
Au cours de l’année écoulée, le trafic des robots est passé d’un phénomène que les propriétaires de sites pouvaient ignorer à un phénomène qui affecte directement le comportement de l’infrastructure. Ce changement n’est pas seulement une question de volume. Il s’agit de la façon dont le trafic automatisé interagit avec les sites web modernes, en particulier les boutiques WooCommerce.
À première vue, une requête n’est rien d’autre qu’une requête. Mais toutes les requêtes ne sont pas égales, et WooCommerce rend cette différence encore plus claire.
Dans cet article, vous verrez pourquoi les sites WooCommerce sont plus sensibles au trafic des robots, ce qui se passe sous le capot lorsque les robots atteignent des points de terminaison clés, et pourquoi les hypothèses courantes sur le trafic et les performances ne tiennent pas la route dans un contexte de commerce électronique.
Pourquoi WooCommerce transforme le trafic en charge de travail
Sur un site WordPress typique, la plupart des pages sont mises en cache à la périphérie sur un CDN comme Cloudflare, de sorte que les requêtes sont servies sans engager le serveur d’origine. Même pour des volumes plus importants, le coût reste relativement faible car le système est optimisé pour réutiliser les données mises en cache.
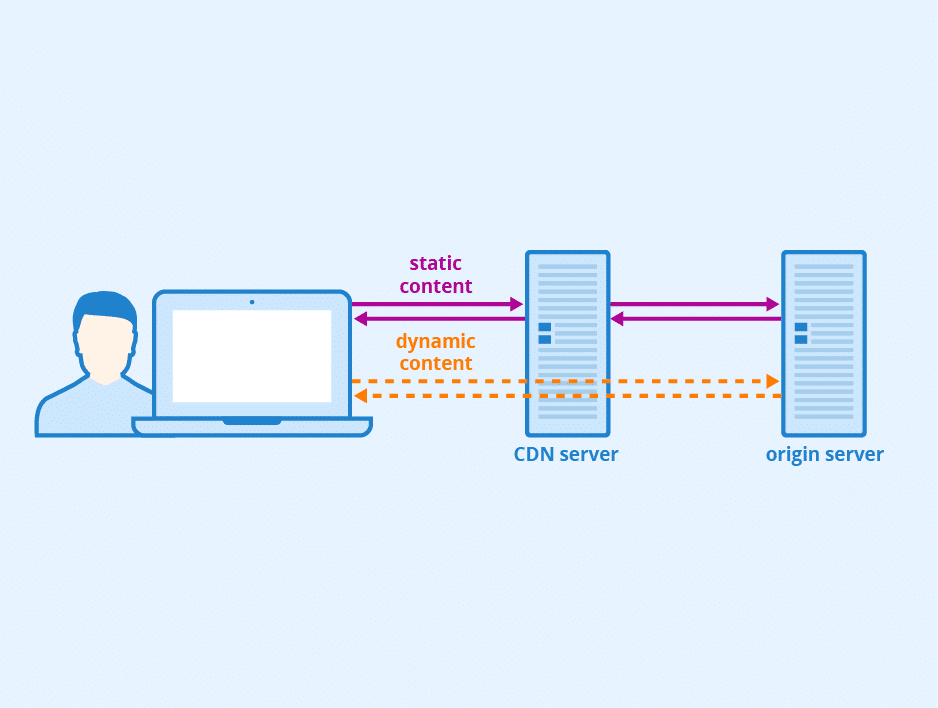
WooCommerce fonctionne différemment. Une grande partie des requêtes dépendent de données en temps réel et d’un contexte spécifique à l’utilisateur et ne peuvent pas être servies à partir du cache. Chaque requête doit être traitée sur le serveur d’origine à partir de zéro. Cela inclut :
- L’exécution de PHP pour gérer la logique de la requête
- L’interrogation de la base de données pour les produits, les prix ou les données de session
- L’élaboration dynamique de la réponse avant de la renvoyer
L’exécution de PHP pour chaque demande occupe un thread PHP pendant la durée du processus, et le nombre de threads disponibles pour chaque site est limité. Une fois qu’ils sont tous utilisés, les nouvelles requêtes doivent attendre. Il se peut également que votre site atteigne régulièrement la limite de threads PHP.
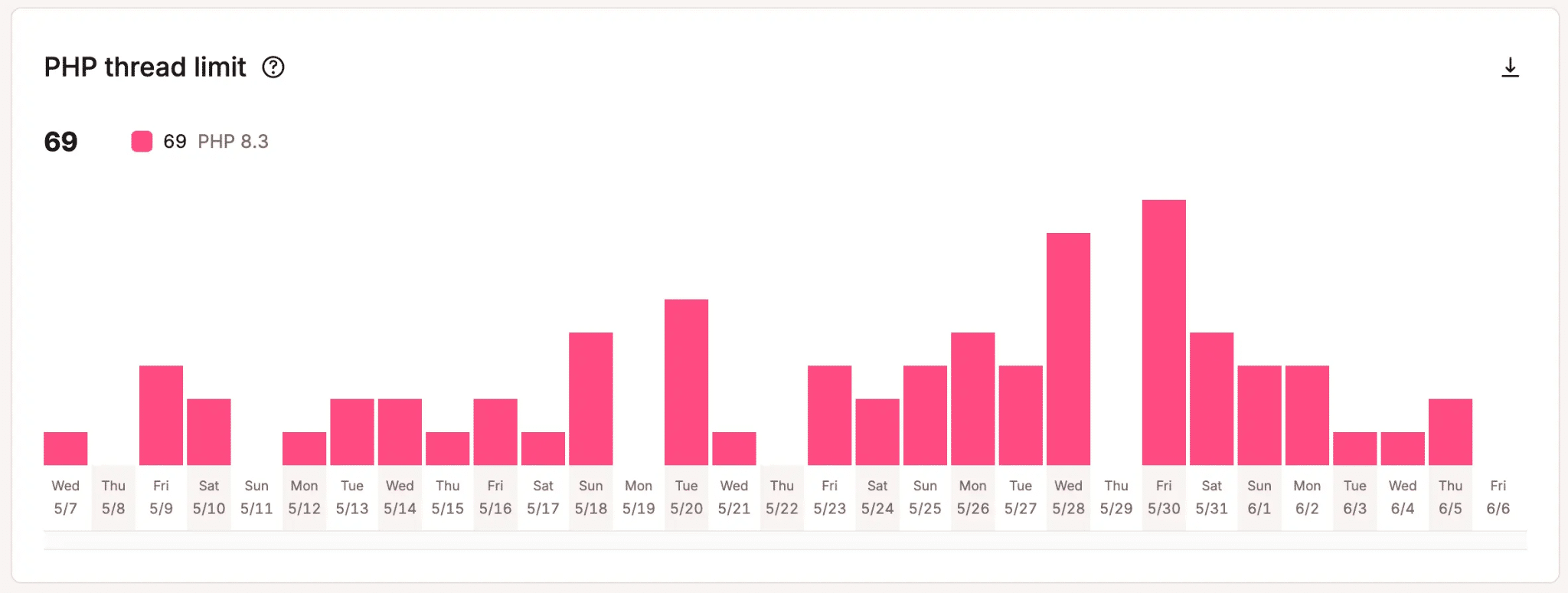
Dans le même temps, la base de données est interrogée sur les données et les informations de session. La gestion de la session se fait également en arrière-plan.
Même avant de prendre en compte le comportement des robots, il est clair que les requêtes WooCommerce sont intrinsèquement coûteuses. Une fois que le trafic automatisé entre en jeu, ce coût s’accroît.
Là où les robots causent le plus de dégâts sur les sites WooCommerce
L’impact du trafic de robots sur les sites WooCommerce tend à se concentrer sur un petit ensemble de points de terminaison conçus pour les interactions avec les utilisateurs réels.
Ce sont les parties du site où les requêtes sont les plus coûteuses et les moins bien mises en cache :
- Les points de terminaison du panier et de la commande (
/cart,/checkout,?add-to-cart=) - Requêtes de recherche
- Pages de produits filtrées et basées sur des réglages
- Interactions et composants dynamiques pilotés par AJAX
Chacun de ces éléments se comporte différemment, mais chaque requête déclenche un traitement réel sur le serveur.
Les points de terminaison au panier et à la commande sont les exemples les plus évidents. Une requête vers /cart ou tout ce qui implique ?add-to-cart= déclenche une logique d’application pour valider la session, mettre à jour le statut du panier, interroger les données des produits et préparer une réponse spécifique. Lorsque ces opérations se répètent à grande échelle, elles consomment rapidement les ressources du serveur.
Dans notre rapport récemment publié, « The AI & bot traffic reality check », notre équipe d’ingénieurs a constaté que plus de sept millions de requêtes de robots ont atteint des URL d’ajout au panier sur l’infrastructure Kinsta en 24 heures.
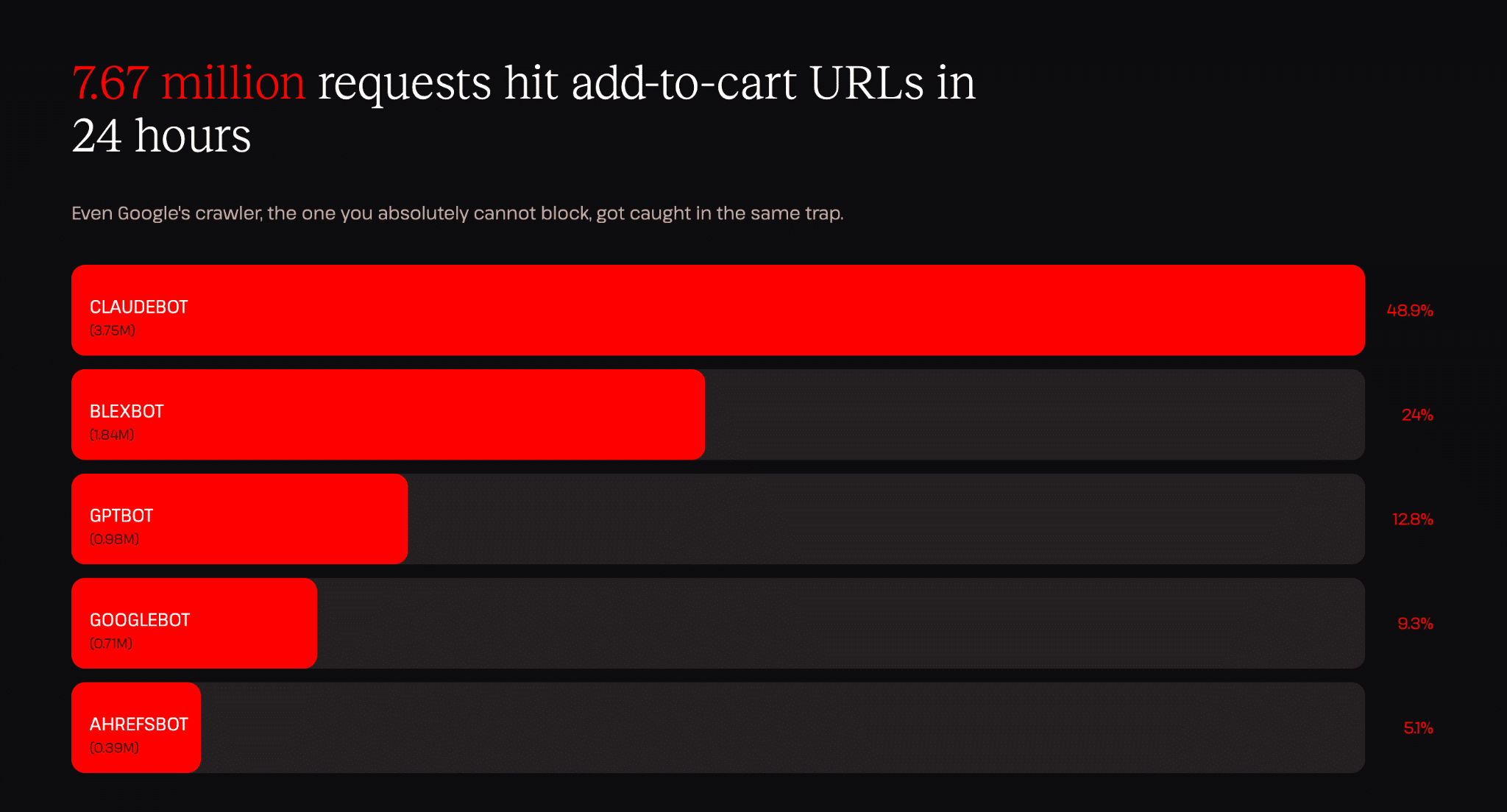
Pour mettre les chiffres en perspective, 3,75 millions de requêtes en 24 heures de la part de ClaudeBot représentent environ une requête toutes les 23 millisecondes (toute la journée et toute la nuit), chacune étant traitée comme une nouvelle requête.
Outre les points de terminaison du panier et de la caisse, la recherche et le filtrage introduisent également un autre type de pression. Les boutiques WooCommerce permettent souvent aux utilisateurs de filtrer les produits en fonction d’attributs tels que le prix, la catégorie, la taille ou la disponibilité. Chaque combinaison crée une URL légèrement différente et, du point de vue d’un robot d’indexation, chaque variation mérite d’être explorée.
Dans notre rapport, nous avons constaté que le meta-externalagent (Facebook/Meta AI crawler) était bloqué sur les pages de comparaison de WooCommerce et tournait en boucle dans des variations sans signification sur les pages de calendrier pendant des jours.
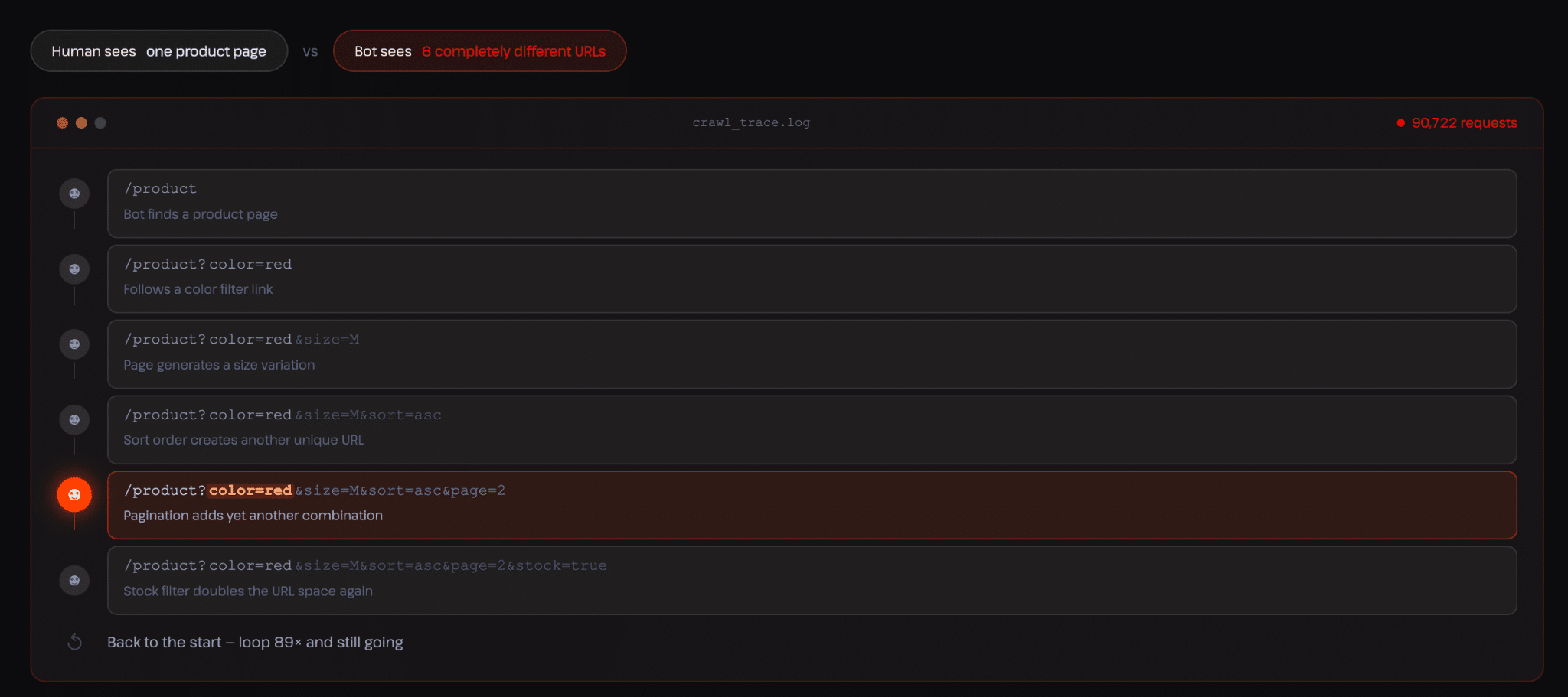
Cela se produit parce que les robots d’indexation ne comprennent pas le contexte. Le crawler suit la première variation, puis découvre une autre version légèrement différente, puis une autre, et continue d’étendre son chemin. À aucun moment, il ne se rend compte qu’il visite en fait la même page à plusieurs reprises.
Sur les sites WooCommerce, cela devient particulièrement problématique parce que beaucoup de ces variations sont liées à des fonctionnalités dynamiques.
Pourquoi le trafic de robots ne ressemble pas à une attaque (mais se comporte comme telle)
L’une des raisons pour lesquelles il est facile d’ignorer ce problème est qu’il ne ressemble pas à une attaque malveillante.
Lorsqu’une attaque malveillante se produit, vous remarquez des pics provenant d’une source unique avec des signes évidents d’abus et éventuellement des charges utiles malveillantes, mais avec le trafic de robots, les requêtes semblent normales parce qu’elles suivent la structure du site, accèdent à des URL valides et reçoivent des réponses valides.
De l’extérieur, cela ressemble souvent à une activité d’exploration légitime, mais le système n’évalue pas l’intention. Il se contente de traiter les requêtes.
Lorsque des robots d’exploration inefficaces ou peu performants fonctionnent à grande échelle, ils créent des schémas qui ressemblent à des abus, même si ce n’était pas l’objectif initial. Les requêtes répétées, les boucles et l’accès très fréquent à des points de terminaison dynamiques se traduisent tous par une charge de travail soutenue pour le serveur.
C’est pourquoi la distinction entre « bons » et « mauvais » robots devient moins utile dans la pratique.
Un robot d’exploration peut être légitime et néanmoins générer des schémas de trafic qui dégradent les performances. Le problème n’est pas seulement de savoir qui fait la requête, mais ce que cette requête oblige le système à faire.
Ce que cela signifie pour les performances de WooCommerce
Lorsque ce type de trafic augmente, les effets se manifestent d’une manière qu’il est facile d’attribuer à tort.
- Les pages commencent à se charger plus lentement, en particulier lors des pics d’activité
- Les flux de commande sont retardés ou incohérents
- Dans certains cas, les requêtes commencent à être mises en file d’attente, car les workers PHP sont accaparés par la gestion d’interactions automatisées répétées
De l’extérieur, cela ressemble à un problème de performance, mais la cause sous-jacente est souvent la pression soutenue du trafic automatisé qui frappe les points de terminaison non mis en cache.
Cela affecte également la façon dont le trafic est interprété. De grands volumes de requêtes automatisées peuvent gonfler le nombre de visites sans contribuer à l’activité réelle de l’utilisateur. Un pic de trafic peut ne pas correspondre à une augmentation de l’engagement, des conversions ou des revenus. Sans visibilité sur ce qui génère ce trafic, il devient difficile de distinguer la demande réelle de la charge automatisée.
À l’échelle, cela devient à la fois un problème de performance et de décision.
Pourquoi le blocage des robots n’est pas une solution complète
Si vous n’êtes pas encore familiarisé avec le trafic des robots, votre réaction naturelle à ce type de comportement est de le bloquer. Dans certains cas, cela fonctionne. Mais dans la plupart des cas, cela crée de nouveaux compromis.
En réalité, le trafic automatisé n’est pas toujours nuisible. Les robots d’indexation des moteurs de recherche sont essentiels à la visibilité. Les robots d’IA jouent un rôle dans la manière dont le contenu est diffusé par les agents d’IA, ce que l’on appelle aujourd’hui les pratiques GEO et AEO.
Le fait de tout bloquer résout le problème du trafic, mais il en supprime également les avantages. Tout autoriser évite les perturbations, mais expose le système à une charge inutile.
Le défi est que les sites WooCommerce n’ont pas besoin d’une règle unique pour tout le trafic. Ils ont besoin d’un comportement différent en fonction de la destination de la requête et de la source du trafic.
Une façon plus pratique de penser au trafic des robots
Au lieu de se demander si les robots doivent être autorisés ou bloqués, la question la plus utile est : quels types de trafic doivent être autorisés à accéder à quelles parties du site ?
Il n’est pas nécessaire que les robots d’indexation accèdent aux points de terminaison du panier et de la commande. Les pages de recherche et les pages filtrées peuvent être limitées sans affecter les fonctionnalités de base. Parallèlement, les pages de produits et de catégories doivent rester accessibles aux moteurs de recherche.
C’est ce type de séparation qui permet de gérer le trafic des robots.
Dans notre analyse de plus de 10 milliards de requêtes à travers l’infrastructure gérée par Kinsta, ces modèles apparaissent comme des comportements récurrents sur les sites WooCommerce réels. Si vous souhaitez explorer l’ensemble des données et voir comment ces schémas évoluent sur différents types de sites, le rapport AI bot traffic fournit plus de détails.
En même temps, gérer cela manuellement est rarement pratique. Elle nécessite des ajustements de temps en temps, une visibilité claire des modèles de trafic et un moyen d’appliquer les décisions sans interrompre l’utilisation légitime. C’est exactement la lacune que l’outil de protection contre les robots de Kinsta est conçu pour résoudre, en donnant aux propriétaires de sites la possibilité de contrôler la façon dont les différents types de trafic sont traités sans s’appuyer sur des règles uniques.
N’hésitez pas à consulter notre documentation et à contacter le support si vous avez besoin de plus d’éclaircissements sur la façon dont cela peut fonctionner pour votre site ou votre agence.

Joel est un développeur d'interfaces publiques qui travaille chez Kinsta en tant que rédacteur technique. Il est un enseignant passionné par l'open source et a écrit plus de 200 articles techniques, principalement autour de JavaScript et de ses frameworks.

