
Lorsque l’utilisation des ressources sur le site d’un client commence à augmenter sans que le nombre de visites n’augmente en conséquence, le trafic généré par les robots en est probablement la cause. Les robots qui accèdent à des points de terminaison non mis en cache, tels que les actions liées au panier, les pages de produits filtrées et les requêtes de recherche, déclenchent l’exécution de code PHP et des requêtes de base de données à chaque requête. De ce fait, votre cache de pages n’a jamais l’occasion de les prendre en charge.
Bien que votre premier réflexe soit de bloquer tout le trafic automatisé, Googlebot, Bingbot, les lecteurs RSS et les outils de surveillance de disponibilité entrent dans la même catégorie automatisée que les robots que vous souhaitez bloquer. Tout bloquer revient à supprimer le trafic qui assure la visibilité et le bon fonctionnement de vos sites.
La protection anti-robots de Kinsta vous permet de filtrer les requêtes qui engendrent des coûts sans apporter de valeur ajoutée, tout en laissant passer celles qui comptent. Ces contrôles s’effectuent au niveau de l’infrastructure, ce qui signifie que le filtrage a lieu avant même que les requêtes n’atteignent votre site WordPress.
Pourquoi le blocage généralisé du trafic n’est pas la solution
Un blocage total de tout le trafic automatisé est, en théorie, une tactique valable pour réduire le gaspillage de bande passante. Cependant, cela supprime également les requêtes dont vous dépendez. Par exemple, un blocage total empêche Googlebot et Bingbot d’explorer votre contenu, les outils de surveillance de la disponibilité ne remplissent plus les tâches que vous leur confiez, et les intégrations d’API qui relient les flux de travail de vos clients à WordPress cessent de fonctionner.
En revanche, le trafic qu’il convient de bloquer constitue un sous-ensemble spécifique de l’ensemble : roles bots non vérifiés et les automatisations qui ciblent des points de terminaison non mis en cache. Dans de nombreux cas, ceux-ci ne contribuent ni au référencement naturel (SEO), ni à l’expérience utilisateur, ni au chiffre d’affaires.
Cependant, il s’agit d’un comportement typique de nombreuses actions basées sur des robots, selon David Belson, ancien responsable de l’analyse des données chez Cloudflare :
La plupart des cas que nous observons ne sont pas malveillants. Il s’agit de robots se comportant de manière inefficace à grande échelle, et c’est là que les véritables problèmes commencent.
Un robot suivant des variantes d’URL ne peut pas reconnaître qu’il est pris dans une boucle. Prenons par exemple chaque filtre de produit, chaîne de requête ou réglage de panier traité comme une page distincte. Nos propres données d’infrastructure ont enregistré 550 millions de requêtes filtrées par une seule règle de détection de boucle sur une période de 30 jours. Un serveur traite chacune d’entre elles comme une tâche réelle, quelle que soit l’intention.
La sécurité au niveau de la plateforme de Kinsta gère déjà les menaces les plus évidentes en bloquant le trafic classé comme malveillant avant qu’il n’atteigne votre site. Cela couvre la protection contre les attaques DDoS et les requêtes provenant d’adresses IP associées à des sources d’attaques connues. Cependant, entre cette protection de base et le trafic que vous souhaitez autoriser, il existe une couche intermédiaire de sécurité contre les robots non vérifiés et indésirables.
C’est le filtrage sélectif du trafic automatisé restant qui empêche la consommation de ressources de grimper alors que le nombre de visites reste stable. C’est ce schéma que de nombreuses agences gérant l’hébergement WordPress pour plusieurs clients reconnaissent comme le signe que la charge générée par les robots a dépassé le seuil que la couche de sécurité par défaut peut gérer à elle seule.
Comprendre le trafic que vous gérez réellement
Kinsta classe chaque requête en combinant sa propre analyse du trafic et le système d’apprentissage automatique de Cloudflare, qui attribue à chaque visiteur un score de robot compris entre 1 et 99. Un score de 99 indique que la requête provient très probablement d’un humain ; un score de 1 confirme une activité automatisée.
Cinq catégories sont déterminantes pour les décisions en matière de protection :
- Les robots vérifiés correspondent à un trafic automatisé provenant d’organisations reconnues. Cela inclut Googlebot, Bingbot et d’autres services figurant dans le répertoire des robots vérifiés de Cloudflare. Ceux-ci sont autorisés à passer à tous les niveaux de protection, quels que soient vos réglages.
- Les humains probables obtiennent un score compris entre 30 et 99 et correspondent à de véritables visiteurs présentant un comportement de navigation normal.
- Les robots probables obtiennent un score compris entre 2 et 29 et correspondent à des automatisations non vérifiées détectées comme une activité de robot probable.
- Le trafic automatisé obtient un score de 1 et englobe les robots confirmés, mais inclut également les outils qui se connectent à votre site par programmation sans identité vérifiée. Il s’agit notamment d’intégrations personnalisées, de scripts de déploiement, de moniteurs de disponibilité auto-hébergés, etc.
- Les robots d’exploration IA à fréquence excessive sont des robots IA qui génèrent une charge via des requêtes à haute fréquence ou en boucle.
Il existe deux autres catégories qui méritent d’être mentionnées. Tout d’abord, le trafic malveillant est automatiquement bloqué à chaque niveau de protection, sans nécessiter de configuration. Cependant, il existe également du trafic non classé. Il s’agit généralement de volumes de trafic très faibles et inoffensifs. Il consiste le plus souvent en des requêtes de services internes qui n’ont pas d’impact sur le serveur d’origine, telles que les requêtes générées lorsque votre site renvoie une page d’erreur.
Comment analyser votre utilisation des ressources à l’aide de MyKinsta
La première étape consiste à déterminer quelle catégorie de trafic est à l’origine de l’utilisation des ressources. La vue Analyse du trafic automatisé et des robots dans MyKinsta montre comment les requêtes parvenant à votre site sont classées, ce qui facilite l’identification des cas où le trafic automatisé contribue à une charge accrue.
Pour accéder à ces données, rendez-vous dans Sites > nom du site > Analyses > Robots et trafic automatisé.
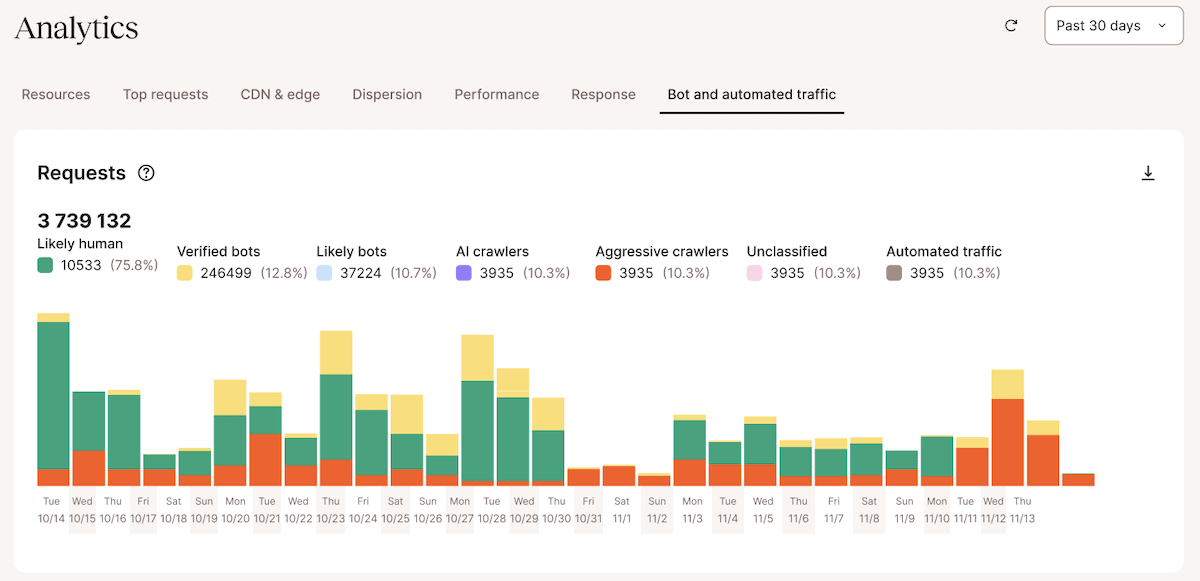
Cette vue classe le trafic en plusieurs catégories : robots vérifiés, robots probables, robots d’indexation IA, robots d’indexation agressifs, trafic automatisé et visiteurs probablement humains. Au lieu de déduire indirectement l’activité des robots à partir de la bande passante ou du nombre de visites uniquement, vous pouvez voir quelle quantité de trafic automatisé atteint réellement votre site et comment Kinsta le classe.
Par exemple, les pics de robots d’indexation agressifs ou de trafic automatisé indiquent souvent que des robots accèdent de manière répétée à des points de terminaison non mis en cache. De même, des volumes élevés de trafic provenant de robots d’indexation IA peuvent expliquer une augmentation inattendue de la bande passante ou une charge accrue sur le serveur d’origine, même lorsque le trafic humain reste relativement stable.
Le graphique des résultats de la protection contre les robots montre également comment les requêtes sont traitées après classification, y compris le trafic autorisé, contesté ou bloqué. Cela vous donne une idée plus précise de la manière dont vos paramètres de protection affectent le trafic entrant avant de modifier les niveaux de protection.
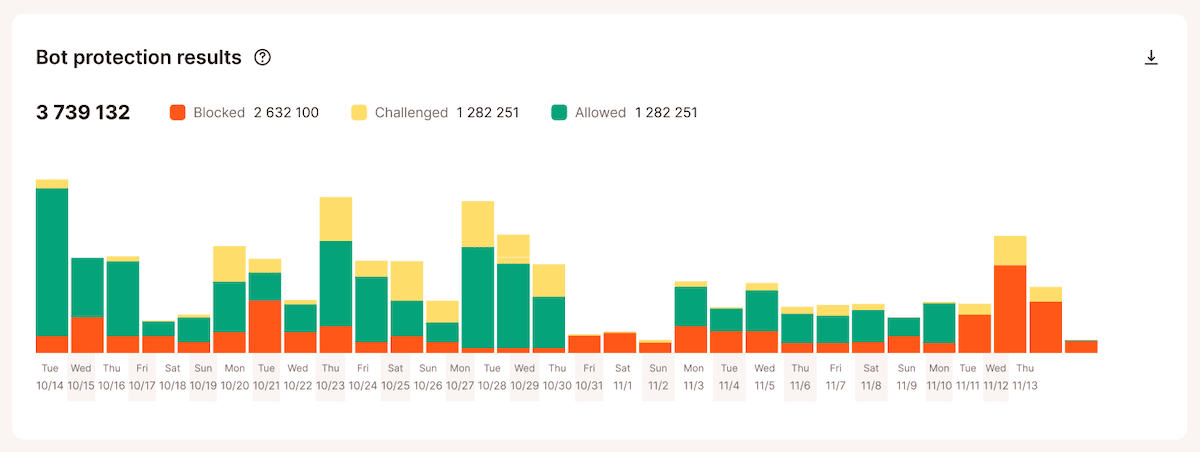
Le rapport Requêtes les plus fréquentes par nombre de vues dans Analyses permet également d’identifier les points de terminaison exacts qui reçoivent le plus grand volume de requêtes. Un ensemble de requêtes répétées vers des chemins non mis en cache, tels que les URL « add-to-cart », les pages de produits filtrées, les requêtes de recherche et les points de terminaison de commande, indique généralement que des robots consomment des ressources serveur que le cache ne peut pas absorber.

Ensemble, ces analyses constituent le moyen le plus clair de mettre en corrélation les modèles de trafic et l’utilisation des ressources avant de décider du niveau de protection à appliquer.
Fonctionnement de la protection Kinsta contre les robots
Les réglages de protection contre les robots dans MyKinsta opèrent au niveau de l’infrastructure. Le filtrage s’effectue avant que les requêtes n’atteignent le niveau PHP ou la base de données ; la réduction de la charge du serveur s’applique donc à l’intégralité du coût de la requête. Cela signifie qu’aucune extension n’est nécessaire et qu’aucune modification de la configuration de WordPress n’est nécessaire.
Kinsta classe le trafic entrant en combinant sa propre analyse du trafic et le système de détection des robots de niveau entreprise de Cloudflare. Les requêtes sont classées en groupes de trafic tels que les robots vérifiés, les robots potentiels, les robots d’indexation basés sur l’IA, les robots d’indexation agressifs, le trafic automatisé et les utilisateurs potentiellement humains. Le niveau de protection que vous sélectionnez détermine ensuite la manière dont chaque catégorie est traitée.
Tous les réglages de protection contre les robots se trouvent sous Sites > nom-du-site > Protection contre les robots.
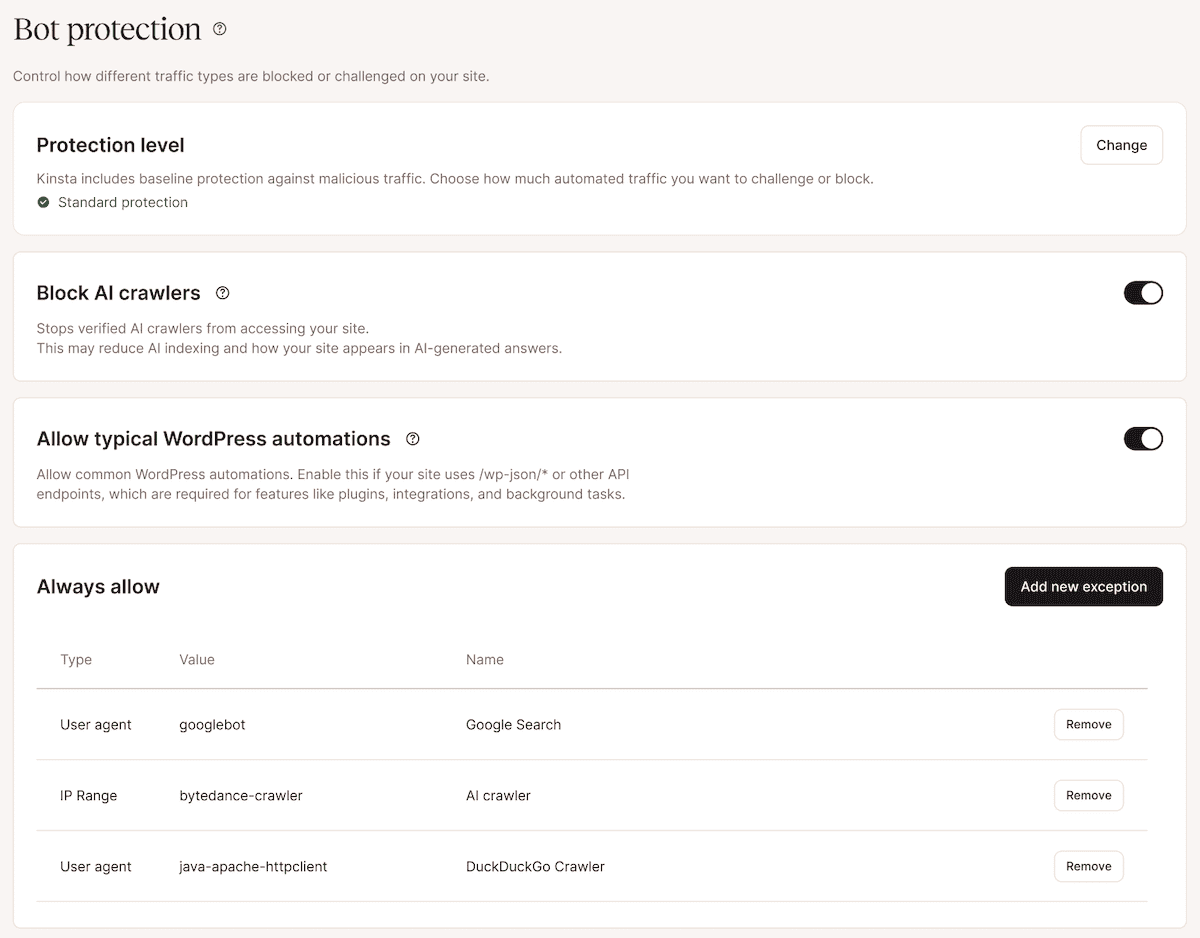
L’écran Protection contre les robots comporte quatre éléments principaux :
- Les niveaux de protection qui déterminent si le trafic est autorisé, soumis à une vérification ou bloqué.
- Un bouton distinct permettant de bloquer les robots d’indexation basés sur l’IA.
- Des réglages permettant d’autoriser les automatisations WordPress courantes pour les API WordPress courantes et les fonctionnalités en arrière-plan.
- Autoriser systématiquement les exceptions pour les sources de trafic de confiance.
Dans le cadre de l’intégration de Cloudflare par Kinsta, l’infrastructure sous-jacente d’évaluation et de vérification des robots est de niveau entreprise par défaut.
Choix d’un niveau de protection
Vous avez le choix entre quatre niveaux dans le panneau Niveau de protection de l’écran Protection contre les robots :
- Bloquer le trafic malveillant est le réglage par défaut sur tous les sites Kinsta. Il gère l’atténuation des attaques DDoS et bloque le trafic provenant d’adresses IP et de points de terminaison associés à des sources d’attaques connues.
- Bloquer les automatisations étend l’option par défaut pour bloquer également le trafic automatisé confirmé, tout en laissant les visiteurs humains et ceux susceptibles d’être humains intacts.
- Défier les robots bloque le trafic automatisé et malveillant tout en ajoutant une étape de vérification pour les robots potentiels. Les visiteurs qui réussissent ce test ne sont plus soumis à cette vérification pendant dix jours sur le même navigateur et la même adresse IP. Notez que les tests basés sur CAPTCHA peuvent s’avérer difficiles pour les visiteurs utilisant des technologies d’assistance, ce qu’il convient de prendre en compte pour les sites soumis à des exigences d’accessibilité.
- L’option Défier tout le monde applique également des défis aux visiteurs probablement humains, ce qui la rend plus adaptée à une utilisation à court terme lors d’un pic de trafic qu’à un paramétrage permanent.
Pour modifier le niveau, rendez-vous dans Sites > sitename > Protection contre les robots, puis cliquez sur le bouton Modifier. Vous pouvez également appliquer une modification à plusieurs sites à la fois en vous rendant dans Sites, en sélectionnant les sites concernés, puis en utilisant Actions > Modifier la protection contre les robots.

Le passage au niveau Défier les robots ou à un niveau supérieur peut affecter les outils qui se connectent à votre site par programmation. Tout service ne figurant pas dans le répertoire des robots vérifiés de Cloudflare sera bloqué ou soumis à une vérification à ces niveaux.
Autoriser les automatisations WordPress courantes
Certaines fonctionnalités de WordPress reposent sur des requêtes automatisées pour fonctionner normalement. Cela inclut des fonctionnalités telles que l’API REST de WordPress, les tâches planifiées en arrière-plan, les intégrations d’extensions, les outils de référencement, les formulaires, les connexions aux outils d’analyse et les services de synchronisation.
Le réglage Autoriser les automatisations WordPress courantes permet de préserver ces flux de travail WordPress courants tout en continuant à filtrer le trafic automatisé indésirable. Cela permet de réduire le risque de blocage de fonctionnalités légitimes lorsque vous utilisez des niveaux de protection plus stricts.

Si votre site dépend d’intégrations personnalisées ou de services tiers, il est tout de même recommandé de tester les fonctionnalités critiques après avoir activé des paramètres de protection plus stricts.
Blocage des robots d’indexation IA
Le bouton Bloquer les robots d’exploration IA cible les robots d’exploration IA qui collectent du contenu à des fins d’entraînement de modèles, de génération augmentée par la récupération et de fonctionnalités de recherche basées sur l’IA. Il bloque ces robots, y compris ceux qui ont été vérifiés tels que GPTBot, mais n’affecte pas les robots d’exploration des moteurs de recherche. Googlebot et Bingbot continuent d’explorer et d’indexer votre site, que le bouton soit activé ou désactivé.
Pour l’activer, rendez-vous dans Sites > sitename > Protection contre les robots, puis cliquez sur le curseur situé à côté de Bloquer les robots d’exploration IA. Pour plusieurs sites, utilisez Actions > Modifier le blocage des robots d’exploration IA depuis la vue Sites.
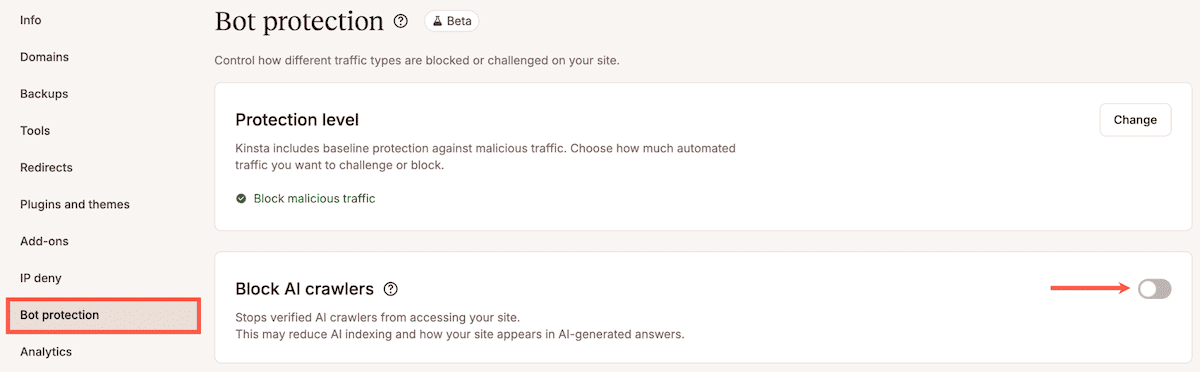
Pour les sites où vous soupçonnez que le volume de robots d’exploration IA a un impact d’après vos données d’analyse, ce bouton permet de les supprimer sans affecter la visibilité dans les moteurs de recherche traditionnels. Cependant, cela s’accompagne d’une visibilité réduite dans les aperçus IA et les résumés de contenu.
Les robots d’exploration bloqués par ce commutateur alimentent les systèmes qui mettent en avant le contenu dans les réponses et recommandations générées par l’IA. Pour les stratégies de contenu qui reposent sur cette visibilité, veillez à surveiller l’impact avant de laisser le commutateur activé de manière permanente.
Créer des exceptions avec Toujours autoriser
La section Toujours autoriser vous permet de créer des exceptions pour le trafic qui ne doit jamais être bloqué ou remis en cause par la protection anti-robots.
Cette fonctionnalité est utile pour les intégrations de confiance, les services de surveillance, les systèmes de déploiement, les API internes ou certains visiteurs qui ont besoin d’un accès ininterrompu à votre site.
Vous pouvez créer des exceptions en fonction :
- Des adresses IP ou des plages d’adresses IP
- Des chemins d’accès ou des points de terminaison
- Des agents utilisateur
Par exemple, vous pouvez ajouter un service de surveillance à la liste autorisée, exempter un point de terminaison API personnalisé des vérifications d’authentification, ou vous assurer qu’un workflow de déploiement continue de fonctionner normalement même avec des niveaux de protection plus stricts.
Les exceptions s’appliquant avant l’application des règles de protection, elles doivent être utilisées avec prudence et revues périodiquement afin d’éviter de contourner involontairement les mesures de sécurité.
Cesser d’allouer de la bande passante au trafic qui ne renvoie rien
Le trafic de robots non géré génère une charge serveur que l’optimisation du code ne peut pas résoudre, car il arrive avant que le cache ne puisse l’absorber. Ce trafic consomme des threads PHP et des connexions à la base de données à chaque requête.
La solution ne consiste pas à bloquer toute automatisation, mais à filtrer de manière sélective le trafic qui gaspille des ressources, tout en autorisant les robots et les services dont votre site dépend.
Si vous souhaitez mieux contrôler la manière dont le trafic automatisé est géré sur votre site, la protection anti-robots de Kinsta vous offre les outils nécessaires pour surveiller, classer, vérifier et bloquer le trafic indésirable directement depuis MyKinsta.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

