
Lo scraping di contenuti, o quello che ci piace definire “furto di contenuti“, è un problema che esiste da quando esiste Internet. Per chi pubblica regolarmente o lavora con l’ottimizzazione per i motori di ricerca (SEO), può essere davvero esasperante. Più si cresce, più ci si accorge di quante aziende di scraping di contenuti ci sono in giro. Qui a Kinsta pubblichiamo molti contenuti e il content scraping è un problema che affrontiamo regolarmente. La domanda è: meglio cercare di reagire o semplicemente ignorarli e andare avanti? Oggi analizzeremo i pro e i contro di entrambi gli aspetti.
Che cos’è lo scraping di contenuti?
Lo scraping di contenuti avviene fondamentalmente quando qualcuno prende i vostri contenuti e li utilizza sul proprio sito (manualmente o automaticamente con un plugin o un bot) senza darvene l’attribuzione o il merito. Di solito questo viene fatto nella speranza di ottenere in qualche modo più traffico, SEO o nuovi utenti. Questo è contrario alle leggi sul copyright negli Stati Uniti e in altri paesi. Anche Google non approva questa pratica e raccomanda di creare i propri contenuti originali.
Ecco un paio di esempi di scraping di contenuti citati da Google:
- Siti che copiano e ripubblicano contenuti da altri siti senza aggiungere alcun contenuto o valore originale
- Siti che copiano contenuti da altri siti, li modificano leggermente (ad esempio sostituendo sinonimi o utilizzando tecniche automatizzate) e li ripubblicano
- Siti che riproducono feed di contenuti da altri siti senza fornire alcun tipo di organizzazione o beneficio unico all’utente
- Siti dedicati all’incorporazione di contenuti come video, immagini o altri media da altri siti senza un sostanziale valore aggiunto per l’utente
Questo non va confuso con la syndication di contenuti, che di solito avviene quando si ripubblicano i propri contenuti per ottenere una maggiore diffusione. La syndication di contenuti può essere effettuata anche da terzi, ma c’è una linea sottile tra questa e lo scraping di contenuti. Se qualcuno sta facendo syndication dei contenuti, è necessario utilizzare tag speciali come rel=canonical o noindex.
Esistono molti plugin di terze parti per WordPress che consentono di acquisire automaticamente i feed RSS di terze parti. Anche se gli sviluppatori hanno buone intenzioni, purtroppo a volte questi plugin vengono abusati e utilizzati per lo scraping di contenuti. Uno dei motivi per cui WordPress è così popolare è la sua facilità d’uso, ma a volte questo può anche ritorcersi contro.
Esempio di content scraping farm
Le chiamiamo farm, ovvero “fattorie”, quando lo stesso proprietario effettua lo scraping di contenuti su decine di siti. In genere sono facili da individuare perché il proprietario del sito di solito utilizza lo stesso tema per tutti i siti e anche solo una leggera variazione tra i nomi di dominio.
Nel post di oggi utilizziamo un esempio reale! Non ci vergogniamo di denunciare questo tipo di siti perché non forniscono alcun valore aggiunto e non fanno altro che vanificare il duro lavoro svolto dagli editori di contenuti. Ecco un esempio di scraping farm di contenuti. Abbiamo archiviato ogni link nel caso in cui i siti dovessero scomparire in futuro. Potete cliccare su ognuno di essi e vedere che utilizzano tutti lo stesso tema e gli stessi contenuti di scraping. In genere uno scraper prende i contenuti da molte fonti diverse, il nostro blog è una di queste.
- thetechworld.xyz (link archiviato)
- mytechnewstoday.org (link archiviato)
- mytechcrunch.com (link archiviato)
- technewssites.xyz (link archiviato)
- technewssites.info (link archiviato)
- www.thetechworld.info (link archiviato)
- www.mytechnewstoday.xyz (link archiviato)
- www.futuretechnologynews.info (link archiviato)
- futuretechnologynews.xyz (link archiviato)
Come potete vedere qui sotto, si tratta di un semplice scraping dei post del nostro blog, parola per parola, insieme a tutti i nostri articoli su tutti i domini di cui sopra.
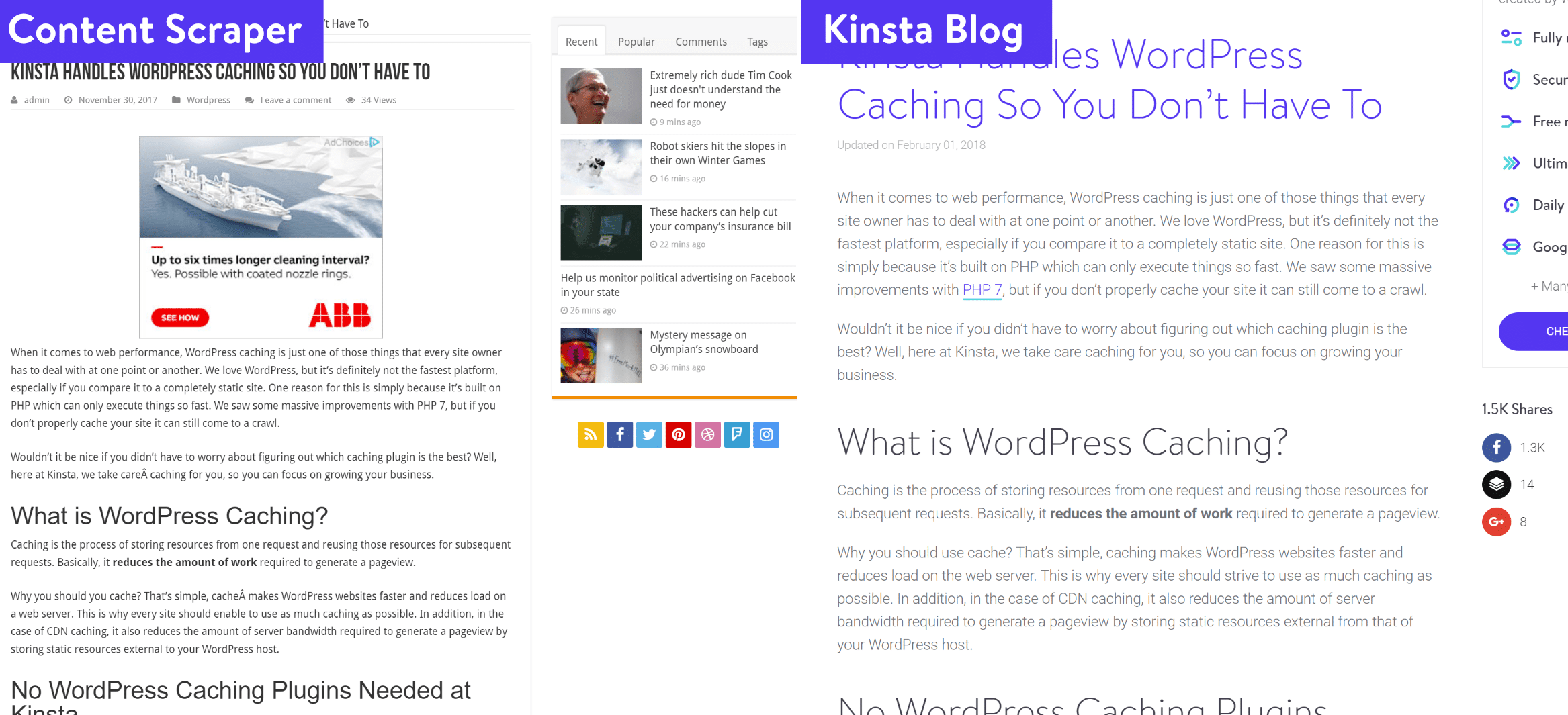
Come trovarli?
Uno dei modi più semplici per trovarli è utilizzare uno strumento come Copyscape o Ahrefs (se stanno copiando anche i vostri link interni). Copyscape permette anche di inviare il vostro file sitemap e di ricevere una notifica automatica quando scansiona il web e trova i contenuti.

Potete anche effettuare una ricerca manuale su Google utilizzando il tag “allintitle”. Basta inserire il tag insieme al titolo del vostro post. Esempio: allintitle: Kinsta Handles WordPress Caching So You Don’t Have To

La parola chiave allintitle induce Google a cercare quelle parole solo nei titoli dei post. Il secondo metodo, più efficace, consiste nel cercare un testo all’interno del vostro post, con il termine di ricerca tra doppi apici. Le doppie virgolette indicano a Google di cercare esattamente lo stesso testo. Potreste ottenere dei falsi positivi con la ricerca del titolo, perché qualcuno potrebbe usare lo stesso titolo, ma il secondo metodo è molto più efficace perché è altamente improbabile che qualcuno abbia le stesse frasi o gli stessi paragrafi.
Lo scraping dei contenuti influisce sulla SEO?
La prossima domanda che probabilmente vi farete è: in che modo questo influisce sulla SEO? Nell’esempio precedente, infatti, l’azienda di scraping dei contenuti non utilizza i tag rel=canonical, i crediti o i tag noindex. Ciò significa che quando il bot di Google effettuerà il crawling, penserà che si tratti del loro contenuto originale. Non è giusto, potreste pensare. E avete ragione, non lo è. Noi abbiamo pubblicato i contenuti e loro li hanno copiati. Tuttavia, prima di farvi prendere dal panico, è importante capire cosa succede davvero dietro le quinte.
Innanzitutto, anche se il crawler di Google potrebbe considerarlo un loro contenuto, molto probabilmente l’algoritmo di Google non lo vede. Google non è stupido e ha messo in atto molte regole e controlli per garantire che i proprietari dei contenuti originali ricevano comunque il merito. Come facciamo a saperlo? Diamo un’occhiata a ciascuno di questi post dal punto di vista SEO.
Questa persona ha fatto lo scraping del nostro post nel novembre 2017, quindi ha avuto tutto il tempo di posizionarsi se voleva farlo. Quindi, tiriamo fuori il nostro pratico strumento Ahrefs e controlliamo quali sono le parole chiave per cui il post si sta posizionando. E possiamo vedere che non si classifica per nessuna parola chiave. Quindi, per quanto riguarda il traffico organico, non traggono alcun beneficio da questo post.
Se selezioniamo il nostro post originale su Ahrefs, possiamo vedere che ci posizioniamo per 96 parole chiave.

Quando Google vede quello che si potrebbe pensare sia un contenuto duplicato, utilizza molti segnali e dati diversi per capire chi ha scritto originariamente il contenuto e cosa dovrebbe essere classificato. Ecco un paio di esempi:
- Date di pubblicazione (anche se in questo caso il contenuto è stato copiato lo stesso giorno)
- Autorità del dominio e page rank. Sì, Google probabilmente utilizza ancora il page rank internamente
- Segnali social
- Traffico
- Backlink
Anche in questo caso si tratta di ipotesi, dato che nessuno sa realmente cosa utilizzi Google. Ma il punto è che probabilmente non c’è bisogno di perdere il sonno se qualcuno ha copiato i vostri contenuti. Tuttavia, potreste comunque fare qualcosa al riguardo. Inoltre, non è impossibile che qualcun altro vi superi nel ranking con i vostri contenuti. Approfondiamo questo aspetto qui di seguito.
Cosa facciamo per lo scraping dei contenuti
Creare contenuti utili, unici e condivisibili non è facile, richiede molto del vostro tempo prezioso (e spesso costa molto denaro), quindi dovete assolutamente proteggerli. Ma ecco altri motivi per cui non dovreste ignorare gli scrapers.
- Se un sito con una quantità significativa di traffico sta copiando i vostri contenuti e li utilizza per integrare i suoi altri contenuti, è possibile che ne stia traendo vantaggio. Questo non è assolutamente corretto, visto che siete i proprietari originali del contenuto.
- Cose del genere possono alterare seriamente i dati nei vostri strumenti di reportistica e rendervi la vita più difficile. Ad esempio, questi dati vengono visualizzati nei rapporti sui backlink di strumenti come Ahrefs o Majestic. Più si è “grandi”, più la situazione si complica.
- Volete affidarvi esclusivamente a Google per capire se il contenuto originale è il vostro o il loro? Nonostante loro siano molto intelligenti in questo senso, noi sicuramente preferiamo di no. Inoltre, anche se il loro post non è posizionato sui motori di ricerca per nessuna parola chiave, in realtà è indicizzato da Google (come si vede qui sotto).

Contattare il proprietario del sito web e presentare un reclamo DMCA
Per essere sicuri di ottenere il giusto merito, di solito contattiamo prima il proprietario del sito web e ne chiediamo la rimozione. Vi consigliamo di creare alcuni template di e-mail da riutilizzare per accelerare questo processo e non perdere tempo. Se non riceviamo risposta dopo un paio di tentativi, facciamo un ulteriore passo avanti e presentiamo un reclamo DMCA.
I reclami DMCA possono essere un po’ complicati perché devi cercare l’IP del sito, trovare l’host, ecc. Ma non c’è da preoccuparsi: abbiamo documentato tutti i passaggi per presentare facilmente un reclamo DMCA e per rintracciare il proprietario. Potete anche inoltrare una richiesta di rimozione legale direttamente a Google.
Per quanto riguarda l’esempio di cui abbiamo parlato sopra, sembra proprio che per noi sia giunto il momento di fare il passo successivo poiché non siamo riusciti a contattare il proprietario del sito web. 😩
Aggiornare il file di disavow
Per assicurarci che questi non abbiano alcun impatto sul nostro sito (indipendentemente da ciò che accadrà con il reclamo DMCA), aggiungiamo questi domini nel nostro file di disavow. Ciò indica a Google che non vogliamo avere nulla a che fare con loro e che non stiamo cercando di manipolare le SERP in alcun modo.
Se state facendo questo per un sito di qualità superiore, potete anche inviare solo l’URL per il disavowal, invece dell’intero dominio. In genere, però, non si vedono siti di alta qualità che effettuano lo scraping di contenuti.
Passo 1
In Ahrefs selezioniamo il dominio in questione e clicchiamo su “Disavow Domains”. In questo modo ci assicuriamo che tutto ciò che proviene da questo sito web di scraping di contenuti non abbia mai un impatto su di noi.

La cosa migliore di Ahrefs quando si tratta di questo tipo di problemi è l’opzione “Nascondi i link disavowed”. In questo modo i domini e gli URL vengono automaticamente nascosti per non essere visualizzati in futuro nel vostro report principale. Ciò è molto utile per restare organizzati e non perdere la testa, soprattutto se utilizzate esclusivamente Ahrefs per gestire i vostri backlink. 👍

Passo 2
Come potete vedere qui sotto, abbiamo aggiunto tutti i domini della content scraping farm alla nostra sezione di Ahrefs dedicata ai link non riconosciuti. Il passo successivo è cliccare su “Esporta” e ottenere il file di disavow (TXT) da inviare a Google Search Console.

Passo 3
Andate quindi allo Strumento di disavow di Google. Selezionate il vostro profilo di Google Search Console e cliccate su “Disavow Links”.

Passo 4
Scegliete il file di disavow esportato da Ahrefs e inviatelo. In questo modo il file di disavow precedente verrà sovrascritto. Se non avete mai utilizzato Ahrefs in passato e se esiste già un file di disavow, è consigliabile scaricare quello attuale, unirlo a quello nuovo e caricarlo. Da quel momento in poi, se utilizzerete solo Ahrefs, potrete semplicemente caricarlo e sovrascriverlo.

Bloccare gli IP degli scraper
Potete anche fare un ulteriore passo avanti e bloccare gli IP degli scrapers. Una volta individuato il traffico insolito (cosa che a volte può essere difficile da fare), potete bloccarlo sul vostro server utilizzando file .htaccess o regole Nginx. Se siete clienti di Kinsta, il nostro team di supporto può bloccare gli IP per voi. Oppure se utilizzate un WAF di terze parti come Sucuri o Cloudflare, anche questi hanno delle opzioni per bloccare gli IP.
Riepilogo
Le farm di scraping di contenuti potrebbero non influire sempre sulla vostra SEO, ma sicuramente non aggiungono alcun valore agli utenti. Vi consigliamo di dedicare un po’ di tempo alla loro eliminazione. Noi, per esempio, abbiamo un’intera scheda di Trello dedicata alle richieste di “takedown”. Ciò aiuta a rendere il web un posto migliore per tutti e garantisce che i vostri contenuti unici siano visti e classificati solo sul vostro sito.
Cosa ne pensate dello scraping di contenuti? Cercate di combatterlo o semplicemente lo ignorate? Ci piacerebbe sentire le vostre opinioni qui sotto nei commenti.

Brian ha una grande passione per WordPress, lo usa da più di dieci anni e sviluppa anche un paio di plugin premium. Brian ama i blog, i film e le escursioni. Entra in contatto con Brian su Twitter.

