
Los problemas de escalabilidad casi nunca surgen de la nada. Normalmente se van acumulando poco a poco hasta que el lanzamiento de una campaña, un pico de tráfico, un aumento de la demanda estacional o un proceso de pago lento obligan a todo el mundo a prestarles atención.
Algunos equipos optimizan desde el principio basándose en suposiciones. Otros esperan hasta que las ralentizaciones, las quejas o el aumento de los costes hacen que sea inevitable tomar medidas. Ambos enfoques conllevan riesgos. Uno puede hacer que malgastes tu presupuesto. El otro puede dejar tu sitio mal preparado para cuando llegue el crecimiento.
Las analíticas ofrecen a los equipos una forma más eficaz de decidir cuándo actuar. En este artículo, explicamos cómo se pueden utilizar las analíticas como herramienta de planificación para detectar umbrales, limitaciones y patrones de uso antes de que se conviertan en problemas más graves.
¿Por qué las decisiones sobre la escalabilidad suelen tomarse demasiado tarde?
Las decisiones sobre el escalado suelen tomarse en el peor momento posible, cuando ya ha empezado a fallar algo.
Tu sitio empieza a ir más lento durante una campaña. El proceso de pago empieza a ralentizarse en los momentos de mayor tráfico. Los equipos internos empiezan a informar de problemas que no logran explicar del todo. Lo que podría haber sido un ajuste planificado se convierte en una solución urgente de la noche a la mañana.
Este patrón reactivo es habitual porque muchos equipos no tienen una visión clara de cuándo su infraestructura se está acercando a sus límites. Pueden ver que el tráfico crece, pero no entender cómo afecta ese crecimiento a los recursos del servidor, al rendimiento de la caché, al ancho de banda o a la actividad de la base de datos. Así que esperan hasta que las señales se vuelven imposibles de ignorar.
También ocurre lo contrario. Algunos equipos actualizan sus sistemas antes de tiempo por miedo a un posible aumento de la carga en el futuro, incluso cuando los datos no indican una presión constante. Esto lleva a gastos innecesarios, sobre todo cuando el problema real se podría haber resuelto con una mejor caché, una limpieza del código o cambios en los flujos de trabajo.
Un escalado reactivo genera varios problemas que hacen que el crecimiento sea más difícil de gestionar:
Las decisiones se toman bajo presión
Cuando la escalabilidad se ve afectada por una ralentización, una interrupción del servicio o un pico de tráfico, los equipos se ven obligados a diagnosticar los problemas mientras el negocio ya está sufriendo las consecuencias. Esa presión lleva a tomar decisiones precipitadas y a aplicar soluciones temporales que no abordan la causa real.
La planificación se convierte en una lotería
En lugar de utilizar las tendencias para orientar los presupuestos y los plazos, los equipos vinculan las decisiones de infraestructura a las emergencias. Eso hace más difícil predecir cuándo se necesitará capacidad o justificar el coste.
La confianza se erosiona con el tiempo
Cuando cada decisión sobre el escalado parece urgente, los equipos empiezan a dudar de su propio criterio. No están seguros de si han actuado demasiado tarde, demasiado pronto o por motivos equivocados. Con el tiempo, la infraestructura empieza a parecerles un riesgo recurrente en lugar de algo que puedan controlar.
Los informes te dicen lo que ha pasado, pero el análisis operativo te dice qué hacer a continuación
La mayoría de los equipos ya tienen acceso a los informes. Pueden ver las tendencias de tráfico, las visitas a las páginas, las conversiones y las fuentes de referencia. Esa información es útil, pero solo cuenta una parte de la historia.
Los informes superficiales muestran los resultados. Te dice cuántas personas visitaron tu sitio, qué hicieron y si se convirtieron. Lo que no muestra es cómo gestionó tu infraestructura esa actividad entre bastidores. Esa brecha es más importante a medida que creces.
Un pico de tráfico puede parecer un éxito en un panel de informes, pero no explica si tu servidor se vio sobrecargado, si los hilos de PHP llegaron al límite o si la caché permitió que todo siguiera funcionando sin problemas. Dos sitios web pueden registrar el mismo aumento de visitas y obtener resultados de rendimiento totalmente diferentes, dependiendo de cómo se utilicen sus recursos.
El análisis operativo ofrece una visión más detallada. En lugar de centrarse solo en los resultados, muestra lo que ocurre bajo la superficie. Los equipos pueden ver cómo se gestionan las solicitudes, cómo se utilizan los recursos y dónde empieza a acumularse la presión. Métricas como el uso del ancho de banda, la eficiencia de la caché, la actividad de los hilos PHP y el comportamiento de las respuestas ofrecen a los equipos una imagen más clara de cómo gestiona su infraestructura la demanda real.
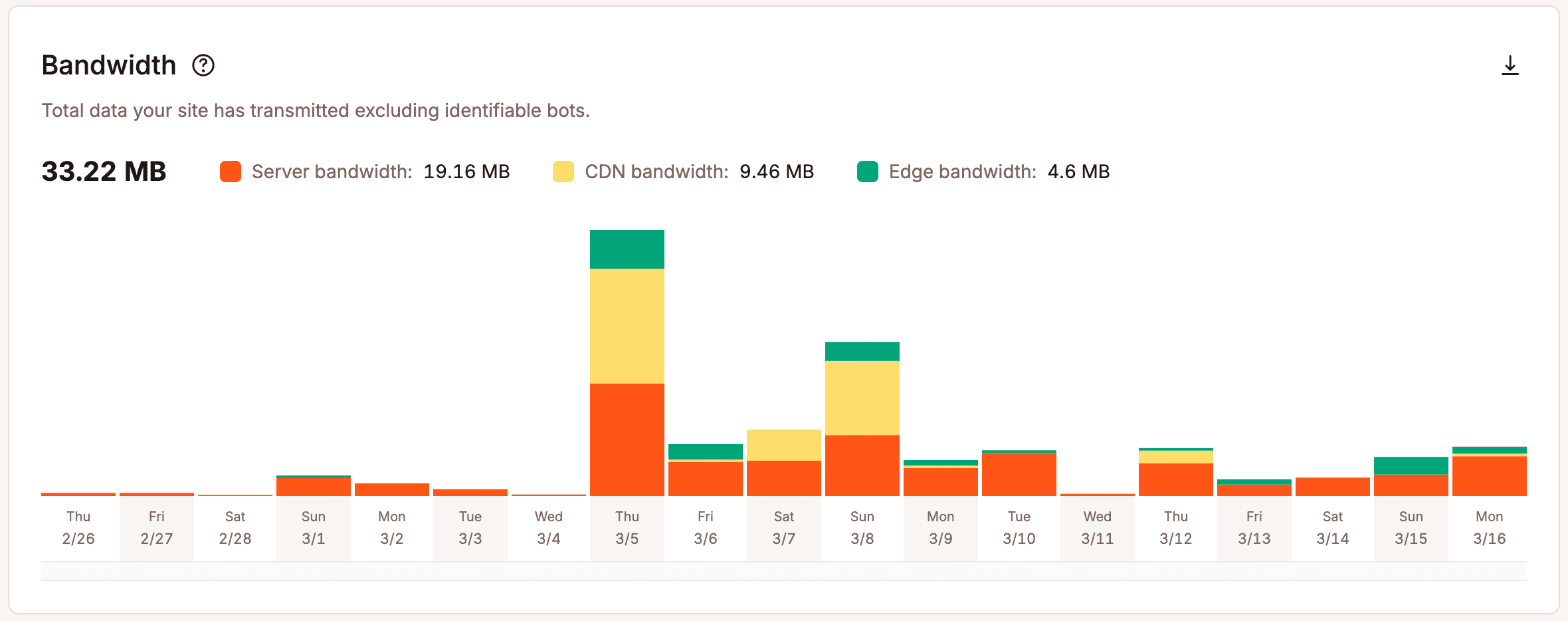
Sin esa visibilidad, las decisiones sobre el crecimiento se vuelven subjetivas. Los equipos reaccionan ante incidentes aislados, se guían por el instinto o se preparan para los peores escenarios posibles sin saber qué probabilidad hay de que se den.
Las señales que indican que ha llegado el momento de optimizar o escalar
La verdadera pregunta no es: «¿Podemos hacer que el sitio sea más rápido?» La mayoría de los equipos siempre pueden encontrar algo que ajustar, limpiar o mejorar.
La pregunta más acertada es: «¿Qué nos indican los datos que debemos hacer ahora?».
Las analíticas ayudan a los equipos a distinguir entre un bache temporal y un problema real de capacidad. En lugar de actuar basándose en una preocupación vaga, pueden fijarse en indicadores cuantificables que muestran cuándo hay que prestar atención a la optimización o al escalado.
Las tendencias de tráfico no dejan de crecer
Un pico puntual de tráfico no siempre significa que un sitio web necesite más recursos. Puede deberse a una campaña de correo electrónico puntual, una mención en redes sociales, un éxito de relaciones públicas o un evento estacional. Vale la pena realizar una revisión de esos momentos, pero no siempre indican una necesidad de escalar a largo plazo.
El crecimiento sostenido nos da una idea diferente. Si las visitas, las solicitudes o la actividad de los usuarios conectados siguen aumentando con el tiempo, quizá debas revisar tu configuración actual. Estos aumentos repetidos pueden ir ejerciendo una presión cada vez mayor sobre los recursos del servidor, la actividad de la base de datos, las capas de caché y el ancho de banda.
Los datos sobre tendencias ayudan a los equipos a planificar con antelación. Cuando ven que el tráfico aumenta mes tras mes, pueden evaluar el rendimiento, identificar los puntos débiles y hacer mejoras antes de que el crecimiento se ralentice.
Patrones de uso de recursos que indican tensión
El tráfico por sí solo no refleja el esfuerzo que realiza tu sitio. Incluso un número modesto de visitantes puede sobrecargar el sitio cuando las páginas dinámicas, las consultas pesadas a la base de datos, una caché deficiente o los procesos en segundo plano consumen demasiados recursos.
Las analíticas a nivel de alojamiento muestra dónde se acumula la carga. Los equipos pueden revisar el uso de hilos PHP, el consumo de ancho de banda, las tasas de aciertos y fallos de la caché, la actividad de la base de datos, los códigos de respuesta y el volumen de solicitudes.
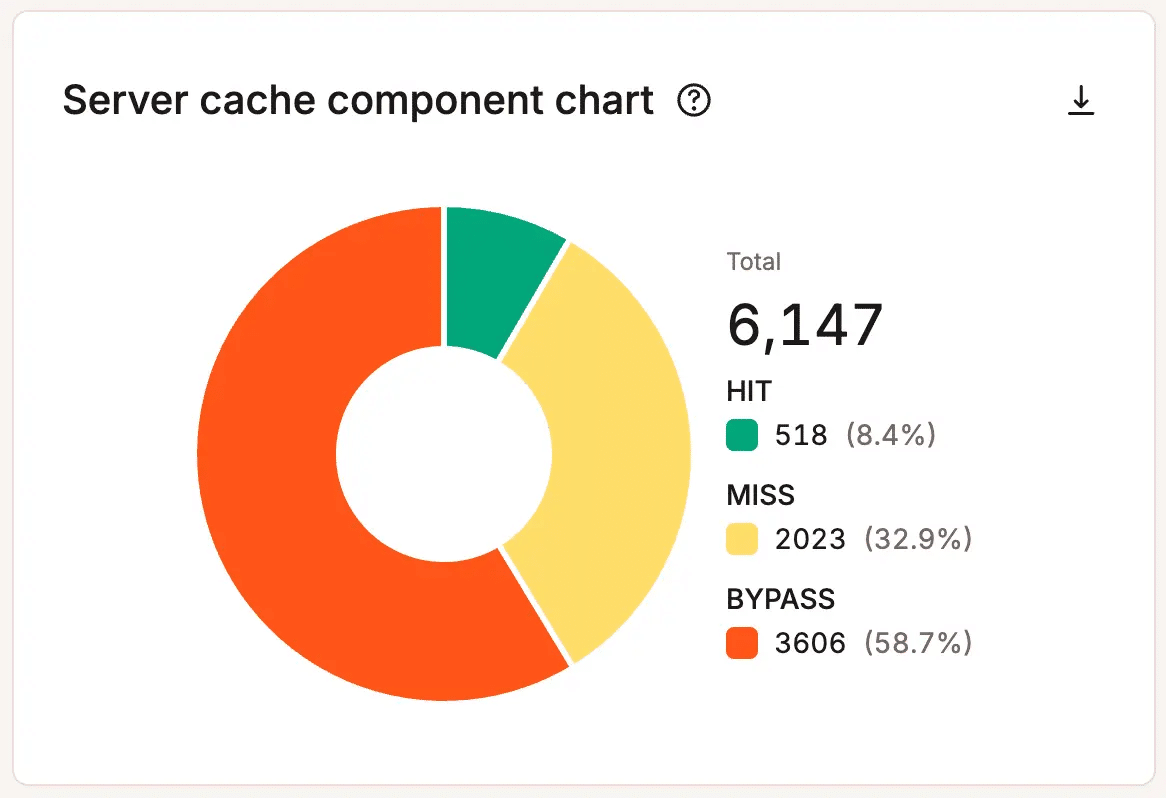
Busca patrones, no picos puntuales. Un breve aumento en el número de hilos PHP durante una hora de mucho tráfico puede que no tenga importancia. Pero los picos repetidos, el aumento de la demanda de ancho de banda o un rendimiento de la caché constantemente bajo pueden indicar que tu sitio necesita optimización, una revisión del flujo de trabajo o más capacidad.
Problemas de rendimiento que aparecen en condiciones específicas
Algunos problemas de rendimiento solo se notan cuando tu sitio web se ve sometido a una gran carga. Un sitio web puede parecer rápido en un día normal, pero ralentizarse durante el lanzamiento de un producto, una campaña de recaudación de fondos, un periodo de inscripción, las rebajas del Black Friday o una gran campaña de contenidos.
Esos momentos suelen revelar los verdaderos límites de tu configuración actual.
Las analíticas ayudan a los equipos a determinar si el problema es temporal, recurrente o si es probable que empeore. Si el rendimiento solo baja durante picos de tráfico poco frecuentes, es posible que el equipo tenga que mejorar la preparación de las campañas. Si se producen ralentizaciones cada vez que aumenta la demanda, es probable que el sitio necesite una optimización más profunda o una configuración de alojamiento más escalable.
Errores y anomalías que se convierten en señales de alerta temprana
Los errores, las solicitudes fallidas y la actividad inusual pueden advertir a los equipos antes de que los visitantes sientan todo el impacto.
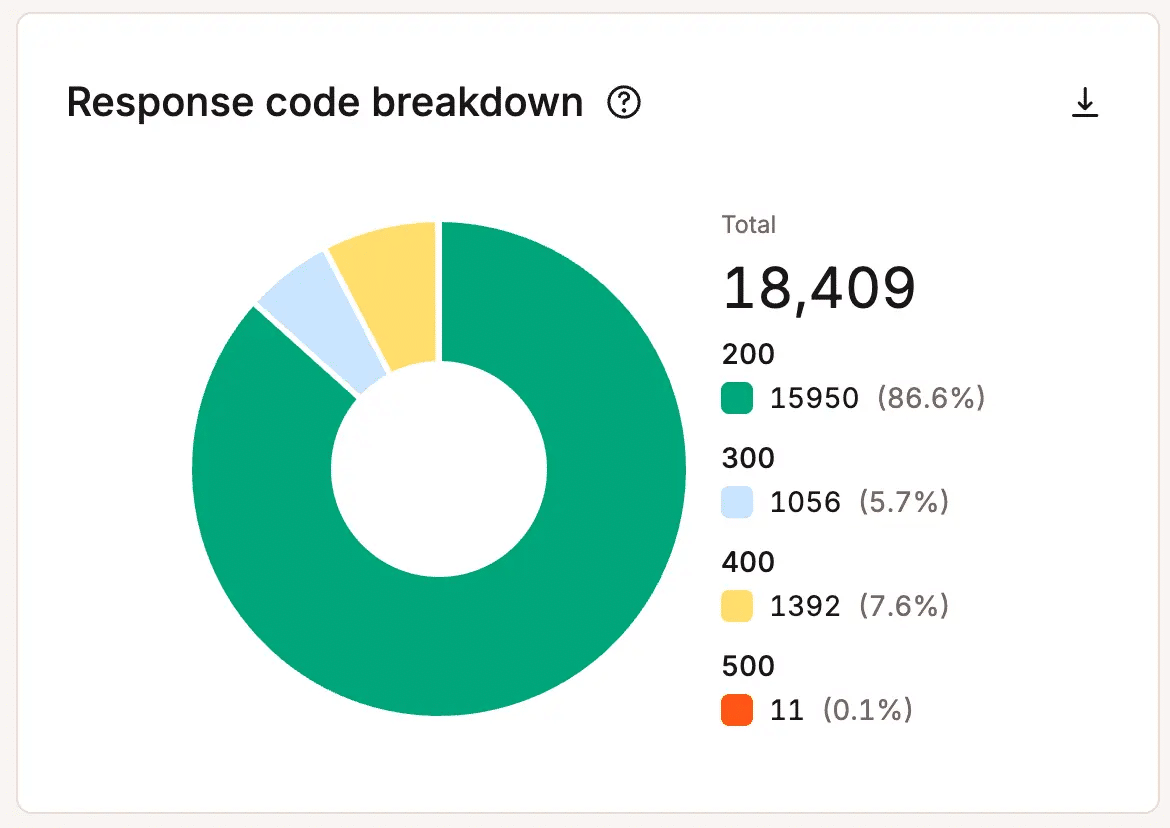
El aumento de las tasas de error puede indicar una sobrecarga de la infraestructura, problemas con las aplicaciones, cuellos de botella en los recursos o fallos en los procesos. Los patrones de tráfico inusuales pueden revelar la presencia de bots, solicitudes abusivas o una demanda inesperada que consume recursos sin aportar valor al negocio.
Estas señales permiten a los equipos actuar a tiempo. Cuando detectan errores y anomalías en su contexto, pueden investigar la causa, reducir la carga de trabajo innecesaria y proteger la experiencia del cliente antes de que las pequeñas señales de alerta se conviertan en problemas evidentes.
Cómo las analíticas ayudan a tomar decisiones de escalabilidad más acertadas
Las analíticas ayudan a los equipos a pasar de «algo no cuadra» a «esto es lo que muestran los datos». Ese cambio hace que las decisiones sobre escalabilidad sean más prácticas, menos impulsivas y más fáciles de justificar.
También ayuda a los equipos a elegir el siguiente paso correcto. No todas las ralentizaciones o picos exigen un plan de alojamiento mayor. A veces la optimización tiene más sentido. Otras veces, los datos apuntan a un problema de flujo de trabajo, un proceso que consume muchos recursos o un cambio más amplio en la infraestructura.
Saber si conviene optimizar antes de actualizar
Aumentar la capacidad no siempre es la mejor opción inicial. Si las analíticas muestran una baja eficiencia de la caché, solicitudes inusualmente pesadas, código ineficiente o tareas en segundo plano que consumen muchos recursos, el equipo puede mejorar el rendimiento antes de cambiar de estrategia.
Esto puede implicar ajustar las reglas de la caché, depurar los plugins o el código personalizado, revisar las consultas a la base de datos o modificar los procesos que generan una carga innecesaria. En estos casos, las analíticas ayudan a los equipos a evitar pagar por más capacidad cuando una mayor eficiencia resuelve el problema.
Saber cuándo conviene actualizar
En algún momento, la optimización puede no ser suficiente. Si los datos muestran una presión constante sobre los recursos, ralentizaciones recurrentes durante el crecimiento normal, necesidades crecientes de ancho de banda o límites claros de uso, el equipo puede justificar más fácilmente una actualización.
Por ejemplo, el gráfico de abajo muestra que este sitio alcanzó el número máximo de hilos PHP asignados, 69, en 69 ocasiones en menos de 30 días.
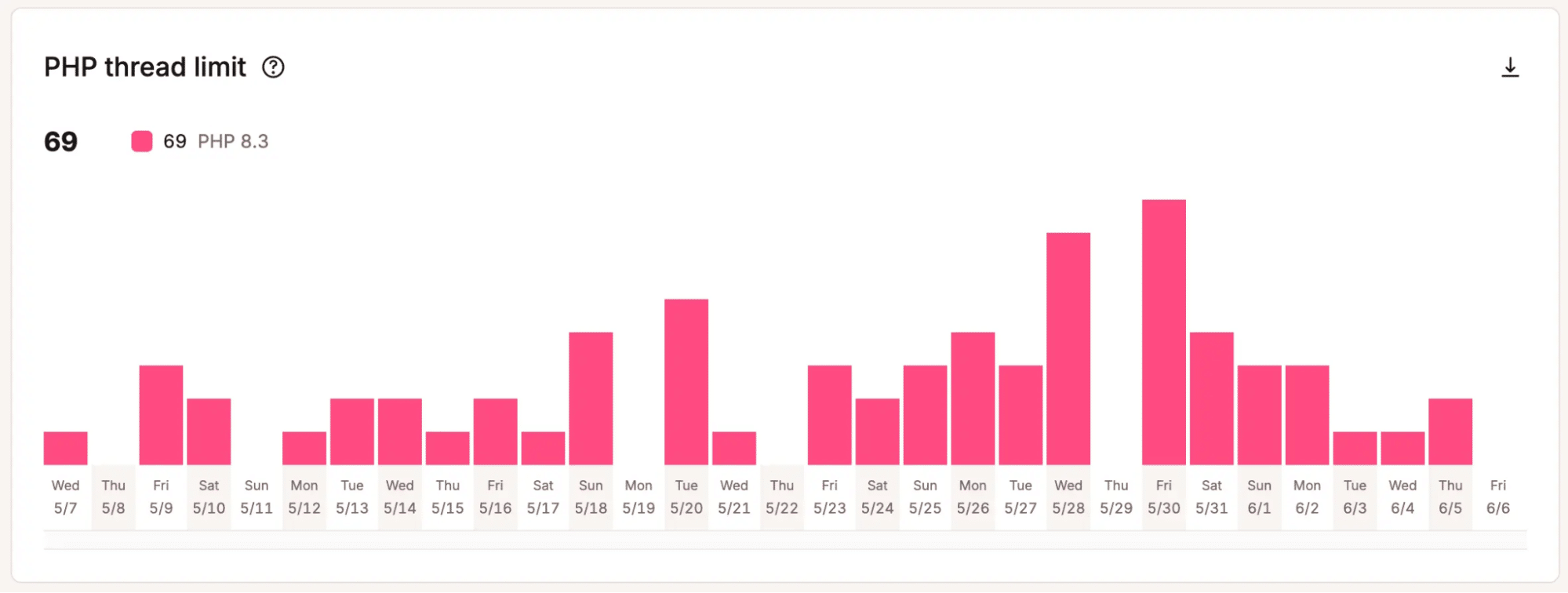
Esto es importante cuando los equipos tienen que decidir si merece la pena el coste de aumentar la capacidad. En lugar de basarse en corazonadas, pueden señalar patrones que indiquen que la configuración actual está llegando a sus límites.
Saber explicar la decisión internamente
Las decisiones sobre escalabilidad rara vez se limitan al equipo técnico. La dirección, el departamento financiero, el de marketing y el de operaciones quieren saber por qué es importante este cambio y por qué se hace ahora.
Las analíticas ayudan a los equipos a elaborar un argumento comercial claro. En lugar de basarse en opiniones, pueden recurrir a datos reales y relacionar el gasto en infraestructura con la fiabilidad del sitio, la preparación de las campañas, la experiencia del cliente y la protección de los ingresos. Esto hace que el debate pase de centrarse en preferencias técnicas a centrarse en riesgos cuantificables, plazos e impacto previsto.
¿Por qué el alojamiento reactivo complica el escalado?
El alojamiento reactivo hace que el crecimiento sea más difícil de gestionar porque los equipos no ven los límites hasta que ya sienten el impacto.
Muchos entornos de alojamiento sólo ofrecen a los equipos una visión limitada de los umbrales de capacidad reales. Los equipos pueden conocer los límites de su plan, pero no siempre pueden ver lo cerca que está el sitio de la tensión o qué partes del stack crean la mayor presión.
Eso crea un círculo vicioso. El sitio se ralentiza, una campaña no da los resultados esperados o empiezan a llegar solicitudes de soporte técnico. Entonces, el equipo investiga, se pone en contacto con el proveedor de alojamiento y se plantea una actualización cuando el problema ya ha afectado al negocio.
Este modelo genera incertidumbre. Hace que sea más difícil predecir, justificar y confiar en la infraestructura. Para los equipos en expansión, esa falta de claridad convierte la escalabilidad en una reacción en lugar de en una parte planificada del crecimiento.
Cómo ayuda Kinsta a los equipos a crecer con más confianza
Kinsta ofrece a los equipos una visión más clara del rendimiento de sus sitios de WordPress bajo demanda real. Con las analíticas de MyKinsta, los equipos pueden realizar un seguimiento de los patrones de tráfico, el uso de recursos, las señales de rendimiento y los puntos de presión emergentes sin tratar el alojamiento como una caja negra.
Esa visibilidad hace que el escalado sea menos reactivo. Los equipos detectan antes las tendencias, planifican el crecimiento con más confianza y toman decisiones de infraestructura respaldadas por datos reales.
Analíticas que revelan las limitaciones reales
Kinsta ayuda a los equipos a ver dónde empiezan a surgir los límites. Las analíticas de MyKinsta muestran señales como las tendencias del tráfico, el uso del ancho de banda, el rendimiento de la caché, los códigos de respuesta y la actividad de los recursos, dando a los equipos una visión más práctica de cómo su sitio gestiona la demanda.
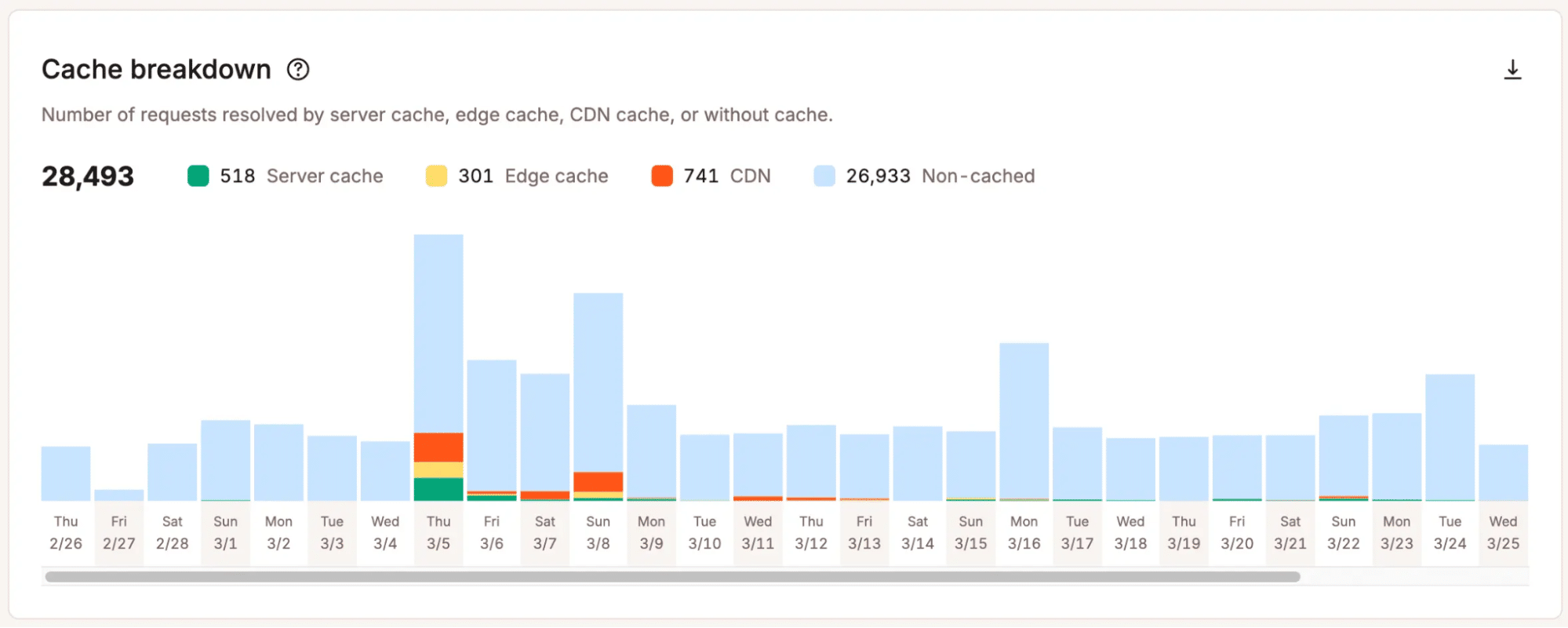
Esa claridad importa porque las decisiones de escalado no deben depender de suposiciones vagas. Cuando los equipos ven dónde se acumula la presión, pueden decidir si optimizar, ajustar su plan o echar un vistazo técnico más profundo.
Una plataforma construida para tomar decisiones informadas
El crecimiento a menudo conlleva cuestiones presupuestarias, planificación de lanzamientos y presión para justificar nuevos gastos. Kinsta apoya estas conversaciones con datos más claros sobre el uso y el rendimiento del sitio.
Esto hace que la planificación de la infraestructura sea más fácil de explicar. En lugar de pedir más capacidad porque el sitio «parece lento», los equipos pueden basar la decisión en tendencias cuantificables, cargas recurrentes o necesidades de crecimiento específicas.
La previsibilidad como ventaja de crecimiento
El escalado resulta menos estresante cuando los equipos ven lo que va a cambiar antes de que se convierta en algo urgente. Con una mejor visibilidad de los patrones de uso y los indicadores de rendimiento, los equipos pueden prepararse para las campañas, la demanda estacional y el crecimiento a largo plazo con más confianza.
Esa previsibilidad proporciona a los equipos una plataforma de alojamiento que pueden comprender, planificar y en la que pueden confiar a medida que el crecimiento continúa.
Deja de ver las analíticas como un complemento de los informes
Las analíticas funcionan mejor cuando influyen en cómo planificas, y no solo en cómo revisas los resultados a posteriori.
Cuando puedes detectar tendencias, patrones de uso y los primeros indicios de sobrecarga, puedes planificar mejor las decisiones de escalabilidad y justificarlas con mayor claridad. No tienes que adivinar cuándo actuar o reaccionar bajo presión. Puedes tomar decisiones fundamentadas basadas en el rendimiento real de tu sitio.
Esto hace que el crecimiento sea más predecible y mucho menos estresante.
Explora MyKinsta para comprender mejor tus patrones de uso, señales de rendimiento y necesidades de escalado antes de que se conviertan en urgentes.


