
Bot-Traffic wird oft als Sicherheitsproblem oder SEO-Problem dargestellt. Auf der WordPress-Hosting-Infrastruktur zeigt er sich jedoch als ein Leistungsproblem, das sich auf eine ganz bestimmte Gruppe von URLs konzentriert.
Nicht alle Anfragen kosten das Gleiche. Der Unterschied zwischen einer statischen Seite im Zwischenspeicher und einem dynamischen Endpunkt ist nicht nur eine kleine Leistungsabweichung. Es ist der Unterschied zwischen einer Anfrage, die fast nichts kostet, und einer, die einen PHP-Thread reserviert, eine komplette Datenbankabfrage auslöst und Sitzungs-Overhead erzeugt, unabhängig davon, ob der Besucher ein echter Kunde oder ein Bot ist, der nie konvertiert.
Wenn du verstehst, warum manche Endpunkte viel teurer sind als andere, kannst du eine Bot-Management-Strategie, die tatsächlich funktioniert, von einer Strategie unterscheiden, die zu viel oder zu wenig blockiert.
Nicht alle Anfragen sind gleich
Wenn ein Besucher auf einer typischen WordPress-Website landet, wie z.B. einem Blogbeitrag, einer Produktliste oder einer „Über“-Seite, liefert der Server die Antwort fast immer aus dem Cache.
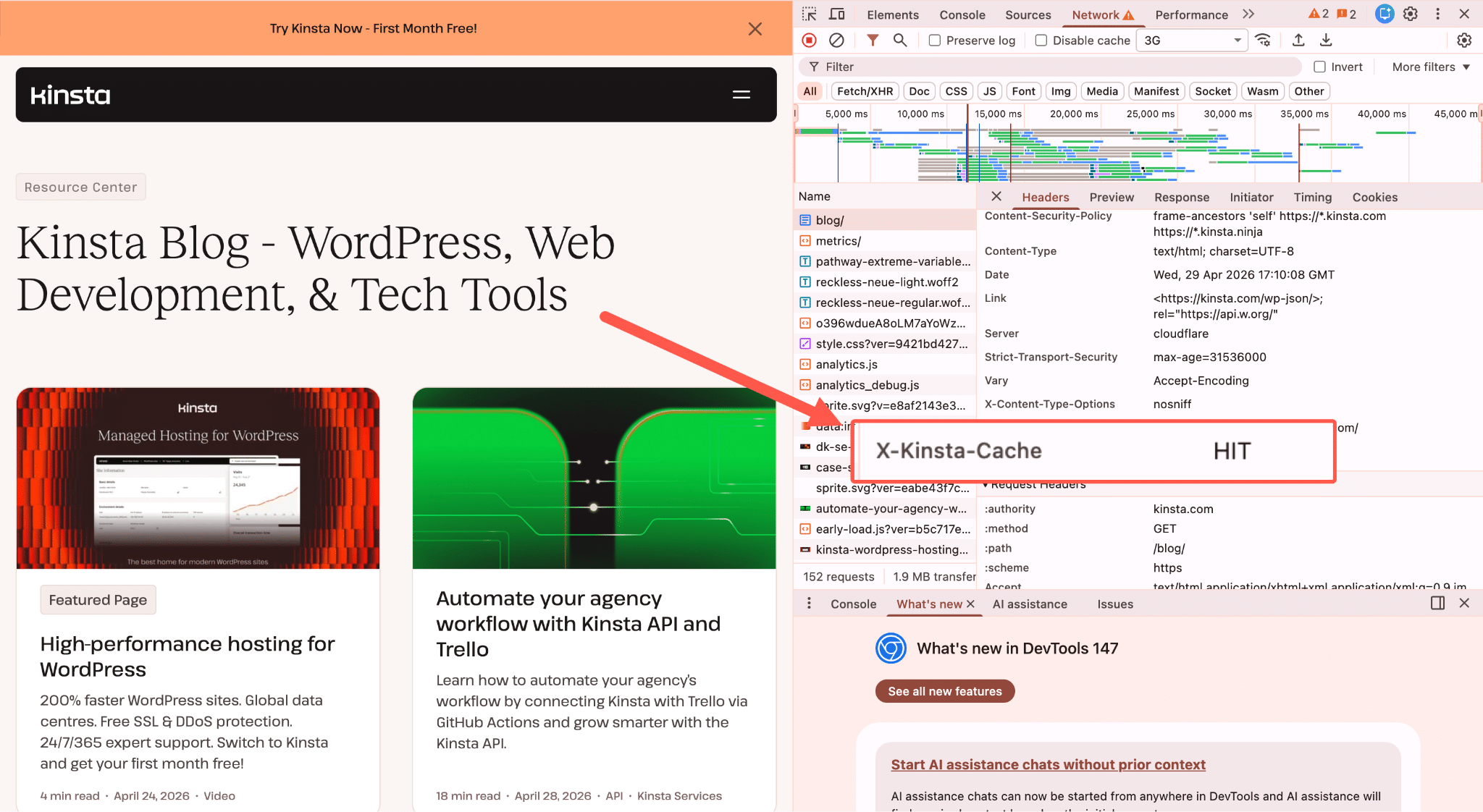
Der Ganzseiten-Cache von Kinsta erledigt dies am Rande, so dass die Anfrage nie das PHP eines Servers oder dessen Datenbank auslöst.
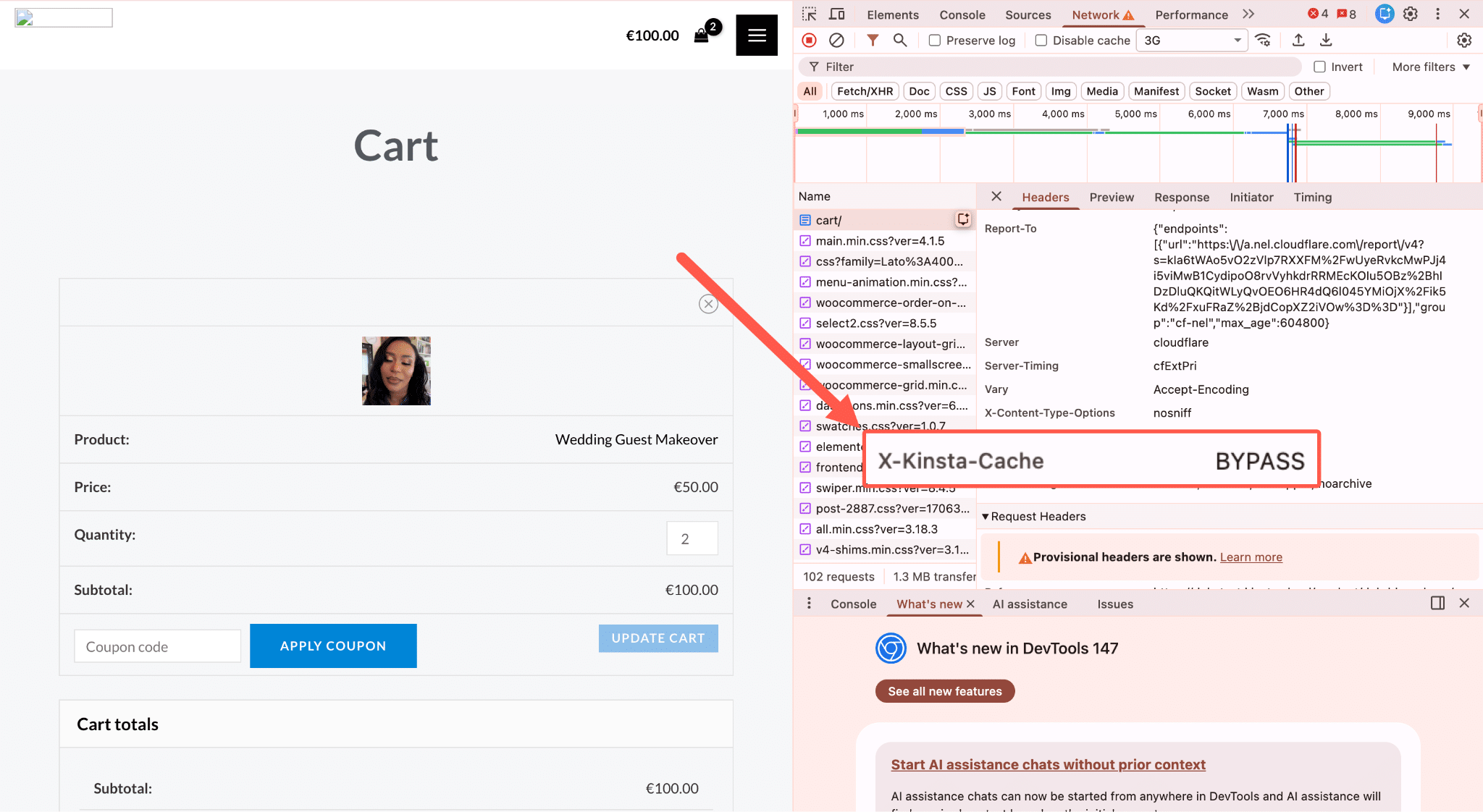
Aber wenn eine Anfrage auf einem nicht cachefähigen Endpunkt landet, muss der Server echte Arbeit leisten. Ein PHP-Thread wird zugewiesen und für die gesamte Dauer der Anfrage gehalten, und deine Datenbank wird abgefragt. Wenn die Website den Status des Warenkorbs, Benutzersitzungen oder personalisierte Inhalte enthält, kommt eine weitere Ebene hinzu. Nichts davon kann zwischengespeichert werden, da die Antwort für jede Anfrage einzigartig ist.
Auf einer gesunden Website mit überwiegend menschlichen Besuchern ist das in Ordnung. Deine dynamischen Endpunkte bedienen echte Kunden, die Artikel in ihren Warenkorb legen, zur Kasse gehen und nach Produkten suchen. Die Belastung ist proportional zur tatsächlichen Nutzung.
Bot-Traffic macht dieses Modell zunichte. Ein Crawler legt nichts in den Warenkorb oder konvertiert nicht, aber er löst die gleiche serverseitige Ausführung aus wie ein echter Kunde, und zwar in einem Tempo, das kein Mensch aufrechterhalten könnte.
Die spezifischen Endpunkte, an denen dies auftritt
In einem WooCommerce-Shop sind die folgenden URL-Muster und Endpunkte von vornherein nicht zwischenspeicherbar, und das sind genau die, die vom Bot-Traffic am stärksten betroffen sind.
?add-to-cart=
Dies ist das ressourcenintensivste Beispiel, das wir in unserem Bericht über KI und Bot-Traffic dokumentiert haben. Das Hinzufügen eines Produkts zum Warenkorb erfordert die Ausführung von PHP, einen Datenbankzugriff und die Erstellung oder Validierung einer Sitzung. Es gibt keine zwischengespeicherte Version dieser Antwort, da jeder Treffer ein neuer Vorgang ist.
Um das Ausmaß zu verdeutlichen: Die Infrastrukturdaten von Kinsta haben in einem 24-Stunden-Fenster 7,67 Millionen „In den Warenkorb“-Treffer von fünf Bots aufgezeichnet.
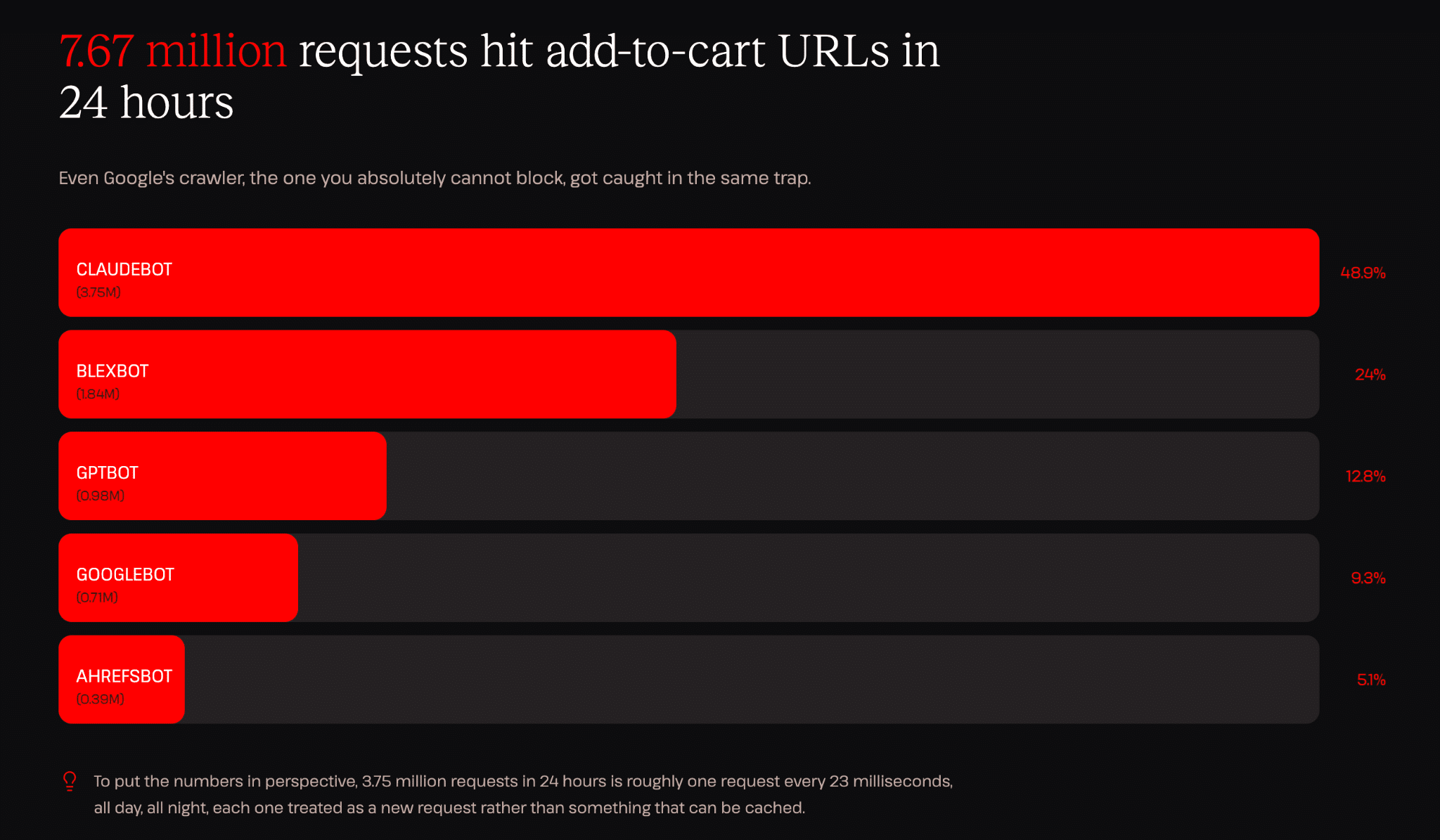
Das ist etwa eine Anfrage alle 11 Millisekunden, den ganzen Tag und die ganze Nacht lang, jede mit voller PHP- und Datenbank-Ausführung, ohne sinnvolle Ausgabe für den Crawler und ohne direkten Kundenbezug.
/cart und /checkout
Diese Seiten sind in WooCommerce standardmäßig vom Seitencache ausgeschlossen. Sie enthalten Live-Sitzungsdaten, den Status des personalisierten Warenkorbs und (im Fall von checkout) die Logik für die Zahlungsabwicklung.
Ein Bot, der /checkout wiederholt aufruft, tut nichts Nützliches, aber der Server weiß das nicht. Er verarbeitet jede Anfrage so, als ob es sich um eine echte Transaktion handeln könnte.
?s= (Suchanfragen)
WordPress- und WooCommerce-Suchanfragen werden bei jeder Anfrage mit deiner Datenbank abgeglichen. Es gibt keine Cache-Schicht, die einen eindeutigen Suchstring aufnehmen kann.
Ein Crawler, der durch parametrisierte URL-Variationen arbeitet oder einfach jedem Suchlink folgt, den er findet, kann einen langen Schwanz von einzigartigen, teuren Datenbankabfragen erzeugen.
Facettierte Navigation und Filterparameter
An dieser Stelle wird das Problem noch größer. Ein typischer WooCommerce-Produktkatalog erzeugt URLs wie:
/shop/?color=blue
/shop/?color=blue&size=M
/shop/?color=blue&size=M&orderby=price
/shop/?color=blue&size=M&orderby=price&paged=2Für einen Menschen sind dies kleine Variationen derselben Seite. Für einen Bot, der den Links folgt, ist jede von ihnen eine einzigartige URL, die es wert ist, gecrawlt zu werden, und für jede muss der Server eine gefilterte Datenbankabfrage von Grund auf durchführen.
In der Google-Dokumentation wird die facettierte Navigation ausdrücklich als Ursache für die Crawling-Ineffizienz genannt, bei der die Crawler fast unendlich viele Variationen desselben Inhalts untersuchen. Das Problem ist aber nicht nur, dass dadurch Crawl-Budget verschwendet wird. Jede Variation kostet echte Server-Ressourcen, um sie zu erzeugen.
AJAX-gestützte Interaktionen
Viele WordPress-Plugins, wie z. B. Wunschlisten, Verfügbarkeitsprüfungen, Live-Preisaktualisierungen und Kalenderansichten, basieren auf AJAX-Anfragen, die den Seiten-Cache vollständig umgehen.
Ein Bot, der diese Interaktionen auslöst, und sei es auch nur indirekt durch das Laden einer Seite, die diese Interaktionen auslöst, erzeugt serverseitige Last, die zwar nicht als „Seitenanforderung“ in deinen Analysen auftaucht, aber in deiner PHP-Thread-Nutzung sichtbar wird.
Was passiert, wenn die PHP-Threads aufgebraucht sind
Jeder dynamische Endpunkt hält einen PHP-Thread für die gesamte Dauer der Anfrage. Dieses Detail scheint für sich genommen unbedeutend zu sein, aber die Thread-Kapazität ist begrenzt und Bots stellen sich nicht höflich in Warteschlangen an.
Kinsta weist jeder WordPress-Website eine feste Anzahl von PHP-Threads zu, und jede nicht gecachte Anfrage reserviert einen für ihre Dauer.
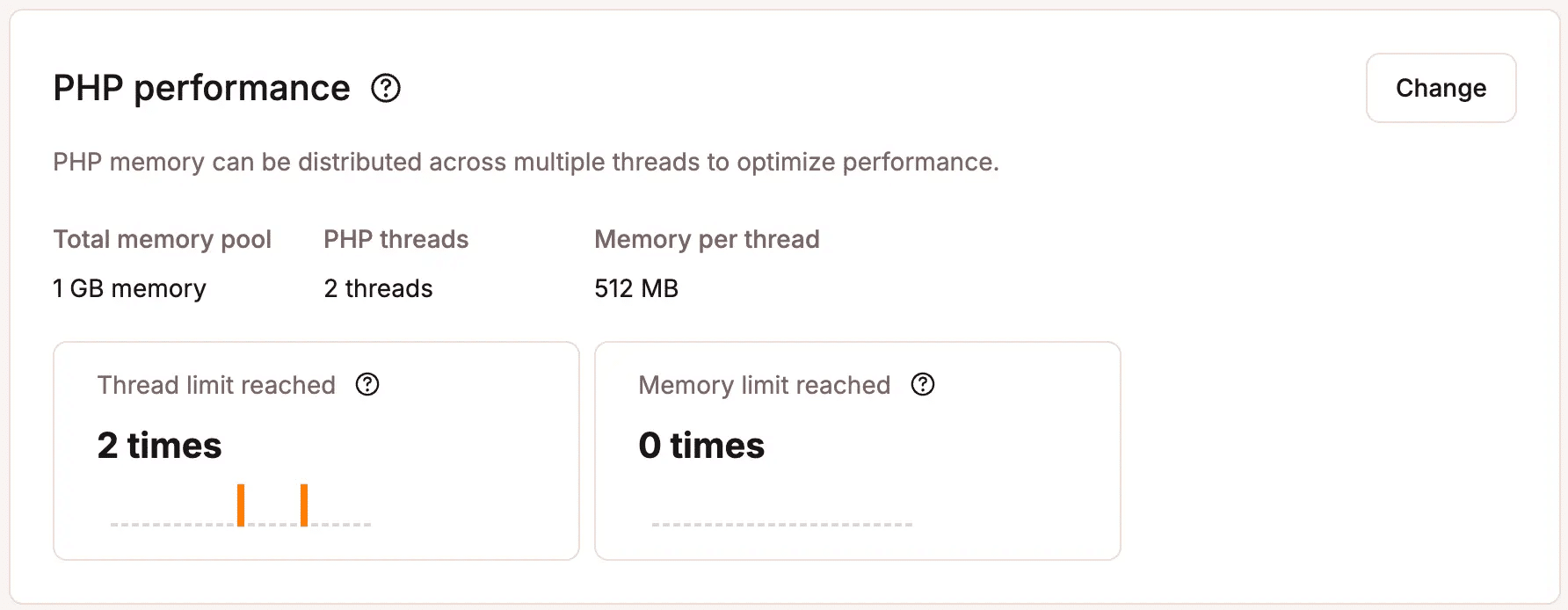
Bei normalem Datentraffic ist dies selten eine Einschränkung. Die Anfragen kommen rein, werden schnell bearbeitet und die Threads werden frei.
Bei anhaltender Bot-Last auf dynamischen Endpunkten werden Threads reserviert und gehalten. Wenn alle Threads belegt sind, warten die neu eingehenden Anfragen in einer Warteschlange. Echte Kunden, die versuchen, ein Produkt in ihren Einkaufswagen zu legen oder den Bestellvorgang abzuschließen, erleben langsame Seitenladevorgänge, Timeouts oder HTTP 504 Fehler.

Dies ist die infrastrukturelle Realität, die den Bot-Traffic auf dynamischen Endpunkten wesentlich von dem auf cachefähigen Seiten unterscheidet.
Das Schleifenproblem: Wenn Bots feststecken
Ein Großteil des Bot-Traffics, den das Kinsta-Infrastrukturteam sieht, ist nicht das Ergebnis eines absichtlichen Angriffs. Er ist das Ergebnis von Crawlern, die jedem Link auf jeder Seite folgen, ohne einen Mechanismus, der erkennt, wenn sie sich im Kreis drehen.
So sieht eine Query-String-Schleife in der Praxis aus:
- Ein Bot kommt bei
/shop/an - Die Seite enthält einen Link zu
/shop/?color=blue(eine gefilterte Ansicht) - Diese Seite enthält einen Link zu
/shop/?color=blue&size=M - Diese Seite enthält einen Link zu
/shop/?color=blue&size=M&orderby=price - Diese Seite enthält einen Link, um etwas in den Warenkorb zu legen:
/shop/?add-to-cart=123 - Jede dieser Seiten erzeugt leicht unterschiedliche Links, die der Bot noch nicht besucht hat
Der Bot folgt jedem. Er hat kein Konzept von „Ich habe diese Produktseite bereits in einem anderen Filterzustand gesehen“ Jede URL sieht neu aus, wird angefordert und trifft auf dem Server ein.
Genau dieses Muster von Bots, die Abfrage-String-Variationen über dynamische Endpunkte hinweg durchlaufen, ist eines der häufigsten Probleme, die wir in unserem Bericht festgestellt haben. Eine einzige Schleifenregel, die durch ein fehlerhaftes Muster ausgelöst wurde, filterte 550 Millionen Anfragen in 30 Tagen in der Kinsta-Infrastruktur. Das ist kein Angriff, sondern eine ineffiziente Automatisierung in großem Maßstab, die sich verschlimmert, weil sie nicht frühzeitig erkannt wird.
Wie gutes Bot-Management auf der Endpunktebene aussieht
Für WooCommerce-Shops und WordPress-Websites mit dynamischen Funktionen gelten unabhängig von der jeweiligen Konfiguration ein paar Grundsätze.
- Robots.txt ist ein Signal, kein Schutzschild. Du kannst (und solltest) Crawlern den Zugriff auf die Pfade
/cart,/checkoutund?add-to-cart=in deinerrobots.txtverbieten. Googlebot respektiert dies. Die Einhaltung derrobots.txtist jedoch freiwillig. Ein wachsender Teil der KI-Trainingscrawler prüft sie entweder nicht oder beachtet sie nicht. Wenn du einen Pfad in derrobots.txtverbietest, kommunizierst du deine Absicht; um sie durchzusetzen, brauchst du eine Regel auf WAF-Ebene. - Verschärfe die Generierung von URL-Parametern. Die Standardkonfiguration von WooCommerce generiert einen langen Schwanz von URL-Varianten durch Session-Token, Mengenparameter und Filterkombinationen. Wenn du den Parameterwildwuchs an der Quelle durch kanonische Tags, konsolidierte Permalink-Strukturen und robots.txt
Disallow-Regelnfür Parametervarianten einschränkst, bleiben Crawler in weniger Schleifen stecken. - Beobachte die Endpunkte, nicht nur das gesamte Anfragevolumen. Ein Anstieg des gesamten Trafficaufkommens könnte auf eine Kampagne hindeuten. Ein Anstieg der Anfragen an
?add-to-cart=von einem User-Agent, der nicht im Browser arbeitet, ist ein Bot-Problem. Serverprotokolle und Analysetools, die dir die Verteilung der Anfragen nach URL-Muster und User-Agent zeigen, machen den Unterschied aus, ob du das Problem innerhalb von Stunden oder erst in einigen Tagen erkennst. - Schütze die PHP-Thread-Kapazität als primäre Metrik. Wenn deine PHP-Threads regelmäßig ausgelastet sind und du keinen entsprechenden Anstieg der echten Benutzersitzungen hast, ist der Bot-Traffic auf dynamischen Endpunkten mit ziemlicher Sicherheit ein Faktor, der dazu beiträgt. Das APM-Tool von Kinsta zeigt die langsamsten PHP-Transaktionen pro Endpunkt an. Wenn also der Warenkorb oder der Checkout-Pfad der Übeltäter sind, siehst du das direkt, anstatt zu raten.
So sieht das für verschiedene Website-Typen aus
Das Problem mit den dynamischen Endpunkten tritt vor allem bei WooCommerce-Shops auf, aber auch bei anderen Website-Typen kann es in verschiedenen Formen auftreten.
- WooCommerce-Shops sind am stärksten gefährdet, weil ihre teuersten Endpunkte wie Warenkorb, Kasse und gefilterte Produktseiten genau diejenigen sind, die Bots durch normales Link-Following finden. Die Folgen sind direkt: Die Erschöpfung von PHP-Threads während Bot-Spikes verschlechtert die Checkout-Leistung für echte Kunden.
- Content-Websites und Blogs sind beim Checkout weniger gefährdet, können aber durch Bots, die paginierte Archive, Tag-Seiten und Suchergebnisse durchforsten, erheblich beeinträchtigt werden. Jede einzelne Suchanfrage ist ein neuer Datenbankzugriff. Ein aggressiver Crawler, der sich systematisch durch ein großes Archiv arbeitet, kann eine anhaltende Datenbanklast erzeugen, auch wenn er keine „Shop“-Funktionalität berührt.
- Unternehmens- und Dienstleistungswebsites sind stärker von Formularendpunkten (Kontaktformulare, Formulare für Angebotsanfragen und Buchungsvorgänge) betroffen, die Sitzungsdaten verarbeiten und oft in die Datenbank schreiben. Von Bots übermittelte Formulardaten sind eine andere Art von Problem (CRM-Verschmutzung, verschwendete Verkaufsanstrengungen), aber der zugrunde liegende Mechanismus ist derselbe: dynamische Endpunkte, die bei jedem Treffer echte Ressourcen kosten.
- Web-Apps und SaaS-Produkte sind der empfindlichste Fall. Ihre API-Endpunkte, Dashboard-Routen und Anwendungslogik können nicht zwischengespeichert werden, und jeglicher Bot-Traffic, der die Anwendungsschicht erreicht, umgeht die Caching-Infrastruktur vollständig. Die angemessene Reaktion ist hier in der Regel eine harte Blockade des gesamten nicht authentifizierten Datentraffics zu den Pfaden
/apiund/app, wobei legitime Integrationen ausdrücklich zugelassen werden.
Tiefer gehen: Das Gesamtbild des Bot-Traffics
Das Problem der dynamischen Endpunkte ist Teil einer breiteren Veränderung in der Art und Weise, wie Bot-Traffic die WordPress-Infrastruktur beeinflusst. Das Volumen der KI-Crawler hat deutlich zugenommen und ihr Verhalten hat sich verändert: aggressiveres Link-Following, mehr Bereitschaft, Crawl-Direktiven zu ignorieren und mehr Traffic, der genau die Endpunkte trifft, die am meisten Kosten verursachen.
Einen vollständigen Überblick über die Veränderungen, die zugrunde liegenden Daten und einen Rahmen für Entscheidungen zum Bot-Management auf der Grundlage deines spezifischen Website-Typs und deiner Prioritäten findest du im Kinsta-Report „The AI & Bot Traffic Reality Check„, der eine Analyse von mehr als 10 Milliarden Anfragen auf der von Kinsta verwalteten Infrastruktur enthält.
Wenn du bereit bist, nach dem, was du hier gelesen hast, zu handeln, behandelt der Bot-Schutz von Kinsta die häufigsten Muster automatisch, einschließlich des Schutzes für kostenintensive dynamische Endpunkte. Aktiviere die gewünschte Schutzstufe einmalig in MyKinsta, und das System kümmert sich um den Rest.
Du kannst dich auch an das Support-Team wenden, wenn du weitere Fragen hast.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.

