
Le stockage persistant fait référence à la conservation des données de manière non volatile, de sorte qu’elles restent disponibles même après la mise hors tension ou le redémarrage d’un appareil ou d’une application. Le stockage et la récupération des données permettent aux applications web de sauvegarder les informations et les états de l’utilisateur et de fonctionner de manière fiable.
Dans les applications monolithiques, l’accès au stockage est simple car le serveur et le stockage cohabitent. Cependant, les systèmes distribués géographiquement rendent l’accès plus complexe, car le système de stockage doit rester disponible pour tous les composants dans le monde entier.
La conteneurisation complique encore le problème, car les conteneurs sont légers, sans état et éphémères – des caractéristiques qui ne conviennent pas au stockage de données. Par conséquent, toute solution de stockage persistant doit pouvoir fonctionner de manière transparente avec les conteneurs, ce qui ajoute une nouvelle couche de complexité.
La plateforme d’hébergement d’applications conteneurisées de Kinsta utilise les volumes persistants de Kubernetes pour associer le stockage persistant à un ou plusieurs processus d’une application. Les utilisateurs de Kinsta peuvent définir leurs pré-requis en matière de stockage persistant lors de la création d’applications au sein du tableau de bord MyKinsta.
Cet article se penche sur le stockage persistant en explorant ses types, son architecture et ses cas d’utilisation. Il propose également une démonstration pratique illustrant la différence entre le stockage en volume et le stockage en volume persistant dans Docker.
Types de stockage persistant
Il existe plusieurs types de stockage non volatile, notamment les disques rotatifs traditionnels (disques durs ou HDD), les disques durs à semi-conducteurs (SSD), le stockage en réseau (NAS) et les réseaux de stockage (SAN).
- Les disques durs sont des dispositifs de stockage de données électromécaniques qui stockent et récupèrent des données numériques à l’aide de disques magnétiques en rotation. Les disques utilisent des têtes magnétiques sur un bras actionneur mobile qui lit et écrit les données.
- Les disques SSD, parfois appelés dispositifs de stockage à semi-conducteurs, dispositifs à semi-conducteurs ou disques à semi-conducteurs, utilisent des assemblages de circuits intégrés pour stocker des données de manière persistante, généralement à l’aide de dispositifs flash interconnectés ne contenant aucune pièce mobile. Leur nature stationnaire les rend plus rapides et plus fiables que les disques durs.
- Le stockage en réseau est un groupe de disques durs, de disques SSD, ou les deux, connectés via un réseau local à l’aide d’un système de fichiers tel que le New Technology File System (NTFS) ou le quatrième système de fichiers étendu (EXT4).
- Les SAN sont des périphériques de stockage en réseau à grande vitesse et au niveau des blocs, comme les bibliothèques de bandes ou les baies de disques. Leur connexion apparaît au système d’exploitation comme un stockage local et n’est pas accessible via le réseau local (LAN).
Architecture du stockage persistant
Il existe trois approches du stockage persistant, chacune ayant des cas d’utilisation et des limites qui lui sont propres.
Architecture persistante objet
L’approche de l’architecture persistante objet utilise le mappage objet-relationnel (ORM) pour stocker les données en tant qu’objets dans une base de données relationnelle ou clé-valeur. Cette approche est utile lorsque les données n’ont pas de schéma défini, car l’ORM gère leur stockage et leur récupération.
Architecture persistante en bloc
L’architecture persistante en bloc utilise des dispositifs de stockage au niveau du bloc, qui sont utiles pour le stockage de fichiers volumineux. Cette approche est avantageuse pour le stockage de grandes quantités de données, car vous pouvez utiliser plusieurs blocs pour augmenter la capacité de stockage.
Architecture persistante à base de fichiers
Comme son nom l’indique, l’approche de l’architecture persistante à base de fichiers utilise un système de fichiers pour stocker les données. Une méthode consiste à utiliser des serveurs de base de données, qui fournissent un moyen centralisé de stocker les données. Les solutions d’hébergement cloud comme celle de Kinsta utilisent des serveurs de base de données qui sont facilement attachés aux applications et offrent une persistance.
L’architecture persistante à base de fichiers est utile dans les applications nécessitant une récupération fréquente des fichiers et lorsque vous avez besoin d’une interface pour les gérer.
Cas d’utilisation du stockage persistant
Cette section aborde certains des cas d’utilisation de chaque type de stockage.
Stockage persistant d’objets
- Stockage dans le cloud : Le stockage persistant d’objets est couramment utilisé dans les solutions de stockage dans le cloud pour stocker et récupérer de grandes quantités de données non structurées, telles que des images, des vidéos et des documents. Les fournisseurs de cloud utilisent le stockage objet pour offrir à leurs clients des services de stockage évolutifs, hautement disponibles et durables.
- Analyse de données massives (big data) : Le stockage objet persistant est utilisé dans l’analyse des big data pour stocker et gérer de grands ensembles de données souvent utilisés pour l’analyse des données, l’apprentissage automatique et l’IA. Le stockage objet permet d’accéder aux données rapidement et efficacement, ce qui en fait un composant clé des architectures big data.
- Réseaux de diffusion de contenu : Le stockage persistant d’objets est utilisé dans les réseaux de diffusion de contenu (CDN) pour stocker et distribuer du contenu, tel que des images, des vidéos et des fichiers statiques, à travers un réseau mondial de serveurs. Le stockage d’objets permet aux CDN de fournir des contenus à haut débit aux utilisateurs du monde entier, quelle que soit leur localisation.
Stockage persistant en bloc
- Calcul haute performance (HPC) : Les environnements HPC permettent un traitement rapide et efficace de volumes importants de données. Le stockage persistant par blocs permet aux clusters HPC de stocker et d’extraire de grands ensembles de données, tels que des simulations scientifiques, des modélisations météorologiques et des analyses financières. Le stockage en bloc est souvent privilégié pour le calcul intensif parce qu’il offre un accès aux données très performant et à faible latence, et permet des opérations d’entrée/sortie (E/S) parallèles, ce qui peut améliorer considérablement les temps de traitement.
- Montage vidéo : Les applications de montage vidéo nécessitent un accès performant et à faible temps de latence à des fichiers vidéo volumineux. Elles doivent également prendre en charge un grand nombre d’opérations d’entrée/sortie par seconde et une faible latence pour rendre et modifier les fichiers vidéo en temps réel. Le stockage en bloc offre ces capacités, ce qui en fait une solution idéale pour les flux de travail de l’édition vidéo.
- Jeux : Les applications de jeux exigent également des performances élevées et une faible latence pour accéder aux ressources des jeux et aux données des joueurs. Le stockage en bloc permet de stocker et d’extraire rapidement de grandes quantités de données, ce qui garantit que les environnements de jeu se chargent rapidement et restent réactifs pendant le jeu.
Stockage persistant à base de fichiers
- Médias et loisirs : Les applications de montage vidéo, d’animation et de rendu utilisent couramment le stockage persistant. Ces applications nécessitent un accès performant et à faible latence aux fichiers multimédias volumineux, tels que les vidéos, les fichiers audio et les images. Cela fournit un système de fichiers partagé auquel plusieurs clients peuvent accéder, ce qui en fait une solution de stockage idéale pour ces applications.
- Gestion de contenu web : Les systèmes de gestion de contenu (CMS) utilisent le stockage persistant à base de fichiers dans des systèmes de fichiers partagés pour stocker et gérer le contenu des sites web, tel que le texte, les images et les fichiers multimédias. Cela fournit un emplacement central pour le contenu du site web, ce qui facilite sa gestion et sa mise à jour. Cela permet également à plusieurs utilisateurs de travailler simultanément sur le même contenu, ce qui améliore la collaboration et la productivité.
Stockage persistant dans des conteneurs
Les conteneurs sont légers, portables, sûrs et simples, et offrent une fusion entre différentes applications. Ils doivent disposer d’un mécanisme permettant de conserver les données entre les redémarrages et les suppressions de conteneurs. Les conteneurs disposent d’un stockage de fichiers ou d’un système de fichiers comme les applications traditionnelles, mais chaque fois que vous les reconstruisez avec de nouvelles modifications, vous perdez toutes les données non persistantes.
C’est pourquoi les conteneurs offrent la possibilité d’inclure le stockage en volume ou de monter un volume de stockage. Les conteneurs traitent les volumes de stockage comme un répertoire. Toutes les données écrites sur le volume vont dans le système de fichiers de l’hôte.
Le stockage persistant pour les conteneurs doit fonctionner de cette manière car le redémarrage d’un conteneur crée une nouvelle instance et supprime l’ancienne. Si un conteneur n’a pas une vue cohérente des données, celles-ci disparaîtront lorsque le conteneur redémarrera. Un volume de stockage préserve les données à travers les sessions et les redémarrages de conteneurs, ce qui permet au conteneur de conserver son état même s’il est déplacé ou redémarré.
Volume vs volume persistant
Les conteneurs offrent deux façons de stocker des données persistantes : en utilisant des volumes et des volumes persistants. Il existe une différence importante entre les deux. Un conteneur gère les données dans le stockage en volume. Lorsque vous arrêtez un conteneur, les données sont conservées et sont disponibles lorsque vous redémarrez le conteneur. En revanche, lorsque vous supprimez ou retirez un conteneur, les données sont perdues car vous supprimez également le volume de stockage sous-jacent.
Le stockage en volume persistant ou les montages bind sont un moyen de stocker les données en dehors du système de fichiers du conteneur. Ainsi, les données ne sont pas perdues, même si vous supprimez le conteneur. Elles sont persistantes jusqu’à ce qu’elles soient supprimées manuellement.
La section suivante présente les deux types de volumes à l’aide d’exemples.
Démonstration du stockage persistant d’un conteneur
Nous avons créé une petite application web pour démontrer le stockage persistant avec les conteneurs Docker. Vous pouvez suivre cette démonstration en installant Docker et en téléchargeant le code à partir de ce dépôt GitHub.
L’application est un formulaire élémentaire avec 2 champs pour l’entrée de l’utilisateur :
- Title
- Document text
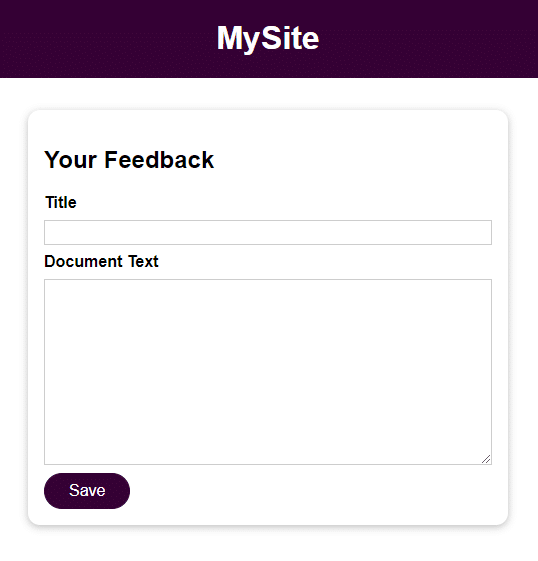
Une fois que vous avez enregistré les données de l’utilisateur, vous pouvez y accéder en ouvrant le fichier dans le répertoire feedback avec le nom fourni dans le champ Title. Les données saisies dans le champ Document Text constituent le contenu du fichier.
Comment utiliser le stockage en volume
Une fois que vous avez installé l’application sur votre propre machine, elle peut utiliser le stockage en volume comme indiqué dans le Dockerfile.
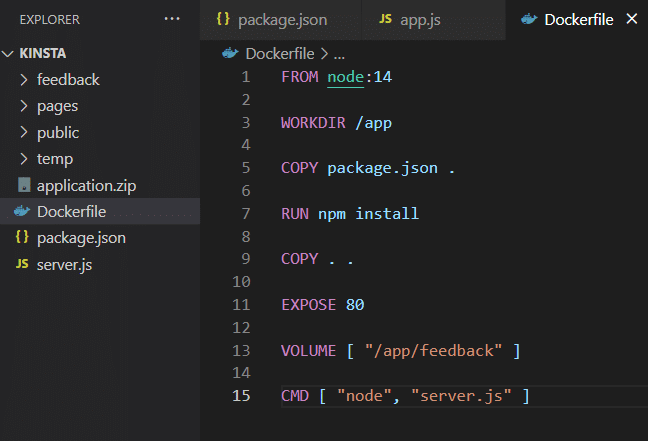
Vous devez maintenant construire l’image et exécuter le conteneur. Pour ce faire, exécutez les commandes suivantes.
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app feedback-node:volumes
Une fois l’application exécutée, naviguez vers localhost:3000 pour soumettre vos commentaires.
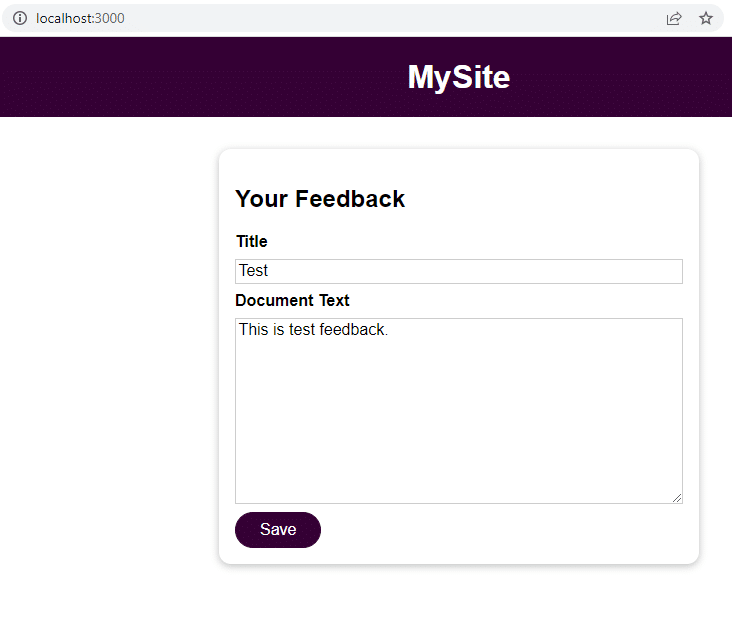
Cliquez sur Save et accédez à localhost:3000/feedback/test.txt pour voir si l’entrée a été stockée avec succès ou non.
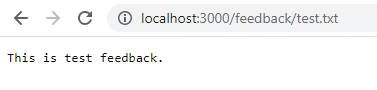
Retirez le conteneur et redémarrez-le pour voir si l’entrée persiste.
docker stop feedback-app
docker start feedback-appSi vous visitez maintenant la même URL, vous constatez que le retour d’information est toujours présent. Mais que se passe-t-il si vous retirez le conteneur et le redémarrez ?
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app feedback-node:volumesUne fois redémarré, si vous revenez à cette URL, elle n’existe plus car les données ont été perdues lorsque vous avez retiré le conteneur. Les données de volume ne persistent que lorsque vous arrêtez le conteneur, pas lorsque vous le retirez.
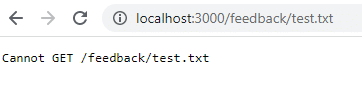
Pour atténuer ce problème et conserver les données même lorsque vous retirez le conteneur, vous devez utiliser le stockage en volume persistant ou le stockage nommé. Tout d’abord, vous devez nettoyer les conteneurs et les images.
docker stop feedback-app
docker rm feedback-app
docker rmi feedback-node:volumesComment utiliser le stockage en volume persistant
Avant de tester cette méthode, vous devez supprimer l’attribut VOLUME du fichier Docker et reconstruire l’image.
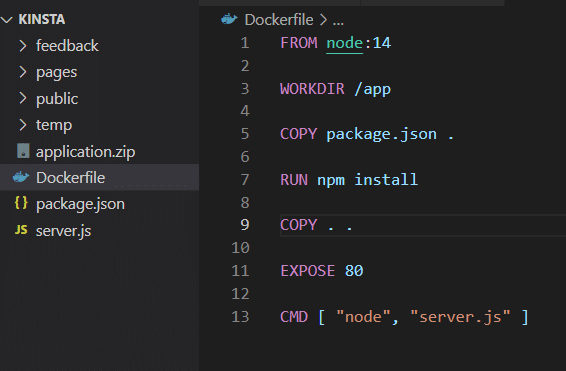
docker build -t feedback-node:volumes .
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesComme vous pouvez le voir, dans la deuxième commande, vous utilisez le drapeau -v pour définir le volume persistant à l’extérieur du conteneur, qui persiste même lorsque vous retirez le conteneur.
Comme à l’étape précédente, essayez d’ajouter un retour d’information et d’y accéder une fois que vous avez arrêté, supprimé et redémarré le conteneur.
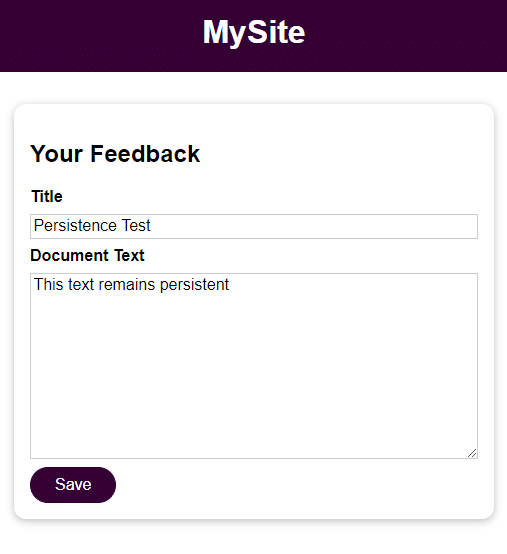
docker stop feedback-app
docker rm feedback-app
docker run -d -p 3000:80 --name feedback-app -v feedback:/app/feedback feedback-node:volumesComme vous le voyez, même après avoir arrêté et retiré le conteneur, les données sont accessibles et demeurent.
Résumé
Le stockage persistant est vital pour les applications conteneurisées car il permet de conserver les données en dehors du cycle de vie d’un conteneur. Les deux principaux types de stockage persistant pour les applications conteneurisées sont les volumes et les montages bind, chacun ayant ses avantages et ses cas d’utilisation.
Les volumes sont stockés dans le système de fichiers du conteneur, tandis que les montages bind sont directement accessibles sur la machine hôte.
Le stockage persistant permet de partager les données entre les conteneurs, ce qui rend possible la création d’applications complexes à plusieurs niveaux. Le stockage persistant est essentiel pour assurer la stabilité et la continuité des applications conteneurisées, en fournissant un moyen fiable et flexible de stocker des données cruciales.
Vous développez une application qui nécessite un stockage persistant ? Parcourez notre bibliothèque d’exemples de démarrage rapide pour voir comment déployer votre application sur Kinsta depuis des hébergeurs Git comme GitHub, GitLab et Bitbucket.
Notre documentation officielle sur le stockage persistant vous aidera à obtenir rapidement votre application et ses données en ligne.

Steve Bonisteel est un rédacteur technique chez Kinsta qui a commencé sa carrière d'écrivain en tant que journaliste de presse écrite, chassant les ambulances et les camions de pompiers. Il couvre les technologies similaires à l'Internet depuis la fin des années 1990.

