
Het kan enorm vervelend zijn om je website te zien dalen in de zoekresultaten. Als je pagina’s niet meer door Google gecrawld worden, kunnen deze lagere rankings bijdragen aan minder bezoekers en conversies.
De fout “Indexed, though blocked by robots.txt” kan duiden op een probleem met het crawlen door zoekmachines op je site. Wanneer dit gebeurt, heeft Google een pagina geïndexeerd die het niet kan crawlen. Gelukkig kun je je robots.txt bestand bewerken om aan te geven welke pagina’s wel of niet geïndexeerd moeten worden.
In dit bericht leggen we de fout “Indexed, though blocked by robots.txt” uit en hoe je je website op dit probleem kunt testen. Daarna laten we je twee verschillende methoden zien om het op te lossen. Laten we beginnen!
Wat is de fout “Indexed, though blocked by robots.txt”?
Als website-eigenaar kan Google Search Console je helpen om de prestaties van je site op veel belangrijke gebieden te analyseren. Deze tool kan de paginasnelheid, beveiliging en “crawlability” controleren, zodat je je online aanwezigheid kunt optimaliseren:
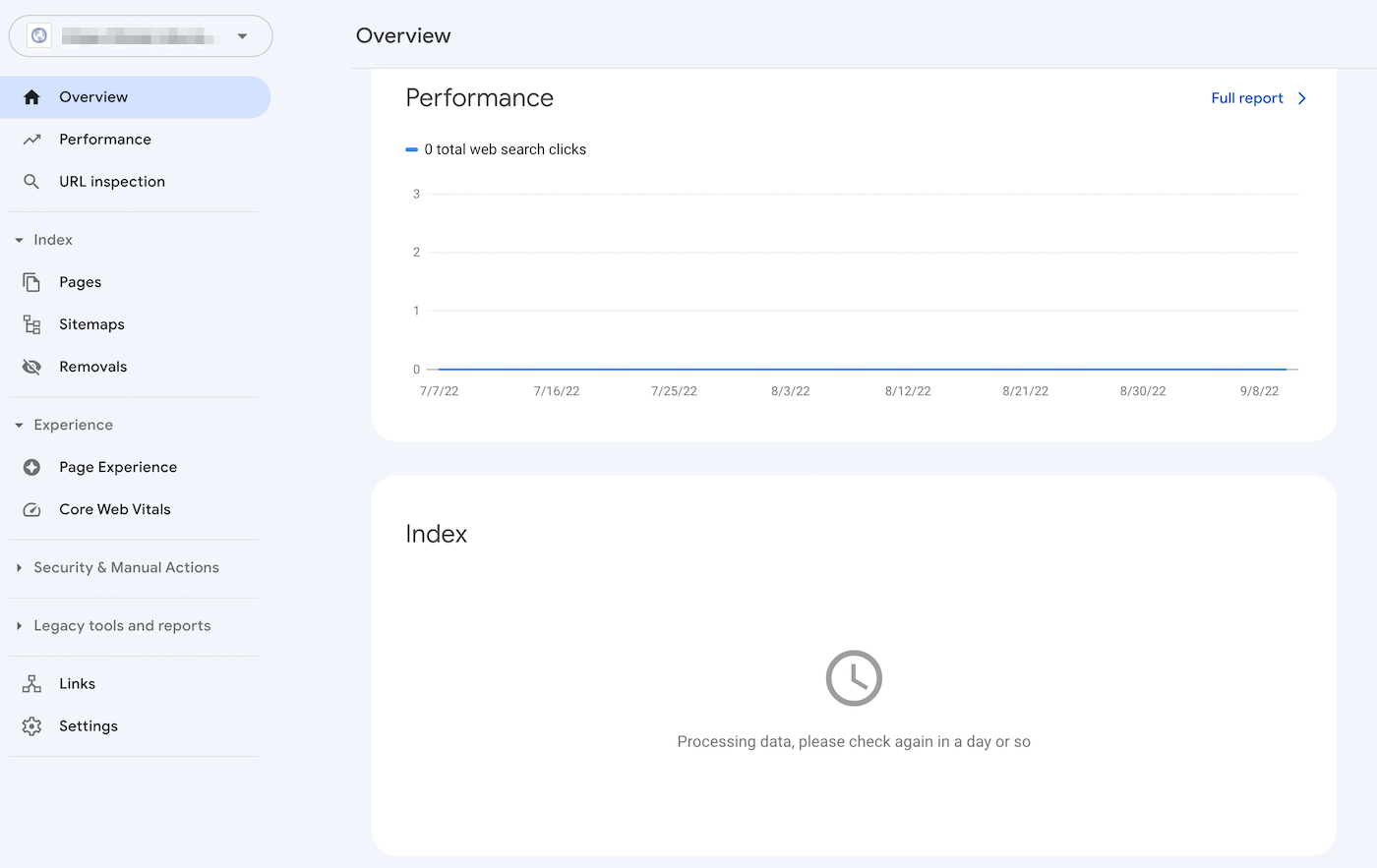
Het Index Coverage rapport van Search Console kan je bijvoorbeeld helpen om de Search Engine Optimization (SEO) van je site te verbeteren. Het analyseert hoe Google je online content indexeert en geeft informatie over veel voorkomende fouten, zoals een waarschuwing “Indexed, though blocked by robots.txt”:
Om deze fout te begrijpen, laten we eerst het robots.txt bestand bekijken. In wezen informeert het zoekmachinecrawlers welke van je website bestanden wel of niet geïndexeerd moeten worden. Met een goed gestructureerd robots.txt bestand kun je ervoor zorgen dat alleen belangrijke webpagina’s worden gecrawld.
Als je een waarschuwing “Indexed, though blocked by robots.txt” hebt ontvangen, hebben de crawlers van Google de pagina wel gevonden, maar merken ze op dat deze in je robots.txt bestand is geblokkeerd. Wanneer dit gebeurt, weet Google niet zeker of je wilt dat die pagina geïndexeerd wordt.
Als gevolg daarvan kan deze pagina wel verschijnen in de zoekresultaten, maar wordt er geen beschrijving weergegeven. Het zal ook afbeeldingen, video’s, PDF’s en niet-HTML bestanden uitsluiten. Daarom moet je je robots.txt bestand bijwerken als je deze informatie wilt weergeven.
Mogelijke problemen bij het indexeren van pagina’s
Je kunt opzettelijk richtlijnen toevoegen aan je robots.txt bestand die pagina’s blokkeren voor crawlers. Deze richtlijnen verwijderen de pagina’s echter mogelijk niet volledig uit Google. Als een externe website naar de pagina linkt, kan dat een “Indexed, though blocked by robots.txt” fout veroorzaken.
Google (en andere zoekmachines) moeten je pagina’s indexeren voordat ze ze nauwkeurig kunnen scoren. Om ervoor te zorgen dat alleen relevante content in de zoekresultaten verschijnt, is het cruciaal om te begrijpen hoe dit proces werkt.
Hoewel bepaalde pagina’s geïndexeerd zouden moeten zijn, kan het zijn dat ze dat niet zijn. Dit kan verschillende oorzaken hebben:
- Een richtlijn in het robots.txt bestand die indexering verhindert
- Dode links of redirectketens
- Canonieke tags in de HTML header
Aan de andere kant zouden sommige webpagina’s niet geïndexeerd moeten worden. Ze kunnen per ongeluk geïndexeerd worden vanwege deze factoren:
- Onjuiste noindex richtlijnen
- Externe links van andere sites
- Oude URL’s in de Google index
- Geen robots.txt bestand
Als te veel van je pagina’s worden geïndexeerd, kan je server overweldigd raken door de crawler van Google. Bovendien zou Google tijd kunnen verspillen aan het indexeren van irrelevante pagina’s op je website. Daarom moet je je robots.txt bestand op de juiste manier maken en bewerken.
De bron van de fout “Indexed, though blocked by robots.txt” vinden
Een effectieve manier om problemen bij het indexeren van pagina’s op te sporen is door je aan te melden bij Google Search Console. Nadat je het eigendom van de site hebt gecontroleerd, krijg je toegang tot rapporten over de prestaties van je website.
Klik in het gedeelte Index op het tabblad Valid with warnings. Je krijgt dan een lijst met indexeringsfouten te zien, waaronder eventuele “Indexed, though blocked by robots.txt” waarschuwingen. Als je er geen ziet, heeft je website waarschijnlijk geen last van dit probleem.
Je kunt ook de robots.txt tester van Google gebruiken. Met deze tool kun je je robots.txt bestand scannen op syntaxiswaarschuwingen en andere fouten:
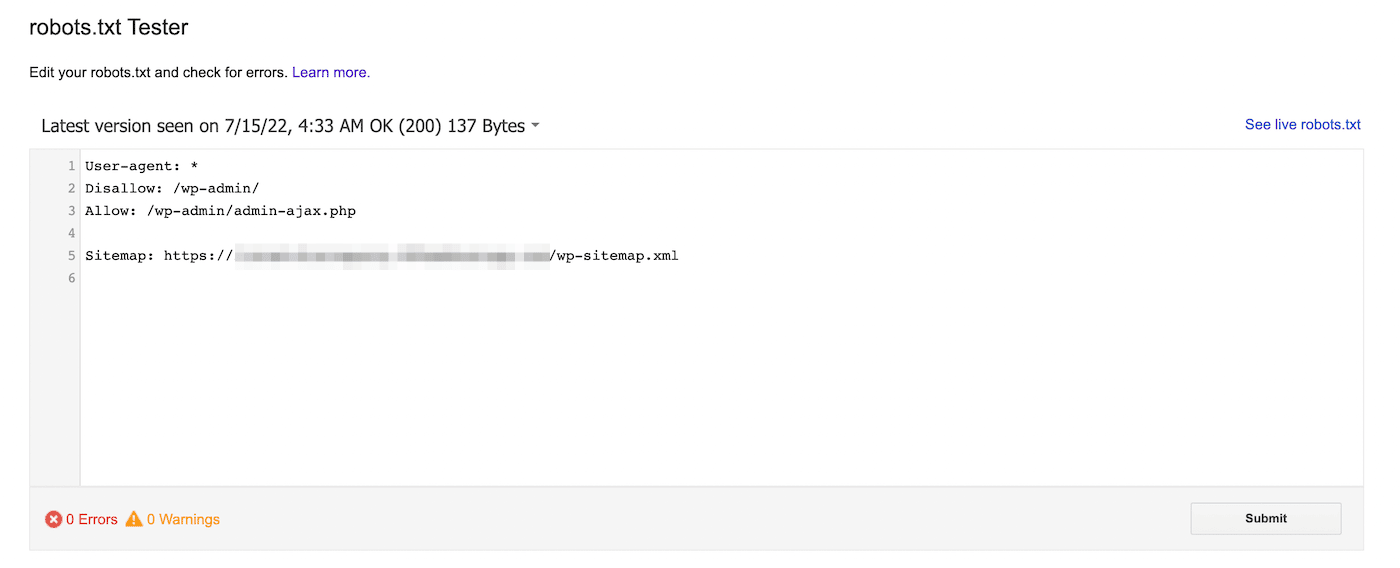
Voer onderaan de pagina een specifieke URL in om te zien of die geblokkeerd is. Je moet een user-agent kiezen in het dropdown menu en Test selecteren:

Je kunt ook navigeren naar domain.com/robots.txt. Als je al een robots.txt bestand hebt, kun je dat hiermee bekijken:
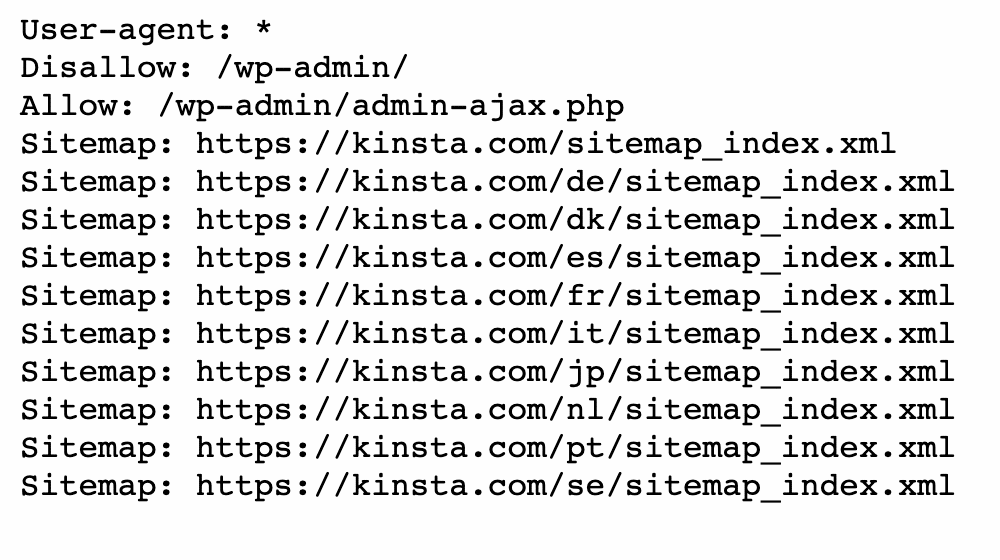
Zoek vervolgens naar disallow statements. Sitebeheerders kunnen deze statements toevoegen om zoekcrawlers te instrueren hoe ze toegang krijgen tot specifieke bestanden of pagina’s.
Als het disallow statement alle zoekmachines blokkeert, kan het er als volgt uitzien:
Disallow: /Het kan ook een specifieke user-agent blokkeren:
User-agent: *
Disallow: /Met een van deze tools kun je eventuele problemen met de indexering van je pagina’s vaststellen. Vervolgens moet je actie ondernemen om je robots.txt bestand bij te werken.
Zo los je de fout “Indexed, though blocked by robots.txt” op
Nu je meer weet over het robots.txt bestand en hoe het het indexeren van pagina’s kan verhinderen, is het tijd om de “Indexed, though blocked by robots.txt” fout op te lossen. Zorg er echter voor dat je eerst evalueert of de geblokkeerde pagina geïndexeerd moet worden voordat je deze oplossingen gebruikt.
Methode 1: robots.txt direct bewerken
Als je een WordPress website hebt, heb je waarschijnlijk een virtueel robots.txt bestand. Je kunt het bezoeken door in een webbrowser te zoeken naar domein.com/robots.txt (waarbij je domein.com vervangt door je domeinnaam). Met dit virtuele bestand kun je echter geen wijzigingen aanbrengen.
Om robots.txt te bewerken moet je een bestand op je server maken. Kies eerst een teksteditor en maak een nieuw bestand aan. Zorg ervoor dat je het de naam “robots.txt” geeft:
Vervolgens moet je verbinding maken met een SFTP client. Als je een Kinsta hostingaccount gebruikt, meld je dan aan bij MyKinsta en navigeer naar Websites > Info:
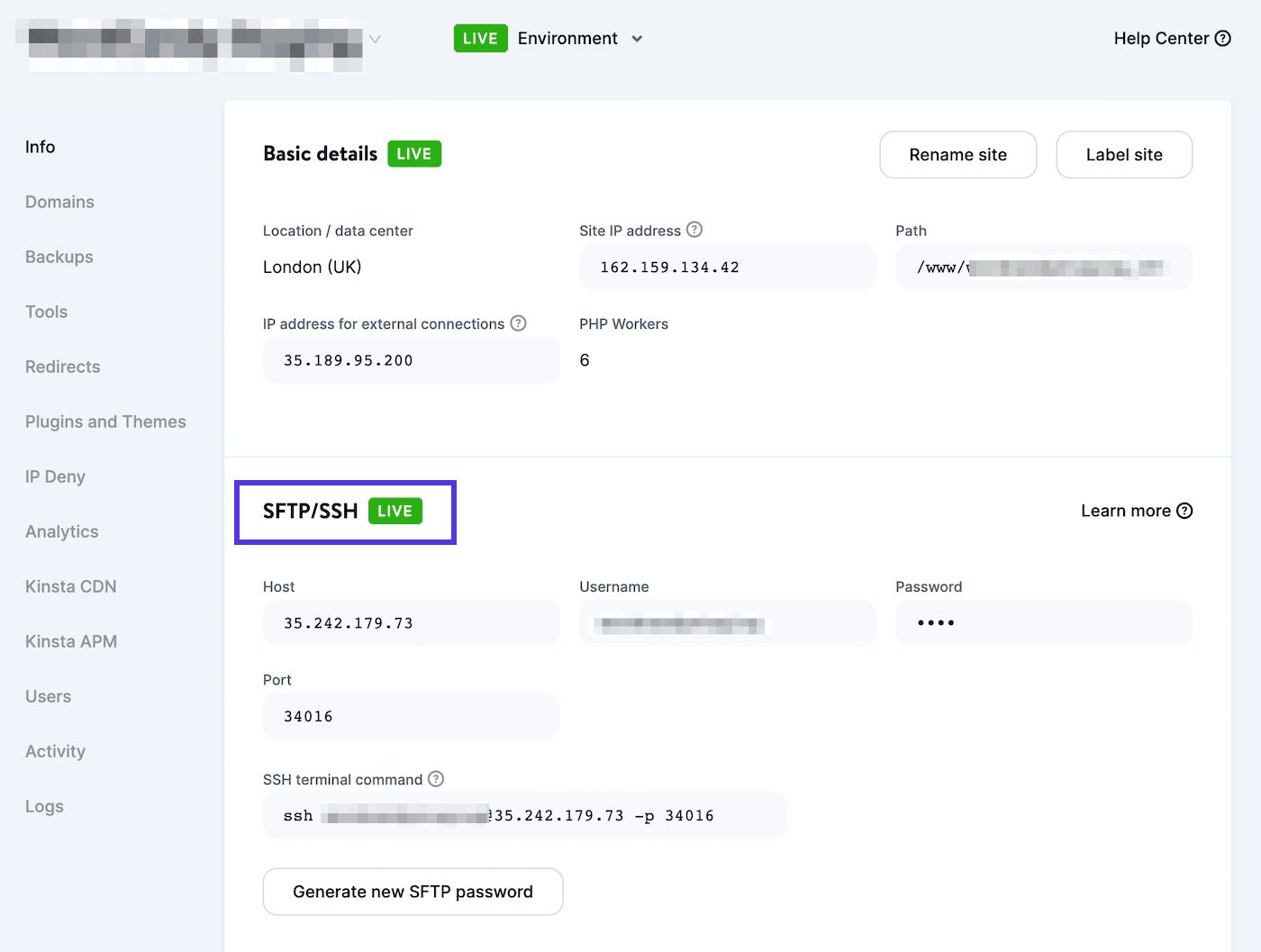
Je vindt hier je gebruikersnaam, wachtwoord, host en poortnummer. Vervolgens kun je een SFTP client zoals FileZilla downloaden. Voer je SFTP inloggegevens in en klik op Quickconnect:

Als laatste upload je het robots.txt bestand naar je hoofdmap (voor WordPress sites moet die public_html heten). Daarna kun je het bestand openen en de nodige wijzigingen aanbrengen.
Je kunt allow en disallow statements gebruiken om de indexering van je WordPress site aan te passen. Je kunt bijvoorbeeld willen dat een bepaald bestand wordt gecrawld zonder de hele map te indexeren. In dat geval kun je deze code toevoegen:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpVergeet niet om de pagina die de “Indexed, though blocked by robots.txt” fout veroorzaakt tijdens dit proces te targeten. Afhankelijk van je doel kun je aangeven of Google de pagina wel of niet moet crawlen.
Als je klaar bent, sla dan je wijzigingen op. Ga dan terug naar Google Search Console om te zien of deze methode de fout heeft opgelost.
Methode 2: Gebruik een SEO plugin
Als je een SEO plugin hebt geactiveerd, hoef je geen geheel nieuw robots.txt bestand aan te maken. In veel gevallen zal de SEO tool er een voor je bouwen. Bovendien kan het ook manieren bieden om het bestand te bewerken zonder het WordPress dashboard te verlaten.
Yoast SEO
Een van de populairste SEO plugins is Yoast SEO. Het kan een gedetailleerde on-page SEO analyse bieden, samen met extra tools om je zoekmachine indexering aan te passen.
Om te beginnen met het bewerken van je robots.txt bestand, ga je naar Yoast SEO > Tools in je WordPress dashboard. Uit de lijst met ingebouwde tools kies je de File editor:

Yoast SEO maakt niet automatisch een robots.txt bestand aan. Als je er nog geen hebt, klik dan op Create robots.txt file:
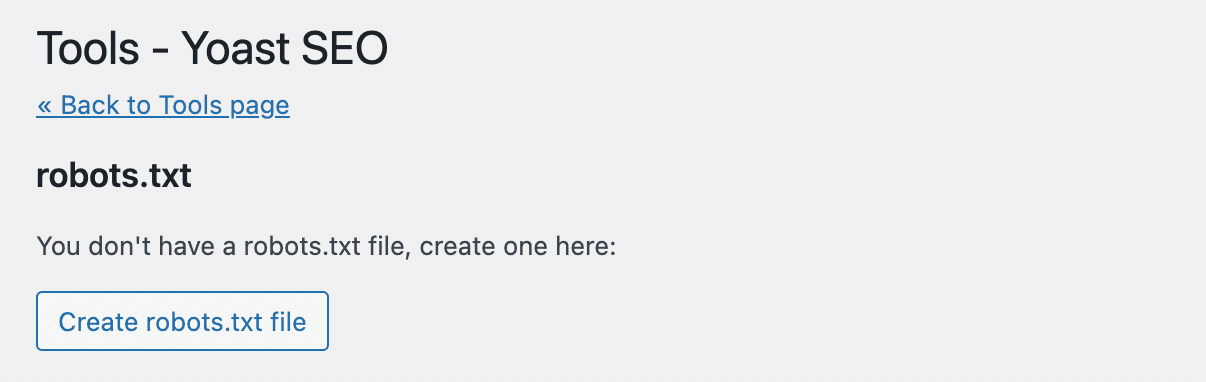
Hiermee open je een teksteditor met de content van je nieuwe robots.txt bestand. Vergelijkbaar met de eerste methode kun je allow statements toevoegen aan pagina’s die je wilt laten indexeren. Als alternatief kun je disallow statements gebruiken voor URL’s om indexering te voorkomen:
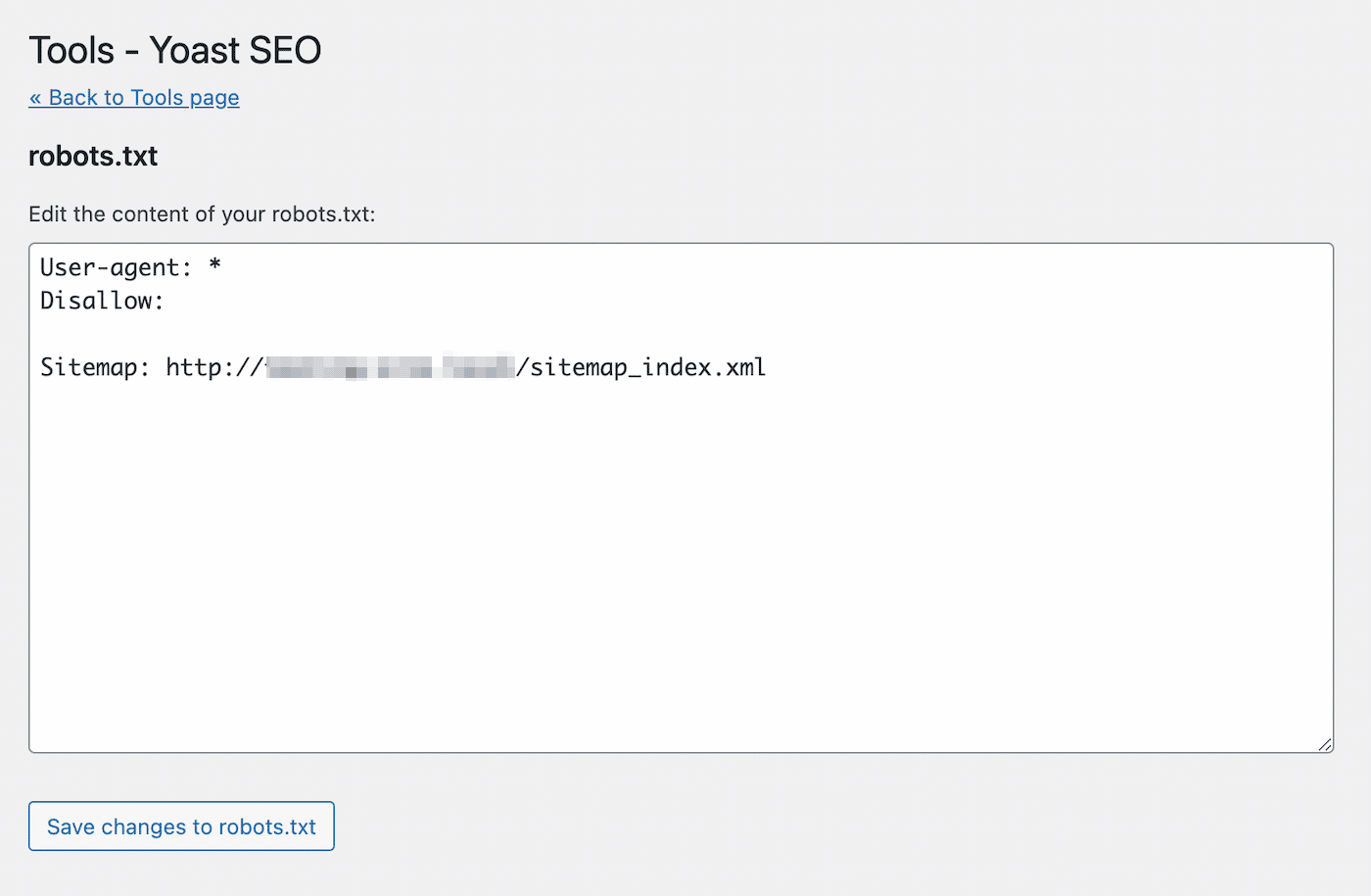
Sla het bestand op nadat je je wijzigingen hebt aangebracht. Yoast SEO zal je waarschuwen als je het robots.txt bestand hebt bijgewerkt.
Rank Math
Rank Math is een andere freemium plugin die een robots.txt editor bevat. Na het activeren van de tool op je WordPress site, ga je naar Rank Math > General Settings > Edit robots.txt:
In de code editor zie je een aantal standaardregels, waaronder je sitemap. Om de instellingen ervan bij te werken, kun je naar behoefte code plakken of verwijderen.
Tijdens dit bewerkingsproces zijn er een paar regels die je moet volgen:
- Gebruik een of meer groepen, waarbij elke groep meerdere regels bevat.
- Begin elke groep met een user-agent en volg met specifieke directories of bestanden.
- Ga ervan uit dat elke webpagina indexering toestaat, tenzij er een disallow regel op staat.
Houd er rekening mee dat deze methode alleen mogelijk is als je nog geen robots.txt bestand in je hoofddirectory hebt. Als je dat wel hebt, moet je het robot.txt bestand direct bewerken met een SFTP client. Als alternatief kun je dit reeds bestaande bestand verwijderen en in plaats daarvan de Rank Math editor gebruiken.
Zodra je een pagina niet toestaat in robots.txt, moet je ook een noindex richtlijn toevoegen. Die houdt de pagina privé voor Google-zoekopdrachten. Navigeer hiervoor naar Rank Math > Titels & Meta > Posts:
Scroll naar beneden naar Post Robots Meta en schakel deze in. Selecteer dan No Index:
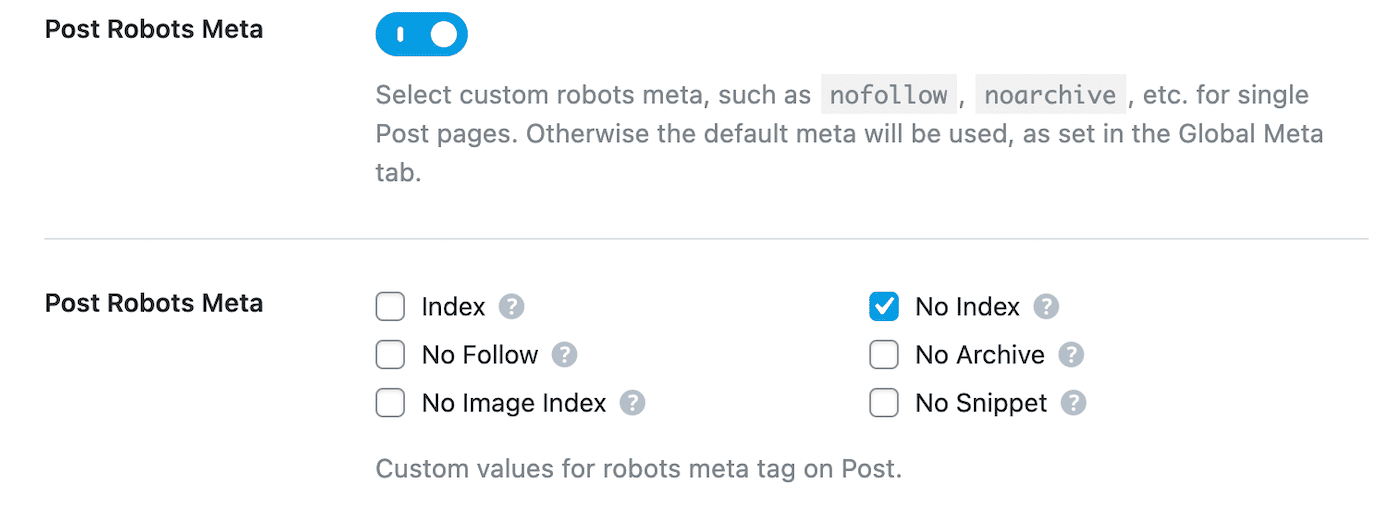
Sla tot slot je wijzigingen op. Zoek in Google Search Console de waarschuwing “Indexed, though blocked by robots.txt” en klik op Validate Fix. Hierdoor kan Google de opgegeven URL’s opnieuw crawlen en de fout oplossen.
Squirrly SEO
Met de Squirrly SEO plugin kun je op vergelijkbare wijze robots.txt bewerken. Om te beginnen klik je op Squirrly SEO > SEO Configuration. Dit opent de Tweaks and Sitemap instellingen:
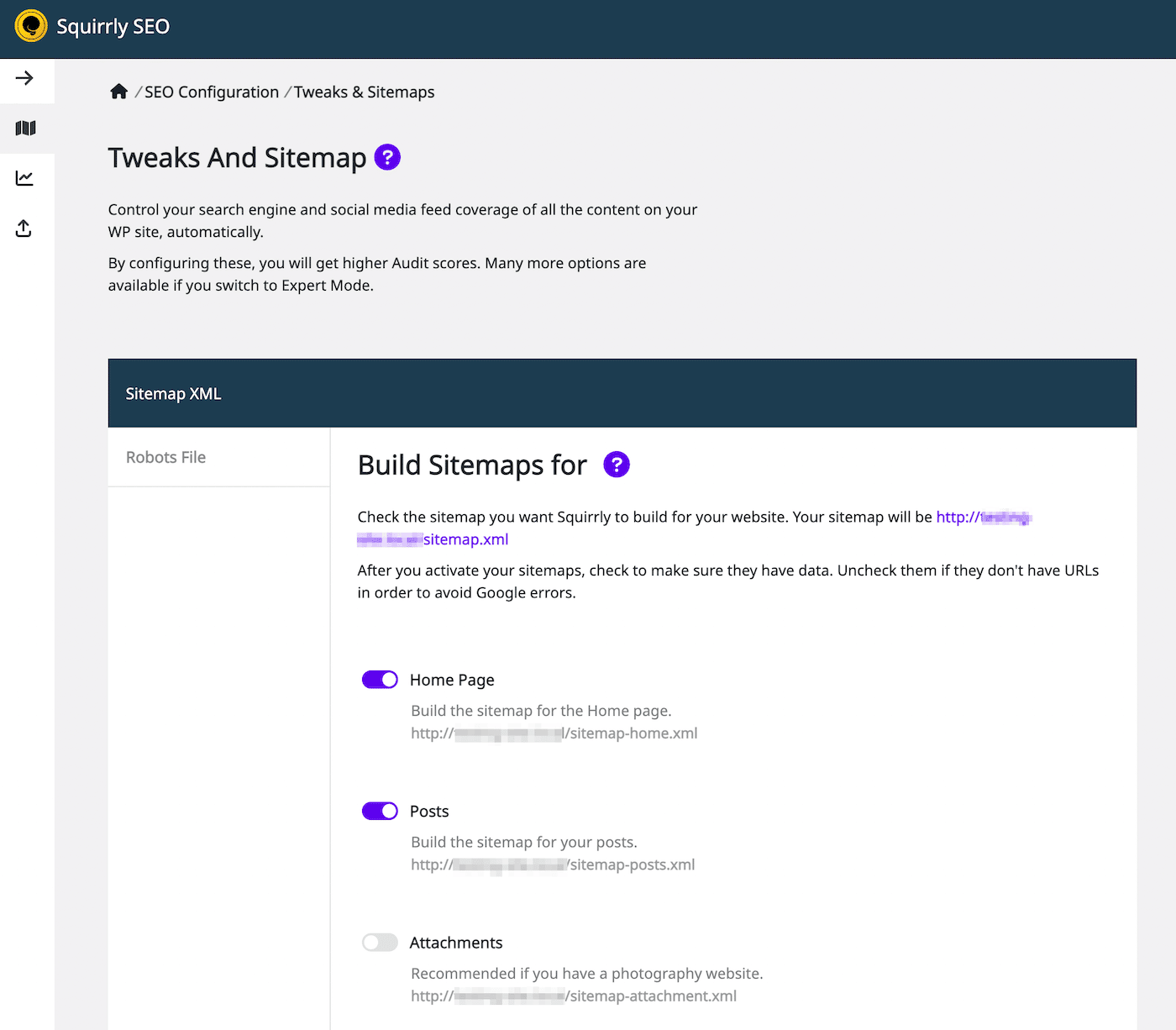
Selecteer aan de linkerkant het tabblad Robots File. Dan zie je een robots.txt bestandseditor die lijkt op andere SEO plugins:
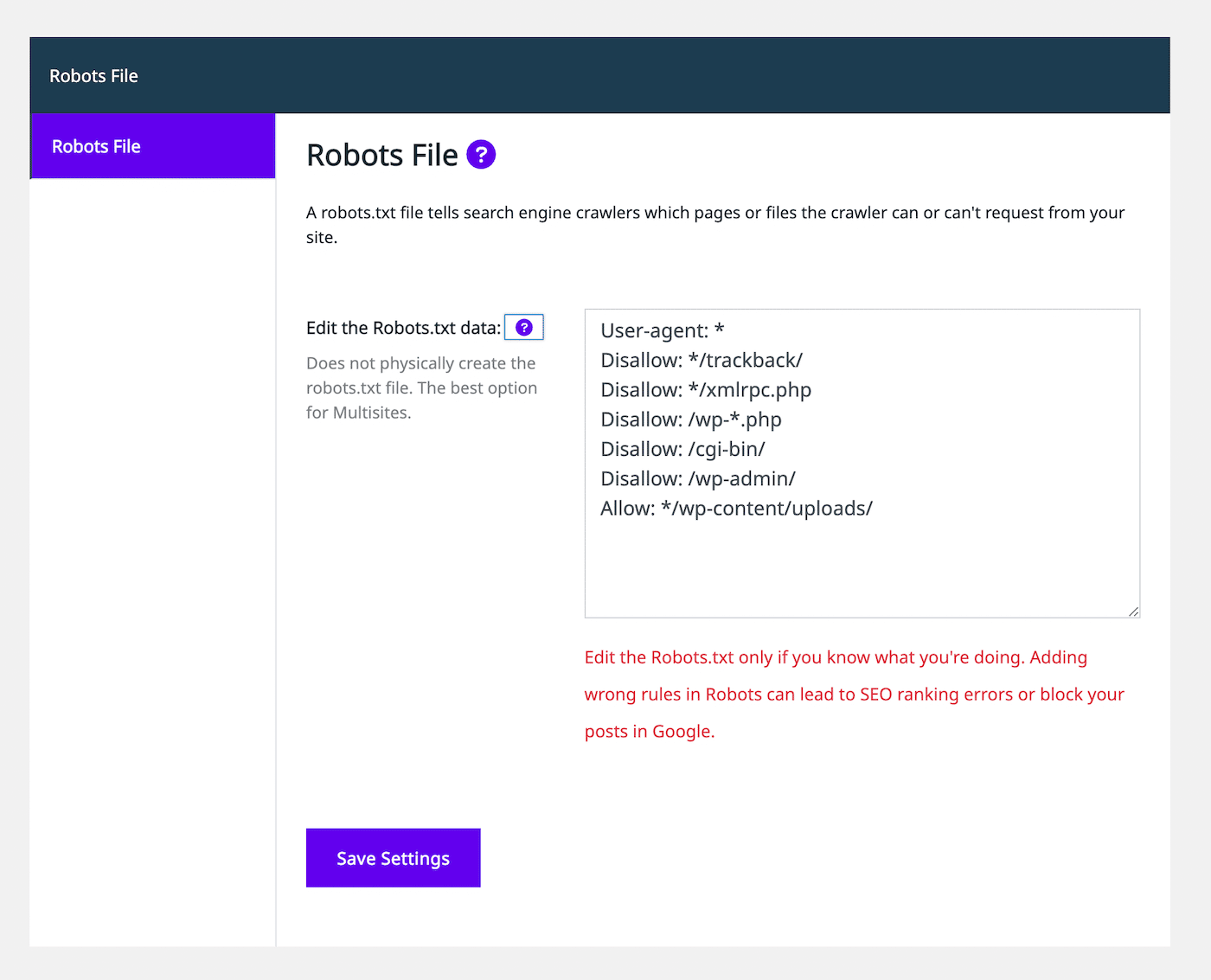
Met behulp van de teksteditor kun je allow of disallow statements toevoegen om het robots.txt bestand aan te passen. Ga door met het toevoegen van zoveel regels als je nodig hebt. Als je tevreden bent met hoe dit bestand eruit ziet, selecteer dan Save Settings.
Bovendien kun je noindex regels toevoegen aan bepaalde berichttypes. Om dit te doen, hoef je alleen maar de instelling Let Google Index It op het tabblad Automation uit te schakelen. Standaard laat SEO Squirrly dit ingeschakeld.
Samenvatting
Normaal gesproken vindt Google je webpagina’s en indexeert ze in zijn zoekresultaten. Echter, een slecht geconfigureerd robots.txt bestand kan zoekmachines verwarren over het al dan niet negeren van deze pagina tijdens het crawlen. In dit geval moet je de crawlinginstructies verduidelijken om de SEO op je website te blijven maximaliseren.
Je kunt robots.txt rechtstreeks bewerken met een SFTP client zoals FileZilla. Als alternatief bevatten veel SEO plugins, waaronder Yoast, Rank Math en Squirrly SEO, robots.txt editors binnen hun interfaces. Met een van deze tools kun je toestaan en verbieden toevoegen om zoekmachines te helpen je inhoud content te indexeren.
Om je website naar de top van de zoekresultaten te helpen, raden we je aan een SEO-geoptimaliseerde webhost te kiezen. Bij Kinsta bevatten onze managed WordPress hosting abonnementen SEO tools zoals uptimemonitoring, SSL certificaten en redirectmanagement. Bekijk onze abonnementen vandaag nog!

Hoofdredacteur bij Kinsta en content marketing consultant voor WordPress plugin-ontwikkelaars. Verbind met <a href="">Matteo op Twitter.

