
Botverkeer wordt vaak gezien als een beveiligingsprobleem of een SEO-probleem. Maar op WordPress hostinginfrastructuur is het vooral een prestatieprobleem, en wel een dat zich concentreert op een heel specifieke set URL’s.
Niet alle verzoeken hebben dezelfde impact. Het verschil tussen een statische pagina uit de cache en een dynamisch endpoint is enorm als we het over prestaties hebben. Het is het verschil tussen een verzoek dat bijna niets kost en een verzoek dat een PHP thread in beslag neemt, een volledige databasequery uitlokt en sessie-overhead genereert, of de bezoeker nu een echte klant is of een bot die nooit converteert.
Snappen waarom sommige endpoints veel duurder zijn dan andere, is precies wat een botbeheerstrategie die werkt onderscheidt van een die te veel of te weinig blokkeert.
Niet alle verzoeken zijn gelijk
Wanneer een bezoeker op een typische WordPress pagina landt, zoals een artikel, een lijst met producten of een ‘Over’-pagina, levert de server dat antwoord bijna altijd vanuit de cache.
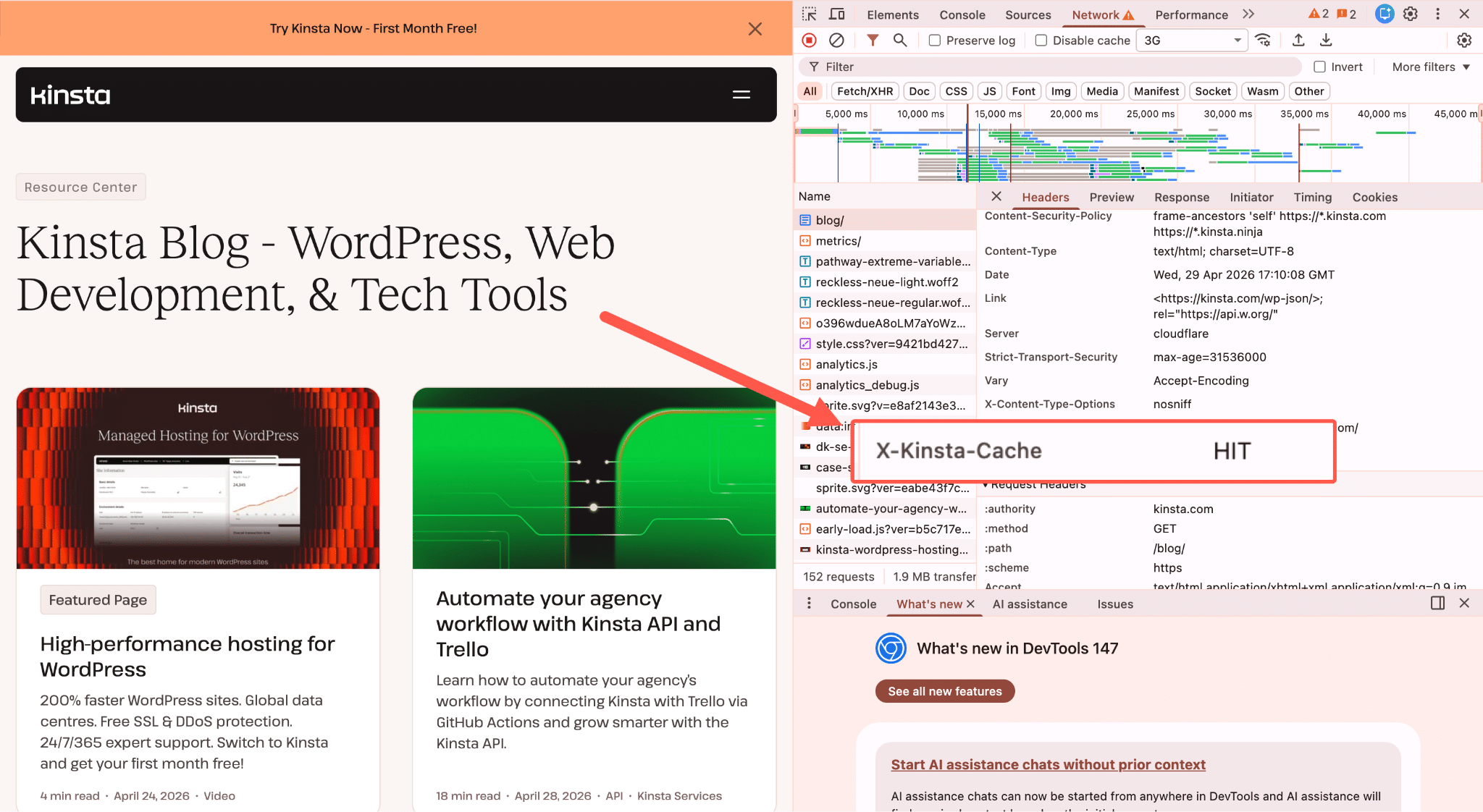
Kinsta’s full-page cache vangt dit op aan de edge, zodat het verzoek de PHP en database van de server nooit bereikt.
Maar zodra een verzoek op een niet-gecachet endpoint terechtkomt, moet de server echt werk verrichten. Er wordt een PHP thread toegewezen en vastgehouden voor de volledige duur van het verzoek, en je database wordt bevraagd. Gaat de pagina over de status van de winkelwagen, gebruikerssessies of gepersonaliseerde inhoud, dan komt daar nog sessieafhandeling bovenop. Niets hiervan kan in de cache, omdat het antwoord voor elk verzoek uniek is.
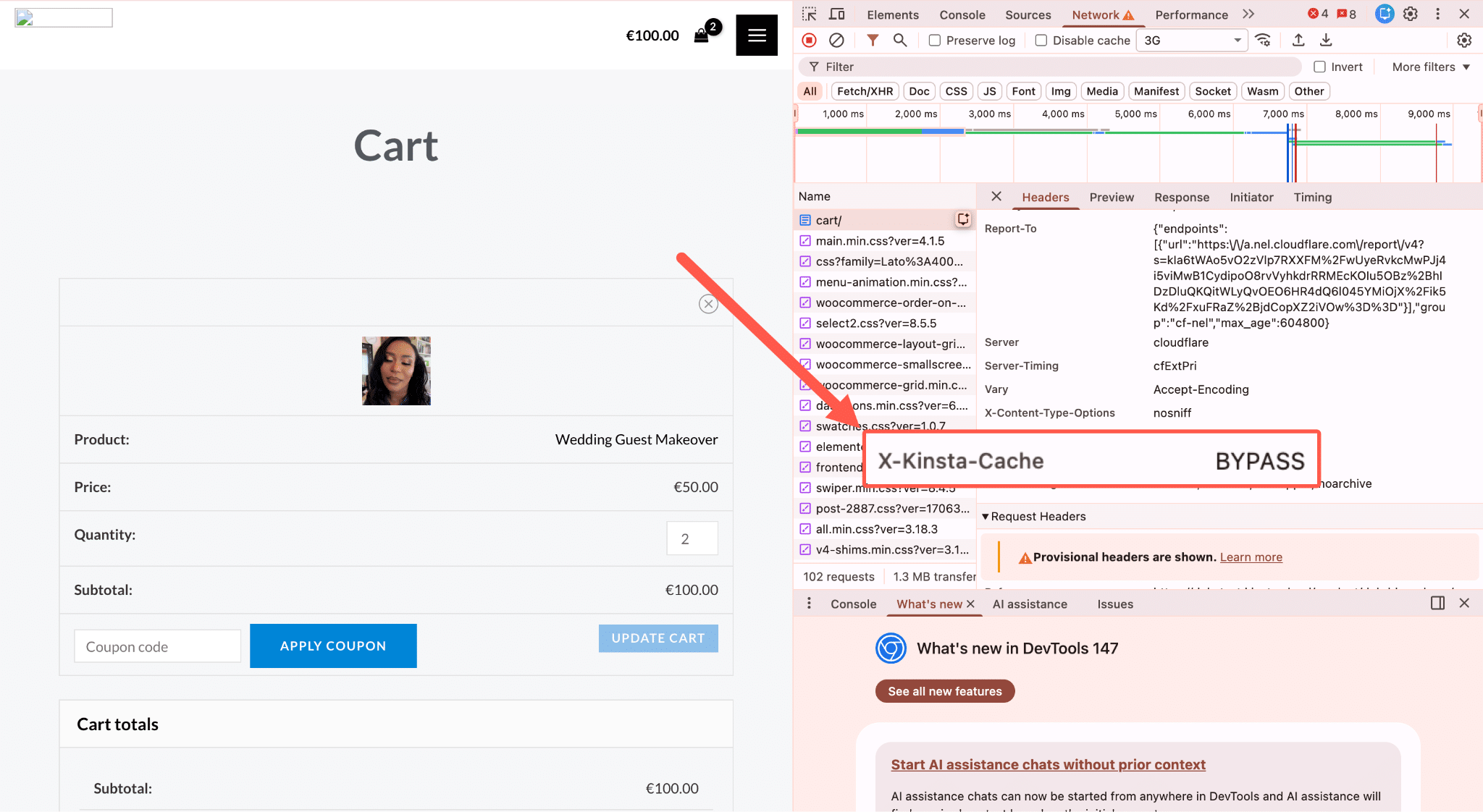
Op een gezonde site met vooral menselijke bezoekers is dit prima. Je dynamische endpoints bedienen echte klanten die producten zoeken, aan hun winkelwagen toevoegen en afrekenen. De belasting is evenredig met het werkelijke gebruik.
Botverkeer doorbreekt dit model. Een crawler voegt niets toe aan een winkelwagen en converteert nooit, maar activeert wel dezelfde server-side uitvoering als een echte klant, en in een tempo dat geen mens kan volhouden.
De specifieke endpoints waar dit gebeurt
In een WooCommerce winkel zijn de volgende URL-patronen en endpoints bewust niet gecachet, en dat zijn precies de endpoints die het hardst door botverkeer worden geraakt.
?add-to-cart=
Dit is het meest resource-intensieve voorbeeld dat we hebben gedocumenteerd in ons AI & Botverkeer Rapport. Een product aan de winkelwagen toevoegen vereist het uitvoeren van PHP, een schrijfactie in de database en het aanmaken of valideren van een sessie. Er bestaat geen gecachete versie van dit antwoord, want elke hit is nieuw werk.
Om de schaal te schetsen: Kinsta’s infrastructuurgegevens registreerden ooit 7,67 miljoen hits van vijf bots binnen 24 uur.
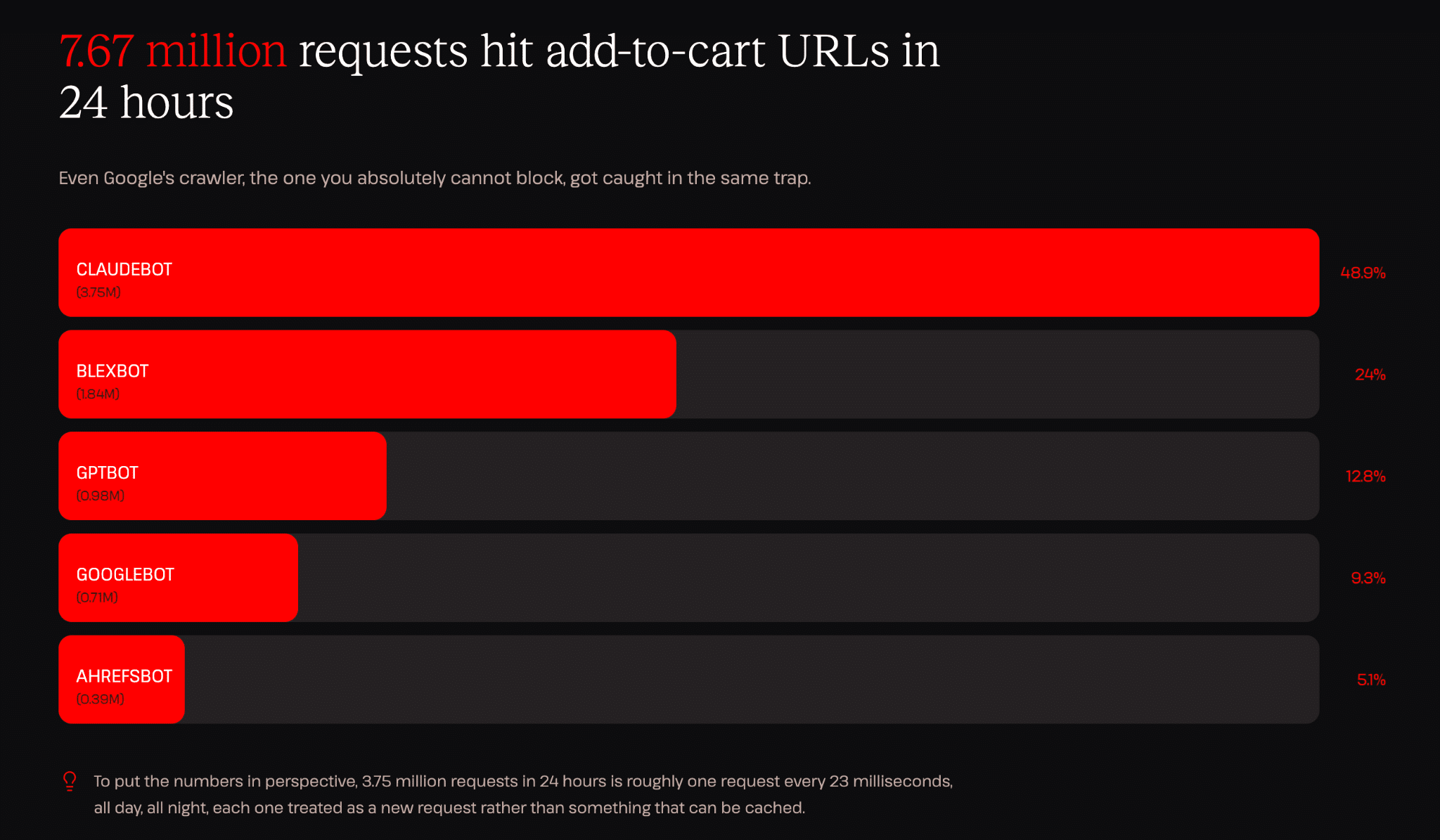
Dat komt neer op ongeveer één verzoek per 11 milliseconden, dag en nacht. Elk verzoek vraagt om volledige uitvoering van PHP en database, levert geen zinvolle output voor de crawler op en bedient geen enkele klant.
/cart en /checkout
Deze pagina’s zijn in WooCommerce standaard uitgesloten van de paginacache. Ze bevatten live sessiegegevens, een gepersonaliseerde winkelwagenstatus en, bij het afrekenen, logica voor betalingsverwerking.
Een bot die /checkout keer op keer aanroept, doet niets nuttigs, maar dat weet de server niet. Hij verwerkt elk verzoek alsof het een echte transactie kan zijn.
?s= (zoekopdrachten)
Zoekopdrachten in WordPress en WooCommerce worden bij elke aanvraag in je database uitgevoerd. Er is geen cachelaag die een unieke zoekopdracht kan opvangen.
Een crawler die geparametriseerde URL-variaties afloopt of simpelweg elke zoeklink volgt die hij tegenkomt, kan een lange reeks unieke, dure databasequery’s genereren.
Gefacetteerde navigatie en filterparameters
Hier wordt het probleem pas echt groot. Een typische WooCommerce productcatalogus genereert URL’s als:
/shop/?color=blue
/shop/?color=blue&size=M
/shop/?color=blue&size=M&orderby=price
/shop/?color=blue&size=M&orderby=price&paged=2Voor een mens zijn dit kleine variaties op dezelfde pagina. Voor een bot die links volgt, is elke URL een unieke URL die het crawlen waard lijkt, en voor elke URL moet de server een gefilterde databasequery vanaf nul uitvoeren.
De documentatie van Google noemt gefacetteerde navigatie expliciet als bron van inefficiënt crawlen, doordat crawlers bijna oneindig veel variaties van dezelfde inhoud aflopen. Maar het probleem is niet alleen dat dit crawlbudget verspilt. Elke variatie kost ook echte serverresources om te genereren.
AJAX-gestuurde interacties
Veel WordPress plugins, zoals zoeklijsten, beschikbaarheidscontroles, live prijsupdates en kalenderweergaven, leunen op AJAX-verzoeken die de paginacache volledig omzeilen.
Een bot die deze interacties triggert, zelfs indirect door een pagina te laden die ze activeert, veroorzaakt server-side belasting die niet als ‘page request’ in je analytics opduikt, maar wel zichtbaar wordt in je gebruik van PHP threads.
Wat gebeurt er als PHP threads opraken
Elke hit op een dynamisch endpoint houdt een PHP thread vast voor de volledige duur van die aanvraag. Op zichzelf lijkt dat detail onbelangrijk, maar threadcapaciteit is eindig, en bots wachten niet netjes op hun beurt.
Kinsta wijst per WordPress site een vast aantal PHP threads toe, en elk niet-gecachet verzoek reserveert er één zolang het duurt.
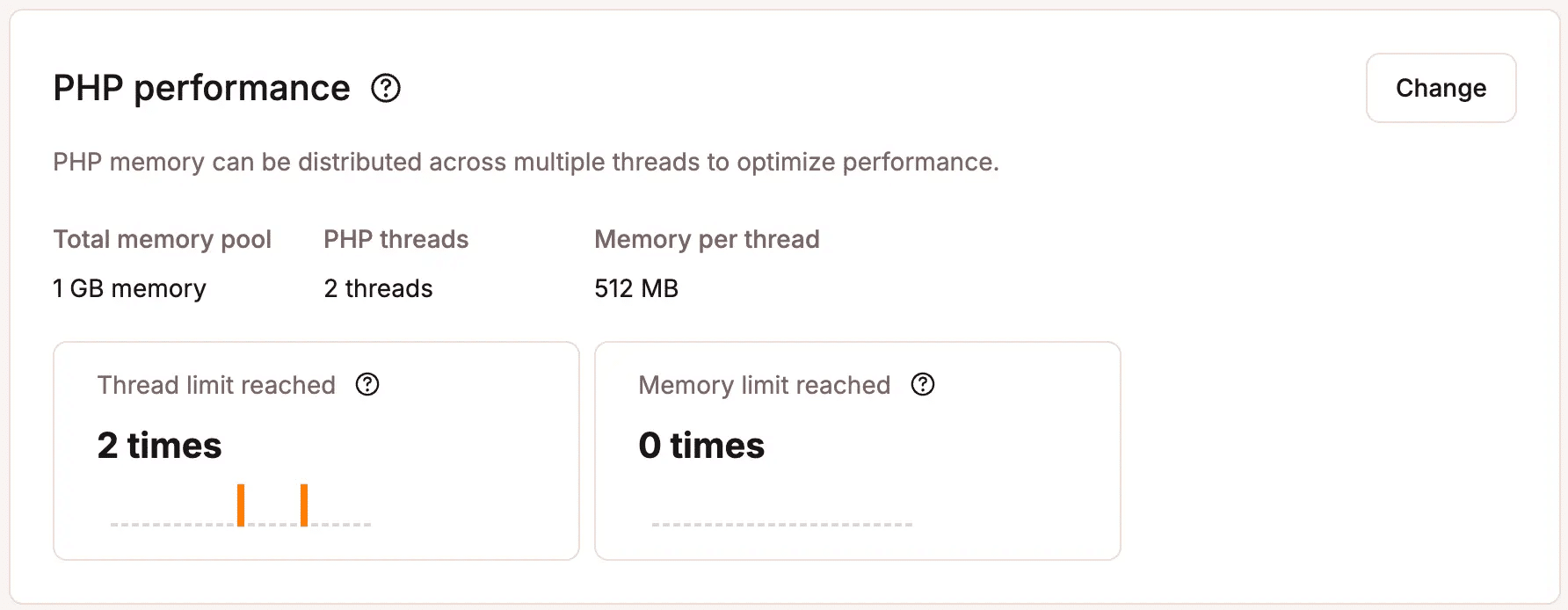
Bij normaal verkeer is dit zelden een knelpunt. Verzoeken komen binnen, worden snel afgehandeld en threads komen weer vrij.
Bij aanhoudende botbelasting op dynamische endpoints raken threads gereserveerd en bezet. Zijn alle threads bezet, dan belanden nieuwe verzoeken in een wachtrij. Echte klanten die een product aan hun winkelwagen willen toevoegen of willen afrekenen, krijgen te maken met trage laadtijden, timeouts of HTTP 504 fouten.

Dit is de infrastructurele realiteit die botverkeer op dynamische endpoints wezenlijk anders maakt dan botverkeer op pagina’s die wél gecachet kunnen worden.
Het loopprobleem: wanneer bots vastlopen
Veel van het botverkeer dat het infrastructuurteam van Kinsta ziet, komt niet voort uit een opzettelijke aanval. Het komt van crawlers die elke link op elke pagina volgen, zonder enig mechanisme om te merken dat ze rondjes draaien.
Zo ziet zo’n query string-loop er in de praktijk uit:
- Een bot komt binnen op
/shop/ - Die pagina bevat een link naar
/shop/?color=blue(een gefilterde weergave) - Die pagina bevat weer een link naar
/shop/?color=blue&size=M - En die weer naar
/shop/?color=blue&size=M&orderby=price - Die bevat een link om iets aan de winkelwagen toe te voegen:
/shop/?add-to-cart=123 - En elk van deze pagina’s genereert weer net iets andere links die de bot nog niet heeft bezocht
De bot volgt ze allemaal. Hij heeft geen besef van “deze productpagina heb ik al gezien, alleen met andere filters”. Elke URL oogt nieuw, wordt opgevraagd en komt vers op de server terecht.
Precies dit patroon, bots die query string-variaties aflopen over dynamische endpoints, is een van de meest voorkomende problemen die we in ons rapport tegenkwamen. Eén enkele loopregel, geactiveerd door zo’n zich misdragend patroon, filterde 550 miljoen verzoeken in 30 dagen op de infrastructuur van Kinsta. Dat is geen aanval, maar inefficiënte automatisering op grote schaal, verergerd doordat niets het vroeg genoeg oppikte.
Hoe goed botbeheer er op endpointniveau uitziet
Voor WooCommerce winkels en WordPress sites met dynamische functionaliteit gelden een paar principes, los van je specifieke setup.
- Robots.txt is een verkeersbord, geen schild. Je kunt (en moet) crawlers weren van de paden
/cart,/checkouten?add-to-cart=in jerobots.txt. Googlebot respecteert dat. Maarrobots.txtnaleven is vrijwillig. Een groeiend deel van de AI-trainingscrawlers controleert het niet of negeert het. Een pad blokkeren inrobots.txtgeeft je intentie aan; afdwingen vraagt om een regel op WAF-niveau. - Houd het genereren van URL-parameters in toom. De standaardconfiguratie van WooCommerce genereert een lange staart aan URL-varianten via sessietokens, aantalparameters en filtercombinaties. Beperk je die parameterwildgroei bij de bron, met canonical tags, samengevoegde permalinkstructuren en
Disallow-regels in robots.txt op parametervarianten, dan geef je crawlers minder loops om in vast te lopen. - Monitor op endpointniveau, niet alleen het totale verzoekvolume. Een piek in het totale verkeer kan een campagne zijn. Een piek in verzoeken naar
?add-to-cart=vanaf een niet-browser user agent is een botprobleem. Serverlogs en analysetools die de verdeling van aanvragen per URL-patroon en user agent tonen, bepalen of je dit binnen een paar uur doorhebt of pas na een paar dagen. - Bewaak de capaciteit van je PHP threads als belangrijkste meetwaarde. Draaien je PHP threads regelmatig op volle capaciteit zonder een vergelijkbare piek in echte gebruikerssessies, dan is botverkeer op dynamische endpoints vrijwel zeker een van de oorzaken. Kinsta’s APM tool toont de traagste PHP-transacties per endpoint, dus als winkelwagen- of kassapaden de boosdoener zijn, zie je dat meteen in plaats van dat je moet gissen.
Hoe dit uitpakt voor verschillende typen sites
Het probleem met dynamische endpoints is het acuutst bij WooCommerce winkels, maar het duikt in verschillende vormen op bij allerlei typen sites.
- WooCommerce winkels lopen het meeste risico, omdat hun duurste endpoints, zoals winkelwagen-, kassa- en gefilterde productpagina’s, precies de pagina’s zijn die bots via gewone link-following vinden. De gevolgen zijn direct merkbaar: raken PHP threads uitgeput tijdens botpieken, dan verslechtert het afrekenen voor echte klanten.
- Contentsites en blogs hebben minder last van de afrekenkant, maar kunnen flink geraakt worden door bots die gepagineerde archieven, tagpagina’s en zoekresultaten doorlopen. Elke unieke zoekopdracht is een nieuwe databasehit. Een agressieve crawler die systematisch een groot archief doorspit, kan een aanhoudende databasebelasting veroorzaken, zonder ook maar enige ‘winkel’-functionaliteit aan te raken.
- Zakelijke en dienstverlenende sites zijn kwetsbaarder voor formulier-endpoints (contactformulieren, offerteaanvragen en boekingsflows), die sessieafhandeling en vaak schrijfacties naar de database met zich meebrengen. Door bots ingediende formulieren zijn een ander soort probleem (CRM-vervuiling, verspilde verkoopinzet), maar het onderliggende mechanisme is hetzelfde: dynamische endpoints die bij elke hit echte resources kosten.
- Webapps en SaaS-producten zijn het gevoeligst. Hun API endpoints, dashboard routes en applicatielogica zijn niet te cachen, en al het botverkeer dat de applicatielaag bereikt, omzeilt de caching-infrastructuur volledig. De juiste reactie is hier meestal een harde blokkade van al het niet-geauthenticeerde verkeer naar de paden
/apien/app, met expliciete toestemmingslijsten voor legitieme integraties.
Tijd om dieper te graven: het volledige beeld van botverkeer
Het probleem met dynamische endpoints is onderdeel van een bredere verschuiving in hoe botverkeer de WordPress infrastructuur belast. AI crawlers zijn flink gegroeid in volume en veranderd in gedrag: agressievere link-following, meer bereidheid om crawl-richtlijnen te negeren en meer verkeer dat precies de endpoints raakt die het duurst zijn om te serveren.
Wil je het volledige beeld van wat er is veranderd, de cijfers erachter en een raamwerk om botbeheer af te stemmen op je sitetype en prioriteiten? Dan vind je dat allemaal in het complete Kinsta-rapport De AI & Botverkeer Realitycheck, inclusief een analyse van meer dan 10 miljard verzoeken op door Kinsta beheerde infrastructuur.
Wil je iets doen met wat je hier hebt gelezen? Kinsta’s Botbescherming handelt de meest voorkomende patronen automatisch af, inclusief bescherming voor dure dynamische endpoints. Stel je gewenste beschermingsniveau één keer in MyKinsta in, en het systeem regelt de rest.
Heb je nog vragen? Neem dan contact op met het ondersteuningsteam.


