
Lorsqu’ils démarrent un nouveau projet, les développeurs ont souvent du mal à choisir une pile de logiciels. Trouver la bonne technologie pour résoudre un problème peut être une expérience éprouvante. Les bases de données, en particulier, peuvent être difficiles à choisir, surtout si vous n’êtes pas certain de la façon dont vos données seront utilisées.
Étant donné que les bases de données sont un fondement essentiel du développement de logiciels et qu’elles servent à divers usages pour des projets de construction de tous types et de toutes tailles, il est utile de comprendre l’importance des bases de données pour choisir une structure de base de données appropriée pour votre pile.
Cet article vous aidera à choisir la bonne base de données open source en explorant les différences entre deux grands systèmes de gestion de bases de données : MongoDB et PostgreSQL.
Qu’est-ce que MongoDB ?
MongoDB est une base de données non relationnelle multi-plateforme et open source publiée le 11 février 2009. Elle est connue pour utiliser des documents de type JSON avec des schémas optionnels.
MongoDB est considéré comme l’un des services de base de données dans le cloud les plus avancés du marché, avec une mobilité et une distribution des données inégalées sur Azure, AWS et Google Cloud, une automatisation intégrée pour l’optimisation de la charge de travail et des ressources.
Il permet également de créer une base de données en nuage en quelques minutes à l’aide de la CLI Atlas, de l’interface utilisateur ou d’un fournisseur de ressources IaaS (infrastructure-as-a-service).
Avec MongoDB Atlas, vous pouvez maintenir le fonctionnement de votre application pour faire face à l’augmentation du trafic à mesure que de nouvelles fonctionnalités font leur apparition dans votre pipeline. MongoDB Atlas fournit à ses utilisateurs des outils avancés d’optimisation des bases de données afin que vous possédiez toujours les ressources de base de données dont vous avez besoin pour continuer à construire.
Principales caractéristiques
Voici quelques caractéristiques principales de MongoDB qui lui valent une place parmi les meilleures bases de données non relationnelles du marché :
- Conseils en matière de performances : Au fur et à mesure que vos applications évoluent, MongoDB vous assiste en vous proposant les meilleures pratiques de conception de schémas à la demande pour une efficacité maximale.
- Clusters multi-clouds : Avec MongoDB, vous pouvez mettre en place des applications résilientes et puissantes qui exploitent deux ou plusieurs clouds en même temps.
- Équilibrage de charge : MongoDB facilite le contrôle de la concurrence pour prendre en charge les demandes de plusieurs clients en parallèle sur d’autres serveurs. Cela peut aider à diminuer la charge sur chaque serveur tout en garantissant la cohérence et la disponibilité des données et permet des applications évolutives.
Cas d’utilisation
MongoDB est utilisé par des milliers d’organisations dans le monde pour leurs besoins de stockage de données ou comme service de base de données de leurs applications.
MongoDB joue un rôle central dans :
- La gestion de contenu : Avec MongoDB, vous pouvez servir et stocker n’importe quel type de contenu, construire n’importe quelle fonctionnalité et intégrer n’importe quel type de données dans une seule base de données. MongoDB vous met sur la voie du succès avec du matériel de base et des équipes plus productives pour que vos projets coûtent 10 % de ce qu’ils devraient coûter, tout en offrant toutes les fonctionnalités nécessaires à la création d’applications riches en contenu.
- Les paiements : Si vous développez un nouveau produit de paiement, l’agilité des données de MongoDB permettra à ce nouveau produit d’atteindre rapidement le marché, sans que vous ayez à vous soucier d’une complexité inutile comme la fragmentation des données. Même si vous êtes à la tête d’une entreprise mature qui tente de moderniser son écosystème de paiement, vous pouvez tirer parti de la flexibilité de MongoDB pour l’utiliser comme une couche de données opérationnelles consolidées, ce qui vous permettra de créer de nouveaux produits et services en utilisant les données existantes sans une solution risquée.
- Personnalisation : MongoDB vous permet de personnaliser les expériences de millions de clients en temps réel, avec des fonctionnalités telles que des offres ciblées, des pages d’accueil personnalisées et l’ouverture de session sur les réseaux de médias sociaux. Vous pouvez même exécuter des requêtes complexes directement sur vos données sans vous soucier de la transformation, de l’extraction et du chargement.
- Déchargement du mainframe : Vous pouvez facilement déplacer les charges de travail hors du mainframe avec MongoDB. Le déchargement du mainframe est le processus de réplication des données du mainframe auxquelles on accède couramment vers une couche de données opérationnelles (ODL) construite sur MongoDB, contre laquelle les opérations peuvent être redirigées à partir des applications consommatrices.
Qu’est-ce que PostgreSQL ?
Malgré la popularité des bases de données NoSQL, les bases de données relationnelles restent pertinentes pour diverses applications en raison de leur robustesse et de leurs fortes capacités de requêtes.
Les bases de données relationnelles conviennent parfaitement à l’exécution de requêtes complexes et à la création de rapports basés sur des données dans les cas où la structure des données ne change pas fréquemment. Les bases de données à code open source comme PostgreSQL offrent une alternative rentable en tant que base de données de production stable par rapport à ses contemporains sous licence comme SQL Server et Oracle.
PostgreSQL est un système de gestion de base de données extrêmement stable, soutenu par plus de 20 ans de développement communautaire qui a conduit à ses hauts niveaux d’intégrité, de résilience et de correction. Vous pouvez utiliser PostgreSQL comme entrepôt de données principal ou source de données pour diverses applications mobiles, géospatiales, analytiques et web.
PostgreSQL ne comporte également aucun coût de licence, ce qui élimine le risque de sur-déploiement. Son groupe dévoué de passionnés et de contributeurs trouve régulièrement des bogues et des solutions, contribuant ainsi à la sécurité globale du système de base de données.
Caractéristiques principales
Voici quelques caractéristiques saillantes de PostgreSQL qui en font l’une des bases de données les plus utilisées aujourd’hui :
- Colonnes non atomiques : L’une des principales contraintes d’un modèle relationnel est que les colonnes doivent être atomiques. PostgreSQL, cependant, n’a pas cette contrainte et permet aux colonnes d’avoir des sous-valeurs auxquelles les requêtes peuvent facilement accéder.
- Prise en charge des données JSON : La possibilité d’interroger et de stocker JSON permet à PostgreSQL d’exécuter également des charges de travail NoSQL – par exemple, si vous concevez une base de données pour stocker les données de plusieurs capteurs et que vous n’êtes pas sûr des colonnes spécifiques dont vous aurez besoin pour prendre en charge tous les types de capteurs. Dans ce scénario, vous pouvez construire une table telle que l’une des colonnes est JSON pour stocker les données non structurées ou en constante évolution.
- Fonctions Window : Les fonctions Window de PostgreSQL jouent un rôle essentiel qui en fait un favori pour les applications analytiques. Avec les fonctions Window, vous pouvez exécuter des fonctions s’étendant sur plusieurs lignes et retourner le même nombre de lignes. Les fonctions de fenêtre diffèrent des fonctions d’agrégation dans le sens où les fonctions d’agrégation ne peuvent retourner qu’une seule ligne après agrégation.
Cas d’utilisation
Voici quelques cas d’utilisation où PostgreSQL s’avère utile :
- Base de données hub fédérée : Le support JSON et les wrappers de données étrangères de PostgreSQL lui permettent de se connecter à d’autres magasins de données – y compris les types NoSQL – et de servir de hub fédéré pour les systèmes de bases de données polyglottes.
- Données scientifiques : Les projets scientifiques et de recherche peuvent générer des téraoctets de données, qui doivent être gérées de la manière la plus efficace et la plus avantageuse possible. PostgreSQL offre un merveilleux moteur SQL doté de solides capacités analytiques, ce qui fait du traitement de grandes quantités de données un jeu d’enfant.
- Fabrication : Divers fabricants industriels de classe mondiale s’appuient sur PostgreSQL pour accélérer l’innovation et propulser la croissance grâce à des processus centrés sur le client, tout en optimisant les performances de la chaîne logistique en utilisant PostgreSQL comme backend de stockage.
- Pile open source LAPP : PostgreSQL peut exécuter des applications et des sites web dynamiques dans le cadre d’une alternative robuste à la pile LAMP. LAPP est l’acronyme de Linux, Apache, PostgreSQL, Python, PHP et Perl.
MongoDB vs PostgreSQL : Comparaison face à face
La vraie question n’est pas MongoDB vs PostgreSQL, mais plutôt la meilleure base de données documentaire vs la meilleure base de données relationnelle.
Très souvent, au début d’un projet de développement, les chefs de projet ont une bonne compréhension du cas d’utilisation mais n’ont pas une idée claire des fonctionnalités spécifiques de l’application dont leurs utilisateurs et leur entreprise auraient besoin. Ils finissent par devoir miser sur un choix et espérer qu’il s’agisse de la meilleure solution.
Dans la section suivante, nous allons élucider les différences entre MongoDB et PostgreSQL pour vous aider à prendre facilement cette décision. Nos informations sont basées sur des facteurs clés tels que l’architecture, la conformité ACID, l’extensibilité, la réplication, la sécurité et le support, pour n’en citer que quelques-uns.
Plongeons-y !
Conformité ACID
L’une des caractéristiques les plus essentielles des bases de données relationnelles qui simplifient l’écriture des applications est la conformité ACID des transactions. En ce qui concerne les niveaux d’isolement dans les transactions de base de données, PostgreSQL utilise par défaut le niveau d’isolement de lecture engagée. Il permet également aux utilisateurs d’ajuster le niveau d’isolation de lecture engagée jusqu’au niveau d’isolation sérialisable.
Ce qu’il est important de noter ici, c’est que les transactions permettent d’apporter ou d’annuler diverses modifications à une base de données dans un groupe. Par conséquent, dans une base de données relationnelle, les données seraient modélisées à travers des tables parent-enfant indépendantes dans un schéma tabulaire.
En comparaison, les bases de données documentaires ont plus de facilité à exécuter des transactions car elles rassemblent les données dans un document et comme la lecture et l’écriture sont des opérations atomiques, elles ne nécessitent pas de transaction multi-documents.
MongoDB prend en charge l’isolation complète pendant la mise à jour d’un document. Toute erreur déclenche le retour en arrière de l’opération de mise à jour, ce qui annule la modification et garantit que les clients obtiennent une vue cohérente du document.
MongoDB prend également en charge les transactions de base de données sur plusieurs documents, ce qui permet d’annuler ou de valider des modifications connexes en tant que groupe. Grâce à sa capacité de transactions multi-documents, MongoDB est l’une des rares bases de données à réunir la flexibilité, la vitesse et la puissance du modèle de document avec les garanties ACID des bases de données traditionnelles.
Architecture/Modèle de document
Le modèle de document de MongoDB permet à l’utilisateur d’établir une correspondance naturelle avec les objets dans le code de l’application, ce qui facilite l’apprentissage et l’utilisation par les développeurs complets. Les documents vous offrent la possibilité de représenter des relations hiérarchiques pour stocker facilement des tableaux et d’autres structures plus sophistiquées.
En stockant les données dans des champs tels que des sous-documents et des tableaux imbriqués, les informations connexes dans les documents JSON peuvent être stockées ensemble pour un accès rapide aux requêtes via le langage de requête MongoDB.
Avec MongoDB, vous pouvez stocker des données sous forme de documents dans une représentation binaire connue sous le nom de JSON binaire (BSON). Les champs peuvent différer en fonction du document auquel ils se rapportent. Par conséquent, il n’est pas nécessaire de déclarer la structure des documents au système – les documents sont auto-descriptifs.
Si vous devez ajouter un nouveau champ à un document, le champ peut être généré sans avoir d’impact sur les autres documents de la collection ou sans mettre à jour un ORM ou un catalogue du système central.
MongoDB vous offre également la possibilité de valider les schémas pour appliquer des contrôles de gouvernance des données à chaque collection. Cette flexibilité s’avère pratique lorsqu’il s’agit de rassembler des informations provenant de plusieurs sources disparates ou de prendre en compte les modifications apportées aux documents au fil du temps, notamment lorsque la nouvelle fonctionnalité de l’application est déployée de manière cohérente.
PostgreSQL abrite un modèle d’architecture client-serveur qui se compose des deux processus suivants :
- Processus côté client : Il s’agit des applications utilisées par les utilisateurs pour interagir avec la base de données. Généralement, elle dispose d’une interface utilisateur simple et est utilisée pour communiquer entre l’utilisateur et la base de données par le biais d’API.
- Processus côté serveur : C’est l’application « Postgres » qui s’occupe des opérations, des connexions, des actifs dynamiques et statiques. Un site PostgreSQL en fonctionnement est géré par un Postmaster, un processus central de coordination. Le démon postmaster est responsable de :
- L’exécution de la récupération
- L’initialisation du serveur
- L’arrêt du serveur
- L’exécution des processus d’arrière-plan
- La gestion des demandes de connexion des nouveaux clients
.
Extensibilité
L’extensibilité est simplement la qualité d’être conçu pour permettre l’ajout de nouvelles capacités ou fonctionnalités.
PostgreSQL prend en charge l’extensibilité de plusieurs façons, y compris les fonctions et procédures stockées. Ce qui rend PostgreSQL extensible, ce sont ses opérations pilotées par catalogue.
Les bases de données relationnelles stockent souvent des informations sur les tables, les bases de données, les colonnes, etc. dans des catalogues système. Ces « dictionnaires de données » apparaissent à l’utilisateur comme des tables, mais ils contiennent des informations stockées en interne par le système de base de données.
PostgreSQL stocke les informations sur les colonnes, et les tables, ainsi que les informations concernant les types de données, les fonctions et les méthodes d’accès présentes.
Et ce n’est pas tout : PostgreSQL peut également incorporer du code écrit par l’utilisateur en lui-même via le chargement dynamique. Souvent, les utilisateurs peuvent avoir besoin de certaines fonctionnalités qui peuvent être implémentées via des bibliothèques partagées. Les utilisateurs peuvent simplement spécifier le fichier de code et PostgreSQL le chargera selon les besoins, ce qui le rend particulièrement adapté au prototypage rapide de nouvelles applications.
D’autre part, MongoDB est finalement devenu extensible, permettant aux utilisateurs de créer leurs fonctions et de les utiliser dans le framework. C’est l’équivalent des fonctions définies par l’utilisateur (User-Defined Functions ou UDF) qui permettent aux utilisateurs de bases de données relationnelles (comme PostgreSQL) d’étendre les instructions SQL.
En outre, PostgreSQL et MongoDB prennent tous deux en charge plusieurs extensions comme Adminer pour la gestion des bases de données.
Collaboration et agilité
MongoDB dispose d’un modèle de document, ce qui rend la collaboration et le développement plus faciles et plus rapides à mettre en œuvre. MongoDB utilise essentiellement JSON ou BSON pour stocker ses données sous forme de documents.
BSON comprend plusieurs types de données qui ne sont pas présents dans les données JSON, tels que les tableaux DateTime, long, int et byte qui permettent de traiter les données plus efficacement car elles sont plus spécifiques en fonction du type de données au lieu de tout traiter comme un type « number » universel. Il permet aux requêtes de s’exécuter plus rapidement car il s’agit d’un format de sérialisation qui archive efficacement les documents de type JSON.
BSON ignore les clés qui ne sont pas utiles à la requête, ce qui accélère la récupération des données. Un utilisateur pourrait définir davantage la structure du document et entreprendre un certain développement en introduisant de nouveaux champs, en retravaillant les données ou en le faisant évoluer comme bon lui semble.
Cette flexibilité est un énorme avantage pour MongoDB car elle permet d’éviter les retards causés par le fait de demander à l’administrateur de restructurer les déclarations du langage de définition des données, puis de repartir de zéro en recréant ou en rechargeant une base de données.
MongoDB facilite également la collaboration entre les développeurs ou les équipes, il n’y a donc pas besoin d’intermédiation ou de communication compliquée entre les équipes.
En ce qui concerne la collaboration, PostgreSQL inclut des privilèges au niveau de l’utilisateur, l’héritage des rôles et des privilèges au niveau de la table. Vous pouvez gérer les utilisateurs et leur accorder des privilèges de lecture et d’écriture.
En outre, vous pouvez également examiner les activités d’accès aux données de divers groupes ou utilisateurs grâce à l’option d’audit qui accorde une couche supplémentaire de sécurité. Cependant, PostgreSQL n’est pas aussi rapide que MongoDB, car il s’agit d’une base de données relationnelle qui stocke les données en lignes et en colonnes.
Prise en charge des clés étrangères
Une caractéristique clé qui distingue MongoDB de PostgreSQL est son approche du stockage de ses données.
Comme il s’agit d’une base de données non relationnelle, MongoDB utilise des collections au lieu de tables. Une clé étrangère est simplement un ensemble d’attributs dans une table qui fait référence à la clé primaire d’une autre table. La clé étrangère relie ces deux tables l’une à l’autre.
Puisqu’il n’y a pas de tables dans MongoDB, il n’y a pas non plus de clés étrangères dans MongoDB ; donc pas de contraintes de clé étrangère. Cependant, MongoDB dispose d’une norme DBRef qui permet de normaliser la création des références.
D’autre part, PostgreSQL prend en charge les clés étrangères car il est conforme à la norme SQL. En activant les contraintes de clé étrangère, PostgreSQL peut empêcher l’insertion de données invalides dans les colonnes de clé étrangère.
Partitionnement et sharding
Le partitionnement et le sharding consistent essentiellement à diviser de grands ensembles de données en sous-ensembles plus petits. Le sharding implique que les données sont stockées sur plusieurs ordinateurs tandis que le partitionnement regroupe ces données au sein d’une seule instance de base de données.
MongoDB est évolutif grâce au partitionnement des données sur des instances au sein du cluster. Il ne divise pas les documents en morceaux car il s’agit d’unités indépendantes, ce qui facilite leur distribution sur divers serveurs tout en préservant les données localement.
Les données peuvent être distribuées sur différentes régions en toute simplicité via le service cloud MongoDB Atlas. Vous pouvez également choisir de les stocker en permanence dans des régions spécifiques ou des régions mondiales pour garantir une latence réduite.
Depuis la version 5.0, MongoDB inclut une fonction de resharding « live » qui représente un gain de temps considérable puisqu’il suffit de définir une politique. La base de données peut automatiquement redistribuer les données le moment venu.
Auparavant, vous pouviez le faire sans mettre le système hors service, mais le processus était compliqué et risqué. Alors que MongoDB disposait depuis un certain temps d’un géo-partitionnement mondial, les données augmentaient dans différents pays à des rythmes différents. Le resharding en live pourrait être bénéfique pour les données qui doivent rester locales dans un pays.
D’autre part, PostgreSQL prend en charge le partitionnement déclaratif, qui est essentiellement un moyen de spécifier comment diviser une table en partitions. La table qui est divisée est appelée la table partitionnée, la spécification consiste en la méthode de partitionnement, et la liste des colonnes ou des expressions à utiliser est appelée la clé de partition.
Vous pouvez implémenter le partitionnement via une plage, où la table peut être partitionnée par des plages définies par une colonne clé ou un ensemble de colonnes, sans chevauchement entre les plages de valeurs affectées aux différentes partitions.
Vous pouvez également implémenter le partitionnement par liste où la table est partitionnée selon les valeurs de clé spécifiées.
Réplication
La réplication est le processus qui consiste à créer une copie du même ensemble de données sur plusieurs serveurs. Elle permet aux administrateurs de bases de données de fournir une redondance élevée des données et une haute disponibilité des données.
Pour MongoDB, ceci est réalisé en utilisant un « replica set » – un cluster synchronisé composé de trois serveurs ou plus qui répliquent continuellement les données entre eux. Cela permet d’assurer la redondance et la protection contre les temps d’arrêt qui pourraient survenir en cas d’interruption programmée pour la maintenance ou de panne du système, augmentant ainsi la tolérance aux pannes de la base de données.
Les ensembles de répliques peuvent également être mis en œuvre dans différents centres de données, car ils seraient très utiles en cas de pannes régionales. Ceci peut être fait par MongoDB Atlas, qui rend la construction et la configuration de ces clusters plus simples et plus rapides.
PostgreSQL offre une réplication primaire-secondaire. Les journaux Write-ahead permettent de partager les modifications apportées avec les nœuds de réplication, rendant ainsi possible la réplication asynchrone. Les autres types de réplication comprennent la réplication logique, la réplication en continu et la réplication physique.
Index
Les index sont des objets ou des structures qui nous permettent de récupérer plus rapidement des lignes ou des données spécifiques.
PostgreSQL fournit une gamme de types d’index uniques pour répondre efficacement à toute charge de travail de requête. Ses techniques d’indexation incluent l’arbre B, le multi-colonne et les expressions. En outre, des techniques d’indexation partielle et avancée telles que GiST, KNN Gist, SP-Gist, GIN, BRIN, les index de couverture et les filtres bloom peuvent également être implémentés dans PostgreSQL.
D’autre part, MongoDB vous permet de stocker des données dans n’importe quelle structure accessible rapidement par indexation, quelle que soit la profondeur de leur imbrication dans des tableaux ou des sous-documents.
Langage et syntaxe
MongoDB et PostgreSQL prennent tous deux en charge une variété de langages.
MongoDB fournit des pilotes pour certains des meilleurs langages de base de données comme Python, R, Java, Scala, C, C++, C#, Node.js, et bien d’autres encore. Ces bibliothèques et pilotes MongoDB prennent en charge toutes les fonctionnalités de MongoDB, offrant ainsi des performances et une évolutivité élevées dans toutes les applications.
PostgreSQL supporte plusieurs langages procéduraux avec une distribution de base comme PL/pgSQL, PL/Python, PL/Perl et PL/Tcl ainsi que d’autres langages développés et maintenus en dehors de la distribution de base de PostgreSQL comme PL/Java, PL/PHP et PL/Ruby.
Normalisation
La normalisation est le processus de structuration d’une base de données relationnelle pour réduire la redondance des données, minimiser les anomalies dans la modification des données et améliorer l’intégrité des données.
MongoDB peut traiter à la fois des modèles de données normalisés et dénormalisés (également connus sous le nom de modèles intégrés).
Les modèles intégrés permettent aux applications de stocker des éléments d’information similaires dans le même enregistrement de base de données, ce qui offre de meilleures performances pour les opérations de lecture et la possibilité de récupérer des données connexes en une seule opération de base de données.
En outre, vous pouvez également mettre à jour des données similaires en une seule opération d’écriture atomique, tandis que les applications émettent moins de requêtes pour effectuer les opérations courantes. Les documents dans MongoDB pour le modèle de données intégré doivent être plus petits que la taille maximale des documents BSON (16 Mo).
Les modèles de données normalisés décrivent les relations à l’aide de références entre les documents. Il serait avantageux d’utiliser cette méthode lorsque l’incorporation peut entraîner une duplication des données mais que les avantages insuffisants en termes de performances de lecture l’emportent sur les implications de ces duplications.
Cependant, le processus de dénormalisation entraîne généralement une forte consommation de mémoire lorsque des données précédemment normalisées dans une base de données sont regroupées pour augmenter les performances.
Les schémas PostgreSQL ont une relation identifiée. La structure peut être identifiée avec une relation 1:1, 1:many, ou many:1. La normalisation des données peut être très bénéfique car elle supprime les copies redondantes de données, ce qui garantit également l’intégrité.
Performances
L’évaluation des performances de deux systèmes de base de données différents est difficile car MongoDB et PostgreSQL ont tous deux des méthodes différentes de stockage et de récupération des données.
MongoDB a été conçu pour évoluer horizontalement, car il combine souvent sa puissance avec des machines supplémentaires et ne dépend pas de la puissance de traitement. Il est capable d’alimenter des applications massives, qu’elles soient mesurées par la taille des données ou des utilisateurs.
MongoDB peut également s’adapter aux cas d’utilisation qui nécessitent l’exécution rapide de requêtes et peut traiter une grande quantité de données. Il pourrait intégrer des centaines de machines au total.
Depuis MongoDB 4.4, les requêtes implémentées contre des ensembles de répliques produisent des performances améliorées et prévisibles grâce à des lectures « couvertes ». Ces lectures sont dirigées vers plusieurs nœuds au sein du replica set jusqu’à ce que le nœud le plus rapide réponde.
PostgreSQL, bien que moins rapide que MongoDB en termes de vitesse d’insertion brute, excelle en termes de conformité ACID. Les transactions sont traitées de manière sûre et fiable, permettant à une transaction entière d’échouer au lieu d’exécuter une écriture qui a partiellement réussi.
MongoDB n’a que récemment (avec la version 4) commencé à prendre en charge les transactions ACID similaires aux bases de données SQL.
Contrairement à MongoDB, PostgreSQL dépend d’une stratégie de mise à l’échelle (vertical scaling) pour les volumes de données et la mise à l’échelle des écritures. Elle s’effectue en ajoutant davantage de ressources matérielles comme des disques, des CPU et de la mémoire à un nœud de base de données existant.
Toutefois, PostgreSQL a fait quelques efforts en matière d’optimisation des performances, notamment un planificateur de requêtes mature, la compilation just-in-time (JIT) des expressions, le partitionnement des tables et la parallélisation des requêtes en lecture.
Prix
PostgreSQL est entièrement gratuit et open source. Tout le monde peut donc utiliser ses fonctionnalités et apporter facilement des modifications au code si nécessaire.
MongoDB est également un outil open source. Cependant, MongoDB dispose d’autres options comme l’entreprise et Atlas (pour le cloud), qui ont des prix variables. Un modèle de tarification sur site est proposé pour l’édition entreprise de MongoDB.
Mongo RealmDB est disponible gratuitement pour tous les utilisateurs d’Atlas à des fins d’évaluation et d’utilisation légère, permettant aux développeurs de créer et de diffuser des applications mobiles.
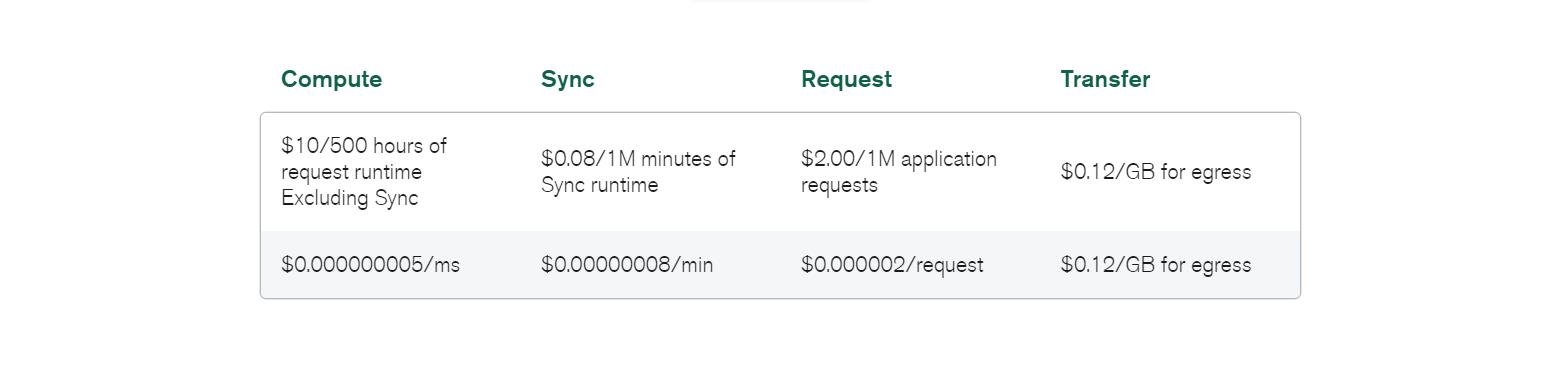
La migration des données peut également générer des frais généraux ; toutefois, il s’agit d’un élément standard, quelle que soit la base de données que vous avez mise en œuvre dans votre système.
Traitement des requêtes
PostgreSQL utilise le modèle de base de données relationnelle qui repose sur le stockage des données dans des tables et l’utilisation du langage de requête structuré (SQL) pour l’accès à la base de données. Les commandes SQL peuvent être saisies à l’aide du terminal PostgreSQL psql. Il dispose d’une facilité pour les grands objets, qui fournit un accès de type flux aux données utilisateur qui sont stockées dans une structure spéciale de grands objets.
Avant d’ajouter les données, le schéma de la base de données doit être construit afin de bien comprendre les relations entre les données pour traiter les requêtes. Les informations connexes peuvent être stockées dans des tables distinctes de la base de données. On peut y accéder via des clés étrangères et des jointures.
Il peut être difficile d’ajuster la structure de la base de données une fois qu’elle est chargée. Il faut plusieurs équipes dans le développement, les opérations et l’administrateur de la base de données pour coordonner soigneusement les modifications apportées à la structure.
D’un autre côté, la structure de données de MongoDB n’a pas besoin d’être planifiée à l’avance car elle traite essentiellement des données non structurées. La structure de données est également beaucoup plus facile à ajuster.
Les développeurs peuvent choisir ce qui est essentiel dans l’application et apporter les modifications nécessaires. MongoDB utilise MQL, qui peut être utilisé pour travailler avec des documents dans MongoDB et extraire des données tout en offrant la flexibilité et la puissance de SQL.
MongoDB traite les données sous forme de documents JSON. Vous pouvez également interroger les champs à l’intérieur du document JSON. Ainsi, MongoDB est très utile dans les cas où vous souhaitez stocker des documents dans un champ de données flexible.
Alors que PostgreSQL utilise la fonction GROUP_BY pour traiter et exécuter des requêtes agrégées, MongoDB utilise généralement des pipelines d’agrégation pour traiter ses requêtes.
Un inconvénient majeur de MongoDB, cependant, est que vous ne pouvez pas facilement joindre des tables. Dans PostgreSQL, cela est rendu simple avec une instruction JOIN.
MongoDB a essayé de résoudre ce problème en introduisant des types de données multidimensionnels où vous pouvez intégrer un stockage de documents à l’intérieur d’un autre. Cependant, c’est désorganisé et pas aussi élégant que la simple fonction join que PostgreSQL intègre.
Sécurité
En matière de sécurité, PostgreSQL l’emporte sur MongoDB. Les règles strictes régissant la structure de la base de données permettent à PostgreSQL d’être une base de données très sûre, d’où la fiabilité de son utilisation pour les systèmes bancaires.
PostgreSQL offre des tonnes de méthodes d’authentification, notamment un module d’authentification enfichable (PAM) et le protocole d’accès aux répertoires légers (LDAP), qui réduisent la surface d’attaque des serveurs. Il assure également une protection au niveau du serveur grâce à l’authentification basée sur l’hôte et l’authentification par certificat.
En outre, PostgreSQL assure le cryptage des données et vous permet d’utiliser des certificats SSL lorsque vos données transitent par le web ou les autoroutes du réseau public. PostgreSQL vous permet également de mettre en œuvre les outils d’authentification par certificat client (CCA) en option, et d’utiliser des fonctions cryptographiques pour stocker des données cryptées dans PostgreSQL.
Toutefois, le niveau de sécurité de PostgreSQL peut différer d’un système de cloud à un autre, même s’il s’agit de la même base de données.
MongoDB Atlas fonctionne de la même manière chez les trois plus grands fournisseurs de clouds, ce qui facilite la migration entre plusieurs clouds.
En outre, MongoDB dispose d’un chiffrement côté client et au niveau du champ, ce qui permet aux utilisateurs de chiffrer les données avant de les envoyer à la base de données via le réseau. Cependant, comme les données sont stockées dans des paires clé-valeur dans un enregistrement, il lui manque la sécurité dont se targue PostgreSQL ; MongoDB se concentre principalement sur la vitesse.
Support et communauté
PostgreSQL est entièrement open source et soutenu par sa communauté, ce qui le renforce en tant qu’écosystème complet. PostgreSQL publie régulièrement des versions mises à jour, et les développeurs, les passionnés ou les entreprises tierces apportent leur soutien et tentent de développer le système en corrigeant les bogues ou en apportant de légères modifications au système de base de données.
Comme PostgreSQL, MongoDB dispose également d’un forum communautaire qui permet aux utilisateurs de se connecter avec plusieurs autres utilisateurs et d’obtenir des réponses à leurs questions générales. L’assistance aux entreprises MongoDB peut également inclure une base de connaissances étendue avec des cas d’utilisation, des tutoriels détaillés, des notes techniques sur les optimisations et les meilleures pratiques.
En outre, il existe des cours en ligne avec des formations et des certifications fournies par MongoDB, gratuitement.
Défis
Bien que nous ayons discuté des caractéristiques de MongoDB et de PostgreSQL qui en font un succès auprès des développeurs, ils ont également leur lot de faiblesses.
MongoDB a tendance à se concentrer sur l’exploitation rapide des données, mais n’a pas la sécurité des données que PostgreSQL semble posséder. Il est assez gourmand en mémoire, car le processus de dénormalisation entraîne généralement une forte consommation de mémoire.
En outre, comme il n’y a pas de prise en charge des jointures, les bases de données MongoDB sont surchargées de données – parfois en double – ce qui pèse lourdement sur la mémoire. MongoDB a également essayé d’inclure l’interprétation dans d’autres langages de requête dans le cadre de son extensibilité ; cependant, cela peut ralentir ses performances car la base de données n’a pas été initialement construite pour traiter les modèles de données relationnels.
La traduction des requêtes SQL en requêtes MongoDB peut prendre du temps supplémentaire pour utiliser le moteur, ce qui pourrait retarder le déploiement et le développement.
D’autre part, si PostgreSQL est facile à installer et s’adapte à presque toutes les plateformes, son efficacité peut différer d’une plate-forme à l’autre. De plus, il ne dispose pas d’outils de révision ou d’instruments de reporting qui pourraient montrer l’état actuel de la base de données. Il se peut que vous deviez vérifier la base de données en permanence si quelque chose ne se passe pas comme prévu afin d’éviter de remarquer une défaillance lorsqu’il est trop tard.
PostgreSQL est également un peu plus lent car il se concentre sur la compatibilité. Bien que des efforts aient été faits pour améliorer la vitesse de PostgreSQL, les modifications nécessitent encore un peu de travail.
MongoDB vs PostgreSQL : Lequel choisir ?
MongoDB est une base de données non relationnelle, tandis que PostgreSQL est une base de données relationnelle. Alors que les bases de données NoSQL fonctionnent sur le stockage des données dans des paires clé-valeur comme un seul enregistrement, les bases de données relationnelles stockent les données sur différentes tables.
Si vous donnez la priorité à une intégration plus rapide des données et à l’évolutivité sur plusieurs serveurs, MongoDB pourrait être un choix approprié pour votre entreprise.
MongoDB peut fonctionner au mieux lorsqu’il est intégré à une plateforme analytique, car la vitesse de MongoDB offre des performances dynamiques qui peuvent aider à suivre le comportement de l’utilisateur en temps réel. MongoDB peut également s’avérer très utile pour votre entreprise si vous possédez une application web très fréquentée qui ne dépend pas d’un schéma structuré comme le New York Times (qui utilise en fait MongoDB), ou pour des catalogues de produits où vous devez stocker plusieurs objets avec diverses collections d’attributs.
En revanche, PostgreSQL est parfaitement adapté à l’analyse et à l’entreposage de données. Si vous construisez un outil d’automatisation de base de données ou une application bancaire où vous préférez que la sécurité des données et les garanties transactionnelles soient appliquées, PostgreSQL pourrait être la solution idéale.
Résumé
Pour résumer, jusqu’à présent, nous avons couvert les détails de base de PostgreSQL et MongoDB de la même manière. Nous avons discuté de leur histoire, de leurs principales caractéristiques et de ce qui les rend différents.
Bien que PostgreSQL et MongoDB constituent tous deux d’excellentes bases de données, il s’agit en fin de compte de choisir ce qui convient le mieux à votre entreprise.
Entre PostgreSQL et MongoDB, quelle base de données préférez-vous ? Faites-le nous savoir dans les commentaires !

Salman Ravoof est un développeur web autodidacte, un écrivain, un créateur et un grand admirateur des logiciels libres. Outre la technologie, il est passionné par la science, la philosophie, la photographie, les arts, les chats et la nourriture. Apprenez-en plus sur son site web, et connectez-vous avec Salman sur X.

