
Murphys Gesetz besagt, dass alles, was schief gehen kann, auch schief gehen wird. Das trifft in der Welt der Programmierung nur allzu gut zu. Wenn du eine Anwendung erstellst, kann es passieren, dass du Fehler und andere Probleme verursachst. Fehler in JavaScript sind ein häufiges Problem!
Der Erfolg eines Softwareprodukts hängt davon ab, wie gut es den Entwicklern gelingt, diese Probleme zu lösen, bevor sie den Benutzern schaden. Und von allen Programmiersprachen ist JavaScript berüchtigt für seine durchschnittliche Fehlerbehandlung.
Wenn du eine JavaScript-Anwendung entwickelst, ist die Wahrscheinlichkeit groß, dass du an der einen oder anderen Stelle einen Fehler bei den Datentypen machst. Wenn das nicht der Fall ist, kann es passieren, dass du einen undefinierten Wert durch eine Null oder einen dreifachen Gleichheitsoperator (===) durch einen doppelten Gleichheitsoperator (==) ersetzt.
Es ist nur menschlich, Fehler zu machen. Deshalb zeigen wir dir alles, was du über den Umgang mit Fehlern in JavaScript wissen musst.
Dieser Artikel führt dich durch die grundlegenden Fehler in JavaScript und erklärt die verschiedenen Fehler, die dir begegnen können. Anschließend erfährst du, wie du diese Fehler erkennen und beheben kannst. Außerdem haben wir ein paar Tipps, wie du Fehler in Produktionsumgebungen effektiv beheben kannst.
Ohne Umschweife: Los geht’s!
Schau dir unseren Video-Leitfaden zur Behandlung von JavaScript-Fehlern an
Was sind JavaScript-Fehler?
Als Fehler in der Programmierung werden Situationen bezeichnet, in denen ein Programm nicht normal funktioniert. Das kann passieren, wenn ein Programm nicht weiß, wie es die anstehende Aufgabe bewältigen soll, z. B. wenn es versucht, eine nicht vorhandene Datei zu öffnen oder einen webbasierten API-Endpunkt zu erreichen, obwohl keine Netzwerkverbindung besteht.
In solchen Situationen gibt das Programm eine Fehlermeldung aus, die besagt, dass es nicht weiß, wie es weitergehen soll. Das Programm sammelt so viele Informationen wie möglich über den Fehler und meldet dann, dass es nicht weitermachen kann.
Intelligente Programmierer versuchen, diese Szenarien vorherzusehen und abzudecken, damit der Nutzer eine technische Fehlermeldung wie „404“ nicht selbst herausfinden muss. Stattdessen zeigen sie eine viel verständlichere Meldung an: „Die Seite konnte nicht gefunden werden.“
Fehler in JavaScript sind Objekte, die angezeigt werden, wenn ein Programmierfehler auftritt. Diese Objekte enthalten ausführliche Informationen über die Art des Fehlers, die Anweisung, die den Fehler verursacht hat, und den Stack-Trace, als der Fehler auftrat. Mit JavaScript können Programmierer auch eigene Fehler erstellen, um zusätzliche Informationen für die Fehlersuche zu erhalten.
Eigenschaften eines Fehlers
Nachdem die Definition eines JavaScript-Fehlers nun klar ist, ist es an der Zeit, sich mit den Details zu beschäftigen.
Fehler in JavaScript haben bestimmte Standard- und benutzerdefinierte Eigenschaften, die helfen, die Ursache und Auswirkungen des Fehlers zu verstehen. Standardmäßig enthalten Fehler in JavaScript drei Eigenschaften:
- nachricht: Ein String-Wert, der die Fehlermeldung enthält
- name: Die Art des Fehlers, der aufgetreten ist (wir werden im nächsten Abschnitt näher darauf eingehen)
- stack: Der Stack-Trace des Codes, der ausgeführt wurde, als der Fehler auftrat.
Zusätzlich können Fehler auch Eigenschaften wie columnNumber, lineNumber, fileName usw. enthalten, um den Fehler besser zu beschreiben. Diese Eigenschaften gehören jedoch nicht zum Standard und sind möglicherweise nicht in jedem Fehlerobjekt vorhanden, das von deiner JavaScript-Anwendung erzeugt wird.
Stack Trace verstehen
Ein Stack Trace ist die Liste der Methodenaufrufe, in denen sich ein Programm befand, als ein Ereignis wie eine Ausnahme oder eine Warnung auftrat. So sieht ein Beispiel für einen Stack Trace mit einer Ausnahme aus:
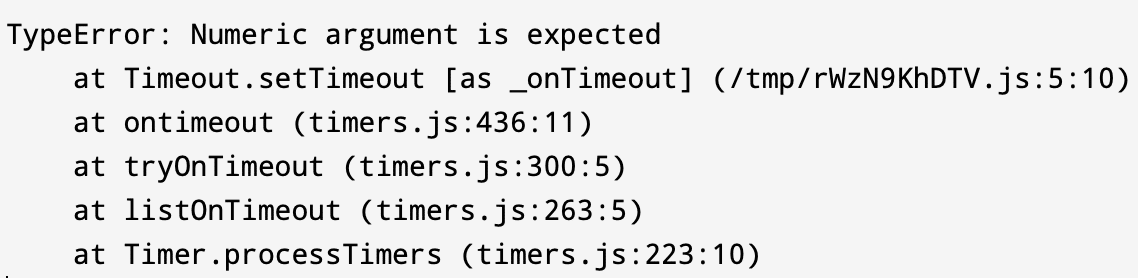
Wie du sehen kannst, werden zunächst der Fehlername und die Fehlermeldung ausgegeben, gefolgt von einer Liste der Methoden, die aufgerufen wurden. Für jeden Methodenaufruf werden die Stelle im Quellcode und die Zeile, in der er aufgerufen wurde, angegeben. Mit diesen Daten kannst du durch deine Codebasis navigieren und herausfinden, welcher Teil des Codes den Fehler verursacht.
Diese Liste der Methoden ist übereinander angeordnet. Sie zeigt, wo die Ausnahme zuerst ausgelöst wurde und wie sie sich durch die gestapelten Methodenaufrufe ausgebreitet hat. Wenn du eine Catch-Funktion für die Ausnahme implementierst, kann sie sich nicht über den Stack ausbreiten und dein Programm zum Absturz bringen. Es kann jedoch vorkommen, dass du fatale Fehler absichtlich nicht abfängst, um das Programm in bestimmten Szenarien zum Absturz zu bringen.
Fehler vs. Ausnahmen
Die meisten Menschen betrachten Fehler und Ausnahmen als ein und dasselbe. Es gibt jedoch einen kleinen, aber grundlegenden Unterschied zwischen ihnen.
Um das besser zu verstehen, lass uns ein kurzes Beispiel nehmen. Hier siehst du, wie du einen Fehler in JavaScript definieren kannst:
const wrongTypeError = TypeError("Wrong type found, expected character")Und so wird das wrongTypeError objekt zu einer Ausnahme:
throw wrongTypeErrorDie meisten Leute neigen jedoch dazu, die Kurzform zu verwenden, die Fehlerobjekte definiert, während sie geworfen werden:
throw TypeError("Wrong type found, expected character")Das ist eine gängige Praxis. Das ist jedoch einer der Gründe, warum Entwickler dazu neigen, Ausnahmen und Fehler zu verwechseln. Deshalb ist es wichtig, die Grundlagen zu kennen, auch wenn du die Kurzschrift benutzt, um deine Arbeit schnell zu erledigen.
Arten von Fehlern in JavaScript
Es gibt eine Reihe von vordefinierten Fehlertypen in JavaScript. Sie werden automatisch von der JavaScript-Laufzeitumgebung ausgewählt und definiert, wenn der Programmierer Fehler in der Anwendung nicht explizit behandelt.
In diesem Abschnitt lernst du einige der häufigsten Fehlerarten in JavaScript kennen und erfährst, wann und warum sie auftreten.
RangeError
Ein RangeError wird ausgelöst, wenn eine Variable mit einem Wert gesetzt wird, der außerhalb ihres zulässigen Wertebereichs liegt. Er tritt normalerweise auf, wenn ein Wert als Argument an eine Funktion übergeben wird und der angegebene Wert nicht im Bereich der Funktionsparameter liegt. Bei der Verwendung von schlecht dokumentierten Bibliotheken von Drittanbietern kann es manchmal schwierig sein, diesen Fehler zu beheben, da du den Bereich der möglichen Werte für die Argumente kennen musst, um den richtigen Wert zu übergeben.
Einige der häufigsten Szenarien, in denen RangeError auftritt, sind:
- Der Versuch, ein Array mit unzulässiger Länge über den Array-Konstruktor zu erstellen.
- Übergabe falscher Werte an numerische Methoden wie
toExponential(),toPrecision(),toFixed(), etc. - Übergabe von unzulässigen Werten an String-Funktionen wie
normalize().
ReferenceError
Ein ReferenceError tritt auf, wenn etwas mit der Referenz einer Variablen in deinem Code nicht stimmt. Vielleicht hast du vergessen, einen Wert für die Variable zu definieren, bevor du sie benutzt, oder du versuchst, eine unzugängliche Variable in deinem Code zu verwenden. In jedem Fall liefert der Stacktrace genügend Informationen, um die fehlerhafte Variablenreferenz zu finden und zu beheben.
Einige der häufigsten Gründe, warum ReferenceErrors auftreten, sind:
- Ein Tippfehler in einem Variablennamen.
- Der Versuch, auf Block-Scoped-Variablen außerhalb ihres Scopes zuzugreifen.
- Verweis auf eine globale Variable aus einer externen Bibliothek (z. B. $ aus jQuery), bevor sie geladen wurde.
SyntaxError
Diese Fehler sind mit am einfachsten zu beheben, da sie auf einen Fehler in der Syntax des Codes hinweisen. Da JavaScript eine Skriptsprache ist, die interpretiert und nicht kompiliert wird, werden diese Fehler ausgelöst, wenn die App das Skript ausführt, das den Fehler enthält. Bei kompilierten Sprachen werden solche Fehler während der Kompilierung erkannt. Daher werden die Binärdateien der App erst erstellt, wenn sie behoben sind.
Einige der häufigsten Gründe, warum SyntaxErrors auftreten können, sind:
- Fehlende Anführungszeichen
- Fehlende schließende Klammern
- Falsche Ausrichtung von geschweiften Klammern oder anderen Zeichen
Es ist eine gute Praxis, ein Linting-Tool in deiner IDE zu verwenden, um solche Fehler zu erkennen, bevor sie im Browser erscheinen.
TypeError
TypeError ist einer der häufigsten Fehler in JavaScript-Anwendungen. Dieser Fehler tritt auf, wenn ein Wert nicht dem erwarteten Typ entspricht. Einige der häufigsten Fälle, in denen er auftritt, sind:
- Aufrufen von Objekten, die keine Methoden sind.
- Der Versuch, auf Eigenschaften von null oder undefinierten Objekten zuzugreifen
- Behandlung einer Zeichenkette als Zahl oder andersherum
Es gibt noch viel mehr Möglichkeiten, wo ein TypeError auftreten kann. Wir werden uns später einige bekannte Fälle ansehen und lernen, wie man sie beheben kann.
InternalError
Der Typ InternalError wird verwendet, wenn eine Ausnahme in der JavaScript-Laufzeit-Engine auftritt. Das kann auf ein Problem in deinem Code hindeuten, muss es aber nicht.
In den meisten Fällen tritt InternalError nur in zwei Szenarien auf:
- Wenn ein Patch oder ein Update für die JavaScript-Laufzeitumgebung einen Fehler enthält, der Ausnahmen auslöst (dies kommt sehr selten vor)
- Wenn dein Code Elemente enthält, die für die JavaScript-Engine zu groß sind (z. B. zu viele Switch-Cases, zu große Array-Initialisierungen, zu viele Rekursionen)
Der beste Ansatz zur Lösung dieses Fehlers besteht darin, die Ursache anhand der Fehlermeldung zu identifizieren und deine App-Logik nach Möglichkeit umzustrukturieren, um die plötzliche Belastungsspitze der JavaScript-Engine zu beseitigen.
URIError
URIError tritt auf, wenn eine globale URI-Verarbeitungsfunktion wie decodeURIComponent unrechtmäßig verwendet wird. Er zeigt in der Regel an, dass der an den Methodenaufruf übergebene Parameter nicht den URI-Standards entspricht und daher von der Methode nicht richtig geparst wurde.
Die Diagnose dieser Fehler ist in der Regel einfach, da du nur die Argumente auf Fehler untersuchen musst.
EvalError
Ein EvalError tritt auf, wenn ein Fehler bei einem eval() Funktionsaufruf auftritt. Die Funktion eval() wird verwendet, um in Zeichenketten gespeicherten JavaScript-Code auszuführen. Da jedoch von der Verwendung der Funktion eval() aus Sicherheitsgründen dringend abgeraten wird und die aktuellen ECMAScript-Spezifikationen die Klasse EvalError nicht mehr auslösen, gibt es diesen Fehlertyp nur, um die Abwärtskompatibilität mit altem JavaScript-Code zu wahren.
Wenn du mit einer älteren Version von JavaScript arbeitest, kann es sein, dass du auf diesen Fehler stößt. In jedem Fall ist es am besten, den Code des eval() Funktionsaufrufs auf Ausnahmen zu untersuchen.
Benutzerdefinierte Fehlertypen erstellen
JavaScript bietet zwar eine ausreichende Liste von Fehlertypklassen, die die meisten Szenarien abdecken, aber du kannst jederzeit einen neuen Fehlertyp erstellen, wenn die Liste deine Anforderungen nicht erfüllt. Die Grundlage für diese Flexibilität liegt in der Tatsache, dass JavaScript es dir erlaubt, mit dem Befehl throw buchstäblich alles zu werfen.
Technisch gesehen sind diese Anweisungen also völlig legal:
throw 8
throw "An error occurred"Das ausgeben eines primitiven Datentyps liefert jedoch keine Details über den Fehler, wie z. B. den Typ, den Namen oder den zugehörigen Stack-Trace. Um dies zu beheben und die Fehlerbehandlung zu standardisieren, wurde die Klasse Error eingeführt. Es wird auch davon abgeraten, primitive Datentypen beim Auslösen von Ausnahmen zu verwenden.
Du kannst die Klasse Error erweitern, um deine eigene Fehlerklasse zu erstellen. Hier ist ein einfaches Beispiel dafür, wie du das machen kannst:
class ValidationError extends Error {
constructor(message) {
super(message);
this.name = "ValidationError";
}
}Du kannst die Klasse auf folgende Weise verwenden:
throw ValidationError("Property not found: name")Und du kannst es dann mit dem Schlüsselwort instanceof identifizieren:
try {
validateForm() // code that throws a ValidationError
} catch (e) {
if (e instanceof ValidationError)
// do something
else
// do something else
}Top 10 der häufigsten Fehler in JavaScript
Jetzt, wo du die gängigen Fehlertypen kennst und weißt, wie du deine eigenen erstellen kannst, ist es an der Zeit, dir einige der häufigsten Fehler anzusehen, mit denen du beim Schreiben von JavaScript-Code konfrontiert wirst.
Schau dir unseren Video-Leitfaden zu den häufigsten JavaScript-Fehlern an
1. Uncaught RangeError
Dieser Fehler tritt in Google Chrome unter verschiedenen Umständen auf. Zunächst kann er auftreten, wenn du eine rekursive Funktion aufrufst und diese nicht beendet wird. Du kannst dies selbst in der Chrome Developer Console überprüfen:
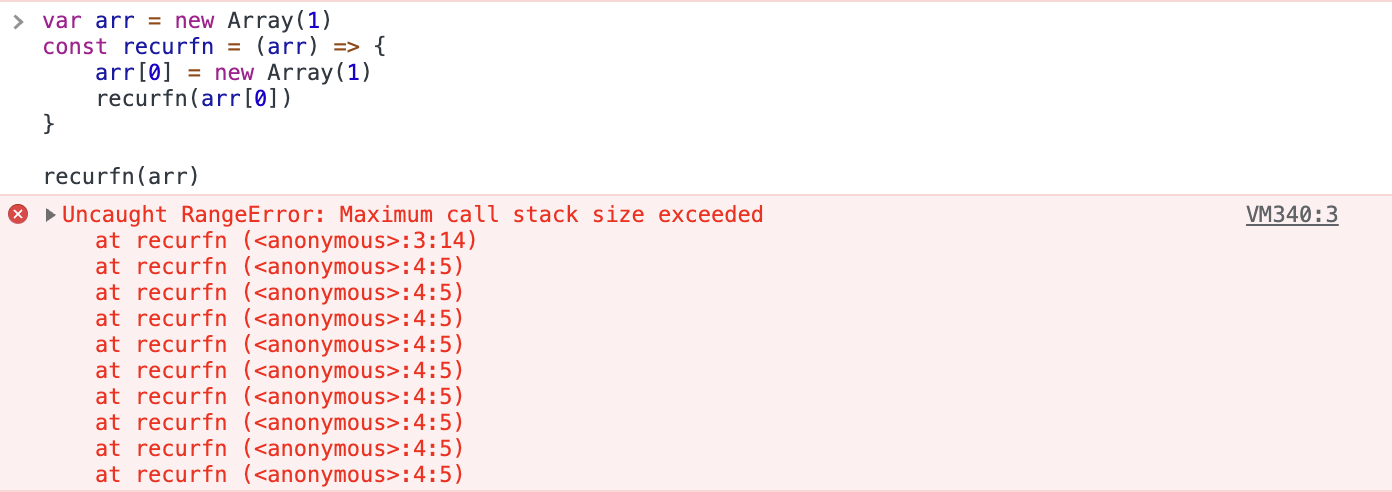
Um einen solchen Fehler zu beheben, musst du sicherstellen, dass du die Grenzfälle deiner rekursiven Funktion richtig definierst. Ein weiterer Grund, warum dieser Fehler auftritt, ist, wenn du einen Wert übergeben hast, der außerhalb des Parameterbereichs einer Funktion liegt. Hier ist ein Beispiel:

Die Fehlermeldung zeigt normalerweise an, was in deinem Code falsch ist. Sobald du die Änderungen vornimmst, wird der Fehler behoben sein.

2. Uncaught TypeError: Cannot set property
Dieser Fehler tritt auf, wenn du eine Eigenschaft auf eine undefinierte Referenz setzt. Du kannst das Problem mit diesem Code reproduzieren:
var list
list.count = 0Hier ist die Ausgabe, die du erhalten wirst:

Um diesen Fehler zu beheben, initialisiere die Referenz mit einem Wert, bevor du auf ihre Eigenschaften zugreifst. So sieht es aus, wenn er behoben ist:

3. Uncaught TypeError: Cannot read property
Dies ist einer der am häufigsten auftretenden Fehler in JavaScript. Dieser Fehler tritt auf, wenn du versuchst, eine Eigenschaft zu lesen oder eine Funktion für ein undefiniertes Objekt aufzurufen. Du kannst ihn ganz einfach reproduzieren, indem du den folgenden Code in der Chrome Developer Konsole ausführst:
var func
func.call()Hier ist die Ausgabe:

Ein undefiniertes Objekt ist eine der vielen möglichen Ursachen für diesen Fehler. Eine weitere Ursache kann eine falsche Initialisierung des Zustands beim Rendern der Benutzeroberfläche sein. Hier ist ein praktisches Beispiel aus einer React-Anwendung:
import React, { useState, useEffect } from "react";
const CardsList = () => {
const [state, setState] = useState();
useEffect(() => {
setTimeout(() => setState({ items: ["Card 1", "Card 2"] }), 2000);
}, []);
return (
<>
{state.items.map((item) => (
<li key={item}>{item}</li>
))}
</>
);
};
export default CardsList;Die Anwendung startet mit einem leeren Zustandscontainer und wird nach einer Verzögerung von 2 Sekunden mit einigen Elementen versorgt. Die Verzögerung wurde eingebaut, um einen Netzwerkaufruf zu imitieren. Selbst wenn dein Netzwerk superschnell ist, wirst du mit einer kleinen Verzögerung rechnen müssen, durch die die Komponente mindestens einmal gerendert wird. Wenn du versuchst, diese App auszuführen, erhältst du die folgende Fehlermeldung:
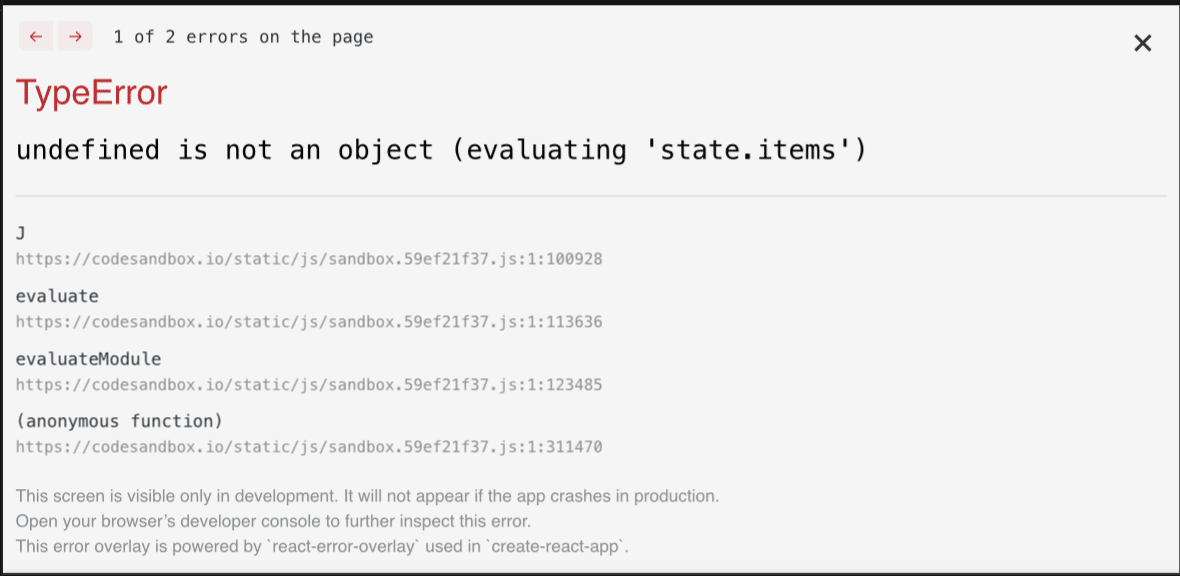
Das liegt daran, dass der Zustandscontainer zum Zeitpunkt des Renderns undefiniert ist; es gibt also keine Eigenschaft items für ihn. Diesen Fehler zu beheben ist einfach. Du musst dem Zustandscontainer nur einen Standardwert zuweisen.
// ...
const [state, setState] = useState({items: []});
// ...Nach der eingestellten Verzögerung wird deine App nun eine ähnliche Ausgabe zeigen:

Die genaue Lösung in deinem Code könnte anders aussehen, aber das Wichtigste ist, dass du deine Variablen immer richtig initialisierst, bevor du sie benutzt.
4. TypeError: ‚undefined‘ ist kein Objekt
Dieser Fehler tritt in Safari auf, wenn du versuchst, auf die Eigenschaften eines undefinierten Objekts zuzugreifen oder eine Methode aufzurufen. Du kannst den gleichen Code wie oben ausführen, um den Fehler selbst zu reproduzieren.

Die Lösung für diesen Fehler ist ebenfalls dieselbe – stelle sicher, dass du deine Variablen richtig initialisiert hast und sie nicht undefiniert sind, wenn auf eine Eigenschaft oder Methode zugegriffen wird.
5. TypeError: null ist kein Objekt
Auch dieser Fehler ist ähnlich wie der vorherige. Er tritt bei Safari auf. Der einzige Unterschied zwischen den beiden Fehlern ist, dass dieser Fehler ausgelöst wird, wenn das Objekt, auf dessen Eigenschaft oder Methode zugegriffen wird, null und nicht undefined ist. Du kannst diesen Fehler reproduzieren, indem du den folgenden Code ausführst:
var func = null
func.call()Hier ist die Ausgabe, die du erhalten wirst:

Da null ein Wert ist, der explizit auf eine Variable gesetzt wird und nicht automatisch von JavaScript zugewiesen wird. Dieser Fehler kann nur auftreten, wenn du versuchst, auf eine Variable zuzugreifen, die du null selbst gesetzt hast. Du musst also deinen Code überarbeiten und überprüfen, ob die Logik, die du geschrieben hast, korrekt ist.
6. TypeError: Eigenschaft ‚length‘ kann nicht gelesen werden
Dieser Fehler tritt in Chrome auf, wenn du versuchst, die Länge eines null oder undefined Objekts zu lesen. Die Ursache für dieses Problem ist ähnlich wie bei den vorherigen Problemen, aber es tritt recht häufig beim Umgang mit Listen auf und verdient daher eine besondere Erwähnung. Hier erfährst du, wie du das Problem reproduzieren kannst:
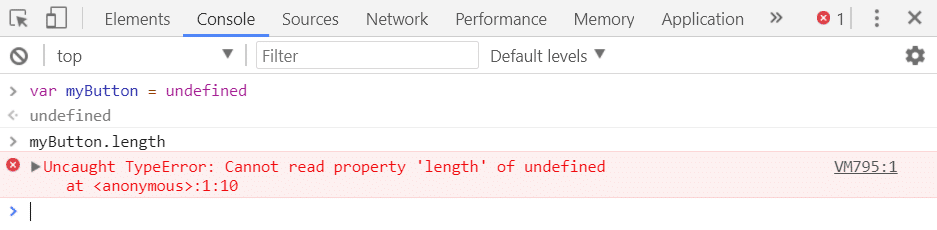
In den neueren Versionen von Chrome wird dieser Fehler jedoch als Uncaught TypeError: Cannot read properties of undefined gemeldet. So sieht es jetzt aus:

Die Lösung besteht wiederum darin, sicherzustellen, dass das Objekt, auf dessen Länge du zugreifen willst, existiert und nicht auf null gesetzt ist.
7. TypeError: ‚undefined‘ ist keine Funktion
Dieser Fehler tritt auf, wenn du versuchst, eine Methode aufzurufen, die es in deinem Skript nicht gibt oder die zwar existiert, aber im aufrufenden Kontext nicht referenziert werden kann. Dieser Fehler tritt normalerweise in Google Chrome auf und du kannst ihn lösen, indem du die Codezeile überprüfst, die den Fehler verursacht. Wenn du einen Tippfehler findest, korrigiere ihn und prüfe, ob dein Problem dadurch gelöst wird.
Wenn du das selbstreferenzierende Schlüsselwort this in deinem Code verwendet hast, kann dieser Fehler auftreten, wenn this nicht ordnungsgemäß an deinen Kontext gebunden ist. Betrachte den folgenden Code:
function showAlert() {
alert("message here")
}
document.addEventListener("click", () => {
this.showAlert();
})Wenn du den obigen Code ausführst, wird er den besprochenen Fehler auslösen. Das liegt daran, dass die anonyme Funktion, die als Ereignis-Listener übergeben wird, im Kontext von document ausgeführt wird.
Im Gegensatz dazu ist die Funktion showAlert im Kontext der window definiert.
Um dieses Problem zu lösen, musst du die richtige Referenz auf die Funktion übergeben, indem du sie mit der Methode bind() bindest:
document.addEventListener("click", this.showAlert.bind(this))8. ReferenceError: event is not defined
Dieser Fehler tritt auf, wenn du versuchst, auf eine Referenz zuzugreifen, die im aufrufenden Bereich nicht definiert ist. Das passiert in der Regel beim Umgang mit Ereignissen, da sie dir in der Callback-Funktion oft eine Referenz namens event zur Verfügung stellen. Dieser Fehler kann auftreten, wenn du vergisst, das Ereignisargument in den Parametern deiner Funktion zu definieren oder es falsch schreibst.
Im Internet Explorer und in Google Chrome tritt dieser Fehler zwar nicht auf (da der IE eine globale Ereignisvariable anbietet und Chrome die Ereignisvariable automatisch an den Handler anhängt), aber in Firefox kann er auftreten. Es ist also ratsam, nach solchen kleinen Fehlern Ausschau zu halten.
9. TypeError: Zuweisung an konstante Variable
Dies ist ein Fehler, der aus Unachtsamkeit entsteht. Wenn du versuchst, einer konstanten Variablen einen neuen Wert zuzuweisen, wirst du mit einem solchen Ergebnis konfrontiert:

Auch wenn es im Moment einfach zu beheben scheint, stell dir vor, du hast hunderte solcher Variablendeklarationen und eine davon ist fälschlicherweise als const statt als let definiert! Im Gegensatz zu anderen Skriptsprachen wie PHP gibt es in JavaScript nur minimale Unterschiede bei der Deklaration von Konstanten und Variablen. Deshalb ist es ratsam, deine Deklarationen zuerst zu überprüfen, wenn du diesen Fehler siehst. Dieser Fehler kann auch auftreten, wenn du vergisst, dass die besagte Referenz eine Konstante ist und sie als Variable benutzt. Das deutet entweder auf Unachtsamkeit oder einen Fehler in der Logik deiner Anwendung hin. Überprüfe das unbedingt, wenn du versuchst, dieses Problem zu beheben.
10. (unbekannt): Skript-Fehler
Ein Skriptfehler tritt auf, wenn ein Skript eines Drittanbieters einen Fehler an deinen Browser sendet. Dieser Fehler wird von (unbekannt) gefolgt , weil das Skript eines Drittanbieters zu einer anderen Domain gehört als deine App. Der Browser verbirgt andere Details, um zu verhindern, dass sensible Informationen vom Skript des Drittanbieters durchsickern.
Du kannst diesen Fehler nicht beheben, ohne die vollständigen Details zu kennen. Hier ist, was du tun kannst, um mehr Informationen über den Fehler zu erhalten:
- Füge das Attribut
crossoriginin das Skript-Tag ein. - Setze den richtigen
Access-Control-Allow-OriginHeader auf dem Server, der das Skript hostet. - [Optional] Wenn du keinen Zugriff auf den Server hast, auf dem das Skript gehostet wird, kannst du einen Proxy verwenden, der deine Anfrage an den Server weiterleitet und mit den richtigen Headern an den Client zurückschickt.
Sobald du die Details des Fehlers kennst, kannst du dich daran machen, das Problem zu beheben, das wahrscheinlich entweder mit der Bibliothek des Drittanbieters oder dem Netzwerk zusammenhängt.
Wie du Fehler in JavaScript erkennst und vermeidest
Auch wenn die oben genannten Fehler die häufigsten sind, auf die du in JavaScript stoßen wirst, reicht es nie aus, sich auf ein paar Beispiele zu verlassen. Es ist wichtig zu wissen, wie du bei der Entwicklung einer JavaScript-Anwendung alle Arten von Fehlern erkennen und verhindern kannst. Hier erfährst du, wie du mit Fehlern in JavaScript umgehen kannst.
Manuelles Ausgeben und Lösen von Fehlern
Die grundlegendste Art, mit Fehlern umzugehen, die entweder manuell oder von der Laufzeit ausgelöst wurden, ist, sie abzufangen. Wie die meisten anderen Sprachen bietet auch JavaScript eine Reihe von Schlüsselwörtern zur Fehlerbehebung. Es ist wichtig, dass du jedes dieser Schlüsselwörter genau kennst, bevor du dich daran machst, Fehler in deiner JavaScript-App zu beheben.
throw
Das erste und grundlegendste Schlüsselwort der Gruppe ist throw. Wie du siehst, wird das throw-Schlüsselwort verwendet, um Fehler auszulösen und manuell Ausnahmen in der JavaScript-Laufzeit zu erzeugen. Wir haben dies bereits weiter oben in diesem Artikel besprochen, und hier ist die Bedeutung dieses Schlüsselworts im Wesentlichen:
- Du kannst
throwalles geben, auch Zahlen, Strings undErrorObjekte. - Es ist jedoch nicht ratsam, primitive Datentypen wie Strings und Zahlen zu nehmen, da sie keine Debug-Informationen über die Fehler enthalten.
- Beispiel
throw TypeError("Please provide a string")
try
Das Schlüsselwort try wird verwendet, um anzuzeigen, dass ein Codeblock eine Ausnahme auslösen könnte. Seine Syntax lautet:
try {
// error-prone code here
}Es ist wichtig zu beachten, dass ein catch Block immer auf den try Block folgen muss, um Fehler effektiv zu behandeln.
catch
Das Schlüsselwort catch wird verwendet, um einen catch-Block zu erstellen. Dieser Codeblock ist für die Behandlung von Fehlern zuständig, die der nachfolgende try Block auffängt. Hier ist seine Syntax:
catch (exception) {
// code to handle the exception here
}Und so implementierst du die Blöcke try und catch zusammen:
try {
// business logic code
} catch (exception) {
// error handling code
}Anders als in C++ oder Java kannst du in JavaScript nicht mehrere catch Blöcke an einen try Block anhängen. Das bedeutet, dass du das nicht tun kannst:
try {
// business logic code
} catch (exception) {
if (exception instanceof TypeError) {
// do something
}
} catch (exception) {
if (exception instanceof RangeError) {
// do something
}
}Stattdessen kannst du eine if...else Anweisung oder eine switch case Anweisung innerhalb des einzelnen catch-Blocks verwenden, um alle möglichen Fehlerfälle zu behandeln. Das würde dann so aussehen:
try {
// business logic code
} catch (exception) {
if (exception instanceof TypeError) {
// do something
} else if (exception instanceof RangeError) {
// do something else
}
}finally
Das Schlüsselwort finally wird verwendet, um einen Codeblock zu definieren, der ausgeführt wird, nachdem ein Fehler behandelt worden ist. Dieser Block wird nach den try- und catch-Blöcken ausgeführt.
Außerdem wird der finally-Block unabhängig vom Ergebnis der anderen beiden Blöcke ausgeführt. Das bedeutet, dass der Interpreter den Code im finally-Block ausführt, bevor das Programm abstürzt, selbst wenn der catch-Block den Fehler nicht vollständig behandeln kann oder ein Fehler im catch-Block ausgelöst wird.
Um als gültig zu gelten, muss auf den try-Block in JavaScript entweder ein catch- oder ein finally-Block folgen. Ohne einen dieser Blöcke löst der Interpreter einen SyntaxError aus. Achte deshalb darauf, dass du deinen try-Blöcken mindestens einen dieser beiden Blöcke folgen lässt, wenn du Fehler behandelst.
Globale Fehlerbehandlung mit der Methode onerror()
Die Methode onerror() steht für alle HTML-Elemente zur Verfügung, um Fehler zu behandeln, die bei ihnen auftreten können. Wenn zum Beispiel ein img -Tag das Bild, dessen URL angegeben ist, nicht finden kann, wird seine onerror-Methode ausgelöst, damit der Benutzer den Fehler behandeln kann.
Normalerweise würdest du im onerror-Aufruf eine andere Bild-URL angeben, auf die der img -Tag zurückgreifen kann. So kannst du das mit JavaScript machen:
const image = document.querySelector("img")
image.onerror = (event) => {
console.log("Error occurred: " + event)
}Du kannst diese Funktion aber auch nutzen, um einen globalen Fehlerbehandlungsmechanismus für deine App zu erstellen. So kannst du das tun:
window.onerror = (event) => {
console.log("Error occurred: " + event)
}Mit diesem Event-Handler kannst du dich von den vielen try...catch Blöcken in deinem Code befreien und die Fehlerbehandlung in deiner App ähnlich wie die Ereignisbehandlung zentralisieren. Du kannst mehrere Fehlerhandler an das Fenster anhängen, um das Single-Responsibility-Prinzip aus den SOLID-Designprinzipien zu wahren. Der Interpreter wird alle Handler durchlaufen, bis er den richtigen erreicht.
Übergabe von Fehlern über Callbacks
Während einfache und lineare Funktionen eine einfache Fehlerbehebung ermöglichen, können Rückrufe die Angelegenheit verkomplizieren.
Betrachte das folgende Stück Code:
const calculateCube = (number, callback) => {
setTimeout(() => {
const cube = number * number * number
callback(cube)
}, 1000)
}
const callback = result => console.log(result)
calculateCube(4, callback)Die obige Funktion demonstriert einen asynchronen Zustand, in dem eine Funktion einige Zeit braucht, um Operationen zu verarbeiten und das Ergebnis später mit Hilfe eines Rückrufs zurückgibt.
Wenn du versuchst, in den Funktionsaufruf eine Zeichenkette anstelle von 4 einzugeben, erhältst du als Ergebnis NaN.
Das muss richtig gehandhabt werden. So geht’s:
const calculateCube = (number, callback) => {
setTimeout(() => {
if (typeof number !== "number")
throw new Error("Numeric argument is expected")
const cube = number * number * number
callback(cube)
}, 1000)
}
const callback = result => console.log(result)
try {
calculateCube(4, callback)
} catch (e) { console.log(e) }Damit sollte das Problem im Idealfall gelöst sein. Wenn du jedoch versuchst, eine Zeichenkette an den Funktionsaufruf zu übergeben, bekommst du Folgendes zu sehen:

Obwohl du beim Aufruf der Funktion einen try-catch-Block implementiert hast, heißt es immer noch, der Fehler sei nicht gefunden. Der Fehler wird aufgrund der Timeout-Verzögerung erst nach der Ausführung des catch-Blocks ausgelöst.
Das kann bei Netzwerkaufrufen schnell passieren, wenn sich unerwartete Verzögerungen einschleichen. Du musst solche Fälle bei der Entwicklung deiner App abdecken.
Hier erfährst du, wie du Fehler in Callbacks richtig beheben kannst:
const calculateCube = (number, callback) => {
setTimeout(() => {
if (typeof number !== "number") {
callback(new TypeError("Numeric argument is expected"))
return
}
const cube = number * number * number
callback(null, cube)
}, 2000)
}
const callback = (error, result) => {
if (error !== null) {
console.log(error)
return
}
console.log(result)
}
try {
calculateCube('hey', callback)
} catch (e) {
console.log(e)
}Die Ausgabe auf der Konsole wird nun sein:

Dies zeigt an, dass der Fehler angemessen behandelt wurde.
Fehler in Promises behandeln
Die meisten Menschen bevorzugen Promises für die Behandlung asynchroner Aktivitäten. Promises haben einen weiteren Vorteil – ein abgelehntes Promise beendet dein Skript nicht. Trotzdem musst du einen catch-Block implementieren, um Fehler in Promises zu behandeln. Um das besser zu verstehen, wollen wir die Funktion calculateCube() mit Promises umschreiben:
const delay = ms => new Promise(res => setTimeout(res, ms));
const calculateCube = async (number) => {
if (typeof number !== "number")
throw Error("Numeric argument is expected")
await delay(5000)
const cube = number * number * number
return cube
}
try {
calculateCube(4).then(r => console.log(r))
} catch (e) { console.log(e) }Die Zeitüberschreitung aus dem vorherigen Code wurde zum besseren Verständnis in die Funktion delay ausgelagert. Wenn du versuchst, eine Zeichenkette statt 4 einzugeben, bekommst du eine ähnliche Ausgabe wie diese:

Auch hier liegt es daran, dass Promise den Fehler auslöst, nachdem alles andere bereits ausgeführt wurde. Die Lösung für dieses Problem ist einfach. Füge der Promise-Kette einfach einen catch() -Aufruf wie folgt hinzu:
calculateCube("hey")
.then(r => console.log(r))
.catch(e => console.log(e))Jetzt lautet die Ausgabe:

Du kannst sehen, wie einfach es ist, Fehler mit Versprechen zu behandeln. Außerdem kannst du einen finally() Block und den Aufruf des Versprechens verketten, um Code hinzuzufügen, der nach Abschluss der Fehlerbehandlung ausgeführt wird.
Alternativ kannst du Fehler in Versprechen auch mit der traditionellen try-catch-finally-Technik behandeln. So würde dein Versprechensaufruf in diesem Fall aussehen:
try {
let result = await calculateCube("hey")
console.log(result)
} catch (e) {
console.log(e)
} finally {
console.log('Finally executed")
}Dies funktioniert jedoch nur innerhalb einer asynchronen Funktion. Daher ist die bevorzugte Methode zur Behandlung von Fehlern in Versprechen die Verkettung von catch und finally mit dem Aufruf des Versprechens.
throw/catch vs onerror() vs Callbacks vs Promises: Was ist das Beste?
Da dir vier Methoden zur Verfügung stehen, musst du wissen, wie du die am besten geeignete für einen bestimmten Anwendungsfall auswählen kannst. Im Folgenden erfährst du, wie du das für dich entscheiden kannst:
throw/catch
Diese Methode wirst du die meiste Zeit verwenden. Achte darauf, dass du in deinem Catch-Block Bedingungen für alle möglichen Fehler implementierst, und vergiss nicht, einen Finally-Block einzufügen, wenn du nach dem Try-Block einige Speicherbereinigungsroutinen ausführen musst.
Zu viele try/catch-Blöcke können jedoch dazu führen, dass dein Code schwer zu pflegen ist. Wenn du dich in einer solchen Situation befindest, solltest du Fehler über den globalen Handler oder die promise-Methode beheben.
Bei der Entscheidung zwischen asynchronen try/catch-Blöcken und dem Versprechen catch() ist es ratsam, sich für die asynchronen try/catch-Blöcke zu entscheiden, da sie deinen Code linear und leicht zu debuggen machen.
onerror()
Die Methode onerror() ist am besten geeignet, wenn du weißt, dass deine App viele Fehler behandeln muss und diese über die gesamte Codebasis verstreut sein können. Die Methode onerror ermöglicht es dir, Fehler so zu behandeln, als wären sie ein weiteres Ereignis, das von deiner Anwendung behandelt wird. Du kannst mehrere Fehlerhandler definieren und sie beim ersten Rendering an das Fenster deiner Anwendung anhängen.
Du musst aber auch bedenken, dass die onerror() Methode in kleineren Projekten mit geringerer Fehleranfälligkeit unnötig schwierig einzurichten sein kann. Wenn du dir sicher bist, dass deine App nicht zu viele Fehler auslöst, ist die traditionelle throw/catch-Methode am besten für dich geeignet.
Callbacks und Promises
Die Fehlerbehandlung in Callbacks und Promises unterscheidet sich aufgrund ihres Codedesigns und ihrer Struktur. Wenn du dich jedoch zwischen diesen beiden entscheiden musst, bevor du deinen Code geschrieben hast, ist es am besten, sich für Promises zu entscheiden.
Das liegt daran, dass Versprechen ein eingebautes Konstrukt zur Verkettung eines catch() und eines finally() Blocks haben, um Fehler einfach zu behandeln. Diese Methode ist einfacher und sauberer als die Definition zusätzlicher Argumente oder die Wiederverwendung vorhandener Argumente zur Fehlerbehandlung.
Änderungen mit Git Repositories nachverfolgen
Viele Fehler entstehen oft durch manuelle Fehler in der Codebasis. Beim Entwickeln oder Debuggen deines Codes kann es passieren, dass du unnötige Änderungen vornimmst, die zu neuen Fehlern in deiner Codebasis führen können. Automatisierte Tests sind eine gute Möglichkeit, um deinen Code nach jeder Änderung zu überprüfen. Sie können dir aber nur sagen, ob etwas falsch ist. Wenn du nicht regelmäßig Sicherungskopien deines Codes erstellst, verschwendest du Zeit mit dem Versuch, eine Funktion oder ein Skript zu reparieren, das vorher einwandfrei funktioniert hat.
An dieser Stelle kommt Git ins Spiel. Mit einer guten Commit-Strategie kannst du deine Git-Historie als Backup-System nutzen, um deinen Code im Laufe der Entwicklung zu betrachten. Du kannst ganz einfach durch deine älteren Commits blättern und herausfinden, welche Version der Funktion vorher einwandfrei funktionierte, aber nach einer Änderung, die nichts mit dem Code zu tun hat, Fehler auslöst.
Du kannst dann den alten Code wiederherstellen oder die beiden Versionen vergleichen, um herauszufinden, was falsch gelaufen ist. Moderne Webentwicklungs-Tools wie GitHub Desktop oder GitKraken helfen dir, diese Änderungen nebeneinander zu sehen und die Fehler schnell zu finden.
Eine Gewohnheit, die dir helfen kann, weniger Fehler zu machen, ist die Durchführung von Code-Reviews bei jeder größeren Änderung an deinem Code. Wenn du in einem Team arbeitest, kannst du einen Pull Request erstellen und ihn von einem Teammitglied gründlich überprüfen lassen. So hast du ein zweites Paar Augen, um Fehler zu entdecken, die dir vielleicht entgangen sind.
Best Practices für den Umgang mit Fehlern in JavaScript
Die oben genannten Methoden sind ausreichend, um eine robuste Fehlerbehandlung für deine nächste JavaScript-Anwendung zu entwickeln. Allerdings solltest du bei der Umsetzung ein paar Dinge beachten, um das Beste aus deiner Fehlersicherung herauszuholen. Hier sind einige Tipps, die dir dabei helfen.
1. Verwende benutzerdefinierte Fehler bei der Behandlung von Betriebsausnahmen
Wir haben benutzerdefinierte Fehler zu Beginn dieses Leitfadens eingeführt, um dir eine Vorstellung davon zu geben, wie du die Fehlerbehebung an den speziellen Fall deiner Anwendung anpassen kannst. Es ist ratsam, wann immer möglich benutzerdefinierte Fehler anstelle der generischen Klasse Error zu verwenden, da sie der aufrufenden Umgebung mehr kontextbezogene Informationen über den Fehler liefern.
Außerdem kannst du mit benutzerdefinierten Fehlern festlegen, wie ein Fehler in der aufrufenden Umgebung angezeigt wird. Das bedeutet, dass du bestimmte Details ausblenden oder zusätzliche Informationen über den Fehler anzeigen lassen kannst, wie und wann du willst.
Du kannst sogar so weit gehen, dass du den Inhalt des Fehlers nach deinen Wünschen formatierst. So hast du eine bessere Kontrolle darüber, wie der Fehler interpretiert und behandelt wird.
2. Keine Ausnahmen machen
Selbst die erfahrensten Entwickler machen oft einen Anfängerfehler – sie machen Ausnahmen tief in ihrem Code.
Du könntest in Situationen kommen, in denen du ein Stück Code hast, das optional ausgeführt werden soll. Wenn er funktioniert, ist das toll; wenn nicht, brauchst du nichts zu tun.
In solchen Fällen ist es oft verlockend, den Code in einen Try-Block zu packen und einen leeren Catch-Block daran zu hängen. Auf diese Weise lässt du jedoch zu, dass dieser Code einen Fehler verursacht und damit davonkommt. Das kann gefährlich werden, wenn du eine große Codebasis und viele Instanzen solcher schlechten Fehlermanagement-Konstrukte hast.
Der beste Weg, mit Ausnahmen umzugehen, besteht darin, eine Ebene zu bestimmen, auf der alle Ausnahmen behandelt werden, und sie bis dorthin aufzuheben. Diese Ebene kann ein Controller (in einer MVC-Architektur) oder eine Middleware (in einer traditionellen serverorientierten App) sein.
Auf diese Weise erfährst du, wo du alle in deiner App auftretenden Fehler findest und wie du sie beheben kannst, auch wenn das bedeutet, dass du nichts dagegen tun kannst.
3. Verwende eine zentrale Strategie für Logs und Fehlerwarnungen
Die Protokollierung eines Fehlers ist oft ein wesentlicher Bestandteil der Fehlerbehandlung. Wer keine zentrale Strategie für die Protokollierung von Fehlern entwickelt, dem entgehen möglicherweise wertvolle Informationen über die Nutzung seiner App.
Die Ereignisprotokolle einer App können dir helfen, wichtige Daten über Fehler herauszufinden und sie schnell zu beheben. Wenn du in deiner App geeignete Warnmechanismen eingerichtet hast, kannst du wissen, wenn ein Fehler in deiner App auftritt, bevor er einen großen Teil deiner Nutzer/innen erreicht.
Es ist ratsam, einen vorgefertigten Logger zu verwenden oder einen zu erstellen, der deinen Bedürfnissen entspricht. Du kannst diesen Logger so konfigurieren, dass er Fehler je nach Stufe behandelt (Warnung, Debug, Info usw.), und manche Logger gehen sogar so weit, dass sie die Protokolle sofort an entfernte Logging-Server senden. Auf diese Weise kannst du beobachten, wie sich die Logik deiner Anwendung bei aktiven Nutzern verhält.
4. Benutzer angemessen über Fehler benachrichtigen
Ein weiterer wichtiger Punkt, den du bei der Festlegung deiner Strategie für die Fehlerbehandlung beachten solltest, ist, dass du den Nutzer nicht aus den Augen verlierst.
Alle Fehler, die das normale Funktionieren deiner App beeinträchtigen, müssen dem Nutzer eine sichtbare Warnung geben, um ihn darauf hinzuweisen, dass etwas schief gelaufen ist, damit er versuchen kann, eine Lösung zu finden. Wenn du eine schnelle Lösung für den Fehler kennst, wie z. B. einen Vorgang erneut zu versuchen oder dich ab- und wieder anzumelden, solltest du dies in der Meldung erwähnen, damit der Fehler in Echtzeit behoben werden kann.
Bei Fehlern, die den normalen Betrieb nicht beeinträchtigen, kannst du die Meldung unterdrücken und den Fehler auf einem Remote-Server speichern, um ihn später zu beheben.
5. Implementiere eine Middleware (Node.js)
Die Node.js-Umgebung unterstützt Middlewares, um Funktionen zu Serveranwendungen hinzuzufügen. Du kannst diese Funktion nutzen, um eine Middleware zur Fehlerbehandlung für deinen Server zu erstellen.
Der größte Vorteil der Middleware ist, dass alle Fehler zentral an einer Stelle behandelt werden. Du kannst diese Einrichtung zu Testzwecken einfach aktivieren/deaktivieren.
Hier erfährst du, wie du eine einfache Middleware erstellen kannst:
const logError = err => {
console.log("ERROR: " + String(err))
}
const errorLoggerMiddleware = (err, req, res, next) => {
logError(err)
next(err)
}
const returnErrorMiddleware = (err, req, res, next) => {
res.status(err.statusCode || 500)
.send(err.message)
}
module.exports = {
logError,
errorLoggerMiddleware,
returnErrorMiddleware
}Du kannst diese Middleware dann wie folgt in deiner App verwenden:
const { errorLoggerMiddleware, returnErrorMiddleware } = require('./errorMiddleware')
app.use(errorLoggerMiddleware)
app.use(returnErrorMiddleware)Du kannst nun eigene Logik innerhalb der Middleware definieren, um Fehler angemessen zu behandeln. Du musst dich nicht mehr darum kümmern, einzelne Konstrukte zur Fehlerbehandlung in deiner Codebasis zu implementieren.
6. Neustart deiner App zur Behandlung von Programmierfehlern (Node.js)
Wenn Node.js-Apps auf Programmierfehler stoßen, müssen sie nicht unbedingt eine Ausnahme auslösen und versuchen, die App zu schließen. Solche Fehler können aus Programmierfehlern resultieren, wie z. B. ein hoher CPU-Verbrauch, Speicheraufblähung oder Speicherlecks. Der beste Weg, damit umzugehen, ist ein eleganter Neustart der App, indem du sie über den Node.js-Cluster-Modus oder ein spezielles Tool wie PM2 zum Absturz bringst. So kannst du sicherstellen, dass die App nicht bei einer Benutzeraktion abstürzt und ein schlechtes Benutzererlebnis bietet.
7. Catch All Uncaught Exceptions (Node.js)
Du kannst nie sicher sein, dass du alle möglichen Fehler, die in deiner App auftreten können, abgedeckt hast. Deshalb ist es wichtig, dass du eine Rückfallstrategie implementierst, um alle nicht abgefangenen Ausnahmen deiner App abzufangen.
Hier erfährst du, wie du das machen kannst:
process.on('uncaughtException', error => {
console.log("ERROR: " + String(error))
// other handling mechanisms
})Du kannst auch feststellen, ob es sich bei dem aufgetretenen Fehler um eine Standardausnahme oder um einen benutzerdefinierten Betriebsfehler handelt. Anhand des Ergebnisses kannst du den Prozess beenden und ihn neu starten, um unerwartetes Verhalten zu vermeiden.
8. Alle unbehandelten Promise-Abweisungen abfangen (Node.js)
Ähnlich wie du nie alle möglichen Ausnahmen abfangen kannst, ist die Wahrscheinlichkeit groß, dass du es verpasst, alle möglichen Ablehnungen von Versprechen zu behandeln. Im Gegensatz zu Ausnahmen werden bei Ablehnungen von Versprechen jedoch keine Fehler ausgelöst.
Ein wichtiges Versprechen, das abgelehnt wurde, könnte also als Warnung übersehen werden und deine App könnte auf ein unerwartetes Verhalten stoßen. Deshalb ist es wichtig, einen Fallback-Mechanismus für den Umgang mit Ablehnungen von Versprechen zu implementieren.
Hier erfährst du, wie du das machen kannst:
const promiseRejectionCallback = error => {
console.log("PROMISE REJECTED: " + String(error))
}
process.on('unhandledRejection', callback)Zusammenfassung
Wie in jeder anderen Programmiersprache sind Fehler auch in JavaScript recht häufig und natürlich. In manchen Fällen musst du sogar absichtlich Fehler auslösen, um deinen Benutzern die richtige Antwort zu geben. Daher ist es sehr wichtig, ihre Anatomie und Typen zu verstehen.
Außerdem musst du mit den richtigen Werkzeugen und Techniken ausgestattet sein, um Fehler zu erkennen und zu verhindern, dass sie deine Anwendung zum Absturz bringen.
In den meisten Fällen reicht eine solide Strategie zum Umgang mit Fehlern bei sorgfältiger Ausführung für alle Arten von JavaScript-Anwendungen aus.
Gibt es noch andere JavaScript-Fehler, die du noch nicht lösen konntest? Gibt es Techniken für den konstruktiven Umgang mit JS-Fehlern? Lass es uns in den Kommentaren unten wissen!

Kumar ist Softwareentwickler und technischer Autor in Indien. Er hat sich auf JavaScript und DevOps spezialisiert. Auf seiner Website kannst du mehr über seine Arbeit erfahren.

