
Con la sua crescente quota di mercato, WordPress è stato e continua a essere il CMS più popolare per creare, gestire e sviluppare siti web.
Tuttavia, WordPress rappresenta solo una frazione dello sviluppo effettuato sul web. E tutti gli sviluppatori che non usano WordPress? Anche loro creano, gestiscono e amministrano applicazioni web per la propria azienda, per i propri clienti, per i loro clienti o per se stessi.
Noi di Kinsta abbiamo lavorato con migliaia di sviluppatori e centinaia di agenzie i cui clienti hanno progetti costruiti su WordPress. Molti hanno anche progetti non basati sul famoso CMS.
Fino a oggi, Kinsta si è concentrata sulla creazione di soluzioni di hosting WordPress gestite, il che significa che i clienti (e i loro clienti) non erano in grado di sfruttare i vantaggi della nostra piattaforma per progetti non WordPress e di ospitare tutti i progetti sotto “un unico tetto”. Questo rendeva il loro lavoro più difficile e meno efficiente.
Abbiamo quindi iniziato a cercare un modo per semplificare la loro vita.
Più feedback ricevevamo e più parlavamo con i nostri clienti e beta tester dei loro progetti, più ci rendevamo conto che i nostri clienti stavano lottando con un unico punto dolente.
Ma c’è un colpo di scena: non erano solo i nostri clienti.
Ci siamo resi conto che questo punto dolente è vissuto da quasi tutti gli sviluppatori, i team DevOps e le agenzie che gestiscono progetti web. Tutti lottano con questo problema e sono desiderosi di trovare una soluzione migliore.
Gli Sviluppatori Non Dovrebbero Perdere Tempo a Preoccuparsi dell’Hosting, ma Concentrarsi sullo Sviluppo
Qual è il problema?
La mancanza di semplicità in una piattaforma di hosting cloud.
Gli sviluppatori vogliono distribuire le loro applicazioni velocemente. Hanno bisogno di una piattaforma che permetta loro di avere tutto in un unico posto, sotto lo stesso tetto.
Una piattaforma chiara e facile da usare in modo da non ridurre il lavoro di sviluppo ad un’unica tecnologia, framework o libreria.
Una piattaforma che non richieda corsi speciali o certificazioni per essere utilizzata, con una struttura di prezzi semplice e trasparente (avete mai provato a capire come sono strutturati i prezzi di AWS? È una sfida!).
Sapevamo che l’architettura a container di Kinsta ci avrebbe permesso di rispondere a queste esigenze e di fornire agli sviluppatori la piattaforma e gli strumenti per fare il loro lavoro al meglio.
Sapevamo di avere:
- Oltre 8 anni di esperienza nel settore dell’hosting
- Assistenza impareggiabile
- Sviluppatori e tecnici di talento in grado di risolvere qualsiasi problema
- Team DevOps, che non è secondo a nessuno quando si tratta di orchestrare, gestire e scalare la nostra piattaforma di hosting
Ecco perché abbiamo costruito le nostre nuove soluzioni di hosting sulla stessa piattaforma che rende così potenti i nostri servizi di hosting WordPress. Ora, dopo oltre un anno di duro lavoro che ha coinvolto più di 320 Kinstaniani, oltre 750 beta tester e innumerevoli iterazioni, l’abbiamo resa disponibile al pubblico.
Presentazione delle Soluzioni di Hosting di Applicazioni e Database
La visione di Kinsta è quella di cambiare lo status quo. Lo facciamo grazie al nostro forte impegno ad offrire la migliore esperienza agli sviluppatori:
Siamo in costante evoluzione per offrire strumenti e servizi all’avanguardia. Ci impegniamo per offrire la migliore esperienza a sviluppatori ed aziende, e lavoriamo per garantire il massimo delle prestazioni e della facilità d’uso.
Con l’aggiunta di nuovi servizi alla nostra offerta, sviluppatori e team DevOps di tutti i tipi e dimensioni hanno ora a disposizione una pletora di soluzioni di hosting per le loro applicazioni, database, servizi e siti WordPress, con una flessibilità mai vista.
In particolare, Kinsta offre ora:
Diamo un’occhiata più da vicino.
Hosting WordPress Gestito (in Breve)
Grazie a Google Cloud Platform e al suo Premium Tier Network, abbiamo creato un servizio di hosting WordPress gestito che fornisce a oltre 25.000 aziende e 100.000 siti web tutto ciò di cui hanno bisogno per continuare a funzionare e crescere.
Grazie all’utilizzo di CPU di altissimo livello e alla disponibilità globale delle VM C2 ottimizzate per il calcolo di Google, ai 27 data center disponibili e al velocissimo CDN Kinsta con 300 PoP per servire contenuti statici e dinamici a un pubblico distribuito a livello globale, i clienti che migrano da qualsiasi host a Kinsta notano tempi di caricamento mediamente più veloci del 20% quasi istantaneamente.
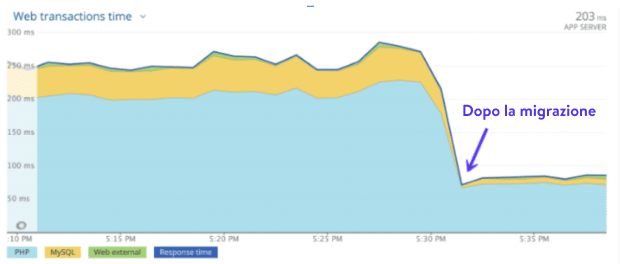
Ma i vantaggi non si fermano qui.
Grazie ai backup automatici, a MyKinsta (la nostra bacheca personalizzata e facile da usare per la gestione dei siti), allo strumento di monitoraggio delle applicazioni integrato e alla protezione firewall e DDoS di livello aziendale fornita da Cloudflare, la nostra soluzione di hosting WordPress gestito consente ai gestori e agli sviluppatori di dormire sonni tranquilli sapendo che i loro siti sono al sicuro.
Inoltre, sanno che Kinsta fa risparmiare loro ore di lavoro ogni mese. Meno tempo speso a svolgere attività ripetitive ma fondamentali significa meno spese generali e meno costi di manutenzione per la vostra azienda.
La vostra attività si basa su WordPress? Siete sviluppatrici o sviluppatori WordPress alla ricerca di un hosting con strumenti che vi aiutino a semplificare il vostro lavoro? Date un’occhiata alle nostre soluzioni di hosting WordPress gestito.
Hosting di Applicazioni (in Breve)
Lo sviluppo web sta vivendo un momento interessante che dimostra quanto questo mondo sia articolato, ricco di sfumature e complesso. La nostra nuova soluzione di Hosting di Applicazioni ottimizza il lavoro degli sviluppatori web di oggi.
Liberiamo gli sviluppatori dalla necessità di configurare i container, gestire i server, preoccuparsi del sistema operativo, della gestione dei backup, dell’installazione dei certificati SSL e dei domini personalizzati: tutto ciò che potrebbe impedirvi di concentrarvi esclusivamente sullo sviluppo.
Abbiamo creato una piattaforma di sviluppo pensata per aiutarvi a portare le vostre applicazioni agli utenti nel più breve tempo possibile.
L’Hosting di Applicazioni di Kinsta è ciò che il mercato chiama Platform-as-a-Service (PaaS), dotato di strumenti che permettono di implementare rapidamente applicazioni da servizi di code-hosting come GitHub.
Come Distribuire un’Applicazione su Kinsta
I nostri tecnici e product manager si sono concentrati per creare un processo di distribuzione semplificato che richiede solo 3 passaggi:
- Connessione all’account GitHub e selezione del repository
- Distribuzione automatica (a ogni commit) o manuale dell’applicazione
- Sviluppo, scaling, esecuzione dei processi
È tutto qui!
Non è necessario configurare le immagini dei container perché noi rileviamo e distribuiamo automaticamente le applicazioni basate su queste tecnologie:
- Node.js
- PHP
- Django
- Rails
- Java
- Scala
- Go
Nota: stiamo creando una serie di repository “Hello World” da forkare e distribuire su Kinsta per provare il servizio.
Se si preferisce avere un maggiore controllo con un’immagine Docker personalizzata, è possibile utilizzare nel repository un proprio Dockerfile. Questo permetterà di utilizzare quasi tutti i linguaggi di programmazione e framework senza essere limitati a quelli supportati dai nostri attuali Buildpack.
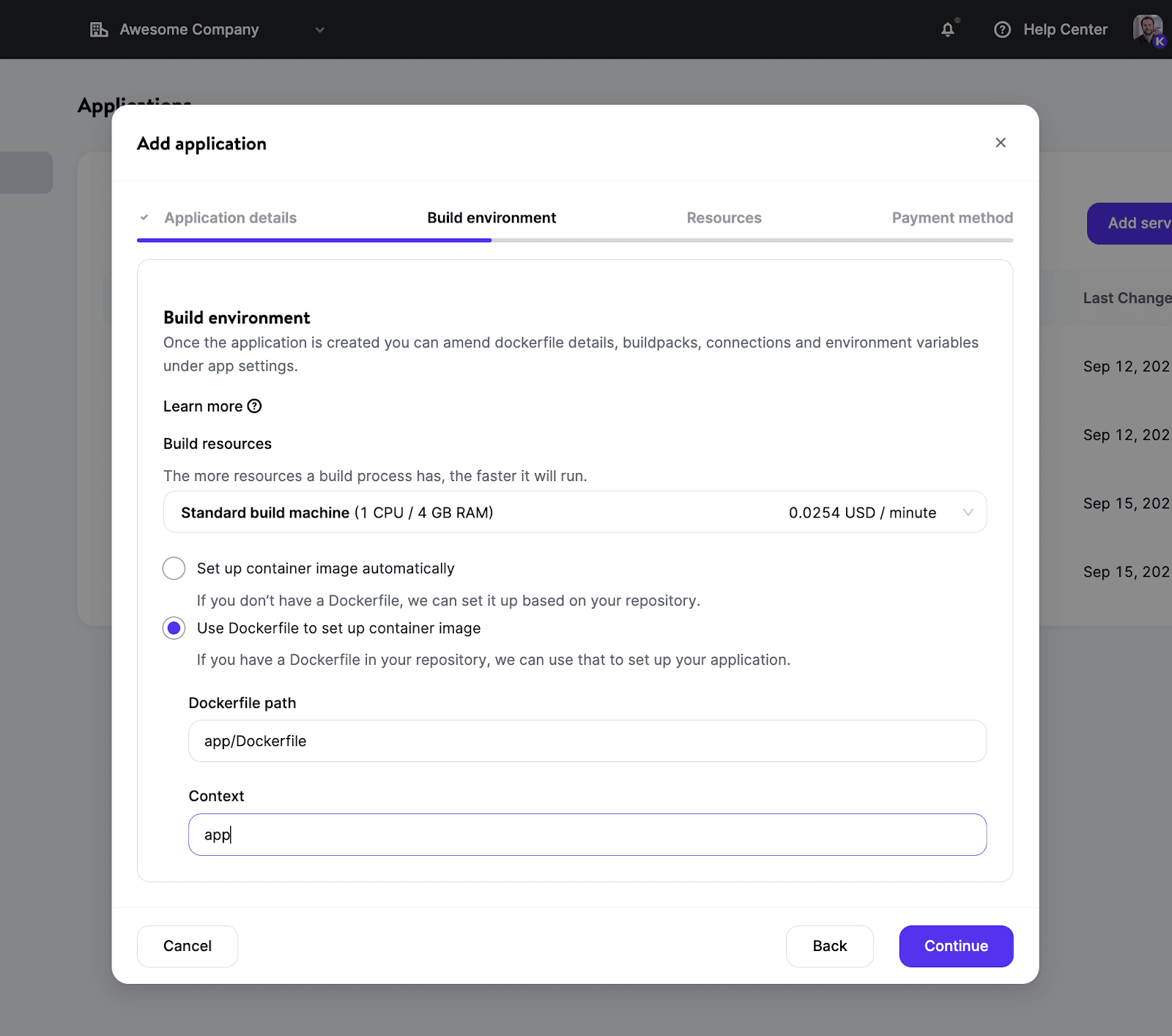
Una volta configurato l’ambiente di creazione, potrete scegliere la quantità di risorse (grazie ai diversi tipi di pod) in base alle vostre esigenze e definire il numero di istanze necessarie per scalare.
Per maggiori informazioni sulle caratteristiche del servizio, abbiamo una pubblicato ricca documentazione sull’Hosting di Applicazioni.
Potenti Strumenti di Analisi per Monitorare le Vostre Applicazioni
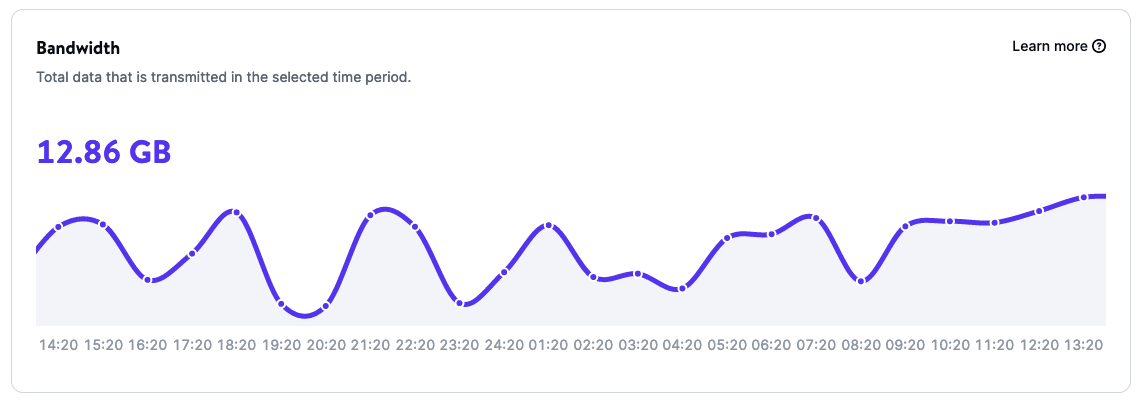
Grazie alle pagine delle statistiche delle applicazioni, è possibile ottenere rapporti sull’utilizzo delle applicazioni:
- Larghezza di banda
- Tempo di build
- Tempo di esecuzione
- Utilizzo della CPU
- Utilizzo della memoria
E i Prezzi?
I prezzi dell’Hosting di Applicazioni sono basati sulle risorse, il che significa che il costo del servizio dipende esclusivamente dal consumo di risorse. I primi 20 dollari sono a nostro carico sia per i nuovi clienti che per i clienti esistenti.
Scoprite di più sull’Hosting di Applicazioni di Kinsta e distribuire la vostra prima applicazione in uno dei nostri 24 data center.
Hosting di Database (in Breve)
I database sono una componente fondamentale di molti progetti web. Anche se ci sono applicazioni che non ne hanno bisogno, la maggior parte richiede un database.
Grazie alla soluzione di Hosting di Database di Kinsta, è possibile configurare un database con pochi clic e connettersi sia con un’applicazione ospitata da Kinsta che con un servizio esterno.
Supportiamo diversi tipi di database. Basta selezionare la versione più adatta alle caratteristiche del progetto. In particolare, troverete:
- MySQL
- MariaDB
- Redis
- PostgreSQL
E stiamo lavorando per aggiungerne altri nel prossimo futuro!
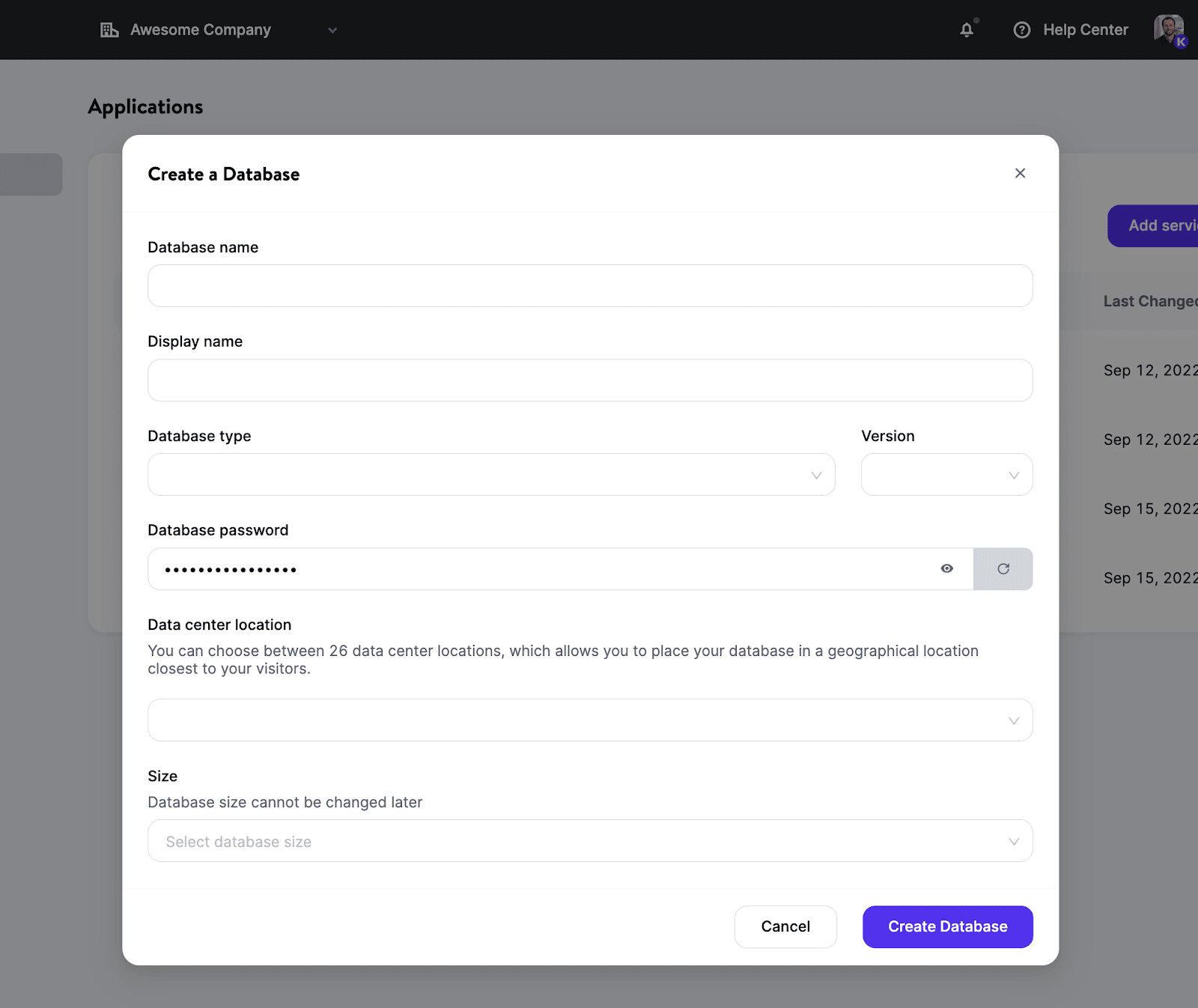
Come Distribuire un Database su Kinsta
Per configurare e rendere disponibile un nuovo database bastano pochi minuti. Non dovrete gestire server, cluster e container o preoccuparvi di altre attività di cui solitamente si occupano i DevOps.
Ecco i passaggi da seguire:
- Selezionare il tipo di database e la versione preferita.
- Scegliere un data center tra i 24 attualmente disponibili.
- Impostare le risorse del vostro database.
Voilà: avete appena creato e containerizzato un database (senza risorse condivise!) per i vostri progetti.
Se create una connessione interna tra la vostra applicazione e il vostro database, entrambi vivranno nello stesso cluster e comunicheranno attraverso una connessione sicura, che offre prestazioni migliori rispetto alle connessioni esterne.
Inoltre, non vi verrà addebitato il traffico interno, perché le richieste rimangono all’interno della stessa rete!
Per maggiori informazioni, si legga la nostra documentazione sull’Hosting di Database.
Potenti Strumenti di Analisi per Monitorare il Database
Le Statistiche del Database offrono informazioni sull’utilizzo del database:
- Archiviazione
- Tempo di esecuzione
- Utilizzo della CPU
- Utilizzo della memoria
E i Prezzi?
Come per l’Hosting di Applicazioni, l’Hosting di Database viene fatturato in base all’utilizzo e dipende dalle dimensioni e del tempo di esecuzione del database.
Provate l’Hosting di Database di Kinsta installando il vostro primo database in uno dei nostri 24 data center. E non dimenticate: il primo mese avrete uno sconto di 20 dollari.
Cosa Succederà in Futuro?
Questo è solo l’inizio della nuova era di Kinsta. I nostri team di sviluppo e di progettazione stanno lavorando sodo su nuove funzionalità, correggendo bug e valutando attentamente i feedback che ci avete fornito.
Tra le nuove soluzioni a cui stiamo lavorando, ricordiamo l’hosting di siti statici, il machine learning, le applicazioni cloud e il servizio Function-as-a-Service in ambito edge, per citarne solo alcune. Oltre a ciò, continueremo a lavorare per migliorare ancora le nostre soluzioni di Hosting WordPress Gestito e ottimizzarle con il rilascio di nuove funzionalità, come l’edge caching, che riduce il tempo medio necessario per servire l’HTML di WordPress presente nella cache di oltre il 50%!
Sono tempi fantastici per lavorare nello sviluppo web e non potremmo essere più entusiasti di ciò che ci aspetta qui da Kinsta!
Riepilogo
Ampliando le soluzioni di hosting di Kinsta, stiamo arricchendo il modo in cui supportiamo le aziende e gli sviluppatori, indipendentemente dalla tecnologia con cui lavorano. Come ha sintetizzato il Presidente del Consiglio di Amministrazione di Kinsta:
Stiamo costruendo una piattaforma in cui gli sviluppatori possono trovare tutto ciò di cui hanno bisogno per gestire un servizio web con facilità, in modo da potersi concentrare sulla creazione e sulla condivisione del loro migliore lavoro con il mondo. — Mark Gavalda, Presidente del Consiglio di Amministrazione
Per celebrare questo nuovo capitolo della storia di Kinsta, tutti i clienti, nuovi ed esistenti, possono provare il nostro Hosting di applicazioni e l’Hosting di database con uno sconto di 20 dollari sul primo mese.
Ti diamo in benvenuto nella nuova era di Kinsta, la piattaforma costruita per gli sviluppatori moderni per trasformare le idee in applicazioni reali e scalabili nel modo che avete sempre immaginato.
Semplice, veloce, trovate tutto in un unico posto.
Grazie a tutti i nostri fantastici clienti per averci affidato la loro attività e per averci sostenuto in questo viaggio!

Redattore Capo presso Kinsta e Content Marketing Consultant per sviluppatori di plugin WordPress. Entra in contatto con Matteo su Twitter.

