
Para la mayoría de los vendedores, las actualizaciones constantes son necesarias para mantener su sitio fresco y mejorar su posicionamiento SEO.
Sin embargo, algunos sitios tienen cientos o incluso miles de páginas, lo que supone un reto para los equipos que envían manualmente las actualizaciones a los motores de búsqueda. Si el contenido se actualiza con tanta frecuencia, ¿cómo pueden asegurarse los equipos de que estas mejoras repercuten en su posicionamiento SEO?
Aquí es donde entran en juego los robots de rastreo. Un robot de rastreo web rastreará tu mapa web en busca de nuevas actualizaciones e indexará el contenido en los motores de búsqueda.
En este post, esbozaremos una lista exhaustiva de robots que cubre todos los robots de rastreo web que necesitas conocer. Antes de entrar en materia, vamos a definir los robots de rastreo web y a mostrar cómo funcionan.
Consulta Nuestro Videotutorial Sobre los Rastreadores Web Más Comunes
¿Qué es un rastreador web?
Un rastreador web es un programa informático que escanea automáticamente y lee sistemáticamente las páginas web para indexarlas para los motores de búsqueda. Los rastreadores web también se conocen como arañas o robots (bots).
Para que los motores de búsqueda presenten páginas web actualizadas y relevantes a los usuarios que inician una búsqueda, debe producirse un rastreo desde un bot rastreador web. Este proceso a veces puede producirse automáticamente (dependiendo de la configuración del rastreador y de tu sitio), o puede iniciarse directamente.
Existen muchos factores que influyen en la clasificación SEO de tus páginas, como la relevancia, los vínculos de retroceso, el alojamiento web y muchos otros. Sin embargo, nada de esto importa si los motores de búsqueda no rastrean e indexan tus páginas. Por eso es tan importante que te asegures de que tu sitio permite que se produzcan los rastreos correctos y que elimines cualquier barrera que se interponga en su camino.
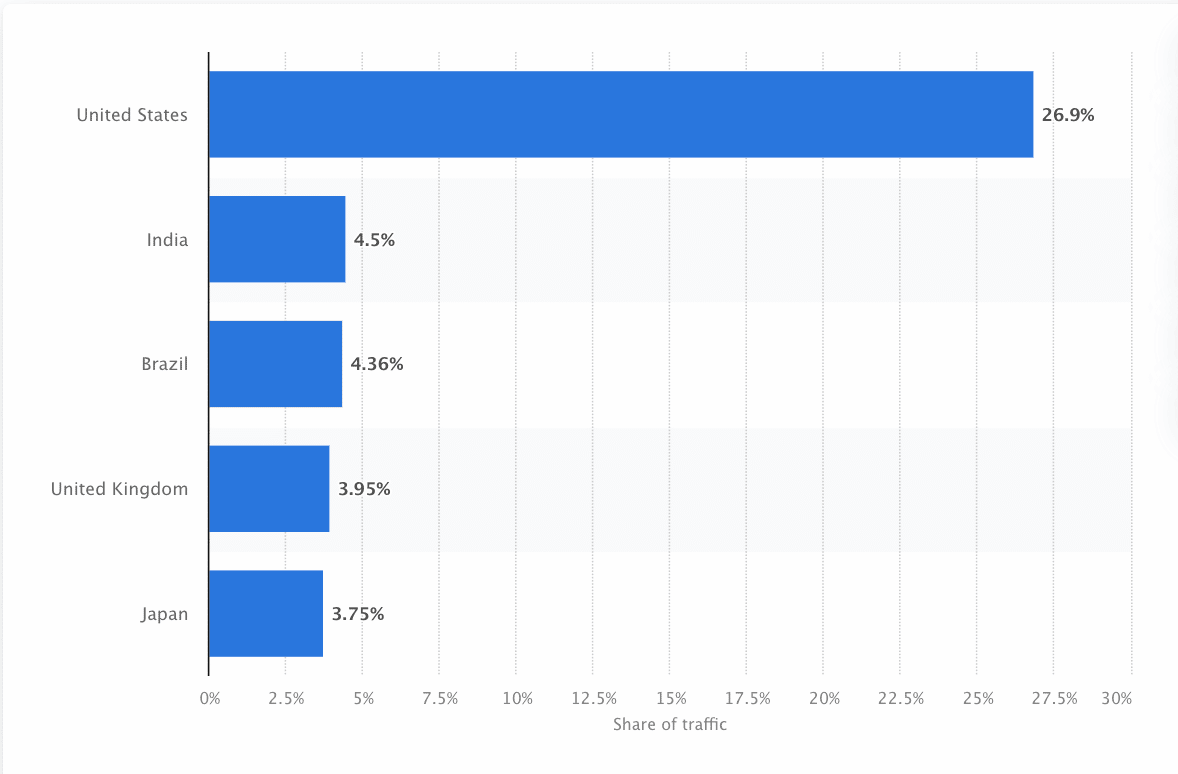
Los robots deben escanear y rastrear continuamente la web para garantizar que se presenta la información más precisa. Google es el sitio web más visitado en Estados Unidos, y aproximadamente el 26,9% de las búsquedas proceden de usuarios estadounidenses:
Sin embargo, no existe un rastreador web que rastree para todos los motores de búsqueda. Cada motor de búsqueda tiene puntos fuertes únicos, por lo que los desarrolladores y vendedores a veces recopilan una «lista de rastreadores» Esta lista de rastreadores les ayuda a identificar diferentes rastreadores en el registro de su sitio web para aceptarlos o bloquearlos.
Los profesionales del marketing deben elaborar una lista de rastreadores con los distintos rastreadores web y comprender cómo evalúan su sitio (a diferencia del scraping de contenido que roban el contenido) para asegurarse de que optimizan sus páginas de destino correctamente para los motores de búsqueda.
¿Cómo funciona un rastreador web?
Un rastreador web escaneará automáticamente tu página web después de publicarla e indexará tus datos.
Los rastreadores web buscan palabras clave específicas asociadas a la página web e indexan esa información para motores de búsqueda relevantes como Google, Bing y otros.
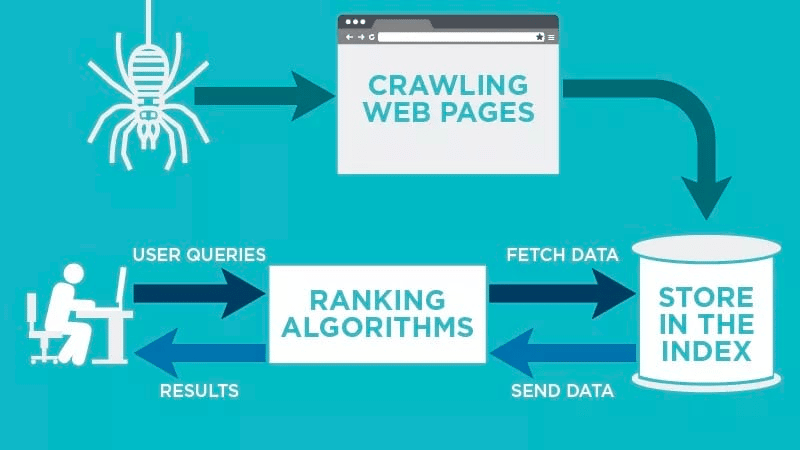
Los algoritmos de los motores de búsqueda obtendrán esos datos cuando un usuario envíe una consulta por la palabra clave relevante vinculada a ella.
Los rastreos comienzan con URL conocidas. Se trata de páginas web establecidas con diversas señales que dirigen a los rastreadores web a esas páginas. Estas señales pueden ser
- Backlinks: El número de veces que un sitio enlaza con él
- Visitantes: Cuánto tráfico se dirige a esa página
- Autoridad del dominio: La calidad general del dominio
A continuación, almacenan los datos en el índice del motor de búsqueda. Cuando el usuario inicia una consulta de búsqueda, el algoritmo obtiene los datos del índice y aparecen en la página de resultados del motor de búsqueda. Este proceso puede producirse en pocos milisegundos, por lo que los resultados suelen aparecer rápidamente.
Como webmaster, puedes controlar qué robots rastrean tu sitio. Por eso es importante tener una lista de rastreadores. Es la protocolo robots.txt que vive dentro de los servidores de cada sitio y que dirige a los rastreadores hacia el nuevo contenido que necesita ser indexado.
Dependiendo de lo que introduzcas en tu protocolo robots.txt en cada página web, puedes decirle a un rastreador que escanee o evite indexar esa página en el futuro.
Al comprender lo que busca un rastreador web en su escaneado, puedes entender cómo posicionar mejor tu contenido para los motores de búsqueda.
Elaborar tu lista de rastreadores: ¿Cuáles son los distintos tipos de rastreadores web?
Cuando empieces a pensar en compilar tu lista de rastreadores, hay tres tipos principales de rastreadores que debes buscar. Entre ellos están:
- Rastreadores internos: Son rastreadores diseñados por el equipo de desarrollo de una empresa para escanear su sitio. Normalmente se utilizan para auditar y optimizar el sitio.
- Rastreadores comerciales: Son rastreadores personalizados, como Screaming Frog, que las empresas pueden utilizar para rastrear y evaluar eficazmente su contenido.
- Rastreadores de código abierto: Son rastreadores de uso gratuito creados por diversos desarrolladores y hackers de todo el mundo.
Es importante comprender los distintos tipos de rastreadores que existen para saber qué tipo necesitas aprovechar para tus propios objetivos empresariales.
Los 13 rastreadores web más comunes que debes añadir a tu lista de rastreadores
No existe un rastreador que haga todo el trabajo para todos los motores de búsqueda.
En su lugar, hay una variedad de rastreadores web que evalúan tus páginas web y escanean el contenido para todos los motores de búsqueda disponibles para los usuarios de todo el mundo.
Veamos algunos de los rastreadores web más comunes hoy en día.
1. Googlebot
Googlebot es el rastreador web genérico de Google que se encarga de rastrear los sitios que aparecerán en el motor de búsqueda de Google.

Aunque técnicamente existen dos versiones de Googlebot – Googlebot Desktop y Googlebot Smartphone (Móvil) -, la mayoría de los expertos consideran que Googlebot es un único rastreador.
Esto se debe a que ambos siguen el mismo token de producto único (conocido como token de agente de usuario) escrito en el robots.txt de cada sitio. El agente de usuario de Googlebot es simplemente «Googlebot»
Googlebot se pone a trabajar y suele acceder a tu sitio cada pocos segundos (a menos que lo hayas bloqueado en el robots.txt de tu sitio). Se guarda una copia de seguridad de las páginas escaneadas en una base de datos unificada llamada Google Cache. Esto te permite consultar versiones antiguas de tu sitio.
Además, Google Search Console es otra herramienta que los webmasters utilizan para comprender cómo rastrea Googlebot su sitio y para optimizar sus páginas para la búsqueda.
| User Agent | Googlebot |
| Full User Agent String | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
2. Bingbot
Bingbot fue creado en 2010 por Microsoft para escanear e indexar URL con el fin de garantizar que Bing ofrezca resultados de búsqueda relevantes y actualizados para los usuarios de la plataforma.
Al igual que Googlebot, los desarrolladores o responsables de marketing pueden definir en el robots.txt de su sitio si aprueban o deniegan que el agente identificador «bingbot» escanee su sitio.
Además, tienen la posibilidad de distinguir entre los rastreadores de indexación mobile-first y los rastreadores de escritorio, ya que Bingbot cambió recientemente a un nuevo tipo de agente. Esto, junto con las herramientas para webmasters de Bing, proporciona a los webmasters una mayor flexibilidad para mostrar cómo se descubre y se muestra su sitio en los resultados de búsqueda.
| User Agent | Bingbot |
| Full User Agent String | Desktop – Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) Chrome/W.X.Y.Z Safari/537.36
Mobile – Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; bingbot/2.0; +https://www.bing.com/bingbot.htm) «W.X.Y.Z» se sustituirá por la última versión de Microsoft Edge que esté utilizando Bing, por ejemplo, «100.0.4896.127″. |
3. Yandex Bot
Yandex Bot es un rastreador específico para el motor de búsqueda ruso, Yandex. Se trata de uno de los motores de búsqueda más grandes y populares de Rusia.

Los webmasters pueden hacer que las páginas de su sitio sean accesibles a Yandex Bot a través de su archivo robots.txt.
Además, también pueden añadir una etiqueta Yandex.Metrica a páginas específicas, reindexar páginas en el Yandex Webmaster o emitir un protocolo IndexNow, un informe único que señala las páginas nuevas, modificadas o desactivadas.
| User Agent | YandexBot |
| Full User Agent String | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
4. Apple Bot
Apple encargó al Apple Bot que rastreara e indexara páginas web para las sugerencias de Siri y Spotlight de Apple.
Apple Bot tiene en cuenta múltiples factores a la hora de decidir qué contenido elevar en las Sugerencias de Siri y Spotlight. Estos factores incluyen la participación del usuario, la relevancia de los términos de búsqueda, el número/calidad de los enlaces, las señales basadas en la ubicación e incluso el diseño de la página web.
| User Agent | Applebot |
| Full User Agent String | Mozilla/5.0 (Device; OS_version) AppleWebKit/WebKit_version (KHTML, like Gecko) Version/Safari_version Safari/WebKit_version (Applebot/Applebot_version) |
5. DuckDuck Bot
El DuckDuckBot es el rastreador web de DuckDuckGo, que ofrece «Protección de la privacidad sin fisuras en tu navegador web»
Los webmasters pueden utilizar la API de DuckDuckBot para ver si el DuckDuck Bot ha rastreado su sitio. A medida que rastrea, actualiza la base de datos de la API de DuckDuckBot con direcciones IP y agentes de usuario recientes.
Esto ayuda a los webmasters a identificar a cualquier impostor o bot malicioso que intente asociarse con DuckDuck Bot.
| User Agent | DuckDuckBot |
| Full User Agent String | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
6. Baidu Spider
Baidu es el principal motor de búsqueda chino, y Baidu Spider es el único rastreador del sitio.

Google está prohibido en China, por lo que es importante permitir que Baidu Spider rastree tu sitio si quieres llegar al mercado chino.
Para identificar Baidu Spider que rastrea tu sitio, busca los siguientes agentes de usuario: baiduspider, baiduspider-image, baiduspider-video, etc.
Si no haces negocios en China, puede tener sentido bloquear la Baidu Spider en tu script robots.txt. Esto evitará que la Baidu Spider rastree tu sitio, eliminando así cualquier posibilidad de que tus páginas aparezcan en las páginas de resultados del motor de búsqueda de Baidu (SERPs).
| User Agent | Baiduspider |
| Full User Agent String | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
7. Sogou Spider
Sogou es un motor de búsqueda chino que, según se dice, es el primer motor de búsqueda con 10.000 millones de páginas chinas indexadas.

Si haces negocios en el mercado chino, éste es otro popular rastreador de buscadores que debes conocer. El Sogou Spider sigue los parámetros de texto de exclusión y retraso de rastreo del robot.
Al igual que con Baidu Spider, si no quieres hacer negocios en el mercado chino, deberías desactivar esta araña para evitar tiempos de carga lentos del sitio.
| User Agent | Sogou Pic Spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou head spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07) Sogou Orion spider/3.0( http://www.sogou.com/docs/help/webmasters.htm#07) Sogou-Test-Spider/4.0 (compatible; MSIE 5.5; Windows 98) |
8. Facebook External Hit
Facebook External Hit, también conocido como Facebook Crawler, rastrea el HTML de una aplicación o sitio web compartido en Facebook.

Esto permite a la plataforma social generar una vista previa compartible de cada enlace publicado en la plataforma. El título, la descripción y la imagen en miniatura aparecen gracias al rastreador.
Si el rastreo no se ejecuta en cuestión de segundos, Facebook no mostrará el contenido en el fragmento personalizado generado antes de compartirlo.
| User Agent | facebot facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php) facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
9. Exabot
Exalead es una empresa de software creada en 2000 y con sede en París, Francia. La empresa proporciona plataformas de búsqueda para clientes particulares y empresariales.
Exabot es el rastreador de su motor de búsqueda principal, basado en su producto CloudView.
Como la mayoría de los motores de búsqueda, Exalead tiene en cuenta tanto el backlinking como el contenido de las páginas web a la hora de clasificarlas. Exabot es el agente de usuario del robot de Exalead. El robot crea un «índice principal» que recopila los resultados que verán los usuarios del motor de búsqueda.
| User Agent | Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Exabot-Thumbnails) Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot) |
10. Swiftbot
Swiftype es un motor de búsqueda personalizado para tu sitio web. Combina «la mejor tecnología de búsqueda, algoritmos, marco de ingestión de contenidos, clientes y herramientas de análisis«.
Si tienes un sitio complejo con muchas páginas, Swiftype ofrece una interfaz útil para catalogar e indexar todas tus páginas por ti.
Swiftbot es el rastreador web de Swiftype. Sin embargo, a diferencia de otros robots, Swiftbot sólo rastrea los sitios que le solicitan sus clientes.
| User Agent | Swiftbot |
| Full User Agent String | Mozilla/5.0 (compatible; Swiftbot/1.0; UID/54e1c2ebd3b687d3c8000018; +http://swiftype.com/swiftbot) |
11. Slurp Bot
Slurp Bot es el robot de búsqueda de Yahoo que rastrea e indexa páginas para Yahoo.
Este rastreo es esencial tanto para Yahoo.com como para sus sitios asociados, incluidos Yahoo Noticias, Yahoo Finanzas y Yahoo Deportes. Sin él, no aparecerían listados de sitios relevantes.
El contenido indexado contribuye a una experiencia web más personalizada para los usuarios, con resultados más relevantes.
| User Agent | Slurp |
| Full User Agent String | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp) |
12. CCBot

CCBot es un rastreador web basado en Nutch desarrollado por Common Crawl, una organización sin ánimo de lucro centrada en proporcionar (sin ningún coste) una copia de internet a empresas, particulares y cualquier persona interesada en la investigación online. El bot utiliza MapReduce, un framework de programación que le permite condensar grandes volúmenes de datos en unos resultados totales de gran valor.
Gracias a CCBot, la gente puede utilizar los datos de Common Crawl para mejorar el software de traducción de idiomas y predecir tendencias. De hecho, GPT-3 se entrenó en gran medida con los datos de su conjunto de datos.
| User Agent | CCBot/2.0 (https://commoncrawl.org/faq/) CCBot/2.0 CCBot/2.0 (http://commoncrawl.org/faq/) |
13. GoogleOther
Se trata de una novedad. GoogleOther fue lanzado por Google en abril de 2023 y funciona igual que Googlebot.
Ambos comparten la misma infraestructura y tienen las mismas características y limitaciones. La única diferencia es que GoogleOther será utilizado internamente por los equipos de Google para rastrear el contenido de acceso público de los sitios.
El motivo de la creación de este nuevo rastreador es reducir la capacidad de rastreo de Googlebot y optimizar sus procesos de rastreo web.
GoogleOther se utilizará, por ejemplo, para rastreos de investigación y desarrollo (I+D), lo que permitirá a Googlebot centrarse en tareas directamente relacionadas con la indexación de búsquedas.
| User Agent | GoogleOther |
Los 8 rastreadores comerciales que los profesionales de SEO deben conocer
Ahora que ya tienes 13 de los bots más populares en tu lista de rastreadores, veamos algunos de los rastreadores comerciales y herramientas SEO más comunes para profesionales.
1. Ahrefs Bot
El Ahrefs Bot es un rastreador web que recopila e indexa la base de datos de 12 billones de enlaces que ofrece el popular software SEO, Ahrefs.
El Ahrefs Bot visita 6.000 millones de sitios web cada día y se considera «el segundo rastreador más activo», sólo por detrás de Googlebot.
Al igual que otros bots, el Bot Ahrefs sigue las funciones de robots.txt, así como las reglas de permitir/no permitir en el código de cada sitio.
2. Semrush Bot
El Semrush Bot permite a Semrush, un software SEO líder, recopilar e indexar datos de sitios para que sus clientes los utilicen en su plataforma.
Los datos se utilizan en el buscador público de backlinks de Semrush, la herramienta de auditoría de sitios, la herramienta de auditoría de backlinks, la herramienta de construcción de enlaces y el asistente de redacción.
Rastrea tu sitio recopilando una lista de URL de páginas web, visitándolas y guardando determinados hipervínculos para futuras visitas.
3. Moz’s Campaign Crawler Rogerbot
Rogerbot es el rastreador del sitio líder en SEO, Moz. Este rastreador recopila específicamente contenido para las auditorías de sitios de la Campaña Moz Pro.

Rogerbot sigue todas las reglas establecidas en los archivos robots.txt, por lo que puedes decidir si quieres bloquear/permitir que Rogerbot rastree tu sitio.
Los webmasters no podrán buscar una dirección IP estática para ver qué páginas ha rastreado Rogerbot debido a su enfoque multifacético.
4. Screaming Frog
Screaming Frog es un rastreador que los profesionales de SEO utilizan para auditar su propio sitio e identificar áreas de mejora que repercutirán en su clasificación en los motores de búsqueda.

Una vez iniciado el rastreo, puedes revisar los datos en tiempo real e identificar enlaces rotos o mejoras necesarias en los títulos de tus páginas, metadatos, robots, contenido duplicado, etc.
Para configurar los parámetros de rastreo, debes adquirir una licencia de Screaming Frog.
5. Lumar (antes Deep Crawl)
Lumar es un «centro de mando centralizado para mantener la salud técnica de tu sitio» Con esta plataforma, puedes iniciar un rastreo de tu sitio para ayudarte a planificar su arquitectura.
Lumar se enorgullece de ser el «rastreador de sitios web más rápido del mercado» y presume de poder rastrear hasta 450 URL por segundo.
6. Majestic
Majestic se centra principalmente en rastrear e identificar vínculos de retroceso en las URL.

La empresa se enorgullece de tener «una de las fuentes de datos de backlinks más completas de Internet», destacando su índice histórico que ha pasado de 5 a 15 años de enlaces en 2021.
El rastreador del sitio pone todos estos datos a disposición de los clientes de la empresa.
7. cognitiveSEO
cognitiveSEO es otro importante software SEO que utilizan muchos profesionales.
El rastreador cognitivoSEO permite a los usuarios realizar auditorías exhaustivas del sitio que informarán sobre la arquitectura de su sitio y la estrategia SEO global.
El robot rastreará todas las páginas y proporcionará «un conjunto de datos totalmente personalizado» y exclusivo para el usuario final. Este conjunto de datos también incluirá recomendaciones para el usuario sobre cómo puede mejorar su sitio para otros rastreadores, tanto para influir en las clasificaciones como para bloquear rastreadores innecesarios.
8. Oncrawl
Oncrawl es un «rastreador SEO y analizador de registros líder del sector» para clientes de nivel empresarial.
Los usuarios pueden configurar «perfiles de rastreo» para crear parámetros específicos para el rastreo. Puedes guardar estos ajustes (incluida la URL de inicio, los límites de rastreo, la velocidad máxima de rastreo, etc.) para volver a ejecutar fácilmente el rastreo con los mismos parámetros establecidos.
¿Necesito proteger mi sitio de rastreadores web maliciosos?
No todos los rastreadores son buenos. Algunos pueden afectar negativamente a la velocidadde tu página, mientras que otros pueden intentar piratear tu sitio o tener intenciones maliciosas.
Por eso es importante saber cómo bloquear la entrada de rastreadores en tu sitio.
Si estableces una lista de rastreadores, sabrás cuáles son los buenos. Después, podrás eliminar a los sospechosos y añadirlos a tu lista de bloqueados.
Cómo bloquear rastreadores web maliciosos
Con tu lista de rastreadores en la mano, podrás identificar qué robots quieres aprobar y cuáles necesitas bloquear.
El primer paso es revisar tu lista de rastreadores y definir el agente de usuario y la cadena de agente completa que se asocia a cada rastreador, así como su dirección IP específica. Estos son factores de identificación clave que se asocian a cada bot.
Con el agente de usuario y la dirección IP, puedes hacerlos coincidir en los registros de tu sitio mediante una búsqueda DNS o una coincidencia IP. Si no coinciden exactamente, puede que tengas un bot malicioso intentando hacerse pasar por el real.
Entonces, puedes bloquear al impostor ajustando los permisos mediante la etiqueta robots.txt de tu sitio.
Resumen
Los rastreadores web son útiles para los motores de búsqueda e importantes para que los profesionales del marketing los comprendan.
Asegurarte de que tu sitio es rastreado correctamente por los rastreadores adecuados es importante para el éxito de tu negocio. Si llevas una lista de rastreadores, podrás saber a cuáles debes prestar atención cuando aparezcan en el registro de tu sitio.
A medida que sigas las recomendaciones de los rastreadores comerciales y mejores el contenido y la velocidad de tu sitio, facilitarás que los rastreadores accedan a tu sitio e indexen la información correcta para los motores de búsqueda y los consumidores que la buscan.


