integration auf Herausforderungen stößt oder Hilfe benötigst, sind die Qualität und Verfügbarkeit des Kundensupports und der umfassenden Online-Dokumentation entscheidend.
- Verfügbarkeit der Cloud-Bereitstellung: Da immer mehr Unternehmen auf die Cloud umsteigen, ist es wichtig festzustellen, ob das Drittanbieterprodukt in einer Cloud-Umgebung eingesetzt werden kann.
Auf der Grundlage dieser Faktoren kannst du nun entscheiden, ob du eine Sharding-Lösung bauen oder für eine Lösung bezahlen willst, die dir die Arbeit abnimmt.
Heute unterstützen die meisten Datenbanken auf dem Markt Datenbank-Sharding. Zum Beispiel relationale Datenbanken wie MariaDB (ein Teil des High-Performance Server Stacks bei Kinsta) und NoSQL-Datenbanken wie MongoDB.
Was ist Sharding in MongoDB?
Der Hauptzweck des Einsatzes einer NoSQL-Datenbank ist ihre Fähigkeit, die Rechen- und Speicheranforderungen bei der Abfrage und Speicherung riesiger Datenmengen zu bewältigen.
In der Regel enthält eine MongoDB-Datenbank eine große Anzahl von Sammlungen. Jede Sammlung besteht aus verschiedenen Dokumenten, die Daten in Form von Schlüssel-Werte-Paaren enthalten. Mit MongoDB Sharding kannst du diese große Sammlung in mehrere kleinere Sammlungen aufteilen. Dadurch kann MongoDB Abfragen durchführen, ohne den Server stark zu belasten.
Telefónica Tech zum Beispiel verwaltet weltweit über 30 Millionen IoT-Geräte. Um mit der ständig steigenden Gerätenutzung Schritt zu halten, brauchte das Unternehmen eine Plattform, die elastisch skaliert und eine schnell wachsende Datenumgebung verwalten kann. Die Sharding-Technologie von MongoDB war für sie die richtige Wahl, da sie am besten zu ihren Kosten- und Kapazitätsanforderungen passte.
Mit MongoDB-Sharding führt Telefónica Tech weit über 115.000 Abfragen pro Sekunde durch. Das sind 30.000 Datenbankeinfügungen pro Sekunde bei einer Latenz von weniger als einer Millisekunde!
Vorteile von MongoDB Sharding
Hier sind einige Vorteile von MongoDB Sharding für große Datenmengen, die du nutzen kannst:
Speicherkapazität
Wir haben bereits gesehen, dass beim Sharding die Daten auf die Shards des Clusters verteilt werden. Durch diese Verteilung enthält jeder Shard ein Fragment der gesamten Clusterdaten. Zusätzliche Shards erhöhen die Speicherkapazität des Clusters, wenn dein Datensatz größer wird.
Lesen/Schreiben
MongoDB verteilt die Lese- und Schreiblast auf die Shards in einem Sharded-Cluster, so dass jeder Shard eine Teilmenge der Clusteroperationen verarbeiten kann. Beide Arbeitslasten können horizontal über den Cluster skaliert werden, indem weitere Shards hinzugefügt werden.
Hohe Verfügbarkeit
Der Einsatz von Shards und Config-Servern als Replika-Sets bietet eine höhere Verfügbarkeit. Selbst wenn ein oder mehrere Shard-Replikat-Sets komplett ausfallen, kann der Sharded-Cluster teilweise Lese- und Schreibvorgänge durchführen.
Schutz vor einem Ausfall
Viele Nutzer/innen sind betroffen, wenn ein Rechner aufgrund eines ungeplanten Ausfalls ins Gras beißt. Da in einem nicht gesharten System die gesamte Datenbank ausgefallen wäre, sind die Auswirkungen massiv. Mit MongoDB Sharding kann der Radius der Auswirkungen auf die Nutzer/innen eingedämmt werden.
Geo-Verteilung und Leistung
Replizierte Shards können in verschiedenen Regionen platziert werden. Das bedeutet, dass Kunden mit geringer Latenz auf ihre Daten zugreifen können, d.h. sie können ihre Anfragen an den Shard weiterleiten, der ihnen am nächsten ist. Auf der Grundlage der Data Governance Policy einer Region können bestimmte Shards so konfiguriert werden, dass sie in einer bestimmten Region platziert werden.
Komponenten von MongoDB Sharded Clustern
Nachdem wir das Konzept eines MongoDB Sharded Clusters erklärt haben, wollen wir uns nun mit den Komponenten beschäftigen, aus denen solche Cluster bestehen.
1. Shard
Jeder Shard enthält eine Teilmenge der geshardeten Daten. Ab MongoDB 3.6 müssen Shards als Replikatset bereitgestellt werden, um Hochverfügbarkeit und Redundanz zu gewährleisten.
Jede Datenbank im Sharded-Cluster hat einen primären Shard, der alle nicht geshardeten Sammlungen für diese Datenbank enthält. Der primäre Shard ist nicht mit dem primären Shard in einem Replikatset verbunden.
Um den primären Shard für eine Datenbank zu ändern, kannst du den Befehl movePrimary verwenden. Der Prozess der Migration des Primary Shards kann einige Zeit in Anspruch nehmen.
Während dieser Zeit solltest du nicht versuchen, auf die mit der Datenbank verbundenen Collections zuzugreifen, bis der Migrationsprozess abgeschlossen ist. Je nach der Menge der zu migrierenden Daten kann dieser Prozess den gesamten Clusterbetrieb beeinträchtigen.
Du kannst die Methode sh.status() in mongosh verwenden, um dir einen Überblick über den Cluster zu verschaffen. Diese Methode gibt den primären Shard für die Datenbank sowie die Verteilung der Chunks auf die Shards zurück.
2. Config-Server
Die Bereitstellung von Config-Servern für Sharded-Cluster als Replika-Sets würde die Konsistenz der Config-Server verbessern. Das liegt daran, dass MongoDB die standardmäßigen Lese- und Schreibprotokolle für Replikatsätze für die Konfigurationsdaten nutzen kann. Um Konfigurationsserver als Replikat-Sets einzusetzen, musst du die WiredTiger Storage Engine verwenden.
WiredTiger verwendet die Gleichzeitigkeitskontrolle auf Dokumentenebene für seine Schreiboperationen. Daher können mehrere Clients verschiedene Dokumente einer Sammlung gleichzeitig ändern. Config-Server speichern die Metadaten für einen Sharded Cluster in der Config-Datenbank.
Um auf die Konfigurationsdatenbank zuzugreifen, kannst du den folgenden Befehl in der Mongo-Shell verwenden:
use configHier gibt es einige Einschränkungen, die du beachten musst:
- Eine Replikatset-Konfiguration, die für Config-Server verwendet wird, sollte keine Arbiter haben. Ein Arbiter nimmt zwar an der Wahl zum Primary teil, hat aber keine Kopie des Datensatzes und kann nicht zum Primary werden.
- Dieses Replikatset darf keine verzögerten Mitglieder haben. Verspätete Mitglieder haben Kopien des Datensatzes des Replikatsets. Aber der Datensatz eines verzögerten Mitglieds enthält einen früheren oder verzögerten Zustand des Datensatzes.
- Du musst Indizes für die Config-Server erstellen. Einfach ausgedrückt: Kein Mitglied sollte die Einstellung
members[n].buildIndexesauffalsehaben.
Wenn die Konfigurations-Server-Replikatgruppe ihr primäres Mitglied verliert und kein neues wählen kann, werden die Metadaten des Clusters schreibgeschützt. Du kannst zwar immer noch von den Shards lesen und schreiben, aber es werden keine Chunk-Splits oder Migrationen durchgeführt, bis das Replikat-Set ein primäres Mitglied wählen kann.
3. Abfrage-Router
MongoDB Mongos-Instanzen können als Query Router dienen, damit Client-Anwendungen und die Sharded-Cluster problemlos miteinander verbunden werden können.
Ab MongoDB 4.4 kann mongos hedged reads unterstützen, um die Latenzzeiten zu verringern. Bei Hedged Reads senden die Mongos-Instanzen Lesevorgänge an zwei Replikatgruppenmitglieder für jeden abgefragten Shard. Die Ergebnisse werden dann von dem ersten Befragten pro Shard zurückgegeben.
Hier siehst du, wie die drei Komponenten in einem Sharded-Cluster zusammenspielen:
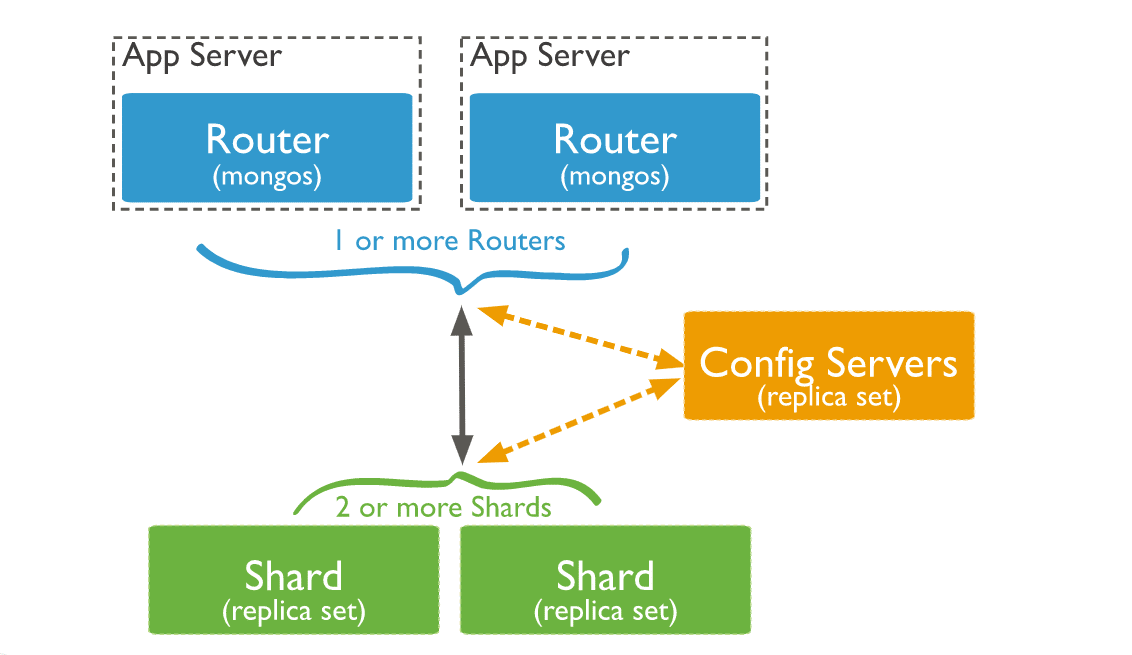
Eine MongoDB-Instanz richtet eine Anfrage an einen Cluster, indem:
- Die Liste der Shards, die die Abfrage erhalten sollen, überprüft wird.
- Ein Cursor auf allen Ziel-Shards eingerichtet wird.
Mongos führt dann die Daten der einzelnen Shards zusammen und gibt das Ergebnisdokument zurück. Einige Abfragemodifikatoren, wie z.B. das Sortieren, werden auf jedem Shard ausgeführt, bevor die Mongos die Ergebnisse abrufen.
In einigen Fällen, in denen der Shard-Schlüssel oder ein Shard-Schlüssel-Präfix Teil der Abfrage ist, führt mongos eine vorgeplante Operation aus, die Abfragen auf eine Unterklasse von Shards im Cluster verweist.
Für einen Produktionscluster musst du sicherstellen, dass die Daten redundant sind und deine Systeme hochverfügbar sind. Du kannst die folgende Konfiguration für einen produktiven Sharded-Cluster-Einsatz wählen:
- Einsatz jedes Shards als 3er-Replikat-Set
- Einsatz der Konfigurationsserver als 3er-Replikatset
- Einsatz von einem oder mehreren Mongos-Routern
Für einen nicht-produktiven Cluster kannst du einen Sharded Cluster mit den folgenden Komponenten einrichten:
- Einem einzelnen Shard-Replikatsatz
- Einem Replikatsatz-Konfigurations-Server
- Eine Mongos-Instanz
Wie funktioniert MongoDB Sharding?
Nachdem wir nun die verschiedenen Komponenten eines Sharding-Clusters besprochen haben, ist es an der Zeit, dass wir uns mit dem Prozess beschäftigen.
Um die Daten auf mehrere Server zu verteilen, verwendest du Mongos. Wenn du eine Verbindung herstellst, um die Abfragen an MongoDB zu senden, sucht mongos nach, wo sich die Daten befinden. Er holt sie dann vom richtigen Server und führt alles zusammen, wenn es auf mehrere Server aufgeteilt wurde.
Da das im Backend erledigt wird, musst du auf der Anwendungsseite nichts mehr tun. MongoDB wird sich wie eine normale Abfrageverbindung verhalten. Dein Client stellt eine Verbindung zu MongoDB her, und der Config-Server kümmert sich um den Rest.
Wie richte ich MongoDB Sharding Schritt für Schritt ein?
Die Einrichtung von MongoDB Sharding ist ein Prozess, der mehrere Schritte umfasst, um einen stabilen und effizienten Datenbank-Cluster zu gewährleisten. Hier findest du eine detaillierte Schritt-für-Schritt-Anleitung, wie du MongoDB-Sharding einrichtest.
Bevor wir beginnen, ist es wichtig zu wissen, dass du mindestens drei Server brauchst, um Sharding in MongoDB einzurichten: einen für den Konfigurationsserver, einen für die Mongos-Instanz und einen oder mehrere für die Shards.
1. Ein Verzeichnis vom Config Server erstellen
Zu Beginn erstellen wir ein Verzeichnis für die Daten des Config-Servers. Dazu führen wir auf dem ersten Server den folgenden Befehl aus:
mkdir /data/configdb2. MongoDB im Konfig-Modus starten
Als Nächstes starten wir MongoDB im Konfigurationsmodus auf dem ersten Server mit folgendem Befehl:
mongod --configsvr --dbpath /data/configdb --port 27019Damit wird der Config-Server auf port 27019 gestartet und seine Daten werden im Verzeichnis /data/configdb gespeichert. Beachte, dass wir das Flag --configsvr verwenden, um anzugeben, dass dieser Server als Konfigurationsserver verwendet wird.
3. Mongos-Instanz starten
Der nächste Schritt besteht darin, die Mongos-Instanz zu starten. Bei diesem Vorgang werden die Abfragen anhand des Sharding-Schlüssels an die richtigen Shards weitergeleitet. Um die Mongos-Instanz zu starten, verwendest du den folgenden Befehl:
mongos --configdb <config server>:27019Ersetze <config server> durch die IP-Adresse oder den Hostnamen des Rechners, auf dem der Config-Server läuft.
4. Mit der Mongos-Instanz verbinden
Sobald die Mongos-Instanz läuft, können wir uns über die MongoDB-Shell mit ihr verbinden. Dazu führst du den folgenden Befehl aus:
mongo --host <mongos-server> --port 27017In diesem Befehl sollte <mongos-server> durch den Hostnamen oder die IP-Adresse des Servers ersetzt werden, auf dem die Mongos-Instanz läuft. Dadurch wird die MongoDB-Shell geöffnet, so dass wir mit der Mongos-Instanz interagieren und dem Cluster Server hinzufügen können.
Ersetze <mongos-server> durch die IP-Adresse oder den Hostnamen des Rechners, auf dem die Mongos-Instanz läuft.
5. Server zu Clustern hinzufügen
Jetzt, da wir mit der Mongos-Instanz verbunden sind, können wir mit folgendem Befehl Server zum Cluster hinzufügen:
sh.addShard("<shard-server>:27017")In diesem Befehl sollte <shard-server> durch den Hostnamen oder die IP-Adresse des Servers ersetzt werden, auf dem der Shard läuft. Dieser Befehl fügt den Shard dem Cluster hinzu und macht ihn für die Nutzung verfügbar.
Wiederhole diesen Schritt für jeden Shard, den du dem Cluster hinzufügen möchtest.
6. Sharding für die Datenbank aktivieren
Schließlich aktivieren wir das Sharding für eine Datenbank, indem wir den folgenden Befehl ausführen:
sh.enableSharding("<database>")In diesem Befehl sollte <database> durch den Namen der Datenbank ersetzt werden, die du sharden möchtest. Dadurch wird das Sharding für die angegebene Datenbank aktiviert, so dass du ihre Daten auf mehrere Shards verteilen kannst.
Und das war’s! Wenn du diese Schritte befolgst, solltest du jetzt einen voll funktionsfähigen MongoDB-Sharding-Cluster haben, der horizontal skaliert und mit hohem Datenverkehr umgehen kann.
Best Practices für MongoDB Sharding
Nachdem wir unseren Sharded-Cluster eingerichtet haben, ist eine regelmäßige Überwachung und Wartung des Clusters unerlässlich, um eine optimale Leistung zu gewährleisten. Einige Best Practices für MongoDB Sharding sind:
1. Bestimme den richtigen Shard-Schlüssel
Der Shard-Schlüssel ist ein wichtiger Faktor beim MongoDB-Sharding, der bestimmt, wie die Daten auf die Shards verteilt werden. Es ist wichtig, einen Shard-Schlüssel zu wählen, der die Daten gleichmäßig über die Shards verteilt und die gängigsten Abfragen unterstützt. Du solltest vermeiden, einen Shard-Schlüssel zu wählen, der Hotspots oder eine ungleichmäßige Datenverteilung verursacht, da dies zu Leistungsproblemen führen kann.
Um den richtigen Shard-Schlüssel zu wählen, solltest du deine Daten und die Arten von Abfragen, die du durchführen wirst, analysieren und einen Schlüssel wählen, der diese Anforderungen erfüllt.
2. Plane für das Datenwachstum
Wenn du deinen Sharded-Cluster einrichtest, solltest du für zukünftiges Wachstum planen, indem du mit genügend Shards beginnst, um deine aktuelle Arbeitslast zu bewältigen, und bei Bedarf weitere hinzufügst. Vergewissere dich, dass deine Hardware- und Netzwerkinfrastruktur die Anzahl der Shards und die Datenmenge, die du in Zukunft erwartest, unterstützen kann.
3. Dedizierte Hardware für Shards verwenden
Verwende für jeden Shard eine eigene Hardware, um optimale Leistung und Zuverlässigkeit zu gewährleisten. Jeder Shard sollte über einen eigenen Server oder eine eigene virtuelle Maschine verfügen, damit er alle Ressourcen ohne Störungen nutzen kann.
Die Verwendung gemeinsamer Hardware kann zu Ressourcenkonflikten und Leistungseinbußen führen, was die Zuverlässigkeit des gesamten Systems beeinträchtigt.
4. Replikatsätze für Shard-Server verwenden
Die Verwendung von Replikatsätzen für Shard-Server bietet hohe Verfügbarkeit und Fehlertoleranz für deinen MongoDB-Sharded-Cluster. Jedes Replikatset sollte aus mindestens drei Mitgliedern bestehen, und jedes Mitglied sollte sich auf einem separaten physischen Rechner befinden. Auf diese Weise wird sichergestellt, dass dein Sharded-Cluster den Ausfall eines einzelnen Servers oder Replikats überstehen kann.
5. Shard-Leistung überwachen
Die Überwachung der Leistung deiner Shards ist wichtig, um Probleme zu erkennen, bevor sie zu großen Problemen werden. Du solltest die CPU, den Arbeitsspeicher, die Festplatten-E/A und die Netzwerk-E/A für jeden Shard-Server überwachen, um sicherzustellen, dass der Shard die Arbeitslast bewältigen kann.
Du kannst die in MongoDB integrierten Überwachungstools wie mongostat und mongotop oder Überwachungstools von Drittanbietern wie Datadog, Dynatrace und Zabbix verwenden, um die Leistung der Shards zu überwachen.
6. Plan für Disaster Recovery
Um die Zuverlässigkeit deines MongoDB-Sharded-Clusters aufrechtzuerhalten, ist es wichtig, die Disaster Recovery zu planen. Du solltest einen Disaster-Recovery-Plan haben, der regelmäßige Backups, das Testen von Backups, um sicherzustellen, dass sie gültig sind, und einen Plan für die Wiederherstellung von Backups im Falle eines Ausfalls umfasst.
7. Verwende Hashed-basiertes Sharding, wenn es angebracht ist
Bei Anwendungen, die bereichsbasierte Abfragen durchführen, ist das Hashed-Sharding von Vorteil, da die Operationen auf weniger Shards, meist auf einen einzigen Shard, beschränkt werden können. Um dies zu implementieren, musst du deine Daten und die Abfragemuster verstehen.
Hashed Sharding sorgt für eine gleichmäßige Verteilung von Lese- und Schreibvorgängen. Allerdings bietet es keine effizienten bereichsbasierten Operationen.
Was sind die häufigsten Fehler, die du beim Sharding deiner MongoDB-Datenbank vermeiden solltest?
MongoDB-Sharding ist eine leistungsstarke Technik, mit der du deine Datenbank horizontal skalieren und die Daten auf mehrere Server verteilen kannst. Es gibt jedoch einige häufige Fehler, die du beim Sharding deiner MongoDB-Datenbank vermeiden solltest. Nachfolgend findest du einige der häufigsten Fehler und wie du sie vermeiden kannst.
1. Den falschen Sharding-Schlüssel wählen
Eine der wichtigsten Entscheidungen, die du beim Sharding deiner MongoDB-Datenbank treffen wirst, ist die Wahl des Sharding-Schlüssels. Der Sharding-Schlüssel bestimmt, wie die Daten auf die Shards verteilt werden, und die Wahl des falschen Schlüssels kann zu einer ungleichmäßigen Datenverteilung, Hotspots und schlechter Leistung führen.
Ein häufiger Fehler ist es, einen Shard-Schlüsselwert zu wählen, der sich nur für neue Dokumente erhöht, wenn ein bereichsbasiertes Sharding im Gegensatz zum Hash-Sharding verwendet wird. Zum Beispiel ein Zeitstempel (natürlich) oder irgendetwas mit einer Zeitkomponente als wichtigstem Bestandteil, wie ObjectID (die ersten vier Bytes sind ein Zeitstempel).
Wenn du einen Shard-Schlüssel auswählst, gehen alle Einfügungen in den Chunk mit dem größten Bereich. Auch wenn du immer wieder neue Shards hinzufügst, wird sich deine maximale Schreibkapazität nicht erhöhen.
Wenn du vorhast, die Schreibkapazität zu skalieren, solltest du einen Hash-basierten Shard-Schlüssel verwenden, der die Verwendung desselben Feldes ermöglicht und gleichzeitig eine gute Skalierbarkeit beim Schreiben bietet.
2. Der Versuch, den Wert des Shard-Schlüssels zu ändern
Shard-Schlüssel sind für ein bestehendes Dokument unveränderlich, das heißt, du kannst den Schlüssel nicht ändern. Du kannst bestimmte Aktualisierungen vor dem Sharding vornehmen, aber nicht danach. Der Versuch, den Shard-Schlüssel für ein bestehendes Dokument zu ändern, schlägt mit der folgenden Fehlermeldung fehl:
cannot modify shard key's value fieldid for collection: collectionnameDu kannst das Dokument entfernen und wieder einfügen, um den Shard-Schlüssel neu zu gestalten, anstatt zu versuchen, ihn zu ändern.
3. Fehler bei der Überwachung des Clusters
Sharding führt zu einer zusätzlichen Komplexität in der Datenbankumgebung, so dass es wichtig ist, den Cluster genau zu überwachen. Wird der Cluster nicht überwacht, kann dies zu Leistungsproblemen, Datenverlusten und anderen Problemen führen.
Um diesen Fehler zu vermeiden, solltest du Überwachungstools einrichten, die wichtige Kennzahlen wie CPU-Auslastung, Speicherplatz, Festplattenplatz und Netzwerkverkehr überwachen. Außerdem solltest du Warnmeldungen einrichten, wenn bestimmte Schwellenwerte überschritten werden.
4. Zu lange mit dem Hinzufügen eines neuen Shards warten (überlastet)
Ein häufiger Fehler, den du beim Sharding deiner MongoDB-Datenbank vermeiden solltest, ist, zu lange mit dem Hinzufügen eines neuen Shards zu warten. Wenn ein Shard mit Daten oder Abfragen überlastet wird, kann dies zu Leistungsproblemen führen und den gesamten Cluster verlangsamen.
Angenommen, du hast einen imaginären Cluster, der aus 2 Shards mit 20000 Chunks (5000 gelten als „aktiv“) besteht, und wir müssen einen dritten Shard hinzufügen. Dieser 3. Shard wird schließlich ein Drittel der aktiven Chunks (und der gesamten Chunks) speichern.
Die Herausforderung besteht darin, herauszufinden, ab wann der Shard keinen zusätzlichen Aufwand mehr verursacht und ein Gewinn ist. Wir müssen die Last berechnen, die das System bei der Migration der aktiven Chunks auf den neuen Shard erzeugen würde, und wann sie im Vergleich zum Gesamtsystemgewinn vernachlässigbar wäre.
In den meisten Szenarien ist es relativ leicht vorstellbar, dass diese Migrationen bei einer überlasteten Gruppe von Shards noch länger dauern und dass es viel länger dauert, bis unser neu hinzugefügter Shard die Schwelle überschreitet und ein Nettogewinn wird. Daher ist es am besten, proaktiv zu handeln und die Kapazität zu erhöhen, bevor es notwendig wird.
Zu den möglichen Abhilfestrategien gehören die regelmäßige Überwachung des Clusters und das proaktive Hinzufügen neuer Shards zu Zeiten mit geringem Datenverkehr, damit es weniger Konkurrenz um die Ressourcen gibt. Es wird empfohlen, gezielte „heiße“ Chunks (auf die mehr zugegriffen wird als auf andere) manuell auszugleichen, um die Aktivität schneller auf den neuen Shard zu verlagern.
5. Unterversorgung von Config-Servern
Wenn die Konfigurationsserver zu wenig Ressourcen zur Verfügung stellen, kann dies zu Leistungsproblemen und Instabilität führen. Eine Unterversorgung kann durch eine unzureichende Zuweisung von Ressourcen wie CPU, Arbeitsspeicher oder Speicherplatz entstehen.
Dies kann zu langsamen Abfragen, Timeouts und sogar zu Abstürzen führen. Um dies zu vermeiden, ist es wichtig, den Config-Servern genügend Ressourcen zuzuweisen, vor allem in größeren Clustern. Die regelmäßige Überwachung der Ressourcennutzung der Config Server kann dabei helfen, Probleme mit einer unzureichenden Ressourcenzuweisung zu erkennen.
Eine weitere Möglichkeit, dies zu verhindern, ist die Verwendung von dedizierter Hardware für die Konfigurationsserver, anstatt die Ressourcen mit anderen Clusterkomponenten zu teilen. So kann sichergestellt werden, dass die Konfigurationsserver genügend Ressourcen haben, um ihre Arbeitslast zu bewältigen.
6. Versäumnisse bei der Datensicherung und -wiederherstellung
Backups sind wichtig, um sicherzustellen, dass die Daten bei einem Ausfall nicht verloren gehen. Datenverluste können aus verschiedenen Gründen auftreten, z. B. durch Hardwareausfälle, menschliches Versagen oder böswillige Angriffe.
Wenn du es versäumst, Daten zu sichern und wiederherzustellen, kann das zu Datenverlusten und Ausfallzeiten führen. Um diesen Fehler zu vermeiden, solltest du eine Sicherungs– und Wiederherstellungsstrategie einrichten, die regelmäßige Sicherungen, Testsicherungen und die Wiederherstellung von Daten in einer Testumgebung umfasst.
7. Versäumnis, den Sharded Cluster zu testen
Bevor du deinen Sharded-Cluster in die Produktion überführst, musst du ihn gründlich testen, um sicherzustellen, dass er die erwartete Last und die Abfragen bewältigen kann. Wenn du den Sharded-Cluster nicht testest, kann das zu schlechter Leistung und Abstürzen führen.
MongoDB Sharding vs. Clustered Indexes: Was ist effektiver für große Datenmengen?
Sowohl MongoDB Sharding als auch geclusterte Indizes sind effektive Strategien für den Umgang mit großen Datenmengen. Aber sie dienen unterschiedlichen Zwecken. Die Wahl des richtigen Ansatzes hängt von den spezifischen Anforderungen deiner Anwendung ab.
Sharding ist eine horizontale Skalierungstechnik, bei der die Daten auf viele Knoten verteilt werden, was sie zu einer effektiven Lösung für den Umgang mit großen Datenmengen mit hohen Schreibraten macht. Es ist für Anwendungen transparent und ermöglicht es ihnen, mit MongoDB zu interagieren, als wäre es ein einziger Server.
Andererseits verbessern geclusterte Indizes die Leistung von Abfragen, die Daten aus großen Datensätzen abrufen, da MongoDB die Daten effizienter finden kann, wenn eine Abfrage auf das indizierte Feld passt.
Was ist also effektiver für größere Datenmengen? Die Antwort hängt vom jeweiligen Anwendungsfall und den Anforderungen an die Arbeitslast ab.
Wenn die Anwendung einen hohen Schreib- und Abfragedurchsatz erfordert und horizontal skaliert werden muss, ist MongoDB Sharding wahrscheinlich die bessere Option. Clustering-Indizes können jedoch effektiver sein, wenn die Anwendung einen hohen Leseaufwand hat und häufig abgefragte Daten in einer bestimmten Reihenfolge organisiert werden müssen.
Sowohl Sharding als auch geclusterte Indizes sind leistungsstarke Werkzeuge für die Verwaltung großer Datenmengen in MongoDB. Entscheidend ist, dass du die Anforderungen deiner Anwendung und die Merkmale der Arbeitslast sorgfältig analysierst, um den besten Ansatz für deinen speziellen Anwendungsfall zu finden.
Zusammenfassung
Ein Sharded-Cluster ist eine leistungsstarke Architektur, die große Datenmengen verarbeiten und horizontal skalieren kann, um den Anforderungen wachsender Anwendungen gerecht zu werden. Der Cluster besteht aus Shards, Konfigurationsservern, Mongos-Prozessen und Client-Anwendungen.
Die Daten werden anhand eines sorgfältig ausgewählten Shard-Schlüssels partitioniert, um eine effiziente Verteilung und Abfrage zu gewährleisten. Durch die Nutzung von Sharding können Anwendungen eine hohe Verfügbarkeit, eine verbesserte Leistung und eine effiziente Nutzung von Hardwareressourcen erreichen. Die Wahl des richtigen Sharding-Schlüssels ist entscheidend für die gleichmäßige Verteilung der Daten.
Was denkst du über MongoDB und die Praxis des Shardings von Datenbanken? Gibt es einen Aspekt des Shardings, den wir deiner Meinung nach hätten behandeln sollen? Lass es uns in den Kommentaren wissen!


