
Como te dirá cualquier propietario de un sitio web, la pérdida de datos y el tiempo de inactividad, incluso en dosis mínimas, pueden ser catastróficos. Pueden golpear a los desprevenidos en cualquier momento, provocando una reducción de la productividad, la accesibilidad y la confianza en el producto.
Para proteger la integridad de tu sitio web, es vital crear protecciones contra la posibilidad de un tiempo de inactividad o una pérdida de datos.
Ahí es donde entra en acción la replicación de datos.
La replicación de datos es un proceso de copia de seguridad automatizado en el que tus datos se copian repetidamente desde su base de datos principal a otra ubicación remota para su custodia. Es una tecnología integral para cualquier sitio o aplicación que ejecute un servidor de bases de datos. También puedes aprovechar la base de datos replicada para procesar SQL de sólo lectura, permitiendo que se ejecuten más procesos dentro del sistema.
Configurar la replicación entre dos bases de datos ofrece tolerancia a los fallos frente a percances inesperados. Se considera la mejor estrategia para conseguir una alta disponibilidad durante los desastres.
En este artículo, nos adentraremos en las diferentes estrategias que pueden implementar los desarrolladores de backend para conseguir una replicación de PostgreSQL sin problemas.
¿Qué es la Replicación PostgreSQL?
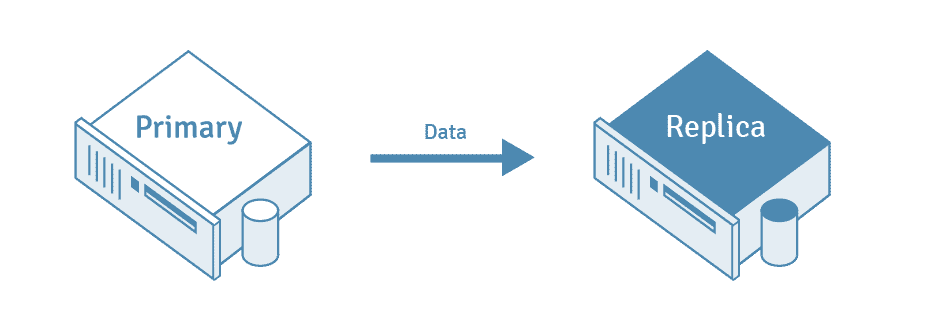
La replicación PostgreSQL se define como el proceso de copiar datos de un servidor de base de datos PostgreSQL a otro servidor. El servidor de la base de datos de origen también se conoce como servidor «primario», mientras que el servidor de la base de datos que recibe los datos copiados se conoce como servidor «réplica».
La base de datos PostgreSQL sigue un modelo de replicación sencillo, en el que todas las escrituras van a un nodo primario. El nodo primario puede entonces aplicar estos cambios y difundirlos a los nodos secundarios.
¿Qué es la Conmutación por Error Automática?
La conmutación por error es un método para recuperar los datos si el servidor primario falla por cualquier motivo. Siempre que hayas configurado PostreSQL para gestionar la replicación de tu flujo físico, tú — y tus usuarios — estaréis protegidos contra el tiempo de inactividad debido a un fallo del servidor primario.
Ten en cuenta que el proceso de conmutación por error puede tardar un poco en configurarse e iniciarse. No hay herramientas incorporadas para monitorear y evaluar los fallos del servidor en PostgreSQL, así que tendrás que ser creativo.
Afortunadamente, ya no tienes que depender de PostgreSQL para la conmutación por error. Hay herramientas dedicadas que permiten la conmutación por error automática y el cambio automático al standby, reduciendo el tiempo de inactividad de la base de datos.
Al configurar la replicación por error, prácticamente garantizas una alta disponibilidad al asegurar que los servidores en espera estén disponibles si el servidor primario se colapsa alguna vez.
Ventajas de Utilizar la Replicación PostgreSQL
He aquí algunas de las principales ventajas de aprovechar la replicación PostgreSQL:
- Migración de datos: Puedes aprovechar la replicación de PostgreSQL para la migración de datos, ya sea a través de un cambio de hardware del servidor de base de datos o mediante el despliegue del sistema.
- Tolerancia a los fallos: Si el servidor primario falla, el servidor en espera puede actuar como servidor, ya que los datos contenidos para ambos servidores, el primario el primario y el que está en espera, son los mismos.
- Rendimiento del procesamiento transaccional online (OLTP): Puedes mejorar el tiempo de procesamiento de transacciones y el tiempo de consulta de un sistema OLTP eliminando la carga de consulta de informes. El tiempo de procesamiento de transacciones es el tiempo que tarda en ejecutarse una consulta determinada antes de que finalice la transacción.
- Prueba del sistema en paralelo: Al actualizar un nuevo sistema, tienes que asegurarte de que el sistema se comporta bien con los datos existentes, de ahí la necesidad de probar con una copia de la base de datos de producción antes de la implantación.
Cómo Funciona la Replicación PostgreSQL
Generalmente, la gente cree que cuando se está jugando con una arquitectura primaria y secundaria, sólo hay una manera de configurar las copias de seguridad y la replicación. Sin embargo, las implementaciones de PostgreSQL pueden seguir cualquiera de estos tres métodos:
- Replicación en streaming: Replica los datos del nodo primario al secundario, y luego copia los datos a Amazon S3 o Azure Blob para el almacenamiento de las copias de seguridad.
- Replicación a nivel de volumen: Replica los datos en la capa de almacenamiento, empezando por el nodo primario hacia el secundario, y luego copia los datos en Amazon S3 o Azure Blob para el almacenamiento de las copias de seguridad.
- Copias de seguridad incrementales: Replica los datos del nodo primario mientras construye un nuevo nodo secundario a partir del almacenamiento de Amazon S3 o Azure Blob, lo que permite el streaming directamente desde el nodo primario.
Método 1: Streaming
La replicación en streaming de PostgreSQL, también conocida como replicación WAL, puede configurarse sin problemas después de instalar PostgreSQL en todos los servidores. Este enfoque de la replicación se basa en el traslado de los archivos WAL del primario a la base de datos de destino.
Puedes implementar la replicación en flujo de PostgreSQL utilizando una configuración primaria-secundaria. El servidor primario es la instancia principal que maneja la base de datos primaria y todas sus operaciones. El servidor secundario actúa como instancia complementaria y ejecuta en sí mismo todos los cambios realizados en la base de datos primaria, generando una copia idéntica en el proceso. El primario es el servidor de lectura/escritura, mientras que el secundario es de mera lectura.
Para este método, tienes que configurar tanto el nodo primario como el nodo secundario. Las siguientes secciones dilucidarán los pasos necesarios para configurarlos con facilidad.
Configurar el Nodo Primario
Puedes configurar el nodo primario para la replicación en streaming llevando a cabo los siguientes pasos:
Paso 1: Inicializar la Base de Datos
Para inicializar la base de datos, puedes aprovechar el comando de utilidad initdb. A continuación, puedes crear un nuevo usuario con privilegios de replicación utilizando el siguiente comando:
CREATE USER 'example_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'example_password';El usuario tendrá que proporcionar una contraseña y un nombre de usuario para la consulta dada. La palabra clave de replicación se utiliza para dar al usuario los privilegios necesarios. Un ejemplo de consulta sería algo así
CREATE USER 'rep_username' REPLICATION LOGIN ENCRYPTED PASSWORD 'rep_password';Paso 2: Configurar las Propiedades de Streaming
A continuación, puedes configurar las propiedades de streaming con el archivo de configuración de PostgreSQL (postgresql.conf) que se puede modificar como sigue:
wal_level = logical
wal_log_hints = on
max_wal_senders = 8
max_wal_size = 1GB
hot_standby = onAquí tienes un poco de información sobre los parámetros utilizados en el fragmento anterior:
wal_log_hints: Este parámetro es necesario para la funciónpg_rewind, que resulta muy útil cuando el servidor secundario está desincronizado con el primario.wal_level: Puedes utilizar este parámetro para habilitar la replicación en flujo de PostgreSQL, con valores posibles comominimal,replica, ological.max_wal_size: Se puede utilizar para especificar el tamaño de los archivos WAL que se pueden conservar en los archivos de registro.hot_standby: Puedes aprovechar este parámetro para establecer una conexión de lectura con el secundario cuando está configurado como ON.max_wal_senders: Puedes utilizarmax_wal_senderspara especificar el número máximo de conexiones concurrentes que pueden establecerse con los servidores en espera.
Paso 3: Crear una Nueva Entrada
Después de haber modificado los parámetros en el archivo postgresql.conf, una nueva entrada de replicación en el archivo pg_hba.conf puede permitir que los servidores establezcan una conexión entre sí para la replicación.
Normalmente puedes encontrar este archivo en el directorio de datos de PostgreSQL. Puedes utilizar el siguiente fragmento de código para ello:
host replication rep_user IPaddress md5Una vez ejecutado el fragmento de código, el servidor primario permite que un usuario llamado rep_user se conecte y actúe como servidor en espera utilizando la IP especificada para la replicación. Por ejemplo:
host replication rep_user 192.168.0.22/32 md5Configurar el Nodo En Espera
Para configurar el nodo en espera para la replicación en streaming, sigue estos pasos:
Paso 1: Copia de Seguridad del Nodo Primario
Para configurar el nodo en espera, aprovecha la utilidad pg_basebackup para generar una copia de seguridad del nodo primario. Esto servirá como punto de partida para el nodo en espera. Puedes utilizar esta utilidad con la siguiente sintaxis:
pg_basebackp -D -h -X stream -c fast -U rep_user -WLos parámetros utilizados en la sintaxis mencionada son los siguientes:
-h: Puedes utilizarlo para mencionar el host primario.-D: Este parámetro indica el directorio en el que estás trabajando actualmente.-C: Puedes utilizarlo para establecer los puntos de control.-X: Este parámetro puede utilizarse para incluir los archivos de registro transaccional necesarios.-W: Puedes utilizar este parámetro para solicitar al usuario una contraseña antes de enlazar con la base de datos.
Paso 2: Configurar el Archivo de Configuración de la Replicación
A continuación, tienes que comprobar si existe el archivo de configuración de la replicación. Si no existe, puedes generar el archivo de configuración de la replicación como recovery.conf.
Debes crear este archivo en el directorio de datos de la instalación de PostgreSQL. Puedes generarlo automáticamente utilizando la opción -R dentro de la utilidad pg_basebackup.
El archivo recovery. conf debe contener los siguientes comandos:
standby_mode = 'on'
primary_conninfo = 'host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name="host_name"'
recovery_target_timeline = 'latest'Los parámetros utilizados en los comandos mencionados son los siguientes
primary_conninfo: Puedes utilizarlo para establecer una conexión entre los servidores primario y secundario aprovechando una cadena de conexión.standby_mode: Este parámetro puede hacer que el servidor primario se inicie como el secundario cuando se ponga en marcha.recovery_target_timeline: Puedes utilizarlo para establecer el tiempo de recuperación.
Para establecer una conexión, debes proporcionar el nombre de usuario, la dirección IP y la contraseña como valores del parámetro primary_conninfo. Por ejemplo:
primary_conninfo = 'host=192.168.0.26 port=5432 user=rep_user password=rep_pass'Paso 3: Reiniciar el Servidor Secundario
Por último, puedes reiniciar el servidor secundario para completar el proceso de configuración.
Sin embargo, la replicación en streaming conlleva varios retos, como por ejemplo:
- Varios clientes PostgreSQL (escritos en diferentes lenguajes de programación) conversan con un único punto final. Cuando el nodo primario falle, estos clientes seguirán reintentando el mismo nombre DNS o IP. Esto hace que la conmutación por error sea visible para la aplicación.
- La replicación de PostgreSQL no lleva incorporada la conmutación por error ni la supervisión. Cuando el nodo primario falla, tienes que promover un secundario para que sea el nuevo primario. Esta promoción debe ejecutarse de forma que los clientes escriban sólo en un nodo primario, y no observen inconsistencias en los datos.
- PostgreSQL replica todo su estado. Cuando necesitas desarrollar un nuevo nodo secundario, el secundario necesita recapitular todo el historial de cambios de estado del nodo primario, lo que consume muchos recursos y hace que sea costoso eliminar nodos en el head y crear otros nuevos.
Método 2: Dispositivo de Bloque Replicado
El enfoque del dispositivo de bloque replicado depende de la duplicación de discos (también conocida como replicación de volúmenes). En este enfoque, los cambios se escriben en un volumen persistente que se replica sincrónicamente en otro volumen.
La ventaja añadida de este enfoque es su compatibilidad y la durabilidad de los datos en entornos de nube con todas las bases de datos relacionales, como PostgreSQL, MySQL y SQL Server, por nombrar algunas.
Sin embargo, el método de réplica en disco de PostgreSQL necesita que se repliquen tanto los datos del registro WAL como los de la tabla. Dado que cada escritura en la base de datos tiene que pasar por la red de forma sincrónica, no puedes permitirte perder un solo byte, ya que eso podría dejar tu base de datos en un estado corrupto.
Este método se aprovecha normalmente con Azure PostgreSQL y Amazon RDS.
Método 3: WAL
La WAL se compone de archivos de segmentos (16 MB por defecto). Cada segmento tiene uno o más registros. Un registro de secuencia de registro (LSN) es un indicador de un registro en la WAL, que permite conocer la posición/ubicación en la que se ha guardado el registro en el archivo de registro.
Un servidor en espera aprovecha los segmentos de WAL – también conocidos como XLOGS en la terminología de PostgreSQL– para replicar continuamente los cambios de su servidor primario. Puedes utilizar el registro de escritura anticipada para garantizar la durabilidad y la atomicidad en un SGBD, serializando trozos de datos byte-array (cada uno con un LSN único) en un almacenamiento estable antes de que se apliquen a una base de datos.
La aplicación de una mutación a una base de datos puede llevar a varias operaciones del sistema de archivos. Una cuestión pertinente que se plantea es cómo puede una base de datos asegurar la atomicidad en caso de fallo del servidor debido a un corte de energía mientras estaba en medio de una actualización del sistema de archivos. Cuando una base de datos arranca, inicia un proceso de arranque o réplica que puede leer los segmentos de WAL disponibles y los compara con el LSN almacenado en cada página de datos (cada página de datos está marcada con el LSN del último registro de WAL que afecta a la página).
Replicación Basada en el Envío de Registros (Nivel de Bloque)
La replicación en flujo perfecciona el proceso de envío de registros. En lugar de esperar al cambio de WAL, los registros se envían a medida que se crean, lo que disminuye el retraso de la replicación.
La replicación en flujo también supera el envío de registros porque el servidor en espera se enlaza con el servidor primario a través de la red aprovechando un protocolo de replicación. El servidor primario puede entonces enviar los registros WAL directamente a través de esta conexión sin tener que depender de los scripts proporcionados por el usuario final.
Replicación Basada en el Envío de Registros (Nivel de Archivo)
El envío de registros se define como la copia de los archivos de registro a otro servidor PostgreSQL para generar otro servidor en espera mediante la replicación de los archivos WAL. Este servidor está configurado para trabajar en modo de recuperación, y su único propósito es aplicar los nuevos archivos WAL a medida que aparecen.
Este servidor secundario se convierte entonces en una copia de seguridad caliente del servidor PostgreSQL primario. También puede configurarse para ser una réplica de lectura, en la que puede ofrecer consultas de sólo lectura, lo que también se denomina hot standby.
Archivo WAL Continuo
Duplicar los archivos WAL a medida que se crean en cualquier ubicación distinta del subdirectorio pg_wal para archivarlos se conoce como archivo WAL. PostgreSQL llamará a un script dado por el usuario para archivar, cada vez que se cree un archivo WAL.
El script puede aprovechar el comando scp para duplicar el archivo en una o varias ubicaciones, como un soporte NFS. Una vez archivados, los archivos de segmento WAL pueden aprovecharse para recuperar la base de datos en cualquier momento.
Otras configuraciones basadas en el registro son:
- Replicación sincrónica: Antes de que se consigne cada transacción de replicación sincrónica, el servidor primario espera hasta que los nodos secundarios confirmen que han recibido los datos. La ventaja de esta configuración es que no habrá conflictos causados por procesos de escritura paralelos.
- Replicación síncrona multimaster: Aquí, todos los servidores pueden aceptar solicitudes de escritura, y los datos modificados se transmiten desde el servidor original a todos los demás servidores antes de que se confirme cada transacción. Aprovecha el protocolo 2PC y se adhiere a la regla de todo o nada.
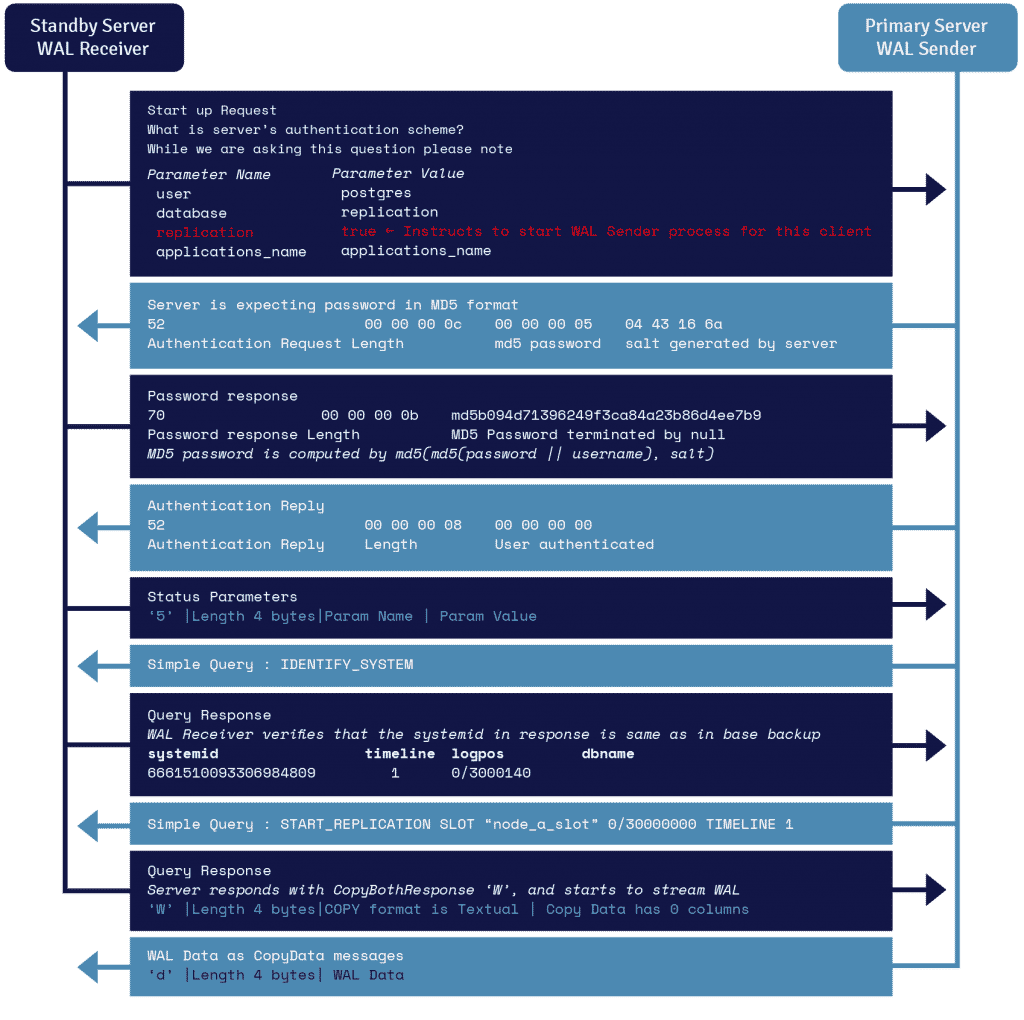
Detalles del Protocolo de Streaming WAL
Un proceso conocido como receptor de WAL, que se ejecuta en el servidor en espera, aprovecha los detalles de conexión proporcionados en el parámetro primary_conninfo de recovery.conf y se conecta al servidor primario aprovechando una conexión TCP/IP.
Para iniciar la replicación en streaming, el frontend puede enviar el parámetro de replicación dentro del mensaje de inicio. Un valor booleano de verdadero, sí, 1 u ON permite al backend saber que debe entrar en modo de replicación física walsender.
El emisor de la WAL es otro proceso que se ejecuta en el servidor primario y se encarga de enviar los registros de la WAL al servidor en espera a medida que se generan. El receptor de la WAL guarda los registros de la WAL en la WAL como si fueran creados por la actividad de los clientes conectados localmente.
Una vez que los registros de la WAL llegan a los archivos de segmentos de la WAL, el servidor en espera sigue reproduciendo constantemente la WAL para que el primario y el en espera estén actualizados.
Elementos de la Replicación PostgreSQL
En esta sección, conocerás mejor los modelos más utilizados (replicación monomáster y multimáster), los tipos (replicación física y lógica) y los modos (síncrono y asíncrono) de la replicación PostgreSQL.
Modelos de Replicación de Bases de Datos PostgreSQL
La escalabilidad significa añadir más recursos/hardware a los nodos existentes para mejorar la capacidad de la base de datos de almacenar y procesar más datos, lo que puede conseguirse de forma horizontal y vertical. La replicación de PostgreSQL es un ejemplo de escalabilidad horizontal que es mucho más difícil de implementar que la escalabilidad vertical. Podemos conseguir la escalabilidad horizontal principalmente mediante la replicación monomáster (SMR) y la replicación multimáster (MMR).
La replicación monomáster permite que los datos se modifiquen sólo en un nodo, y estas modificaciones se replican en uno o más nodos. Las tablas replicadas en la base de datos de réplica no pueden aceptar ningún cambio, excepto los del servidor primario. Incluso si lo hacen, los cambios no se replican al servidor primario.
La mayoría de las veces, la SMR es suficiente para la aplicación porque es menos complicada de configurar y gestionar, además de que no hay posibilidades de conflictos. La replicación monomáster también es unidireccional, ya que los datos de replicación fluyen en una dirección principalmente, desde la base de datos primaria a la réplica.
En algunos casos, la SMR por sí sola puede no ser suficiente, y puedes necesitar implementar la MMR. La MMR permite que más de un nodo actúe como nodo primario. Los cambios en las filas de las tablas en más de una base de datos primaria designada se replican en sus tablas homólogas en todas las demás bases de datos primarias. En este modelo, se suelen emplear esquemas de resolución de conflictos para evitar problemas como las claves primarias duplicadas.
El uso de MMR tiene algunas ventajas, por ejemplo:
- En caso de fallo del servidor, otros servidores pueden seguir prestando servicios de actualización e inserción.
- Los nodos primarios están repartidos en varios lugares diferentes, por lo que la posibilidad de que fallen todos los nodos primarios es muy pequeña.
- Posibilidad de emplear una red de área amplia (WAN) de bases de datos primarias que pueden estar geográficamente cerca de grupos de clientes, pero manteniendo la consistencia de los datos en toda la red.
Sin embargo, el inconveniente de aplicar el MMR es la complejidad y su dificultad para resolver los conflictos.
Varias ramas y aplicaciones ofrecen soluciones de MMR, ya que PostgreSQL no lo soporta de forma nativa. Estas soluciones pueden ser de código abierto, gratuitas o de pago. Una de estas extensiones es la replicación bidireccional (BDR), que es asíncrona y se basa en la función de decodificación lógica de PostgreSQL.
Como la aplicación BDR replica las transacciones en otros nodos, la operación de réplica puede fallar si hay un conflicto entre la transacción que se aplica y la transacción consignada en el nodo receptor.
Tipos de Replicación PostgreSQL
Hay dos tipos de replicación PostgreSQL: la lógica y la física.
Una simple operación lógica initdb realizaría la operación física de crear un directorio base para un clúster. Asimismo, una simple operación lógica «CREATE DATABASE» realizaría la operación física de crear un subdirectorio en el directorio base.
La replicación física suele tratar con archivos y directorios. No sabe qué representan estos archivos y directorios. Estos métodos se utilizan para mantener una copia completa de todos los datos de un único clúster, normalmente en otra máquina, y se realizan a nivel de sistema de archivos o de disco y utilizan direcciones de bloque exactas.
La replicación lógica es una forma de reproducir las entidades de datos y sus modificaciones, basándose en su identidad de replicación (normalmente una clave primaria). A diferencia de la replicación física, se ocupa de las bases de datos, las tablas y las operaciones DML y se realiza a nivel de clúster de base de datos. Utiliza un modelo de publicación y suscripción en el que uno o varios suscriptores están suscritos a una o varias publicaciones en un nodo editor.
El proceso de replicación comienza tomando una instantánea de los datos en la base de datos del editor y luego la copia al suscriptor. Los suscriptores extraen los datos de las publicaciones a las que se suscriben y pueden volver a publicar los datos más tarde para permitir la replicación en cascada o configuraciones más complejas. El suscriptor aplica los datos en el mismo orden que el editor, de modo que se garantiza la coherencia transaccional de las publicaciones dentro de una misma suscripción, también conocida como replicación transaccional.
Los casos de uso típicos de la replicación lógica son:
- Envío de cambios incrementales en una única base de datos (o en un subconjunto de la misma) a los suscriptores a medida que se producen.
- Compartir un subconjunto de la base de datos entre varias bases de datos.
- Desencadenar el envío de los cambios individuales a medida que llegan al suscriptor.
- Consolidar varias bases de datos en una sola.
- Proporcionar acceso a los datos replicados a diferentes grupos de usuarios.
La base de datos del suscriptor se comporta de la misma manera que cualquier otra instancia de PostgreSQL y puede utilizarse como editor para otras bases de datos definiendo sus publicaciones.
Si el suscriptor es tratado como de sólo lectura por la aplicación, no habrá conflictos desde una única suscripción. En cambio, si hay otras escrituras realizadas por una aplicación o por otros suscriptores en el mismo conjunto de tablas, pueden surgir conflictos.
PostgreSQL admite ambos mecanismos de forma concurrente. La replicación lógica permite un control detallado tanto de la replicación de datos como de la seguridad.
Modos de Replicación
Existen principalmente dos modos de replicación en PostgreSQL: sincrónica y asincrónica. La replicación sincrónica permite que los datos se escriban en el servidor primario y en el secundario al mismo tiempo, mientras que la replicación asincrónica garantiza que los datos se escriban primero en el host y luego se copien en el servidor secundario.
En la replicación en modo síncrono, las transacciones en la base de datos primaria se consideran completas sólo cuando esos cambios se han replicado a todas las réplicas. Los servidores de réplica deben estar disponibles todo el tiempo para que las transacciones se completen en el primario. El modo síncrono de replicación se utiliza en entornos transaccionales de alto nivel con requisitos de conmutación por error inmediatos.
En el modo asíncrono, las transacciones en el servidor primario pueden declararse completas cuando los cambios se han realizado sólo en el servidor primario. Estos cambios se replican posteriormente en las réplicas. Los servidores de réplica pueden permanecer desincronizados durante un tiempo determinado, llamado retraso de replicación. En caso de caída, puede producirse una pérdida de datos, pero la sobrecarga que proporciona la replicación asíncrona es pequeña, por lo que es aceptable en la mayoría de los casos (no sobrecarga al servidor). La conmutación por error de la base de datos primaria a la secundaria tarda más que la replicación sincrónica.
Cómo Configurar la Replicación PostgreSQL
En esta sección mostraremos cómo configurar el proceso de replicación de PostgreSQL en un sistema operativo Linux. En este caso, utilizaremos Ubuntu 18.04 LTS y PostgreSQL 10.
¡Vamos a profundizar!
Instalación
Comenzarás instalando PostgreSQL en Linux con estos pasos:
- En primer lugar, tendrás que importar la clave de firma de PostgreSQL escribiendo el siguiente comando en el terminal:
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O- | sudo apt-key add - - A continuación, añade el repositorio PostgreSQL escribiendo el siguiente comando en el terminal:
echo "deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main" | sudo tee /etc/apt/sources.list.d/postgresql.list - Actualiza el índice del repositorio escribiendo el siguiente comando en el terminal:
sudo apt-get update - Instala el paquete PostgreSQL con el comando apt:
sudo apt-get install -y postgresql-10 - Por último, establece la contraseña del usuario de PostgreSQL con el siguiente comando:
sudo passwd postgres
La instalación de PostgreSQL es obligatoria tanto para el servidor primario como para el secundario antes de iniciar el proceso de replicación de PostgreSQL.
Una vez que hayas configurado PostgreSQL en ambos servidores, puedes pasar a la configuración de la replicación del servidor primario y del secundario.
Configuración de la Replicación en el Servidor Primario
Realiza estos pasos una vez que hayas instalado PostgreSQL en los dos servidores primario y secundario.
- En primer lugar, accede a la base de datos PostgreSQL con el siguiente comando:
su - postgres - Crea un usuario de replicación con el siguiente comando:
psql -c "CREATEUSER replication REPLICATION LOGIN CONNECTION LIMIT 1 ENCRYPTED PASSWORD'YOUR_PASSWORD';" - Edita pg_hba.cnf con cualquier aplicación nano en Ubuntu y añade la siguiente configuración: archivo editar comando
nano /etc/postgresql/10/main/pg_hba.confPara configurar el archivo, utiliza el siguiente comando:
host replication replication MasterIP/24 md5 - Abre y edita postgresql.conf y pon la siguiente configuración en el servidor primario:
nano /etc/postgresql/10/main/postgresql.confUtiliza los siguientes ajustes de configuración:
listen_addresses = 'localhost,MasterIP'wal_level = replicawal_keep_segments = 64max_wal_senders = 10 - Por último, reinicia PostgreSQL en el servidor principal:
systemctl restart postgresqlAhora has completado la configuración en el servidor primario.
Configurar la Replicación en el Servidor Secundario
Sigue estos pasos para configurar la replicación en el servidor secundario:
- Inicia sesión en PostgreSQL RDMS con el siguiente comando:
su - postgres - Detenemos el servicio PostgreSQL para poder trabajar en él con el siguiente comando
systemctl stop postgresql - Editar el archivo pg_hba.conf con este comando y añadir la siguiente configuración:
// "Edit" command nano /etc/postgresql/10/main/pg_hba.conf // "Configuration" command host replication replication MasterIP/24 md5 - Abrir y editar postgresql.conf en el servidor secundario y poner la siguiente configuración o descomentarla si está comentada:
nano /etc/postgresql/10/main/postgresql.conf listen_addresses = 'localhost,SecondaryIP' wal_keep_segments = 64 wal_level = replica hot_standby = on max_wal_senders = 10SecondaryIPes la dirección del servidor secundario - Accede al directorio de datos de PostgreSQL en el servidor secundario y elimina todo:
cd /var/lib/postgresql/10/main rm -rfv * - Copia los archivos del directorio de datos del servidor primario de PostgreSQL al directorio de datos del servidor secundario de PostgreSQL y escribe este comando en el servidor secundario:
pg_basebackup -h MasterIP -D /var/lib/postgresql/11/main/ -P -U replication --wal-method=fetch - Introduce la contraseña del servidor primario PostgreSQL y pulsa enter. A continuación, añade el siguiente comando para la configuración de recuperación:
// "Edit" Command nano /var/lib/postgresql/10/main/recovery.conf // Configuration standby_mode = 'on' primary_conninfo = 'host=MasterIP port=5432 user=replication password=YOUR_PASSWORD' trigger_file = '/tmp/MasterNow'Aquí,
YOUR_PASSWORDes la contraseña del usuario de replicación en el servidor primario PostgreSQL creado - Una vez que la contraseña se ha establecido, tendrías que reiniciar la base de datos PostgreSQL secundaria como se detuvo:
systemctl start postgresqlTesting Your Setup
Prueba de la Configuración
Ahora que hemos realizado los pasos, vamos a probar el proceso de replicación y a observar la base de datos del servidor secundario. Para ello, creamos una tabla en el servidor primario y observamos si la misma se refleja en el servidor secundario.
Vamos a ello.
- Como vamos a crear la tabla en el servidor primario, tendrás que iniciar sesión en el servidor primario:
su - postgres psql - Ahora creamos una tabla simple llamada ‘testtable’ e insertamos datos en la tabla ejecutando las siguientes consultas PostgreSQL en el terminal:
CREATE TABLE testtable (websites varchar(100)); INSERT INTO testtable VALUES ('section.com'); INSERT INTO testtable VALUES ('google.com'); INSERT INTO testtable VALUES ('github.com'); - Observa la base de datos PostgreSQL del servidor secundario iniciando sesión en él:
su - postgres psql - Ahora, comprobamos si la tabla ‘testtable’ existe, y podemos devolver los datos ejecutando las siguientes consultas PostgreSQL en el terminal. Este comando muestra esencialmente toda la tabla.
select * from testtable;
Este es el resultado de la tabla de prueba:
| websites |
-------------------
| section.com |
| google.com |
| github.com |
--------------------Deberías poder observar los mismos datos que en el servidor primario.
Si ves lo anterior, ¡has realizado con éxito el proceso de replicación!
¿Cuáles Son los Pasos de la Conmutación por Error Manual de PostgreSQL?
Vamos a repasar los pasos para una conmutación por error manual de PostgreSQL:
- Para el servidor primario.
- Promueve el servidor en espera ejecutando el siguiente comando en el servidor en espera:
./pg_ctl promote -D ../sb_data/ server promoting - Conéctate al servidor en espera promocionado e inserta una fila:
-bash-4.2$ ./edb-psql -p 5432 edb Password: psql.bin (10.7) Type "help" for help. edb=# insert into abc values(4,'Four');
Si la inserción funciona bien, entonces el servidor en espera, que antes era de sólo lectura, ha sido promovido como nuevo servidor primario.
Cómo Automatizar la Conmutación por Error en PostgreSQL
Configurar la conmutación por error automática es fácil.
Necesitarás el gestor de conmutación por error EDB PostgreSQL (EFM). Después de descargar e instalar EFM en cada nodo primario y en el nodo en espera, puedes crear un Cluster EFM, que consta de un nodo primario, uno o más nodos en espera y un nodo Testigo opcional que confirma las afirmaciones en caso de fallo.
EFM supervisa continuamente el estado del sistema y envía alertas por correo electrónico en función de los eventos del sistema. Cuando se produce un fallo, cambia automáticamente al nodo en espera más actualizado y reconfigura todos los demás servidores en espera para que reconozcan el nuevo nodo primario.
También reconfigura los equilibradores de carga (como pgPool) y evita que se produzca el «split-brain» (cuando dos nodos se creen primarios).
Resumen
Debido a la gran cantidad de datos, la escalabilidad y la seguridad se han convertido en dos de los criterios más importantes en la gestión de bases de datos, especialmente en un entorno transaccional. Aunque podemos mejorar la escalabilidad verticalmente añadiendo más recursos/hardware a los nodos existentes, no siempre es posible, a menudo debido al coste o las limitaciones de añadir nuevo hardware.
Por tanto, se requiere una escalabilidad horizontal, lo que significa añadir más nodos a los nodos de red existentes, en lugar de mejorar la funcionalidad de los nodos existentes. Aquí es donde entra en escena la replicación PostgreSQL.
En este artículo, hemos hablado de los tipos de réplicas PostgreSQL, las ventajas, los modos de replicación, la instalación y la conmutación por error PostgreSQL entre SMR y MMR. Ahora vamos a escuchar tu opinión.
¿Cuál sueles implementar? ¿Qué característica de la base de datos es la más importante para ti y por qué? ¡Nos encantaría leer tus opiniones! Compártelas en la sección de comentarios más abajo.

Salman Ravoof es desarrollador web autodidacta, escritor, creador y un gran admirador del Software Libre y de Código Abierto (FOSS, Free and Open Source Software). Además de la tecnología, le apasionan la ciencia, la filosofía, la fotografía, las artes, los gatos y la comida. Obtén más información sobre él en su sitio web, y conecta con Salman en X.

