
De nos jours, presque tous les logiciels ou applications web nécessitent une base de données en backend. L’augmentation du nombre de transactions par seconde et les téraoctets de données stockées exigent un framework stable et flexible pour héberger et servir ces données.
Naturellement, pour les startups, la question du coût entre également en ligne de compte. Mais si nous vous disions que vous pouvez accéder à cette base de données et même la construire gratuitement, sans aucune condition ?
Oui, vous avez bien entendu – la base de données PostgreSQL garantit tout ce que nous avons mentionné ci-dessus, y compris quelques avantages supplémentaires ! Dans cet article, nous allons passer en revue les différents aspects de PostgreSQL qui lui permettent de se démarquer dans un segment qui évolue rapidement.
Passons aux choses sérieuses.
Qu’est-ce que PostgreSQL ?
PostgreSQL est un système de base de données open source, très stable, qui prend en charge différentes fonctions de SQL, comme les clés étrangères, les sous-requêtes, les déclencheurs, ainsi que différents types et fonctions définis par l’utilisateur. Il augmente encore le langage SQL en proposant plusieurs fonctionnalités qui permettent de mettre à l’échelle et de réserver méticuleusement les charges de travail de données. Il est principalement utilisé pour stocker les données de nombreuses applications mobiles, web, géospatiales et analytiques.
Nous allons approfondir tous les aspects de PostgreSQL dans cet article, en commençant par ses fonctionnalités clés dans la section suivante. Mettons-nous au travail.
Caractéristiques principales de PostgreSQL
Il existe quelques caractéristiques clés de la base de données PostgreSQL qui la rendent unique et largement favorisée par rapport aux autres bases de données. Actuellement, c’est la deuxième base de données la plus utilisée, juste derrière MySQL.
Examinons ces caractéristiques plus en détail.
Fiabilité et conformité aux normes
PostgreSQL offre une véritable sémantique ACID pour les transactions et supporte entièrement les clés étrangères, les jointures, les vues, les déclencheurs et les procédures stockées, dans de nombreux langages différents. Il inclut la plupart des types de données de SQL comme INTEGER, VARCHAR, TIMESTAMP, et BOOLEAN. Il prend également en charge le stockage d’objets binaires de grande taille, notamment des images, des vidéos ou des sons. Il est fiable car il dispose d’un vaste réseau de soutien communautaire intégré. PostgreSQL est une base de données tolérante aux pannes grâce à sa journalisation write-ahead.
Extensions
PostgreSQL peut se vanter d’avoir plusieurs ensembles de fonctionnalités robustes, notamment la récupération ponctuelle, le Multi-Version Concurrency Control (MVCC), les tablespaces, les contrôles d’accès granulaires, la réplication asynchrone, un planificateur/optimiseur de requêtes raffiné et la journalisation write-ahead. Multi-Version Concurrency Control permet la lecture et l’écriture simultanées des tables, en bloquant uniquement les mises à jour simultanées d’une même ligne. De cette façon, les conflits sont évités.
Évolutivité
PostgreSQL prend en charge Unicode, les jeux de caractères internationaux, les codages de caractères multi-octets, et tient compte des paramètres locaux pour le tri, la sensibilité à la casse et le formatage. PostgreSQL est hautement évolutif – tant au niveau du nombre d’utilisateurs simultanés qu’il peut accueillir que de la quantité de données qu’il peut gérer. En outre, PostgreSQL est multi-plateforme et peut fonctionner sur de nombreux systèmes d’exploitation, notamment Linux, Microsoft Windows, OS X, FreeBSD et Solaris.
Chargement dynamique
Le serveur PostgreSQL peut également inclure du code écrit par l’utilisateur dans lui-même via le chargement dynamique. L’utilisateur peut spécifier un fichier de code objet ; par exemple, une bibliothèque partagée qui implémente une nouvelle fonction ou un nouveau type et PostgreSQL le chargera selon les besoins. La possibilité de modifier son fonctionnement à la volée le rend particulièrement adapté à la mise en œuvre rapide de nouvelles structures de stockage et de nouvelles applications.
Architecture de PostgreSQL
Le serveur PostgreSQL possède une structure simple, composée d’une mémoire partagée, de processus d’arrière-plan et d’une structure de répertoire de données. Dans cette section, nous discutons de chaque composant et de la façon dont ils interagissent les uns avec les autres. Vous trouverez ci-dessous une illustration de l’architecture PostgreSQL. Initialement, une requête est envoyée par le client au serveur. Ensuite, le serveur PostgreSQL traite les données en utilisant des tampons partagés et des processus d’arrière-plan. Le fichier physique du serveur de base de données PostgreSQL est stocké dans le répertoire de données.
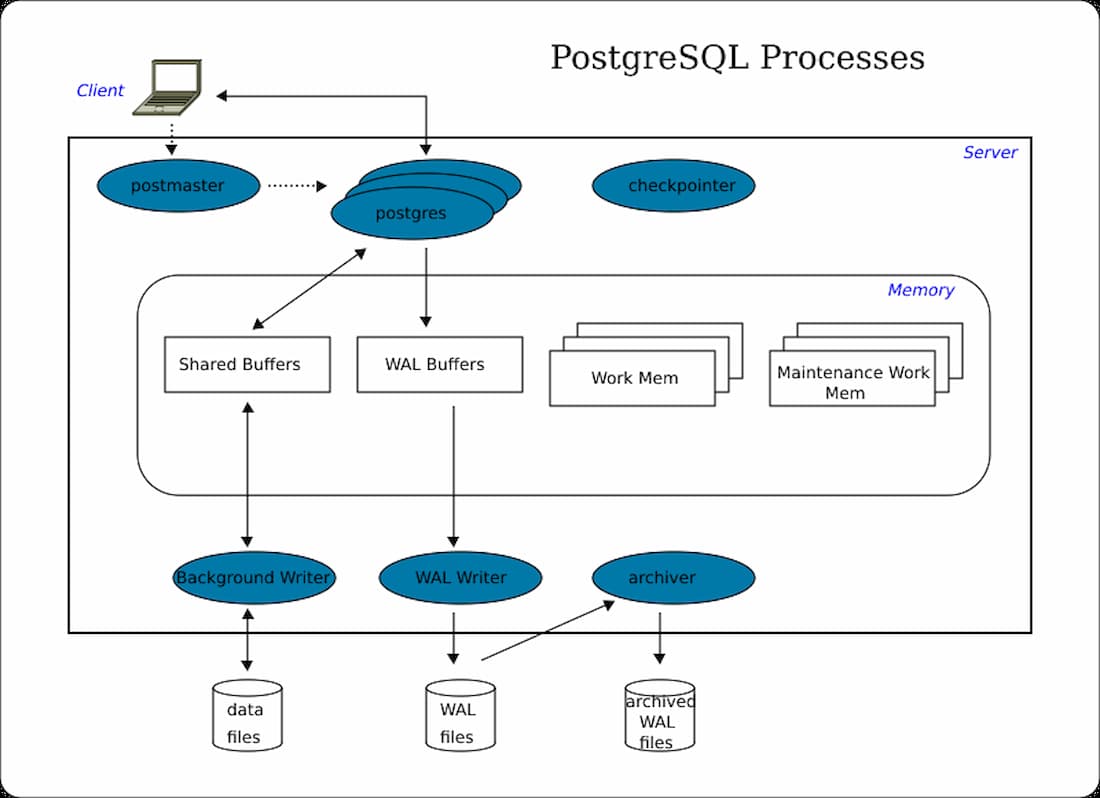
Mémoire partagée
La mémoire partagée est réservée au cache du journal des transactions et au cache de la base de données. Elle comporte en outre des éléments comme les tampons partagés, les tampons WAL, la mémoire de travail et la mémoire de travail de maintenance. Plongeons dans chaque sujet ci-dessous.
Tampons partagés
Ces tampons servent à minimiser les IO DISK du serveur. Pour remplir cet objectif, il est juste de fixer la valeur du tampon partagé à 25 % de la mémoire totale si nous avons un serveur dédié pour PostgreSQL. La valeur par défaut des tampons partagés à partir de la version 9.3 est de 128 Mo. Il est impératif d’essayer de minimiser la contention lorsque plusieurs utilisateurs y accèdent simultanément. Les blocs fréquemment utilisés doivent rester dans la mémoire tampon le plus longtemps possible. Cela permet d’accéder aux données le plus rapidement possible.
Tampons WAL
Les tampons WAL stockent temporairement les modifications apportées à la base de données. Le fichier WAL est constitué du contenu écrit par le tampon WAL à un moment prédéterminé. Les fichiers WAL et les tampons WAL sont importants pour récupérer les données pendant la sauvegarde et la restauration.
Mémoire de travail
Cet espace mémoire est utilisé pour les opérations bitmap, le tri, les jointures de fusion et les jointures de hachage pour écrire des données dans des fichiers disque temporaires. Le paramètre par défaut à partir de la version 9.3 est de 4 Mo.
Mémoire de travail de maintenance
Cet emplacement mémoire est utilisé pour les opérations de base de données telles que ANALYZE, VACUUM, ALTER TABLE et CREATE INDEX. Le paramètre par défaut à partir de la version 9.4 est de 64 Mo.
Processus d’arrière-plan
Chaque processus d’arrière-plan est intégral et exécute une fonction unique pour gérer le serveur. Quelques processus d’arrière-plan importants sont détaillés ci-dessous :
Processus Checkpointer
Lorsqu’un point de contrôle se produit, le tampon sale est écrit dans le fichier. Le Checkpointer écrit essentiellement toutes les pages sales de la mémoire sur le disque et nettoie la zone tampon partagée. Si la base de données tombe en panne, la perte de données peut être mesurée en obtenant la différence entre l’heure du dernier point de contrôle et l’heure d’arrêt de PostgreSQL.
Processus Writer en arrière-plan
Il met à jour les journaux et les informations de sauvegarde. Jusqu’à la version 9.1, ce processus était intégré au processus de checkpointer qui était effectué régulièrement. Cependant, à partir de la version 9.2, le processus checkpointer a été séparé du processus background writer.
WAL Writer
Ce processus écrit et vide périodiquement les données WAL sur le tampon WAL vers le stockage persistant.
Archiver
S’il est activé, ce processus a la responsabilité de copier les fichiers journaux WAL dans un répertoire spécifié.
Logger/Collecteur de logs
Ce processus écrit un tampon WAL dans le fichier WAL.
Structure des fichiers de données/répertoire de données
PostgreSQL possède plusieurs bases de données, formant ensemble un cluster de bases de données. Lors de l’initialisation, les bases de données template0, template1 et Postgres sont créées. La création de la nouvelle base de données de l’utilisateur se fait par le biais des bases de données template, qui se composent des tables du catalogue système. Bien que la liste des tables dans template0 et template1 soit la même après l’initialisation, seule la base de données template1 peut créer les objets dont l’utilisateur a besoin, c’est pourquoi la base de données de l’utilisateur est créée en clonant la base de données template1.
Les données nécessaires au cluster sont stockées dans le répertoire de données du cluster, également appelé « PGDATA ». Il se compose de plusieurs sous-répertoires. Quelques-uns, importants, sont mentionnés ci-dessous :
- Global: Le sous-répertoire global est composé de tables en grappes telles que la base de données des utilisateurs.
- Base: Le sous-répertoire Base est l’emplacement physique du tablespace par défaut. Il contient plusieurs sous-répertoires par base de données, dans lesquels sont stockés les catalogues système.
- PID: Le fichier PID est constitué de l’ID du processus postmaster actuel (PID).
- PG_VERSION: Ce sous-répertoire se compose des informations sur la version de la base de données.
- PG_NOTIFY: Ce sous-répertoire contient les données d’état LISTEN/NOTIFY. Ces fichiers peuvent être utiles pour le dépannage.
Pourquoi utiliser PostgreSQL ?
En plus de fournir un ensemble de fonctionnalités comme les index, les vues et les procédures stockées, PostgreSQL a beaucoup plus à offrir, à savoir :
- Support de la langue
- Open source
- Base de données relationnelle
- Performances
- Extensibilité
- Capacités d’équilibrage de charge
- Fiabilité
- Internationalisation
Examinons-les plus en détail.
Support du langage
PL/PGSQL est un langage procédural natif fourni par PostgreSQL qui possède différentes fonctionnalités modernes. Il soutient le type de données JSON qui est léger et assure la flexibilité incluse dans un seul paquet. Par conséquent, PostgreSQL prend en charge plusieurs langages de programmation et protocoles, notamment Perl, Ruby, Python, .Net, C/C++, Java, ODBC et Go.
Open source
Il est gratuit et open source – c’est de loin l’avantage le plus important de PostgreSQL. Il a été soutenu par plus de 20 ans de développement communautaire, ce qui a contribué à son haut niveau d’intégrité. Son code source est disponible sous une licence open source qui vous permet de l’utiliser, de le modifier et de le mettre en œuvre comme bon vous semble – sans frais supplémentaires.
Base de données relationnelle par objet
Les objets, les classes et la surcharge de fonctions sont directement pris en charge dans PostgreSQL. Il est possible d’étendre les types de données pour créer des types de données personnalisés, en raison de leurs caractéristiques orientées objet. Cela garantit une grande flexibilité pour les développeurs opérant avec des modèles de données complexes qui nécessitent une intégration de la base de données.
L’héritage des tables est une autre fonctionnalité prise en charge par PostgreSQL en raison de ses caractéristiques orientées objet. La table enfant peut hériter des colonnes de sa table parent, en plus des autres colonnes que la table enfant possède, ce qui la rend différente d’elle-même.
Performances
Les opérations d’écriture dans PostgreSQL peuvent être effectuées simultanément sans avoir besoin de verrous de lecture/écriture. Les index sont utilisés pour accélérer les requêtes lors du traitement de grandes quantités de données, ce qui permet aux bases de données de trouver une ligne spécifique sans avoir à parcourir toutes les données.
Avec PostgreSQL, vous pouvez même créer un index d’expression, qui fonctionne sur le résultat d’une expression ou d’une fonction plutôt que sur la simple valeur d’une colonne. L’indexation partielle est également prise en charge, dans laquelle seule une partie de la table est indexée. Il prend également en charge la parallélisation des requêtes de lecture, la compilation Just-in-time (JIT) des expressions et les transactions imbriquées (via des points de sauvegarde), ce qui garantit de grandes performances et une grande efficacité.
Extensibilité
PostgreSQL est hautement extensible car son fonctionnement est basé sur les catalogues, c’est-à-dire que les informations sont stockées dans des bases de données, des colonnes, des tables, etc. PostgreSQL contient non seulement une quantité accrue d’informations dans ses catalogues, mais aussi des détails sur les types de données, les méthodes d’accès, les fonctions, etc. Vous pouvez même aller jusqu’à écrire vos codes à partir de différents langages de programmation sans recompiler votre base de données, et définir vos types de données.
Capacités d’équilibrage de charge
Il garantit la haute disponibilité et l’équilibrage de la charge grâce au fonctionnement des serveurs de secours, à la planification continue, à la préparation du primaire pour les serveurs de secours, à la mise en place d’un serveur de secours, à la réplication en continu, aux créneaux de réplication, à la réplication en cascade et à l’archivage continu en secours. En outre, PostgreSQL prend en charge la réplication synchrone, où deux instances de base de données peuvent fonctionner en même temps et où la base de données principale est synchronisée avec une base de données seconadire simultanément, ce qui garantit davantage la haute disponibilité.
Fiabilité
En plus de stocker les données en toute sécurité et de permettre à l’utilisateur de récupérer les données lorsque la requête est traitée, il est soutenu par une communauté de contributeurs qui trouvent régulièrement des bogues et essaient d’améliorer le logiciel, ce qui rend PostgreSQL fiable.
Internationalisation
Le processus de conception d’un logiciel afin qu’il puisse être utilisé dans diverses régions est connu sous le nom d’internationalisation. Il prend en charge les jeux de caractères internationaux par le biais de codages de caractères multi-octets, de collations ICU, d’Unicode, et il tient compte des spécificités locales pour le tri, le formatage et la sensibilité à la casse. L’affichage des messages générés par PostgreSQL dans la langue de votre choix est un exemple d’internationalisation.
Quand utiliser PostgreSQL
Avez-vous besoin de construire des requêtes et des relations complexes qui doivent être fréquemment mises à jour et constamment maintenues de la manière la plus rentable possible ? PostgreSQL pourrait être une option appropriée. Non seulement PostgreSQL est gratuit, mais il est également multi-plateforme, et pas seulement limité au système d’exploitation Windows. Si vous souhaitez analyser des données, PostgreSQL fournit une grande quantité d’expressions régulières comme base pour le travail analytique.
C’est également l’une des meilleures bases de données en matière de support CSV. Des commandes simples comme « copier depuis » et « copier vers » aident au traitement rapide des données. En cas de problème d’importation, une erreur est signalée et l’importation est immédiatement interrompue. Les sections suivantes couvrent certaines des applications les plus courantes de PostgreSQL dans le monde moderne. Commençons.
Données géospatiales gouvernementales
L’extension de base de données géospatiale PostGIS pour PostgreSQL est incontestablement bénéfique. Lorsqu’il est utilisé avec l’extension PostGIS, PostgreSQL prend en charge les objets géographiques et peut être utilisé comme magasin de données géospatiales pour les systèmes d’information géographique (SIG) et les services de localisation.
Industrie financière
PostgreSQL est un SGBD idéal pour l’industrie financière. Puisqu’il est entièrement conforme à la norme ACID, il constitue un choix idéal pour le traitement des transactions en ligne (OLTP), car ces bases de données doivent être écrites, lues et mises à jour fréquemment, tout en mettant l’accent sur un traitement rapide. Il est également apte à exécuter des analyses de bases de données. Il peut être intégré à tout logiciel effectuant des opérations mathématiques, comme Matlab et R.
Données scientifiques
Les données scientifiques nécessitent des téraoctets de données. Il est impératif de traiter ces données de la manière la plus efficace possible. PostgreSQL fournit de merveilleuses analyses et un puissant moteur SQL. Cela permet de gérer une grande quantité de données avec facilité.
Technologie web
Les sites web traitent souvent des centaines ou des milliers de requêtes par seconde. Si le développeur est à la recherche d’une solution rentable et évolutive, PostgreSQL est la meilleure solution. PostgreSQL peut exécuter des sites web et des applications dynamiques dans le cadre d’une alternative robuste à la pile LAMP, c’est-à-dire la pile LAPP. (Linux, Apache, PostgreSQL, PHP, Python et Perl)
Fabrication
De nombreuses startups et grandes entreprises utilisent PostgreSQL comme principale solution de stockage de données pour les produits, les solutions et les applications à l’échelle d’Internet. Les performances de la chaîne logistique peuvent être optimisées en utilisant ce SGBD open-source comme backend de stockage. Par conséquent, cela permet aux entreprises de réduire le coût d’exploitation de leur activité.
Les défis opérationnels de PostgreSQL
Jusqu’à présent, nous n’avons fait que chanter les louanges de PostgreSQL dans cet article, il est donc normal que nous vous montrions quelques défauts sur lesquels vous pourriez tomber en jouant avec PostgreSQL. Voici quelques défis opérationnels que vous pourriez rencontrer au cours du processus d’adoption de PostgreSQL.
- Absence d’un écosystème de base de données mature : PostgreSQL peut se targuer d’avoir l’une des communautés qui se développent le plus rapidement, mais contrairement aux fournisseurs de bases de données traditionnels, la communauté PostgreSQL ne bénéficie pas du confort d’un écosystème de bases de données développé.
- Manque d’expertise : PostgreSQL est souvent couplé à diverses bases de données, telles que MongoDB. Or, chaque base de données nécessite des prouesses spécialisées, et l’embauche de personnel technique possédant les compétences PostgreSQL souhaitées peut s’avérer une tâche ardue à remplir. Outre les outils de gestion pour PostgreSQL, les experts en bases de données et les équipes DevOps doivent s’attaquer à diverses bases de données provenant de plusieurs fournisseurs. Cela peut être difficile à gérer lorsque vous ne pouvez pas passer d’un processus existant à un autre.
- Incohérence: PostgreSQL étant un outil open source, différentes équipes de développement informatique au sein d’une organisation peuvent commencer à l’exploiter de manière organique. Cela peut conduire à un autre obstacle : l’absence d’un point de connaissance unique pour toutes les instances de PostgreSQL dans l’environnement informatique. Un autre problème qui pourrait découler du fait que différentes équipes tentent de résoudre le même problème est la duplication et la redondance du travail.
Principales alternatives à PostgreSQL
Voici quelques alternatives clés de PostgreSQL que vous pouvez exploiter pour votre site web WordPress.
MySQL
Lorsque vous pensez aux bases de données, votre esprit se dirige instantanément vers MySQL. C’était une option assez omniprésente pour les développeurs pendant très longtemps avant que des alternatives viables ne commencent à apparaître. Elle était utilisée par bien plus de 39 % des développeurs en 2019. Même s’il n’a pas la polyvalence de PostgreSQL, il peut toujours s’avérer utile pour divers cas d’utilisation comme les applications web évolutives.
MySQL a été maintenu par Oracle depuis sa création en 1995. Oracle propose également des versions élites de MySQL avec des extensions propriétaires, des services supplémentaires, des extensions et un support utilisateur robuste. Pour mieux comprendre MySQL, vous devez avoir une meilleure compréhension des modèles client-serveur et des bases de données relationnelles. En termes simples, vos données sont réparties dans diverses zones de stockage distinctes, également appelées tables, par opposition au fait de tout décharger dans une seule grande unité de stockage. C’est l’essence même d’une base de données relationnelle.
En plus d’être une plateforme de base de données fiable et solide, elle est assez facile à maîtriser. La courbe d’apprentissage n’est pas aussi raide que celle de certains de ses contemporains, car il n’est pas nécessaire d’avoir une maîtrise complète de SQL pour commencer à travailler avec MySQL.
Si vous utilisez WordPress pour votre site web et que vous souhaitez comprendre comment faire fonctionner MySQL plus rapidement, votre meilleure option serait d’affiner votre base de données pour l’aligner sur la façon dont vous utilisez WordPress. En termes techniques, cela s’appelle un réglage des performances de MySQL. L’avantage évident de l’optimisation de MySQL est un temps de chargement plus court et un site web globalement plus rapide. En outre, si vous entretenez correctement votre base de données, vous devriez constater une amélioration constante de votre croissance, même si elle s’étend.
MariaDB
MariaDB est un fork du système de gestion de base de données relationnelle MySQL, soutenu commercialement, qui se targue d’une approche fondamentalement distincte pour répondre aux besoins du monde moderne. Le moteur de stockage spécialisé et enfichable de MariaDB offre une prise en charge des charges de travail qui nécessitaient auparavant une vaste gamme de bases de données spécialisées. Cela lui permet d’être un guichet unique pour les organisations, que ce soit sur le cloud ou le matériel de base qu’elles aiment.
Vous pouvez déployer MariaDB en quelques minutes pour des cas d’utilisation analytiques, transactionnels ou hybrides afin d’offrir une dextérité opérationnelle inégalée sans renoncer aux fonctionnalités clés de l’entreprise. Cela inclut une conformité SQL complète et ACID réelle.
MariaDB offre les produits suivants à ses utilisateurs :
- MariaDB Enterprise : MariaDB Enterprise est une solution de base de données open source absolue, de qualité production, qui peut s’attaquer aux charges de travail analytiques, transactionnelles ou hybrides analytiques/transactionnelles avec élégance. MariaDB Enterprise possède également la capacité de passer de bases de données en colonnes et autonomes à des bases de données SQL entièrement distribuées qui peuvent effectuer des millions de transactions par seconde. Elle vous permet également d’effectuer des analyses interactives et improvisées sur des milliards de lignes.
- MariaDB Community Server : MariaDB Community Server est la base de données relationnelle open source exploitée par une grande majorité de développeurs aujourd’hui. Non seulement le serveur communautaire MariaDB est compatible avec Oracle, MySQL et diverses autres bases de données, mais il est également garanti de rester open source pour toujours. Ses principales caractéristiques sont le stockage en colonnes pour l’analyse, le SQL moderne, les moteurs de stockage enfichables et la haute disponibilité.
- MariaDB SkySQL : SkySQL est connu comme une offre Database-as-a-Service (DBaaS) qui apporte toute la puissance de MariaDB Enterprise dans le cloud ainsi que sa prise en charge des charges de travail analytiques, transactionnelles et hybrides. SkySQL est construit sur Kubernetes et remanié pour les services et l’infrastructure du cloud. SkySQL s’est fait un nom dans cet espace en combinant le libre-service et la facilité d’utilisation avec des capacités d’assistance de premier ordre et une fiabilité d’entreprise. De manière assez évidente dans la dernière déclaration, cela comprend tout ce qui est nécessaire pour exécuter en toute sécurité des bases de données essentielles dans le nuage couplé à une gouvernance d’entreprise.
Grâce à sa compatibilité avec MySQL, vous pouvez utiliser MariaDB comme « stand-in » pour MySQL sans pratiquement aucune conséquence.
Meilleures pratiques pour votre base de données
Lorsque vous pensez à des plateformes adaptées aux les propriétaires de sites web débutants, vous pensez probablement à WordPress. WordPress vous permet de réaliser beaucoup de choses sans aucune expérience préalable du codage. Cependant, pour tirer le maximum de valeur de WordPress, vous devez tout de même avoir une compréhension claire du fonctionnement de certains de ses éléments de base. Par exemple, si vous utilisez WordPress pour votre site web depuis un certain temps déjà, c’est probablement le bon moment pour comprendre le fonctionnement des bases de données WordPress.
Cela amène immédiatement une question commune : pourquoi WordPress a-t-il besoin d’une base de données après tout ? On ne le dirait peut-être pas, mais WordPress est bien plus qu’un simple outil. Il y a beaucoup de travail en coulisse pour le faire fonctionner efficacement, quelle que soit la taille de votre site web.
Pour aller plus loin, vous devez savoir qu’un site web WordPress est composé de nombreux types de données différentes. Il va sans dire que toutes ces informations sont stockées dans une base de données WordPress consolidée. Cette base de données fait partie intégrante de votre site web WordPress. Elle enregistre toutes les modifications que vous ou vos visiteurs apportez et permet à votre site web de fonctionner de manière transparente. Voici quelques données qui sont rassemblées dans votre base de données WordPress :
- Informations organisationnelles telles que les étiquettes et les catégories.
- Réglages du site.
- Pages, articles et contenu similaire.
- Données relatives aux thèmes et aux extensions.
- Commentaires et données des utilisateurs.
Lorsque vous installez un site web WordPress, une partie du processus consiste à créer une base de données pour celui-ci. En général, cela se fait automatiquement. Toutefois, il existe une disposition si vous souhaitez créer une base de données manuellement, ou même exploiter une base de données existante avec un nouveau site web.
La section suivante traite des pratiques recommandées pour votre base de données WordPress.
Utiliser un outil de gestion de base de données
La fonction de base des outils de gestion de base de données est de vous permettre de regarder le contenu de votre base de données. Pour qu’une base de données fonctionne sans problème, l’utilisation d’un outil de gestion de base de données pourrait être votre meilleure option. En général, les outils de gestion de base de données regroupent des fonctions qui répondent aux besoins de trois professionnels distincts des bases de données :
- Les analystes de bases de données peuvent extraire les données de plusieurs sources. Viennent ensuite le nettoyage, l’intégration et la préparation des données pour l’analyse. Pour les analystes de bases de données, avoir la possibilité de collaborer sur des ensembles de données et des requêtes sans avoir à compter sur l’informatique pour y accéder est une exigence intégrale.
- Les développeurs de bases de données ont besoin d’outils qui leur permettent d’écrire un code de haute qualité dès la première fois et de le maintenir de manière transparente. Les développeurs de bases de données apprécient les outils de collaboration et d’automatisation de la programmation. Cela leur permet de condenser les cycles de développement sans augmenter les risques.
- Les administrateurs de bases de données exploitent des outils conçus pour suivre les performances et la santé des bases de données. Ils s’attaquent à des tâches allant du démêlage et du diagnostic des obstructions de performance à l’exécution des modifications du schéma de la base de données.
Lorsque vous recherchez un outil de gestion de base de données qui réponde aux besoins de votre entreprise, vous devriez rechercher des outils capables d’intégrer les tâches de test, de développement de base de données et de déploiement dans le processus de livraison et d’intégration continues, ce qui facilite le suivi du développement des applications.
Un outil de gestion de base de données efficace devrait également permettre la visualisation des données à partir de résultats tabulaires sous forme de diagrammes, d’histogrammes et de graphiques, avec une distribution facile aux décideurs. Il doit également aider les administrateurs à localiser les problèmes avant qu’ils ne surviennent en production en ciblant les instructions SQL et les applications qui ne s’adaptent pas bien à l’augmentation du volume de transactions.
Adminer (précédemment connu sous le nom de phpMinAdmin) est un outil de gestion de base de données gratuit et open source qui offre des tonnes de fonctionnalités utiles et une IU (interface utilisateur) plus élégante. Vous pouvez facilement déployer cet outil pratique de gestion de base de données sur votre serveur, et tout ce que vous avez à faire est de télécharger son unique fichier PHP, de faire pointer votre navigateur vers lui et de vous connecter.
Utilisation d’un plugin de base de données
Si vous voulez évaluer la qualité d’un site web, ne cherchez pas plus loin que sa base de données. Chaque grain d’information associé à votre site web trouve son chemin vers votre base de données WordPress. Certaines d’entre elles sont cruciales, tandis que d’autres ne font que vous freiner. Il s’agit notamment des mauvaises tables, des anciens brouillons, des commentaires de spam. Pour éviter qu’elles n’entravent votre site web, vous devez faire appel aux extensions WordPress de base de données.
Les extensions de base de données peuvent se présenter sous différentes formes. Certaines extensions peuvent être utilisées pour nettoyer la base de données des fichiers inutiles sur une base mensuelle ou hebdomadaire. D’autres peuvent être utilisées pour sauvegarder votre base de données avant d’effectuer des changements, par exemple, lors d’une migration. Outre l’amélioration de la vitesse de votre site web, vous pouvez utiliser des extensions de base de données pour offrir une expérience utilisateur plus efficace tout en améliorant vos chances d’être mieux classé dans les moteurs de recherche.
Diagnostiquer et réparer votre base de données
En tant qu’utilisateur de WordPress, vous avez probablement eu affaire à quelques erreurs récalcitrantes de WordPress. Voici l’un des messages d’erreur les plus courants que vous avez pu rencontrer :
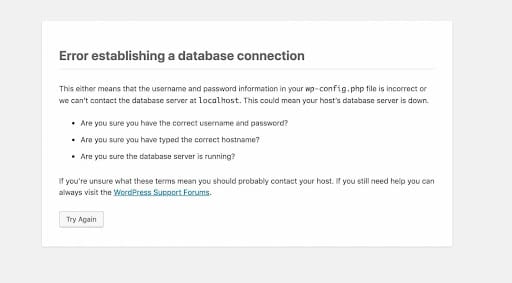
L’importance de réparer votre base de données devrait être assez évidente. Non seulement les erreurs WordPress entravent le bon fonctionnement de votre site web, mais elles peuvent avoir un effet néfaste sur l’expérience du consommateur. Les installations et les mises à jour ratées, les temps d’arrêt et les ressources manquantes peuvent laisser une trace dans votre potentiel de gain et nuire à votre crédibilité.
Résumé
PostgreSQL est un système de gestion de base de données relationnelle open source et gratuit qui se concentre sur la conformité et l’extensibilité de SQL. Fort de plus de 30 ans de développement actif, PostgreSQL est l’un des outils de base de données open-source les plus utilisés dans le monde.
Dans cet article, nous avons abordé certaines des principales caractéristiques de PostgreSQL, son architecture, ses cas d’utilisation, ses avantages, ses défis opérationnels et ses principales alternatives. Nous avons conclu par quelques pratiques recommandées pour maintenir votre base de données WordPress en parfait état tout en continuant à la faire évoluer.

Salman Ravoof est un développeur web autodidacte, un écrivain, un créateur et un grand admirateur des logiciels libres. Outre la technologie, il est passionné par la science, la philosophie, la photographie, les arts, les chats et la nourriture. Apprenez-en plus sur son site web, et connectez-vous avec Salman sur X.


{kind=link}