
何週間もかけてキャンペーンを計画し、メール配信を予約し、広告を出稿。いよいよトラフィックが増え始める時。ところがその直後、サイトの表示は徐々に遅くなり、最悪の場合は完全に停止。注文は失敗し、フォームは送信されず、アナリティクスのダッシュボードが状況を把握しきれないうちに、せっかく生まれた勢いが静かに失われていきます。
こうした事態は、サイトのダウンが収益に直結する深刻なビジネス課題であることを浮き彫りにします。売上の損失は最も分かりやすいコストですが、影響はそれだけにとどまりません。サイトが停止すれば有料広告費は無駄になり、購買意欲の高い訪問者は離れていき、ブランドへの信頼は損なわれていきます。さらに、レポートにははっきりと表れない形で、将来の成長機会を静かに奪っていく可能性も。
「サイトのダウン」とは何か─単なるオフライン以上のリスク
「サイトのダウン」とは多くの場合、サイトが完全に利用できない状態を指しますが、これにはいくつか段階があり、技術的には「稼働している」状態でも、最も深刻な被害が発生することがあります。
完全停止:サイトにアクセスできない状態
完全停止(ハードダウン)は最もわかりやすく、診断も簡単です。
- サイトがまったく読み込まれないサーバー障害
- システムのクラッシュや設定ミスによる500番台のエラー
- そもそもトラフィックがサイトに到達しないDNS障害
サイトが完全停止している間は、文字通りすべてが停止します。訪問者はコンテンツを閲覧できず、決済は失敗し、マーケティングトラフィックは行き詰まることになります。
機能停止:サイトは表示されるが、実質的に利用できない状態
機能停止(ソフトダウン)はより気づきにくく、ユーザーにとってはかえってストレスの大きいものです。サイト自体は表示されるものの、重要な操作が失敗したり、完了までに時間がかかりすぎたりします。
以下のような現象が見られます。
- ページが壊れているように感じるような深刻な遅さ
- 負荷がかかるとページがタイムアウト(特にトラフィック急増時)
- 決済、フォーム、ログイン、サブスクリプションを中断させるバックエンドの障害
稼働時間レポートではこれらの問題が必ずしも明らかではないため、社内で見落とされやすい一方で、顧客は遅延の1秒ごとに影響を実感します。
サイトのダウンとパフォーマンス障害の一般的な原因
完全停止と機能停止はいずれも、共通する根本的な原因から発生することが少なくありません。
- 限られたリソースを圧迫するキャンペーン中のトラフィックの急増
- 分離や余裕のない低性能・共用レンタルサーバー環境
- 更新中に発生したプラグインやテーマの干渉
- サーバーやネットワークにストレスを与えるインフラの問題やDDoS攻撃
こうした問題は、都合のよいタイミングで起こることはほとんどありません。むしろ、注目度や期待値が最も高まっている瞬間に表面化します。
わずかな時間のトラブルであっても、その影響は想像以上に大きくなりがちです。新商品のローンチやセールの最中に数分間表示が遅くなるだけでも、閑散時の数時間の停止より大きな損失につながることがあります。高いプレッシャーがかかる場面でパフォーマンスが低下すると、チームが状況を把握する前に、コストは一気に膨らんでいきます。
サイトのダウンによる直接的な金銭的損失
サイトが停止したりパフォーマンスが低下したりすると、その経済的影響は決して机上の話ではありません。影響は即座に現れ、数値として把握できます。多くの企業にとって最初に目に付くのは売上の損失ですが、それだけが問題というわけではありません。
以下、サイト停止によって生じる具体的なコストについて見ていきましょう。
トランザクションの損失とコンバージョンの放棄
サイトのダウンは、まさに収益を生み出す導線を直撃します。決済ページが機能しない、フォームが送信できない、重要なコンテンツが読み込まれないといった状況では、わずかな中断でも取引の機会が失われ、カゴ落ちが発生し、売上にはつながりません。
実際に、Kinstaに移行したとある会社も同様の問題を抱えていました。WordPressサイトは負荷がかかるたびに頻繁にクラッシュし、表示速度も大幅に低下し、サーバー障害のたびに売上を失っていました。Kinstaへの移行後は信頼性が大きく改善し、あるサイトでは稼働率99.98%を達成。以前は収益機会を損なっていた中断も大幅に減少しました。
キャンペーンやトラフィック急増時の機会損失
需要が急増する局面では、サイトダウンのコストはさらに跳ね上がります。キャンペーンやローンチ、有料広告の強化、季節イベントなどでは、注目度と期待値が同時に高まります。サイトがその負荷に耐えられなければ、広告費だけが消化され、クリックは発生しても収益には結びつきません。
実際、Kinstaの顧客の中にはこの状況を成果へと転換した事例もあります。たとえば、イギリスのスポーツニュースサイトは、Kinstaのスケーラブルなインフラにより、47万ページビューという過去最高のトラフィックを記録した日でも一切のトラブルなく運営を継続することができました。本来であれば高額な損失につながりかねない状況を、パフォーマンス向上の成果へと変えました。
こうした収益機会は、重要な瞬間にインフラが機能しなければ、一瞬で失われてしまいます。
金銭的影響を把握するためのシンプルな考え方
複雑なモデルを使わなくても、サイト停止がどれほど高くつくかは把握できます。シンプルな見積もり方法でも、リスクは十分に見えてきます。
平均1時間あたりの売上 × 停止時間(分)= 想定される売上損失
たとえば、大規模なプロモーション中に1時間あたり約75万円を売り上げている場合、わずか10分のパフォーマンス低下でも大きな打撃になります。そこに失われたリード、無駄になった広告費、将来的な顧客離れまで加われば、実際のコストは一気に膨らみます。
売上の損失は最も分かりやすく、数値化しやすいコストですが、それがすべてではありません。むしろ最も深刻なのは、その先に広がる影響です。サイト停止は、顧客の信頼やブランド評価、将来の売上機会といった、測定しにくい領域にまで波及します。こうした見えにくいコストこそが、信頼性を戦略的な優先事項に押し上げる理由になります。
多くの企業が見落としがちな隠れたコスト
ブランドの信頼性と信用力
サイトの信頼性は、顧客が意識していなくても、企業に対する印象を左右します。サイトが何度も停止したり、アクセス増加時に十分なパフォーマンスを発揮できなかったりすると、信頼は徐々に損なわれていきます。
特にローンチや発表、大規模なキャンペーンの最中に発生する障害は大きな打撃に。こうしたタイミングは新規訪問者にとって第一印象となることが多く、その段階でのパフォーマンス問題はブランドイメージに長く影響を残しかねません。繰り返される不安定さは、企業としての専門性や信頼性、規模感に対する疑念を生み、たとえ後に改善されたとしても、信頼を取り戻すことを難しくします。
顧客体験と解約
ユーザーの視点から見れば、サイトが完全に停止している場合と、サイトが極端に遅い場合に大きな差はありません。ページがなかなか表示されない、決済が失敗する、フォームが送信できないといった状況は、いずれも「アクセスする価値がない」という印象を与えてしまいます。
期待に応えられなければ、ユーザーは待ってはくれません。乗り換えのハードルは低く、代替手段はすぐに見つかり、競合はワンクリック先。たとえすぐに離脱しなかったとしても、こうした小さなストレスが積み重なることで解約率は高まり、いざというときに再訪してもらえる可能性も低下します。
実際、Kinstaへの移行後にページ表示速度が60%向上し、プロモーション期間中の売上が35%増加、顧客維持率も25%改善した企業もあります。
このように、顧客がサイトをどのように体験しているかに目を向けることは、決して時間や予算の無駄にはなりません。
無駄なマーケティング費用
サイトが停止しても、マーケティングの仕組みは止まりません。有料広告は配信され続け、メールキャンペーンもクリックを生み出し続けます。インフルエンサーの投稿もトラフィックを送り込みます。にもかかわらず、サイトがそのアクセスを処理できなければ、予算だけが消化され、成果にはつながりません。
無駄になるのは広告費だけではありません。社内チームは一気に対応モードへと追い込まれ、本来行うべきキャンペーンの最適化や勢いの拡大ではなく、問題の特定や影響の抑制、不満を抱えた顧客への対応に追われることになります。こうした混乱による機会損失は、あっという間に膨らんでいきます。
SEOとオーガニック流入の可視性
検索エンジンは安定した稼働を前提としています。クロールのタイミングでサイトが停止していたり表示が遅かったりすると、ページが正しくインデックスされなかったり、検索結果から外れてしまったりすることがあります。特に頻繁にコンテンツを公開しているサイトや、オーガニックトラフィックに大きく依存しているサイトでは、短時間の停止でもクロールパターンに影響を与える可能性があります。
サイトが復旧した後も、その影響は残ることが少なくありません。順位がすぐに元に戻るとは限らず、失われた可視性の回復には数週間から数か月かかることも。その頃には、最初のトラブルはすでに記憶から薄れているかもしれません。
こうした見えにくいコストは、静かに積み重なっていきます。ブランドへの印象は変化し、顧客は徐々に離れ、マーケティングの効率は低下し、オーガニックトラフィックも時間とともに弱まっていきます。影響がはっきりと見える頃には、原因となった停止は遠い出来事のように感じられるかもしれませんが、ダメージはすでに生じています。
実は重要な稼働率の数値
稼働率の数値は、マーケティング上の宣伝文句のように扱われることがあります。もちろん、サーバー選びの際に、高い稼働率は好印象を与えますが、日常的には特に意味を感じないということが多いかもしれません。実際には、稼働率のわずかな違いが現実的なビジネスリスクを引き起こす可能性があります。
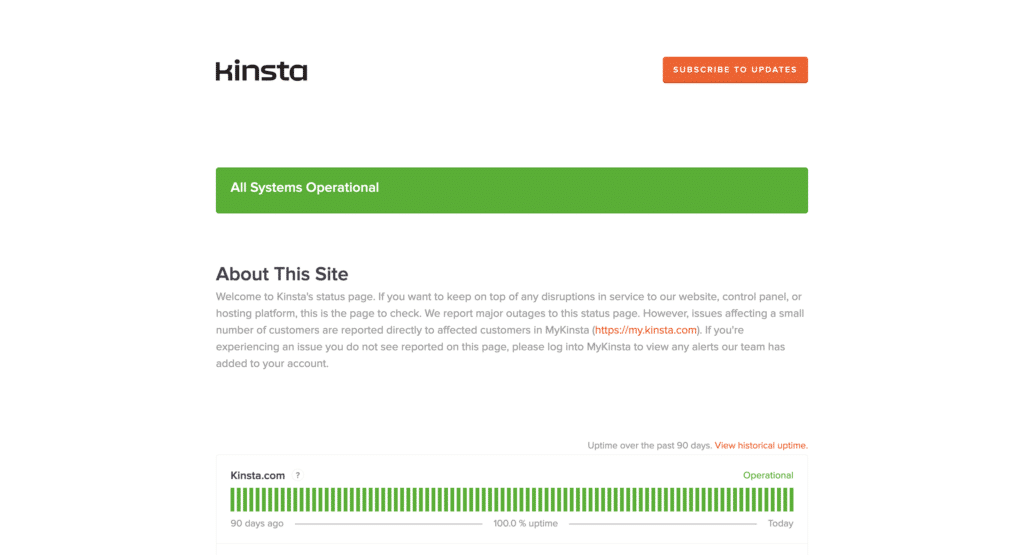
稼働率99.9% VS 99.5%
例えば、「99.9%」と「99.5%」の稼働率の差は一見わずかに思えるかもしれません。しかし、99.9%の稼働率でも年間では約8.7時間の停止が発生します。これが99.5%に下がると、年間の停止時間は43時間以上にまで増えます。これは、気づかれにくい短時間のインシデントが数回発生する程度と、ほぼ丸2日分の可用性を失うこととの違いです。
さらにこのサイトがダウンする時間は、トラフィックの少ない時間帯に分散して発生してくれるわけではありません。信頼性が最も重要な更新時、トラフィックの急増時、ストレスの多い時などに集中する傾向があります。
なぜ事業の成長とともに「許容できる停止」が許容できなくなるのか
事業の初期段階では、数時間の停止はなんとか許容できるように感じられるかもしれません。トラフィックはまだ少なく、収益への影響も限定的で、失うものの大きさもはっきりしないことが多いからです。しかし、ビジネスが成長するにつれて、その余裕は次第になくなっていきます。
トラフィックが増えるほど、1分あたりに失われる可能性のある収益も大きくなります。キャンペーンが増えれば、失敗がそのままコストに直結するピークの瞬間も増加。顧客数が拡大すれば、信頼性やプロフェッショナリズムに対する期待も高まります。かつては単なる不便で済んでいた問題が、やがて成長を妨げる慢性的な負債へと変わっていってしまいます。
稼働率は見栄えの指標ではなく、リスク管理の指標
この視点で捉えると、稼働率は見栄えの良い数字を誇るためのものでも、完璧さを追い求めるためのものでもありません。重要なのは、リスクへのさらされ方を抑えることです。稼働率を高めることで、収益やマーケティング成果、顧客の信頼を損なうインシデントの発生頻度や継続時間、影響の大きさを減らすことができます。
マネージドサーバーがサイトのダウンを未然に抑える仕組み
サイト停止を防ぐ取り組みは、トラブルが発生するはるか前から始まっています。どのようなサーバー環境でもリスクを完全に排除することはできませんが、マネージドサーバーは、問題の発生頻度や影響の大きさを抑え、対応までの時間を短縮するように設計されています。
訪問者や顧客が不具合に気づいてから対処するのではなく、あらかじめ回復力を高め、早期に介入できる体制を整えることに重点が置かれています。
信頼性のために構築されたインフラ
マネージドサーバーと低価格のレンタルサービスとの大きな違いのひとつは、環境の分離にあります。共用サーバー環境では、あるサイトのトラフィック急増や設定ミスが、他の多数のサイトに影響を及ぼすことがあります。一方、マネージドサーバーでは各サイトが分離された環境で運用され、それぞれ専用のリソースが割り当てられるため、他サイトの負荷と競合することがありません。
また、スケーラブルなアーキテクチャも重要な要素です。キャンペーンやローンチによってアクセスが殺到した場合でも、マネージドサーバーはその負荷を吸収できるよう設計されています。さらに、最新のクラウドインフラと冗長構成を組み合わせることで、単一障害点を減らし、最も避けたいタイミングで発生しがちな停止リスクを抑えることができます。
積極的な監視と予防
負荷下でのパフォーマンスの安定性
信頼性とは、サイトがオンライン状態を維持することだけを指すものではありません。表示速度を安定して保つことも含まれます。マネージドサーバー環境は、需要が増加してもパフォーマンスを維持できるよう最適化されています。
CDNの統合や高度なキャッシュ戦略によってトラフィックをグローバルに分散し、オリジンサーバーへの負荷を軽減します。さらに最適化されたサーバー設定と組み合わせることで、アクセスが集中するピーク時でも安定した応答時間を確保できるため、関心が最も高まる瞬間にキャンペーンが失速することを防ぎます。
サイトダウンのリスクを減らすために実践できること
サーバー設定を変更する前でも、以下のような事前対策によって停止リスクを軽減することができます。
- 稼働時間とパフォーマンスを継続的に監視し、ユーザーからの苦情が発生する前に問題を早期に検出する
- 大規模キャンペーン実施前にサイトをテストし、負荷時のパフォーマンス問題や限界点を明らかにする
- 問題のある決済フロー、フォーム、データベース制約など、トラフィック問題や単一障害点を特定する
- サーバーのSLAとサポート対応速度を確認し、問題発生時の支援体制を把握する
- 技術的・運用的な観点から、問題の検出と解決にかかる時間を理解しておく


